
文章链接:https://arxiv.org/abs/2511.23475
开源链接:https://github.com/HKUST-C4G/AnyTalker
项目链接:https://hkust-c4g.github.io/AnyTalker-homepage
亮点直击
可扩展的多人驱动结构:本文提出了一种可扩展的多流处理结构 Audio-Face Cross Attention Layer,能够以循环调用的方式驱动任意数量的角色,并确保各个角色之间自然的互动。
低成本多人说话模式训练方法:提出了一种新颖的两阶段训练流程,使模型先利用水平拼接的单人数据学习多人说话模式,再通过多人数据精调,以优化生成视频人物之间的互动性。
首个交互性评价新指标:首次提出用于量化评估多人物交互性的全新度量指标,并构建配套的基准数据集以进行系统评估。
总结速览
解决的问题
-
可扩展性:部分方法在训练阶段即为同一视频中的人物分配固定标记或路由顺序,因而难以突破"双人"的限制,生成超越两个身份的自然交互视频。
-
高训练成本:现有方法普遍依赖成本高昂的多人场景数据集开展训练;而多人场景因涵盖话轮转换、角色更替以及目光注视等非言语的复杂因素,导致数据采集与标注成本高。
-
缺乏交互性的定量评估方法:多人视频作为较新的领域,既往用于单人口型同步或视频质量的指标,难以充分衡量多人场景下的多个角色之间互动自然度。
提出的方案/应用的技术:
-
构建可扩展的多流处理结构:为每对音频与身份量身定制的交叉注意力模块。将每对脸部 clip 图像特征与Wav2Vec2 音频特征在 sequence维度拼接,共同作为 K/V;计算后的注意力结果按展开成sequence的 face mask token进行局部激活,仅修改对应脸部区域。该运算可每个"角色-音频"对循环执行,以支持任意人数。
-
提出低成本多人对话学习策略:一阶段训练时,仅使用单人数据,以 50% 概率将两条单人视频水平拼接成"双人对话"伪样本,充分利用海量单人数据,让模型快速习得多人说话范式。二阶段利用少量的的真实多人数据优化互动性。
-
首创交互性量化指标:在沉默时段追踪倾听者眼部关键点位移幅度,以此衡量生成视频的交互强度,实现多人互动效果的客观评估。
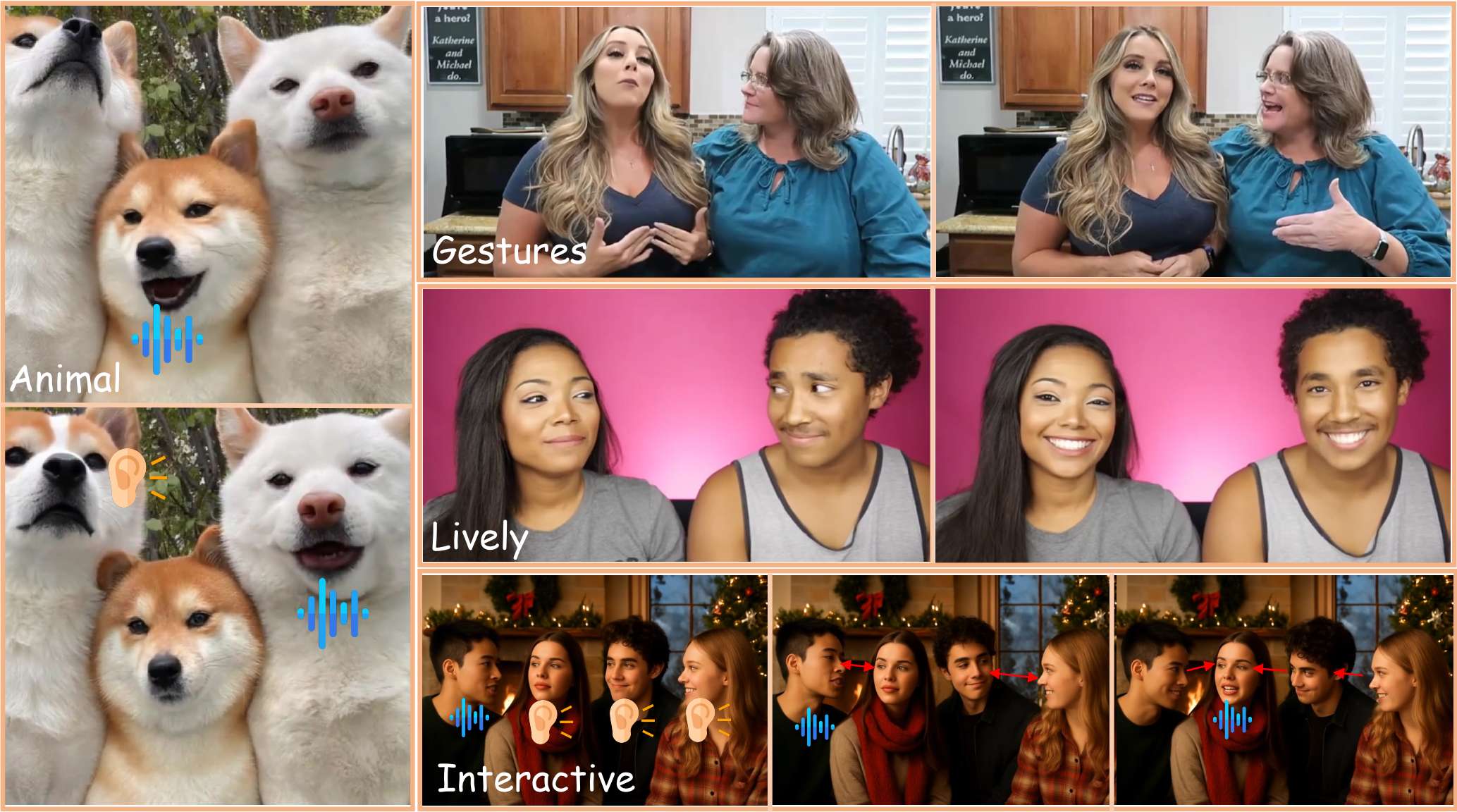
图 1:AnyTalker是一个强大的音频驱动多人视频生成框架,它可以生成富含手势、生动情感和交互性的视频,并且可以自由地推广到任数量的ID甚至非真人输入。
达到的效果:
-
突破可驱动人数的限制:无论输入的是单段独白还是多人对话,AnyTalker 都能自适应匹配音频与角色数量,一键生成自然流畅的多人说话视频。
-
交互真实细腻:生成视频中人物对视,挑眉、点头等非语言动作自然流畅,面部表情随语音节奏精准呼应,呈现高度逼真的多人互动场景,并在新提出的互动性 Benchmark 上表现远超过去所有方法。
-
准确的口型同步:在 HDTF、VFHQ 两大单说话人视频 Benchmark上,AnyTalker 的 Sync-C 指标领先;于本文新建的多人数据集,同样保持优势。
方法
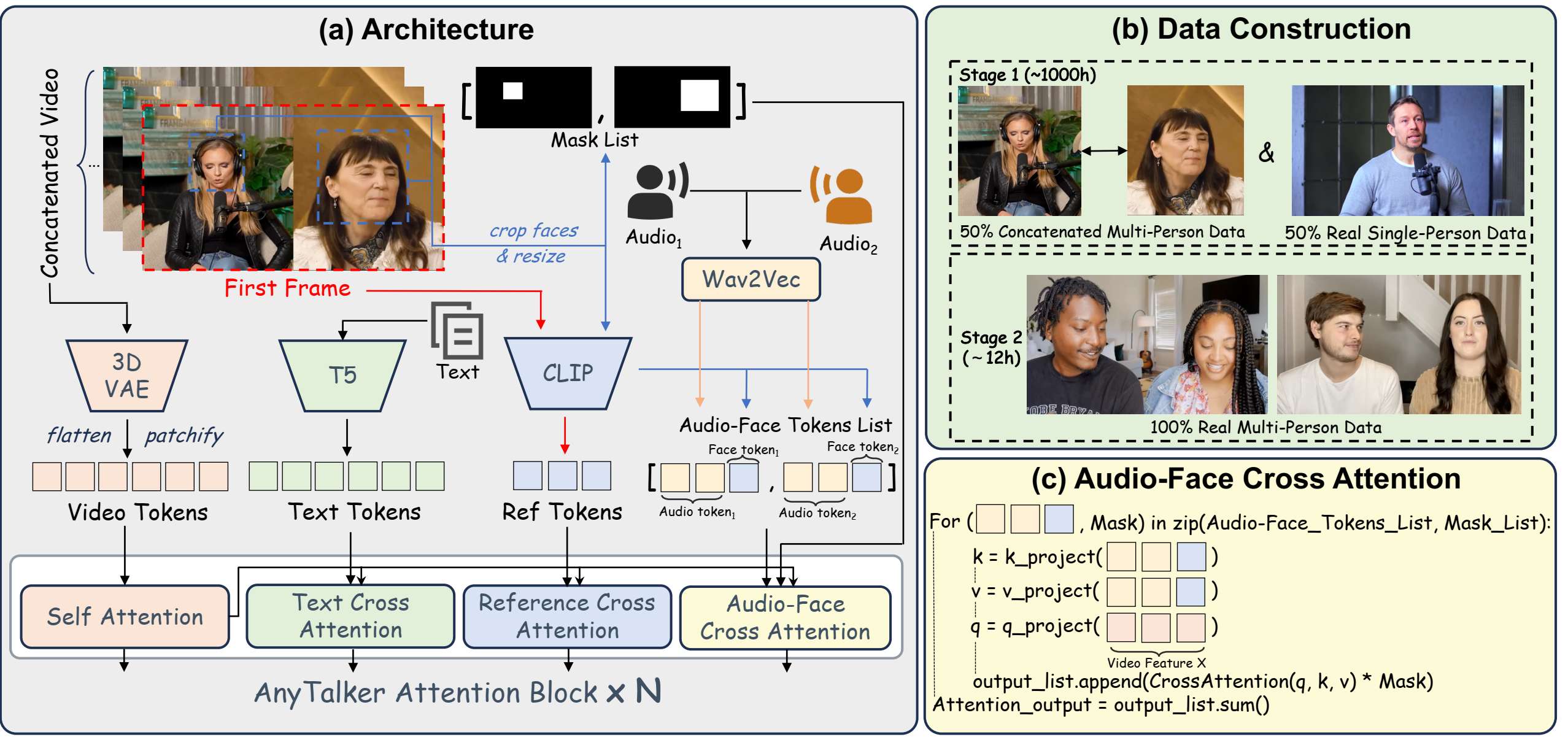
图2:(a)AnyTalker的架构采用了一种新颖的多流音频处理层Audio-Face Cross Attention Layer,能够处理多个面部和音频输入。(b)AnyTalker的训练分为两个阶段:第一阶段使用由单人数据和其混合而成的级联多人数据来学习嘴唇动作;第二阶段采用真实的多人数据来增强生成视频中的交互性。(c)音频人脸交叉注意的详细实现,这是一种可循环调用的结构,使用人脸掩码对输出应用掩码。
总览
本文提出的 AnyTalker 整体框架如上图所示。AnyTalker 继承了 Wan I2V 模型的部分架构组件。为了处理多音频和身份输入,引入了一种专门的多流处理结构,称为 Audio-Face Cross Attention(AFCA),并把整体的训练流程分为两个阶段。
作为一个基于 DiT 的模型,AnyTalker 通过 patchify 和 flatten 操作将3D VAE特征 转换为 token,而文本特征 则由 T5 编码器生成。此外,AnyTalker 继承了 Reference Attention Layer,这是一种交叉注意力机制,利用 CLIP 图像编码器 从视频的第一帧提取特征 。Wav2Vec2也被用于提取音频特征 。整体输入特征 可表示为:
Audio-Face Cross Attention
为了实现多人对话,模型必须能够处理多路音频输入。潜在的解决方案可能包括 MultiTalk 中使用的 L-RoPE 技术,该技术为不同的音频特征分配唯一的标签和偏置。然而,这些标签的范围需要显式定义,限制了其可扩展性。因此,我们设计了一种更具可扩展性的结构,以可扩展的方式驱动多个身份并实现精确控制。
如图2(a)和(c)所示,我们引入了一种名为 Audio-Face Cross Attention(AFCA)的专用结构,该结构可以根据输入的 face-audio 对数量循环执行多次。如图2(c)和公式(4)所示,它能够灵活处理的多个不同的音频和身份输入,每次迭代的输出相加得到最终的注意力输出。
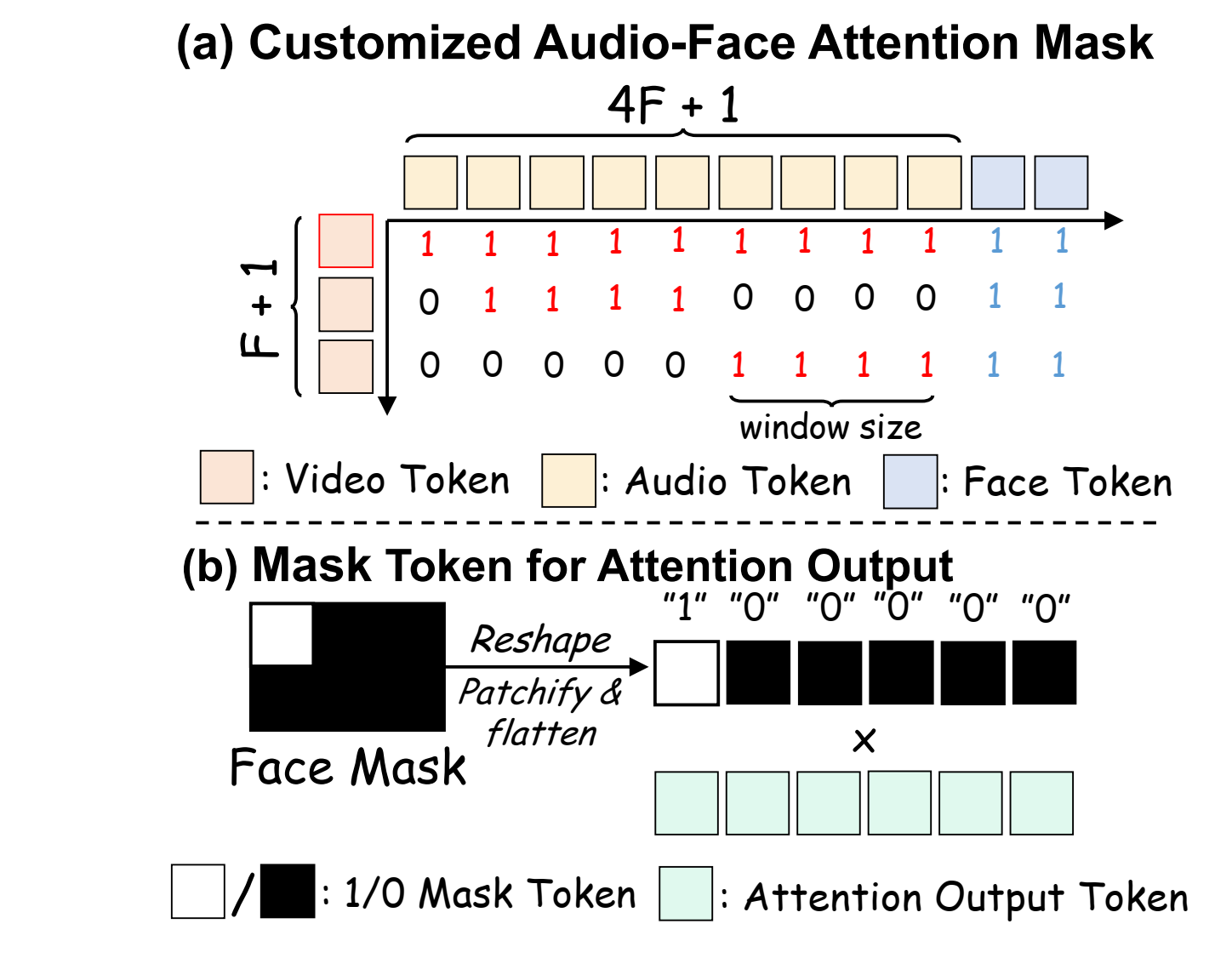
图3:(a)通过定制的注意力mask建议视频token到映射音频token 的映射。每4个音频 token绑定到1个视频 token,第一个 token除外。(b)用于Audio-Face Cross Attention中输出mask的token。
音频 token 建模。我们使用 Wav2Vec2 对音频特征进行编码。第一个潜在帧关注所有音频 token,而每个后续潜在帧仅关注对应于四个音频 token 的局部时间窗口。视频和音频流之间的结构化对齐通过施加时间注意力掩码 实现,如图3(a)所示。此外,为了实现全面的信息整合,每个音频 token 在 AFCA 计算中与由 编码的人脸 token 拼接。这种拼接使得所有视频查询 token 能够有效关注不同的音频和人脸信息对,计算如下:
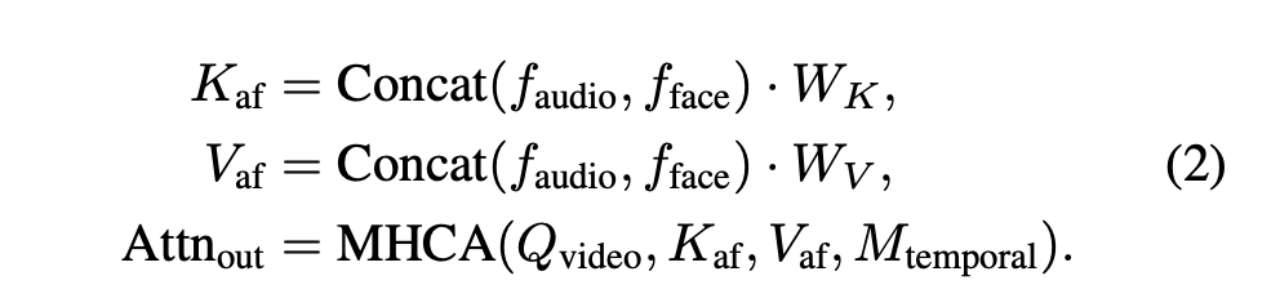
其中,MHCA 表示多头交叉注意力,W_K和 W_V分别表示键矩阵和值矩阵。注意力输出 Attn_out将随后由人脸掩码 token 进行调整,如公式(3)所述。
人脸 token 建模。人脸图像通过在训练时在线裁剪所选视频片段的第一帧并使用 InsightFace 获得,而人脸掩码 则预先计算,覆盖整个视频中人脸的最大区域,即全局人脸边界框。该掩码确保面部动作不会超出此区域,防止在重塑和展平操作后错误激活视频 token,特别是对于面部位移较大的视频。该掩码与 具有相同的尺寸,可直接用于逐元素乘法计算 Audio-Face Cross Attention 输出,公式如下:

因此,每个 I2V DiT 块的隐藏状态 ,可表示为:
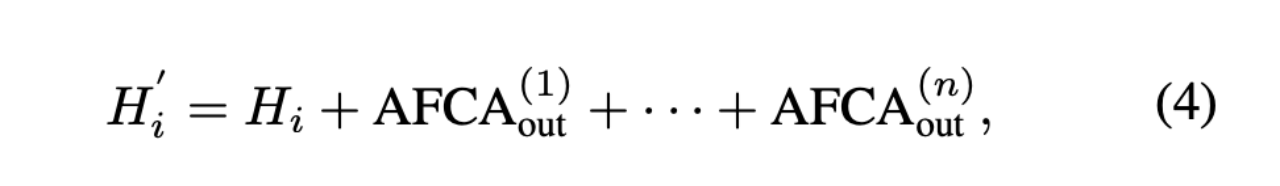
其中,i 表示注意力层的层索引,n 表示身份数量。注意,所有 项都由具有共享参数的同一 AFCA 层产生。AFCA 计算被迭代应用 n 次,每次对应一个角色,该架构可以任意扩展可驱动身份的数量。
训练策略
AnyTalker 探索了利用单人数据学习多人说话模式的潜力,其中低成本单人数据构成了训练数据的大部分。
单人数据预训练。我们使用标准单人数据和通过水平拼接生成的合成双人数据训练模型。每个批次的数据以50%的概率随机配置为双人或单人模式,如图2(b)所示。在双人模式下,批次中的每个样本与其下一个索引的数据及其对应音频进行水平拼接。这种方法使得每个批次在两种模式下的批量大小保持一致。此外,我们预定义了一些通用文本提示,用于描述双人对话场景。
多人数据互动性优化。在第二阶段,我们使用少量真实多人数据对模型进行微调,以增强不同身份之间的交互性。尽管我们的训练数据仅包含两个身份之间的交互,但我们惊讶地发现,配备 AFCA 模块的模型能够自然地泛化到超过两个身份的场景,如图1所示。我们推测,这是因为 AFCA 机制使得模型能够学习人类交互的通用模式,包括不仅准确地对音频进行唇同步,还包括对其他身份说话行为的倾听和响应。
为了构建高质量的多人训练数据,我们构建了一个严格的质量控制流程,使用 InsightFace 确保大多数帧中出现两张人脸,使用音频分离分离音频并确保只有一两个说话者,使用光流过滤过度运动,并使用 Sync-C 分数将音频与人脸配对。该流程最终产生了总共12小时的高质量双人数据,与之前的方法相比数量较少。由于AnyTalker 的 AFCA 设计本身支持多身份输入,双人数据以与第一阶段拼接数据相同的格式输入模型,无需额外处理。
总结来说,单人数据训练过程增强了模型的唇同步能力和生成质量,同时也学习了多人说话模式。随后,轻量级的多人数据微调弥补了单人数据无法完全覆盖的多人之间的真实交互。
交互性评估
但现有的单人说话头生成评估基准不足以评估角色之间的自然交互。尽管 InterActHuman 引入了一个相关Benchmark,但其测试集仅限于单个说话者的场景,不利于评估多个角色之间的交互。为了填补这一空白,我们精心构建了一组包含两个不同说话者的视频用于评估互动性。

图4: 来自InteractiveEyes的两个视频片段,带有运动分数(单位为像素):左显示原始视频,右显示裁剪后的面部和眼部关键点。将头转向演讲者或扬起眉毛将增加运动和交互性;持续的静止使两个分数都保持低水平。
数据集构建
我们选择具有交互性的双人视频构建视频数据集,命名为 InteractiveEyes。图4展示了其中的两个片段。每个视频时长约为10秒,整个片段中始终包含两个角色。此外,通过细致的人工处理,我们对每个视频的音频进行分段,确保大多数视频同时囊括两人说话和倾听的场景,如图5所示。我们还确保每个视频包含相互凝视和头部动作的实例,以提供真实的参考。
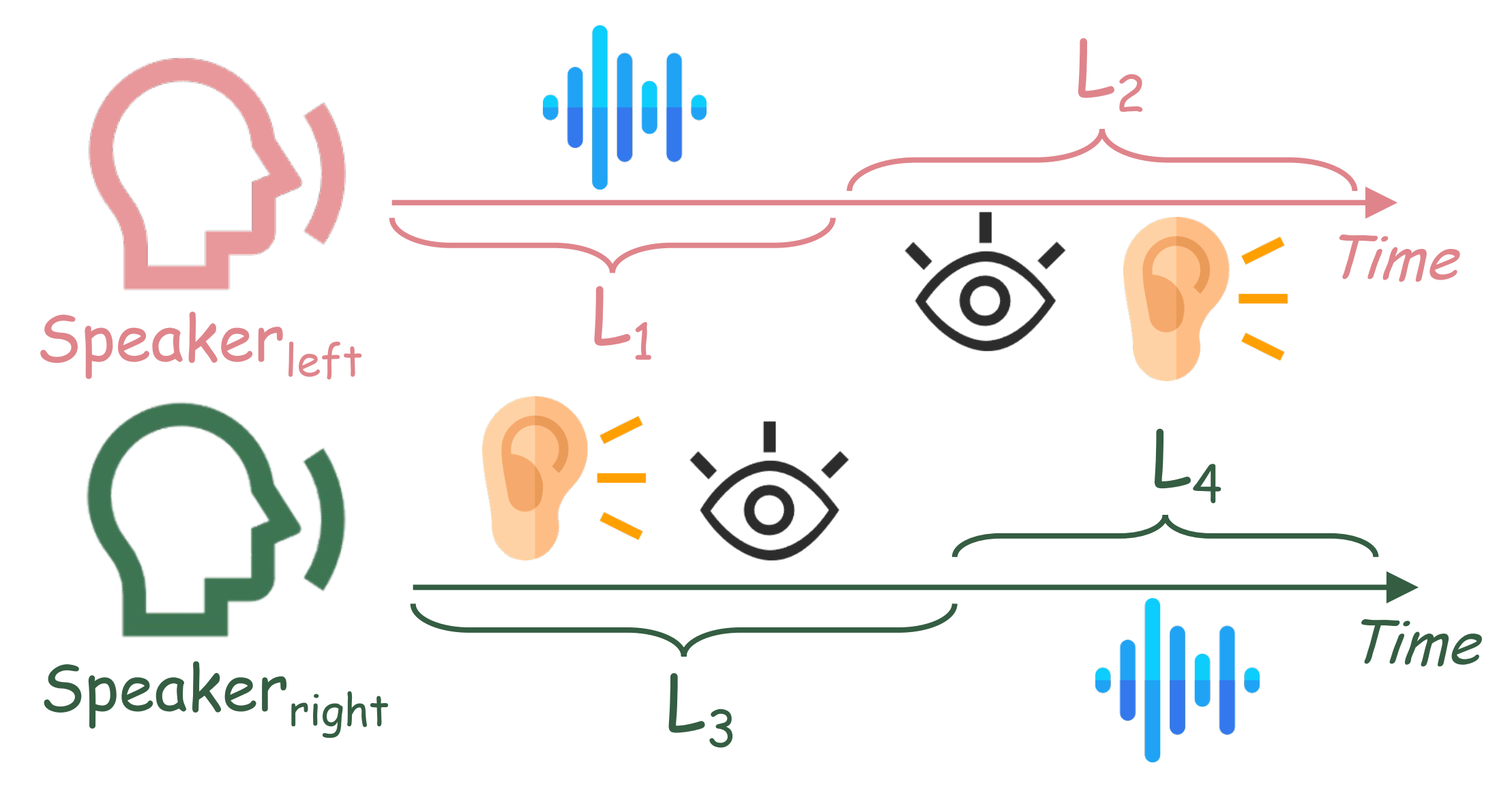
图5: 每个角色的倾听和说话时间段
提出的交互性指标
除了数据集,我们还引入了一种新的指标,即 eye-focused Interactivity,用于评估说话者和倾听者之间的自然交互。由于眼神交流是对话情境中的基本且自发的行为,我们将其作为交互性的关键参考。受 CyberHost中使用的 Hand Keypoint Variance(HKV)指标启发,我们通过跟踪眼关键点的运动幅度来提出一种定量评估交互性的方法。为此,我们在生成帧中提取人脸对齐的眼关键点序列,其中 S 表示帧序列,E 表示眼关键点。运动(Motion)计算如下:
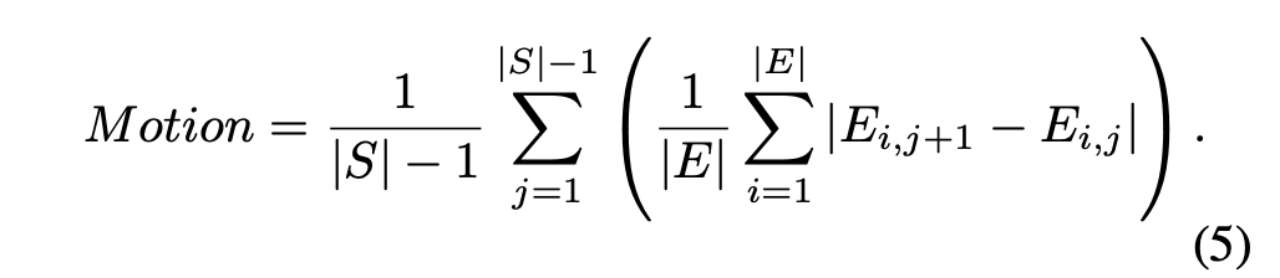
其中,i 和 j 分别表示眼关键点索引和帧索引,,j表示每帧中的眼关键点。该公式直观地计算了眼区域的位移和旋转。我们随后在倾听期间计算运动。原因是,大多数生成方法在激活说话者时表现良好,但倾听者往往显得僵硬。因此,在倾听期间进行评估更具针对性和价值。每个人说话和倾听的时段长度如图5所示,分别记为 。为了量化倾听者的响应积极性,我们计算倾听阶段 和 的平均运动强度:
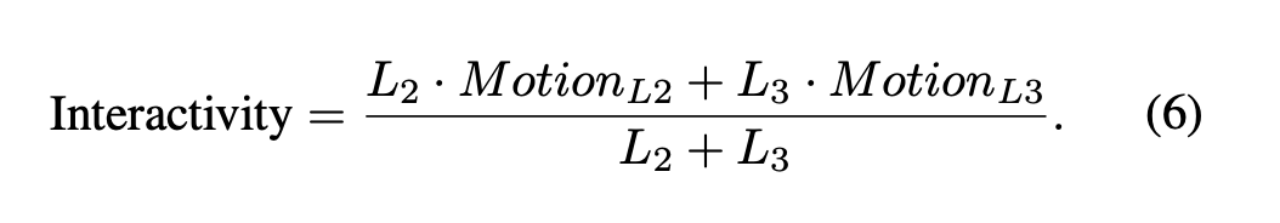
该指标有效衡量了生成的多角色视频中的交互性。如图4所示,所提出的指标与人类感知高度一致:静态或缓慢的眼部运动会得到较低的运动分数,而头部转动和眉毛上扬会提高分数,从而表示更高的交互性。
实验
数据集。我们扩展了常用单人训练数据集并加入了网络收集的数据,第一阶段训练总共约1,000小时,第二阶段训练收集双人对话片段,过滤后仅保留约12小时。评估在两个基准上进行:(i)标准说话头基准 HDTF 和 VFHQ,以及(ii)我们自行收集的多人对话数据集(包含头部和身体,两个角色都说话)。我们从每个基准中随机选择20个视频,严格确保其身份未出现在训练集中。
实现细节。为了全面评估我们的方法,我们训练了两种不同规模的模型:Wan2.1-1.3B-Inp 和 Wan2.1-I2V-14B,它们作为我们实验的基础视频扩散模型。在所有阶段,文本、音频和图像编码器以及3D VAE 保持冻结,DiT 主网络(包括新增的 AFCA 层)的所有参数均开放训练。第一阶段以 2×10−5的学习率进行预训练;第二阶段以 5×10−6的学习率进行微调,使用 AdamW 优化器,在32块 NVIDIA H200 GPU 上进行训练。
评估指标。对于单人 Benchmark,我们采用多种常用指标:Fréchet Inception Distance(FID)和 Fréchet Video Distance(FVD)用于评估生成数据的质量,Sync-C 用于衡量音频与唇动的同步性,以及第一帧与剩余帧之间的身份相似度。对于多人 Benchmark,我们从不同维度进行评估。新引入的指标 Interactivity 作为主要评估指标。对于 FVD 指标,计算方式与单人基准类似。对于 Sync-C 指标,我们将其细化为 Sync-C*,仅关注每个角色说话期间的唇同步,从而避免长时间倾听段落对最终唇同步得分的影响,具体公式为:
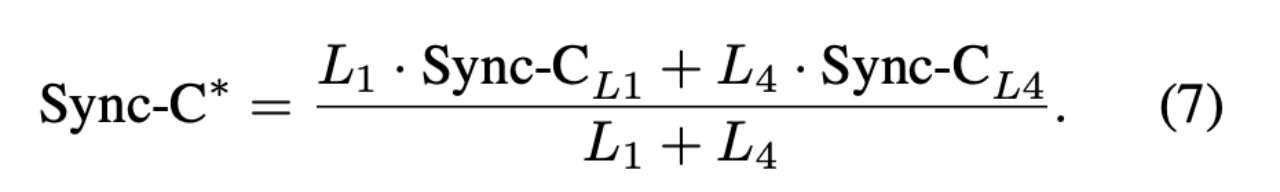
其中,和 表示图5中展示的说话时间段。
对比方法。我们与几种最先进的说话视频生成方法进行比较。对于单人生成,我们与 AniPortrait、EchoMimic 、Hallo3、Sonic、FantasyTalking、StableAvatar、OmniHuman-1.5 和 MultiTalk进行比较。对于多人生成,我们选择 Bind-Your-Avatar和 MultiTalk进行定量和定性比较。
与 SOTA 方法对比
定量对比。首先,我们与几种单人生成方法进行比较,以验证其出色的单人驱动能力。定量结果如表1所示。尽管 AnyTalker 并非专门为驱动说话面孔而设计,但它在所有指标上均取得了最佳或具有竞争力的结果。此外,AnyTalker 的1.3B模型在唇同步方面显著优于 AniPortrait、EchoMimic 和 StableAvatar,尽管它们具有相似数量的参数。这些结果证明了 AnyTalker 框架出色且全面的驱动能力。
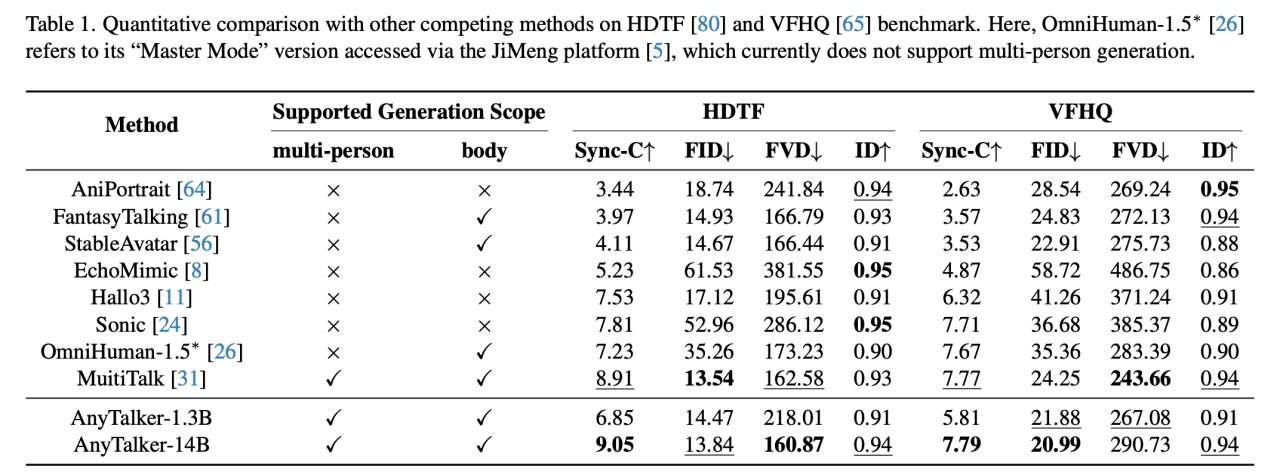
随后,我们使用多人数据集 InteractiveEyes 及相关指标评估 AnyTalker 在驱动多个身份时保持准确唇同步和自然交互性的能力。在此对比中,我们将 AnyTalker 与现有的开源多人驱动方法 MultiTalk 和 Bind-Your-Avatar 进行对比。表2中的结果显示,AnyTalker 的1.3B和14B模型在 Interactivity 指标上均取得了最佳性能。此外,14B模型在所有指标上均取得了最佳结果,从而验证了我们提出的训练流程的有效性。我们还通过定量评估展示了 AnyTalker 生成富含交互性的视频的能力。
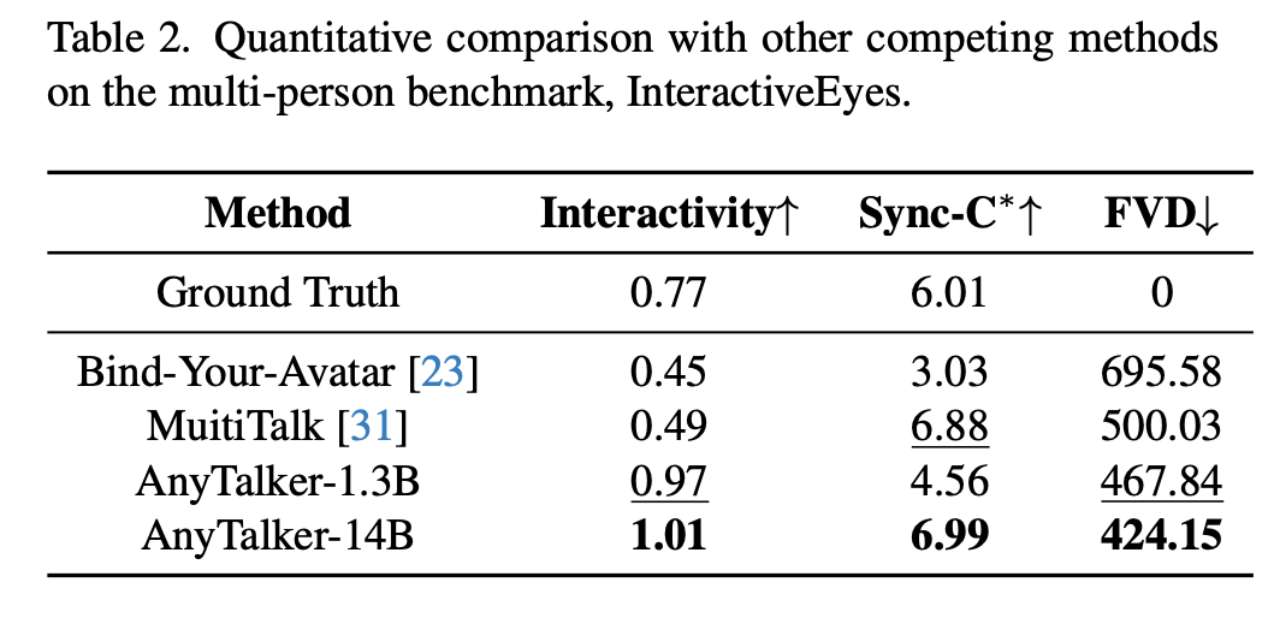
定性对比。我们从 InteractiveEyes 数据集中选择一个真实人类输入,并使用一个由 AIGC 模型生成的输入,两者均附带相应的文本提示和双音频流,使用 Bind-Your-Avatar、MultiTalk 和 AnyTalker 进行定量评估对比。如图6所示,AnyTalker 相比其他方法生成了更自然的视频,具有眼神和头部互动。MultiTalk 表现出较弱的眼神互动,而 Bind-Your-Avatar 往往产生更僵硬的表情。这一趋势进一步验证了我们提出的 Interactivity 指标的有效性。AnyTalker 不仅能生成自然的双人互动说话场景,还能很好地扩展到多个身份,如图1所示,它能有效处理四个身份之间的互动。

图 6: 多种多人驱动方法的定性比较。使用相同的文本提示、参考图像和多个音频流作为输入,我们比较了 Bind-Your-Avatar、MultiTalk和AnyTalker的生成结果。左侧案例使用输入图像来自InteractiveEyes数据集,而右边使用文生图模型生成的图像自作为输入。

图 7: 更多由AnyTalker生成的视频结果
结论
在本文中,我们介绍了 AnyTalker,一个用于生成多人说话视频的音频驱动框架。它提出了一种可扩展的多流处理结构,称为 Audio-Face Cross Attention,能够在保证跨身份无缝交互的同时实现身份扩展。我们进一步提出了一种可泛化的训练策略,通过基于拼接的增强最大化地利用单人数据来学习多人说话模式。此外,我们提出了第一个交互性评估指标和一个专门的数据集,用于全面评估交互性。大量实验表明,AnyTalker 在唇形同步、身份可扩展性和交互性之间取得了良好的平衡。
参考文献
1 AnyTalker: Scaling Multi-Person Talking Video Generation with Interactivity Refinement