通过长训练序列进行 OFDM 符号对齐
长训练序列的相关峰检测
通过长训练序列可以界定signal 域的开始;
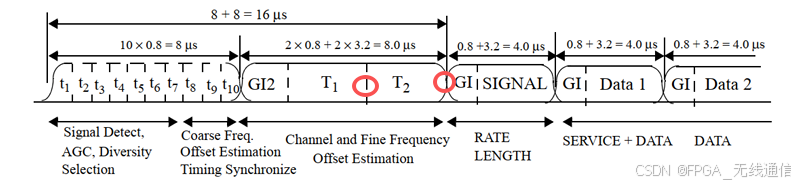
图中⭕️位置为检测到长训练序列相关峰的位置;
2个长训练序列一共128,一个长训练序列为64;
GI2(循环前缀CP):为长训练序列的一半,32个;
所以一共占了160个采样点;
长训练序列的相关检测公式:
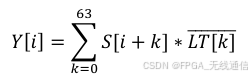
因为长训练序列是已知的,可以提前计算;
Si+k是输入信号,每一个输入数据(采样点)需要进行64 次的复数乘法;
每个采样周期都会有一个采样点输入进来,每个采样点需要64次复数乘法,
因非常消耗乘法器,需要进行算法优化;
通过相关的检测,检测到两个相关峰值,就认为找到了两个长训练序列,
因此可以设置一个门限值,超过门限值就认为检测到了相关峰;

LT1与LT2之间是64个采样点;LT 的长度是64;
算法优化:
因为输入信号Si和 LT 有相关性,只需要取 Si 的符号位即可也就是 数映射为1,负数映射为-1,
这样去做相关运算同样可以获得相关峰。 这样就可以将64个复数乘法器就可以转化为加法器了。
举例:
假如把输入信号和已知的长训练序列其中一个元素定义为
Si=a+bi;LTk=c+di ;
(a+bi)*(c+di)=ac-bd+(ad+bc) i;
i*i=-1;
由于a和b都是取值+1和-1所以可以转换为加减法运算;
图中⭕️位置为检测到长训练序列相关峰的位置;
因为GI2为 长训练序列的一半,所以可以考虑移位进行相关峰检测,最后再经过32个采样点即可到达信号域;
在长训练序列检测的时候,需要考虑 GI2 ,因为先接收到GI2 ,
所以可以把已知的LT设置为 {GI2,T10:31} ,
因为 GI2 其实是 T1 的后 32bit 数据也可以表示为 T132:63 所以可以设置为 LT={T132:63,T10:31};
这样连续检测到两个LT就证明识别了长训练序列,就可以定位到signal 域了。
识别到两个 LT 之后经过32个采样点就到达了signal域的GI部分。
后续再去掉signal 域的GI部分就可以送入FFT做解算。
可以将长训练序列在MATLAB计算好,存起来;

将ltrs 计算好,放入LT_IQ列表(查找表);
设计4级流水线相关器:
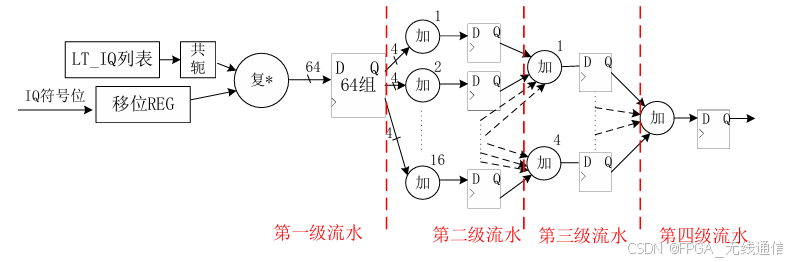
移位寄存器为64位;从移位寄存器将每一个I Q 的符号位取出来与查找表中的共轭值进行复数乘法;
第一级流水:复数乘法器输出会是并行的64 位数据输出,
第二级流水:将64位每相邻4位取出来进行相加,最后得到16位结果;将得到的结果存在寄存器中;
第三极流水:再将16个结果进行每4个分为一组进行累加,得到4个结果,再放到寄存器中;
第四级流水:最后将剩下的4个结果再相加,得到最后一个结果 Yi;
因为最后得到的结果是复数,所以需要进行幅度估计;
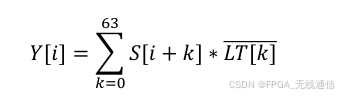
- 1 定义二维数据,LT_IQ,使用sv语法;
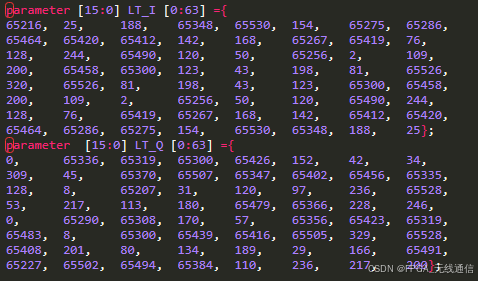
MATLAB:
- 2 将Si替换为符号位,变为(+1-1),相关性不会发生变化,会简化复数乘法运算;

- 3 取共轭和复数乘法转换为加减法;
LT_IQ列表中预先存储的长训练序列值记作L_I 和 L_Q ;
移位寄存器中每个采样点的符号位记作S_I 和 S_Q;
首先对训练序列取共轭得到:(取共轭,Q 端取反)
conj(L_I + L_Q*i) =L_I -- L_Q*i ;
复数相乘 ,存到寄存器
(S_I + S_Q*i)*(L_I -- L_Q*i)=(S_I*L_I +S_Q*L_Q) + (S_Q*L_I -S_I*LQ )*i;
因为S_I 和 S_Q取值只有+1和-1所以以上结果有4中情况
当S_I和S_Q 等于 +1 +1时 :
(S_I + S_Q*i)*(L_I -- L_Q*i)=(L_I +L_Q) + (L_I -L_Q )*i ;
当S_I和S_Q 等于 +1 -1时 :
(S_I + S_Q*i)*(L_I -- L_Q*i)=( L_I - L_Q) + (-L_I - L_Q )*i ;
当S_I和S_Q 等于 -1 +1时 :
(S_I + S_Q*i)*(L_I -- L_Q*i)=(-L_I + L_Q) + (L_I + L_Q )*i ;
当S_I和S_Q 等于 -1 -1时 :
(S_I + S_Q*i)*(L_I -- L_Q*i)=(-L_I - L_Q) + (-L_I + L_Q )*i ;
第一级流水:存储到64个寄存器组
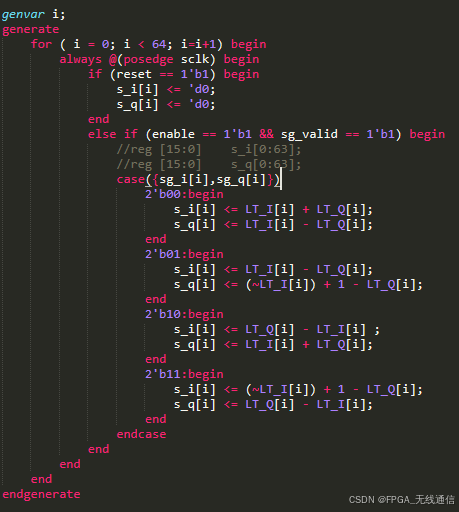
第二级流水:相邻4个相加,拆分为16个寄存器组

第三级流水:拆分为4个寄存器组
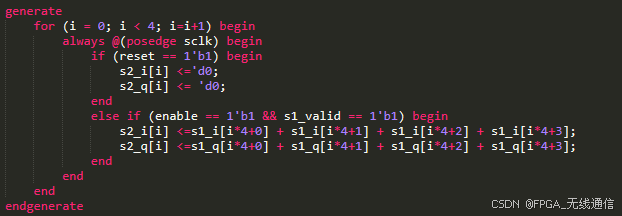
第四级流水:得到最后一个寄存器组

- 4 进行幅度估计

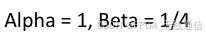
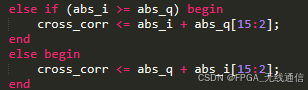
判断数据符号位正负,进行取绝对值:

判断 I 和 Q绝对值的大小,进行公式的计算,得到幅度值:
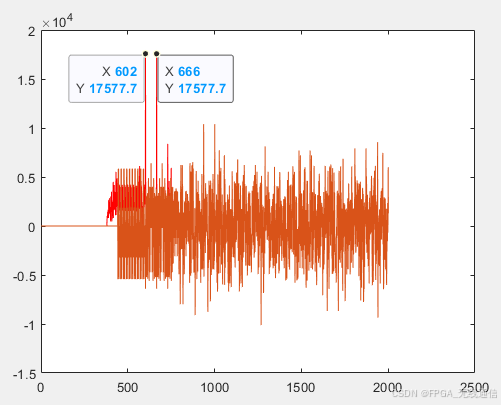
符号对齐
相关峰门限值设置,此处设置门限值,根据matlab 仿真极限值的 60% 作为门限值。
因为剩下循环前缀,为长训练序列的50%,门限值需要排除循环前缀的峰值;
检测长训练序列规则:
外部状态机会控制enable信号何时启动长训练序列检测,应该在短训练序列 检测到之后进行长训练序列检测,并使用粗频偏矫正后的信号做检测;
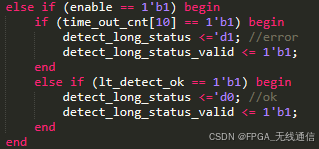
Time out cnt计数器当此模块 enable 时开始计数,当计数器(计采样点)大于等于1023时 给出异常标志和异常状态,因为此模块是在检测到短训练序列后开始运行的,理论会在320(短训练序列160个+长训练序列160个)个采样周期内检测到相关峰。
此计数器检测到相关峰就会清零;
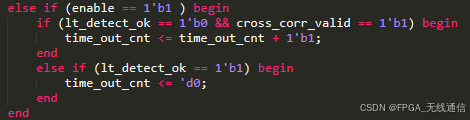
相关峰间距计数器 peak gap cnt, 因为长训练序列有T1和T2因此相关过程会 出现2个相关峰,两个相关峰距离应该是64个采样点(设置大于63小于 65的间隙都表示正确,标准应该等于64个)。通过此计数器在第二个相关峰来临时判断是否检测到长训练序列;


峰值检测计数器 peak cnt当相关峰值超出门限值后计数器加1;

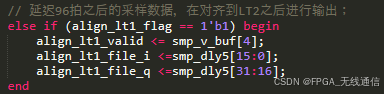
将输入信号延迟96个采样周期,这样当检测到相关峰后可以与LT1的起始位置对齐(原因是信道估计要用到 LT1 和 LT2),因为检测到相关峰位置为128个采样点位置,向前推96个采样点正 好是GI2结束也就是LT1的开始位置。{GI2,LT1,LT2} 其中GI2是32个采样周 期LT1和LT2是64个采样周期;
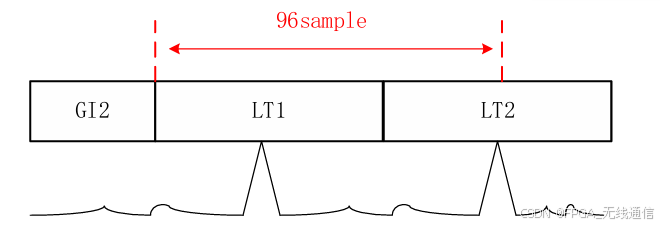

因为 peak gap cnt计数条件是检测到一个长训练序列,然后lt_detect_ok 又再第一个长训练序列的基础上又做了64拍计数,就刚好对齐到了第二个长训练序列的位置;
延迟模块输出信号使得与相关模块输出相关峰对其(再延迟5个时钟周期);
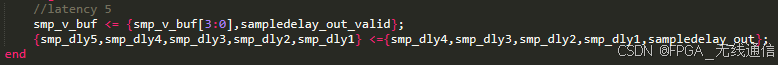
检测到相关峰后拉高lt_detect_ok标志,并把它以组合逻辑赋值给 align_ft1_flag 对齐LT1标志,通过此信号选择输出延迟后的采样信号,送出 到下一级模块,用于后续处理。

最后得到的结果即对齐到了第二个长训练序列位置。