
现代GPU中的控制流管理
摘要
在GPU中,控制流管理机制决定了线程束(warp)中哪些线程在任意时刻处于活动状态。该机制通过监控线程束内标量线程的控制流来优化线程调度,对执行资源的利用率起着至关重要的作用。++控制流管理机制可通过指令由软件控制或辅助实现,但GPU厂商通常不公开其编译器、指令集架构或硬件实现细节++ 。这种透明度的缺失使得研究人员难以理解控制流管理机制的具体运作方式、硬件实现或软件辅助手段,尤其当该机制对其研究产生重大影响时,这一问题显得尤为关键。同时,这也为GPU性能建模带来困难------研究者只能依赖实际硬件的追踪数据来分析控制流,而无法对该机制的功能进行建模或修改以调整其行为。
本文基于多种基准测试获得的实验数据,通过为图灵架构原生指令集****定义合理的控制流指令语义来解决这一问题。在此基础上,我们提出了一种名为"Hanoi"的低成本高效控制流管理机制。该机制在保证正确性的同时,++能生成与实际硬件高度吻合的控制流++ 【注,哪方面吻合】。实验评估表明:实际硬件的控制流轨迹与我们提出机制的差异平均仅为1.03%【注,哪方面的差异】。此外,在比较采用 Hanoi 机制的GPU与实际硬件原生控制流管理的每周期指令数(IPC)时,两者的平均差异仅为0.19%。
I. 引言
图形处理器(GPU)采用单指令多线程(SIMT)架构,该架构在单指令多数据(SIMD)处理单元上同时执行多个线程【注,SIMD 是 实现 SIMT 的组件之一】。该架构中的SIMD通道对来自不同线程的不同操作数执行相同的操作。线程调度对这种架构的SIMD利用率和整体性能有显著影响,因为只有被调度的线程才能使用SIMD通道。++GPU利用两种机制来调度执行线程++ :a) ++线程被分组成称为"线程束(warp)"的集合,每个周期选择一个线程束执行++ ;b) ++确定线程束中哪些线程在任意时刻处于活动状态++ 。我们将后者称为控制流管理机制,这主要是因为其决定了每个 线程束(warp)的控制流,并且深受各独立线程控制流的影响。控制流管理机制****监控线程束内线程的控制流,并协同调度执行相同指令的线程。该机制可通过指令集架构(ISA)中的指令 由软件控制或辅助,以实现最优且高效的线程调度。
为现代GPU设计高效的控制流管理机制至关重要且具有挑战性,这主要是因为现代GPU支持丰富的控制流指令集 。例如,英伟达图灵架构在其原生ISA(称为SASS)中包含****20条控制流指令。这些控制流指令可能导致线程分叉至不同路径,从而使它们因执行不同指令而无法被调度在一起执行。线程分叉会降低SIMD利用率和性能 ;因此,控制流管理机制利用单个线程控制流的运行时信息以及软件信息来重新聚合线程,以获得更高的效率【注,如何重新聚合呢?】。
研究人员已开发出许多 基于公开信息并使用开源工具评估的软件和硬件控制流管理机制。他们广泛使用LLVM进行编译器实现,并利用GPGPU-Sim 3.x作为性能模型进行评估。GPGPU-Sim 3.x和LLVM都使用有良好文档的并行线程执行(PTX)ISA作为软硬件之间的接口。多年来,研究人员一直使用此策略来应对英伟达等领先GPU厂商的不透明编译器、ISA和硬件所带来的挑战。
这种方法的一个主要问题在于,它依赖PTX作为ISA,因为PTX有完善文档。因此,这意味着对运行该ISA的微架构进行建模和优化。然而,PTX与GPU实际运行的指令不同,因此这些模型可能与实际硬件存在显著偏差。这种偏差在控制流管理方面尤为显著。这是因为英伟达GPU运行的是名为SASS的原生ISA,而非PTX,并且从PTX到SASS的翻译远非早期英伟达GPU时代 那样接近一一对应。仅考虑控制流指令,PTX只有5条指令,而图灵的SASS ISA 则有20条 。此外,PTX 代码在生成最终 SASS 之前会经过静态优化,这可能改变最终的控制流。当基于PTX设计控制流管理机制时,会忽略一些约束。这些约束由SASS中需要支持但PTX中不存在的指令所施加。 此外,为了研究诸如深度学习或图分析等现代工作负载的最先进实现,我们别无选择,只能依赖SASS ISA,因为这些应用程序使用了由英伟达高度优化和提供的微调库(如cuDNN、cuBLAS等)。然而,由于其源代码不可用,只能通过在真实硬件上运行时进行性能剖析或收集SASS追踪来研究它们。
研究人员已经认识到模拟PTX的局限性,并开发了诸如Accel-Sim等追踪驱动模拟器。Accel-Sim 模拟在现代GPU架构(如Volta和图灵)上运行的SASS指令追踪。与大多数追踪驱动模拟器一样,它仅模拟硬件组件的性能,而非其功能。这主要是因为指令和硬件组件的功能也未公开 ,而揭示底层硬件机制需要付出额外努力且并非总是可行。因此,像Accel-Sim这样的模拟器仅依赖真实硬件为控制流管理机制生成的控制流追踪。
然而,当研究人员开发改变硬件组件功能的机制时,仅仅模拟性能或依赖硬件追踪是行不通的。在研究新的控制流管理机制时尤其如此,因为新方案的功能会改变控制流,并产生影响其他组件(如发射调度器和相关性检查机制)的副作用。因此,需要建模控制流管理机制的功能,以研究其效果并评估其替代设计。
要建模控制流管理机制的功能,首先需要了解 ISA 中控制流指令的语义,然后需要微架构细节。这些细节均未公开。即使是剖析现代GPU(如Volta和图灵)架构和ISA的相关工作,也未曾涉及控制流管理机制。
在本工作中,我们通过基于研究各种应用程序的二进制文件和追踪所收集的实验数据,定义图灵 ISA 中控制流指令的语义 ,从而弥合这一差距。这种方法使我们能够设计一种名为 Hanoi 的新型控制流管理机制来支持这些控制流指令。我们证明Hanoi生成的控制流能为所有基准测试产生正确的输出,并与真实硬件高度吻合【注,是指哪方面吻合?】。具体而言,比较真实硬件与 Hanoi 的控制流追踪,平均差异仅为1.03%【注,差在什么上?】,仅导致0.19%的性能变化。
据我们所知,Hanoi 是第一个旨在支持图灵ISA中出现在多种知名基准测试中的所有控制流指令的控制流管理机制。Hanoi 在硬件成本方面是轻量级的 ,并已被证明与实际硬件机制高度相似【注,哪方面相似?】。其他已提出的方案是为PTX ISA设计的,或者其成本/效益不足以证明其在真实产品中的适用性。此外,这是首次尝试****描述图灵 ISA 中出现在常见基准测试里的控制流指令的合理语义。文献中提到的一些图灵控制流指令的语义是不完整的,因为仅定义了20条指令中的3条。仅凭这些指令无法处理我们在基准测试中遇到的所有场景。
II. VOLTA 之前 GPU 的控制流管理
英伟达等领先的GPU厂商已通过其文档化的执行模型向程序员披露了控制流管理机制的某些方面。该执行模型为使用 CUDA 或 PTX 等编程语言编写正确且无死锁的程序提供了必要的假设。此外,尽管实现细节从未公开,但它为研究人员推断****控制流管理机制的合理实现提供了宝贵的见解。
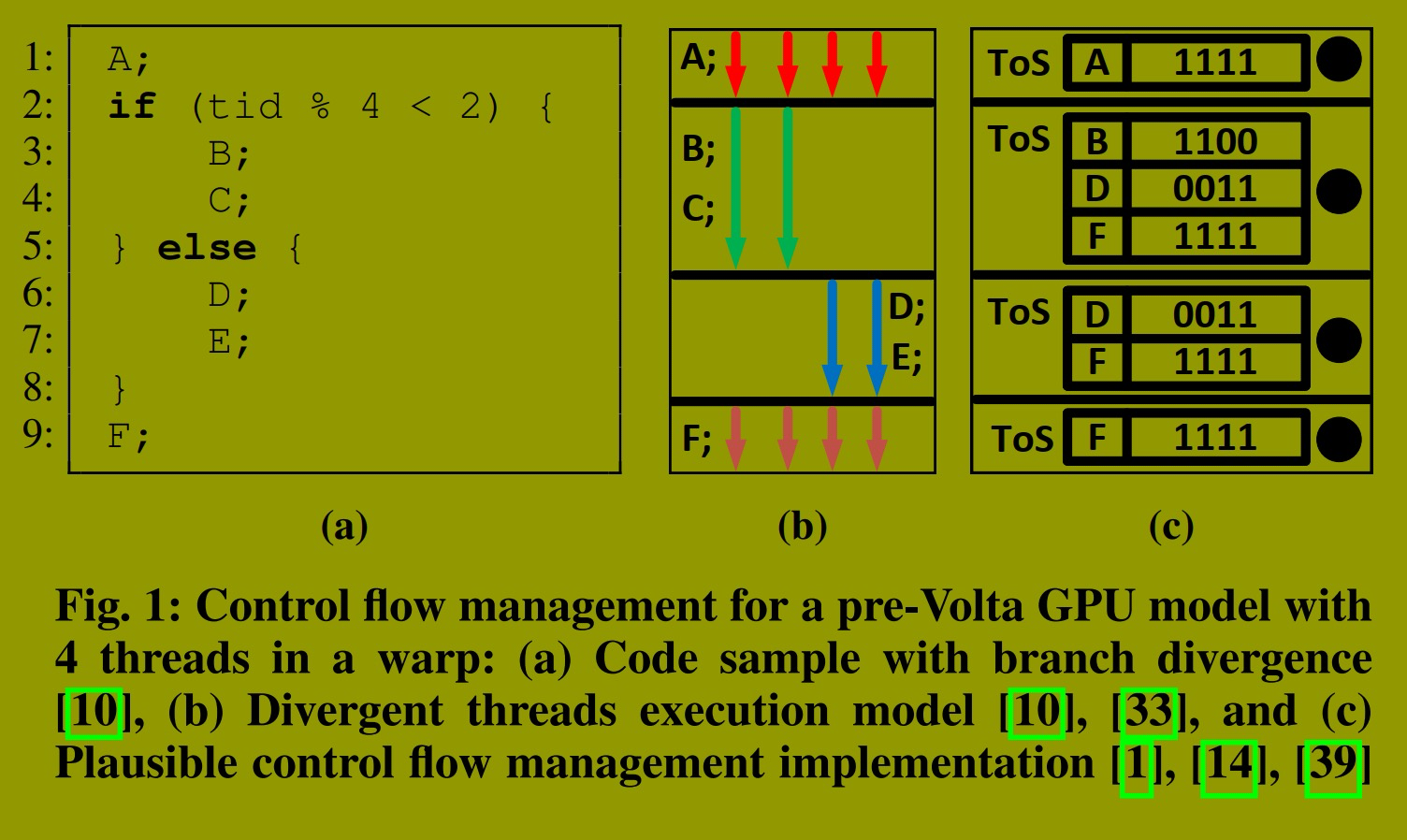
图1 描绘了根据执行模型推导出的、适用于 Volta 之前 GPU 的分叉线程的一种合理控制流管理方案。为简化说明,本文假设线程束仅包含四个线程。线程束中的所有线程开始时同步执行 图1a所示的源代码。一旦线程执行到第2行,分支分叉导致线程束的前半部分线程进入"taken"路径,其余线程进入"not-taken"路径。
在这种情况下,英伟达提供的执行模型规范描述的执行过程如图1b所示。该图展示了"taken"路径和"not-taken"路径的串行执行,以及随后在第9行的重新聚合。第9行是一个称为"直接后支配点"(IPDom)的位置,它是程序中保证两条分叉路径必定重新聚合的最近点 。虽然执行模型未指定哪条分叉路径具有优先级,但在此示例中,假设"taken"路径的优先级高于"not-taken"路径。
实现此行为的一种合理机制涉及使用称为 SIMT stack 的结构。++该机制利用SIMT stack 跟踪线程位于哪条路径,并在IPDom点强制重新聚合++ 。每个栈条目存储下一条指令的程序计数器(PC)以及执行该指令的 线程的活动掩码。在活动掩码中对应 bit 被设置的线程执行下一条指令,而其余线程保持空闲。
图1c 展示了执行此示例代码时栈的更新过程。最初,栈只有一个条目,显示所有线程一起执行指令A(步骤 1 )。当发生分支分叉时,栈顶条目将被弹出,三个新条目被压入栈中(步骤 2 )。第一个条目包含IPDom的PC和完整的活动掩码,因为所有线程必须在重新聚合后从IPDom继续执行。然后压入两个条目,一个对应进入"taken"路径的线程,另一个对应进入"not-taken"路径的线程。
"taken"路径执行完毕后,其对应条目被弹出,执行继续到"not-taken"路径(步骤 3 )。当线程完成"not-taken"路径的执行后,其对应条目被弹出,此时栈顶指针指向包含IPDom PC和完整活动掩码的条目(步骤 4 )。这便是如何在IPDom点强制实现重新聚合。
尽管 SIMT stack 是从执行模型推导而来,但该模型并未披露关于控制流管理机制任何更深入的细节,例如栈是纯粹由硬件实现还是由软件管理。此外,模型对可能显著影响性能的SIMT栈精妙之处保持沉默,包括各种路径选择策略------是优先"taken"路径还是"not-taken"路径,或是在硬件或软件中使用启发式方法进行路径选择。
研究人员采用微基准测试来揭示诸如路径选择策略等精妙之处。他们还广泛采用一种完全由硬件实现、并辅以少量软件协助(用于识别每个分支的IPDom点位置)的SIMT栈。研究人员还对该机制如何集成到GPU核心微架构中做出了假设。
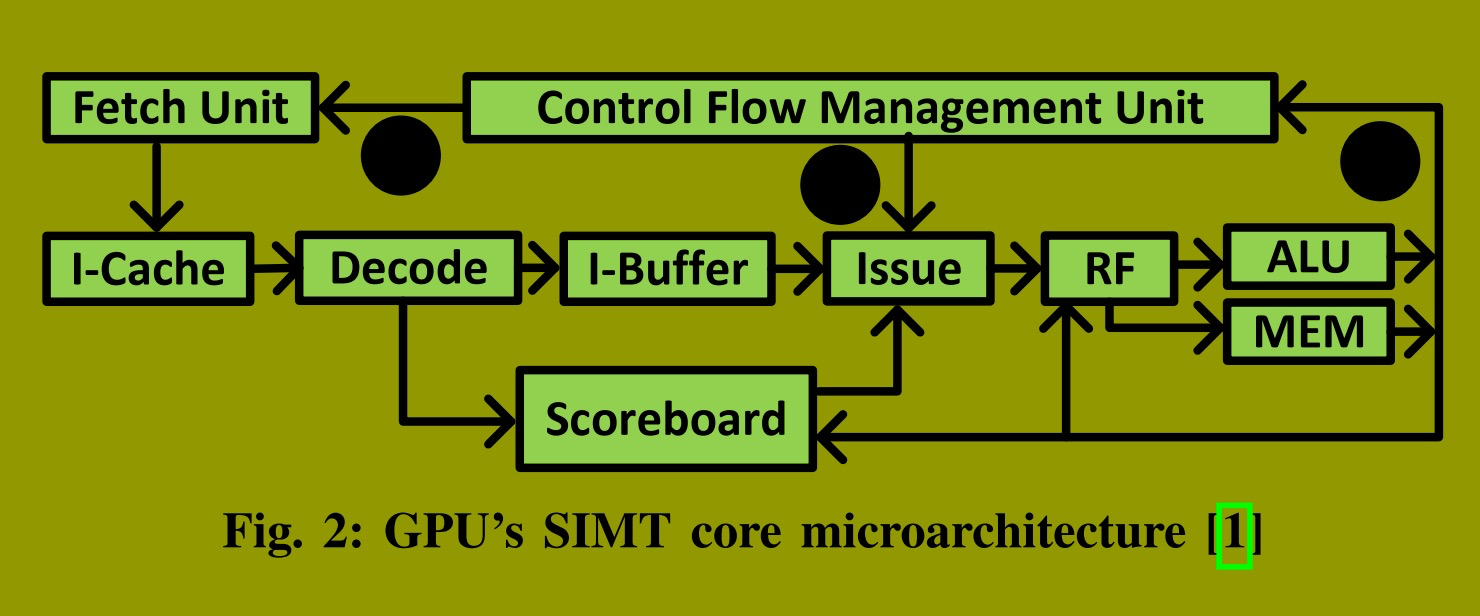
图2 展示了研究人员中一种普遍的假设:++通过每个线程束专用的控制流管理单元(CFU),将该机制集成到 GPU 的 SIMT 核心中。每个CFU包含一个栈和一些控制逻辑。++CFU 提供下一条指令的 PC 和活动掩码。取指单元使用该PC(步骤 1 )向内存请求指令。指令被取出并解码后,将存储到指令缓冲区的槽位中。每个线程束在指令缓冲区中拥有一组专用的槽位。在此SIMT核心架构中,当选中的线程束按程序顺序发射指令。发射逻辑选择下一个指令没有数据/结构冒险的特定 warp。对于数据冒险,则使用每个 warp 私有的计分板****进行依赖性检查。
当一条指令被发射时,活动掩码指示哪些线程执行该指令。CFU提供此掩码(步骤 2 ),后续流水线阶段的组件使用它,例如用于屏蔽寄存器或内存的更新。++控制流指令可能会改变控制流或CFU的内部状态++ ;因此,执行这些指令后需要更新CFU(步骤 3 )。
利用 SIMT stack 进行控制流管理 显著简化了 SIMT 核心架构。这种简化主要源于基于 stack 的实现不支持不同路径的交错执行,从而无需如文献其他方案所提出的为每条路径设置独立的指令缓冲区槽位或计分板。然而,SIMT stack 对线程调度施加了约束,这可能导致某些场景下出现死锁,程序员必须对此加以考虑。
III. VOLTA 之前架构中的 SIMT 引发死锁问题
在Volta之前的执行模型中,当线程发生分叉时,线程调度需遵循三项约束条件。这些约束源自控制流管理机制的实现方式。程序员必须审慎考量这些约束,以确保程序正确性并避免死锁。具体约束如下:
-
分叉路径必须串行执行,即依次按顺序执行。
-
每条路径中的线程需以锁步方式同步执行。
-
必须在**直接后支配点(IPDom)**强制执行路径重聚合。
在相关研究中,由 SIMT 实现约束所引发的死锁被称为 SIMT 引发死锁。在Volta之前的GPU中,控制流管理机制是大多数 SIMT 引发死锁 的主要原因。例如,图3 所示的CUDA自旋锁实现,就因控制流管理机制导致了死锁。

【注,原子操作函数回顾
cpp
// 1. atomicCAS (Compare And Swap) - 核心
// 如果 *addr == compare,则将 val 写入 *addr,返回 *addr 的旧值
int atomicCAS(int* addr, int compare, int val);
// 2. atomicExch (Exchange) - 用于释放锁
// 将 val 写入 *addr,返回 *addr 的旧值
int atomicExch(int* addr, int val);】
在此示例中,当某个线程获取锁后,它会退出循环、执行临界区代码并释放锁,以便其他线程进入。竞争获取锁的线程分叉为两条路径:一条退出循环并进入临界区(路径a),另一条则返回到循环起点(路径b)。成功获取锁的线程进入路径a,而同一线程束中的其余线程则进入路径b,在锁被释放前,它们将持续被困在循环中。
在Volta之前的GPU中,由于约束1和3,这种情况会导致死锁 。根据约束1,必须先后执行两条路径。**如果优先执行路径b,将发生死锁,因为路径b会无限期等待路径a(第4行)释放锁,而路径a却无法执行。反之,若优先执行路径a,则因约束3(要求在锁释放前于IPDom点,即紧邻循环退出后的第3行处进行重聚合)的存在,死锁依然持续。**然而,重聚合无法发生:因为获取锁的线程阻塞在重聚合点等待其他线程,永远无法到达释放锁的代码点;与此同时,等待锁的线程却无限期地困在循环中。
如果控制流管理的约束条件不同,这种死锁本可避免。为解决此问题,英伟达在Volta之后的执行模型规范中取消了这些约束。这表明,Volta之后的GPU采用了截然不同的****控制流管理机制,其细节尚未公开。
IV. VOLTA 之后架构的控制流管理
在Volta之前的执行模型中,程序员需要直面底层控制流管理的约束,并必须进行干预以避免SIMT引发的死锁,这一过程颇为繁琐。Volta架构的引入极大减少了对这类干预的需求,简化了编程工作。Volta之后的执行模型取消了所有三项原有约束,仅引入了一项新约束。因此,程序员如今只需确保这一项约束不会导致线程执行之间出现循环依赖。
在Volta之后的执行模型中,分叉路径不再必然串行执行,同一线程束内的线程也不必须以锁步方式运行。此外,在IPDom点的重聚合不再被严格强制执行。取而代之的是引入了一种名为独立线程调度 的新调度机制,它允许在任何给定周期内,将线程束中具有相同PC值的任意线程调度在一起执行。++这种新的调度方法允许不同路径交错执行,并使得线程束内的线程可以在任何指令处(而不仅仅是在控制流指令或IPDom点)分叉或聚合。++因此,重聚合现在可以相对于执行流程中的IPDom点更早或更晚发生,甚至对于一些分支可以完全忽略。
该模型的唯一约束是++在新增的指令(如专为此目的引入的syncwarp)处强制执行线程束内同步++ 。因此,程序员有责任根据需要同步线程束内的线程以确保正确性。

图4 展示了一段与 图1 类似的示例源代码;主要区别在于第10行添加了 syncwarp() 以同步线程束内的所有线程。图4b 展示了此源代码在 Volta 之后 GPU 上一种可能的执行情况。在此示例执行中,分叉路径中的线程是交错执行的,并且忽略了在IPDom点(第9行)的重聚合。然而,线程束中的所有线程在执行syncwarp后实现了同步。此例说明了程序员如何强制执行线程束内同步。
这种执行模型虽然简化了编程,却几乎掩盖了底层控制流管理机制的所有细节。例如,图灵架构的控制流管理机制++显然是一个软硬件协同设计,因为其原生ISA中的许多控制流指令可以辅助该机制++ 。然而,这些指令的语义以及该机制如何利用它们并未公开。此外,控制流管理机制采用的具体策略也未披露。例如,尽管理论上在Volta之后的GPU中线程可以独立调度,但一种更具成本效益的调度策略可能会选择将每条路径中的所有线程集中调度,并偶尔在路径【注,if/else】间切换以提高效率【注,相当于一个warp 被路径切成了两个或多个w arp,仍然可以利用切换路径来隐藏延迟】。这仅仅是众多可行调度策略中的一种可能。
由于 Volta 之后的执行模型向程序员隐藏了如此多的细节,研究人员在推断底层控制流管理机制时面临困难。这源于存在大量可能的设计决策【注,找出最优解/次优解】。本质上,任何不会导致Volta之前SIMT引发死锁且遵守所有线程束内同步 的硬件/软件控制流管理机制,都是一个可行的设计。【注,需要结合 volta 的 true SIMT 架构,各thread私有PC这个特点来设计最优策略;不同的 PC 可以保持在4-5条之内,减小指令缓存压力】
在本研究中,我们旨在通过分析 Volta 之后 GPU 在其原生 ISA(SASS)级别上的二进制文件和执行轨迹,来揭示其底层的控制流管理机制。
V. 图灵架构的控制流指令
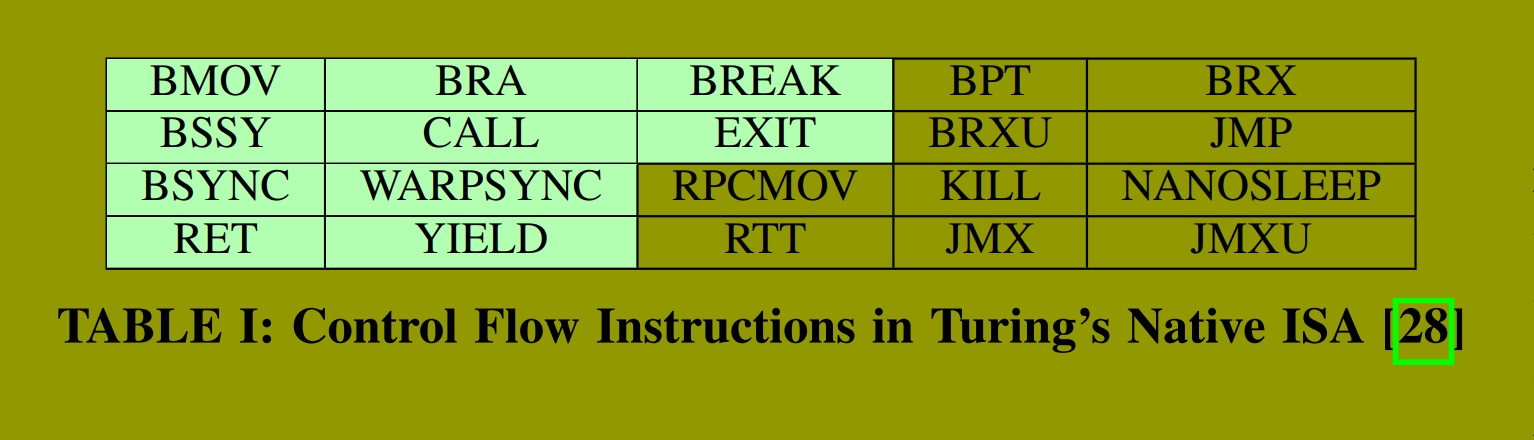
我们分析了图灵 GPU 的原生指令集架构,以理解其底层控制流管理机制。++图灵 ISA 支持谓词化执行,并包含20条控制流指令++ ,其概要见 表I 。英伟达的文档对这些指令有简要提及,但对其功能和语义保持谨慎态度。我们研究了多种基准测试的二进制文件和执行轨迹,以解读这些指令的含义。在我们选取的基准测试中,仅绿色高亮显示的指令出现过。本节将阐释我们的发现以及定义每条指令语义背后的依据。
A. 谓词化控制流指令
我们的研究表明,图灵的控制流指令可由最多两个谓词寄存器进行****防护,这些寄存器在使用前可被取反。这些谓词寄存器是为包含32个线程的线程束设计的32位寄存器,每个线程对应一位。第一个谓词寄存器以 @ 符号为前缀,出现在指令之前;而第二个谓词寄存器始终是第一个操作数。要对谓词取反,需在其寄存器名前加上!符号。如果一条指令有两个谓词,在执行谓词化判断前会对它们进行逻辑与运算。例如,@P0 INST !P1, R0 表示该指令仅在 P0 为真且 P1 为假时才会被执行。
B. EXIT指令
EXIT 指令用于终止线程的执行。该指令最多可接受一个谓词 ,并且没有操作数。被谓词掩码屏蔽的线程将从下一条指令继续执行,而其他线程则被终止。
C. BRA指令
BRA指令有条件或无条件地跳转到目标地址。除了谓词外,目标地址是该指令的唯一操作数。如果指令不使用任何谓词,则跳转为无条件跳转。然而,BRA最多可由两个谓词防护,从而使分支变为条件分支 。例如,执行@!P0 BRA P1, target时,只有P0为假且P1为真的线程才会跳转到目标地址。
D. CALL和RET指令
英伟达在调用函数时使用寄存器而非基于栈的机制来存储返回地址。在此方案中,编译器通常在执行CALL指令前(通常通过MOV指令)将返回地址存入寄存器 。在函数内部,RET指令使用相同的寄存器返回调用函数。CALL和RET指令带有微调其行为的修饰符。
E. BMOV、BSSY、BSYNC和BREAK指令
我们的研究表明,编译器会在程序流中插入 BMOV、BSSY、BSYNC 和 BREAK 指令,以辅助控制流管理机制在分支后进行线程重聚合。++这些指令对 CUDA 或 PTX 程序员不可见,仅由编译器添加到程序中++。
BSYNC指令用于重聚合点,以在分支分叉后重新聚合线程束中的线程。在 BSYNC 点而非 IPDom 点重聚合,允许重聚合早于或晚于 IPDom 点发生。更早的重聚合可以提升某些非结构化控制流程序的性能(详见第六-B节),而更晚的重聚合对于避免 Volta 前 GPU 中出现的 SIMT 引发死锁 是必要的(详见第六-C节)。++英伟达的编译器分析源代码,并在程序流的适当位置插入 BSYNC。这个位置可以是IPDom点或其他位置++。
BSYNC 指令仅接受一个操作数,即一个由 Bx 表示的特殊用途寄存器。Bx 寄存器中存储的值对于理解 BSYNC 至关重要。遗憾的是,英伟达的二进制插桩工具 NVBit 不捕获这些寄存器的值,这与通用寄存器不同。然而,BMOV 指令可在 Bx 和 Rx 寄存器之间传输值。因此,通过读取 Rx 值,我们可以间接获取 Bx 值。++我们发现 Bx 寄存器存储着一个掩码。进一步研究揭示,此掩码指示 BSYNC 必须重聚合线程束中的哪些线程。本文中我们称此掩码为重聚合掩码。例如,如果 B0 中的重聚合掩码是 1100,则指令 BSYNC B0 将仅重聚合线程2和3。++
读取 Bx 值也帮助我们理解了 BSSY 指令的语义。BSSY 指令初始化一个 Bx 寄存器,并通过一条指令的 PC 指定重聚合点。该 PC 始终指向一条 BSYNC 指令。++Bx 被初始化为一个掩码,该掩码指示****执行 BSSY 指令时线程束中哪些线程是活动的。此掩码即代表****重聚合掩码,因为导致分叉的分支前总有一条 BSSY 指令。++ 因此,重聚合掩码中标示的线程束中的所有线程,在因分支分叉之前都已执行过该 BSSY 指令。例如,如果线程束的线程2和3在分支前执行了 BSSY B0, 1000【注,1000 必指向一条 BSYNC 指令】,我们必须将 B0 初始化为1100。地址 1000 处的 BSYNC B0 将读取 B0 并重聚合线程2和3。
我们还发现,当重聚合点不在 IPDom 点时,BREAK 指令对于避免死锁是必需的。根据定义,++所有分叉线程必须在程序结束前经过 IPDom 点++ 。然而,并不能保证所有分叉线程都会经过这些非 IPDom 的重聚合点。因此,线程束中的某些分叉线程可能永远不会到达其指定的重聚合点 。在重聚合点等待这些线程会导致死锁,除非 BREAK 指令将它们从重聚合掩码中移除。第六-B节将详细阐述当重聚合点早于 IPDom 点时,如何使用 BREAK 指令避免死锁。
BREAK 指令接受一个或两个谓词以及一个 Bx 寄存器。谓词决定线程束中的哪些线程必须从 Bx 寄存器的重聚合掩码中移除。被移除的线程将不会与掩码中存在的其他活动线程重聚合。例如,@P0 BREAK !P1, B0,将从 B0的重聚合掩码中移除那些P0为真且P1为假的线程。此后,BSYNC B0 指令将不再等待这些被移除的线程,除非有其他指令改变了B0。
F. WARPSYNC指令
WARPSYNC 指令用于同步线程束中的线程,类似于 BSYNC 指令。该指令仅接受一个操作数,即一个指示线程束中哪些线程必须同步的掩码 。此掩码的定义与 BSYNC 指令中的重聚合掩码相同,因此我们使用相同的名称来指代它们。WARPSYNC 中的重聚合掩码存储在一个 Rx 寄存器或一个立即数中。例如,WARPSYNC 1100同步线程2和3,当 R0 为线程2和3包含1100时,其效果与 WARPSYNC R0完全相同。
G. YIELD指令
我们根据几个关键观察定义了 YIELD 指令的语义。我们观察到,线程束内的线程仅在分支处分叉,并在 BSYNC 或 WARPSYNC 指令处重聚合。对于所有其他指令,线程束内的线程以锁步方式执行 【注,?】。此外,我们还观察到,不同路径的交错执行****仅作为执行 YIELD 指令的结果而发生。
基于这些观察,我们得出结论:除非执行了 YIELD 指令,否则分支的两条路径是按顺序先后调度的。YIELD 指令会导致控制流切换到一条新路径。YIELD 指令没有任何操作数来指示接下来必须调度哪条路径。我们假设它必须是兄弟路径(sibling path),因为这符合我们在实验中观察到的硬件控制流轨迹,且不需要昂贵的微架构支持。如果不存在兄弟路径,则继续执行 YIELD 之后的指令。
YIELD 的这个定义放宽了 Volta 前 GPU 在调度线程束分叉线程时的第一项约束(见第三节)。基于该约束,Volta 前 GPU 从不交错执行不同路径,而 Volta 后如图灵等 GPU 则使用 YIELD 指令来实现此目的。因此,YIELD 可以解决 Volta 前 GPU 中由第一项约束引起的一些 SIMT 引发死锁。
我们设计了一个实验来验证英伟达使用 YIELD 解决其中一些死锁。我们从 图3 所示源代码的二进制文件中移除了 YIELD 指令。这段源代码是 Volta 前 GPU 中 SIMT 引发死锁的一个著名示例(见第三节 )。++原始程序在图灵 GPU 上可以完成,但移除 YIELD 后,程序永远不会结束++ 。这个实验证实,图灵依赖 YIELD 指令来避免 Volta 前 GPU 中存在的某些 SIMT 引发死锁。由于 YIELD 仅对编译器可见,英伟达编译器的算法通过在适当位置插入YIELD 指令对于解决这些死锁至关重要(更多细节见第六-C节)。
VI. 图灵控制流指令的实际应用
图灵架构中的控制流管理机制在多种场景下运用控制流指令。本节阐述其在三个实际案例中的应用:1) 嵌套分支后的线程重聚合,2) 早于IPDom点的重聚合,以及3) 自旋锁实现。
A. 嵌套分支后的重聚合
嵌套分支可能导致嵌套的线程分叉,这需要多个 Bx 寄存器来存储****重聚合掩码。理论上最多可能需要 31个 Bx 寄存器,因为一个线程束的 32 个线程最多可分别进入32条不同路径。然而,英伟达使用更少的Bx寄存器,并将其值溢出到Rx寄存器以节省硬件资源。为此,BMOV 指令在 Bx 和 Rx 寄存器之间传输值。研究表明,许多 Rx 寄存器在运行期间处于闲置状态,因此它们是重聚合点使用前临时存储 Bx 寄存器值的良好选择。
在嵌套线程分叉场景中,BMOV、BSSY 和 BSYNC 指令的使用顺序至关重要。BSSY 初始化一个 Bx 寄存器,BSYNC 使用该寄存器强制重聚合。Bx 中的值必须在初始化后移至 Rx 寄存器,并在重聚合点前移回 Bx 。如果需要将 Bx 重新分配给一个新的重聚合掩码(用于在嵌套分支后重聚合分叉线程),那么,这种数据传输是必要的。
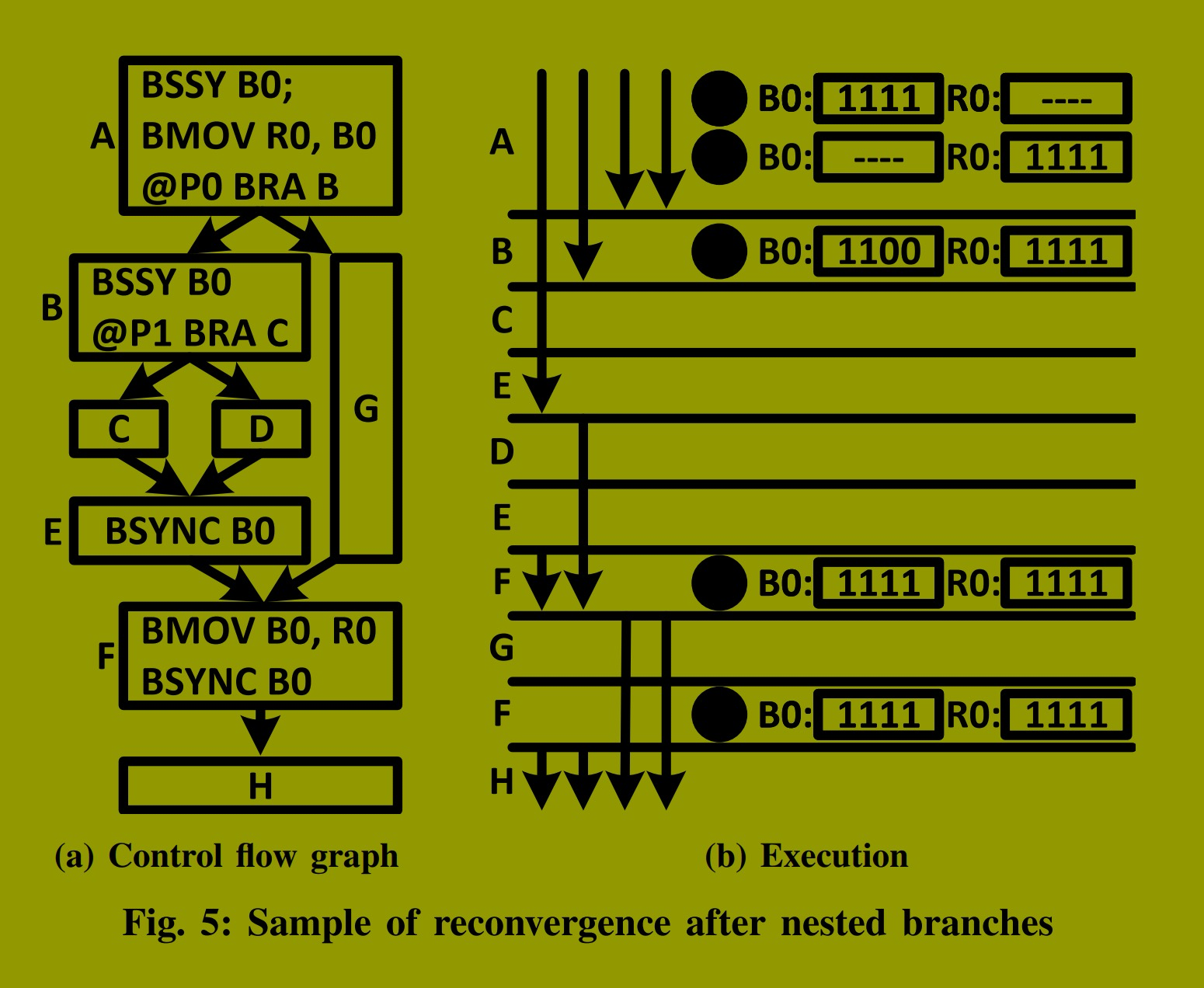
图5 展示了一个具有两次嵌套线程分叉的示例程序中的 BSSY、BSYNC 和 BMOV 指令。该程序的控制流图如 图5a 所示,图5b 表示了一个示例线程束在执行期间更新寄存器的情况。控制流图中的基本块可能包含更多指令,但我们仅展示了控制流指令及其在基本块内的正确顺序 。通过多次实验,我们观察到执行 BMOV 指令的所有活动线程在 Rx 寄存器中读取或写入相同的值。因此,在 图5b 中,我们仅表示执行 BMOV 指令的其中一个活动线程的Rx值 。我们用虚线表示寄存器中的无效值。在此示例中,重聚合****在 BSYNC 指令处强制执行,且分支分叉后优先执行 taken 路径。我们观察到,英伟达优先执行大多数线程遵循的路径,但这只是一种优化。英伟达编译器生成的二进制码,其正确执行并不依赖于控制流管理机制在运行时优先执行 taken 或 not-taken 路径。
在此示例中,B0 在两个 BSYNC 指令中使用:一个在 E处,用于重聚合线程2和3;另一个在F处,用于重聚所有线程。每个 BSYNC 指令都需要一条 BSSY 指令来用重聚合掩码初始化 B0 寄存器。F处的 BSYNC 需要A处的一条 BSSY 来将 B0 初始化为1111(步骤 1 ),而E处的 BSYNC 需要B处的一条 BSSY 来将 B0 初始化为1100(步骤 3 )。由于B在A之后执行,它会覆盖B0中的值。但之后在F处重聚所有线程需要这个值(即重聚合掩码)。为避免B执行时丢失此值,A处的一条 BMOV 将 B0 复制到 R0(步骤 2 )。该值保留在R0中,直到F处的 BSYNC 需要它。在此之前,F处的一条 BMOV 将此值从R0取回并写回B0(步骤 4 , 5 )。此例说明了在此嵌套线程分叉场景中,BMOV 如何利用 R0 寄存器作为 B0 寄存器的备份。
通过这种方式,英伟达避免了为处理最坏嵌套场景而增加Bx寄存器数量。如果可用 Bx 寄存器不足,英伟达编译器会在程序中插入 BMOV 指令,将 Bx 值溢出到 Rx 寄存器。
B. 早于IPDom点的重聚合
使用 BSYNC 指令进行重聚合的优势在于,允许重聚合点早于或晚于 IPDom 点。更早的重聚合可以提升某些非结构化控制流程序的性能。然而,在重聚合点早于 IPDom 点的场景中,控制流指令的错误使用可能导致死锁。发生死锁的原因是,一个较早的重聚合点并非 IPDom 点,而所有分叉线程必须在程序结束前经过 IPDom 点。换言之,某些分叉线程可能永远不会到达一个较早的重聚合点,因此在重聚合点等待它们可能导致死锁。
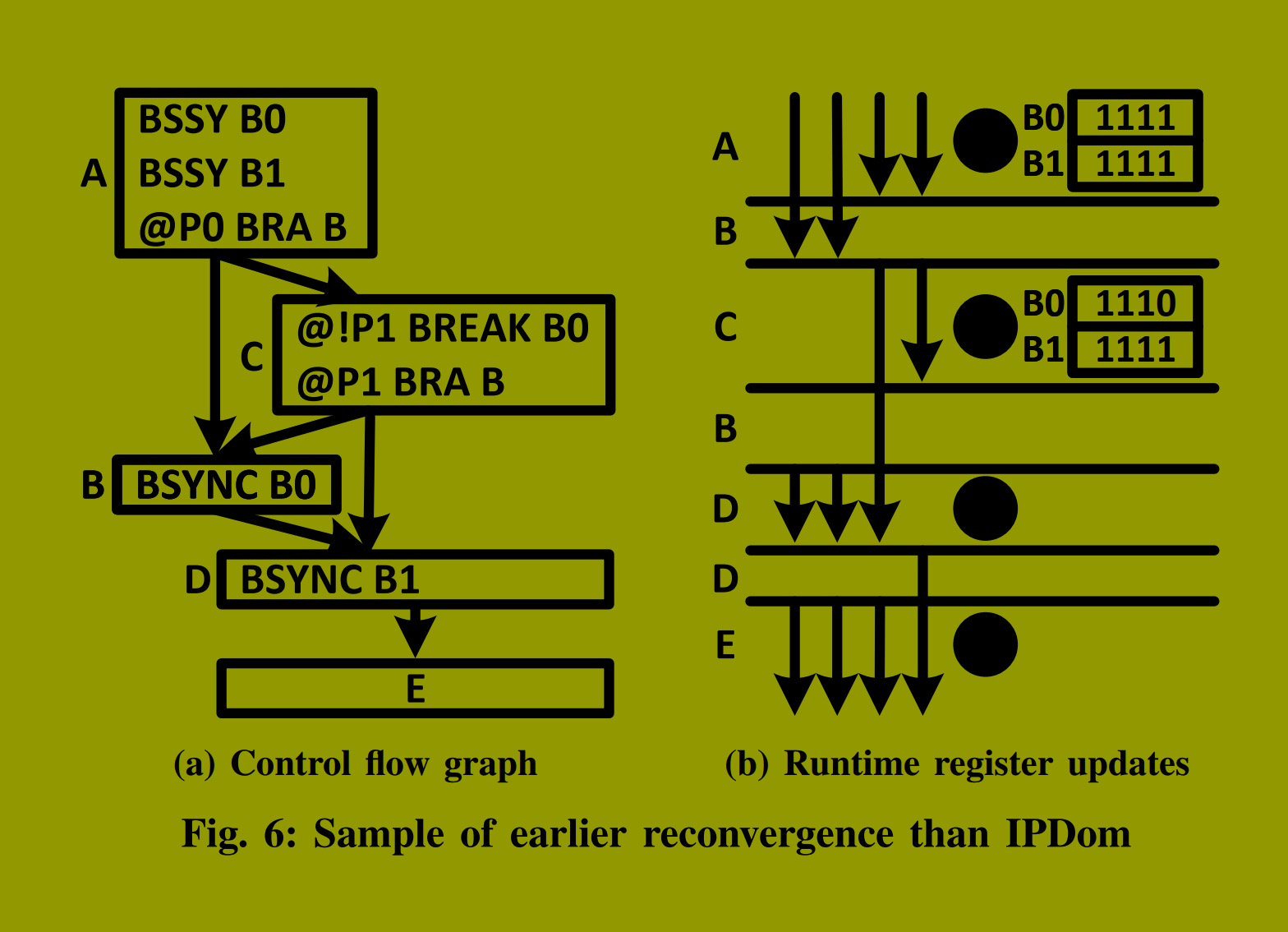
图6 展示了一个可以实现早期重聚合的示例程序。图6a 描述了程序的控制流图,图6b 展示了一个线程束执行期间的寄存器更新情况。为简化起见,虽然每个基本块可能包含更多指令,但我们仅显示控制流指令。英伟达编译器按照图中所示的相同顺序,在每个基本块中插入控制流指令。我们假设taken路径先于not-taken路径执行,且线程束内的线程在BSYNC指令后重聚合。
在此示例中,D是A的IPDom点,因为这是所有线程在结束前都会经过的最早点。然而,线程0在A处分叉后从未经过B,而是在结束前执行C、D和E。因此,B不能是A的IPDom点,因为根据定义所有分叉线程必须经过IPDom点。但是,B可以作为该线程束中线程1、2和3的早期重聚合点,因为它们都可以在执行D之前在此点重聚。
此例中包含两条BSYNC指令,用于重聚在A处分叉后的线程束内的线程:一条插入在B处,另一条在D处。这些BSYNC指令从B0和B1读取其重聚合掩码,这两个寄存器在分叉前的A处初始化。A处的两条BSSY指令将B0和B1初始化为1111,因为线程束的所有线程一起执行BSSY指令(步骤 1 )。如果B0中的值不改变,此程序将因死锁而无法完成。
死锁的发生是因为B0包含1111,并被B处的BSYNC使用,这意味着线程束的所有线程必须在B之后重聚合。然而,线程束中的线程0从未执行B。因此,线程束中所有其他线程等待线程0执行B将永远被阻塞。
为解决此问题,在C处插入一条BREAK指令。BREAK将所有在C处P1为假的线程从B0的重聚合掩码中移除。这些线程在执行C处的分支指令后将分叉至D,并且永远不会再执行B。在此例中,我们假设只有线程0在执行C处的BREAK时P1为假。从B0中移除线程0将其值改为1110,这即是B处的重聚合掩码(步骤 2 )。因此,只有线程1、2和3在B后重聚(步骤 3 ),并且它们永远不会等待线程0。线程0在D后与它们汇合(步骤 4 ),此后程序再无分叉。此例表明,如果我们在C处添加BREAK,则早期重聚合在B处强制执行,程序正确完成且无任何死锁。这个例子强调了编译器可以通过在程序中正确位置插入控制流指令,来辅助控制流管理机制实现比IPDom点更早的线程重聚合。
C. 自旋锁实现
如图3所示的CUDA自旋锁实现在Volta前的GPU中会导致众所周知的SIMT引发死锁,原因有两项约束:1) Volta前GPU在IPDom点强制重聚合,2) 它们串行执行分叉路径(详见第三节)。图灵在编译器的帮助下移除了这些约束,从而避免了这种死锁。如果会导致死锁,编译器不会将BSYNC放在IPDom点,并且当执行相同路径可能导致死锁时,会插入YIELD来切换到兄弟路径。
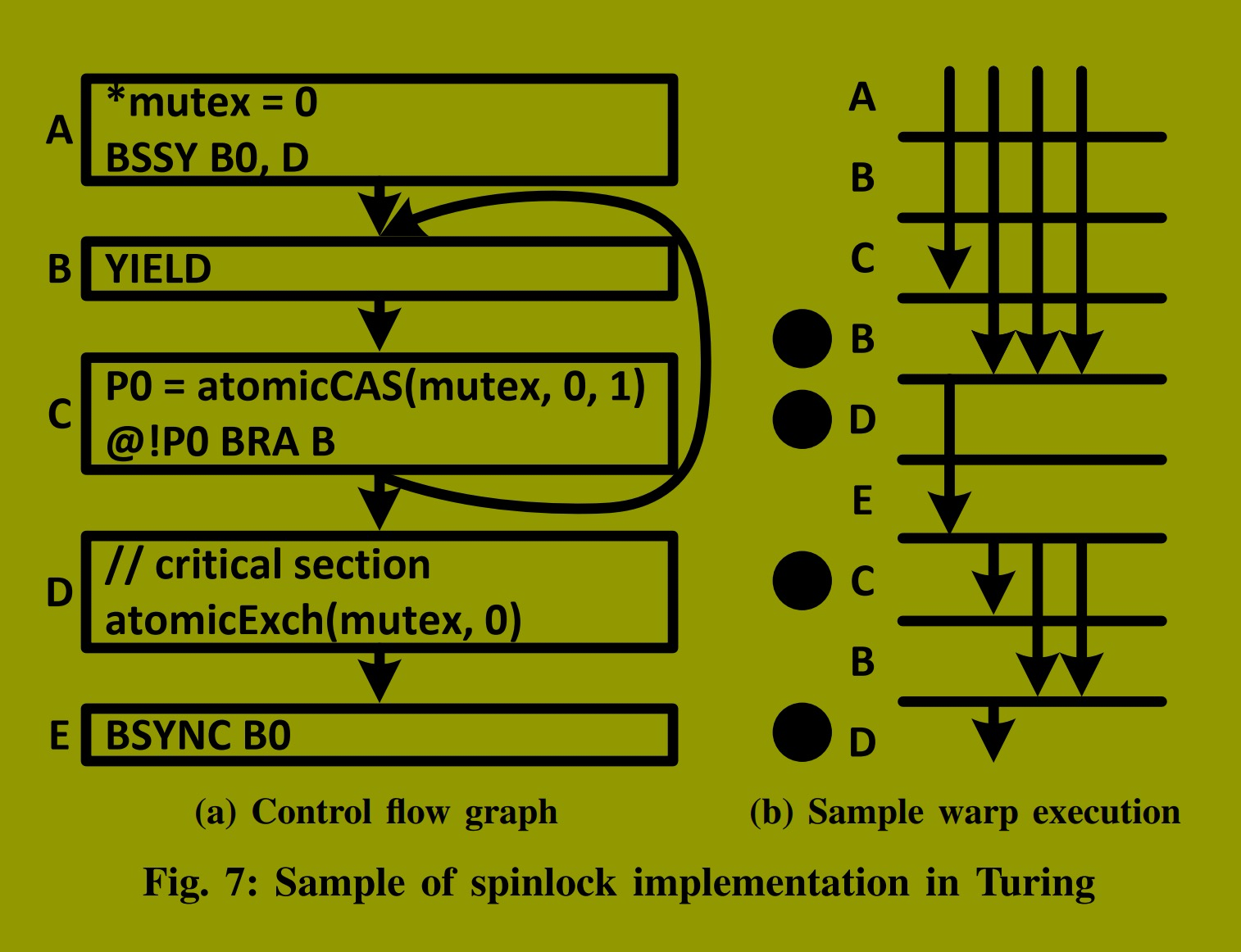
图7阐明了BSYNC和YIELD在图3所示的自旋锁实现中防止死锁的关键作用。图7a展示了该实现添加图灵控制流指令后的控制流图。图7b展示了一个示例线程束的可能执行过程,假设分叉后taken路径先于not-taken路径执行。在taken路径完成前,YIELD介入并将执行切换到not-taken路径。YIELD对于避免死锁是必要的------我们观察到如果从程序二进制码中移除它,程序的执行将永远不会结束。
该程序的临界区位于D处,紧接在循环之后。在循环内部,线程竞争获取锁以获得执行临界区的权限。其中只有一个线程获取锁并在执行C时将P0设为true。该线程与线程束中的其他线程分叉,退出循环以执行临界区。在临界区之后,它释放锁,允许另一个线程获取锁并进入临界区。
在此示例中,线程3获取了锁并与线程束中的其他线程分叉,但并未立即执行临界区,因为taken路径优先级更高,必须先执行。因此,线程0、1和2跳转到循环起点并执行YIELD(步骤 1 )。如果不存在这个YIELD,这些线程将永远无法获取锁,因为线程3仍持有锁。因此,这些线程将永远被困在循环中。然而,YIELD解决了这个问题,并将执行切换到兄弟路径D(步骤 2 )。线程3执行D处的临界区并释放锁。然后,它执行E处的BSYNC,该指令用于重聚所有线程。之后,线程3保持阻塞,直到所有其他线程执行此BSYNC。在此场景中,所有其他线程从C(步骤 3 )继续执行,即YIELD后的下一条指令。这次,其中一个线程可以获取锁,因为线程3已经释放了它。在此例中,线程2获取了锁并执行临界区(步骤 4 )。
如果E处的BSYNC放在释放锁之前,同样会导致死锁。死锁将发生,因为持有锁的线程无限等待与线程束中其他线程重聚合,但其他线程因无法获取锁和退出循环而被困在循环中。在此程序中,IPDom点紧接在分支之后,即在释放锁之前。因此,在检测到死锁场景后,英伟达编译器决定将BSYNC置于IPDom点之后的E处(在锁被释放之后)。
VII. HANOI微架构设计
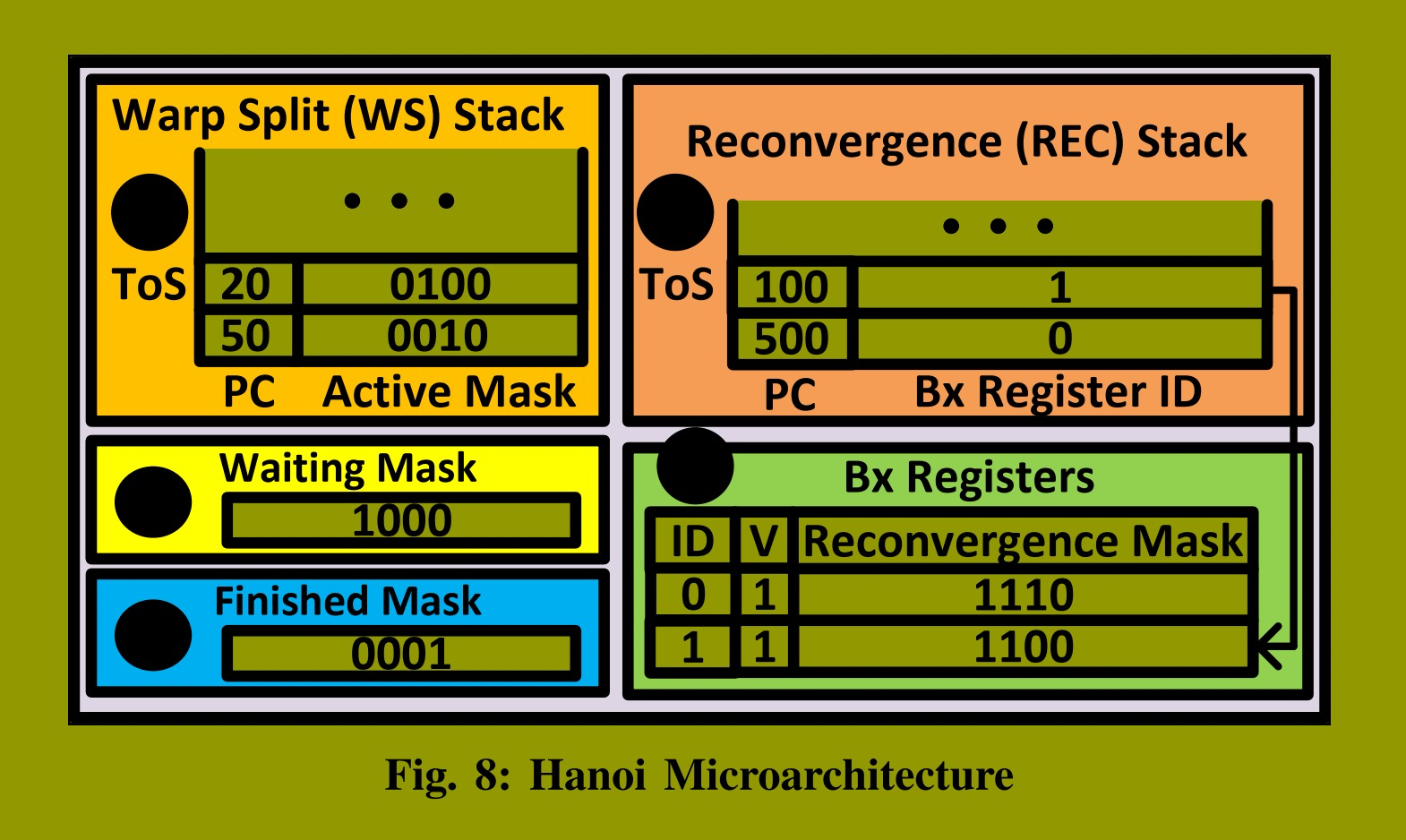
图8展示了我们为图灵架构提出的控制流管理机制设计方案------Hanoi。该设计包含两个堆栈:线程束分叉栈 (图 1 )和重聚合栈 (图 2 )。它还包括若干Bx寄存器(图 3)以及两个掩码:等待掩码 (图 4 )和完成掩码 (图 5)。
WS栈为每个待执行的路径保存一个条目,每个条目包含一个程序计数器(PC)和一个活动掩码。WS栈中的路径按栈顺序执行,栈顶条目对应当前正在执行的路径。活动掩码指示线程束中哪些线程遵循此路径,而PC指定这些线程下一条必须执行的指令。图中,线程2被设置在一个路径中执行指令20,线程1被设置在另一个路径中执行指令50。
REC栈为每个重聚合点保存一个条目,每个条目包含一个PC和一个Bx寄存器标识符(ID)。重聚合按其在REC栈中的顺序发生。栈顶条目对应当前正在执行的路径。PC指向线程在重聚合后必须执行的指令,Bx寄存器ID引用包含重聚合掩码的Bx寄存器。重聚合掩码指示线程束中哪些线程必须在该重聚合点重聚。只有当有效位(V)设置为1时,Bx寄存器才包含有效的重聚合掩码。图中显示了两个重聚合点:一个在PC 100处,另一个在PC 500处。REC栈中PC 100处重聚合点的条目引用B1,其中包含的重聚合掩码指示线程2和3必须在此点重聚。PC 500处重聚合的条目引用B0,其包含的重聚合掩码指示线程2和3必须在此点与线程1汇合。
等待掩码指示哪些线程在当前重聚合点(即REC栈顶条目对应的点)等待。图中,线程3已到达其位于PC 100处的重聚合点。完成掩码跟踪哪些线程已执行EXIT指令并已完成。图中,线程0已完成。
A. 管理Bx寄存器
BSSY指令用于初始化Bx寄存器。它使用操作数中的Bx寄存器ID来寻址特定的Bx寄存器。该Bx寄存器被初始化为执行此BSSY指令的线程束中活动线程的集合。这些线程正是WS栈顶条目活动掩码所指示的那些。因此,当执行BSSY时,此活动掩码被复制到指定的Bx寄存器,其有效位被设为1。
BREAK指令用于更新Bx寄存器。它通过ID寻址一个Bx寄存器,并从其存储的重聚合掩码中移除特定的线程。这种更新是可行的,因为REC栈中的重聚合点从Bx寄存器读取它们的重聚合掩码。换句话说,它们间接引用包含其重聚合掩码的Bx寄存器。如果重聚合掩码直接存储在REC条目中,则无法从非栈顶条目的重聚合掩码中移除线程。
BMOV指令在Bx寄存器和Rx寄存器之间传输数据。当BMOV指令将Bx寄存器值移至Rx寄存器时,它会使Bx寄存器失效。当将值移回Bx寄存器时,其有效位再次被设置为1。BMOV指令用于在不同重聚合点之间共享Bx寄存器。换句话说,REC栈中的多个条目可能引用同一个Bx寄存器。然而,仅当条目处于REC栈顶时才会读取Bx寄存器。因此,只要在需要该值的重聚合点成为REC栈顶条目并被程序执行到之前,将该值从Rx寄存器移回,BMOV指令就可以将值从Bx寄存器移至Rx寄存器。
EXIT指令完成线程的执行。一旦执行EXIT指令,Hanoi会从所有Bx寄存器中移除已完成的线程,并将它们添加到完成掩码中。在将重聚合掩码从Rx寄存器写回Bx寄存器之前,必须从此掩码中移除完成掩码中的线程。此步骤对于确保正确的控制流是必要的,因为当重聚合掩码存储在Rx中时,一些线程可能已经完成。
当重聚合发生时,位于Bx寄存器中的该重聚合点的重聚合掩码不再需要。因此,包含该重聚合掩码的Bx寄存器被置为无效。
B. 管理REC栈
当重聚合发生时,Hanoi从REC栈弹出栈顶条目,从其Bx寄存器中取出重聚合掩码,并将一个新条目压入WS栈。这个新条目包含来自REC栈顶条目的PC和重聚合掩码。因此,对于重聚合掩码中的所有线程,执行从重聚合点之后的指令继续。
Hanoi使用等待掩码来确定何时必须重聚合线程,这对于执行期间正确遍历控制流图至关重要。在调度WS栈顶条目之前,Hanoi检查REC栈顶条目的重聚合掩码是否有效,并且是否完全出现在等待掩码中。如果是,则重聚合掩码中的所有线程都已到达重聚合点,是时候进行重聚合了。如果REC栈顶条目的Bx寄存器无效,Hanoi绝不会重聚合线程,因为该Bx寄存器可能已被另一个重聚合点覆盖和使用。
Hanoi使用REC栈在BSYNC或WARPSYNC指令处进行重聚合。虽然两条指令都重聚线程束内的线程,但它们有显著差异,需要不同的处理。
在每条BSYNC指令之前,都有一条对应的BSSY指令,用于指定重聚合点的PC以及保存重聚合掩码的Bx寄存器ID。执行BSSY后,Hanoi将一个包含指定重聚合PC和Bx寄存器ID的条目压入REC栈。
相比之下,WARPSYNC没有像BSSY那样的前置指令,并且没有Bx操作数。对于WARPSYNC,Hanoi必须分配一个空的Bx寄存器,并用重聚合掩码初始化它。我们假设总是有空闲的Bx寄存器可用;如果没有,编译器可以使用BMOV指令将它们溢出到Rx寄存器。WARPSYNC之后指令的PC成为其REC栈条目中的重聚合PC,因为这是线程重聚合后继续执行的地方。重聚合PC和分配的Bx寄存器ID构成了为WARPSYNC指令压入REC栈的条目。然而,这仅针对执行WARPSYNC指令的重聚合掩码中的第一个线程子集进行。对于其他子集,该条目已存在于REC栈上,因此Hanoi不会再次压入。
如上述,拥有一个独立的栈(REC栈)来追踪重聚合点,使得Hanoi能够高效处理WARPSYNC指令。在仅使用一个栈的替代机制中,支持WARPSYNC指令要么不可能,要么效率极低。这是因为,在使用单一栈的机制中,必须在分叉发生前指定重聚合点,以便正确更新栈并在该点重聚线程。然而,当执行WARPSYNC时,我们只知道线程可能在WARPSYNC之前的某个地方分叉,但不知道具体位置。因此,更新栈以在WARPSYNC执行时正确重聚线程是不可能的或效率低下的。
C. 管理WS栈
由于BSYNC、WARPSYNC、EXIT、BRA和YIELD指令,Hanoi可能会向WS栈压入或弹出条目。对于其他指令,只需更新WS栈顶条目的PC。一些指令,如CALL和RET,会改变PC以跳转到函数或从函数返回。然而,对于大多数指令,只需递增PC指向下一条指令即可。
BRA指令可能导致线程分叉,从而压入两个条目:一个用于taken路径,另一个用于not-taken路径。我们的观察表明,多数线程遵循的路径会首先执行,因此Hanoi将此路径压入到另一路径之后。
当一条路径完成时,必须弹出一个条目。当执行BSYNC、WARPSYNC或EXIT指令时,路径被视为完成。执行BSYNC或WARPSYNC后,Hanoi弹出该条目,并将其活动线程添加到等待掩码中。然而,对于EXIT指令,仅当路径中的所有线程都执行EXIT时,才会从WS栈弹出条目。一些线程可能被谓词屏蔽而未执行EXIT。对于它们,将在下一个周期执行EXIT之后的指令。Hanoi将执行EXIT的线程添加到完成掩码中。
当执行YIELD指令时,Hanoi会切换到兄弟路径(如果存在)。切换到非兄弟路径会产生错误的控制流。如果存在兄弟路径,其条目紧邻WS栈顶条目之下。因此,在执行YIELD指令时,Hanoi只需交换WS栈顶的两个条目即可切换到兄弟路径。然而,一条路径之下可能存在不属于其兄弟的条目。仅当路径共享一个共同的重聚合点时,它们才是兄弟路径,而该共同重聚合点总是由REC栈顶条目表示。因此,为了确定WS栈顶的两条路径是否是兄弟,Hanoi将它们活动掩码的并集与REC栈顶条目的重聚合掩码进行比较。如果该并集是重聚合掩码的子集,则这些路径是兄弟路径;否则不是。例如,在图8中,线程1和2位于WS栈顶的两个条目中。然而,这两条路径不是兄弟路径,因为REC栈顶条目的重聚合掩码不包含线程1。因此,执行YIELD指令不会切换到任何其他路径,其行为类似于空操作(NOP)。
VIII. 方法论
我们利用英伟达工具为一系列广为人知的基准测试生成了原生汇编源代码、控制流图以及执行轨迹,相关信息总结在表II中。具体而言,我们使用 cuobjdump 生成SASS代码,nvdisasm 生成控制流图,NVBit 生成执行轨迹。对于部分基准测试,我们使用了不同的输入数据集,这通过其名称前的数字加以区分(贯穿全文)。通过对这些基准测试的深入分析,我们识别出图灵GPU中控制流指令的定义、使用方式以及控制流管理机制处理这些指令的模式、场景和用例。基于此分析,我们能够就图灵控制流指令的语义及控制流管理机制的详细策略,形成一系列合理且直观的假设。

随后,我们开发了一个验证程序来检验这些假设。我们分别为控制流图、SASS代码和执行轨迹编写了解析器。解析这些文件后,我们将数据加载到验证程序中,该程序会检查从实际硬件获取的轨迹是否违反了我们的任何假设。例如,如果我们假设交错执行仅发生在YIELD指令之后,而轨迹显示在其他点发生了交错,这就构成了违反。一旦出现违反情况,程序会生成日志文件以提供违规原因的洞察。然后,我们据此完善假设并重复此过程。我们的目标是建立一套在所有基准测试中均未被违反的假设集合,从而解释图灵控制流管理机制中控制流指令的语义以及所采用的详细策略。
鉴于英伟达使用了运行时启发式方法,要发现并将所有这些方法纳入我们的假设集极具挑战性。然而,我们成功揭示了其中许多方法,使得我们的设计------Hanoi------的运行机制与图灵的设计非常接近。为了衡量这种接近程度,我们基于假设设计了Hanoi,并生成了其控制流轨迹。接着,我们将此轨迹与图灵的轨迹进行比较,并对我们的设计进行微调,以最小化任何差异。为了评估这些差异对性能的影响,我们在一个名为 Accel-Sim 的著名轨迹驱动模拟器中使用了 Hanoi 的轨迹,并将测得的性能与使用图灵轨迹的基线进行了比较。在我们的性能模拟中,我们采用了英伟达 RTX 2060 的配置,具体细节见表III。
IX. 评估
我们建立了一套关于图灵控制流管理机制中控制流指令语义及其详细策略的假设。基于这些假设,我们设计了Hanoi,并对假设和设计进行了反复优化,使其与图灵架构高度吻合,最终形成了第8节中描述的设计。
为评估Hanoi与图灵设计的接近程度,我们比较了它们的控制流轨迹。控制流轨迹显示了每个线程束从程序开始到结束所执行的指令序列。如果特定线程束在Hanoi和图灵中拥有完全一致的控制流轨迹,则意味着两种设计在每个周期都调度了该线程束中完全相同的线程集合执行。然而,序列的显著差异并不必然意味着设计之间存在实质性差异。诸如在分支分叉后优先执行taken路径而非not-taken路径这样的微小改变,就可能导致显著不同的控制流轨迹。
控制流轨迹本质上是一个指令序列。为了比较它们,我们使用了莱文斯坦距离。该距离衡量将一个轨迹转换为另一个轨迹所需的最小插入、删除或更新的操作次数。我们将此距离除以轨迹长度,计算出一个指标,用以表示两个轨迹之间的百分比差异。
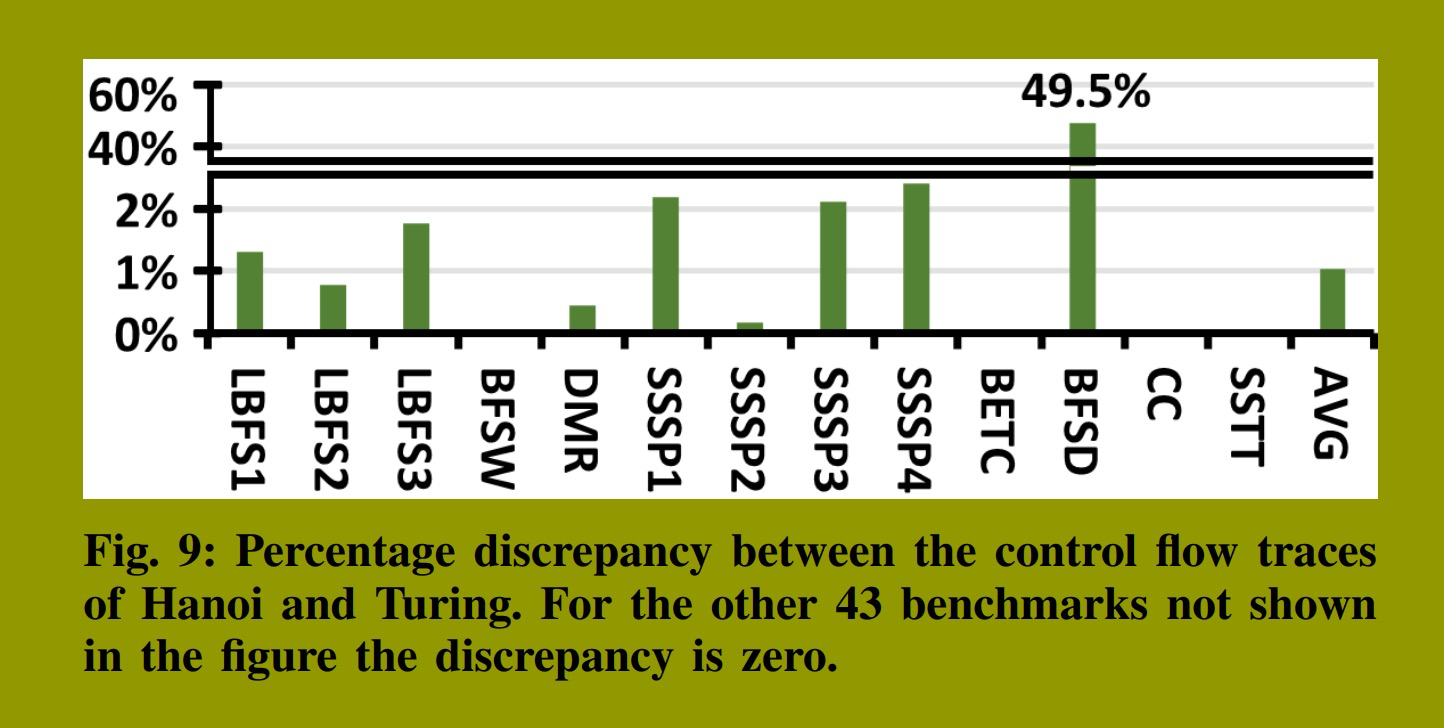
我们分析了59个程序的执行情况:包括41个不同的基准测试以及其中18个使用了不同输入数据的变体。在这59个样本中,有46个的差异率为0%,这表明Hanoi与图灵生成了完全相同的控制流轨迹。其余执行的差异情况如图9所示。除BFSD外,所有基准测试的差异百分比均低于2.4%,平均差异仅为1%。BFSD的高差异率(49.5%)源于图灵使用的一项运行时启发式策略,而Hanoi并未支持该策略。Hanoi会在所有BSYNC指令处强制执行重聚合,而图灵在极少数情况下出于性能考虑会忽略这些重聚合操作。
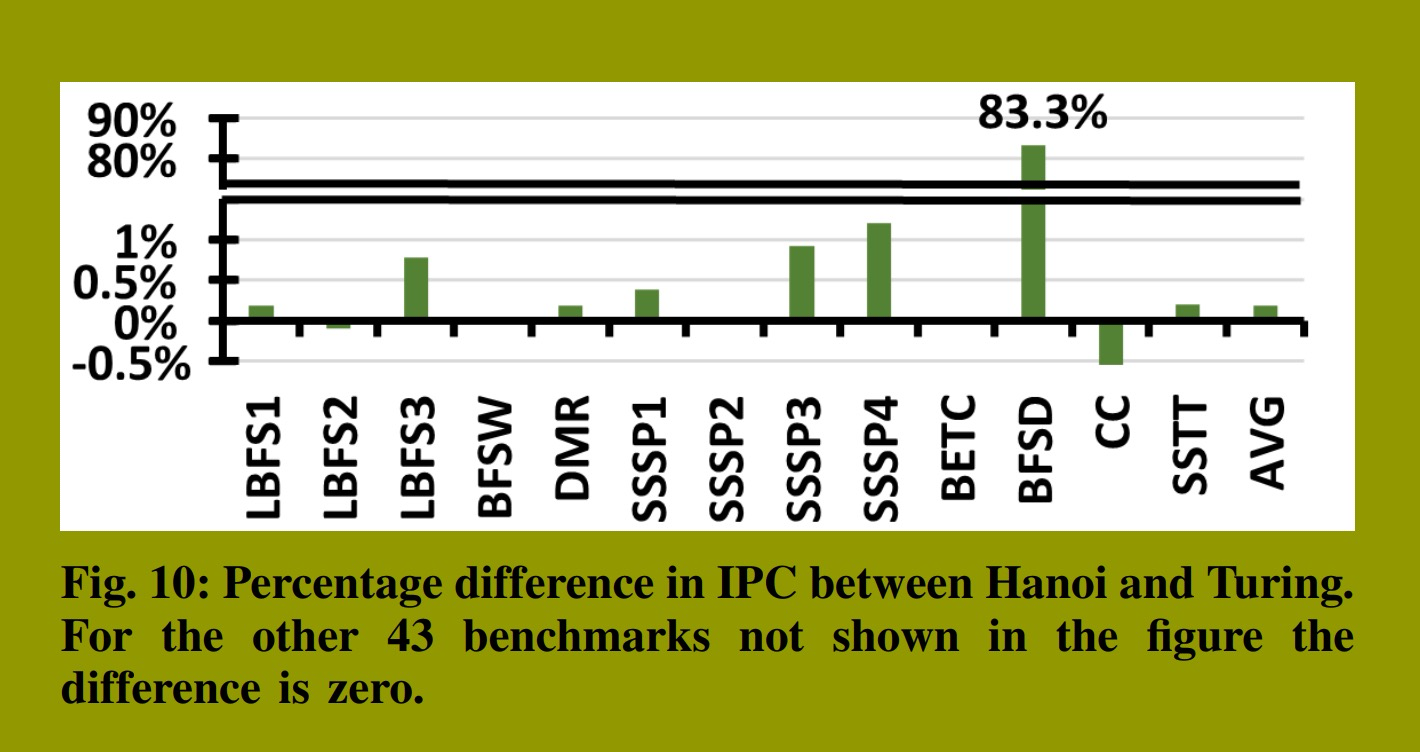
图10展示了这些差异对性能的影响。我们计算了Hanoi与图灵之间的相对IPC差异。平均差异为0.2%,可忽略不计。除BFSD外,所有其他基准测试的性能影响均低于1.2%。然而,BFSD在Hanoi中显示出83.3%的性能提升。这一提升源于Hanoi在所有BSYNC指令处强制执行重聚合,这使得SIMD单元利用率提高了31.9%,从而带来了显著的性能改进。
A. 硬件开销
Hanoi是一种轻量级方案,可无缝集成到GPU流水线中,如图2所示。它无需增加指令缓冲区大小,也不会给记分板带来显著开销。记分板仅需扩展以追踪少数Bx寄存器之间的依赖性。Hanoi中的WS栈最多需要32个条目,以支持一个线程束的32个线程全部分叉的最坏情况。在这种情况下,REC栈需要31个条目来重聚合这些线程。管理WS和REC栈的成本也很低,因为它们采用栈结构管理。WS栈中的每个条目仅包含一个PC和一个32位掩码,比SIMT栈更简单,后者在这些字段之外还需要一个重聚合PC。虽然SIMT栈通过比较重聚合PC与当前PC来确定何时弹出条目,但Hanoi在执行WARPSYNC、BSYNC或EXIT指令时会弹出条目。REC栈中的每个条目也具有很高的成本效益;它仅包含一个PC和一个指向Bx寄存器的索引。由于Bx寄存器可以在REC条目之间共享,因此只需少量即可。例如,在一个拥有8个Bx寄存器的系统中,3位索引位就足够了。等待掩码和完成掩码也仅为32位掩码。总体而言,对于一个包含8个Bx寄存器的设计,Hanoi所需的总存储量为432字节,这个开销可以忽略不计,且比SIMT栈所需的存储量减少了近43%。
X. 相关工作
英伟达等GPU厂商从未完全公开其控制流管理机制。然而,他们在早期出版物和文档中披露了部分内容。研究人员通过微基准测试发现了更多细节,使得SIMT栈设计被广泛接受为基准方案。基于此,研究人员开发了如GPGPU-Sim等性能模拟器,这些模拟器执行PTX指令,足以应对早期GPU和传统工作负载。然而,模拟使用诸如cuDNN和cuBLAS等闭源库的现代工作负载无法通过PTX实现。为解决此问题,研究人员开发了支持SASS指令的追踪驱动模拟器,如Accel-Sim。
Accel-Sim依赖追踪信息获取控制流,但由于对Volta等现代GPU的细节信息不足,并未对控制流机制的功能进行建模。Volta引入了一项名为"独立线程调度"的新特性,导致英伟达执行模型发生重大变化,这表明控制流管理机制也发生了实质性改变。尽管如此,公开信息依然匮乏,即使是那些已经揭秘了Volta和图灵等现代GPU的研究人员,也未曾披露此机制的细节。
据我们所知,本文首次描述了在现代英伟达GPU二进制文件中遇到的控制流指令语义,并提出了一种支持这些指令的控制流机制实现------Hanoi。支持这些指令使得Hanoi的微架构与文献中其他方案相比有显著不同。
例如,Hanoi执行一条路径,并可在YIELD指令后切换到其兄弟路径。这种软件控制的交错执行需要简单的硬件支持,并能提供更具可预测性的控制流,从而可用于优化GPU中的其他组件。其他方案也支持交错执行,但它们都采用运行时细粒度交错,需要复杂得多的硬件。DWS方案需要一个表和路径调度器,而不是Hanoi中的WS栈。与Hanoi不同,它忽略某些重聚合点,并尝试在运行时重聚合具有相同PC的线程束分叉。它对路径调度策略敏感,且可能错过重聚合时机。双路径方案通过扩展SIMT栈条目来解决此问题,使每个条目可存储两条活动路径。在任何周期,都可以调度栈顶的两条路径之一。然而,该方案无法支持BREAK和WARPSYNC,因为BREAK需要修改可能不在栈顶的重聚合掩码,而WARPSYNC缺少像BSSY那样的前置指令来确定何时为重聚合压入栈顶。多路径方案允许调度任何路径,但需要为每条路径配备指令缓冲区槽和记分板,这在Hanoi中得以避免,从而节省了巨大开销。线程束分叉和重聚合点也必须存储在随机存取存储器和按内容寻址存储器中,而非Hanoi使用的两个栈。此外,它未提出任何机制来支持WARPSYNC、YIELD、BREAK和EXIT指令。AWARE方案避免了多路径方案的部分开销,但同样未对上述不支持的指令提出任何机制。子线程束交错方案的设计与Hanoi大相径庭,并支持细粒度交错。然而,作者指出该方案的巨大成本使其效益在商业产品中不具备合理性。Hanoi则不然;它基于真实硬件轨迹设计,是轻量级且高性价比的。
与其他方案相比,Hanoi是一种轻量级得多的方案。它是首个将重聚合掩码存储在Bx寄存器中的设计。这些Bx寄存器可被修改以支持BREAK指令。它们可以转移到Rx寄存器,并在重聚合点之间共享。编译器管理数据传输,使得硬件保持简单。共享Bx寄存器还降低了存储线程重聚合所需元数据的成本。Hanoi是首个无需为每条路径和每个重聚合点存储重聚合PC的设计,这与所有其他替代方案不同。它也不需要像多路径或AWARE方案那样为每个重聚合点存储待定掩码。相反,它利用编译器辅助并使用更简单的硬件机制来重聚线程。
其他可以调度来自不同线程束线程的方案与Hanoi完全不同,后者仅调度线程束内的线程。其他提出的在非IPDom点重聚线程的机制要么对路径调度策略敏感,要么使用性能剖析或预言信息。Hanoi则使用BREAK和其他控制流指令来确保在可能时实现更早的重聚合。我们不知道编译器如何插入这些指令,但该机制与文献中的推测性重聚合高度相似。在可能发生死锁时延迟重聚合的方案已被提出过,但在Hanoi中有所不同。与之前的方案不同,Hanoi依赖使用YIELD指令来避免死锁。我们通过实验观察发现,这就是现代英伟达GPU的运作方式,尽管我们不了解英伟达编译器用于检测或插入这些指令的详细算法。
XI. 结论
在本工作中,我们揭示了SASS指令集中控制流指令的语义以及图灵控制流管理机制使用的详细策略。为实现此目标,我们利用了常用基准测试的轨迹和二进制文件中的信息。基于我们的发现和验证过的假设,我们为图灵设计了一个名为Hanoi的控制流管理机制。Hanoi具有高性价比,且生成的控制流轨迹与图灵高度相似。Hanoi与图灵控制流轨迹之间的平均差异百分比为1%,这导致在大量多样化基准测试中,相对IPC差异小于0.2%。
参考文献:
REFERENCES
[1] T. M. Aamodt, W. W. Fung, and T. H. Hetherington, "Inside volta: The
world's most advanced data center gpu," http://gpgpu-sim.org/manual/
index.php/Main Page.
[2] baidu, "Deepbench: Benchmarking deep learning operations on different
hardware," https://github.com/baidu-research/DeepBench, 2020.
12
[3] A. Bakhoda, G. L. Yuan, W. W. L. Fung, H. Wong, and T. M.
Aamodt, "Analyzing cuda workloads using a detailed gpu simulator,"
in International Symposium on Performance Analysis of Systems and
Software (ISPASS), 2009.
[4] A. Betts, N. Chong, A. Donaldson, S. Qadeer, and P. Thomson, "Gpu-
verify: a verifier for gpu kernels," in International Conference on Object
Oriented Programming Systems Languages and Applications (OOPSLA),
ser. OOPSLA '12. New York, NY, USA: Association for Computing
Machinery, 2012, p. 113--132.
[5] S. Chetlur, C. Woolley, P. Vandermersch, J. Cohen, J. Tran, B. Catanzaro,
and E. Shelhamer, "cudnn: Efficient primitives for deep learning," 2014.
[6] K. D. Cooper and L. Torczon, Engineering a compiler. Morgan
Kaufmann, 2022.
[7] S. Damani, D. R. Johnson, M. Stephenson, S. W. Keckler, E. Yan,
M. McKeown, and O. Giroux, "Speculative reconvergence for improved
simt efficiency," in Proceedings of the 18th ACM/IEEE International
Symposium on Code Generation and Optimization. Association for
Computing Machinery, 2020.
[8] S. Damani, M. Stephenson, R. Rangan, D. Johnson, R. Kulkami, and
S. W. Keckler, "Gpu subwarp interleaving," in International Symposium
on High-Performance Computer Architecture (HPCA), 2022.
[9] G. Diamos, B. Ashbaugh, S. Maiyuran, A. Kerr, H. Wu, and S. Yala-
manchili, "Simd re-convergence at thread frontiers," in International
Symposium on Microarchitecture (MICRO), 2011.
[10] L. Durant, O. Giroux, M. Harris, and N. Stam, "Inside volta: The
world's most advanced data center gpu," https://developer.nvidia.com/
blog/inside-volta/, 2017.
[11] A. ElTantawy and T. M. Aamodt, "Mimd synchronization on simt ar-
chitectures," in International Symposium on Microarchitecture (MICRO),
2016.
[12] A. ElTantawy, J. W. Ma, M. O'Connor, and T. M. Aamodt, "A scalable
multi-path microarchitecture for efficient gpu control flow," in Interna-
tional Symposium on High Performance Computer Architecture (HPCA),
2014.
[13] W. W. L. Fung and T. M. Aamodt, "Thread block compaction for
efficient simt control flow," in International Symposium on High Perfor-
mance Computer Architecture (HPCA), 2011.
[14] W. W. Fung, I. Sham, G. Yuan, and T. M. Aamodt, "Dynamic warp
formation and scheduling for efficient gpu control flow," in International
Symposium on Microarchitecture (MICRO), 2007.
[15] A. Habermaier and A. Knapp, "On the correctness of the simt execution
model of gpus," in Programming Languages and Systems, H. Seidl, Ed.
Berlin, Heidelberg: Springer Berlin Heidelberg, 2012, pp. 316--335.
[16] H. Jeon, G. S. Ravi, N. S. Kim, and M. Annavaram, "Gpu register
file virtualization," in International Symposium on Microarchitecture
(MICRO), 2015.
[17] Z. Jia, M. Maggioni, J. Smith, and D. P. Scarpazza, "Dissecting the
nvidia turing t4 gpu via microbenchmarking," 2019.
[18] Z. Jia, M. Maggioni, B. Staiger, and D. P. Scarpazza, "Dissecting the
nvidia volta gpu architecture via microbenchmarking," arXiv preprint
arXiv:1804.06826, 2018.
[19] M. Khairy, Z. Shen, T. M. Aamodt, and T. G. Rogers, "Accel-sim:
An extensible simulation framework for validated gpu modeling," in
International Symposium on Computer Architecture (ISCA), 2020.
[20] C. Lattner and V. Adve, "Llvm: A compilation framework for lifelong
program analysis & transformation," in International symposium on code
generation and optimization (CGO), 2004.
[21] V. I. Levenshtein et al., "Binary codes capable of correcting deletions,
insertions, and reversals," in Soviet physics doklady, vol. 10, no. 8.
Soviet Union, 1966, pp. 707--710.
[22] G. Li, P. Li, G. Sawaya, G. Gopalakrishnan, I. Ghosh, and S. P. Rajan,
"Gklee: concolic verification and test generation for gpus," SIGPLAN
Not., vol. 47, no. 8, p. 215--224, feb 2012.
[23] E. Lindholm, J. Nickolls, S. Oberman, and J. Montrym, "Nvidia tesla:
A unified graphics and computing architecture," in IEEE Micro, vol. 28,
no. 2, 2008, pp. 39--55.
[24] P. Mattson, C. Cheng, G. Diamos, C. Coleman, P. Micikevicius, D. Pat-
terson, H. Tang, G.-Y. Wei, P. Bailis, V. Bittorf et al., "Mlperf training
benchmark," Proceedings of Machine Learning and Systems, vol. 2, pp.
336--349, 2020.
[25] J. Meng, D. Tarjan, and K. Skadron, "Dynamic warp subdivision for
integrated branch and memory divergence tolerance," in international
symposium on Computer architecture (ISCA), 2010.
[26] L. Nai, Y. Xia, I. G. Tanase, H. Kim, and C.-Y. Lin, "Graphbig:
understanding graph computing in the context of industrial solutions," in
International Conference for High Performance Computing, Networking,
Storage and Analysis (SC), 2015.
[27] V. Narasiman, M. Shebanow, C. J. Lee, R. Miftakhutdinov, O. Mutlu, and
Y. N. Patt, "Improving gpu performance via large warps and two-level
warp scheduling," in International Symposium on Microarchitecture
(MICRO), 2011.
[28] NVIDIA, "Cuda binary utilities," https://docs.nvidia.com/cuda/cuda-
binary-utilities/index.html.
[29] NVIDIA, "Nvidia turing gpu architecture," https://images.nvidia.com/
aem-dam/en-zz/Solutions/design-visualization/technologies/turing-
architecture/NVIDIA-Turing-Architecture-Whitepaper.pdf.
[30] NVIDIA, "Parallel thread execution isa," https://docs.nvidia.com/cuda/
parallel-thread-execution/index.html.
[31] NVIDIA, "Nvidia tesla v100 gpu architecture," https://images.nvidia.
com/content/volta-architecture/pdf/volta-architecture-whitepaper.pdf,
2017.
[32] NVIDIA, "cublas," https://docs.nvidia.com/cuda/cublas/index.html,
2024.
[33] NVIDIA, "Cuda c++ programming guide," 2024.
[34] V. J. Reddi, C. Cheng, D. Kanter, P. Mattson, G. Schmuelling, C.-J.
Wu, B. Anderson, M. Breughe, M. Charlebois, W. Chou, R. Chukka,
C. Coleman, S. Davis, P. Deng, G. Diamos, J. Duke, D. Fick, J. S.
Gardner, I. Hubara, S. Idgunji, T. B. Jablin, J. Jiao, T. S. John, P. Kanwar,
D. Lee, J. Liao, A. Lokhmotov, F. Massa, P. Meng, P. Micikevicius,
C. Osborne, G. Pekhimenko, A. T. R. Rajan, D. Sequeira, A. Sirasao,
F. Sun, H. Tang, M. Thomson, F. Wei, E. Wu, L. Xu, K. Yamada,
B. Yu, G. Yuan, A. Zhong, P. Zhang, and Y. Zhou, "Mlperf inference
benchmark," in International Symposium on Computer Architecture
(ISCA), 2020.
[35] M. Rhu and M. Erez, "The dual-path execution model for efficient
gpu control flow," in International Symposium on High Performance
Computer Architecture (HPCA), 2013.
[36] T. G. Rogers, M. O'Connor, and T. M. Aamodt, "Cache-conscious
wavefront scheduling," in International Symposium on Microarchitecture
(MICRO), 2012.
[37] O. Villa, M. Stephenson, D. Nellans, and S. W. Keckler, "Nvbit: A
dynamic binary instrumentation framework for nvidia gpus," in Interna-
tional Symposium on Microarchitecture (MICRO), 2019.
[38] H. Wong, M.-M. Papadopoulou, M. Sadooghi-Alvandi, and
A. Moshovos, "Demystifying gpu microarchitecture through
microbenchmarking," in International Symposium on Performance
Analysis of Systems & Software (ISPASS), 2010.
[39] S. Woop, J. Schmittler, and P. Slusallek, "Rpu: a programmable ray
processing unit for realtime ray tracing," ACM Trans. Graph., vol. 24,
no. 3, p. 434--444, jul 2005.
https://arxiv.org/pdf/2407.02944