最新更新的 DeepSeek V3.2 中提到了思考模式下的工具调用,那么我们作为开发者,应该如何掌握这个开发技能呢?
下面以一个 demo 为例,详细讲解,如何写一个工具来为 Agent 提供一个"内部思考空间",让 LLM 在回答用户前,能够通过 think(规划下一步)和 analyze(评估已有结果)进行结构化的多步推理,并将思考过程在调用模型的时候,传递到上下文中。 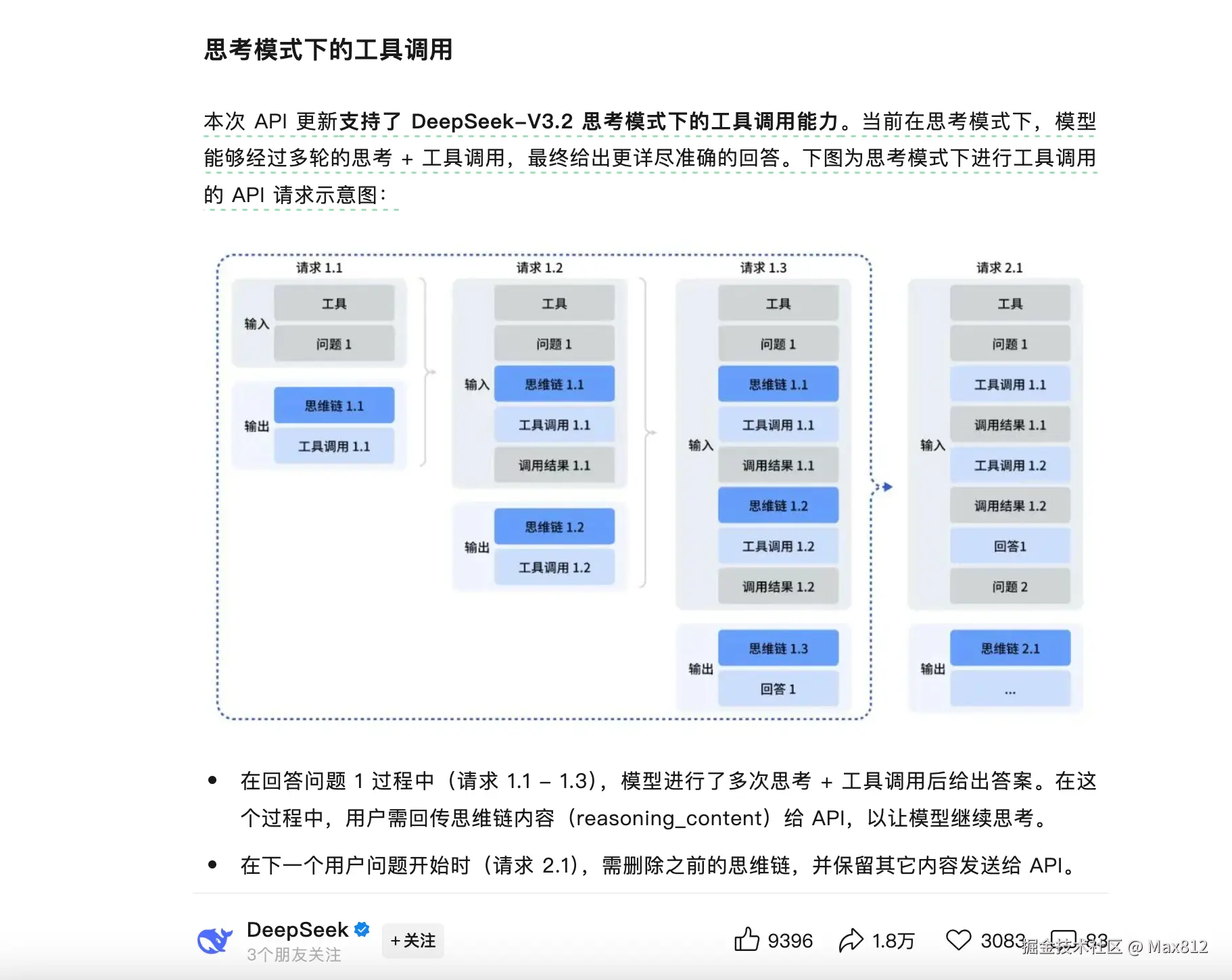
一、为什么模型需要"内部思考"?
在日常开发中,你有没有遇到过这样的场景:
- 用户问了个复杂问题,模型要么一股脑给个不靠谱的答案,要么调用一堆工具但逻辑混乱
- 你想知道模型为什么这么回答,但它的"思考过程"完全是黑盒
- 同样的问题问两次,推理路径完全不一样,难以稳定复现
这些问题的根源在于:模型缺少一个结构化的思考空间。
传统的 Agent 开发中,模型要么直接回答,要么调用工具,但缺少"先想清楚再做"的环节。就像一个冲动行事的人,看到问题就开始干,干完才发现方向错了。
ReasoningTools 要解决的就是这个问题 :给模型提供两个工具 think 和 analyze,让它在回答前能够:
- 先想清楚(think):问题是什么?我要怎么拆解?需要哪些信息?
- 干完评估(analyze):结果符合预期吗?要继续还是收尾?
而且这些"内心活动"都会被记录在 session_state 里,既能帮助模型保持连贯推理,也能让开发者追踪每一步决策依据。
二、think 和 analyze:一对好搭档
2.1 职责分工:谁负责啥?
在开始写代码前,我们先理解这两个工具的职责边界:
think - 前瞻性的计划者
think 发生在执行之前,回答的是"我要做什么":
python
think(
title="理解用户需求",
thought="用户想知道地球上有多少大陆,这是地理常识",
action="回忆或搜索大陆数量", # 计划要做的事
confidence=0.95
)关键特征:
- 时机:行动前
- 视角:未来式("我将要做...")
- 核心问题:"应该做什么?怎么做?"
- 类比:项目经理制定计划
analyze - 回顾性的评估者
analyze 发生在执行之后,回答的是"结果如何":
python
analyze(
title="评估搜索结果",
result="搜索返回:地球有7个大陆", # 已完成的结果
analysis="信息准确完整,可以直接回答用户",
next_action="final_answer", # 决定流程走向
confidence=1.0
)关键特征:
- 时机:行动后
- 视角:过去式("我刚才做了...")
- 核心问题:"结果怎么样?下一步呢?"
- 关键决策:
next_action可以是:continue- 还需要继续推理validate- 需要验证结果final_answer- 可以给出最终答案
- 类比:质检员评估产品
2.2 用 Few-Shot 看懂职责
让我们看看官方 Few-Shot 中的简单示例:
场景:用户问"地球上有多少大陆?"
ini
Step 1 - think(计划阶段)
├─ 问题:这是什么问题?
├─ 思考:这是地理常识
└─ 行动:回忆或验证大陆数量
(Agent 内部回忆)
Step 2 - analyze(评估阶段)
├─ 结果:标准地理模型列出7个大陆
├─ 分析:信息直接准确地回答了问题
└─ 决策:next_action = "final_answer"
给用户输出最终答案稍微复杂点:查询法国首都和人口
vbnet
Step 1 - think
思考:需要两个信息(首都+人口),应该用搜索工具
行动:并行搜索两个问题
(并行调用搜索工具)
search("法国首都") → "巴黎"
search("巴黎人口") → "约210万"
Step 2 - analyze(评估第一个结果)
结果:搜索显示巴黎是首都
分析:得到第一个信息,还需要人口
决策:next_action = "continue"
Step 3 - analyze(评估第二个结果)
结果:搜索提供了人口数据
分析:两个信息都有了,可以回答
决策:next_action = "final_answer"
输出:法国首都是巴黎,人口约210万看出规律了吗?think 总是在"做事前",analyze 总是在"拿到结果后"。
三、从简单到复杂:看推理链如何工作
理解了职责分工,我们来看一个真实的复杂场景:帮用户选择适合数据科学的笔记本电脑。
3.1 场景设定
用户需求:
我是一名数据科学家,预算15000元左右,需要一台能跑深度学习模型的笔记本,主要在家办公但偶尔需要带出去开会。帮我推荐一款。
这个需求的复杂性在于:
- 多维度约束(预算、性能、便携性)
- 需求存在冲突(高性能 vs 轻薄)
- 需要多轮信息收集和权衡
3.2 推理链全景图
让我们看看模型会如何一步步推理(完整版共9步):
vbnet
┌─────────────────────────────────────────┐
│ Step 1: think - 拆解需求 │
│ • 识别关键需求:GPU、内存、便携性、预算 │
│ • 发现冲突:性能 vs 便携 │
│ • 决定优先级:假设性能优先 │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ Step 2: think - 制定搜索策略 │
│ • 明确配置需求:RTX 4060+、32GB │
│ • 锁定品牌:联想/华硕/机械革命 │
│ • 计划:并行搜索多个关键词 │
└─────────────────────────────────────────┘
↓
[并行搜索 ×3] → 得到5款候选
↓
┌─────────────────────────────────────────┐
│ Step 3: analyze - 评估搜索结果 │
│ • 筛选:排除无独显、超预算的 │
│ • 发现问题:ROG 幻16 只有16GB内存 │
│ • 决策:continue(需要查内存能否升级) │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ Step 4: think - 解决内存疑问 │
│ • 识别风险:16GB可能不够 │
│ • 计划:搜索该型号能否升级内存 │
└─────────────────────────────────────────┘
↓
[搜索] → "内存板载,不可升级"
↓
┌─────────────────────────────────────────┐
│ Step 5: analyze - 处理新信息 │
│ • 结果:ROG 幻16 内存无法升级 │
│ • 分析:这会成为未来瓶颈 │
│ • 决策:降级为备选,continue │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ Step 6: think - 深度对比剩余候选 │
│ • 锁定对比维度:散热、屏幕、接口 │
│ • 计划:搜索详细评测 │
└─────────────────────────────────────────┘
↓
[搜索评测] → 对比数据
↓
┌─────────────────────────────────────────┐
│ Step 7: analyze - 综合分析 │
│ • 结果:R9000P散热好但重,极光Pro有雷电口│
│ • 分析:雷电口对"偶尔外出"场景很实用 │
│ • 决策:validate(先验证一下逻辑) │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ Step 8: think - 验证推荐逻辑 │
│ • 检查是否遗漏(预算、性能、便携) │
│ • 识别风险(售后、散热) │
│ • 决定:需要在推荐中说明trade-off │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ Step 9: analyze - 最终决策 │
│ • 形成完整推荐(主推+备选+说明) │
│ • 确认逻辑完整 │
│ • 决策:final_answer │
└─────────────────────────────────────────┘
↓
输出给用户3.3 关键节点解析
节点1:发现问题后的调整(Step 3-5)
这是推理链最精彩的部分:
python
# Step 3 - analyze
analyze(
result="ROG 幻16 只有16GB内存",
analysis="16GB对深度学习可能不够,需要确认能否升级",
next_action="continue" # 不急着下结论
)
# Step 4 - think
think(
thought="如果内存能升级,ROG 幻16 仍是好选择(最轻)",
action="搜索 ROG 幻16 内存升级方案"
)
# Step 5 - analyze
analyze(
result="内存为板载设计,无法升级",
analysis="这是致命缺陷!将其降级为备选",
next_action="continue" # 继续对比其他机型
)如果没有这个推理链,模型可能:
- 直接推荐 ROG 幻16(因为最轻),忽略内存问题
- 或者直接排除它,不告诉用户为什么
有了推理链,模型:
- 发现潜在问题 → 深入调查 → 根据新信息调整决策
- 每一步都有记录,可追溯
节点2:validate 的使用(Step 7-8)
python
# Step 7 - analyze
analyze(
analysis="倾向推荐机械革命极光 Pro",
next_action="validate" # 先别急,验证一下
)
# Step 8 - think
think(
thought="""
检查清单:
✓ 预算满足
✓ 性能满足
✓ 便携性可接受
潜在风险:售后不如联想、散热一般
需要在推荐中说明这些风险
"""
)validate 这一步很关键:在给出最终答案前,再过一遍逻辑,确保没有遗漏、没有逻辑漏洞。
四、技术实现:数据如何组装和传递
理解了推理逻辑,我们来看技术细节:这些 think 和 analyze 是如何被存储和传递的?
4.1 数据结构设计
核心数据结构非常简洁:
python
session_state = {
"current_run_id": "abc-123-def", # 当前运行的ID
"reasoning_steps": {
"abc-123-def": [ # 按 run_id 分组
'{"title":"拆解需求","reasoning":"...","action":"...","confidence":0.9}',
'{"title":"制定策略","reasoning":"...","action":"...","confidence":0.85}',
...
],
"xyz-789-ghi": [...] # 另一次运行
}
}为什么按 run_id 分组?
- 每次
agent.run()是独立的对话轮次 - 避免不同轮次的推理混在一起
- 支持并发请求(每个请求有独立的 run_id)
4.2 数据组装流程
当模型调用 think 时,背后发生了什么?
python
def think(self, session_state, title, thought, action, confidence):
# 1. 创建结构化的推理步骤对象
reasoning_step = ReasoningStep(
title=title,
reasoning=thought,
action=action,
next_action=NextAction.CONTINUE,
confidence=confidence,
)
# 2. 获取当前的 run_id(框架自动注入)
current_run_id = session_state.get("current_run_id", None)
# 3. 初始化嵌套结构(如果还没有)
if "reasoning_steps" not in session_state:
session_state["reasoning_steps"] = {}
if current_run_id not in session_state["reasoning_steps"]:
session_state["reasoning_steps"][current_run_id] = []
# 4. 序列化并追加到列表
session_state["reasoning_steps"][current_run_id].append(
reasoning_step.model_dump_json()
)
# 5. 格式化历史推理步骤,返回给模型
formatted_steps = ""
for i, step in enumerate(session_state["reasoning_steps"][current_run_id], 1):
step_obj = ReasoningStep.model_validate_json(step)
formatted_steps += f"""
Step {i}:
Title: {step_obj.title}
Reasoning: {step_obj.reasoning}
Action: {step_obj.action}
Confidence: {step_obj.confidence}
"""
return formatted_steps.strip()关键点:
- 每次
think后,返回值包含所有历史推理步骤 - 模型能看到完整的推理链,保持上下文连贯
- 数据以 JSON 形式存储,便于序列化和反序列化
4.3 run_id 的生命周期
python
# 用户第一次提问
agent.run("帮我选笔记本")
↓
生成 run_id_1 = "abc-123-def"
↓
session_state["current_run_id"] = run_id_1
↓
所有 think/analyze 都写入 reasoning_steps[run_id_1]
↓
run() 结束
# 用户第二次提问(新的一轮)
agent.run("再推荐一个品牌")
↓
生成 run_id_2 = "xyz-789-ghi"
↓
session_state["current_run_id"] = run_id_2 # 更新
↓
新的推理步骤写入 reasoning_steps[run_id_2]这样设计的好处:
- 不同对话轮次完全隔离
- 支持查看历史对话的推理过程
- 便于并发场景(多个用户同时提问)
与 DeepSeek 思考模式的对比
DeepSeek V3.2 的思考模式是模型层面的能力 (类似 OpenAI 的 o1),而 ReasoningTools 是工具层面的实现。
两者的关系:
- 如果用 DeepSeek 思考模式:推理由模型内部完成,更原生、更强大
- 如果用 ReasoningTools:推理由工具引导,更可控、更灵活
可以结合使用:
python
from agno.models.openai import OpenAIChat
agent = Agent(
model=OpenAIChat(id="deepseek-reasoner"), # 支持思考的模型
tools=[reasoning_tools], # 同时提供推理工具
reasoning=True, # 启用原生推理模式
)这样既能利用模型的原生推理能力,又能通过工具层面的 think/analyze 增强可控性和可解释性。
未来展望
随着推理能力成为 LLM 的标配,工具层面的推理框架会朝着:
- 更灵活的编排:支持 DAG、条件分支
- 更智能的元推理:模型自己决定何时 think/analyze
- 更好的可视化:推理链的交互式展示
但核心思想不变:给模型一个结构化的思考空间,让复杂推理可追溯、可调试、可优化。
参考资源
- Agno 官方文档:docs.agno.com
- ReasoningTools 源码:
libs/agno/agno/tools/reasoning.py - 更多示例:
cookbook/reasoning/
希望这篇文章能帮你理解如何为 Agent 构建"思考工具"。如果你在实践中遇到问题,欢迎在评论区交流!