一、大数据的概念
数据是什么
数据是指对客观事件进行记录并可以鉴别的符号,是对客观事物的性质、状态以及相互关系等进行记载的物理符号
或这些物理符号的组合,它是可识别的、抽象的符号。
它不仅指狭义上的数字,还可以是具有一定意义的文字、字母、数字符号的组合、图形、图像、视频、音频等,也
是客观事物的属性、数量、位置及其相互关系的抽象表示。例如,"0、1、2..."、"阴、雨、下降"、"学生的
档案记录、货物的运输情况"等都是数据。
数据如何产生
对客观事物的计量和记录产生数据。
企业数据分析方向
把隐藏在数据背后的信息集中和提炼出来,总结出所研究对象的内在规律,帮助管理者进行有效的判断和决策。
数据分析在企业日常经营分析中主要有三大方向。
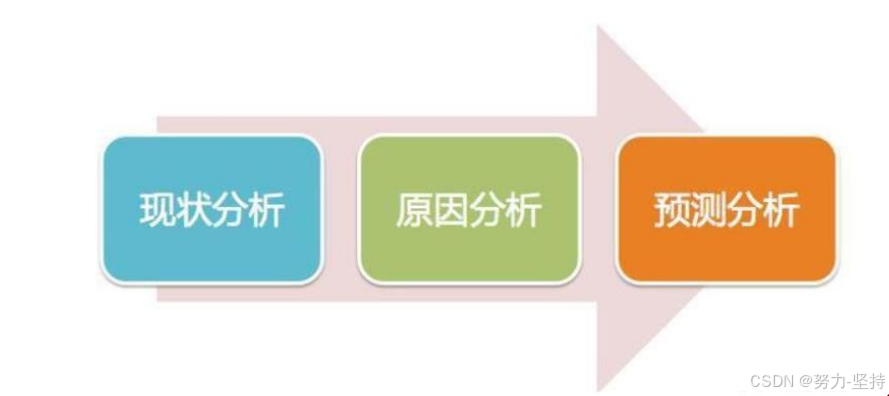
-
- 现状分析(分析当下的数据):现阶段的整体情况,各个部分的构成占比、发展、变动;
-
- 原因分析(分析过去的数据):某一现状为什么发生,确定原因,做出调整优化;
-
- 预测分析(结合数据预测未来):结合已有数据预测未来发展趋势。
1. 原因分析 离线分析(Batch Processing)
面向过去,面向历史,分析已有的数据;在时间维度明显成批次性变化。一周一分析(T+7),一天一分析(T+1),所以也叫做批处理。
2. 现状分析 实时分析(Real Time Processing |Streaming)
面向当下,分析实时产生的数据;所谓的实时是指从数据产生到数据分析到数据应用的时间间隔很短,可细分秒级、毫秒级。

3. 预测分析 机器学习(Machine Learning)
基于历史数据和当下产生的实时数据预测未来发生的事情;侧重于数学算法的运用,如分类、聚类、关联、预测。
二、 数据分析基本步骤
数据分析步骤(流程)的重要性体现在:对如何开展数据分析提供了强有力的逻辑支撑;
张文霖在《数据分析六步曲》说,典型的数据分析应该包含以下几个步骤。
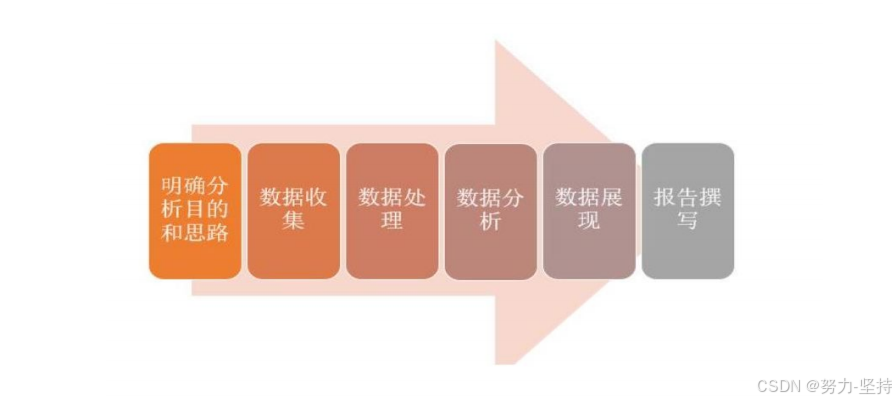
Step1:明确分析目的和思路
目的 是整个分析流程的起点,为数据的收集、处理及分析提供清晰的指引方向; 思路 是使分析框架体系化,比如先分析什么,后分析什么,使各分析点之间具有逻辑联系,保证分析维度的完整性,分析结果的有效性以及正确性,需要数据分析方法论进行支撑; 数据分析方法论是一些营销管理类相关理论,比如用户行为理论、PEST分析法、5W2H分析法等。
Step2:数据收集
数据从无到有 的过程:比如传感器收集气象数据、埋点收集用户行为数据。
数据传输搬运的过程:比如采集数据库数据到数据分析平台。

Step3:数据处理。准确来说,应该称之为数据预处理 。
数据预处理需要对收集到的数据进行加工整理,形成适合数据分析的样式,主要包括数据清洗、数据转化、数据提取、数据计算;
数据预处理可以保证数据的一致性和有效性,让数据变成干净规整的结构化数据 。干净规整的结构化数据:专业来说就是二维表的数据,行列对应;通俗来说就是格式清晰,利于解读的数据。
Step4:数据分析
用适当的分析方法及分析工具,对处理过的数据进行分析,提取有价值的信息,形成有效结论的过程;需要掌握各种数据分析方法,还要熟悉数据分析软件的操作;
Step5:数据展现
数据展现又称之为数据可视化,指的是分析结果图表展示,因为人类是视觉动物;数据可视化(Data Visualization)属于数据应用的一种; 注意,数据分析的结果不是只有可视化展示,还可以继续数据挖掘(Data Mining)、即席查询(Ad Hoc)等。
Step6:报告撰写
数据分析报告是对整个数据分析过程的一个总结与呈现。 把数据分析的起因、过程、结果及建议完整地呈现出来,供决策者参考。 需要有明确的结论,最好有建议或解决方案。
三、大数据特征
大数据(big data)是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合; 是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据5V特征
5个V开头的单词,从5个方面准确、生动、形象的介绍了大数据特征。

Volume (数据体量大) :
采集数据量大、 存储数据量大、计算数据量大、 TB、PB级别起步。
Variety(种类、来源多样化)
种类:结构化、半结构化、非结构化; 来源:日志文本、图片、音频、视频。
Value(低价值密度)
信息海量但是价值密度低、 深度复杂的挖掘分析需要机器学习参与。
Velocity(速度快)
数据增长速度快、 获取数据速度快、 数据处理速度快。
Veracity(数据的质量)
数据的准确性、 数据的可信赖度。
四、 分布式、集群概念
分布式、集群是两个不同的概念。
分布式:多台机器每台机器上部署不同组件。
集群:多台机器每台机器上部署相同组件。