文章目录
很高兴和大家见面,给生活加点impetus!!开启今天的编程之路
作者:٩( 'ω' )و260
我的专栏:Linux,C++进阶,C++初阶,数据结构初阶,题海探骊,c语言
欢迎点赞,关注!!

linux -- 进程间通信
前置细节
进程间通信,为什么有?
我们在学习进程的时候,知道进程是具有独立性的,但是有时进程间需要协同工作,如一个进程完成数据下载之后,另一个进程才能够访问,如一个进程完成数据上传之后,另一个进程需要更新等等,都是进程的协同工作。
那么进程通信是如何做的呢?进程想要通信,那么就必须能够看到并能够使用同一份资源,类似打电话时两个人都能够使用一份手机资源。
所以:想让进程间通信,我们必须破坏进程间独立性,使进程看到同一份资源,下面的进程间通信的方式目的都是让进程看到同一份资源。
而通信方式有很多,大致分为
1:单工通信:一方读,一方写,类似上课,一方一直写,一方一直读
2:半双工通信:两方都能够读写,但都不是同时的,类似交谈
3:全双工通信:双方同时读写,类似吵架
匿名管道
linux诞生之初,并没有通信机制,当需要进程间通信时,第一肯定是想复用之前的代码。
在我们学习文件系统时,struct file结构体中会有一个内核级缓冲区。向文件读写内容其实是向内核级缓冲区中读写数据。如果说一个进程向一个文件中写内容,数据会被写到内核级缓冲区,如果说另一个进程查看该内容,那么就可以看到其他进程写的数据。那么进程之间就能够进行数据交换了。即能够进行通信了。

即我们可以复用文件系统的代码来完成看到同一份共享资源。
在这个过程中有IO操作,即与外设进行操作了,想一想,这个过程有没有必要?
其实是没有必要的,因为会降低效率,直接将数据放到内核级缓冲区中,等待被另一个进程访问即可。
内核级缓冲区不就是在物理内存中的一个内存块吗?所以,我们可以直接使用一个内存块来完成通信,即匿名管道。
为什么是匿名的?因为这个文件不会从磁盘中打开文件,也就不存在路径和文件名。
那我们该如何设计一个匿名管道呢?
函数:
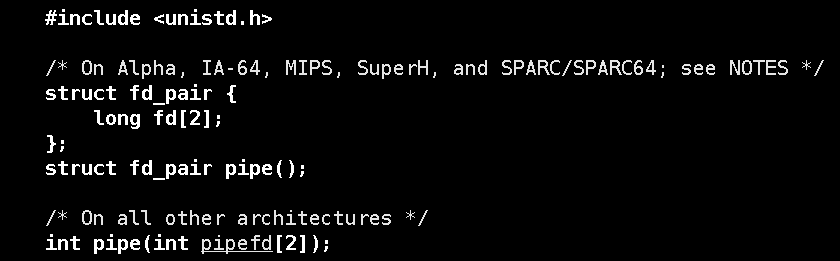
pipe需要传递一个数组,数组中0号下标表示对匿名管道的读,1号下标表示对匿名管道写。但是匿名管道是单工通信,只能有一方读,一方写。所以设计一个匿名管道的思路:
1:pipe函数创建匿名管道
2:fork子进程
3:一方关闭读,一方关闭写(这里让子进程写,父进程读)
4:子进程写数据,父进程读数据
问题:父子进程不是会使用父进程属性初始化子进程数据吗?那么父子进程不是可以看到同一份资源吗?(如代码,虚拟地址空间等等),这不就已经是通信了吗?
父子进程对数据修改会产生写时拷贝,之后又会导致父子进程无法看到同一份资源
直接来看代码实现:
此时父子进程就能够进行通信了。
我们发现,使用匿名管道方式时,我们需要fork子进程,为什么需要fork子进程,为什么需要先创建命名管道,在fork子进程?
就是通过子进程代码和数据是由父进程数据初始化的,所以子进程也能对这个管道读写。
此时虽然发生了写时拷贝,但是可以通过文件描述符对该匿名管道进行访问!!
子进程拷贝父进程数据时,该匿名管道的struct file需要完全拷贝的,但是内核级缓冲区不需要拷贝两份,即浅拷贝。
为什么不拷贝内核级缓冲区?1:否则父子进程无法同时读到同一块资源,无法进程进程间通信2:原本内核级缓冲区存储磁盘文件内容,OS只会让磁盘文件加载一次
我们看待匿名管道时,看成是一个文件即可,只不过该文件内容不会刷新到磁盘中。出口是一个文件。
五大特性 + 四种情况
五大特性
1:匿名管道只能是单工通信。
2:匿名管道只能够适用于具有血缘关系的进程之间进行通信,因为需要fork使血缘进程看到同一个struct file。即匿名管道需要使用到文件和fork继承特性
3:管道是面向字节流的
字节:指我们向管道中写内容时,是不关心向文件中写了什么,只关心向管道中读写的字节大小。
这点在write,read函数中就可以发现:

此时写入的数据都是void*的,说明对写入数据的类型是不关心的。
流:描述读与写的次数不成正比的情况,即通信可能子进程写了很多次,但是父进程只读了一次。
如在文件中,可能用户级缓冲区向语言级缓冲区写了很多次,语言级缓冲区才刷新到内核级缓冲区中,即文件流!!
4:管道的生命周期随进程
很好理解,当进程结束时,进程内部的数据结构都会被销毁,这其中就包含匿名管道
所以当进程结束,即使管道不关闭,也不会造成内存泄漏,进程结束,OS会自动关闭打开的文件并销毁数据结构。
在学习struct innode时,其中有引用计数,在这里就能够统计该文件的innode被多少个内核对象引用,当引用计数为0时,struct innode才会被销毁。具体后面讲
5:管道通信,多于多进程而言,是自带互斥和同步机制的。这里我们讲解一下概念就行。
同步:多进程访问一个资源时,具有一定的顺序性。
互斥:访问一个资源时,只能有一个进程访问。
如果多进程同时访问一个资源时,肯定会出问题的,因为如果同时访问一个资源时,如果一个正在写,一个正在读,就会导致读取到的数据不全。
这个概念主要在多线程位置的时候详细讲解。
四种情况:
主要是:
1:写端写得慢,读端读得快
2:写端写的快,读端短的慢
3:写端直接关闭,读端仍在读
4:写端正在写,读端直接关闭
对应这四种情况时,管道会发生什么情况呢?
直接使用代码来验证:
我们验证基本都是使用这一个代码,写得快写的慢,读的快,读的慢修改sleep和直接close即可
cpp
#include <iostream>
#include <unistd.h>
#include <string.h>
#include <sys/types.h>
#include <sys/wait.h>
int main()
{
int pipefd[2] = {0};
int p = pipe(pipefd);
if (p < 0)
{
perror("pipe");
exit(1);
}
pid_t pid = fork();
if (pid == 0) // 子进程--写
{
close(pipefd[0]);
char buffer[128];
const char *str = "hello";
//int cnt = 0;
while (1)
{
ssize_t n = write(pipefd[1], str, strlen(str));
//sleep(10);//写端写的慢
// if(cnt == 3)
// {
// close(pipefd[1]);//写端直接被关闭
// }
// cnt++;
sleep(1);
}
printf("子进程退出\n");
exit(2);
}
// 父进程 --读
close(pipefd[1]);
char buffer[128];
int cnt = 0;
while (1)
{
ssize_t n = read(pipefd[0], buffer, sizeof(buffer) - 1); // 预留空间放置\0
if(n == 0)
{
printf("读到文件结尾了\n");
sleep(1);
continue;
}
if(cnt == 3)
{
close(pipefd[0]);//读端被关闭
sleep(1);
break;
}
cnt++;
printf("%s\n", buffer);
//sleep(10);读端读的慢
}
int status = 0;
int n = waitpid(-1,&status,0);
printf("退出码:%d\n, 退出信号:%d\n", (status >> 8) & 0xFF, (status) & 0x7F);
sleep(10);
return 0;
}1:写端写的慢,读端读的快

此时我们读端被阻塞住了,为什么写端也是阻塞的呢?因为sleep函数会与外设进行交互,所以显示的是写端也被阻塞了。
现象很明显,当读端读得快,也要等数据写到管道之后再来读。即读端要等写端写
2:写端写得快,读端读的慢
直接修改sleep的时间大小即可。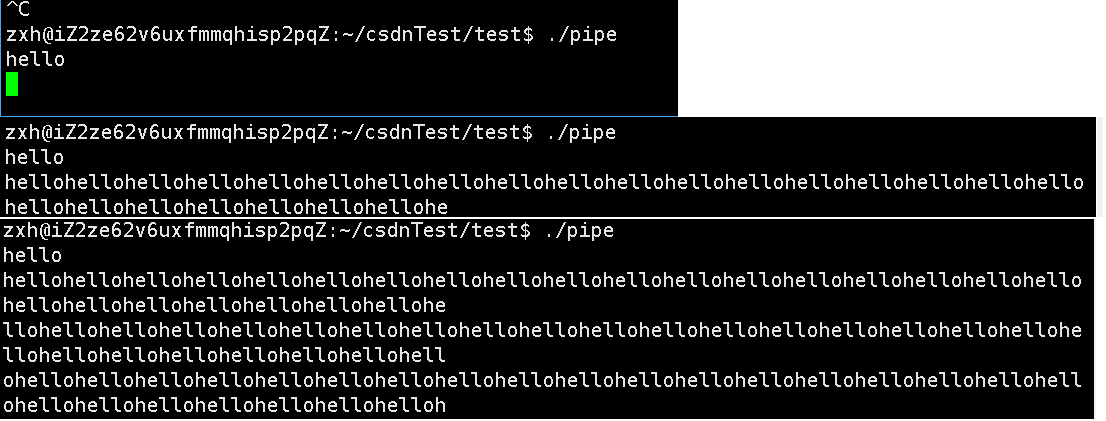
即写端写得快,读端读的慢,写端就要被阻塞,等着读端来读,读端读了之后,写端才能够继续写
3:写端被关闭,但是读端还在读。
首先read的返回值是一个ssize_t类型,其实就是一个整形,表示读到的字节数,当读到的字节数为0时,表示已经读到了文件结尾。
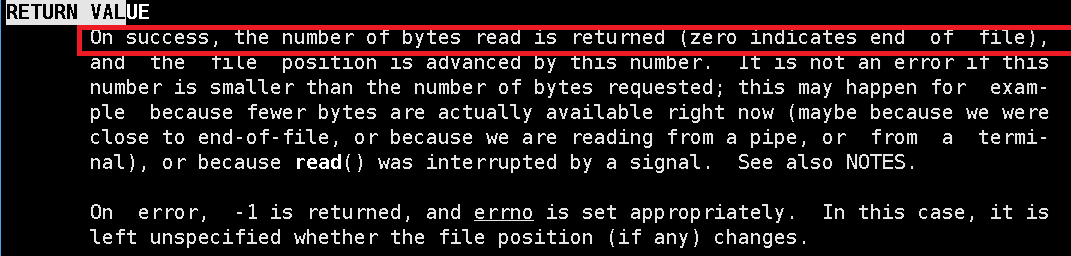
直接来看现象:
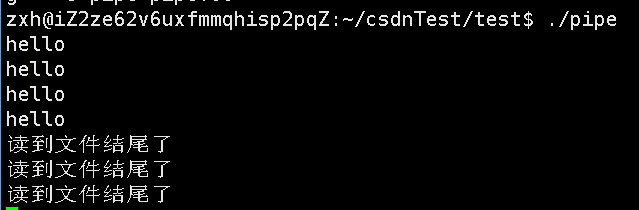
大约三秒之后,会读到文件结尾,因为三秒之后,我将文件写端关闭了,管道中是肯定不可能再有内容输入的,等价于读完了。所以,我们可以利用这个特性来判断是否需要关闭读端。
4:写端不关闭,读端关闭。
直接来看现象:
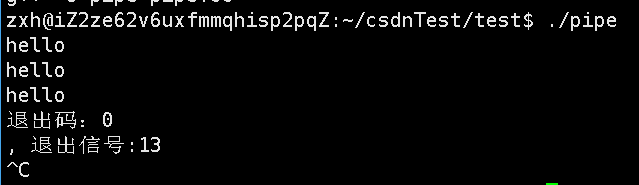
我们能够发现子进程直接退出了,为什么子进程会直接退出呢?
因为父进程读端关闭,意味着不可能读取数据,意味着也不可能再对数据进行进一步处理,但是现在子进程还在写数据,OS不会干没有意义的事情,所以就需要将子进程关闭,如何关闭,使用信号,此时退出码就没有任何意义了。
在这四种现象中,就能够解释同步,即资源访问具有顺序性,要么写端快,写端就会被阻塞,要么读端快,读端就会被阻塞。父子进程访问匿名管道时具有一定顺序性。
进程池
接下来我们可以利用匿名管道的五大特性,四种现象来编码一个进程池代码。
思想:池化技术
什么是池?在以前我们一定接触过这个概念,如学习stl时,学习到的内存池,为什么有内存池,目的是为了提高效率,malloc时开辟一大块空间,需要空间的时候就直接去这一大块空间去拿,不用再去malloc空间了,malloc本质是系统调用brk,而系统调用是有一定成本的。
进程池也类似,我们一次性创建多个进程,当我们有任务时,发配任务给进程完成,此时就不用再来创建进程了。当我们没有任务时,进程就会被阻塞住,等待写端写数据。

步骤:初始化进程池->运行进程池->退出并回收资源
1:初始化进程池:创建进程,创建管道。
我们先来设计类。
进程池中包含一个一个管道,所以我们肯定需要一个channel类,描述管道,ProcessPool描述进程池,管道是进程池的内部类,使用一个数组来组织所有的channel即可。
在channel类中,我们需要标记这个管道的_wfd(文件描述符), _sub_pid(这个管道对应子哪个进程)
随后进行初始化操作。
和我们对管道的现象验证代码是雷同的。
即先创建管道->fork子进程->子进程关闭写,父进程关闭读。
其中有一个细节:在标准代码中为什么需要将先前已经有的fd给删除掉,保证一个管道只有一个进程指向,为什么造成呢?还是因为fork特性!!,
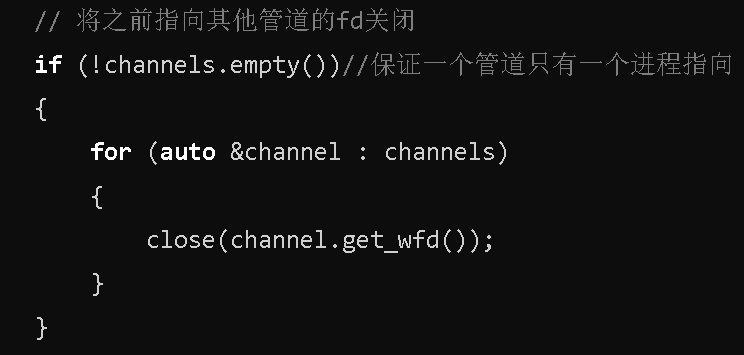
我们来画图解释一下:
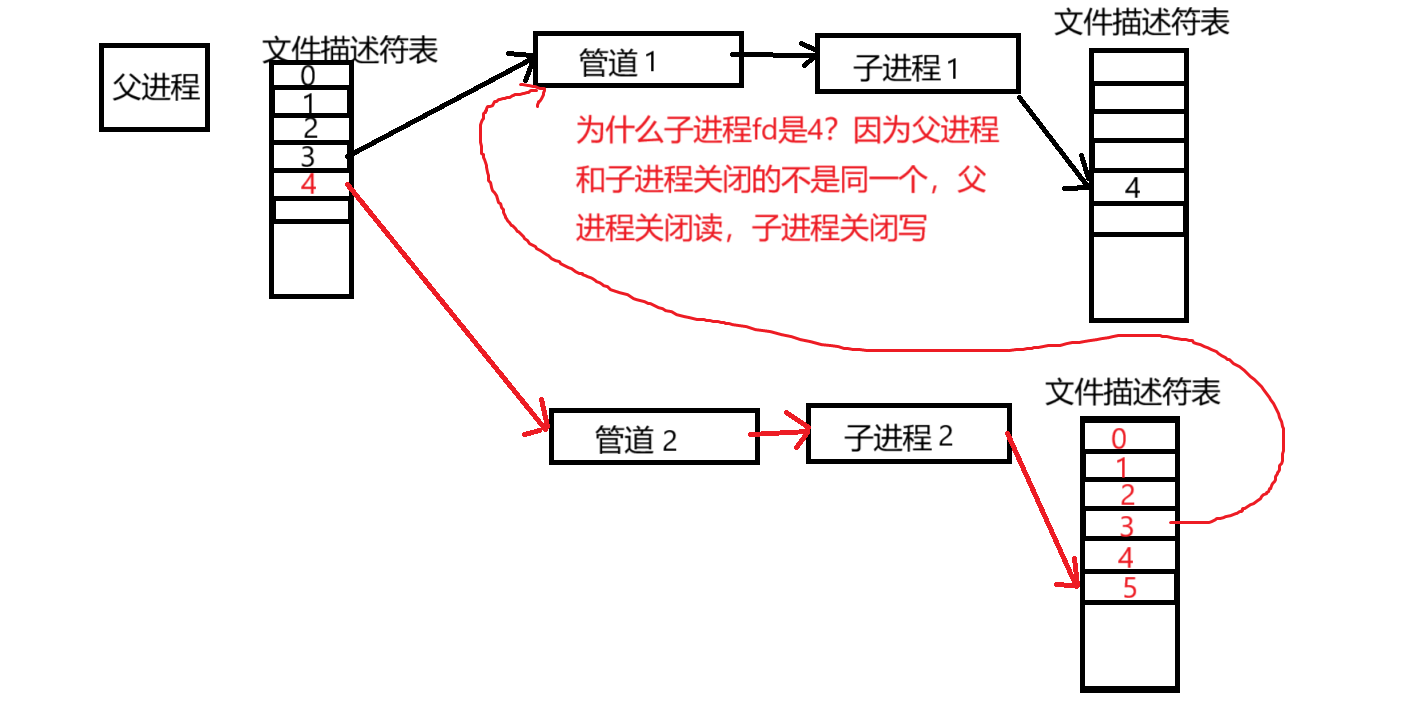
为什么子进程2中fd为3的位置还指向子进程1的管道呢?
fork使父进程数据拷贝给子进程2,此时子进程2的fd表一定有3,而3是指向子进程1的管道,所以需要将子进程2的fd为3的位置给关闭掉,换句话说,只要channel数组里不为空,就需要将之前的channel中对应的子进程的fd表关闭一些内容。
即需要关闭子进程2中的fd为3的位置。
如果我们不关闭会发生什么情况呢?
不关闭,当我们关闭管道1写端,由于子进程2,3,4...n还有指针指向管道1,就会导致子进程不会读到文件结尾,自然也就不会退出了。
还有一个细节:因为子进程就是一直向管道中读取数据就行,而且所有子进程都是相同行为。我是直接实现了一个回调函数让所有子进程调用相同的函数。
2:运行进程池:写端写数据,读端根据拿到的数据完成任务
完成任务,我们需要先设置一个任务表。这里我直接使用的数组实现的,当然也可以使用类来实现,并实现selectTest等函数,这里就不搞这么麻烦了。
完成任务清单的初始化后,就应该像管道中写数据,那么向哪个管道中写数据呢?
所以我们需要选择selectChannel算法表示选择哪一个管道,因为我们拿了管道,就拿到了Channel,就拿到了_wfd。
再设计一个selectTask算法表示选择哪一个任务。
随后向 _wfd中write内容即可,写的其实是下标,子进程拿到下标直接去Task_list任务清单中执行对应任务即可。
3:退出并回收资源:关闭管道的所有写端,读端自动关闭+回收子进程
首先我们waitpid回收子进程,这是肯定需要的,可以直接对ChannelList数组进行遍历,直接关闭对应的_wfd即可。
那如果我们就按照上面的写法,子进程2有fd指向子进程1的管道1,那么我们能不能正常关闭呢?
其实也是可以的,既然越到后面指向子进程1的管道1的fd就越多,但是最后一个进程n的管道n只有一个进程n指向,我们就可以反着来遍历ChannelList来关闭写端。
当进程n回收之后,fd也会被销毁,此时管道n - 1就只有一个进程n - 1指向,这样就可以将进程n - 1给回收掉了,以此类推,直到进程1。
代码已放入到我的码云中,具体可以参考。
进程池代码汇总
命名管道
我们先前学习过匿名管道想要进程间通信,必须利用fork特性 + 文件特性,这就要求能够进行匿名管道通信的进程都是具有血缘的。
但是进程间通信的所有场景中,肯定包含不含血缘关系的进程间的通信。那么该怎么办呢?
此时我们就需要一个文件了,而且是命名文件,即有路径,有文件名。你之前不是说过文件会将内容刷新到磁盘吗,但是这样通信进行IO效率太低了,所以这种文件OS不允许将内容刷新到磁盘中,即管道文件,是以p开头的。
创建管道文件的指令:mkfifo 选项 文件名
为什么命名管道可以使用到没有血缘关系的进程之间的通信,因为在在文件系统中,进程可以通过文件路径 + 文件名的方式访问文件。而路径 + 文件名之后具有唯一性,所以就能够保证进程可以看到同一份资源,即具有了通信的标准。
即底层原理:在磁盘上真实存在的文件,有路径有名称,有唯一innode,任何进程都可以访问这个文件,同时利用OS不会将同一个文件重复加载到内存中,存在多个进程使用一个磁盘文件--如显示器文件
所以命名管道与匿名管道的区别:匿名管道无文件名,无路径,无innode,无dentry,也很好理解,路径都没有,也自然不会进行路径缓存,也自然不会进行dentry树的构造。
命名管道的特点:
1:命名管道的大小为0,通常作为占用符来使用,为什么呢?因为数据不会刷新到磁盘上,所以也就不需要数据块,即文件名和路径在磁盘上也是作为占位符而存在的。
2:这里先引出这个结论,在下面会使用到这个。
open打开管道文件阻塞问题:open打开管道文件阻塞问题 -- open普通文件就是打开或者没打开并返回fd结果,管道文件要求读写同时打开时代码才能继续向后走(反之被阻塞)。
为什么匿名管道不存在这个问题?因为匿名管道pipe时默认就打开了度写端。
接下来我们写一个客户端与服务端交互的代码:
我们实现Server.cc(服务端)和Client.cc(客户端)和NamedPipe.cc(命名管道)三个源文件。
在NamedPipe.cc中,包含命名管道的创建,命名管道的获取(客户端以写打开,服务端以读打开),命名管道的删除。
而Server.cc和Client.cc前者接收数据,后者发送数据。
命名管道创建:
1:判断管道文件是否已经存在了,不存在才创建,否则return
2:直接调用mkfifo系统调用创建命名管道
命名管道获取:
因为打开命名管道需要两种方式打开,我们直接写一个函数,传递一个flag变量表示该如何对命名管道操作即可。
其实本质上调用的还是open函数
命名管道的删除:
管道存在的话,就直接unlink解除文件名和innode之间的映射关系即可。因为当innode与文件名的映射关系为0时,即引用计数为0,该文件内核数据结构就会被释放。类似软链接中的unlink嘛。
我们来演示一下现象:
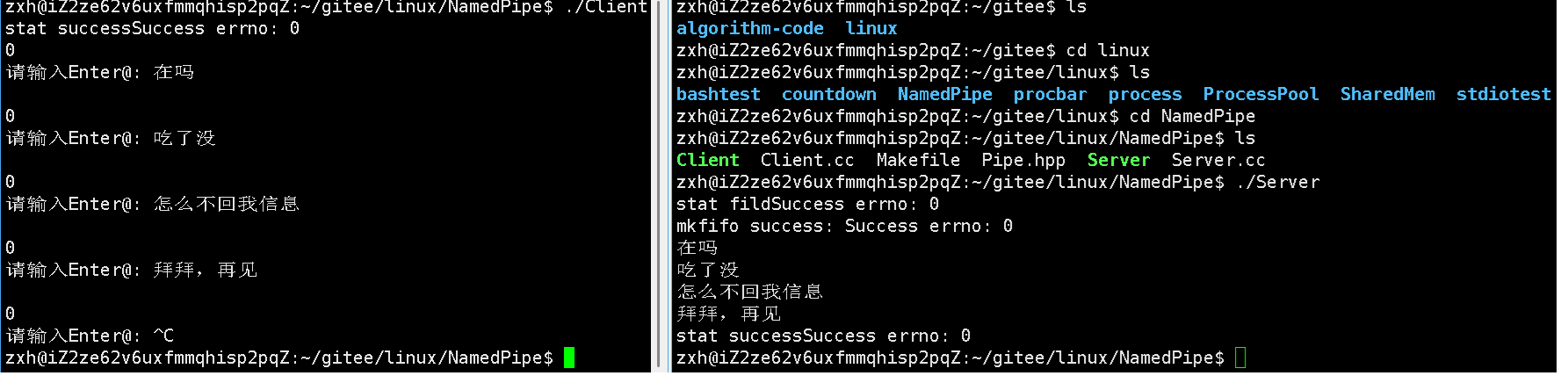
注意一定需要先启动服务端,因为服务端详客户端提供服务,肯定服务端要先运行起来啊
完整代码在我的gitee中:
命名管道