一、MoE模型的核心架构与工作原理
MoE架构并非单一固定的设计,但其核心组件和工作流程具有共通性。
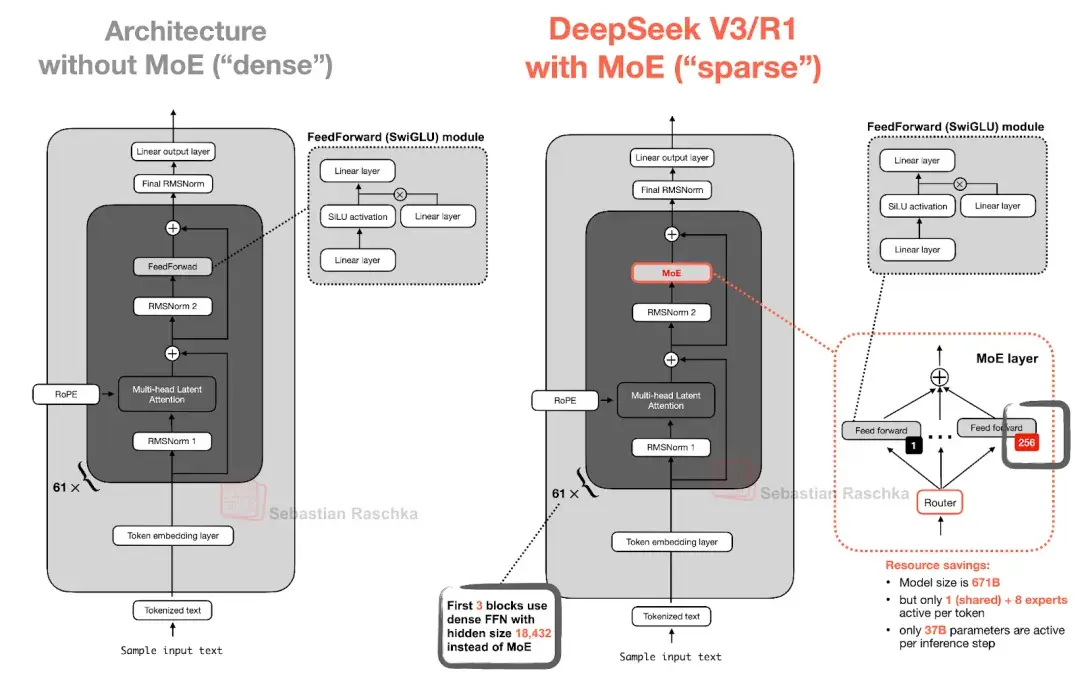
一个典型的MoE层通常嵌入在Transformer架构中,用于替代其中的前馈网络(Feed-Forward Network, FFN)层。
关键的技巧在于:并不为每个 token 启用所有的专家模块(experts),而是由一个「路由器(router)」为每个 token 挑选出其中一小部分进行激活。MoE 的这种设计使得模型拥有极大的参数容量,在训练阶段能吸收更多知识;但在推理时由于稀疏激活,大幅降低了计算开销。
其结构如下:输入: MoE层接收来自前一层(通常是自注意力层)的每个Token的表征向量(Token Representation)。
门控网络 (Gating Network) :
输入的Token表征首先被送入一个轻量级的门控网络。该网络负责为每个Token计算一组权重,这组权重决定了该Token应该被分配给哪些专家网络进行处理。专家网络 (Expert Networks) :
模型包含一组(例如8个、64个或更多)并行的专家网络。每个专家本身通常就是一个标准的FFN(即两个线性层加一个非线性激活函数)。它们在结构上是相同的,但在训练后会学习到不同的参数,从而形成功能上的"专长"。稀疏激活与加权组合:
根据门控网络的输出,每个Token仅被发送给得分最高的k个专家(k通常为1或2)。在这些专家处理完Token后,它们的输出会根据门控网络计算出的权重进行加权求和,形成MoE层的最终输出。残差连接:
与标准Transformer一样,MoE层的输出会通过一个残差连接与该层的输入相加,然后进行层归一化。
这种设计的革命性在于,它实现了总参数量与激活参数量的分离。一个拥有8个专家的MoE模型,其总参数量约等于一个FFN层参数量乘以8,但对于任何一个Token的单次前向传播,其计算量(FLOPs)仅相当于激活了k个专家(例如k=2),远小于一个同等总参数量的稠密模型。这正是Mixtral 8x7B模型(总参数46.7B,激活参数约13B)能够以远低于Llama 2 70B的推理成本,却达到甚至超越其性能的根本原因。DeepSeek-V3 每个 MoE 模块中拥有 256 个专家,总参数量高达 6710 亿。但在推理时,每个 token 实际只激活其中 9 个专家(1 个共享专家 + 路由选出的 8 个专家)
二、 MoE架构三大核心组件
专家网络
门控网络/路由器
整合机制
工作原理:条件计算与稀疏激活MoE的工作流程可以概括为"分发-计算-整合"三部曲:
- 分发 (Dispatch) :
输入批次中的每个令牌,都经过门控网络,门控网络为其选择Top-K个最合适的专家。- 计算 (Compute) :
将令牌发送给各自被选中的专家进行并行计算。未被选中的专家则保持静默,不参与此次计算。- 整合 (Combine) :
将每个令牌对应的K个专家的输出,根据门控网络给出的权重进行加权求和,形成最终的输出。通过这种方式,MoE模型虽然总参数量巨大(例如, Mixtral 8x7B6 模型拥有8个专家,总参数约47B,但实际推理时每个令牌只激活2个专家,计算量仅相当于一个12.9B的密集模型),但其推理时的计算成本(FLOPs)仅与激活的专家数量成正比,远低于同等参数规模的密集模型 。
2.1 专家网络
专家网络(Experts) 每个专家是一个独立的子网络(通常是 FFN),在实际计算中只有部分专家会被激活参与处理。通过让多个专家分担不同数据子集的计算,模型在预训练时可以以较低的计算开销获得大参数量带来的表示能力。
专家网络与自发专化: 经过研究发现,专家都是"自学成才"的。
- 专家网络的角色
在 MOE 模型中,每个专家网络只在接收到相应路由时参与计算。
初期,由于门控网络参数随机,各专家接收到的数据分布比较均匀;
但随着训练进行,局部梯度更新使得某些专家逐渐专注于处理特定类型的输入数据。
这种"自发专化"现象使得模型整体具备了多样化的表示能力。- 在 DeepSeek‑v3 中,不同的专家可能专注于捕捉语言的不同层次信息:例如有的专家更擅长处理句法结构,而有的专家在捕捉长距离依赖或特殊符号时表现更优。这种多样性是通过端到端的训练自发形成的。
2.2 门控网络/路由器
门控网络(Gating/Router) 该模块负责根据输入 token 的特征动态选择激活哪些专家。门控网络一般采用一个带 softmax 的简单前馈网络来计算每个专家的权重。经过训练后,门控网络会逐步学会将相似的输入路由到表现更好的专家。
基本门控函数最常见的门控函数即为一个简单的前馈网络,其将输入与权重矩阵相乘后经过 softmax 得到各专家的概率分布。这种设计允许每个 token 可以被分配给多个专家(通常选择 top‑k 个)。
Gating机制分为三种不同类型:
- 稀疏门控:
激活专家子集
稀疏门控函数选定专家子集来处理每个单独的输入tokens
Shazeer在Gshard提出辅助负载均衡Loss,专家计算的输出由选择概率加权
由于为每个输入token选择专家,因此该方法被视为具有token选择的门控函数- 稠密门控:
激活所有专家- 软门控:
输入token合并和专家合并&可微
2.2.1 动态路由
动态调整与任务难度匹配
最新的研究表明,对于复杂任务可以动态激活更多专家,而对于简单任务仅激活较少专家。例如,某些论文提出了动态路由方法,根据输入的复杂度调整激活专家的数量,从而更高效利用计算资源。
动态路由的正反馈机制门控网络一开始的路由决策可能是近似随机的,但随着专家逐步积累专长,门控网络也会调整其路由策略:
- 正反馈循环:如果某个专家因早期获得较多特定类型数据而表现出色,门控网络便倾向于将更多此类数据路由给它。
- 专家和路由网络的协同演化:专家因接收到较多特定数据而"专长",而门控网络根据反馈不断更新参数,使得路由更加精准。
在 DeepSeek‑v3 的实现中,门控网络不仅考虑输入的特征,还根据历史路由情况动态调整激活专家,从而在保证计算效率的同时使得模型对各类任务都能充分表达。
2.2.2 避免专家"过热"与"冷门"
噪声注入与 Top‑K 路由
为了防止门控网络总是偏向于选取少数专家,常用的策略是在计算专家得分时加入噪声(Noisy Top‑K Gating):
- 噪声注入:在原始得分上添加随机噪声,使得初期路由决策具有更多随机性,帮助专家获得均衡的训练机会。
- 保留 Top‑K:只选取得分最高的 k 个专家,其余专家的权重设为 0,确保计算资源只分配给表现最优的专家。
三、核心挑战:负载不均衡
尽管MoE在扩展性上优势显著,但其训练过程远比密集模型复杂,需要一系列精巧的算法技术来保证训练的稳定性和效率。
在训练过程中,一个常见的棘手问题是负载不均衡(Load Imbalance):门控网络可能倾向于频繁选择少数几个"热门"专家,而其他专家则很少被激活,成为"冷门"专家。这会导致模型训练效率低下,部分参数得不到充分训练,最终损害模型性能 。
辅助负载均衡损失 (Auxiliary Load Balancing Loss)
目的:这是解决负载不均衡最经典和常用的方法。其核心思想是在主任务损失(如交叉熵损失)之外,额外增加一项损失函数,用于惩罚专家负载的不均匀分配,鼓励所有专家被均匀利用 。
数学公式:该损失函数有多种形式,一种常见的形式源自Switch Transformer,其定义如下 :
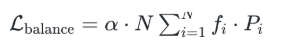
带噪声的Top-K门控 (Noisy Top-K Gating)
目的:为了增加路由过程的随机性,避免门控网络在训练早期就"固化"其选择偏好,研究者们提出了在门控网络的logit上添加高斯噪声的方法 。
机制:在计算最终的Top-K选择之前,向门控网络的输出添加一个小的随机噪声。这有助于在训练初期进行更广泛的探索,让更多的专家有机会被激活和训练,从而提升模型的稳定性和最终性能 。
噪声的引入使得初始路由决策具有随机性,降低了某些专家因早期优势而被持续选中的风险。同时,一些方法采用随机抽样机制,进一步鼓励低激活率的专家获得机会。
专家容量因子 (Expert Capacity Factor)
目的:为了从硬件层面强制避免单个专家过载,MoE系统会为每个专家设置一个"容量"上限,即在一个批次中最多能处理的令牌数量 。额外的 token 会被分配到其他专家或溢出处理。这种机制不仅防止了单个专家过度负载,还促使门控网络在数据分配上更加分散。
机制:容量通常按批次中令牌总数和专家数量的平均值来设定,再乘以一个"容量因子"(Capacity Factor, C)。例如,C=1.25意味着每个专家的容量是平均负载的125%。如果路由到某个专家的令牌数超过其容量,多余的令牌会被"丢弃"(dropped),其表示将直接通过残差连接传递到下一层,不经过专家计算 。这是一种在计算效率和模型性能之间的权衡。
新兴的无辅助损失均衡方法 (Auxiliary-Loss-Free Balancing Methods)
背景:尽管辅助损失很有效,但它会引入额外的超参数,且可能对主任务的梯度产生干扰。因此,自2023年以来,无辅助损失的均衡方法成为研究热点。
机制:这类方法不再依赖于一个独立的损失项,而是直接在路由机制本身进行调整。例如,DeepSeek-V27模型采用了一种策略,通过动态调整每个专家的路由偏置(bias)来直接控制负载,如果一个专家过热,就降低其偏置,反之则提高,从而实现无需额外损失项的自适应负载均衡。
四、分布式训练与并行策略
由于MoE模型参数量巨大,单张GPU无法承载,必须进行分布式训练。
除了常见的数据并行和张量并行,MoE引入了独特的专家并行(EP):将不同的专家分布到不同的GPU(或节点)上。
4.1 混合并行:
现代MoE训练框架(如Megatron-LM、DeepSpeed)通常采用数据并行、张量并行和专家并行相结合的混合并行策略,以最大化利用集群资源 。
4.2 通信优化:
专家并行会引入密集的All-to-All通信模式,即每个GPU都需要将令牌发送给其他GPU上的专家,并接收计算结果。这是训练的主要瓶颈。优化手段包括使用高性能网络互联(如NVLink、Infiniband)、优化通信库(如NCCL)以及设计网络拓扑感知的并行策略 。
MoE及其优化技术->COMET(字节)
4.3 面向边缘设备的部署与推理优化
将庞大的MoE模型部署到手机、智能汽车等边缘设备上是一个新兴且充满挑战的研究方向。
核心挑战:边缘设备内存和算力极其有限,而MoE模型的总参数量巨大。
其优化技术如下:
- 专家卸载 (Expert Offloading) :
只在GPU/NPU上保留少量活跃专家或一个专家缓存,其余大量不常用的专家权重存储在相对较慢的CPU内存或闪存中,按需加载 。- 缓存感知路由 (Cache-Aware Routing) :
设计一种路由策略,使其在选择专家时,倾向于选择那些已经被加载到缓存中的专家,从而最大化缓存命中率,减少从慢速存储中加载专家所带来的延迟 。- 模型蒸馏与压缩 (Model Distillation & Compression) :
将一个大型MoE模型的知识蒸馏到一个更小的密集模型或更小规模的MoE模型中,使其适合边缘部署 。
EdgeMoE8和SiDA-MoE9等研究项目已经验证了这些技术的可行性,能够在移动设备上实现显著的推理延迟降低(高达2-3倍)和内存占用减少。
五、开源框架与推理引擎
一系列开源工具极大地推动了MoE的普及和发展:
- DeepSpeed-MoE10 :微软推出的DeepSpeed11库提供了成熟的MoE实现,集成了高效的CUDA内核、负载均衡策略和内存优化技术,支持万亿级别模型的训练与推理 。
- Tutel12 :同样来自微软,Tutel是一个专注于MoE层本身计算优化的库。它提供了高度优化的稀疏计算内核,可以作为插件集成到PyTorch等框架中,显著提升MoE层的计算效率 。
- FastMoE13 :一个由学术界主导的轻量级、易于使用的MoE训练系统,也基于PyTorch构建 。
- Megablocks14 :https://github.com/stanford-futuredata/megablocks
- Fairseq15 :https://github.com/facebookresearch/fairseq/tree/main/examples/moe_lm
- OpenMoE16 :https://github.com/XueFuzhao/OpenMoE
六、性能比较:MoE模型 vs. 密集模型
MoE模型的核心价值是在相似甚至更低的计算成本下,达到或超越更大规模的密集模型的性能。
大量研究和实践表明,MoE模型在性能和计算成本之间取得了更优的平衡。在相同的计算预算(FLOPs)下,MoE模型通常能展现出更低的困惑度(Perplexity)和更高的下游任务准确率 。
- SwitchTransformer:
Google的研究显示,一个与T5-Base(220M参数)计算量相当的Switch Transformer模型,其性能可以媲美T5-Large(770M参数) 。在TPUv3硬件上,其推理速度比计算量匹配的密集模型快了高达7倍 。- GLaM:
同样来自Google的GLaM模型,虽然总参数量高达1.2T,但其推理成本仅为GPT-3 (175B)的三分之一,却在多项零样本(Zero-shot)NLP任务上取得了更优异的成绩。- Mixtral 8x7B :
由Mistral AI发布的开源模型,其以约13B的激活参数,在众多基准测试中击败了拥有70B参数的Llama 2 70B模型,成为开源社区的标杆。
性能对比:MoE vs. 稠密模型
| 评估维度 | 稠密模型 | MoE模型 | 分析 |
|---|---|---|---|
| 参数效率 | 低。所有参数在每次前向传播中都被激活。 | 高。总参数量巨大,但每次仅激活一小部分。 | MoE以更高的参数量换取了更强的模型容量,但保持了计算成本的可控性。 |
| 训练成本 | 高。达到SOTA性能需要巨大的FLOPs。 | 相对更低。在相同的性能水平下,MoE所需的训练FLOPs显著少于稠密模型。 | MoE的稀疏性使其成为"计算最优训练"的有效路径。 |
| 推理成本 | 高。与参数量成正比,延迟高,部署昂贵。 | 显著更低。推理FLOPs和延迟取决于激活参数量,而非总参数量。 | 这是MoE在实际应用中最具吸引力的优势,使得更强大的模型能够被实际部署。 |
| 模型性能 | 遵循Scaling Law,性能随参数和数据增长。 | 在同等激活参数下性能通常不如稠密模型;但在同等计算成本下,性能远超稠密模型。 | MoE通过增加总参数量,为模型提供了更广阔的"解空间",从而在同等计算预算下获得更高智能。 |
挑战与权衡
尽管推理高效,但MoE模型也存在固有挑战:
- 巨大的内存占用:需要存储所有专家的参数,对GPU显存要求极高。
- 复杂的训练系统:需要专门的并行策略(如专家并行)和通信优化,训练基础设施复杂。
- 通信开销:专家并行中的All-to-All通信是主要瓶颈,尤其是在大规模集群中。