接前篇,通道数和模型结构不变的情况下,砍掉P1头,减半通道数,保持4个头训练,参数量和计算量急剧下降的同时,召回率还有提升。虽说FLOPs也下降了很多,但是召回率才0.78,还有待提升。本篇文章从改进Neck部分和风车卷积插入进行实验
本次优化思路
P1层计算量非常大,引出P1头对边缘设备不友好,因此删除它,考虑从特征融合部分结构改进。
前两层找一个对小目标友好的模块,Neck部分融合时反复进行,最好拿到原始的高分辨率特征图进行融合,保证信息不失真。
P5检测头可以砍掉,对小目标没有什么作用,留着还增加计算量。
模型信息
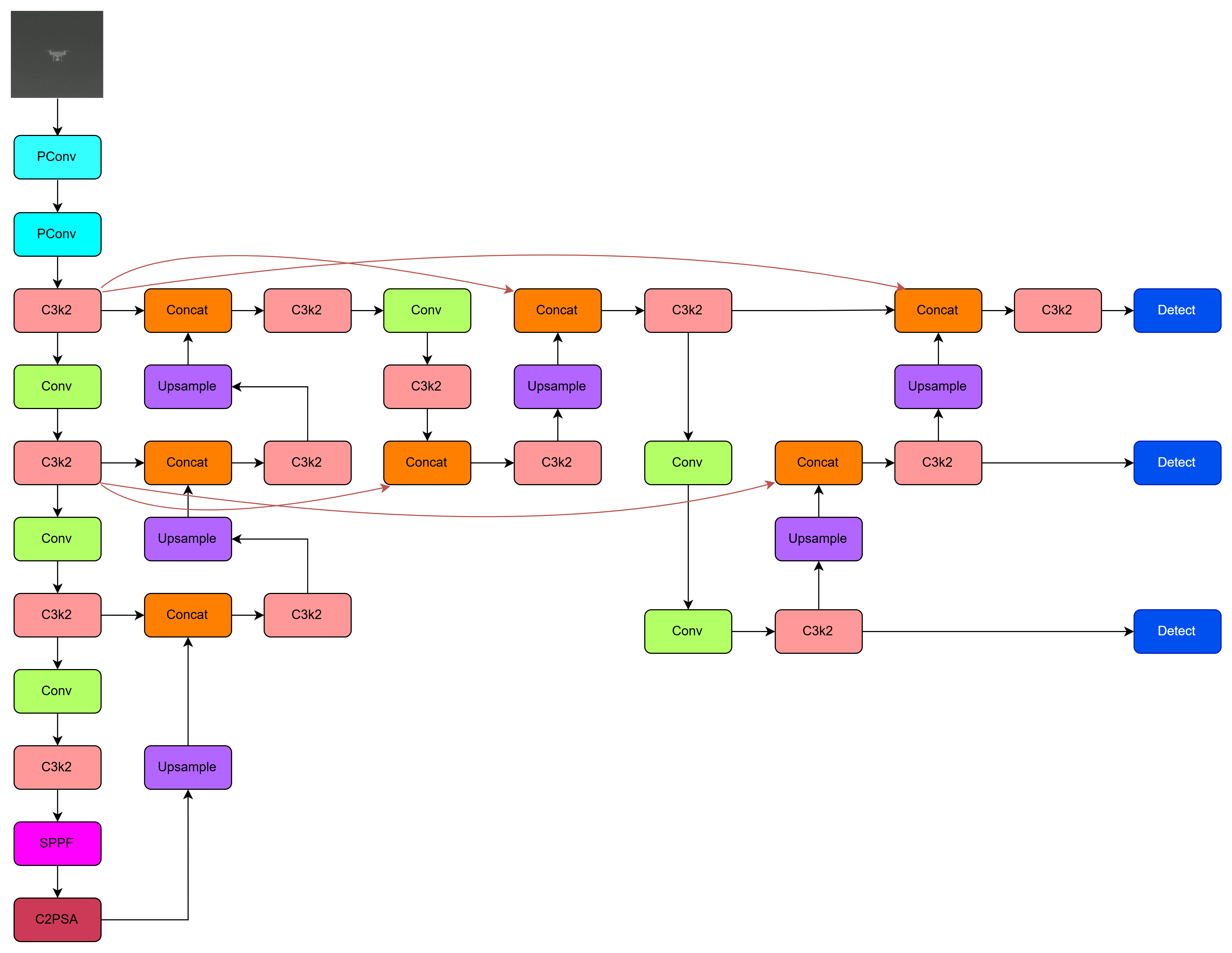
模型结构图
还是使用Yolov11改进实验:
模型参数量分析
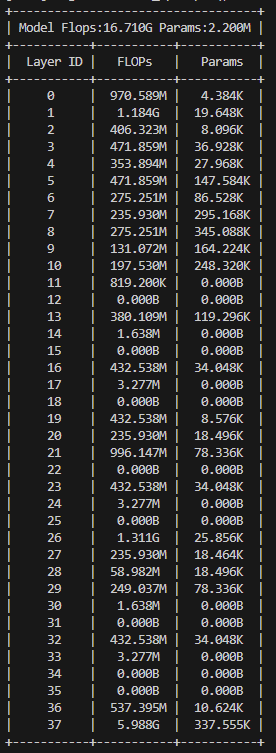
总体FLOPs很小,只有16.7G,参数量也小,2.2M,对标yolov11-n。
风车卷积
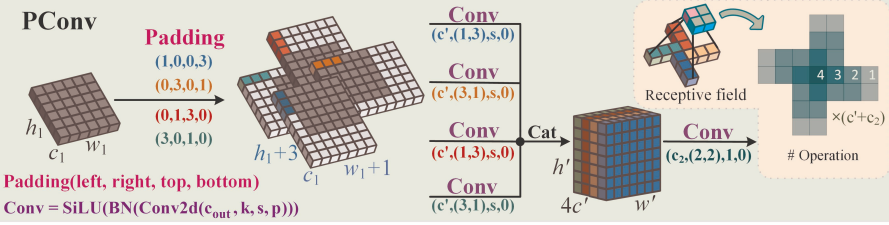
风车卷积主要是为了适配红外小目标中心特征集中、边缘衰减的高斯 - like 空间分布,通过非对称填充和分组卷积,构建 "中心密集、边缘扩散" 的感受野,增强底层特征提取能力。
传统标准卷积采用对称填充与固定大小核(如 3×3),对所有区域无差别提取特征,无法优先捕捉中心关键信息,且感受野有限。
PConv 的设计正是基于这一分布特性,通过 "非对称填充 + 并行分支卷积" 构建 "中心权重高、边缘权重低" 的类高斯感受野,让卷积操作更贴合红外小目标的成像规律,同时避免标准卷积的信息浪费与参数冗余。
PConv采用非对称填充来为图像的不同区域创建水平和垂直卷积核。这些卷积核向外扩散,其中h1、w1和c1分别表示输入张量X(h1,w1,c1)的高度、宽度和通道大小。为了增强训练的稳定性和速度,我们在每次卷积后应用批归一化(BN)和SiLU激活函数。PConv的第一层执行并行卷积,具体如下:
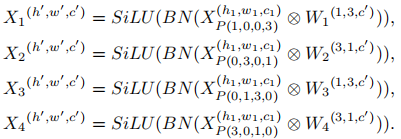
风车卷积的优点
- 感受野扩展:PConv通过分组卷积和不对称填充,显著扩大了感受野,相比标准卷积(3×3)提升了177%-444%。
- 参数效率:PConv在扩大感受野的同时,仅增加了少量参数(111%-122%),显著提高了参数效率。
- 特征提取能力:红外小目标通常呈 "中心亮、边缘暗" 的类高斯灰度分布,PConv 通过 "四分支非对称填充 + 交错卷积",构建 中心权重高、边缘权重低的感受野。
代码修改
yaml配置文件
yaml
# Neck部分多次高分辨率融合,前两层使用风车卷积提取特征
nc: 1 # number of classes
backbone:
# [from, repeats, module, args]
- [-1, 1, PConv, [32, 4, 2]]
- [-1, 1, PConv, [64, 3, 2]]
- [-1, 1, C3k2, [64, True, 0.25]] # 2 P2
- [-1, 1, Conv, [64, 3, 2]]
- [-1, 1, C3k2, [128, True, 0.25]] # 4 P3
- [-1, 1, Conv, [128, 3, 2]]
- [-1, 1, C3k2, [128, False]] # 6 P4
- [-1, 1, Conv, [256, 3, 2]]
- [-1, 1, C3k2, [256, False]] # 8
- [-1, 1, SPPF, [256, 5]]
- [-1, 1, C2PSA, [256]] # 10
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 1, C3k2, [128, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 1, C3k2, [64, False]] # 16
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 2], 1, Concat, [1]] # cat backbone P2
- [-1, 1, C3k2, [32, False]] # 19
# part 2
- [-1, 1, Conv, [64, 3, 2]]
- [-1, 1, C3k2, [128, False]] # 21
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 1, C3k2, [64, False]]
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 2], 1, Concat, [1]] # cat backbone P2
- [-1, 1, C3k2, [64, False]] # 26
# part 3
- [-1, 1, Conv, [32, 3, 2]]
- [-1, 1, Conv, [64, 3, 2]] # 28
- [-1, 1, C3k2, [128, False]] # 29
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]]
- [-1, 1, C3k2, [64, False]] # 32
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 2], 1, Concat, [1]]
- [[-1, 26], 1, Concat, [1]]
- [-1, 1, C3k2, [32, False]] # 36
- [[29, 32, 36], 1, Detect, [nc]] # Detect(P2, P3, P4)ultralytics/nn/moudules
新增APConv.py文件
python
import torch
import torch.nn as nn
import torch.nn.functional as F
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))
class PConv(nn.Module):
''' Pinwheel-shaped Convolution using the Asymmetric Padding method. '''
def __init__(self, c1, c2, k, s):
super().__init__()
# self.k = k
p = [(k, 0, 1, 0), (0, k, 0, 1), (0, 1, k, 0), (1, 0, 0, k)]
self.pad = [nn.ZeroPad2d(padding=(p[g])) for g in range(4)]
self.cw = Conv(c1, c2 // 4, (1, k), s=s, p=0)
self.ch = Conv(c1, c2 // 4, (k, 1), s=s, p=0)
self.cat = Conv(c2, c2, 2, s=1, p=0)
def forward(self, x):
yw0 = self.cw(self.pad[0](x))
yw1 = self.cw(self.pad[1](x))
yh0 = self.ch(self.pad[2](x))
yh1 = self.ch(self.pad[3](x))
return self.cat(torch.cat([yw0, yw1, yh0, yh1], dim=1))
class APC2f(nn.Module):
"""Faster Implementation of APCSP Bottleneck with Asymmetric Padding convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, P=True, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
if P:
self.m = nn.ModuleList(APBottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
else:
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through APC2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
class APBottleneck(nn.Module):
"""Asymmetric Padding bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
p = [(2,0,2,0),(0,2,0,2),(0,2,2,0),(2,0,0,2)]
self.pad = [nn.ZeroPad2d(padding=(p[g])) for g in range(4)]
self.cv1 = Conv(c1, c_ // 4, k[0], 1, p=0)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv2((torch.cat([self.cv1(self.pad[g](x)) for g in range(4)], 1))) if self.add else self.cv2((torch.cat([self.cv1(self.pad[g](x)) for g in range(4)], 1)))
class Bottleneck(nn.Module):
"""Standard bottleneck."""
def __init__(
self, c1: int, c2: int, shortcut: bool = True, g: int = 1, k: tuple[int, int] = (3, 3), e: float = 0.5
):
"""
Initialize a standard bottleneck module.
Args:
c1 (int): Input channels.
c2 (int): Output channels.
shortcut (bool): Whether to use shortcut connection.
g (int): Groups for convolutions.
k (tuple): Kernel sizes for convolutions.
e (float): Expansion ratio.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Apply bottleneck with optional shortcut connection."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))train.py
python
from ultralytics import YOLO
if __name__ == '__main__':
v11 = YOLO('xxx.yaml')
results = v11.train(
data = 'dataxxx.yaml',
epochs = 300,
batch = 32,
cache = True,
mosaic = 0.0,
imgsz = 640,
copy_paste = 0.2,
device = "0",
workers = 16,
project = 'xxx',
plots = True,
name = 'xxx',
)其它修改
(1)/ultralytics/nn/modules/init .py中加入PConv
(2)task.py中parse_moudules函数的base_moudules中加入PConv
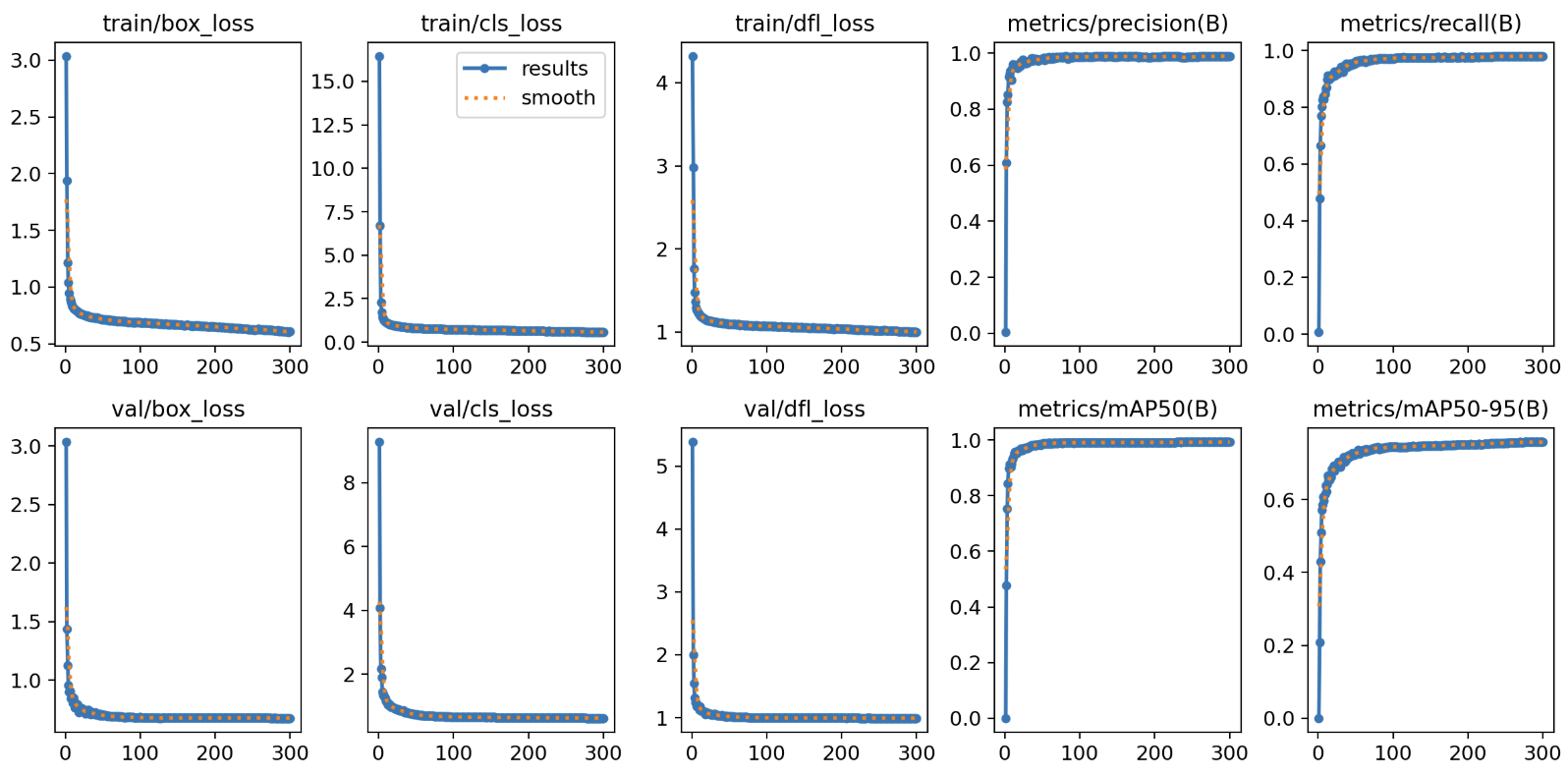
实验结果
训练过程图
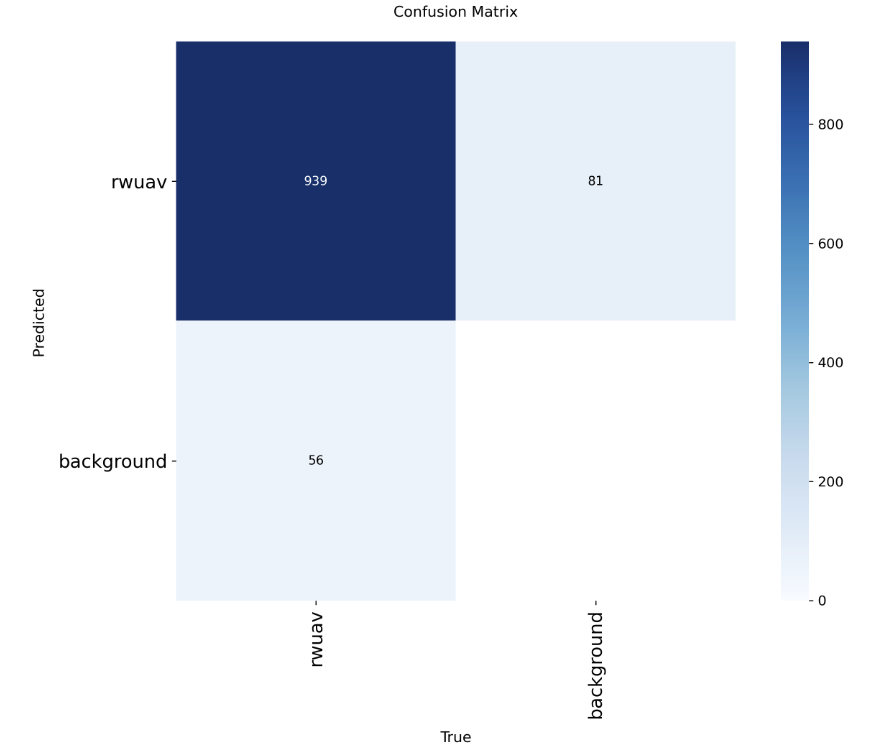
测试集上混淆矩阵
实验总结
目前此网络召回率达到0.94,已经达到我的心理预期了,计算量只有16.7G FLOPs,可以说是很低了,完全可以实时在边缘设备推理。
对比数据
| 模型 | 大小 | P | R | FLOPs |
|---|---|---|---|---|
| 原始yolov11s | 19M | 0.95 | 0.59 | 21.7G |
| 通道减半 | 2.2M | 0.92 | 0.94 | 16.7G |
后续工作
1.RK和jetson部署
2.丰富测试集进行更严苛的测试和改进