TL;DR
- 2025 年 NVIDIA 提出的 Nemotron-Flash,在当前小模型中大幅提升了精度--效率前沿。例如,相比 Qwen3-1.7B/0.6B,Nemotron-Flash 分别实现了超过 5.5% 的平均精度提升、1.3×/1.9× 的更低时延,以及 18.7×/45.6× 的更高吞吐量。
Paper name
Nemotron-Flash: Towards Latency-Optimal Hybrid Small Language Models
Paper Reading Note
Paper URL:
Introduction
背景
- 高效部署小型语言模型(Small Language Models, SLMs)对于许多具有严格时延约束的实际应用场景至关重要。以往关于 SLM 设计的研究主要集中在减少参数量,以获得"参数最优"的 SLM,但参数效率并不必然转化为真实设备上的等比例加速。本研究旨在识别决定 SLM 在真实设备上推理时延的关键因素,并在"真实设备时延"为首要考量时,为 SLM 的设计和训练提供具有普适性的原则与方法。
本文方案
- 架构优化:
- 识别出两个核心架构因素:深度--宽度比 ,以及算子(operator)的选择。前者对小 batch size 下的时延至关重要,而后者同时影响时延和大 batch size 下的吞吐量。基于此,我们首先研究了"时延最优"的深度--宽度比,关键发现是:尽管在相同参数预算下,更"深-窄"的模型通常能获得更好的精度,但它们未必位于精度--时延折中曲线的前沿。接着,我们探索了新兴的高效注意力替代方案,以评估其作为候选构建算子的潜力。利用这些表现优异的算子,我们构建了一套进化搜索框架,能够在混合式 SLM 中自动发现由这些算子组成的、具有时延最优特性的组合,从而推动精度--时延前沿进一步演进。
- 训练优化
- 通过一种权重归一化技术增强了 SLM 的训练,该技术能够实现更有效的权重更新并改善最终的收敛效果,同时可以作为未来 SLM 的通用组件
- 通过约束权重范数来提升 SLM 的训练效果,以提高"有效学习率"
- 采用了可学习的 meta tokens 来进行缓存初始化:Hymba: A Hybrid-head Architecture for Small Language Models
- 综合上述方法,我们提出了一个新的混合式 SLM 家族------Nemotron-Flash,在当前小模型中大幅提升了精度--效率前沿。例如,相比 Qwen3-1.7B/0.6B,Nemotron-Flash 分别实现了超过 5.5% 的平均精度提升、1.3×/1.9× 的更低时延,以及 18.7×/45.6× 的更高吞吐量。

Methods
面向时延最优的 SLM 设计与训练
SLM 设计:深度--宽度比
- 先前的 SLM 工作 1, 11 发现,在相同参数预算下,"深-窄"(deep-thin)模型通常能比"浅-宽"(wide-shallow)模型取得更好的任务精度。然而,当目标变为真实设备上的时延时,这一结论可能不再成立。我们关心的核心问题是:在优化精度--时延权衡时,更深的模型还是更宽的模型更有优势? 为回答这一问题,我们进行了系统性的探索,以理解深度和宽度对精度--时延权衡的影响。
- 探索设置。 我们基于 Llama 训练了一系列模型,采用五种不同的深度设置:6、12、18、24 和 30 个 block,每个 block 均包含一个注意力层和一个前馈网络(FFN)。这些模型在 Smollm-corpus 12 的 100B tokens 上进行训练。对于每一种深度设置,我们进一步改变模型宽度(即 hidden size),以构造不同规模和时延的模型。我们在图 2(a) 和图 2(b) 中分别可视化了由此得到的"精度--参数量"和"精度--时延"权衡曲线。精度通过 8 个常识推理(CR)任务的平均结果来衡量;时延则是在 NVIDIA A100 GPU 上,以 batch size 为 1 进行 1k token 生成的解码时间。

- 观察与分析。 我们有如下观察:
❶ 在较宽的深度范围内,更深的模型通常在"精度--参数量"权衡上表现更好,但这一收益会逐渐趋于饱和;
❷ 在"精度--时延"权衡上,"深-薄"模型的优势可能不再成立,对于给定的时延预算,存在一个最优的深度设置。例如,当时延预算为 3 秒时,在所有被评估的配置中,深度为 12 的模型获得了最高精度;
❸ 最优的深度--宽度比通常会随着时延预算的增加而增大。
这些观察强调:在实际部署约束下需要有意识地选择深度和宽度,而不能简单地默认采用深-窄模型。
用增强版缩放定律确定"甜点"深度--宽度比
尽管上述分析所揭示的总体趋势是稳定的,但具体曲线会随着不同设备和生成长度而发生偏移,这会使"如何选择模型的深度和宽度"变得更加复杂。因此,除了这些经验性结论之外,我们还探索了一种更具原则性的方法,用于在同一模型家族内部确定"甜点"深度--宽度比。为此,我们在已有缩放定律 13, 9 的基础上进行了扩展,使得模型损失显式地参数化为深度与宽度的函数。
具体来说,现有的语言模型缩放定律 13, 9 将语言建模损失表示为
L ( P , N ) = L 0 + C 1 ⋅ P − α + C 2 ⋅ N − γ , L(P, N) = L_0 + C_1 \cdot P^{-\alpha} + C_2 \cdot N^{-\gamma}, L(P,N)=L0+C1⋅P−α+C2⋅N−γ,
其中 P P P 和 N N N 分别是模型大小和数据量, C 1 , C 2 , α , γ C_1, C_2, \alpha, \gamma C1,C2,α,γ 为拟合参数。我们将模型大小 P P P 拆解为模型深度 D D D 和宽度 W W W 两个因素,并将缩放定律重写为:
L ( D , W , N ) = L 0 + a D − α + b W − β + c N − γ (1) L(D, W, N) = L_0 + a D^{-\alpha} + b W^{-\beta} + c N^{-\gamma} \tag{1} L(D,W,N)=L0+aD−α+bW−β+cN−γ(1)
其中拟合参数 a , b , c a, b, c a,b,c 控制每个维度的贡献,而指数 α , β , γ \alpha, \beta, \gamma α,β,γ 则刻画了在各个维度上"收益递减"的程度。
由于数据量的影响是可加且与深度和宽度解耦的,我们可以在固定数据量的前提下,单独研究深度和宽度对语言模型损失的影响,即忽略数据量相关项。在实际应用中,给定一个目标时延预算和部署环境,我们可以对一系列不同的深度--宽度配置进行性能剖析,然后在满足时延约束的前提下,选择在该缩放定律预测下损失最小的那一组深度--宽度比,即"甜点"配置。
以困惑度(PPL)为损失指标。
图 3: 缩放定律的拟合以及在更大深度/宽度设置上的验证。
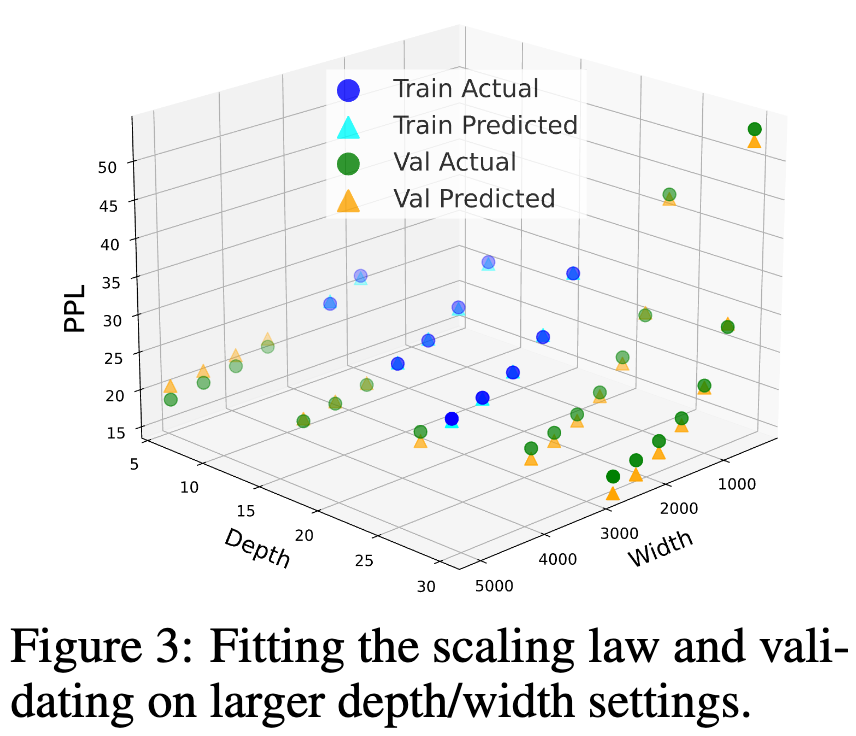
拟合与外推。 为验证这一增强版缩放定律的有效性,我们在前述具有不同深度 (D) 和宽度 (W) 的 Llama 模型上进行了拟合实验。具体做法是:使用困惑度(PPL)作为损失指标,在一部分深度/宽度配置上拟合该缩放定律,并在更大宽度/深度的模型上进行验证,以评估其外推能力。如图 3 所示,我们发现该模型在未见过的深度/宽度设置上具有相当不错的外推表现,其预测的 PPL 与真实值的误差控制在 5.3% 以内,说明所拟合的函数可以在观察到的训练配置之外进行合理泛化。
经验总结:SLM 的深度--宽度比。
深-窄模型未必在时延上是最优的;在给定目标时延预算的情况下,最优的深度--宽度比通常会随时延预算的增加而增大。通过将深度和宽度纳入缩放定律进行拟合,可以为寻找"甜点"深度--宽度比提供一种更加原则化的方法。
SLM 设计:混合算子(Hybrid Operators)
除了模型的深度和宽度之外,每一层中所使用的算子(operator)也是一个至关重要的维度。我们首先在严格可控的设置下训练一系列已有的语言模型架构,以识别在"精度--时延"前沿上最有潜力的算子;随后,我们构建了一条进化搜索(evolutionary search)管线,用于自动且高效地发现这些算子的混合组合,从而构建混合式 SLM。
探索设置。 我们训练了一系列 5 亿参数规模的语言模型,这些模型基于新兴的高效注意力替代机制构建,包括 Mamba 14、Mamba2 15、GLA 16、DeltaNet 17、Gated DeltaNet 18、RWKV7 19,以及窗口大小为 512 的滑动窗口注意力(sliding window attention, SWA)。
- 对于 Mamba/Mamba2,我们使用其官方实现;
- 对于 SWA,我们采用 FlashAttention 20;
- 对于其他所有线性注意力变体,则采用 FlashLinearAttention 21。
所有模型均遵循各自原论文中给出的设计(例如,每个注意力算子之后接一个 FFN,Mamba/Mamba2 除外),使用相同数量的 block,并在 Smollm-corpus 上的 100B tokens 上进行训练。我们在图 4(a) 中展示验证集损失,在图 4(b) 中展示 Wikitext 上的 PPL--时延权衡;时延通过在 NVIDIA A100 GPU 上、启用 CUDA Graph、batch size 为 1、解码 8k tokens 的时间来衡量。
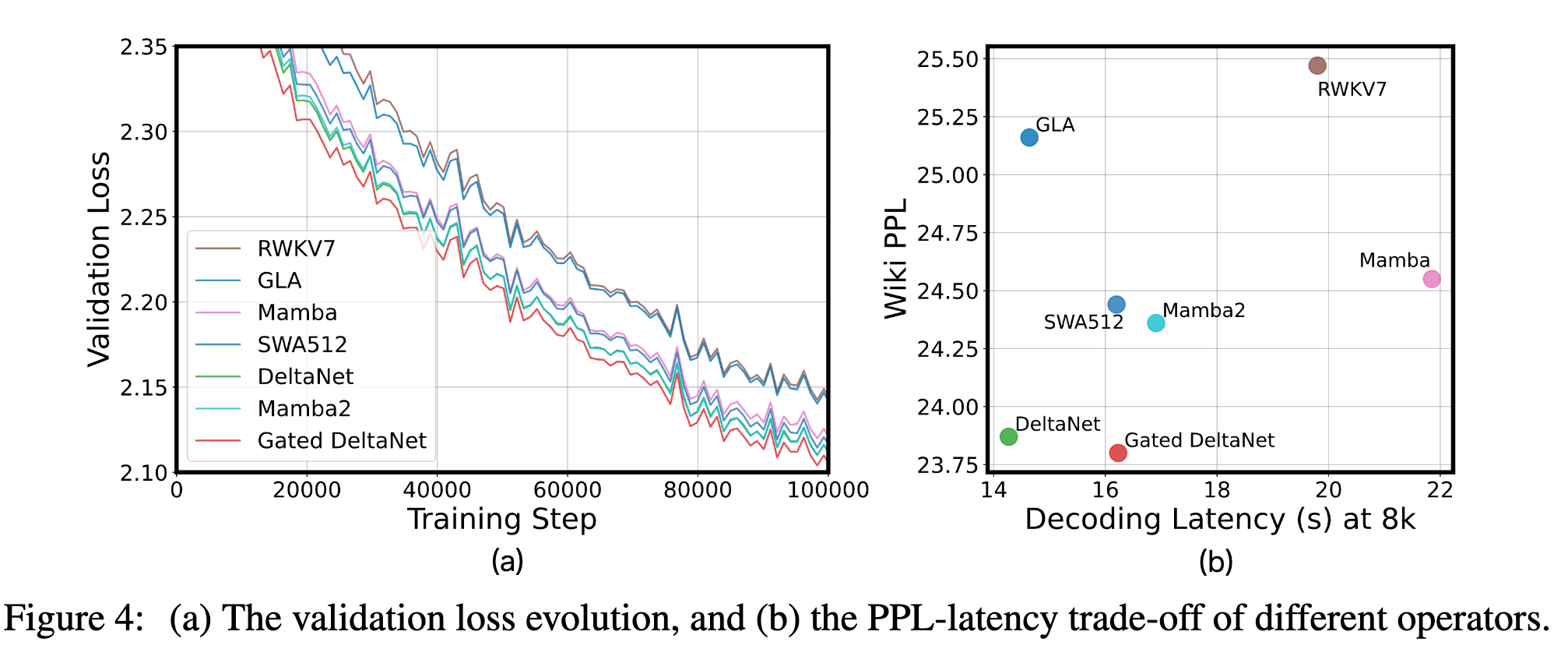
此外,受到近期混合语言模型工作的启发 6, 22, 5, 23, 7------这类工作在同一模型中结合了注意力与 Mamba/Mamba2------我们也将图 4 中表现突出的算子与 Mamba2 或 SWA 按层交替(layer-wise interleaved)的方式进行融合,从而构建混合模型,以观察哪些算子组合更匹配、更具互补性;相关结果见表 1。需要注意的是,为了公平对比,我们在混合模型中控制 block 总数与纯算子模型相同,这一点是基于第 2.1 节中的分析得到的。
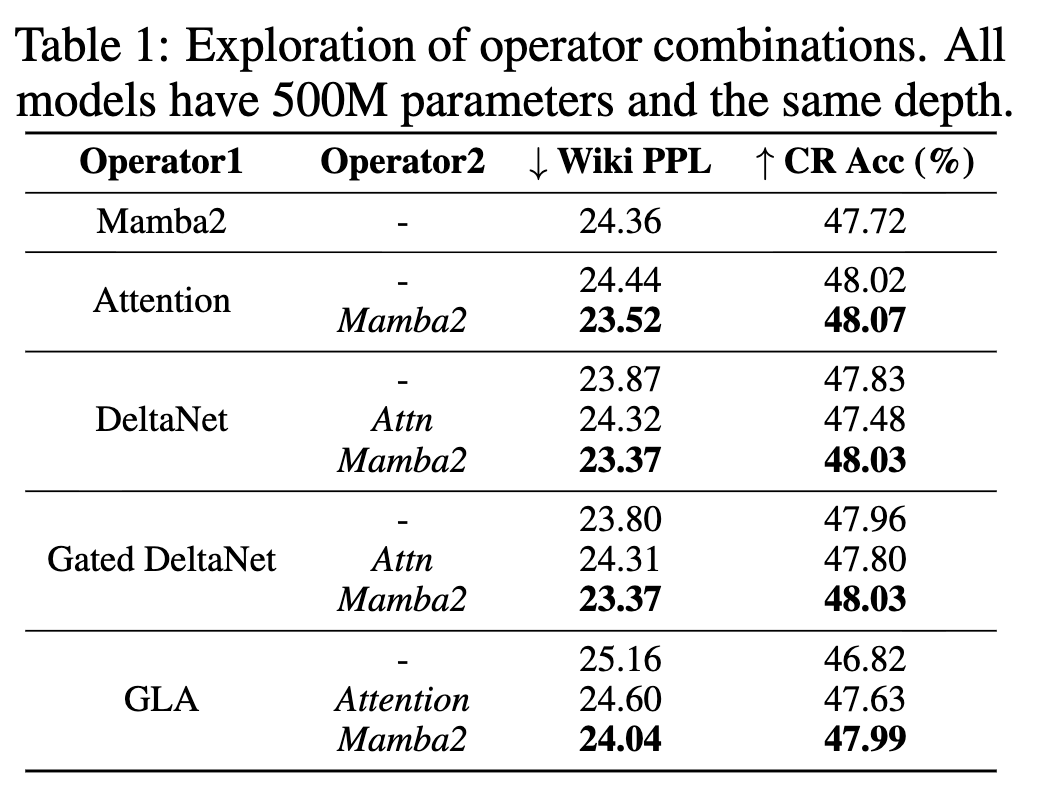
观察与分析。 我们的主要观察如下:
❶ 就语言建模能力而言,DeltaNet 和 Gated DeltaNet 普遍表现为很有前景的候选算子,位于 PPL--时延的帕累托前沿;
❷ 当将这些算子与注意力或 Mamba2 结合构建混合模型时,将 DeltaNet 或 Gated DeltaNet 与 Mamba2 配对通常会带来更低的 PPL 和更高的精度,并且在多种设置下都稳定优于对应的纯模型;相比之下,与注意力配对所带来的收益则不够稳定。这一现象既体现了混合模型本身的优势,也突出了"选择互补算子组合"的重要性;
❸ 当这些算子被用在混合模型中时,算子之间单独表现的差距可能会缩小,这很可能是因为混合层引入了互补且多样的记忆机制。例如,虽然在纯语言建模上 Gated DeltaNet 优于 DeltaNet,但当它们与 Mamba2 组合形成混合模型时,在下游任务上的表现变得相近;在这种情况下,由于 DeltaNet 更高效,它反而成为混合模型中更优的选择。
用进化搜索寻找算子组合
各种高效注意力机制的出现,以及它们在混合模型中的复杂协同效应,促使我们需要一个自动化框架,用于在混合 SLM 中寻找高效且互补的算子组合。为此,我们构建了一个进化搜索引擎,以高效探索复杂的组合设计空间。
以"短程训练 PPL"作为搜索代理指标
支撑我们方法的一个关键观察是:不同语言模型架构之间的相对性能排序在训练早期就会趋于稳定 ,这一点也可以从图 4(a) 中的验证损失曲线中看出。基于这一现象,我们展示了:短程训练得到的 PPL 可以作为预测最终任务性能的可靠代理指标,从而大幅降低评估每个候选架构所需的训练成本。
为量化这一相关性,我们计算了多种 LM 架构在"短程训练 PPL"与"完整训练 PPL"之间的 Spearman 相关系数 24(这是一种衡量排序相关性的指标,对架构排序尤为重要)。结果表明,两者之间的 Spearman 相关性高达 88.8%,这足以在我们的搜索空间内识别出性能较强的架构。
搜索空间设定
基于前面识别出的有潜力的算子以及它们在混合模型中的协同表现,我们选择 DeltaNet、Attention 和 Mamba2 作为候选算子。我们在最多三类构建 block 的组合空间中进行搜索,每一类 block 分别分配给模型的"前段、中段和后段"。这种"三阶段"策略在算子异质性与整体架构规整性之间取得平衡。
搜索时会探索:
- 各算子的配比(ratio);
- 每种 block 类型中 FFN 的数量;
- 每种 block 类型在整个网络中重复出现的次数。
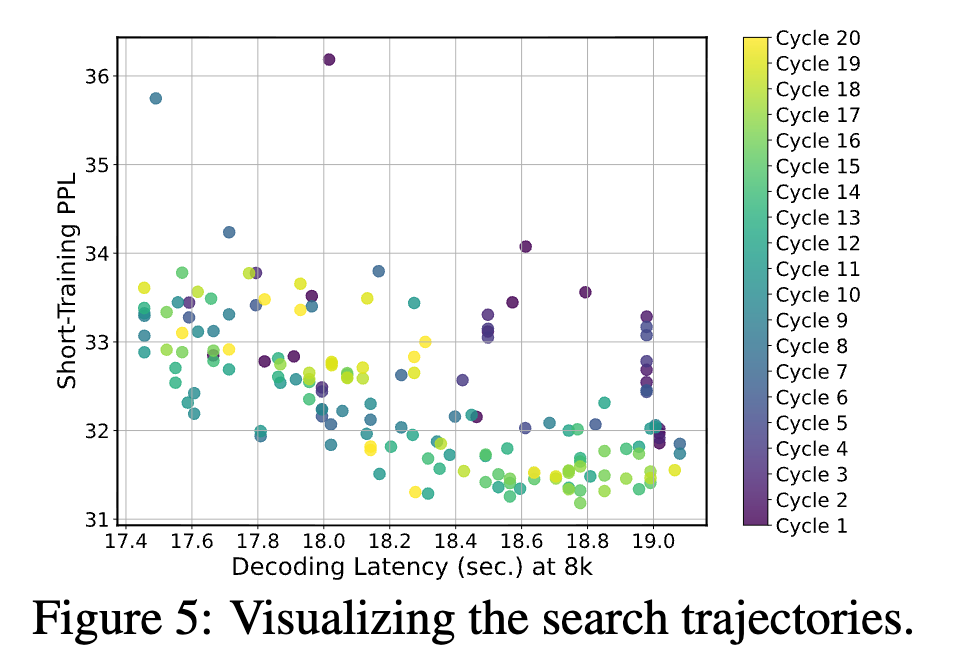
(图 5:搜索轨迹可视化)
进化搜索算法。 我们采用 aging evolution 搜索策略 25,流程包括以下步骤:
① 初始化:用已有设计或随机采样的架构初始化种群,并对它们进行短程训练;
② 选择(Selection):在每一轮进化中,我们采用锦标赛选择(tournament selection)26,从当前种群中挑选在短程训练 PPL 上表现优异且满足预设时延预算的"父代"架构;
③ 变异(Mutation):对被选中的父代在某一设计因子上进行有针对性的变异,例如调整算子配比、FFN 配比或 block 类型数量;
④ 评估与替换(Evaluation & Replacement):对变异后的"子代"架构进行训练和短程 PPL 评估,同时使用预先构建的查找表(LUT)精确估算其时延。然后用新的候选架构替换掉种群中"最老"的架构,从而在探索和利用之间取得平衡。
以解码时延为目标的搜索
为评估搜索框架的有效性,我们首先以"解码时延"作为效率指标进行搜索(在 NVIDIA A100 上,batch size 为 1,生成 8k tokens 的时间)。为方便展示,我们将注意力的窗口大小设为 512,这一长度足以覆盖通用的常识推理任务,同时也适合作为搜索代理。
我们在图 5 中可视化了整个搜索过程,每一轮进化中会采样并评估 10 个新架构。可以看到,搜索过程会在预设时延约束下,逐步朝着"更低 PPL 的更优模型"方向演化。搜索到的架构在表 2 中给出。

有趣的是,我们发现该"时延友好"的架构将 DeltaNet-FFN-Mamba2-FFN 和 Attention-FFN-Mamba2-FFN 作为基本构建模块,并以交替堆叠的方式进行组合。这一结果呼应了我们先前的观察------DeltaNet 与 Mamba2 是强有力的候选算子------也与现有将注意力与状态空间模型交替堆叠的工作 6, 22, 5, 23, 7 一致。
表 3:在相同时延下,将搜索得到的架构与基线模型进行对比。
| 模型 | 参数量 (M) ↓ | Wiki PPL ↓ | CR 准确率 (%) ↑ | 时延 ↓ |
|---|---|---|---|---|
| SWA | 616 | 23.33 | 48.72 | 18.01 |
| GLA | 862 | 22.67 | 48.43 | 18.19 |
| DeltaNet | 852 | 20.90 | 50.38 | 18.18 |
| Gated DeltaNet | 672 | 21.98 | 49.99 | 17.91 |
| Mamba2 | 601 | 23.14 | 48.61 | 17.82 |
| Mamba2 + FFN | 889 | 21.43 | 50.04 | 17.73 |
| Searched (Ours) | 837 | 20.70 | 51.04 | 17.71 |
在上述对比中,我们选取了具有相同模型深度 且通过调整 hidden size 使其解码时延与搜索架构匹配的基线模型。所有模型均在 Smollm-corpus 上的 100B tokens 上训练,并使用 Wikitext PPL 和八个 CR 任务的平均准确率进行评估。
如表 3 所示,搜索得到的混合架构在 PPL 和准确率上均优于纯算子模型。这一提升主要源于:
- 更高效的算子组合,在相同解码时延下可以容纳更多的参数;
- 混合算子在模型中扮演的互补角色。
以参数量为目标的搜索
我们还进行了另一轮搜索,这次以参数量(500M)作为效率指标。我们发现:
❶ 搜索得到的架构相比所有 500M 基线模型,CR 平均准确率提升超过 1.21%,PPL 降低超过 0.74;
❷ 如表 2 所示,与以解码时延为目标的"时延友好"架构相比,这一"参数友好"架构通常包含 更多的注意力模块 (注意力在参数上更高效但解码时更慢),更少的 Mamba2/DeltaNet 模块,并且具有更大的模型深度------这与第 2.1 节中指出的"深度在参数效率上更有优势"的结论相吻合。
这一系列实验表明,我们的搜索方案在"不同效率指标"下都能有效找到与目标指标高度匹配的算子组合。
经验总结:SLM 的算子组合。
混合模型展现出巨大的潜力,但不同算子之间的协同作用十分复杂,因此需要识别并组合互补的算子。在训练早期,架构间相对排序的稳定性可以作为迭代设计的有效信号,而通过合适的搜索算法,可以将这一过程策略性地加速,从而在大规模设计空间中高效找到高质量的混合 SLM 架构。
SLM 训练:权重归一化(Weight Normalization)
当小模型被"正确地"训练时,它们的潜力才能得到更充分的释放。我们观察到,在标准训练方案下,模型的权重呈现出不平滑 特征:在某些维度上权重范数非常大,如图 6 第一行所示。正如文献 27, 28 所指出的,当梯度幅度相近时,较大的权重范数会导致相对权重更新量 变小,尤其是在训练后期学习率较低时,容易造成"学不动"的现象。
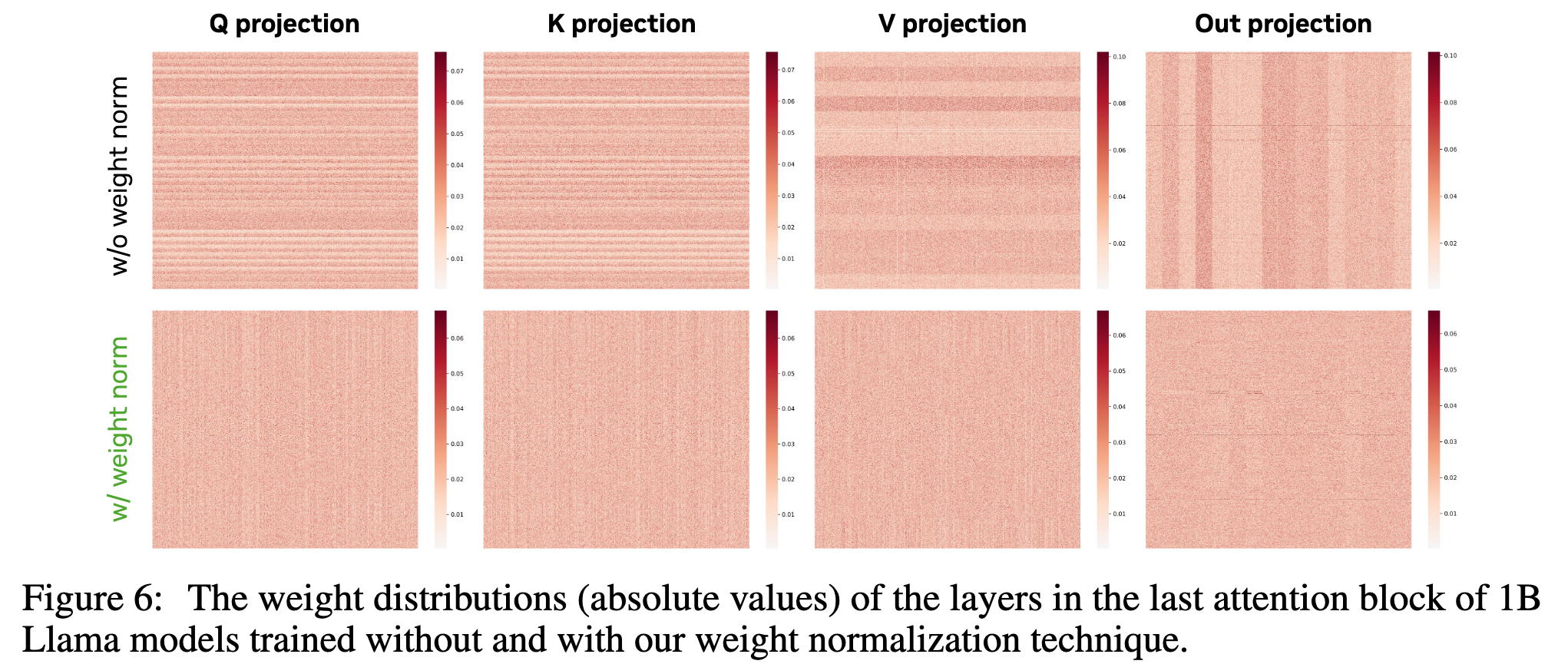
基于这一动机,并参考 28,我们在每次训练迭代后将模型权重投影到单位范数球面上 ,从而约束权重的大小。这个归一化步骤会消除"径向(radial)分量",强化"角度(angular)方向"的更新,使得在相近梯度幅度下能获得更大的相对权重变化。
具体来说,如图 6 所示:
- 作用于 hidden features 的权重矩阵(记为 Case-1),
- 以及输出被加回 hidden features 的权重矩阵(记为 Case-2),
分别呈现出横向和纵向的结构模式。对应地,我们分别沿不同的维度进行权重归一化。形式化地,对于每个权重矩阵 W ∈ R C out × C in W \in \mathbb{R}^{C_{\text{out}} \times C_{\text{in}}} W∈RCout×Cin,在每一步训练后,我们将其投影到单位范数球面上:
-
对于 Case-1:
W i , : ← W i , : ∥ W i , : ∥ 2 , i = 1 , ... , C out , W_{i,:} \leftarrow \frac{W_{i,:}}{\lVert W_{i,:} \rVert_2}, \quad i = 1, \ldots, C_{\text{out}}, Wi,:←∥Wi,:∥2Wi,:,i=1,...,Cout,
-
对于 Case-2:
W : , j ← W : , j ∥ W : , j ∗ ∥ 2 , j = 1 , ... , C in . W_{:,j} \leftarrow \frac{W_{:,j}}{\lVert W_{:,j}^* \rVert_2}, \quad j = 1, \ldots, C_{\text{in}}. W:,j←∥W:,j∗∥2W:,j,j=1,...,Cin.
如图 6 第二行所示,采用权重归一化后,权重分布变得更加平滑。
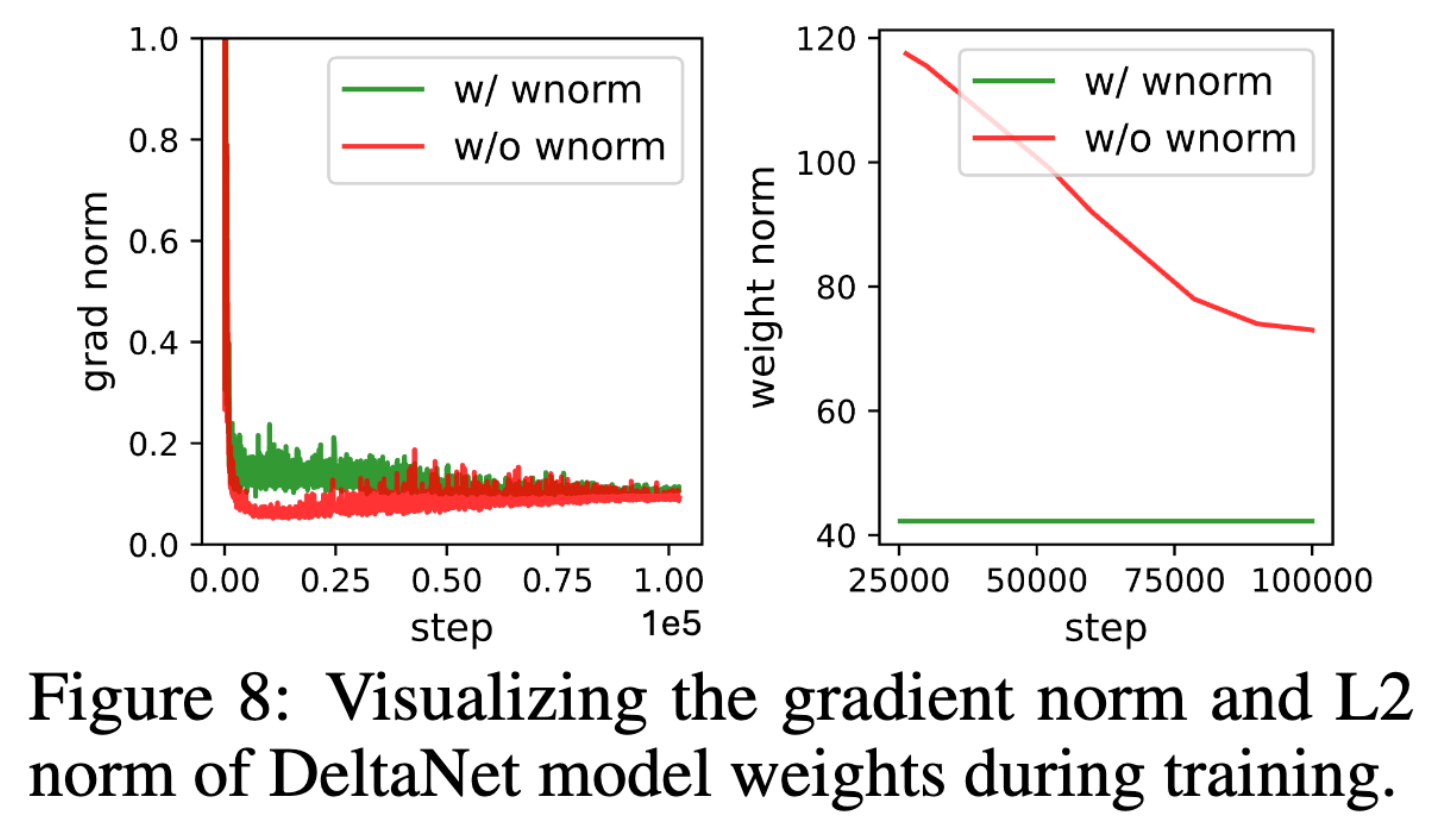
跨模型评估。 我们在不同模型上应用权重归一化,并在图 7 中给出了验证损失曲线,在图 8 中给出了权重矩阵的平均元素级梯度范数和 L2 范数。可以看到:
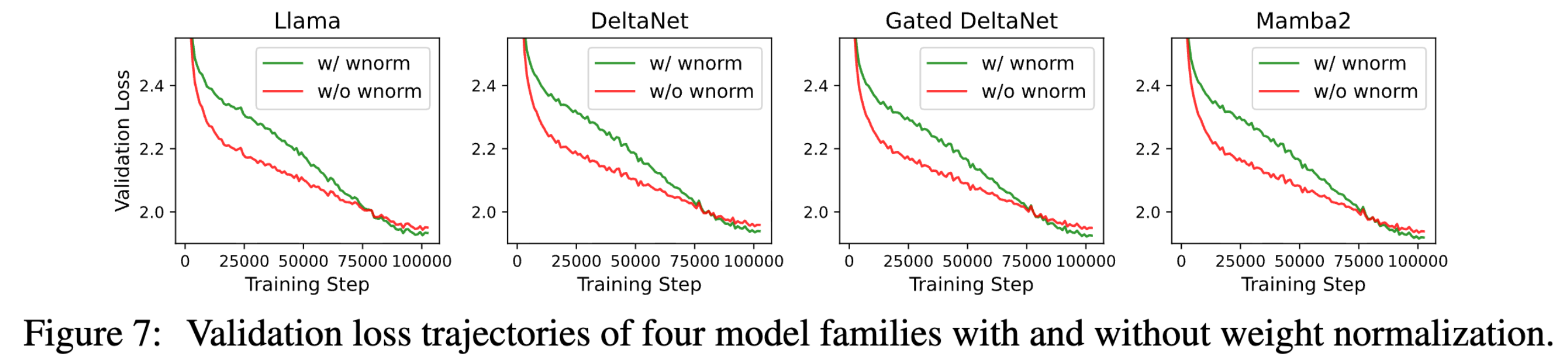
❶ 虽然在训练早期,由于基线(不使用权重归一化)的权重更新不受约束(具有更强的径向更新),其收敛速度更快,但随着训练进行,其收敛速度会逐渐减弱;而加入权重归一化后,收敛速度更加平稳,并且在训练后期超过基线,在多个模型家族中都带来更优的最终收敛表现;
❷ 相比基线,权重归一化显著降低了模型权重的 L2 范数,同时略微提高了梯度范数,从而保证了更大的相对权重变化,这在训练后期尤为有利。
表 4:在 1B 模型上评估权重归一化,这些模型均在 Smollm-corpus 中的数据集上以 100B tokens 进行训练。
| 模型 | 设置 | Wikitext PPL ↓ | CR 准确率 (%) ↑ |
|---|---|---|---|
| Llama 1B | w/o wnorm | 18.67 | 53.81 |
| w/ wnorm | 18.03 | 54.85 | |
| DeltaNet 1B | w/o wnorm | 18.86 | 53.46 |
| w/ wnorm | 18.19 | 54.39 | |
| Mamba2 1B | w/o wnorm | 18.44 | 53.30 |
| w/ wnorm | 17.88 | 54.71 |
如表 4 所示,权重归一化在不同模型家族上都带来了稳定收益:平均 CR 准确率提升约 +1.20%,PPL 平均降低约 0.66,说明其作为一个"外挂式组件"具有较强的通用有效性。
与 nGPT 的关系。 我们的权重归一化技术可以看作 nGPT 28 的一个简化且高效的变体。nGPT 通过在权重归一化之外引入多层激活归一化,使模型中的所有计算都在单位球面上进行。我们发现:
❶ 权重归一化本身(以及由此带来的更有效的权重更新)是收敛性提升的关键因素。当单独使用权重归一化时,其最终任务性能已经可以与完整的 nGPT 方案相当;
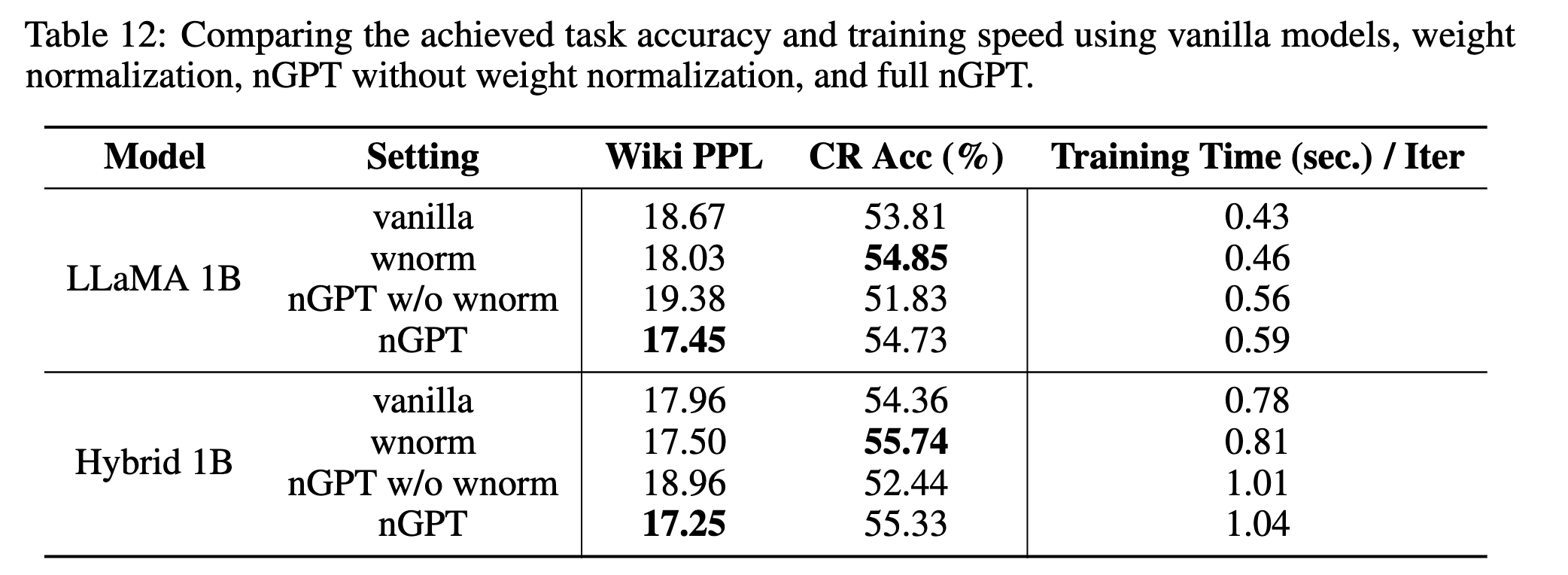
❷ 更重要的是,nGPT 额外引入的激活归一化层会带来显著的训练开销------在 SLM 场景中训练时间增加超过 20%,这会在固定训练时长下减少可见的训练 token 数量。我们的贡献在于识别出最关键的贡献组件(即权重归一化),并给出了一种在计算上更高效的替代方案。
SLM 训练:Meta Tokens
表 5:在包含 48 个算子的两种线性注意力模型,以及在表 2 中所示的包含 24 个算子的搜索模型上,评估 meta tokens 的效果。
| 模型 | Meta Token | Wikitext PPL ↓ | CR 准确率 (%) ↑ |
|---|---|---|---|
| Mamba2-48L-1B | w/o | 19.04 | 51.71 |
| w/ | 18.98 | 52.33 | |
| DeltaNet-48L-1B | w/o | 19.60 | 52.12 |
| w/ | 19.47 | 52.46 | |
| Searched-24L-830M | w/o | 20.61 | 50.74 |
| w/ | 20.49 | 51.13 |
已有工作 Hymba 表明,在序列前端加入一组可学习的 token,可以缓解所谓的 attention sink 问题 ------这一问题源于注意力机制被"强制"集中在一些语义上不重要的 token 上。
我们发现,这些 meta tokens 对非 softmax 的线性注意力机制 同样有帮助:在解码阶段,当将线性注意力改写成递归形式时,它们可以被视为一种"可学习的缓存初始化"。
如表 5 所示,在输入序列前端添加 256 个 meta tokens,可以在开销几乎可以忽略的前提下,稳定提升语言建模与推理精度(平均 CR 准确率提升约 +0.45%)。
Nemotron-Flash:新的模型家族
结合前文提出的所有架构改进和训练技术,我们构建并训练了一个新的混合式小型语言模型(SLM)家族,称为 Nemotron-Flash,包含两种不同规模的模型。
模型配置(Model configuration)
我们采用前面搜索到的 解码友好(decoding-friendly) 模型结构,将
- DeltaNet-FFN-Mamba2-FFN(Block-1)
- Attention-FFN-Mamba2-FFN(Block-2)
作为基本构建模块交替堆叠。基于此,我们构建了两个模型:Nemotron-Flash-1B 和 Nemotron-Flash-3B,参数量分别为 0.96B 和 2.7B,其深度与宽度根据前面的缩放定律进行配置。
具体而言:
- Nemotron-Flash-1B 的配置与表 2 中相同,参数量的增大来自下文所述的新分词器。它的 hidden size 为 2048,包含 12 个 block,每个 block 含有一个 token-mixing 模块和一个 FFN;如果将 DeltaNet、Mamba2、Attention 和 FFN 视为四类算子,则该模型共包含 24 个算子。
- Nemotron-Flash-3B 的 hidden size 为 3072,包含 36 个算子,相比 1B 版本多了两个 Block-1 和一个 Block-2。
分词器(Tokenizer)
不同于以往通过减小词表规模来节省参数、从而实现"参数高效"的 SLM 1,我们采用的是词表规模更大的分词器 30。我们发现:
- 词表增大带来的嵌入层 / LM head 参数与时延开销相对较小;
- 而更粗粒度的 token 表示在对同一句子进行编码时可以显著减少 token 数量,从而带来更明显的时延下降。
实验
训练设置(Training settings)
两种模型均使用 Adam 优化器进行训练(由于采用权重归一化,因此不使用 weight decay),学习率采用余弦调度(cosine schedule),初始学习率为 1e-3。训练过程大致分为两阶段:
-
首先在 Zyda2 数据集上进行训练;
-
随后切换到质量更高的数据集,包括:
- 常识推理数据集(Climb-Mix 32 与 Smollm-corpus 12),
- 一个包含大量数学与代码数据的高质量私有数据集,
- 以及 MegaMath 33。
两种模型均在 256 张 NVIDIA H100 GPU 上训练,总训练 tokens 为 4.5T ,batch size 为 2M tokens ,上下文长度为 4096 。在最后的 25B tokens 训练阶段,我们将上下文长度扩展到 29000。
时延测量的部署设置(Deployment settings for latency measurement)
为了与以全注意力层为主的基线模型进行公平对比,我们采用:
- TensorRT-LLM 的 AutoDeploy kernels 10,并对全注意力层使用高效的 KV cache 管理;
- 使用 CUDA Graph 进一步加速。
对于其他算子,我们使用:
- Mamba2 的官方实现 15,
- 对包括 DeltaNet 在内的线性注意力层使用 FlashLinearAttention 21。
在推理时,我们始终将整个模型包装在一个 CUDA Graph 中。
基线与评测任务(Baselines and tasks)
我们与当前最先进(SOTA)的 SLM 系列进行对比,包括:
- Qwen3 34、Qwen2.5 35、Llama3.2 36、SmolLM2 2、h2o-Danube 37、AMD-OLMo 38 等。
模型精度通过 lm-evaluation-harness 39 在 16 个评测任务上进行评估,任务包括:
- MMLU,
- 常识推理(PIQA、ARCC、ARCE、Hellaswag、Winogrande、OBQA),
- 数学(GSM8K、MathQA),
- 代码(HumanEval、HumanEval-Plus、MBPP、MBPP-Plus),
- 以及检索类任务(FDA、SWDE、Squad)。
评测设定为:
- GSM8K 和 MMLU 使用 5-shot;
- MBPP 和 MBPP-Plus 使用 3-shot;
- 其余任务均为 0-shot。
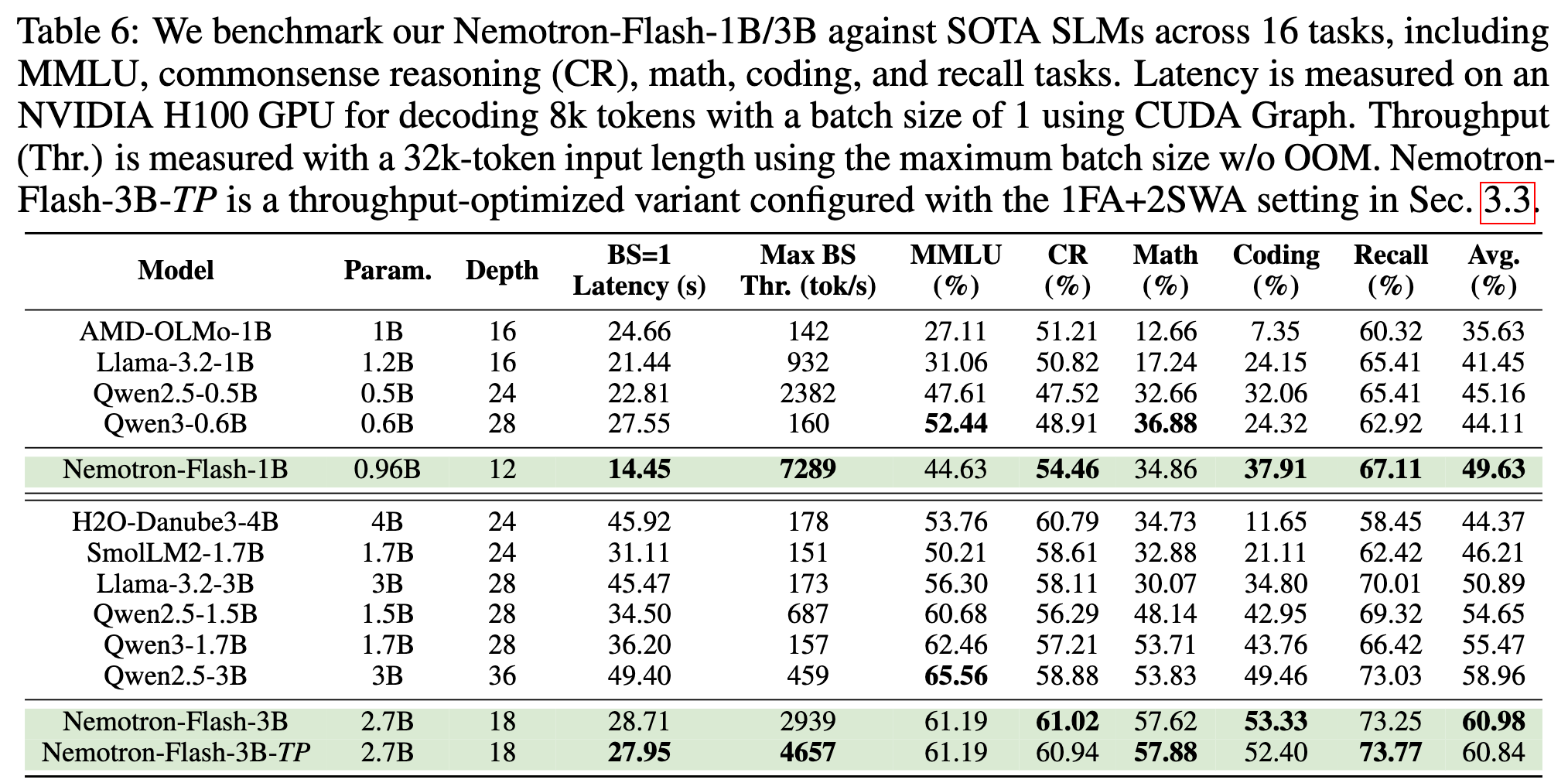
各领域的平均准确率汇总见表 6。
与 SOTA Base SLM 的对比(Benchmark with SOTA Base SLMs)
如表 6 所示,在相近模型规模下,Nemotron-Flash 系列在解码时延和精度上均取得了最优表现。例如:
-
Nemotron-Flash-1B 相比 Qwen3-0.6B:
- 平均准确率提升 5.5%,
- 时延减少 1.9×,
- 吞吐量提升 46×。
-
Nemotron-Flash-3B 相比 Qwen2.5-3B / Qwen3-1.7B:
- 平均准确率分别提升 +2.0% / +5.5%,
- 时延分别降低 1.7× / 1.3×,
- 吞吐量分别提升 6.4× / 18.7×。
此外,在进一步优化注意力配置后,Nemotron-Flash-3B-TP 的吞吐量相较:
- Qwen2.5-3B 提升 10.1×,
- Qwen3-1.7B 提升 29.7×。
值得注意的是:
- 在获得最具竞争力的时延与吞吐量的同时,Nemotron-Flash-3B 在常识推理、数学、代码以及检索任务上,在所有参数量大于 1.5B 的模型中取得了最高精度;
- 尽管 Nemotron-Flash-1B 和 Nemotron-Flash-3B 仅包含 2 层和 3 层完整注意力(full attention)层,但二者的检索性能依然处于最优水平,这表明并不需要在所有层中都维护完整的 KV cache,这一点也与现有混合式 LMs 的观察结果一致 30, 40。
与 SOTA Instruct SLM 的对比(Benchmark with SOTA Instruct SLMs)
我们对 Nemotron-Flash-3B 进行了指令微调(instruction tuning),采用两阶段的有监督微调(SFT)策略,在两个私有数据集上进行训练:
- 第一阶段学习率设为 8e-6,
- 第二阶段设为 5e-6 ;
每个阶段均训练 1 个 epoch ,采用余弦学习率调度器,global batch size 为 384。
为加速训练,我们采用了已有工作 41, 42, 43 中提出的高效 packing 策略,block size 设为 29,000 tokens。
我们将 Nemotron-Flash-3B-Instruct 与 Qwen2.5-1.5B 和 Qwen3-1.7B 在以下任务上进行对比:
- MMLU(5-shot)、
- GPQA(0-shot)、
- GSM8K(5-shot)、
- IFEval。
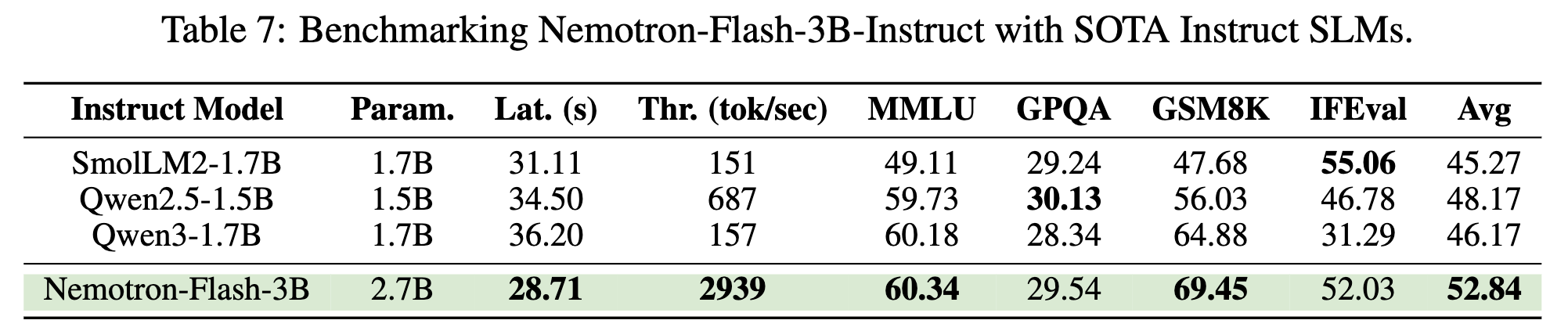
如表 7 所示,Nemotron-Flash-3B-Instruct 在推理能力与指令跟随能力方面均表现出色,取得了最优的平均准确率和效率。例如,相比 Qwen2.5-1.5B 和 Qwen3-1.7B:
- 平均准确率提升超过 +4.7%,
- 吞吐量分别提升 4.3× / 18.7×。
尽管 Nemotron-Flash 的参数量比这些基线模型多出 1.6× 以上(有助于提升"智能水平"),但凭借其在架构层面的优化设计,Nemotron-Flash 依然能够在真实设备上保持更优的效率。
Conclusion
- 以推理时延为目标优化 LLM 的现实价值很大,也很符合 NVIDIA 作者团队的研究需求。本文的工作可以在显著提升模型推理效率的同时基本保持精度。
- 搜索出来的最优架构类似 DeltaNet-FFN-Mamba2-FFN 和 Attention-FFN-Mamba2-FFN,都是 linear attention 在前,full attention 在后,同时网络的最后一层或最后两层都是 full attention,其实和目前大部分 hybrid 模型的算子排布比较接近。