新南威尔士大学 | LiM:利用 RFC 简化网络流量分类

1、研究背景
NTC(Network Traffic Classification,网络流量分类)是网络管理、安全监控和提高服务质量的一项关键任务。由于TLS1.3等加密协议,依赖于检查数据包有效载荷的传统分类方法逐渐失效。尽管目前针对NTC任务提出了许多新颖的方法,但它们经常做出一些于加密规范不符的假设。本文根据这些不合理的假设总结出五个主要的挑战(Challenges, C):
- C1-加密载荷存在隐式模式的假设:很多模型是在加密载荷中存在可利用的分类模式的前提下运行,但这与TLS1.3规范RFC-8446相矛盾,该规范规定,由于使用了带有关联数据的认证加密(AEAD)密码和唯一的初始化向量(IV),相同的明文将始终产生不同的密文。
- C2-固定大小的同质数据包表示:许多研究通常会对数据包进行截断或填充,以使其成为固定长度的输入。这种做法忽略了TLS1.3中所指出的,即加密数据包的长度和时间间隔容易受到流量分析攻击的影响(参考 RFC-8446)。填充或截断并不能有效地利用这一漏洞,并且可能会掩盖对于分类至关重要的与大小相关的关键特征。
- C3-无正当理由包含标头:有一些字段会包含每次会话初始化的伪随机值,这为数据带来了不必要的变化性。例如IP标识、IP头部校验和、序列号和确认号以及TCP选项的时间戳等。
- C4-将网络流量表示为文本或图像:将网络流量转换为文本或视觉格式,利用基础模型(如 BERT、ViT)来利用语义、语法或空间关系,可能会破坏网络协议的固有结构。与自然语言的标记或图像的像素不同,网络头部属性通常缺乏相互依赖性,因此这样的表示方式效果较差。
- C5-对握手包的依赖:一些分类器是基于初始握手数据包来进行分类的。然而,诸如 TCP 连接复用、TLS 1.3 的 0-RTT 数据传输以及通过预共享密钥(PSK)进行会话恢复等机制使得通信能够无需频繁进行握手。因此,那些依赖于握手数据包的分类器在这些常见场景中可能会失效。
这些挑战凸显了对网络流量分类(NTC)采取实用且高效方法的必要性。为了弥补这一差距,我们提出了 NetMatrix,这是一种新颖的表格表示形式,它利用 RFC 规范来捕捉网络流量的有意义特征。NetMatrix 与基本的 XGBoost 分类器(称为 LiM,即"少即是多")相结合,能够达到与资源密集型深度学习模型相当的性能,同时保持显著更低的计算开销。此外,我们的方法展示了处理大量请求的能力、能在数秒内适应新的流量类别,并且在内存和能源效率方面具有更高的性能。
2、方法
2.1 NetMatrix
NetMatrix 是一种简洁的表格形式的网络流量表示方法,旨在克服现有网络流量分析(NTC)方法的局限性。所提出的这种表示方法基于以下原则,与目前的RFC(如 RFC-8446、RFC-2328、RFC4271、RFC-6247、RFC-791、RFC-9293、RFC-7323)相一致:
- 排除加密数据包:鉴于根据 TLS 1.3 规范(RFC-8446)加密数据包的内容不存在可利用的模式,作者完全将其从 NetMatrix 中排除,以解决(C1)问题。
- 利用加密数据包长度和时间信息:鉴于 TLS 1.3 强调了加密数据包长度和时间信息容易受到流量分析攻击的特性(RFC-8446),本文作者纳入了这些属性并解决了(C2)问题。具体而言,利用 IP 头部的总长度字段,并计算数据包之间的到达间隔时间。
- 减少表示体大小:通过排除那些具有噪声性且与特定会话相关的头部字段(例如 IP 标识(IP-ID)、校验和、序列号和 TCP 时间戳),作者专注于那些符合 RFC 规范的稳定且有意义的头部属性。这种减小操作能够减少噪声,并通过集中处理相关数据来提高分类性能,从而解决(C3)问题。
- 保持原始网络流量结构:与将网络流量转换为文本或图像(这可能会掩盖协议结构)的做法不同,NetMatrix 通过使用表格格式来保持原始结构(作为对(C4)问题的解决办法)。这种表示方式能够保留由网络协议所定义的关系。
- 依赖包含加密数据的报文:为了确保其实用性,本文方法依据包含加密数据包的报文来进行分类。即便在无法使用握手报文作为(C5)解决方案的情况下,这种方法依然有效。
NetMatrix 仅利用从网络数据包中提取的三个关键属性来表示一个会话:
- IP 头部总长度:IP 头部中的总长度字段表示整个 IP 数据包的大小,包括头部和数据部分。
- 生存时间(TTL)(IP 头部):TTL 字段表示数据包在被丢弃前能够经过的最大跳数。尽管由于路由变化,TTL 值可能会有所不同,但对于从两个端点之间经过相同路径的数据包而言,它们通常是保持一致的。路由协议力求实现最小的开销,因此轻微的路由变动对到达时的 TTL 产生的影响有限RFC-2328,RFC-4271。因此,TTL 可以提供有关网络路径特征的有用信息。
- 间隔时间(IAT):此属性用于衡量两个连续数据包之间的时间差。
NetMatrix 通过从包含加密数据包的五个连续数据包中提取上述属性来表示每个网络流量会话(即两个端点之间的双向流量)。对于每个数据包,我们收集以下信息:总长度(2 个字节)、生存时间(1 个字节)、间隔到达时间(计算得出,3 个字节)。这样就为每个会话生成了一个 30 个字节的紧凑表示,与现有方法相比大大减少了数据量。例如,ET-BERT 使用 620 个字节,而 YaTC 则需要 1600 个字节来表示一个会话。
2.2 LiM
为了进一步完善 NetMatrix 提供的高效表示,作者采用了标准的 XGBoost 分类器。基于树的模型,例如 XGBoost,特别擅长学习目标函数中的不规则模式,并在表格数据上表现出优越性。其归纳偏差使其天生非常适合 NetMatrix 的结构特性,能够实现高效且准确的分类,而无需像深度学习模型那样消耗大量的计算资源。作者将 NetMatrix 与 XGBoost 分类器的整合称为 LiM(少即是多)。通过利用 LiM,作者证明了一个简单的机器学习模型可以达到与最先进的深度学习方法(如 ET-BERT 和 YaTC)相当的性能,而无需复杂的架构或大量的计算资源。
3、实验评估
为了验证本文所提出方法的有效性和效率,作者进行了实验评估,重点针对遵循 TLS 1.3 协议的加密流量。评估包含两个主要部分:(1)评估分类性能,(2)分析资源消耗。
本文采用了在"ET-BERT"研究中引入的 CSTNET-TLS1.3 数据集,该数据集包含了使用 TLS 1.3 加密的网络流量。此数据集非常适合本文的评估,因为它反映了现代加密协议以及与网络流量分类相关的挑战。为了解决类别不平衡问题,我们从该数据集中随机选取了 10 个类别,每个类别包含超过 400 个样本。为了进行无偏的评估,为每个分类器提供每个类别 400 个样本。这种等量的分配确保了没有类别在训练过程中占据主导地位,并有助于公平地评估资源消耗情况。
3.1 实验设置
硬件:这些实验是在一台配备有两颗英特尔 Xeon Silver 4208 处理器的机器上进行的,这些处理器的基频为 2.10GHz,最高频率可达 3.20GHz。每个处理器每个插槽内有 8 个核心,总共拥有 16 个物理核心和 32 个线程。该系统配备了 125GB 的内存。为了实现 GPU 加速,这台机器安装了四块 NVIDIA Tesla T4 GPU,每块 GPU 都有 16GB 的专用内存,总计 GPU 内存容量为 64GB。每块 GPU 的最大功耗为 70 瓦。
软件:该系统运行于 Ubuntu 24.04.1 LTS操作系统之上。Python 3.13.0 作为编程语言,以及用于实现和训练 LiM 的 XGBoost 2.1.2 库。
为了进行对比分析,本文作者使用了推荐的配置对最先进的模型 ET-BERT 和 YaTC 进行了评估。这些模型是在相同的实验环境中运行的,以确保在不同的分类器之间进行公平且一致的比较。
3.2 实验结果
分类性能:
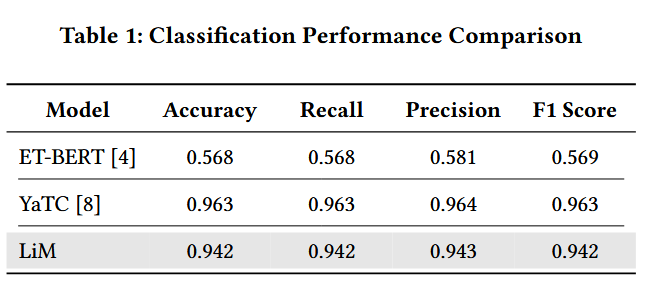
ET-BERT 的分类准确率达到了 0.568,其召回率和 F1 分数也均为 0.568 和 0.569,而其准确率略高一些,为 0.581。这种表现不佳的情况可能是由于为进行所有模型的公平评估而提供的训练设置有限(每个类别 400 个样本)所致。相比之下,YaTC 模型的表现要出色得多,其准确率和 F1 分数达到了 0.963。
所提出的 LiM 分类器与 NetMatrix 表示法相结合时,取得了与之相当的结果,准确率为 0.942,F1 分数为 0.942。精度和召回率也分别接近 0.943 和 0.942,这突显了该模型在所有评估指标上的稳健性。虽然 LiM 在总体性能上略逊于 YaTC,但其结果凸显了简单而有效的方法的优势。NetMatrix 表示法与 XGBoost 分类器的结合表明,无需依赖复杂的架构也能实现高分类性能,为准确性和简洁性之间提供了极具吸引力的平衡。
资源消耗:
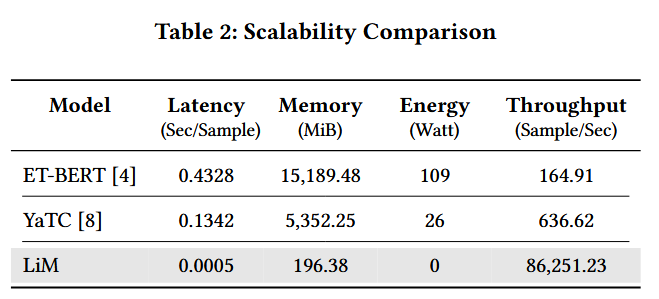
轻量级的 XGBoost 分类器与 NetMatrix 表示法(LiM)相结合后,在所有评估指标上都显示出更低的资源消耗情况。
LiM 的延迟非常低,每样本仅需 0.0005 秒,这使得它能够以近乎即时的速度处理输入数据。相比之下,ET-BERT 的延迟为 0.4328 秒,高出 86560%;而 YaTC 的延迟为 0.1342 秒,比 LiM 高出 26840%。这种延迟的降低突显了 LiM 在需要低训练时间的实时应用中的适用性。在内存使用方面,LiM 在推理过程中仅占用 196.38 MiB 的内存。这比 ET-BERT(需要 15189.48 MiB,增加 7735%)和 YaTC(需要 5352.48 MiB,增加 2725%)的内存使用量有了显著的改善。这种低内存占用使得 LiM 适合部署在计算资源有限的设备上,如边缘设备或物联网系统。LiM 在推理过程中无需利用 GPU,因此没有可测量的能耗。相比之下,ET-BERT 消耗 109 瓦特,而 YaTC 消耗 26 瓦特,这反映了运营成本。最后,LiM 的每秒处理量为 86251.23 个样本,展示了其处理高流量的能力。此吞吐量比 ET-BERT 的每秒 164.91 个样本的吞吐量高出 52302%,比 YaTC 的每秒 636.62 个样本的吞吐量高出 13548%。吞吐量的差异凸显了 LiM 在高需求环境(如实时网络监控和大规模流量分析)中的潜在能力。