最近有项目用到了字符和数字识别,调研后,先拿tesseract -ogr试试,效果还不错
基于 tesseract 实现英文字符和数字识别
tesseract 主要依赖于leptonica 和 tiff 库
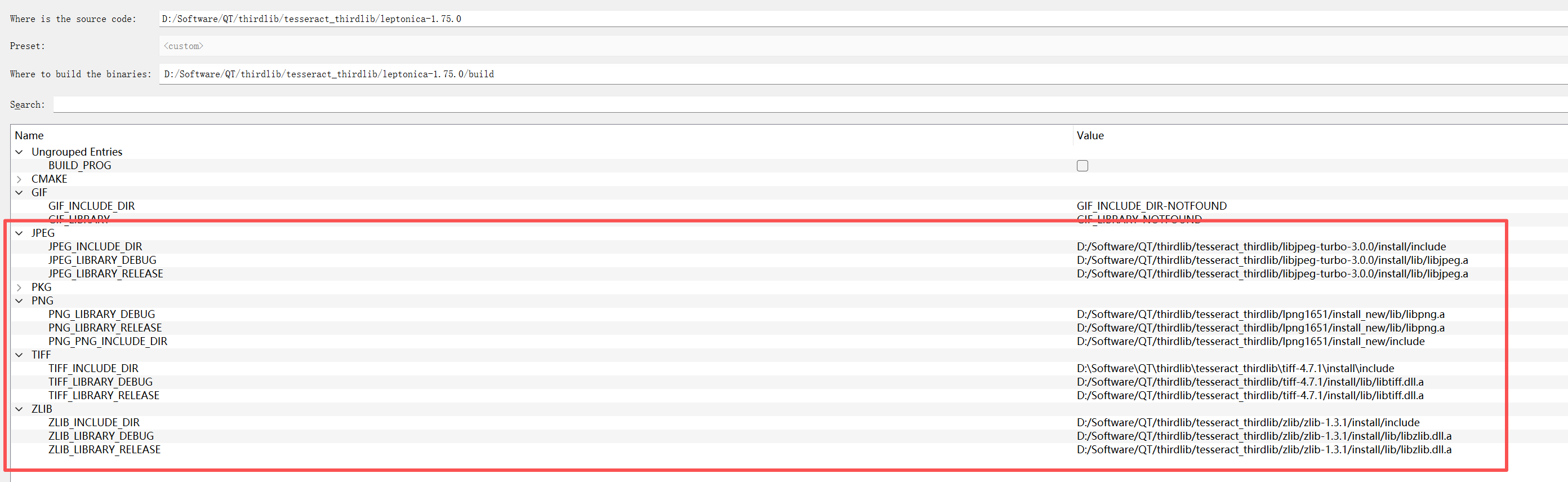
leptonica 依赖于 zlib tiff png jpeg
先列一下我用到的库和版本号
1.jpg库没有cmake.txt,没法直接用cmake编译,我们直接用libjpeg-turbo库,可以用
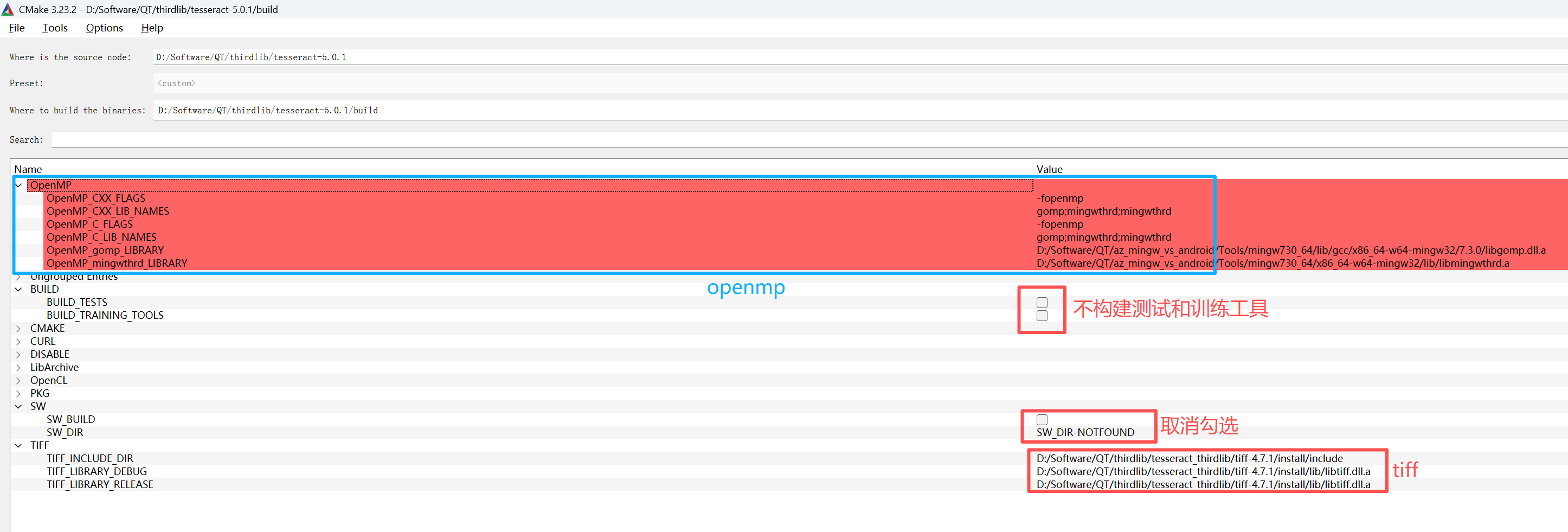
2.tesseract 版本没用特别高,我的mingw版本还没法完全适应C++17,编译不过去,所以降了版本
3.leptonica 版本要升,我最开始用的版本比我下面的低,有些头文件没有
4.png库也要高,低点试了下不行,我试了三个版本
综上,如果你的mingw版本和我一样(mingw730_64),可以直接用下面的版本,我试过了可以

编译过程
1.tesseract 如下设置

2.leptonica 如下设置,其他库自己编吧 很简单 下载后,直接构建就行,一遍过
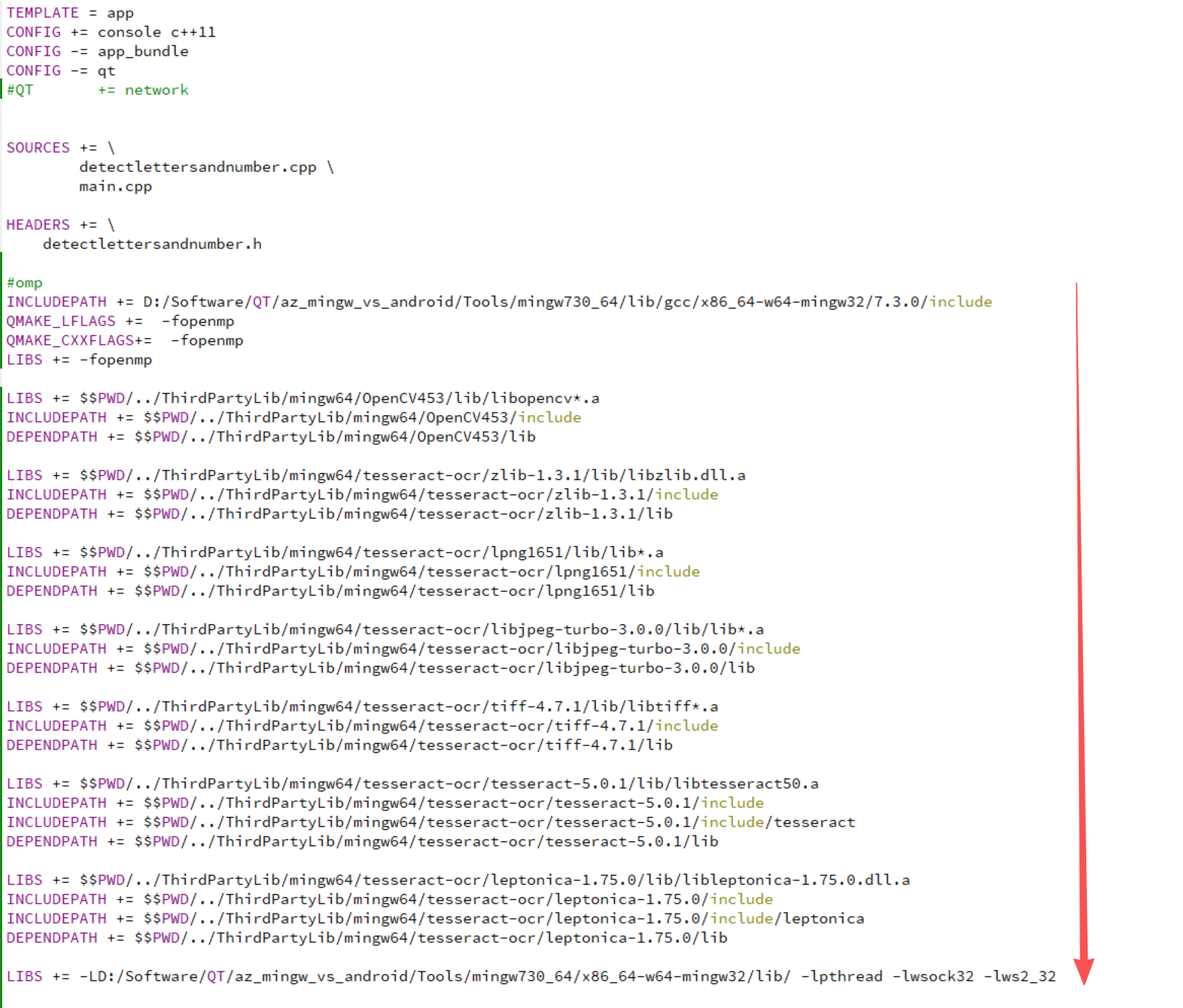
工程构建
QT 的.pro文件,这个动态库填写有先后顺序,烦死了,试了好多次,按我这样往下顺,要不然几百个报错
下面是我试出来的,能正常用
C++接口调用
1.设置识别语言和语言文件存放路径
2.读取图像,我使用opencv 或者用QT 的QImage,转换成unsigned char*即可
3.选择是否划定识别区域,图像太大可能识别效率也上不来,而且误识别区域过多
cpp
#include "opencv2/opencv.hpp"
#include "baseapi.h"
using namespace tesseract;
int main()
{
char* outText;
tesseract::TessBaseAPI* api = new tesseract::TessBaseAPI();
if (api->Init("E:/Software/tesseract/AZ/tessdata", "eng"))
{
fprintf(stderr, "Could not initialize tesseract.\n");
exit(1);
}
// cv::Mat image = cv::imread("C:/Users/lixia/Desktop/789897897897.png");
cv::Mat image = cv::imread("C:/Users/lixia/Desktop/11111111.png");
// 3. 设置图像参数
int width = image.cols;
int height = image.rows;
int channels = image.channels();
int bytes_per_pixel = channels;
int bytes_per_line = static_cast<int>(image.cols * bytes_per_pixel);
// bytes_per_pixel:每个像素占用的字节数
// 对于8位图像(0-255),通常等于通道数
// 例如:灰度图(1通道)= 1,RGB彩图(3通道)= 3,RGBA(4通道)= 4
// bytes_per_line:每行图像数据占用的字节数(步长)
// 通常 = 宽度 × 每像素字节数 + 可能的填充字节
// 在OpenCV中,image.step就是每行的字节数
//传入影像
api->SetImage(image.data,width,height,bytes_per_pixel,bytes_per_line);
//划定范围
// api->SetRectangle(692,670,1100,150);
// Get OCR result
outText = api->GetUTF8Text();
printf("OCR output:\n%s", outText);
// Destroy used object and release memory
api->End();
delete api;
delete[] outText;
return 0;
}处理效果
分析:
1.字体和背景色要有足够的颜色区分
2.实际使用过程中,还是要使用YOLO识别字符区域,或者使用传统的图像处理算法,先大致预识别 一个识别位置,要不然场景很复杂
3.还有待测试的是,不同颜色组合的字体和背景,是否还需要传统方法进行二值化处理后再传入识别函数
4.还需要有一个角度矫正 的策略在预处理上,我测试了文字旋转超过20度感觉识别就很不稳定了

识别结果


识别结果
