本文是介绍HBM的第二篇文章,对第一篇感兴趣的可以看这篇文章。高带宽内存(HBM)的概念、架构与应用
本文是一篇技术文章,详细解释了什么是HBM(高带宽内存),深入介绍了其3D堆叠架构、先进封装技术的关键作用,以及其在现代GPU、AI加速器和嵌入式系统中的应用。

引言
"内存墙"问题的出现,是因为处理器性能的增长速度远超内存带宽的提升。人工智能(AI)和高性能计算(HPC)工作负载需要处理海量张量数据,而传统的DDR或GDDR内存由于总线位宽较窄且依赖高时钟频率,已难以满足需求。高带宽内存(HBM)通过大幅拓宽数据通道------例如HBM3的位宽高达1024位,并将多个DRAM芯片垂直堆叠,有效缓解了这一瓶颈。
那么,究竟什么是HBM?从架构角度看,HBM技术通过硅通孔(TSV)将多层DRAM芯片垂直堆叠并互连,在不依赖极高时钟频率的情况下实现巨大的数据并行性。与独立的内存模块不同,HBM被放置在处理器旁侧的硅中介层(silicon interposer)上,从而显著降低延迟并提升能效。对于在系统设计中探究"什么是HBM"的工程师而言,其提供每秒数TB级别带宽的能力,使其成为AI加速器、GPU以及前沿HPC平台的理想选择。
不过,你可能仍对"什么是HBM"感到好奇?接下来,让我们从它的起源与背景开始深入探讨。
背景:内存墙与总线位宽的扩展
现代CPU和GPU每秒可执行数万亿次运算,但其实际吞吐量往往并非受限于计算单元,而是受制于内存带宽。随着晶体管数量的增加以及多核流水线的不断加深,外部内存已无法以足够快的速度提供数据------这一瓶颈被称为"内存墙"。
这一性能瓶颈的根源在于:逻辑单元的集成密度和时钟频率的提升速度远快于片外数据传输能力,导致算术逻辑单元(ALU)在等待数据时处于空闲状态。传统的DDR和GDDR内存技术试图通过提高时钟频率来弥补这一差距,但更高的频率需要复杂的端接设计、严格的阻抗控制,并带来更高的功耗。
例如,DDR5在16位通道上可达到4.8--6.4 GT/s的数据速率,而GDDR6X在32位接口上每引脚速率接近21--22 Gb/s。若使用GDDR6实现512 GB/s的带宽,则需多个内存芯片以及高速PCB布线,这会引发信号完整性与散热方面的挑战。
为突破这些限制,工程师们采用了截然不同的方案:高带宽内存(HBM)。HBM不再依赖窄总线以极高速度运行,而是采用超宽接口------位宽达1024位甚至更高------同时以相对较低的频率工作。这种"宽、慢、堆叠"的设计范式,不仅实现了数百GB/s的带宽,还显著降低了每比特的功耗,简化了均衡设计,并减少了电磁干扰(EMI)。
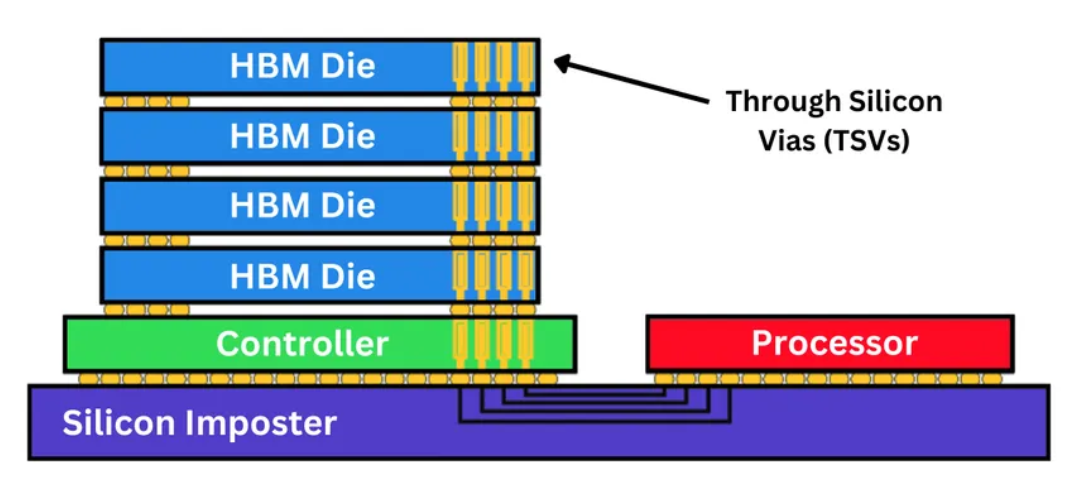
HBM技术的基础在于通过硅通孔(Through-Silicon Vias, TSV)实现的3D堆叠DRAM。TSV是一种垂直互连结构,可将信号穿过硅芯片内部。每个HBM堆栈由多个DRAM层堆叠在一块逻辑裸片(logic die)之上构成,该逻辑裸片负责管理刷新、训练和数据调度等任务。整个堆栈通过硅中介层(silicon interposer)与GPU或CPU相连------这种先进封装基板提供了高密度的微凸块(microbump)互连。
尽管自2000年代初以来,3D堆叠技术已在存算一体(logic-in-memory)和NAND闪存研究中被广泛探索,但HBM是首个实现大规模量产并获得JEDEC标准化的DRAM架构。
HBM1标准于2013年获批,并于2015年首次在AMD的Fiji GPU(Radeon R9 Fury X)中实现商业化应用,开创了在2.5D中介层上集成堆叠式HBM模块的先河。该设计实现了512 GB/s的带宽,同时功耗显著低于GDDR5。
2016年,英伟达(Nvidia)在其面向高性能计算(HPC)和AI训练工作负载的Tesla P100加速器中采用了HBM2,标志着HBM开始向数据中心加速器领域扩展。随后,三星(Samsung)、SK海力士(SK hynix)和美光(Micron)迅速成为HBM的主要供应商,不断在芯片堆叠层数、TSV间距和能效方面进行迭代优化。
到2019年,HBM2E已将每引脚数据速率提升至3.2 Gb/s以上;而如今的HBM3和HBM3E更是突破6.4 Gb/s,单堆栈带宽超过1 TB/s。这些进步使AI加速器、超级计算机和新一代GPU能够高效处理大规模并行工作负载。
如今,高带宽内存已成为人工智能应用、机器学习推理和高性能计算集群不可或缺的核心组件------过去正是内存瓶颈严重制约了这些系统的性能。凭借3D堆叠、超宽接口和低功耗设计的综合优势,HBM已然成为下一代半导体存储架构的基石。
架构与技术
堆叠结构与数据组织
每个HBM堆栈由一个逻辑基底裸片和多层DRAM芯片组成,通过硅通孔(TSV)和微凸块实现垂直互连。逻辑裸片集成了内存控制器、I/O接口、ECC(错误校正码)管理、刷新逻辑以及电源传输电路。在其上方,通常堆叠8至12片经过减薄处理的DRAM芯片,精确对准并键合,形成一个3D堆叠的DRAM模块。
每个HBM堆栈提供16个独立的64位通道,支持对内存体(bank)进行细粒度访问。HBM3进一步提升了并发能力,将每个64位通道拆分为两个32位的"伪通道"(pseudo-channel),从而实现命令流与数据流的并行处理。一条命令总线协调各类操作,而数据总线则采用双倍数据速率(DDR)信令传输有效载荷。
尽管HBM运行频率相对适中,但其1024位的超宽接口带来了惊人的聚合吞吐量。以HBM3为例,在每引脚6.4 Gb/s的速率下,单堆栈带宽可达819 GB/s,远超传统DDR5或GDDR6内存。而由美光、三星和SK海力士共同开发的新一代HBM3E标准,已将每引脚速率提升至9.8 Gb/s,单堆栈带宽逼近1 TB/s------这一突破性性能成为数据中心中AI训练、机器学习和高性能计算加速器的关键使能技术。
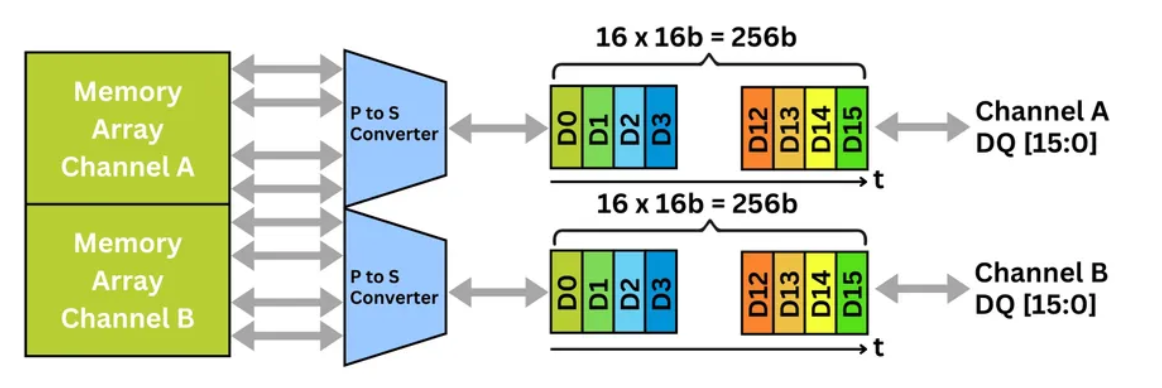
除了原始速度之外,HBM内存还集成了片上ECC(错误校正码)、故障修复和自适应刷新机制。逻辑裸片能够屏蔽故障页面、映射有缺陷的TSV,并动态重新训练时序,以维持系统的可靠性。其解耦的时钟架构允许命令总线以数据频率的一半运行,从而降低抖动并提升信号裕量------这对于多堆栈、高性能部署至关重要。
2.5D封装与硅中介层
HBM接口极其宽广------每个堆栈拥有超过1000个I/O连接------无法使用传统的有机基板进行布线,因为走线长度会引入延迟、信号损耗和串扰。因此,HBM采用2.5D先进封装技术,通过硅中介层(silicon interposer)实现互连。硅中介层提供精细的金属布线层、低寄生电容以及高密度的TSV阵列,有效满足了HBM对高带宽、低延迟和高信号完整性的严苛要求。
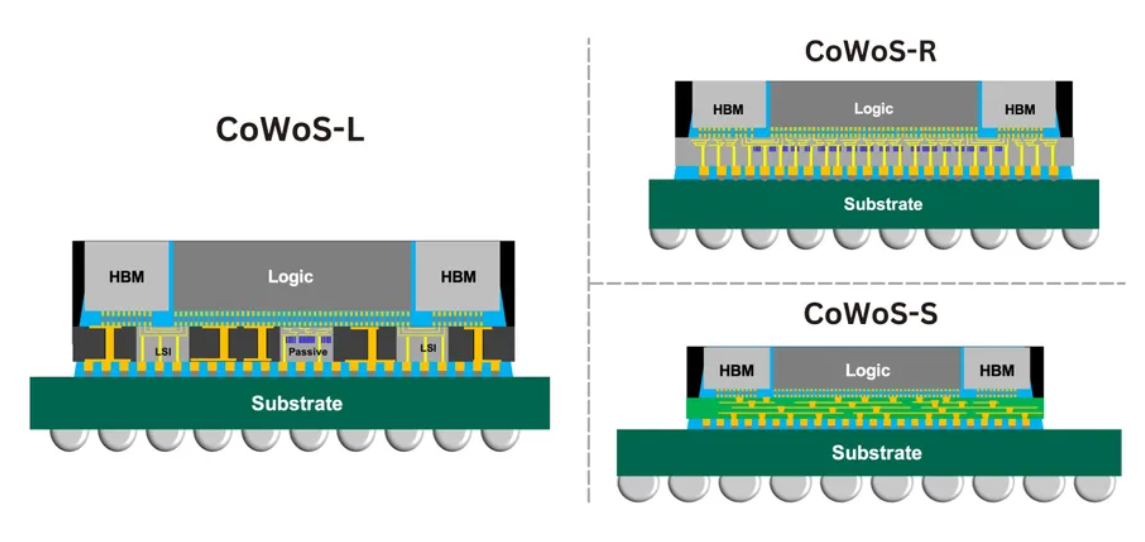
在CoWoS(Chip-on-Wafer-on-Substrate,晶圆上芯片-基板)平台上,HBM堆栈与GPU/CPU裸片被共同安装在一个无源硅中介层(passive silicon interposer)上,随后该中介层再贴装到有机基板上。这种结构显著缩短了互连距离,提升了信号完整性,并实现了计算单元与内存之间每秒数太比特(Tb/s)级别的通信带宽。
其主要变体包括:
-
CoWoS-S
:采用传统硅中介层,布线密度高,是英伟达(Nvidia)和AMD GPU的主流方案。
-
CoWoS-R
:使用带有再分布层(RDL)的有机中介层,成本更低,但I/O密度较低。
-
CoWoS-L
:基于RDL的设计,嵌入有源硅桥(active silicon bridges),适用于更大尺寸的封装。
英特尔(Intel)提供的EMIB (Embedded Multi-Die Interconnect Bridge,嵌入式多裸片互连桥)是另一种技术路径。它将小型硅桥嵌入有机基板中,通过微凸块连接相邻裸片。EMIB-T版本进一步在硅桥内部集成TSV,从而改善供电能力和信号完整性。EMIB支持大型封装(最大可达120 × 180 mm)以及小于45 µm的凸点间距,使得多芯粒(multi-tile)CPU、FPGA以及未来的HBM4集成能够在紧凑的物理空间内实现。
这些2.5D封装架构代表了逻辑芯片、存储器与互连技术的深度融合,为异构计算和高带宽加速器的发展铺平了道路。
标准演进
HBM家族已历经多代演进:
-
HBM1(2013年)
:采用8个通道,每引脚速率达1 Gb/s,单堆栈带宽约128 GB/s。仅在AMD的Fiji GPU中有有限应用。
-
HBM2(2016年)
:数据速率翻倍至2 Gb/s,单堆栈容量提升至8 GB。英伟达Tesla P100和AMD Vega GPU均采用HBM2。
-
HBM2E
:将速率提升至3.2 Gb/s,支持12--16层堆叠,单堆栈带宽高达410 GB/s,容量达32 GB。
-
HBM3
:引入16个通道及伪通道(pseudo-channels),速率提升至6.4 Gb/s,单堆栈带宽达819 GB/s;核心电压降至1.1 V,并采用解耦时钟架构和增强型ECC。英伟达H100 GPU即采用HBM3。
-
HBM3E
:速率进一步提升至约9.2--9.8 Gb/s,维持1024位接口。三星已展示运行在9.8 Gb/s下的12层堆叠、36 GB容量的HBM3E产品。
-
HBM4
:接口位宽翻倍至2048位,采用32个通道(64个伪通道),支持可变电压操作。每引脚速率可达8 Gb/s,单堆栈带宽达2 TB/s,容量最高64 GB。美光早期提供的HBM4样品已实现36 GB容量和2 TB/s带宽。
展望未来,HBM5至HBM8预计将接口位宽进一步扩展至4096位乃至16,384位,数据速率提升至8--32 GT/s。这些新一代HBM可能集成堆栈内缓存(on-stack cache)、CXL接口,甚至嵌入式NAND,从而构建混合型内存模块。
下表总结了各代HBM的关键参数:
| 代际 | 每引脚速率 (Gb/s) | 接口位宽 | 通道数 | 单堆栈带宽 | 容量 |
|---|---|---|---|---|---|
| HBM1 | 1.0 | 1,024 位 | 8 | ~128 GB/s | 4--8 GB |
| HBM2 | 2.0 | 1,024 位 | 8 | 256 GB/s | 最高16 GB |
| HBM2E | 3.2 | 1,024 位 | 8 | 410 GB/s | 最高32 GB |
| HBM3 | 6.4 | 1,024 位 | 16 | 819 GB/s | 最高36 GB |
| HBM3E | 9.8 | 1,024 位 | 16 | ~1 TB/s | 最高36 GB |
| HBM4 | 8.0 | 2,048 位 | 32 | 2 TB/s | 最高64 GB |
HBM技术的演进清晰体现了向垂直集成、大规模并行化和能效优化设计的转变,使人工智能、高性能计算和数据中心工作负载得以突破曾经限制下一代加速器发展的"内存墙"。
封装与集成
将HBM(高带宽内存)集成到现代计算系统中,需要电路设计师、热工程师和先进封装专家之间的紧密协作。与分立式的GDDR或DDR内存模块不同,HBM堆栈与GPU或CPU物理共置于同一2.5D基板上,大幅缩短了互连长度,显著提升了每瓦特性能下的内存带宽。
基于CoWoS的集成
CoWoS(Chip-on-Wafer-on-Substrate)平台目前仍是AI加速器、HPC处理器和数据中心GPU的主流集成方案。该平台将多个HBM堆栈、处理器裸片以及额外的小芯片(chiplets)------如L3缓存、I/O芯粒或片上网络(NoP)裸片------共同集成到一个无源硅中介层上。
该中介层提供超密集金属布线、基于TSV的垂直连接,以及精细间距的微凸块,用于将每个HBM堆栈连接至处理器的内存控制器。由于HBM采用1024位至2048位的超宽接口,这些中介层必须在极低串扰和寄生效应的前提下,容纳每个堆栈数千条信号线,对制造精度和材料性能提出了极高要求。
像MI300这样的大型芯片设计,集成了多个HBM3E堆栈和Zen 4 CPU芯粒,依赖于"光罩拼接"(reticle stitching)技术来制造超出标准光刻工艺尺寸限制的硅中介层------其面积可达单次光刻曝光区域(reticle size)的3.5倍。这种技术实现了前所未有的封装尺寸,支持在异构芯粒之间提供每秒数太比特(Tb/s)级别的聚合带宽。
为支撑如此高密度的供电与信号网络,电源传输网络(Power Delivery Networks, PDNs)需在中介层与封装基板层面协同设计,为HBM、逻辑电路和物理层(PHY)电路分配多个电压域。去耦电容被嵌入中介层和基板中,以抑制电压跌落(voltage droop)和噪声耦合,从而在多千兆比特每秒的数据速率下维持电源效率和信号完整性。
三星、SK海力士和美光等领先存储厂商与晶圆代工厂紧密合作,确保HBM3E及即将推出的HBM4堆栈在机械结构和电气特性上与CoWoS封装工艺要求完全匹配------尤其是在堆叠层数接近12层、带宽突破1 TB/s的情况下,这种协同尤为关键。
EMIB与混合集成
EMIB(Embedded Multi-Die Interconnect Bridge,嵌入式多裸片互连桥)为全硅中介层方案提供了一种替代路径。与覆盖整个封装区域的硅中介层不同,EMIB将小型硅桥直接嵌入有机基板内部,通过精细间距的微凸块连接相邻裸片。这种方法在保持高I/O密度和低延迟的同时,大幅降低了中介层成本。
增强型EMIB-T(支持TSV)版本在每个硅桥内引入硅通孔(TSV),以改善供电能力和回流路径的连续性,从而支持更大规模的多裸片集成。EMIB-T可容纳光罩尺寸级别的裸片,在单个有机封装上集成十余个计算或内存芯粒以及数百条I/O通道,非常适合高性能计算(HPC)、AI加速器和数据中心级CPU等应用场景。
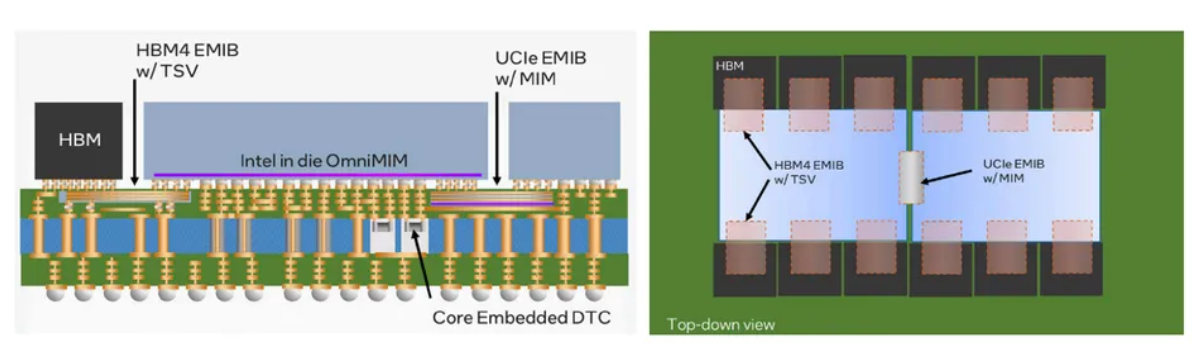
尽管EMIB无法达到CoWoS-S的完整布线密度,但其模块化设计简化了良率管理。尤其对于复杂的SoC(系统级芯片)而言,若采用全硅中介层,其尺寸和成本可能高得难以承受,而EMIB则显著降低了制造成本。预计未来的英特尔至强(Intel Xeon)处理器和FPGA产品系列将把EMIB-T与HBM4结合,用于构建下一代异构计算平台。3
在现代系统中的性能表现
高带宽内存(HBM)的变革性作用在现代AI加速器、GPU和高性能计算(HPC)架构中体现得最为明显------在这些系统中,内存带宽已成为决定性能的关键因素。以下是一些典型实例:
-
英伟达 H100 与 H200:Hopper架构将一块约814 mm²的GPU裸片与六个16 GB的HBM3堆栈集成在CoWoS-S中介层上。内存以每引脚6.4 Gb/s的速率运行,提供总计4.9 TB/s的带宽。这一超高带宽对支撑AI训练中所用的张量核心至关重要。
-
英伟达 GH200(Grace Hopper):该芯片将H100 GPU与Arm架构的Grace CPU相结合,并通过6144位接口连接六个24 GB的HBM3E堆栈。相比HBM3,HBM3E版本带宽提升超过25%。集成式CPU大幅降低了计算单元与内存之间的通信延迟。
-
AMD Instinct MI300 系列:
-
MI300A
:融合Zen 4 CPU核心与CDNA 3 GPU核心,配备128 GB HBM3内存;
-
MI300X
:采用八个GPU裸片和192 GB HBM3,实现高达5.3 TB/s的带宽。 统一的HBM内存池使CPU与GPU核心可直接共享数据,无需额外的数据拷贝操作。
-
-
美光 HBM4 样品:美光推出的36 GB、12层堆叠HBM4样品,在2048位总线上以约7.85 Gb/s的速率运行,提供2 TB/s带宽------比HBM3E高出约60%,且能效提升20%。预计2026年量产,并有望应用于英伟达代号为"Vera Rubin"的新一代GPU中。
-
FPGA 与网络设备:赛灵思(Xilinx,现属AMD)在其Virtex UltraScale+ FPGA中集成了HBM,用于网络数据包缓存和实时分析。博通(Broadcom)的Jericho3-AI网络交换芯片则采用四组HBM3堆栈,提供深度数据包缓冲能力。
然而,HBM的快速普及也带来了供应链方面的挑战。

据国外媒体路透社报道,SK海力士的HBM芯片已售罄至2025年,且市场需求预计将以每年约60%的速度增长。由于封装工艺(如CoWoS和EMIB)极为复杂,且需专用制造产线,当前产能十分有限。台积电新建的先进后端封装厂"Advanced Backend Fab 6"计划每年提供高达100万片晶圆的先进封装产能,但这一规模可能仍无法完全满足AI领域激增的需求。
设计考量
集成HBM的工程师必须应对一系列相互关联的挑战:
-
供电设计(Power Delivery):1024位或2048位的I/O接口会汲取巨大的瞬态电流。电源传输网络(PDN)设计需在宽频范围内将阻抗降至最低。中介层与封装基板通常集成高密度的电源/地平面网格以及大容量去耦电容。例如,英特尔的EMIB-T技术将金属-绝缘体-金属(MIM)电容直接嵌入硅桥中,以提升供电完整性。
-
热管理(Thermal Management):堆叠的DRAM裸片紧邻高温逻辑裸片,形成高度集中的热源。封装常采用蒸汽腔(vapor chambers)、液冷或分体式散热盖(如英特尔EMIB-T所用方案)来维持安全工作温度。设计师还需平衡不同材料间的热膨胀系数,防止封装翘曲(warpage)。
-
信号完整性(Signal Integrity):数千条并行信号线易产生噪声耦合。工程师通过匹配走线长度、采用差分信号、在中介层上集成端接电阻以及使用解耦时钟等手段,有效抑制抖动和串扰。伪通道(pseudo-channels)技术通过减小通道宽度并增加突发长度,也有助于改善信号质量。
-
TSV良率(TSV Yield):每片DRAM包含数百个硅通孔(TSV),制造缺陷可能影响整体良率。HBM通过冗余设计、ECC纠错机制和页面屏蔽(page retirement)等功能,容忍部分TSV故障,从而提升成品率。
-
控制器调优(Controller Tuning):内存控制器需跨多个通道调度访问、管理预取操作并处理刷新任务。HBM更长的突发长度要求更深的缓冲区。自适应刷新算法可降低刷新开销,提升能效。
-
供应与成本(Supply and Cost):HBM器件价格高昂,且先进封装产能受限。工程师需尽早规划量产数量,并可能需要认证多家供应商(如SK海力士、三星、美光),以确保供应链稳定。
HBM设计要求一种系统级协同优化------在功耗、散热、信号完整性与良率之间取得平衡,同时兼顾可扩展性与成本效益,以支撑下一代AI、高性能计算(HPC)和数据中心平台的发展。
新兴趋势与未来方向
下一代高带宽内存(HBM)正从单纯的存储单元演进为融合计算、定制化功能和新型互连标准的智能模块。
存内计算(PIM)革命
存内计算(Processing-in-Memory, PIM)将逻辑电路直接集成到DRAM内部,实现本地化计算。三星推出的HBM-PIM技术,在每个内存体(memory bank)中嵌入微型AI引擎,可直接卸载矩阵乘法、卷积运算和激活函数等任务,大幅减少数据搬运,提升能效与吞吐量。
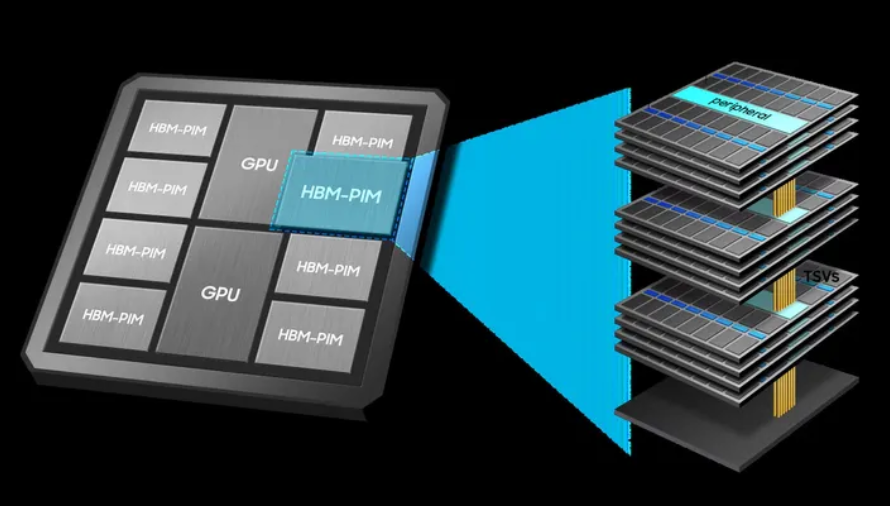
与传统加速器相比,HBM-PIM可将系统性能提升两倍以上,并降低超过70%的能耗。该方案大幅减少了CPU、GPU与内存之间的数据搬运,为面向AI训练与推理加速器的高能效存内计算架构铺平了道路。
面向 HBM4E、HBM5 及更远未来
HBM4E 在 HBM4 的基础上进一步演进,提供可定制的逻辑基底和可配置接口,以支持专用AI芯片和数据中心处理器的多样化需求。
预计于2029年推出的 HBM5 将把I/O位宽翻倍至4096位,并集成堆栈内L3缓存,同时引入CXL(Compute Express Link)和类似LPDDR的接口,以实现内存池化(memory pooling)。4 此外,HBM5可能采用直接混合键合(direct hybrid bonding)技术取代传统的微凸块(micro-bumps),从而进一步降低寄生效应并提升信号完整性。
展望更远期,HBM6 (约2032年)有望实现每引脚16 GT/s的数据速率,单堆栈带宽达8 TB/s;而HBM7/HBM8则可能将DRAM与嵌入式NAND闪存集成,构建以内存为中心的系统架构,提供高达64 TB/s的带宽------这将完美契合百亿亿次级(exascale)AI计算的需求。
混合中介层与高带宽闪存
新兴的 CoWoS-L 设计将硅桥嵌入有机中介层中,支持跨越光罩尺寸的大型封装,实现多裸片高效集成。研究人员还在探索高带宽闪存(high-bandwidth flash)技术,将HBM与NAND闪存集成在同一中介层上,使存储更靠近计算单元,从而在未来的异构系统中弥合内存与持久化存储之间的鸿沟。
与其他内存技术的对比
HBM凭借其超宽接口与3D堆叠的独特组合,在众多内存技术中脱颖而出:
-
DDR 和 LPDDR
模块具备高容量和成本效益,广泛应用于通用计算场景,如CPU、服务器和移动SoC。然而,其接口较窄(仅16--32位)且速度有限(DDR5最高约6.4 GT/s),导致内存带宽受限。
-
尽管 LPDDR5X 在能效方面有所提升,但这些传统技术仍无法满足当前AI模型、数据中心推理任务或高性能计算(HPC)工作负载对超高吞吐量的严苛要求。
相比之下,HBM通过垂直集成与极致并行化,成为突破"内存墙"、支撑下一代计算范式的关键技术。
GDDR6 和 GDDR7 将每引脚数据速率提升至 22--32 Gb/s,为消费级 GPU 和游戏系统带来显著性能提升。然而,它们仍依赖 32 位总线,需使用多个芯片并配合复杂的 PCB 布线才能实现数百 GB/s 级别的带宽。这种扩展方式会增加板级功耗、信号损耗和设计复杂度,因此 GDDR 主要适用于对尺寸和散热限制相对宽松的显卡与工作站。
在封装内缓存内存(On-Package Cache Memory)方面,AMD 的 3D V-Cache 或英特尔的片上 SRAM 等技术可提供超低延迟访问,非常适合将热点数据缓存在计算单元附近。但其容量通常仅限于几十 MB,因此更多是作为 HBM 的补充,而非替代方案。
HBM 正好位于 GDDR 与片上缓存之间,提供一种中等延迟、高带宽的解决方案。在 HBM3E 和 HBM4 中,单堆栈容量可达 36 至 64 GB。凭借 1024 至 2048 位的超宽接口和较低的工作频率,HBM 能以极高的能效实现 TB/s 级吞吐量。通过将 DRAM 芯片垂直堆叠,并借助硅中介层紧邻 GPU 或 CPU 放置,HBM 极大缩短了信号走线长度,降低了每比特传输的功耗,并简化了主板布线。
其代价在于制造成本和集成复杂度较高。但对于 AI 加速器、高性能计算(HPC)系统和数据中心处理器而言,HBM 在每瓦性能方面的优势使其不可或缺。
应用场景与用例
HBM 凭借高带宽和较低的每比特能耗,在多个领域展现出巨大价值:
-
人工智能(AI)与机器学习:深度神经网络涉及大量矩阵乘法和卷积运算。HBM 的并行通道可高效喂给张量核心和 SIMD 单元,减少内存停顿。训练如 GPT-4 这类大型语言模型(LLM)每秒需处理数 TB 数据,HBM 在此场景中至关重要。
-
高性能计算(HPC):计算流体动力学、气象建模和分子动力学等应用执行密集型向量运算。HBM 通过提供贴近计算单元的高带宽,助力 GPU 集群实现强扩展性(strong scaling)。
-
数据中心加速器:例如 AMD MI300A 将 CPU 与 GPU 内存统一于单一封装内,简化编程模型并提升效率。HBM 也广泛用于 AI 推理加速器和定制 ASIC。
-
网络与 FPGA:博通的 Jericho3-AI 交换芯片采用 HBM 堆栈作为深度数据包缓冲区,提供确定性延迟和高吞吐能力。FPGA 则利用 HBM 加速数据分析与包处理任务。
-
嵌入式与边缘计算:随着封装成本下降,HBM 正逐步进入工业 AI 和自动驾驶系统,以适中的功耗提供确定性的高带宽。未来的 CoWoS-L 和 EMIB-T 封装将进一步缩小尺寸,支持更紧凑的形态。
通过融合高带宽、可扩展容量与先进封装技术,HBM 正在重塑 AI、HPC、网络和嵌入式计算领域的性能边界,弥合下一代系统中处理器速度与内存访问能力之间的鸿沟。
工程师设计建议
成功实现 HBM(高带宽内存)需要系统架构师、封装工程师与晶圆代工厂紧密协作。以下最佳实践有助于在 AI、HPC 和数据中心设计中优化性能、可靠性和可制造性:
-
尽早与封装及制造伙伴合作:根据带宽、面积、成本和供应限制,在 CoWoS 各变体或 EMIB 之间做出选择。封装方案将直接影响布局规划、电源分配和热设计。
-
均衡各通道流量:采用能均匀分布事务到各通道和伪通道的内存控制器。将数据结构对齐通道边界,避免局部过载(hotspots)。
-
建模功耗与热行为:使用协同仿真工具评估 PDN 阻抗和散热性能。为未来更高功耗密度的标准(如 HBM3E/HBM4)预留设计余量。
-
充分利用可靠性特性:启用 ECC、页面屏蔽(page retirement)和自适应刷新机制。监控错误统计信息,及时发现器件老化或热斑问题。
-
提前规划供应链约束:HBM 与 CoWoS 产能有限,应尽早锁定配额,并考虑引入第二供应商(如三星、美光)以降低风险。
通过在早期阶段协调架构、封装与供应链策略,工程师可充分发挥 HBM 的优势,在下一代 AI 与 HPC 平台上实现高带宽、低功耗与高可靠性。
结论
HBM 已从一项小众创新演变为 AI、高性能计算和数据中心加速器的基石技术。通过结合 3D 堆叠 DRAM、硅通孔(TSV)以及 CoWoS、EMIB 等先进封装工艺,HBM 实现了 TB/s 级带宽与卓越的能效表现。尽管在热管理、供电设计和制造良率方面仍面临挑战,但 HBM3E、HBM4 以及存内计算(PIM)等技术的持续进步正不断拓展其可扩展性。未来采用混合中介层和集成计算的设计将进一步突破数据传输与并行处理的极限。深入理解 HBM 的原理、实现方式与权衡取舍的工程师,将更有能力引领下一代高带宽系统的设计。
常见问题解答(FAQ)
-
HBM 如何支持生成式 AI 工作负载?
A:HBM 提供极高带宽和低延迟,使生成式 AI 模型能快速访问海量数据集。其超宽内存接口有效缓解了多节点训练与推理过程中的瓶颈。
-
为何高带宽对 AI 和 HPC 系统至关重要?
A:高带宽可加快 CPU、GPU 与内存之间的数据传输速率,确保高端加速器在运行 AI 训练、科学模拟和高级机器学习任务时保持持续高吞吐。
-
HBM 相比 DDR 或 GDDR 如何提升内存容量?
A:堆叠式 DRAM 架构大幅提升了单位封装内的内存容量,可在紧凑空间内构建 TB 级内存系统,满足 AI、HPC 和数据中心对大内存池的需求。
-
HBM 的内存接口架构有何特点?
A:HBM 采用 1024 位或 2048 位内存接口,支持多 Gbps 速率下的宽并行访问。该设计无需极端高频即可实现高吞吐,同时降低功耗并简化布线复杂度。
-
HBM 的数据传输速率与传统 DDR 内存相比如何?
A:HBM 每引脚速率可达 6.4--9.8 Gbps,远超 DDR5 的 6.4 GT/s。其 3D 堆叠结构与超宽接口使其在能效和传输速率上均显著优于传统内存。
-
在高性能计算中,哪些内存技术与 HBM 竞争?
A:竞争技术包括 GDDR6、DDR5 和新兴的 LPDDR5X。虽然 GDDR 具备成本优势,但只有 HBM 能为高端 AI 加速器提供更高的带宽、更大的容量以及更优的能效扩展能力。