1 问题现象
简单记录下之前的一则故障,值班期间有应用反馈说某个业务的中间实体临时表无法读写和删除,严重影响业务正常办理。
2 问题分析
2.1 环境说明
这个业务系统所在的库,是一套8节点的Oracle 19C版本集群环境,承载此业务的PDB主要跑在4节点上,其他节点承载另外的业务pdb。
2.2 查看会话数
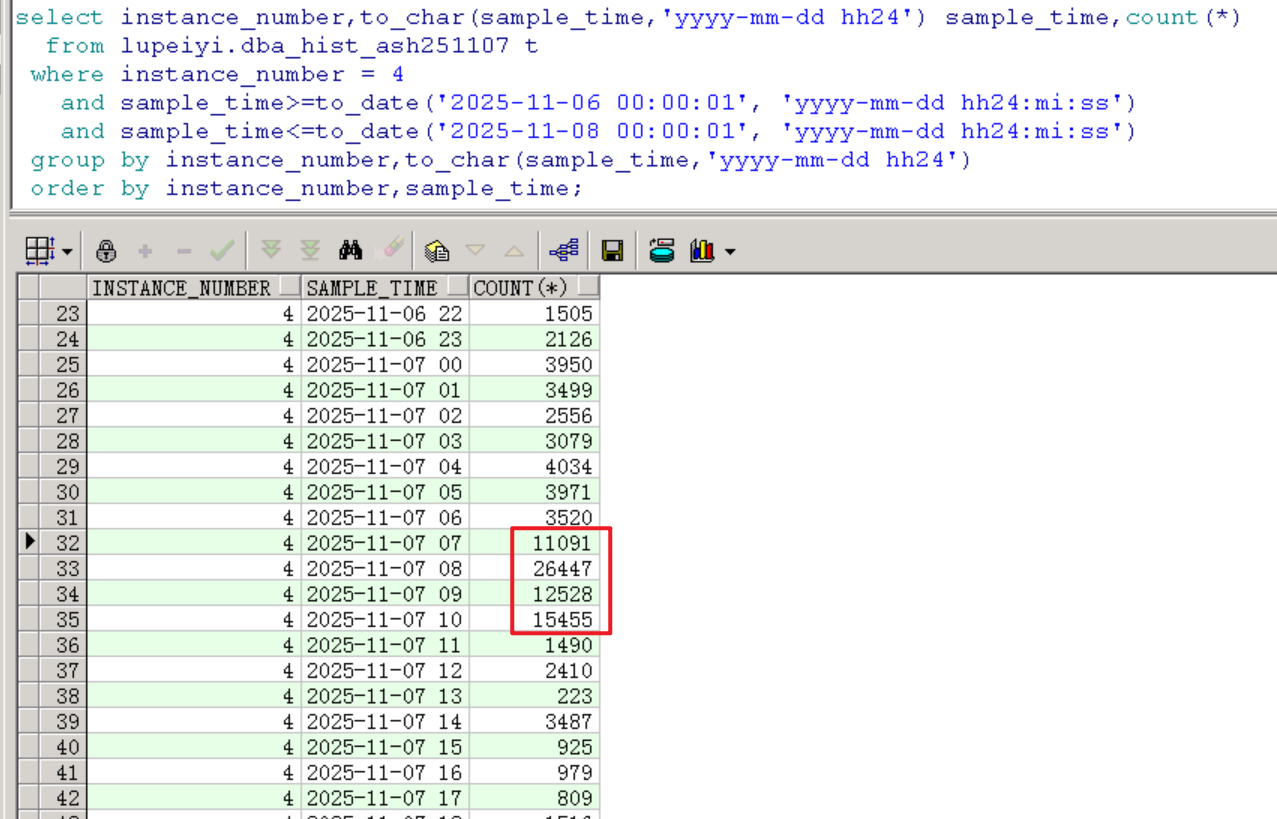
按小时去查看活跃会话数。
下图可以看到活跃会话堆积情况,在7号的7点、8点、9点、10点这四个小时里活跃会话有积压现象,并在8点的时候达到一个峰值26447个,是正常水平情况下峰值的7~8倍。
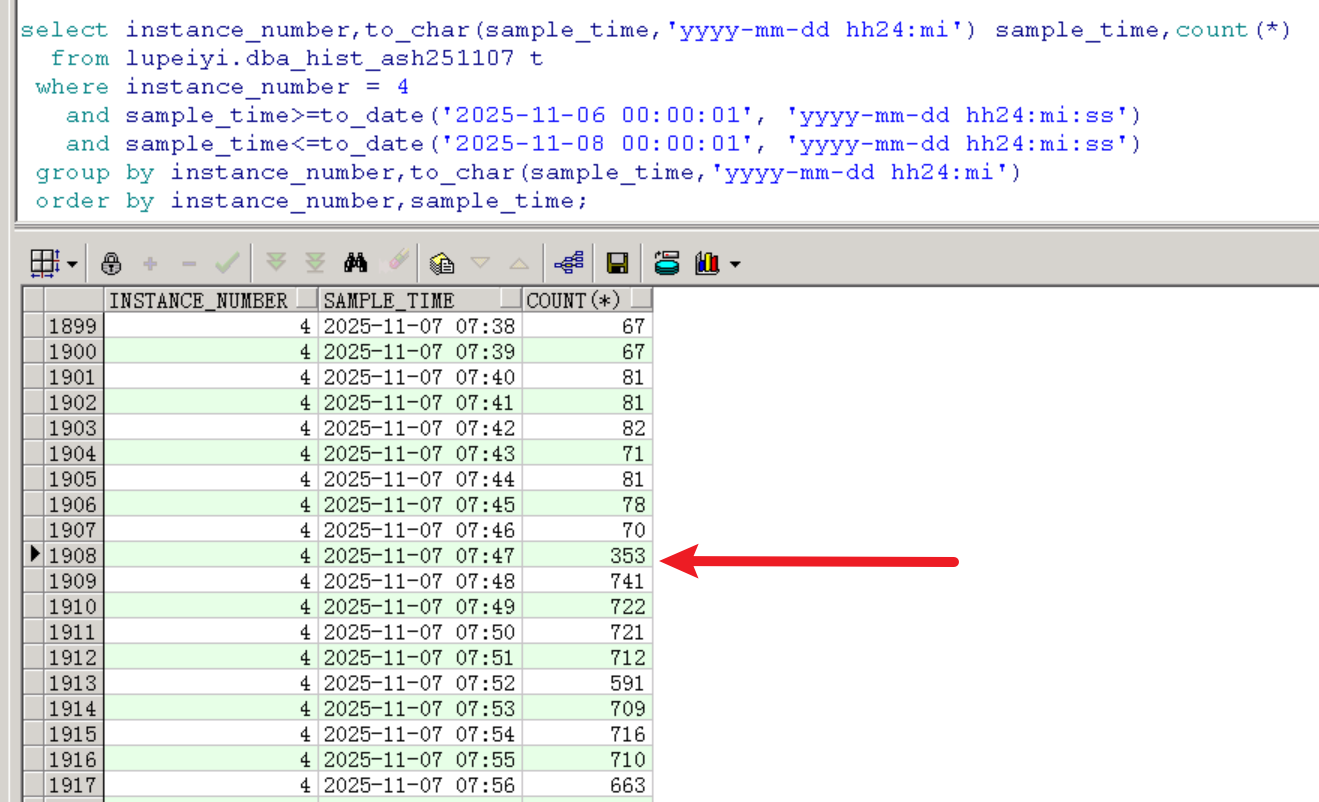
按分钟查看,会话堆积从7点47分开始,从每分钟70个突增到几百个:
2.3 查看TOP EVENT
如下, Commit类的log file sync等待事件出现大量堆积,存在大量insert会话堆积。Concurrency并发类型library cache lock等待事件也出现了大量堆积,平均延迟在9点和10点业务高峰期间达到1854ms。
reliable message等待事件是跨实例消息传递相关,有点类似消息队列,MOS解释如下:
- When a process sends a message using the 'KSR' intra-instance broadcast service, the message publisher waits onthis wait-event until all subscribers have consumed the 'reliable message' just sent. The publisher waits on this wait-event for up to one second and then re-tests if all subscribers have consumed the message, or until posted. If themessage is not fully consumed the wait recurs, repeating until either the message is consumed or until the waiter isinterrupted.
buffer busy waits、enq: FB - contention、enq: HW - contention这些等待事件可以忽略(并发insert产生的写写争用及维护索引争用)。
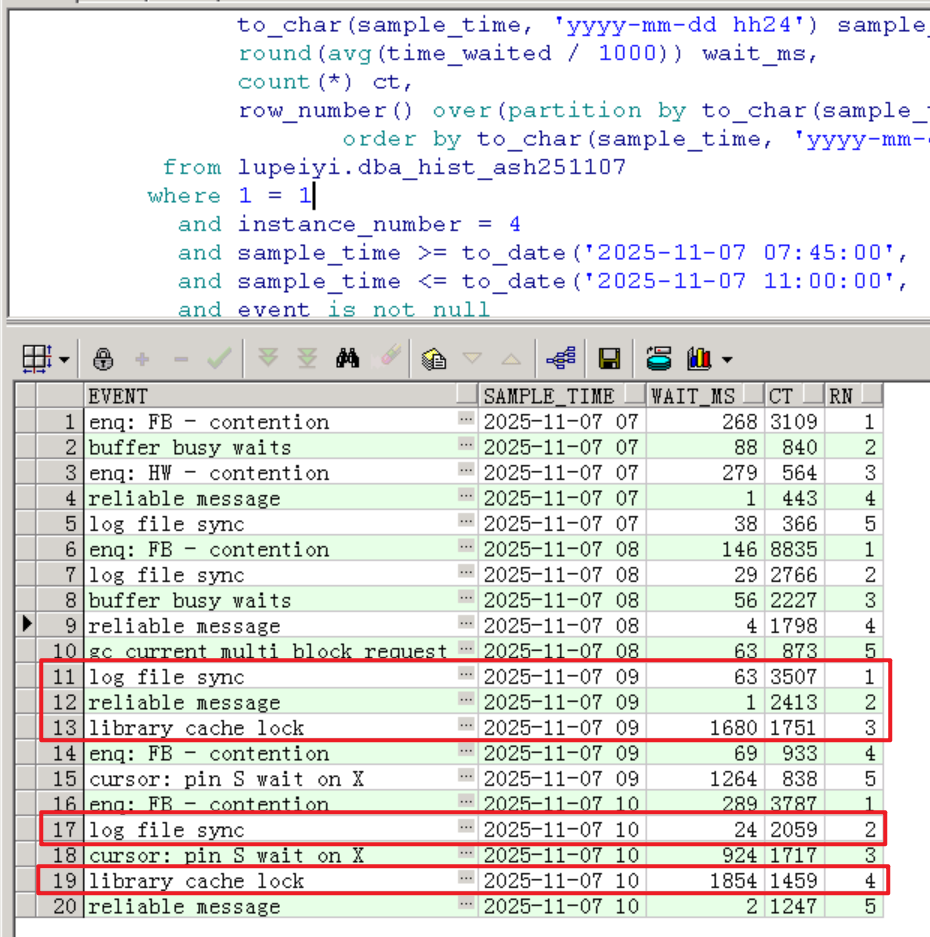
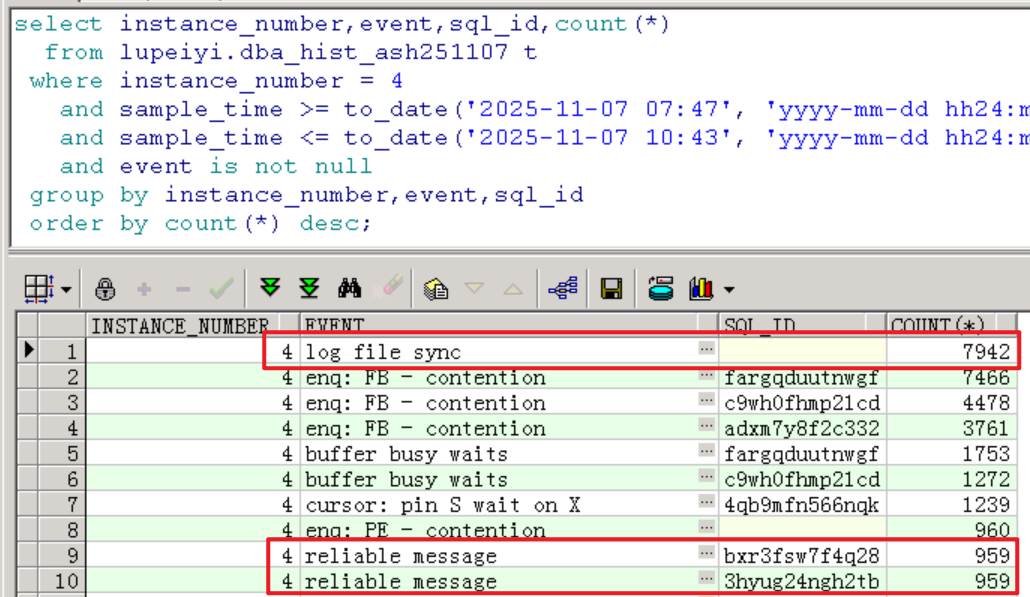
总的Top 10 Event主要是Commit类的log file sync,以及reliable message:
2.4 查看TOP SQL
根据上面查到的TOP等待事件情况,已知log file sync是由于大量写操作引起的,下面主要看library cache lock和reliable message相关的TOP SQL。
可以看到,truncate/drop table有卡住的情况,明显是不正常的。
更为严重的是,有几个library cahce lock等待事件相关的查询语句的平均延迟达到了1685ms、6023ms、7931ms和10104ms,这是非常严重的性能问题。
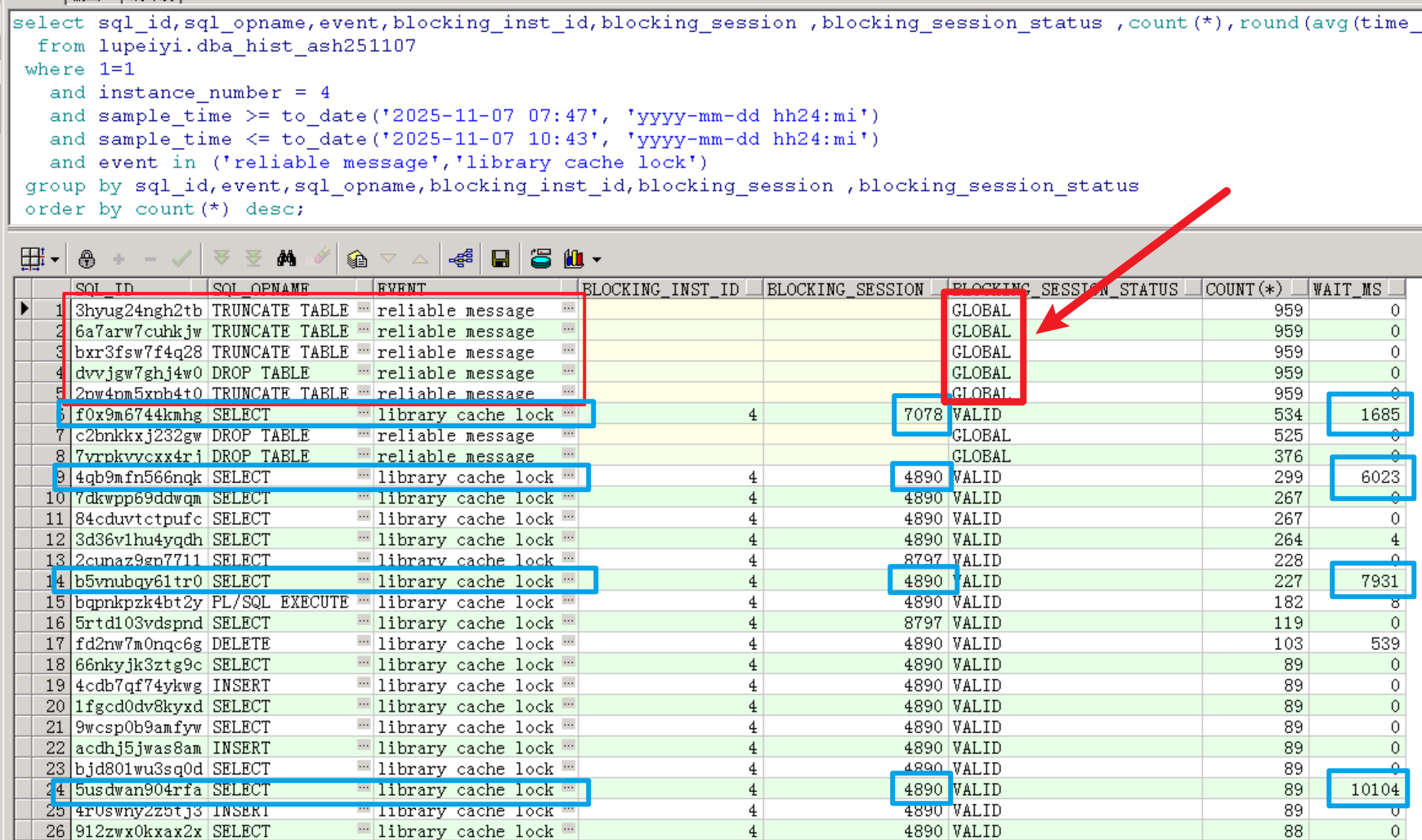
业务反馈接口超时报错的语句正是这些library cahce lock等待事件阻塞而严重延迟的查询语句,因此为了尽快恢复业务,需要优先解决这部分的阻塞。
代入相关sql_id,查看阻塞链条,从阻塞链条来看,阻塞源都是reliable message等待事件。
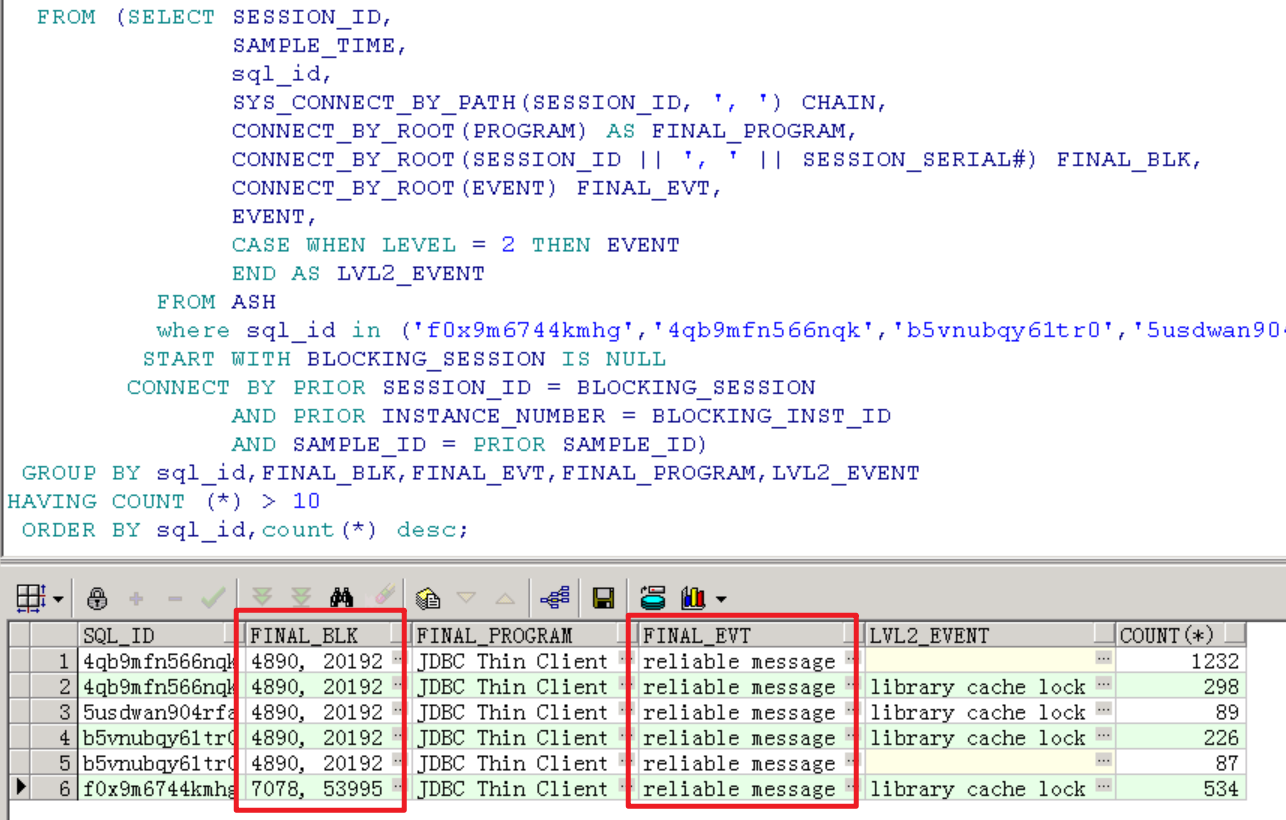
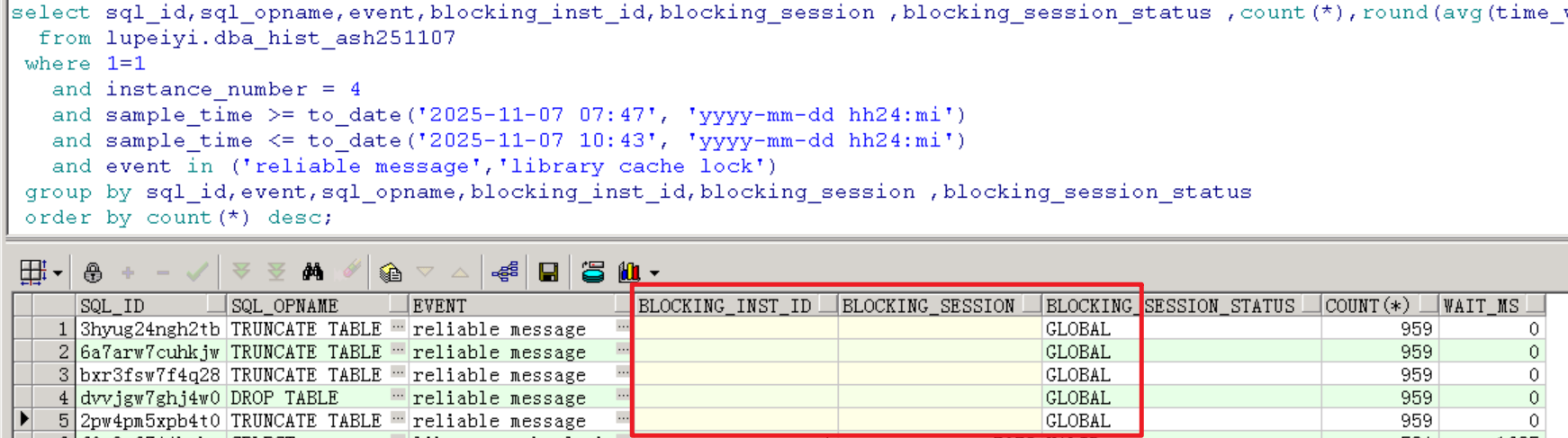
而reliable message等待事件堆积是因为全局性的阻塞,可以看到blk_sess_stat为global,不知道是否因为阻塞源是非活跃会话的缘故,hist_ash这里已经看不到blk_sess和blk_inst了。
而在故障当天,从gv$session中可以看到阻塞源是节点8的gen0进程,而节点8的gen0进程又在等待resource manager。

GEN0 (Generic Background Process)进程是oracle 10g 引入的通用后台进程,用于处理数据库实例中的各种系统任务和管理操作,这个进程也是不可以随便杀的,杀掉会导致实例crash。gen0进程阻塞ddl操作应该是因为ddl会涉及对数据字典基表(如seg, obj, tab, uet等)的修改,这些修改需要获取数据字典对象上的锁(TM锁)。在RAC环境中,为了确保所有节点对数据字典有一致的视图,对这些核心数据字典基表的修改需要进行全局协调,这个协调工作可能有GEN0进程参与。
3 处理过程
根据上面分析过程查到的阻塞链条来说,如果我们将resource manager关闭了,节点4堆积的会话应该就会得到释放。

去节点8上执行调整如下参数,作用是关闭resmgr:
sql
alter system set resource_manager_plan='force:';但是操作HANG住了,应该是在禁用资源管理器时,Oracle 需要清理资源管理器的内部结构、统计信息,并通知所有相关进程(包括 gen0)资源管理策略已改变,这个过程本身需要资源管理器参与执行,这时就和gen0进程相互阻塞了,导致hang住。
节点8上没有承载业务,反馈客户得到允许去强制关闭节点8去释放gen0进程,数据库重新拉起后再关闭resmgr:
sql
shutdown abort;
alter system set resource_manager_plan='force:';强宕节点8后,节点4的堆积会话得到了释放:
4 总结
本案例是一个典型的 Oracle RAC 集群中因 Resource Manager 配置不当引发全局性阻塞 的性能故障。故障表现为业务接口超时,根本原因是节点8的 gen0 后台进程因 Resource Manager 资源争用被阻塞,进而引发跨节点的 reliable message 等待事件堆积,最终导致业务节点(节点4)出现大量 library cache lock 和 log file sync 等待,会话数飙升至正常值的7~8倍。
处理过程通过定位阻塞链条,最终采取强制关闭节点8并禁用 Resource Manager 的方式释放阻塞,使会话数在几分钟内恢复正常。该方法虽有效,但属于紧急恢复手段,存在业务中断风险。