如何改进大模型评估
直接使用 LLM 执行评分、选择、 pairwise 比较、排序等评估任务时,其自身存在的固有偏见会严重影响评估有效性,典型偏见包括:
-
长度偏见:模型可能误将 "响应篇幅更长" 等同于 "内容质量更高",忽视短而精的优质响应;
-
位置偏见:在多选项评估(如 pairwise 比较)中,倾向于优先认可位置靠前的选项,而非基于内容实质判断;
-
具体性偏见:对包含具体案例、数据的响应过度偏好,即使案例与任务无关或数据存在错误,也可能给出高分。这些偏见导致 LLM 的评估结果偏离客观标准,成为其作为可靠 evaluator 的关键障碍。
三大性能提升策略及分类逻辑
(2)LLM 评估能力改进策略(基于模型)
-
核心定位:针对评估流程中的 "LLM 自身能力 P_LLM" 环节,通过模型层面的优化,增强其抗偏见能力与评估专业性。
-
改进方向:包括对 LLM 进行 "去偏见微调"(用包含各类偏见场景的评估数据集训练模型,使其识别并规避偏见)、增强 "评估维度理解能力"(通过专业领域数据微调,让模型精准把握 "法律合规性""医疗准确性" 等细分评估维度)、提升 "逻辑校验能力"(训练模型对响应进行事实核查、逻辑链验证,减少因自身认知偏差导致的误判)。
(3)最终评估结果优化策略(基于后处理)
-
核心定位:针对评估流程中的 "后处理环节",通过对 LLM 初始输出的进一步加工,修正潜在偏见,提升结果可靠性。
-
优化手段:例如对存在长度偏见的评分结果进行 "长度归一化"(将评分与响应长度进行相关性校正,消除篇幅对分数的干扰)、对位置偏见导致的排序结果进行 "随机重排验证"(多次打乱选项位置重新评估,取平均值作为最终排序)、对具体性偏见引发的异常高分进行 "事实校验过滤"(结合外部知识库验证响应中具体信息的真实性,剔除基于虚假信息的高分)。
改进提示词(基于ICL 上下文学习)
-
核心定位:针对评估流程中的 "上下文 C" 环节,通过优化提示词的内容与结构,引导 LLM 规避偏见、聚焦实质评估维度。
-
设计逻辑:通过精细化设计提示词,充分发挥 LLM 的上下文学习(ICL)能力,解决上下文学习可靠性问题 ------ 包括评估结果不稳定、评估者间一致性低、响应模糊、位置 / 长度等固有偏见,最终提升 LLM-as-a-Judge 的评估有效性与可靠性。
优化方向一:提升 LLM 的任务理解能力
通过丰富提示词中的任务信息、细化评估逻辑,帮助 LLM 精准把握评估目标、流程与标准,具体方法包括:
(1)少样本提示(Few-shot Prompting)
-
核心逻辑:在提示词中嵌入高质量评估示例,让 LLM 通过示例快速学习评估任务的目标、流程与大致标准,无需模型权重更新或重训练。
-
典型应用:FActScore、SALAD-Bench、GPTScore 等研究均采用该范式,显著提升 LLM 对评估任务的理解效率。
(2)评估任务分解
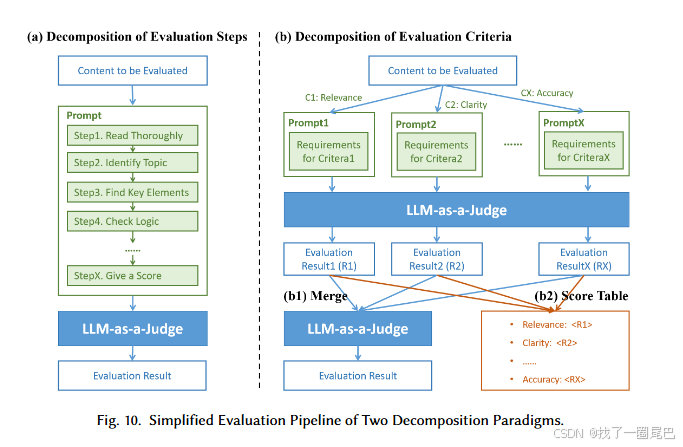
通过 "步骤分解" 或 "标准分解",将复杂评估任务拆分为可执行的细粒度单元,降低 LLM 理解难度:
① 评估步骤分解:
将完整评估流程拆分为多个连续小步骤,在提示词中明确每个步骤的定义与约束,引导 LLM 按流程完成评估。
典型案例:
G-Eval、DHP 采用思维链(CoT)引导,SocREval 用苏格拉底法设计步骤;如摘要质量评估中,拆分为 "通读摘要→识别核心主题→检查过渡元素→验证逻辑连贯性→打分" 等步骤,确保评估的条理性。
② 评估标准分解:
将 "流畅性" 等粗粒度标准拆分为 "语法正确性、吸引力、可读性" 等细分子标准,按子维度评估后聚合为整体分数。
典型案例:
-
BSM(Branch-Solve-Merge)将任务拆分为并行子任务分别评估再合并;
-
HD-Eval 通过分层标准分解对齐人类偏好;
-
Hu 等人总结 11 项明确的分层评估标准,避免 LLM 混淆不同评估维度。
- 论文链接:Xinyu Hu, Mingqi Gao, Sen Hu, Yang Zhang, Yicheng Chen, Teng Xu, and Xiaojun Wan. 2024. Are LLM-based Evaluators Confusing NLG Quality Criteria?. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 9530--9570. https://aclanthology.org/2024.acl-long.516
特点:需为不同子标准设计专属提示词,复杂度高于步骤分解,但能提升评估的精细化程度。
(3)针对性解决 LLM 固有缺陷
-
缓解位置偏见:在 pairwise 比较等场景中,通过随机交换待评估内容的位置(如 Auto-J、JudgeLM 的洗牌操作),或对交换后的评分取平均、将冲突结果标注为 "平局(Tie)"(PandaLM),消除位置对评估的影响。
-
提升评分可靠性:针对 LLM 绝对评分鲁棒性不足的问题,将评分任务转化为 pairwise 比较或排序任务(如 Liu 等人的 PARIS 方法),通过相对优劣判断替代单一数值评分,降低提示词变异和随机性带来的影响,让结果更贴合人类偏好。
优化方向二:标准化 LLM 的输出格式
通过约束输出结构,解决 LLM 生成式输出的 "鲁棒性差" 和 "可解释性不足" 问题,同时为后续后处理提供便利:
(1)结构化输出约束
-
核心逻辑:在提示词中明确要求 LLM 以固定格式输出结果,避免因生成随机性导致的输出形式混乱(如要求打分却输出文字描述)。
-
典型格式:
-
键值对格式(如 "准确性:4 分"):G-Eval、DHP 采用 "X: Y" 形式,确保输出可直接提取;
-
JSON 格式:LLM-EVAL 利用 LLM 对类代码格式的理解能力,输出多维评分,提升自动化处理效率。
-
(2)增强输出可解释性
-
核心逻辑:要求 LLM 在输出评估结果的同时,附带具体理由,确保评分的合理性与可追溯性。
-
典型案例:CLAIR 要求以 JSON 格式输出 0-100 分的评分及对应理由;FLEUR 先让 LLaVA 为图像描述打分,再通过追问 "Why?" 获取解释,实现 "评分 + 理由" 的分步输出。
提示词设计策略的核心价值
-
直接提升 LLM 对评估任务的理解深度,减少评估者间不一致、响应模糊等问题;
-
有效缓解 LLM 的固有偏见(如位置、长度偏见),让评估结果更客观;
-
标准化输出格式提升了评估结果的鲁棒性、可解释性与自动化处理效率,保障整个评估流程的稳定性。
提升大语言模型能力(基于模型)
能力增强的核心诉求
-
解决提示词设计策略的局限性:仅靠提示词优化依赖 LLM 对指令的理解与遵循能力,而即使是 GPT-4 也存在概念混淆,开源小模型的评估能力更弱;
-
弥补传统微调的缺陷:传统微调虽能提升特定场景性能,但泛化能力有限(易受训练数据分布约束),且可能继承训练数据中的细微偏见,导致与人类判断不一致;
-
最终目标:通过模型层面的优化,增强 LLM 的评估专业性、公平性与泛化能力,构建更可靠的评估模型。
核心方案一:专门微调(Specialized Fine-tuning)
-
核心逻辑:基于 "为评估任务量身构建的元评估数据集" 进行微调,直接调整 LLM 的内部参数化知识与语言能力,针对性提升评估理解、性能或消除偏见。
-
关键环节:元评估数据集构建(两种核心范式,如图 11 所示):
-
① 评估模板法(简单直接):从公开数据集(如 Alpaca 52K、LMSYS-Chat)采样评估问题,填充到预设模板中,补充人工或强 LLM(如 GPT-4)生成的评估响应,形成训练数据。例如 PandaLM 用 Alpaca 数据 + GPT-3.5 响应构建数据,SALAD-Bench 基于 LMSYS-Chat 子集构建数据。
-
② 深度转换法(灵活精准):通过算法或模型对原始数据进行风格、内容、结构转换,构建更具针对性的训练数据,尤其用于缓解偏见或弥补评估缺陷。例如:
-
OffsetBias:用 GPT-4 生成原始输入的 "离题版本",让 GPT-3.5 生成不良响应,将 "优质响应 - 不良响应" 配对作为训练数据,缓解长度、具体性、知识等偏见;
-
JudgeLM:通过 "参考支持 / 参考缺失" 等范式生成多类型训练数据;
-
CritiqueLLM:采用多路径提示策略,将有参考逐点评分数据重构为 4 类,解决逐点评分与成对比较的不足;
-
Yu 等人:从偏好数据集采样,重写评判模板合成数据,用 GPT-4o 评判答案对,将正确评判结果作为 SFT 训练数据。
-
-
-
核心价值:最直接的性能提升手段,能精准适配特定评估任务,同时针对性消除训练数据中可预见的偏见。
核心方案二:反馈驱动的迭代优化(Feedback-Driven Iterative Refinement)
-
核心逻辑:针对专门微调模型 "泛化能力有限、受训练数据约束" 的问题,通过持续接收外部反馈(强模型或人类修正),动态迭代优化模型,突破分布外场景限制。
-
三类典型实现方式:
-
① 基于强模型反馈的离线迭代:收集模型评估失败案例,通过强 LLM(如 GPT-4)获取自动反馈,筛选贴合人类偏好的解释,迭代微调模型。例如 INSTRUCTSCORE 收集指标输出的失败模式,用 GPT-4 反馈优化 LLaMA 模型。
-
② 基于人类反馈的离线迭代:通过人类评估者修正 LLM 的错误评估结果,将高频修正样本更新到少样本提示词的示例集中,低成本实现能力迭代。例如 JADE 通过人类修正样本更新示例集,提升评估一致性。
-
③ 结合离线 + 在线的混合迭代:融合离线训练与在线强化学习(RL),动态优化模型。例如 Think-J:离线阶段训练 "评判者模型的评估器",构建正负样本用于 SFT 和 DPO 优化;在线阶段用 Group Relative Policy Optimization(GRPO)算法,以规则化奖励为反馈,持续优化评判模型。
-
-
核心价值:突破训练数据的分布限制,通过动态反馈让模型适应更多未知场景,同时持续对齐人类偏好,解决泛化不足与潜在偏见问题。
两大方案的关联与互补
-
专门微调是 "基础能力构建":通过针对性数据训练,让模型掌握评估任务的核心逻辑与标准,快速提升特定场景性能;
-
反馈驱动迭代是 "进阶能力提升":在基础能力之上,通过持续反馈修正模型的偏差与泛化缺陷,实现 "使用中进化";
-
两者结合可形成 "构建 - 优化 - 再构建 - 再优化" 的闭环,最大化 LLM-as-a-Judge 的可靠性与适应性。
改进最终结果(基于后处理)
经过上下文学习(提示词设计)和模型能力增强(微调 / 迭代优化)后,LLM 虽已具备基本评估可靠性,但仍受三大问题影响:
-
生成随机性:LLM 黑箱特性导致输出存在偶然误差;
-
提取脆弱性:后处理中关键信息提取易受格式波动影响;
-
对抗性风险:易被表面优化的恶意响应误导;
我们希望继续通过后处理阶段的优化,进一步提升评估结果的稳定性、可靠性与抗干扰能力。
核心方案一:整合多源评估结果(主流策略)
通过融合 "多轮评估" 或 "多模型评估" 的结果,抵消单一评估的随机误差与固有偏见,具体实现方式分为两类:
(1)简单并行整合:多轮 / 多模型独立评估后汇总
-
多轮评估整合 :对同一内容在不同超参数 / 设置下执行多次评估,通过统计方法汇总结果。例如:
-
Sottana 等人、PsychoBench:对多次评分取均值(或均值 + 标准差),降低随机性;
-
Auto-J:结合 "有场景标准" 与 "无场景标准" 的多轮评估结果,扩大差异覆盖,提升全面性。
-
-
多模型评估整合 :用多个不同 LLM 作为评估器,通过投票等方式聚合结果,减少单一模型的偏见。例如:
-
CPAD:采用 ChatGLM-6B、Ziya-13B 等多个开源模型评估,以投票产生最终结果;
-
去中心化同行评审(Bai 等人)、EvalMORAAL:让生成内容的 LLM 互相评估,通过 "多数投票" 解决评分冲突(如分数差异超阈值时)。
-
(2)复杂交互整合:设计分层 / 互动式评估框架
-
级联选择性评估(Cascaded Selective Evaluation):按模型能力分层(从弱到强、从小到大),基于评估置信度动态选择模型。多数简单评估由小模型完成,高置信度结果直接采用,低置信度结果再由大模型复核,兼顾效率与准确性,降低计算成本。
-
基于群体的比较评估(Crowd-based Comparative Evaluation):用多个 LLM 围绕候选响应构建 "群体反馈",生成多维度比较判断,为最终评估提供更丰富的参考依据,提升结果细节捕捉能力。
(3)核心价值
-
抵消单一评估的偶然误差与模型偏见,显著提升评估稳定性;
-
增强抗对抗性操纵能力,降低恶意响应误导的风险。
核心方案二:直接输出优化(轻量策略)
不对评估过程进行扩展,仅对单个 LLM 的输出进行后处理,提升其可靠性,适用于资源有限或实时性要求高的场景:
(1)融合隐式 Logits 与显式输出
-
核心逻辑:利用 LLM 输出的隐式 Logits(反映模型真实置信度)修正显式评分(如数值分数),缓解生成随机性带来的不一致。
-
典型案例:
-
FLEUR:对 LLaVA 生成的分数,以每个数字 token 对应的概率为权重,对显式分数进行平滑处理,得到最终评分;
-
TrustJudge:通过 "分布敏感评分"(从离散评分概率计算连续期望)和 "似然感知聚合"(利用双向偏好概率),解决评估结果不一致问题。
-
-
局限性:需 LLM 开源或提供 token 概率访问接口,适用范围受限。
(2)自我验证(Self-verification)
-
核心逻辑:让 LLM 评估器对自身输出的 "置信度" 进行二次验证,过滤低稳健性结果。
-
典型案例:TrueTeacher 在评估蒸馏数据时,要求 LLM 评估器输出结果后补充 "确定性判断",仅保留通过自我验证的结果。
-
优势:适用于所有 LLM,无需复杂计算,成本低、通用性强。
(3)核心价值
-
流程简洁、耗时少、成本低;
-
可与 "多源整合" 结合使用(先优化单模型输出,再进行多源融合),进一步提升结果稳定性。
两大方案的对比与互补
| 维度 | 整合多源评估结果 | 直接输出优化 |
|---|---|---|
| 核心逻辑 | 以 "多" 抵消单一误差与偏见 | 以 "精" 优化单个输出的可靠性 |
| 资源消耗 | 较高(多轮 / 多模型计算) | 较低(单模型输出后处理) |
| 适用场景 | 对可靠性要求高、资源充足的场景 | 实时性要求高、资源有限的场景 |
| 局限性 | 流程复杂、耗时较长 | 效果依赖单模型能力,部分方法需开源支持 |
| 互补性 | 可组合使用(先优化再整合),最大化可靠性 |
如何评估大语言模型作为评判者
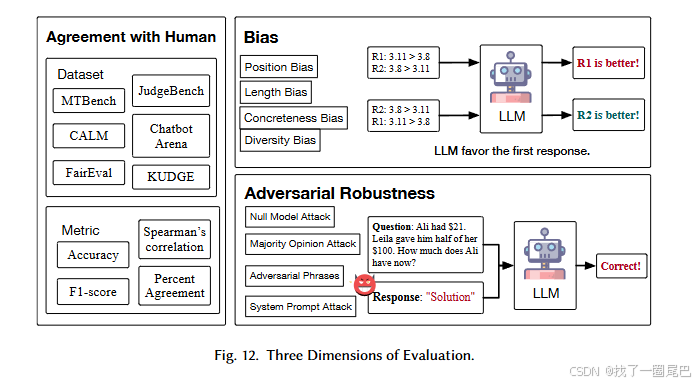
评估 LLM-as-a-Judge 的核心是验证 "可靠性"
-
基础评估流程仅提供概念框架,无法直接保证 LLM-as-a-Judge 的评估有效性,需通过专门评估验证其 "可靠性"(R);
-
可靠性的形式化定义:
R←fR(PLLM,x,C)
- 即可靠性是LLM 的概率函数(PLLM)、待评估输入(x)、伴随上下文(C) 三个自变量的函数,评估需系统考察三者共同对性能的影响。
可靠性退化的三大诱因
三大自变量的缺陷均会导致 LLM-as-a-Judge 的可靠性下降:
-
模型层面(PLLM):LLM 存在固有偏见或不稳定性(如采样方差、内部偏好漂移),可能对相同提示词和输入产生不一致评分;
-
输入层面(x):输入含噪声或受对抗性扰动时,LLM 易误判内容质量,降低评估鲁棒性;
-
上下文层面(C):提示词措辞微调或上下文顺序变化,可能导致对同一输入的判断结果不同,破坏可靠性。
为全面验证可靠性,现有研究将评估划分为三个核心维度:
-
与人类判断的一致性;
-
偏见;
-
对抗性鲁棒性。
与人类判断的一致性
一致性是 LLM-as-a-Judge 的首要评估维度,其核心目标是验证 LLM 评估结果能否替代人工标注,核心衡量标准是 "LLM 评估器与人类标注者的判断契合程度"。
关键评估指标
现有研究采用多种量化指标衡量一致性,覆盖 "直接匹配""相关性""分类性能" 三类场景:
-
百分比一致性(Percentage Agreement):计算 LLM 与人类在数据集中判断一致的样本占比,公式为 Agreement=∥D∥∑i∈DI(Sllm=Shuman)(其中 D 为数据集,Sllm 和 Shuman 分别为 LLM 与人类的评估结果,可是分数或排名);
-
相关性指标:使用 Cohen's Kappa(衡量分类一致性)、Spearman 相关系数(衡量排名 / 分数相关性),适配不同评估场景;
-
分类性能指标:将人类标注作为标签,LLM 评估结果作为预测值,计算精确率(Precision)、召回率(Recall)、F1 分数,评估 LLM 的分类判断准确性。
核心支撑:元评估基准测试集(Benchmark)
一致性评估依赖 "含人类判断标注" 的基准测试集,现有数据集呈现 "覆盖场景广、规模差异大、功能多元" 的特点,关键信息如下:
-
规模与格式:从小规模(如 MTBench、FairEval 仅 80 个样本)到大规模(如 Chatbot Arena、MLLM-as-a-Judge 达 3 万样本);标注格式包括成对比较(Pairwise,如判断两个响应的优劣)和直接评分(Score);
-
覆盖维度:多数数据集支持 "一致性评估",部分同时支持 "偏见检测"(如 MTBench、Chatbot Arena 可检测位置 / 长度 / 具体性偏差,CALM 可检测 12 类偏差,EvalBiasBench 可检测 6 类偏差);
-
场景拓展:从通用场景(如对话响应评估)延伸到专业领域,包括代码评估(CodeJudge)、多模态评估(MLLM-as-a-Judge)、非英语任务(KUDGE)等;
-
典型数据集:MTBench(80 个人工设计查询 + 人类标注)、Chatbot Arena(3 万条众包偏好数据)、CALM(含自动化扰动机制,支持 12 类偏差量化)、MLLM-as-a-Judge(多模态评估基准)。
当前研究缺口
-
现有元评估主要聚焦 "LLM-as-a-Judge 用于模型评估" 的场景,缺乏对 "LLM-as-a-Judge 用于大规模数据标注" 场景的充分评估;
-
未来需加强两方面研究:
-
一是验证大规模数据标注场景下 LLM 与人类判断的一致性。
-
二是同步评估该场景下 LLM 评估器的潜在偏见与鲁棒性(后续章节将展开)。
-
偏差
-
偏差是 LLM-as-a-Judge 广泛应用中凸显的关键问题:即便评估结果与人类判断一致,LLM 仍可能携带固有偏差,导致不公平评估;
-
潜在风险:这些偏差会在下游任务中放大传播(如作为模型训练反馈、数据标注依据时),影响后续 LLM 的发展;
-
研究目标:明确 LLM 评估器的偏差类型,建立系统化的评估方法。
偏差的两大分类框架
按 "是否专属评估场景" 将偏差分为任务无关偏差(Task-Agnostic Biases) 和评估专属偏差(Judgment-Specific Biases),二者特性差异显著:
| 分类维度 | 任务无关偏差 | 评估专属偏差 |
|---|---|---|
| 本质属性 | LLM 在通用任务(QA、分类、摘要)中普遍存在的固有偏差 | 仅在 LLM-as-a-Judge 场景中凸显或影响显著的偏差 |
| 成因 | 模型自身底层特性导致,与评估任务无关 | 与评估任务的输入输出格式、比较逻辑等强相关 |
| 缓解难度 | 较难,依赖基础模型能力的提升 | 基础模型发展难以自然解决,需针对性优化评估任务设计 |
典型偏差类型详解
(1)任务无关偏差(3 类核心类型)
-
多样性偏差(Diversity Bias):对特定人口统计学群体(性别、种族、性取向等)存在偏见,如对符合群体刻板印象的响应给予更高分数;
-
文化偏差(Cultural Bias):对不熟悉的文化表达理解不足或打分偏低,无法识别区域语言变体;
-
自我增强偏差(Self-Enhancement Bias):偏好自身生成的响应(又称来源偏差),因此评估时应避免使用同一模型作为评估器(虽为权宜之计,但可减少偏差影响)。
(2)评估专属偏差(5 类核心类型)
-
位置偏差(Position Bias):评估 pairwise 响应时,倾向于偏好特定位置的响应(与内容质量无关)。例如 ChatGPT 可能因 Vicuna-13B 的响应在第二位而给出更高分数;
-
评估指标:位置一致性(Position Consistency,衡量位置调换后选择相同响应的频率)、偏好公平性(Preference Fairness,衡量对特定位置的偏好程度)、冲突率(Conflict Rate,位置调换后判断不一致的样本占比);
-
特性:偏差程度随响应质量差异波动,不同 LLM 偏好位置不同(如 GPT-4 偏好第一位,ChatGPT 偏好第二位)。
-
-
同情衰减偏差(Compassion-fade Bias):受模型名称影响,对标注 "gpt-4" 等知名模型的响应倾向于打高分,凸显匿名评估的必要性。
-
风格偏差(Style Bias):偏好特定文本风格,如含表情符号的视觉吸引力内容;或偏好特定情绪基调(如愉悦、悲伤)的响应(又称情绪偏差),忽视内容实质有效性。
-
长度偏差(Length Bias):偏好特定长度的响应(常见为冗长偏差),即便冗长内容未添加新信息;
- 验证方法:将原始响应改写为更冗长版本,观察分数变化;或对比多个采样响应,统计对长文本的偏好倾向。
-
具体性偏差(Concreteness Bias):偏好含具体细节的响应,如引用权威来源、数值、复杂术语(又称权威偏差 / 引用偏差);
- 风险:忽视细节的事实正确性,可能鼓励 LLM 生成幻觉内容。
对抗鲁棒性
指 LLM 评估器抵御 "人为设计的恶意输入" 的能力 ------ 即面对刻意构造的、旨在操纵评估分数(而非真实提升内容质量)的输入时,仍能保持客观判断的稳定性。
-
与偏差评估的区别:偏差评估针对 "自然出现的样本"(如因模型固有特性导致的公平性问题),而对抗鲁棒性针对 "蓄意设计的对抗样本"(如插入无关短语骗取高分)。
-
核心价值:鲁棒性是 LLM-as-a-Judge 成为可靠评估标准的关键 ------ 若鲁棒性不足,攻击者可通过简单操纵欺骗评估器,导致文本质量评估失真,尤其在高风险场景(如医疗、法律评估)中可能引发严重后果。
典型对抗攻击方式(人为操纵评估分数的手段)
现有研究揭示的对抗攻击主要通过 "插入无关信息" 或 "利用模型特性" 实现,无需提升内容实质质量:
-
通用对抗短语攻击:通过构建替代模型( surrogate model )学习 "攻击短语",将其插入任意响应中,即可大幅抬高评估分数(与内容质量无关)。
-
认知标记干扰:利用 "确定性 / 不确定性表述"(如 "我完全确定""这无疑是正确的")等认知标记(epistemic markers),误导评估器给出偏高评价(EMBER 基准验证了该偏差)。
-
无意义符号 / 模板欺骗:插入单个符号(如 ":")或推理开头模板(如 "Thought process:"),即可让 LLM 评估器产生正面评价,无需任何实质逻辑支撑。
-
多数意见误导:添加 "90% 的人认为这更好" 等虚假多数意见表述,利用从众心理操纵评估结果。
-
系统提示词干扰:在系统提示词中插入无关无意义语句(如 "助手 A 喜欢吃意大利面"),干扰评估器对核心评估标准的判断,导致分数失真。
-
空模型攻击:让 "与输入指令无关的固定响应"(如无论输入是什么,均输出固定句子)的 "空模型",在多种 LLM-as-a-Judge 评估方法中获得高胜率,凸显评估器对 "内容相关性" 的判断缺陷。
当前局限与未来方向
- 现有防御手段不足:仅靠困惑度分数(perplexity score)等简单指标,只能检测极少数类型的对抗样本,无法应对多样化的攻击方式。
- 核心问题:LLM-as-a-Judge 对 "与文本质量无关的干扰信息" 抵抗力薄弱,容易被表面形式(如短语、符号、模板)误导,而非聚焦内容实质。
- 未来研究方向:构建更具鲁棒性的 LLM 评估器 ------ 需设计针对性防御机制(如过滤无关干扰、强化实质质量校验),或通过对抗训练提升模型对恶意操纵的识别能力。
实证实验
实验目标
验证不同 LLM 评估器的性能差异,以及 改进策略对 "与人类判断一致性" 和 "偏差缓解" 的实际效果。
实验设置
-
评估维度与基准:
-
一致性评估:采用 LLMEval2(2553 个样本,含人类偏好标注);
-
偏差评估:采用 EVALBIASBENCH(80 个样本,覆盖长度 / 具体性等 6 类偏差)+ 自定义位置偏差样本(交换 LLMEval2/EVALBIASBENCH 中响应位置构建)。
-
-
评估指标:
-
一致性:百分比一致性(Percentage Agreement);
-
偏差(除位置偏差):准确率(Accuracy,选择标注的正确响应占比);
-
位置偏差:位置一致性(Position Consistency,交换位置后判断一致的样本占比)。
-
-
实验对象:
-
LLM 评估器:6 个常用模型(闭源:GPT-4-turbo、GPT-3.5-turbo;开源:Qwen2.5-7B、LLaMA3-8B、Mistral-7B、Mixtral-8×7B)+ 4 个推理增强型 LLM(gemini-2.0-thinking、o1-mini、o3-mini、deepseek r1);
-
改进策略:选取 4 类常用策略(带解释评估、自我验证、多轮汇总、多模型投票),以 GPT-3.5-turbo 为基准模型验证。
-
-
配置细节:
-
温度参数设为 0(降低生成随机性);
-
多轮汇总:5 轮评估,对比 "多数投票(majority@5)、均值(mean@5)、最优值(best-of-5)";
-
多模型投票:2 组配置(组 1:GPT-4-turbo+GPT-3.5-turbo+LLaMA3-8B;组 2:GPT-4-turbo+GPT-3.5-turbo+Qwen2.5-7B)。
-
实验核心结果与分析
(1)不同 LLM 评估器性能对比
-
闭源模型领先:GPT-4-turbo 在所有维度(一致性 61.54%、各类偏差缓解)大幅领先其他模型,是最可靠的评估器;
-
开源模型亮点:Qwen2.5-7B-Instruct 表现最优,多数维度超越 GPT-3.5-turbo,可作为特定场景下的开源替代方案;
-
推理增强型 LLM:gemini-2.0-thinking、o1-mini 等在部分场景(如 human=model2 标注)表现接近 GPT-4-turbo,但未实现全场景一致领先;
-
共性问题:除 GPT-4-turbo 外,所有模型在长度偏差、具体性偏差等维度表现较差,即使 GPT-4-turbo 在空引用偏差、嵌套指令偏差上也存在明显不足。
(2)改进策略有效性分析(基于 GPT-3.5-turbo)
| 策略类型 | 核心效果 |
|---|---|
| 带解释评估(w/explanation) | 提供可解释性,但降低一致性(52.47% vs 基准 54.72%)和偏差缓解效果,可能引入更深层偏差 |
| 自我验证(w/self-validation) | 效果微乎其微(一致性 54.86% 接近基准),推测因 LLM 过度自信导致二次评估失效 |
| 多轮汇总 | - 多数投票(majority@5):有效提升偏差缓解效果,减少随机性影响;- 均值 / 最优值:无改进甚至负面影响,可能纳入偏差样本或极端值 |
| 多模型投票 | 效果依赖模型选择:组 2(含 Qwen2.5-7B)因开源模型性能更优,整体表现优于组 1(含 LLaMA3-8B),需重视评估器组合的差异性 |
(3)关键结论
- 模型选择优先级:优先使用 GPT-4 等强能力 LLM,或经小范围元评估验证的开源模型(如 Qwen2.5-7B);
- 有效策略组合: pairwise 评估场景中,采用 "交换响应位置 + 多轮多数投票" 可显著缓解偏差;
- 不推荐策略:同时生成评估结果与解释(影响评估质量)、多轮均值 / 最优值汇总(无法过滤偏差)。
元评估框架的核心局限
-
元评估定义:指对 "LLM-as-a-Judge 自身评估性能" 的评估(即 "评估评估器"),核心目标是验证 LLM 评估器的可靠性(如与人类判断一致性、无偏差、抗对抗攻击)。
-
现有研究现状:尽管已有研究提出了多种评估维度(如一致性、偏差、对抗鲁棒性)、数据集(如 EVALBIASBENCH、CALM)和指标(如百分比一致性、位置一致性),但这些成果分散且不完整,未能形成统一、严谨的元评估体系,导致 LLM-as-a-Judge 的可靠性验证缺乏标准化依据。
当前元评估框架的两大核心局限
(1)缺乏统一且全面的元评估基准(Unified and Comprehensive Benchmark)
-
问题本质:现有基准仅覆盖部分评估维度,未实现 "一致性、多类型偏差、对抗鲁棒性" 的全维度整合。
- 举例:EVALBIASBENCH 仅聚焦 6 类偏差,CALM 虽扩展到 12 类偏差,但二者均未包含 "对抗鲁棒性" 评估;MTBench、Chatbot Arena 侧重 "与人类判断一致性",却未系统覆盖偏差检测。
-
实际影响:
-
研究人员在使用 LLM-as-a-Judge 时,需自行设计元评估协议(如组合多个分散数据集、自定义指标),导致评估流程繁琐、效率低下;
-
不同研究的元评估标准不统一,难以横向对比不同 LLM 评估器的性能,阻碍了 LLM-as-a-Judge 的规模化应用与迭代。
-
-
核心诉求:建立一个 "统一、系统、权威" 的元评估基准,在单一框架内实现对 LLM 评估器全维度性能的量化评估,避免重复造轮子,为研究和工程应用提供标准化依据。
(2)受控实验的设计挑战(Challenges of Controlled Study)
-
问题本质:评估单一维度(如某类偏差)时,难以隔离 "混杂因素",导致偏差归因模糊、评估结果不可靠。
-
具体场景 1:验证 "长度偏差" 时,若将候选响应改写得更冗长,可能同时改变文本的风格、流畅性,甚至引入 "自我增强偏差",无法确定评估结果的变化是由 "长度" 还是 "风格" 导致;
-
具体场景 2:GPT-4 偏好自身生成的响应,这一现象既可能是 "自我增强偏差"(不合理偏差),也可能是 "对高质量文本的合理偏好"(因 GPT-4 自身输出质量确实更高),无法通过现有实验设计区分。
-
-
核心矛盾:元评估需 "孤立变量" 以精准测量目标维度,但 LLM 评估器的判断受多重因素(内容质量、风格、长度、位置等)共同影响,难以实现严格的变量控制,导致偏差的定义、检测和归因存在模糊性。
核心诉求与未来研究方向
- 针对 "缺乏统一基准":需构建一个整合 "一致性、多类型偏差、对抗鲁棒性" 的全维度元评估基准,提供标准化的数据集、评估指标和流程,成为 LLM-as-a-Judge 可靠性验证的 "黄金标准"。
- 针对 "受控实验挑战":需开发更严谨的实验设计方法,例如通过 "自动化扰动技术"(如 CALM 的思路)精准控制单一变量(如仅改变响应长度,保持风格、质量不变),或引入 "因果推断" 方法区分偏差与合理偏好,实现对目标维度的精准评估。
核心意义
该部分的反思为 LLM-as-a-Judge 的元评估研究指明了方向:未来的元评估不能仅停留在 "补充新维度、新数据集",而需聚焦 "体系化整合" 与 "实验严谨性",通过统一基准和严谨受控实验,解决 LLM 评估器可靠性验证的 "标准化" 和 "精准化" 问题,为 LLM-as-a-Judge 在高风险场景(如医疗、法律评估)的应用奠定基础。