在真正开讲之前需要补充一下"16. 基于 CPU 的转换、量化实现"和"18. 持续优化模型微调"中遗漏的信息。
"基于 CPU 的转换、量化实现"内容补充
在这章我通过 Python 导出基于 OpenVINO 的 IR 模型后并没有将对应的 tokenizer 导出。这会导致调用 apply_chat_template 进行推理时出现以下报错:
bash
[2025-11-25 11:20:07,191]_apply_template - Template application failed, using raw string: Check '!chat_tpl.empty()' failed at ../../../../src/cpp/src/tokenizer/tokenizer.cpp:655:
Chat template wasn't found. This may indicate that the model wasn't trained for chat scenario. Please add 'chat_template' to tokenizer_config.json to use the model in chat scenario. For more information see the section Troubleshooting in README.md为此,这里补上 export_tokenizer 函数用于导出 tokenizer 配置。
python
def export_tokenizer(self):
# 导入 openvino_tokenizers
from openvino_tokenizers import convert_tokenizer
# 导入 openvino
from openvino import save_model
# 使用 huggingface 模式加载量化后的 tokenizer
hf_tokenizer = AutoTokenizer.from_pretrained(
self.unsloth_merge_model_dir,
trust_remote_code=True
)
# 对 tokenizer 进行转换
ov_tokenizer, ov_detokenizer = convert_tokenizer(hf_tokenizer, with_detokenizer=True)
# 导出基于 ov 的 tokenizer 和 detokenizer
save_model(ov_tokenizer, os.path.join(self.openvino_int4_model_dir,"openvino_tokenizer.xml"))
save_model(ov_detokenizer, os.path.join(self.openvino_int4_model_dir,"openvino_detokenizer.xml"))这里我们不能直接使用 Huggingface 的 tokenizer_config.json(虽然上面报错说 tokenizer_config.json 中找不到 'chat_template' 参数)。事实上由于我们使用的是 OpenVINO 方案,因此需要对 Huggingface 的 hf_tokenizer 后进行进一步的转换( convert_tokenizer -> save_model)后方可使用。
我们可以将 export_tokenizer 追加到 start_to_export 函数末尾即可:
python
def start_to_export(self):
...
try:
self.export_tokenizer()
except Exception:
logger.error("FATAL: Tokenizer export failed. Cannot proceed with openvino-genai.")
sys.exit(5)
logger.info("Done.")"持续优化模型微调"内容补充
其实 1.2287 并不是我的最终答案。后来我趁放假补充了训练数据量后又做了三次调优。最终模型得分(Loss)定格在 0.8698。超参数组合如下:
bash
训练数据:678915
最终得分 (Loss): 0.8698
验证集损失 (Eval Loss): 0.8698
训练集损失 (Train Loss): 0.8652
最优超参数组合:
{
"learning_rate": "2e-4",
"max_steps": 7500,
"r": 256,
"lora_alpha": 512,
"per_device_train_batch_size": 32,
"gradient_accumulation_steps": 8,
"max_seq_length": 8192
}经复盘发现继续微调下去意义不是很大,毕竟基于现有的资源(硬件资源和数据资源)不会有太大的性能提升,因此后面将以这个作为基线开展工作(除非接下来的"问答验证"环节中评估分数太低,这时就需要调整数据精度并重新训练)。
好啦,书接上回。上一章节我们已经做完模型的持续调优了,接下来就需要将模型导出部署并进行"问答验证"。
看过我博客的小伙伴都知道,之前我尝试过 Optimum Intel 套件直接驱动 Qwen1.5 7B 的 GGUF 模型(属于实验性质),在单用户提问时响应速度还算可以,但准确率嘛就有点"吓人"了。除了幻觉严重外,自控能力还非常有限(无限输出)。但毕竟是低版本模型嘛,可以理解...可以理解。
这次我带着微调后的 Qwen3 0.6B 模型又来挑战了,除了使用垂直领域知识进行微调外,在 OpenVINO 驱动上相较于之前做了大量的改进。同样在自己的 MBP 上进行验证,希望能有个好结果吧。
1.OpenVINO Model Server(OVMS)与思维链
由于 Qwen3 模型是带有思维链模式的,看了一遍 OpenVINO 的官方文档,目前只有 OpenVINO Model Server (OVMS) 提供 --reasoning_parser 参数用于思考链推理,而且也只支持 qwen3。
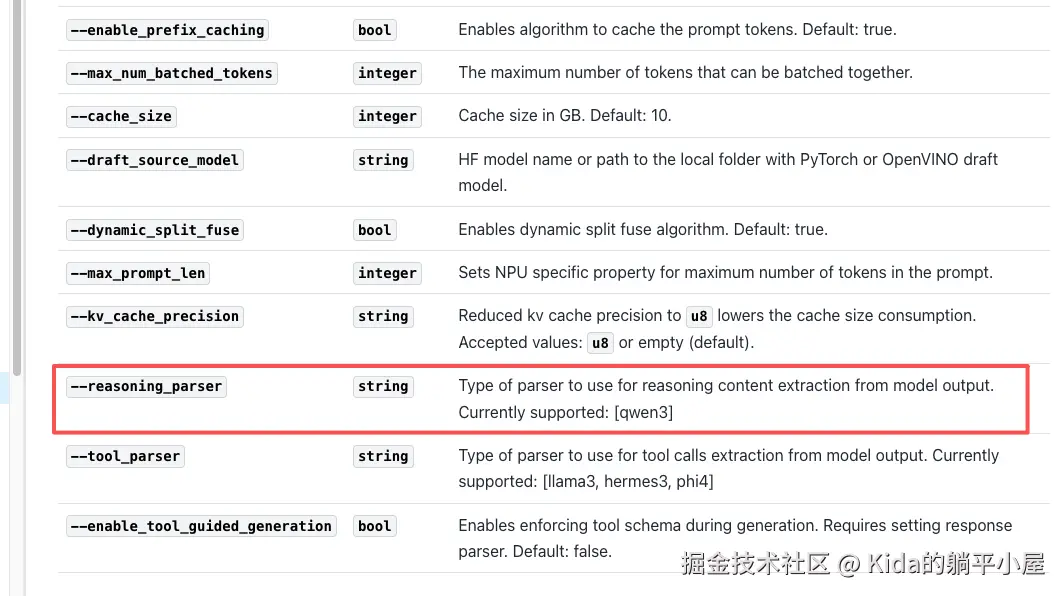
OVMS 目前只支持 Linux 和 Windows 平台,我大 Mac 只能选择 Docker 解决方案。
事不宜迟,Checkout 最新镜像(openvino/model_server:latest)后启动 OVMS 服务。
bash
docker run -d \
-p 8000:8000 \
-p 9000:9000 \
-v <int4_path>/models:/models \
openvino/model_server:latest \
--model_path /models/model1 \
--model_name Qwen3-0.6R \
--reasoning_parser qwen3 \
--rest_port 8000 \
--port 9000 使用以上命令启动后得到输出
bash
2025-11-28 14:50:36 error parsing options - unmatched arguments: --reasoning_parser, qwen3, What?
不是说 reasoning_parser 参数可以用的吗?之后我又尝试将 reasoning_parser 放入环境变量。虽说没有报错了,但思考链没有生效。既然解决不了就先放下,于是得到以下命令:
bash
docker run -d \
-p 8000:8000 \
-p 9000:9000 \
-v <int4_path>/models:/models \
openvino/model_server:latest \
--model_path /models/model1 \
--model_name Qwen3-0.6R \
--rest_port 8000 \
--port 9000 这里需要着重说明的是,参数里挂载目录传参和 model_path 参数之间的关系。首先 OVMS 使用的模型一定要是 IR 模型(我猜的,毕竟我只有 IR 模型运行成功了),因此 <int4_path> 要填写量化后导出的 int4 模型路径。但为什么后面要有一个 models 呢?这是为了配合 model_path 参数使用的需要。目录结构如下:
bash
OpenVINOModel
└── INT4
└── models
└── model1
└── 1
├── config.json
├── generation_config.json
├── openvino_config.json
├── openvino_detokenizer.bin
├── openvino_detokenizer.xml
├── openvino_model.bin
├── openvino_model.xml
├── openvino_tokenizer.bin
└── openvino_tokenizer.xml由于 OVMS 启动时会扫描 model_path 路径下的目录(/models/model1),其中 /models 是固定项,这个属于挂载点。下一级目录 model1 可以是任意的名字,但再下级就需要一个名为 1 的文件夹。这个 1 代表的是模型的版本(version),如果缺失了这个目录,就会一直报找不到版本(No version found for model in path)。
而 docker 命令中 model_name 是为了调用时有一个明确的 model 指向,因此为了不与 0.6B 混淆,这里就重命名为 0.6R。
至此,docker 的 OVMS 应该就能启动成功了(docker logs 看一下就知道了)。
在浏览器输入地址 http://localhost:8000/v1/config 就能够查看模型加载效果
json
{
"Qwen3-0.6R": {
"model_version_status": [
{
"version": "1",
"state": "AVAILABLE",
"status": {
"error_code": "OK",
"error_message": "OK"
}
}
]
}
}好了,服务部署好了就尝试推理吧。
写一个 Python 脚本试试多轮对话:
python
import requests
import json
base_url="http://localhost:8000/v3/chat/completions"
headers = {
"Content-Type": "application/json"
}
payload = {
"model": "Qwen3-0.6R",
"stream": False,
"messages": [
{"role": "system", "content": "你是一名专业的中医药知识问答质量评估员。"},
{"role": "user", "content": "请详细分析一下中医理论中'阴阳'的概念,并给出思考过程。"}
]
}
response = requests.request("POST", base_url, json=payload, headers=headers)
if response.status_code == 200:
results = json.loads(response.text)["results"]
print(results)返回的结果如下:
python
openvino Error code: 404 - {'error': 'Mediapipe graph definition with requested name is not found'}对此官方文档给出提示
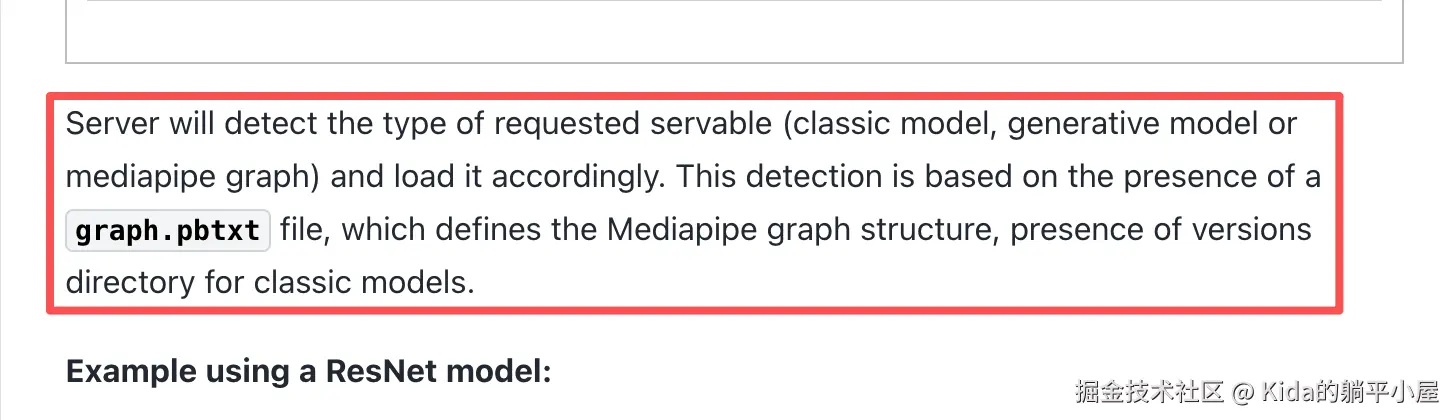
是的,我明白还需要 graph.pbtxt 这个文件了。但是我的 IR 导出并没有将 graph.pbtxt 生成出来。
那么 graph.pbtxt 我要在哪里才能够找到呢?经过一番寻找最终在 Github 的某一个 Issus 中找到了答案。
需要先访问 github.com/openvinotoo... 项目中找到 demos -> continuous_batching -> graph.pbtxt。找到 graph.pbtxt 后下载并拷贝到 <int4_path>/models/model1/1 目录下跟 int4 量化模型放在一起就可以了。如下图:
python
OpenVINOModel
└── INT4
└── models
└── model1
└── 1
├── config.json
├── graph.pbtxt
├── generation_config.json
├── openvino_config.json
├── openvino_detokenizer.bin
├── openvino_detokenizer.xml
├── openvino_model.bin
├── openvino_model.xml
├── openvino_tokenizer.bin
└── openvino_tokenizer.xml就这样 OVMS 启动时就能扫描到了。
好了,现在再试试调用吧。结果...
bash
Mediapipe execution failed. MP status - INVALID_ARGUMENT: CalculatorGraph::Run() failed: \\nCalculator::Process() for node \\"LLMExecutor\\" failed: This servable accepts only single message requestsWhat?This servable accepts only single message requests?不是吧,只支持单次推理?(这里有点搞不懂了,可能是我的 graph.pbtxt 有问题吧,因为之后我尝试过直接用 Optimum Intel 驱动导出的 IR 模型是可以多轮问答的)
OK,就目前这种情况其实就能放弃这个方案了,但为了追求真相我们还是换成单次推理试试:
python
import requests
import json
base_url="http://localhost:8000/v3/completions"
headers = {
"Content-Type": "application/json"
}
payload = {
"model": "Qwen3-0.6R",
"stream": False,
"prompt": "你是一名专业的中医药知识问答质量评估员。请详细分析一下中医理论中'阴阳'的概念,并给出思考过程。"
}
response = requests.request("POST", base_url, json=payload, headers=headers)
if response.status_code == 200:
results = json.loads(response.text)["results"]
print(results)这次 OVMS 确实接收到请求了,但是... CPU 一直拉升并且超长时间内没有响应,如下图:
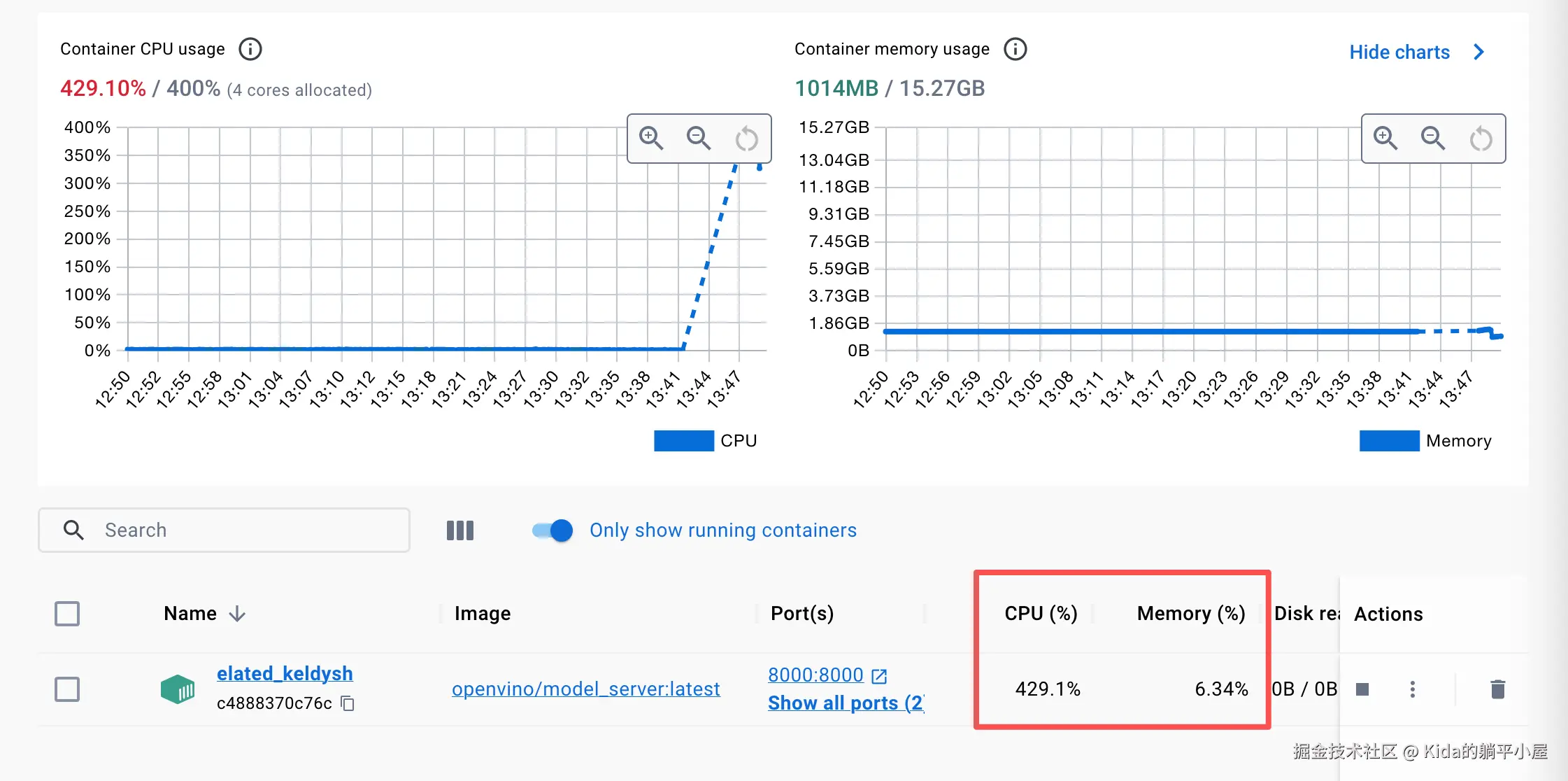
之后足足等了 6 分钟还是没有输出。这台 Mac 的 CPU 分配给 docker 的拢共就只能走 400%,等待的时间内一直被占满,最后实在没有办法了就中断了启动试验。
bash
2025-11-28 13:47:30 [2025-11-28 05:47:30.483][84][llm_executor][info][llm_executor.hpp:66] All requests: 1; Scheduled requests: 1; Cache usage 0.1%;
...
2025-11-28 13:53:53 [2025-11-28 05:53:53.597][84][llm_executor][info][llm_executor.hpp:66] All requests: 1; Scheduled requests: 1; Cache usage 4.2%;也许是我的配置有问题,也可能是我的硬件设备已经不支持这套方案了...也许这套方案在其他硬件或者配置下会有所改善,但就我目前的情况来看是走不通的。
2.OpenVINO GenAI 推理
2.1 OVMS 导出模型
既然 OVMS 走不通,那么我们就选择另一种推理方式 GenAI。
为什么选择 GenAI?这就要说说它与 Optimum Intel 之间的区别。
简单来说,Optimum Intel 更适合从 Huggingface 生态平滑迁移的开发者,而 GenAI 则提供了更高性能、更低依赖的本地化部署选择。
之前之所以使用 Optimum Intel 是因为那时刚刚接触模型开发,在接触 OpenVINO 之前就已经写好了本地基于 Huggingface 的 Qwen1.5 推理底座了。为了能够平滑过度到 CPU 驱动的高性能方案才使用的 Optimum Intel。但这次我们是以性能有限,因此重新选择了对 C++ 更为友好的 GenAI 解决方案。
此外,还有一个原因是后续我有可能会自己开发一个具有边缘推理能力的 APP,这时候 GenAI 就派上用场了(毕竟依赖极少,轻量化且有完整的文本生成流水线,这些对于边缘算力来说是非常重要的)。
ε=(´ο`*)))唉扯远了,回归主题。
在 OVMS 方案中我们使用 SDK 导出 IR 模型时其实是有缺失的情况出现的。这次我们使用官方推荐的导出方式 export_model.py。我在 Github 中找到 openvinotoolkit 项目,并下载 export_model.py 和 requirements.txt 两个文件。下载下来后先安装 requirements.txt ,然后在 step2_export_openvino_model.py 中加入 export_model.py 导出的适配代码,如下图:
python
def export_with_ovms_script(self):
# 读取 requirements.txt 文件并进行安装
export_script_path = self.install_ovms_depend()
# 设置 config.json 文件的导出路径
config_path = os.path.join(self.openvino_model, 'config_all.json')
# 构建结构化的 OVMS 导出脚本
cmd = [
sys.executable, export_script_path,
'text_generation',
'--source_model', self.unsloth_merge_model_dir,
'--model_repository_path', self.openvino_ovms_model_dir,
'--model_name', self.model_name,
'--weight-format', self.weight_format,
'--target_device', self.target_device,
'--config_file_path', config_path,
'--cache_size', str(self.cache_size),
'--max_num_seqs', str(self.max_num_seqs),
'--max_num_batched_tokens', str(self.max_num_batched_tokens),
'--reasoning_parser', self.reasoning_parser,
'--extra_quantization_params', '--sym --group-size 128'
]
# 根据 enable_prefix_caching 配置决定是否加上 --enable_prefix_caching 参数
if self.enable_prefix_caching:
cmd.append('--enable_prefix_caching')
try:
# 运行导出
result = subprocess.run(cmd, capture_output=True, text=True, check=True)
# 如果出现 warning 和 error 就进行输出
if result.stderr:
logger.warning(f"OVMS export stderr: {result.stderr}")
# 设置导出状态为 True
self.ovms_exported = True
logger.info("OVMS export completed successfully")
return True
except subprocess.CalledProcessError as e:
return False导出后的文件目录如下:
bash
OVMS
`-- qwen3-reasoning
|-- added_tokens.json
|-- chat_template.jinja
|-- config.json
|-- generation_config.json
|-- graph.pbtxt
|-- merges.txt
|-- openvino_detokenizer.bin
|-- openvino_detokenizer.xml
|-- openvino_model.bin
|-- openvino_model.xml
|-- openvino_tokenizer.bin
|-- openvino_tokenizer.xml
|-- special_tokens_map.json
|-- tokenizer.json
|-- tokenizer_config.json
`-- vocab.json但是...
如果直接使用官方提供的 export_model.py 脚本导出是会出现报错的。如下图:
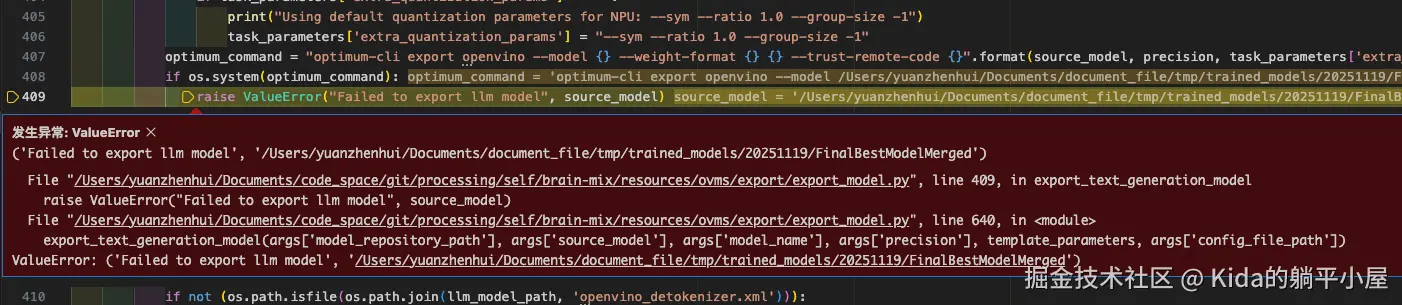
让我们来对照一下 export_model.py 源码和 huggingface 的说明文档。通过上面报错我们可以定位到导出语句:

可以看到在 export_model.py 中导出依然采用的是 optimum-cli export。而关于 optimum-cli export 我们早已在 huggingface 中看过:hf-mirror.com/docs/optimu...
bash
usage: optimum-cli export openvino [-h] -m MODEL [--task TASK] [--framework {pt}] [--trust-remote-code]
[--weight-format {fp32,fp16,int8,int4,mxfp4,nf4,cb4}]
[--quant-mode {int8,f8e4m3,f8e5m2,cb4_f8e4m3,int4_f8e4m3,int4_f8e5m2}]
[--library {transformers,diffusers,timm,sentence_transformers,open_clip}]
[--cache_dir CACHE_DIR] [--pad-token-id PAD_TOKEN_ID] [--ratio RATIO] [--sym]
[--group-size GROUP_SIZE] [--backup-precision {none,int8_sym,int8_asym}]
[--dataset DATASET] [--all-layers] [--awq] [--scale-estimation] [--gptq]
[--lora-correction] [--sensitivity-metric SENSITIVITY_METRIC]
[--quantization-statistics-path QUANTIZATION_STATISTICS_PATH]
[--num-samples NUM_SAMPLES] [--disable-stateful] [--disable-convert-tokenizer]
[--smooth-quant-alpha SMOOTH_QUANT_ALPHA]
output
optional arguments:
-h, --help show this help message and exit
...通过对比发现在 export_model.py 中缺少了 --task 参数,这样的话 optimum-cli export 是无法知道你要导出的是什么类型的。为此,我们还需要修改一下 export_model.py 源码。如下图:

这样才能够正常导出。
2.2 GenAI 推理
模型导出后我们将使用 GenAI 管道的方式加载模型并实现推理。
整体代码我全部写在 step3_openvino_runtime.py 脚本中了,各位感兴趣可以自行 Checkout 下来阅读。在这里我只说代码中几个重点实现。
2.2.1. 线程、队列与生成器(异步流式处理模式)
代码中采用了 Python 异步 I/O 密集型任务的经典模式:生产者-消费者模型。
通过 threading.Lock 确保 OpenVINO 推理过程是互斥的。blocking=False 实现了非阻塞的系统繁忙检测:当有任务正在运行时,新请求会被快速拒绝(返回 "系统繁忙"),而不是排队阻塞,这极大地提高了服务的响应速度和稳定性。
python
def transfor_stream_msg(
self,
msg: Union[str, List[Dict[str, str]]],
**kwargs
) -> Generator[Dict[str, str], None, None]:
# 检查是否线程繁忙
if not OpenvinoRuntime._inference_lock.acquire(blocking=False):
logger.warning("Inference request denied: System is busy.")
yield {"content": "系统繁忙,请稍后再试,CPU资源已被占用。","finished": True,"stop_reason": "busy_lock"}
return
try:
prompt = self._build_prompt(msg)
early_stop_cfg = self.config["early_stop"]
timeout = kwargs.get("timeout_seconds", early_stop_cfg["timeout_seconds"])
# 初始化生产者
token_queue: Queue = Queue()
streamer = ChunkingStreamer(
token_queue=token_queue,
stop_strings=self.stop_strings,
timeout_seconds=timeout,
chunk_size=15,
)而 Queue.Queue 是生产者(后台推理线程)和消费者(主生成器线程)之间的数据通道。它在线程安全的环境下缓存生成的 Subword,解耦了推理速度与消费速度。
将耗时的 self.pipe.generate(...) 放在一个独立的后台线程 run_generation 中运行。这使得主线程能够立即从队列中消费数据并 yield,避免了阻塞,实现了真正的异步流式输出。
python
...
# 初始化错误数组用于存放生成错误
generation_error = [None]
# 持续推理函数
def run_generation():
try:
# GenAI 管道推理
self.pipe.generate(prompt, gen_config, streamer)
except Exception as e:
generation_error[0] = e
logger.error(f"Generation error: {e}")
finally:
streamer.end()
# 独立线程运行
gen_thread = threading.Thread(target=run_generation, daemon=True)
gen_thread.start()
...2.2.2. 模型定制与高效停止机制
针对康养、大健康、药食同源做了严格的提示词约束。
python
SYSTEM_PROMPT_TCM = """
你是康养问答助手。
【强制规则】
1. 只用中文回答,禁止英文
2. 禁止使用任何符号:' " ` * # @ $ % ^ & ( ) [ ] { } < > / \ | ~
3. 标点只用:,。、!?
4. 回答完毕输出【EOA】后立即停止
【输出格式】
【证型】具体证型名称
【调理】分点建议
【EOA】
【举例】
问题:经常头晕乏力,脸色发白
回答:
【证型】气血两虚证
【调理】一、饮食方面,多吃红枣、桂圆、枸杞煮粥,每周炖一次乌鸡汤或猪肝汤补血
二、作息方面,晚上十一点前入睡,午休半小时
三、运动方面,每天散步二十分钟,不宜剧烈运动
【EOA】
注意:禁止输出英文单词。禁止输出特殊符号。
"""在提示词中强制要求回答结束后输出 【EOA】,并将其加入 stop_strings。模型一旦生成此标记,ChunkingStreamer 会立即切断生成,避免了不必要的 token 生成和计算浪费。
python
class OpenvinoRuntime:
...
DEFAULT_CONFIG = {
...
# 停止关键字
"stop_strings": [
"<|im_end|>",
"<|endoftext|>",
"<|im_start|>",
"\n\n\n",
"【EOA】",
"\nUser:",
"\nuser:",
"Human:",
"Assistant:",
]
}
...
class ChunkingStreamer:
...
def _stop_and_trim(self, stop_str: str, last_subword: str):
# 获取完整分段字符串
full_check_string = self.buffer + last_subword
# 字符串中查找词停关键字并获取位置
stop_pos = full_check_string.find(stop_str)
if stop_pos != -1:
# 定位到字符串词停为止并获取在此之前的全部字符串内容
content_to_send = full_check_string[:stop_pos]
if content_to_send:
# 将需要返回的字符串放入数据通道
self.token_queue.put(content_to_send)
# 更新字符缓存区和获取内容
current_buffer_len = len(self.buffer)
self.generated_text = self.generated_text[:len(self.generated_text) - current_buffer_len] + content_to_send
self.buffer = ""
# 停止继续输出
self._request_stop(f"stop_string: {stop_str}")2.2.3. ChunkingStreamer 的三重防御与平滑输出
上面已经浅浅提到了 ChunkingStreamer,其实 ChunkingStreamer 实现流式体验和数据清洗的核心模块,它同时处理了过滤、缓冲和停止。
2.2.3.1 关于 标签的过滤
在 call 方法内,通过一个 while 循环实现状态机
python
def __call__(self, subword: str) -> bool:
# 先检查是否已处于停止信号已发送状态,若是则中断输出
if self.stop_requested.is_set():
return True
# 检查输出是否超时,超时则中断输出
if time.time() - self.start_time > self.timeout_seconds:
self._flush_buffer_and_stop("timeout")
return True
# 将输出词赋值给 processed_subword
processed_subword = subword
# 状态机设置
while True:
if self.in_thought_mode:
# 寻找</think>标签
end_pos = processed_subword.find(THINK_END_TAG)
if end_pos == -1:
# 找不到返回 False
return False
else:
# 找到了就退出思考模式
self.in_thought_mode = False
processed_subword = processed_subword[end_pos + len(THINK_END_TAG):]
if not processed_subword: return False
else:
# 找<think>标签
start_pos = processed_subword.find(THINK_START_TAG)
# 若没有找到则不用找了直接跳出状态机
if start_pos == -1:
break
else:
# 找到的话就开始设值
safe_content = processed_subword[:start_pos]
if safe_content:
self.buffer += safe_content
self.generated_text += safe_content
self.token_count += 1
self.in_thought_mode = True
processed_subword = processed_subword[start_pos + len(THINK_START_TAG):]
if not processed_subword: return False
# 检查输出词是否具有词停关键字
temp_text = self.buffer + processed_subword
for stop_str in self.stop_strings:
if stop_str in temp_text:
self._stop_and_trim(stop_str, processed_subword.strip())
return True
# 经过了以上检查后,没有问题了就可以将输出词放入缓冲区
self.buffer += processed_subword
self.generated_text += processed_subword
self.token_count += 1
# 如果缓冲区内字符大于预设置
if len(self.buffer) >= self.chunk_size:
# 找到最后一个缓冲的词
split_pos = -1
for p in self.punctuation:
pos = self.buffer.rfind(p)
if pos > split_pos:
split_pos = pos
# 将所有缓存区的内容发送到数据通道
content_to_send = ""
if split_pos != -1 and len(self.buffer) - (split_pos + 1) < self.chunk_size:
content_to_send = self.buffer[:split_pos + 1]
self.buffer = self.buffer[split_pos + 1:]
else:
content_to_send = self.buffer[:self.chunk_size]
self.buffer = self.buffer[self.chunk_size:]
self.token_queue.put(content_to_send)
return False当检测到 标签时进行状态切换,并丢弃标签内所有内容,直到检测到 标签结束。这实现了对思考内容的实时、零延迟拦截。
此外,代码中还提供两层额外保障:
- 队列消费端 token.replace(THINK_END_TAG, ''),确保 标签不残留在流中。
- get_clean_texts 中使用 re.sub(r'.*?', '', text, flags=re.DOTALL),作为对最终完整输出的终极清理,捕获并移除任何意外残留的完整思考内容。
python
def get_clean_texts(self) -> str:
text = self.generated_text
# 删除残留的 <think> 标签
text = re.sub(r'<think>.*?</think>', '', text, flags=re.DOTALL)
# 删除词停关键字
for stop_str in self.stop_strings:
text = re.sub(re.escape(stop_str), '', text, flags=re.I)
text = re.sub(r'\n{3,}', '\n\n', text)
return text.strip()2.2.3.2 强制分块与语义平滑
为了更好地检测到【EOA】终止符,强制设定了每次向队列发送数据的最小字符数。即使模型输出速度很快,内容也会被强制按 15 个字符左右的批次释放。然后就能够基于这 15 个字符一次性检测是否具有【EOA】终止符,若存在则终止输出。(这个也是小模型最麻烦的地方,输出不会"刹车"。不得已才采取这种实现方案)
此外,当 buffer 达到 chunk_size 后,代码会优先在缓冲区中寻找最近的标点符号 (。, !, ?, ;, \n) 进行切分。这确保了输出的平滑性同时,尽量避免在句子中间硬性截断,提升了用户阅读体验。
2.2.3.3 停止词检测与精确切除
还记得上面展示过的 _stop_and_trim 函数吗?当检测到 stop_str(如 【EOA】)时,该方法会计算停止词的精确位置 (stop_pos)。它只将停止词之前的内容 (full_check_string:stop_pos) 发送到队列,并立即设置停止标志,确保停止词本身和其后的任何多余内容都不会进入最终输出,实现了干净的自停止。
2.2.4. 推理性能
好了,现在就可以正式测试一下推理效果了,为此我编写了一个测试代码
python
if __name__ == '__main__':
logger.info("=" * 60)
logger.info("Qwen3 0.6B OpenVINO Runtime 推理测试")
logger.info("=" * 60)
# 为了跟 Optimum Intel 套件进行完整的对比,这里用回之前的提示词
input_prompt = "中医药理论是否能解释并解决全身乏力伴随心跳过速的症状?"
# 计算 tokens 数
enc = tiktoken.get_encoding("cl100k_base")
try:
# 获取 runtime 实例
llm = OpenvinoRuntime()
logger.info(f"提示词: {input_prompt}")
logger.info("=" * 60)
full_response = ""
token_count = 0
start_time = time.time()
# 流式输出获取内容
for chunk in llm.transfor_stream_msg(input_prompt):
if not chunk["finished"]:
print(chunk["content"], end="", flush=True)
full_response += chunk["content"]
token_count += len(enc.encode(chunk["content"]))
else:
if 'full_response' in chunk:
final_text = chunk['full_response']
if not full_response:
print(final_text)
token_count += len(enc.encode(final_text))
# 记录结束时间进行耗时计算
end_time = time.time()
duration = end_time - start_time
logger.info("=" * 60)
logger.info(f"总用时: {duration:.2f} 秒")
logger.info(f"总生成 token 数: {token_count}")
if duration > 0:
logger.info(f"生成速率: {token_count/duration:.2f} token/秒")
logger.info("=" * 60)
except Exception as e:
logger.error(f"主程序运行失败: {e}")输出的结果如下:
python
...
[2025-12-02 11:53:48,828]<module> - ============================================================
[2025-12-02 11:53:48,828]<module> - Qwen3 0.6B OpenVINO Runtime 推理测试
[2025-12-02 11:53:48,828]<module> - ============================================================
[2025-12-02 11:53:49,027]_init_components - Loading model from /Users/yuanzhenhui/Documents/document_file/tmp/trained_models/20251119/OpenVINOModel/OVMS/qwen3-reasoning on CPU...
[2025-12-02 11:53:53,040]_init_components - Model loaded successfully (Mock)
[2025-12-02 11:53:53,040]_setup_generation_config - Generation config: do_sample=False, rep_penalty=1.2000000476837158, max_tokens=300
[2025-12-02 11:53:53,040]__init__ - OpenvinoRuntime initialized successfully
[2025-12-02 11:53:53,040]<module> - 提示词: 中医药理论是否能解释并解决全身乏力伴随心跳过速的症状?
[2025-12-02 11:53:53,040]<module> - ============================================================
从整体来看,全身性疲劳与心率加快在中医学上可以归结为"气虚血弱"或"阳气不足"的表现。这通常需要通过调整身体内环境来恢复平衡。推荐使用如黄芪、当归等补气养血药物进行治疗,并结合饮食调养(例如多食用含铁质的食物)以及适当运动以增强体质。同时,在专业医生指导下进行个性化管理及监测,确保安全有效。请勿自行用药。[注] 中医强调个体差异性和复杂系统作用机制,请具体诊断需由有经验的专业医疗人员完成。[2025-12-02 11:53:59,713]<module> - ============================================================
[2025-12-02 11:53:59,713]<module> - 总用时: 6.67 秒
[2025-12-02 11:53:59,713]<module> - 总生成 token 数: 228
[2025-12-02 11:53:59,714]<module> - 生成速率: 34.17 token/秒
[2025-12-02 11:53:59,714]<module> - ============================================================与之前的 Optimum Intel 方案和 Llama.cpp 方案相比,GenAI 在性能上有明显的提升。本机 2 GHz 四核Intel Core i5 CPU 能有 34.17 token/秒是之前未曾尝试过的。若迁移到生产的 Linux 服务器稍微再调优一下应该能够满足一般前置推理要求。
3.问答验证
既然已经完成了基于 CPU 的推理部署工作了,接下来时候验证推理的准确性了。
虽然 Unsloth 训练时用 1% 的数据进行验证,但这毕竟是基于数学层面的验证。在中文的语义语法上、表达上是否清晰、不含歧义...这只能够实际模拟一下才知道。但我并不是行业专家无法就推理结果进行判断,这个时候就需要商用大模型帮我完成这个判断、评估、打分的工作了。
3.1 生成问题
有看过我博客的小伙伴又知道了,我之前曾经使用过 RAGChecker 为之前公司的推理应用做过评估。这次的验证也可以参考 RAGChecker 的处理流程,只不过为了"零投入",使用"人工收集 + Python 数据处理脚本 + 多次分批处理 + 商用大模型"的模式进行处理:
Step1 用商用大模型生成一定数量的问题(这次我就生成 5000 条不同类型的问题吧)
Step2 使用需要评估的模型对这些问题进行作答,答案需要记录起来与问题一一对应
Step3 将问题和答案都导出到 Excel 中,使用多个商用大模型对同一份 Excel 进行评分
Step4 将所有评分记录重新导入数据库并采用平均分的方式获取最终评分
听上去好像没有什么毛病。好,那就立刻开干。
先导出常用的 183 种中药材名称并编写提示词让 Qwen3-MAX 帮我生成 5000 条不同的问题先。
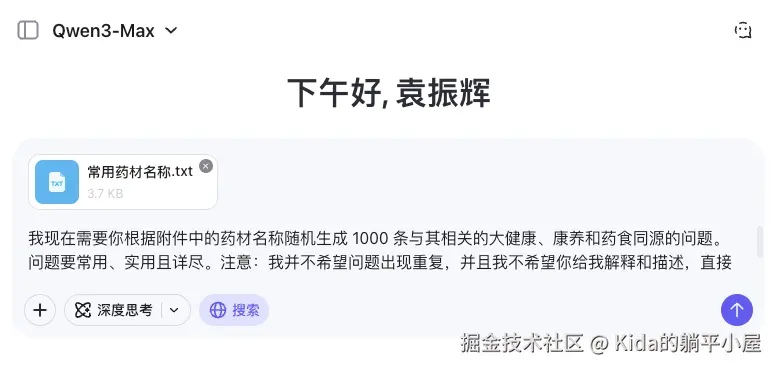
为了保证问题的质量,这里加上联网搜索让生成出来的问题更加完整。此外,为了提高响应速度最终按每次 1000 条记录分批生成。
3.2 生成答案
将 5000 条问题导入到 SQLite 后进行数据清洗,排重后 5000 条数据剩下 3370 条。
python
def insert_all_validate_data_to_sqlite(self):
# 遍历目录下的所有 txt 文件
for i in os.listdir(self.dataset_path):
if 'txt' not in i:
continue
new_path = self.dataset_path + i
with open(new_path, "r", encoding="utf-8") as f:
try:
loop_index = 0
# 打开文件遍历每一行,将其全部插入到 SQLite 中
for idx,line in enumerate(f):
loop_index = idx
question = line.split(". ")[1]
data = {"question":question.strip()}
self.sql.insert("check_dataset_qa",data)
except:
logger.info(f"error insert index: {loop_index}")
logger.info(f"{i} inserted completed...")
def clean_dulplicate_data(self):
# 分组查询获取重复问题的最大 id 值
sql = "select question,max(id) id from check_dataset_qa group by question having count(1) > 1"
results = self.sql.fetch_all(sql)
while len(results) > 0:
# 删除重复数据
ids = [result[1] for result in results]
ids_str = ','.join(map(str, ids))
del_sql = f"delete from check_dataset_qa where id in ({ids_str})"
self.sql.execute(del_sql)
results = self.sql.fetch_all(sql)
logger.info(f"delete dulpicate data completed...")遍历 3370 条记录并将"问题"提交给 0.6B 进行回答推理
python
def generate_answers(self):
# 初始化 openvino 对象
ort = OpenvinoRuntime()
sql = "SELECT id,question FROM check_dataset_qa WHERE answer IS NULL LIMIT 10"
results = self.sql.fetch_all(sql)
batch_count = 0
while len(results) > 0:
# 分批次遍历获取问题和对应的 id 值
for id,question in results:
answer = ""
# 推理流式返回,将所有回答收集起来
for chunk in ort.transfor_stream_msg(question):
if not chunk["finished"]:
answer += chunk["content"]
else:
if 'full_response' in chunk:
final_text = chunk['full_response']
if not answer:
answer += final_text
# 最后根据 id 进行回答字段的更新
update_sql = f"UPDATE check_dataset_qa SET answer = '{answer}' WHERE id = {id}"
self.sql.execute(update_sql)
logger.info(f"Update id: {id} completed...")
results = self.sql.fetch_all(sql)
batch_count += 1
logger.info(f"Generate batch {batch_count} answers completed...")3.3 导出 CSV 并用大模型评分(Qwen3-MAX、DeepSeek 和 KIMI 2)
已回答的记录分批导出成 CSV 文件并提交给商用大模型进行评分,以下以 DeepSeek 界面为例:
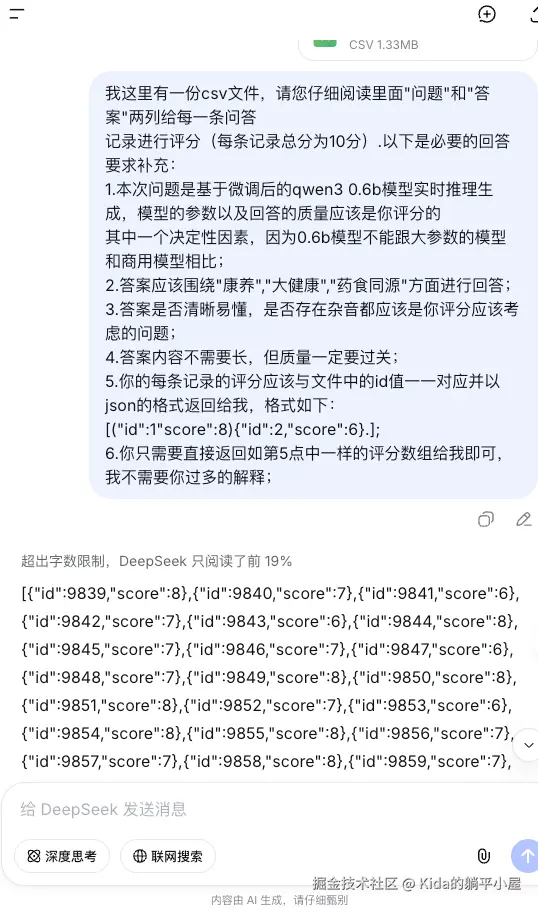
如上图所示,提示词中让商用大模型直接返回 id 和评分的 JSON 数据,这样就方便我们进行数据库字段更新了。(这里因为要做到零成本所以没有调用 API 接口,而是通过文档导入导出的方式,在 Web 端获取结果)
将 Web 端返回的结果制作成 json 文件,并导入到 SQLite
python
def load_json_and_update_sqlite(self):
for i in os.listdir(self.score_path):
new_path = self.score_path + i
type = i.split(".")[0]
json_data = CommonUtil.load_json_file(new_path)
for json_obj in json_data:
id = json_obj['id']
score = json_obj['score']
update_sql = f"update check_dataset_qa set {type}_score = {score} where id = {id}"
self.sql.execute(update_sql)
logger.info(f"Update id: {id} completed...")
logger.info(f"{type} inserted completed...")3.4 汇总评分(全 SQL 操作)
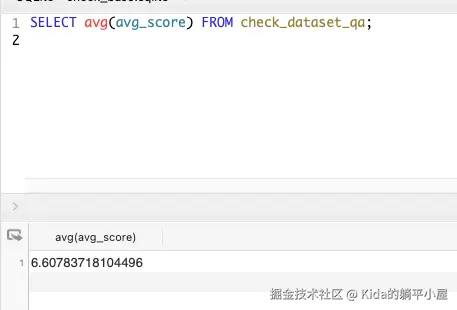
待全部分数导入完毕后,就可以计算每条记录的大模型平均分了,有了每条记录的平均分就可以计算整体回答质量的平均分。如下图所示:

最终,整个模型评分为 6.607。
整体质量在合格线之上,评分等级数据统计如下:
| 平均分 | 占比 |
|---|---|
| <6 | 2.67% |
| >=6 and <7 | 36.87% |
| >=7 and <8 | 57.32% |
| >=8 and <9 | 3.12% |
| >=9 | 0% |
通过表格可知,推理返回结果基本能贴题但不够全面,侧面说明训练数据"面"还不够广。并且经抽查发现推理结果含有大量"杂音",这说明还需要在训练精度和提示词上下点功夫才行。
总的来说就是资源(数据、硬件、时间等)还不够,就当前结果而言个人觉得已经在能力范围内做到最好了。
直到模型使用 CPU 方案落地的那一刻为止目前还没有用过一分钱(严格坚守自己的原则),后续只要继续优化调整即可。
坦白说,虽然最终未能实现思考链推理有点遗憾,但性能和质量的确是上来了(相比上一年的 Qwen1.5 版本)。每次跨越一小步就可以了,毕竟个人力量怎能与企业集团相比呢。
如果没有办法做多轮精准应答,那么可以改变策略,做边缘推理也行。就像我上面说的那样,可以考虑将这个模型放入 APP 里面。用户可以在本地算力下做一些简短的推理,之后再根据业务需求决定是否发送到云端进行深层推理。那这就能做很多东西了...
好了,以上就是本章分享的全部内容了,代码均发布到 brain-mix 项目中,欢迎各位的指导。
gitee:gitee.com/yzh0623/bra...
github:github.com/yzh0623/bra...
(未完待续...)