文章目录
- 前言
- 一、RAG对话流程图
-
- RAG对话主流程
- 子流程:知识库文档相似度、分数检索
- [子流程:SSE Stream流数据推送](#子流程:SSE Stream流数据推送)
- 二、流程核心部分说明
-
- [2.1 修改PgVector向量索引策略为余弦相似度:"cosine"](#2.1 修改PgVector向量索引策略为余弦相似度:"cosine")
- [2.2 内容增强检索的相似度和分数查询](#2.2 内容增强检索的相似度和分数查询)
-
- [2.2.1 查询内容加强embedding](#2.2.1 查询内容加强embedding)
- [2.2.2 相似度和分数查询](#2.2.2 相似度和分数查询)
- 3.余弦距离转换成余弦相似度
- 四、常见问题
前言
`知识库管理 ' 创建知识库:【智慧城市 (pg @ text-embedding-v1)】,上传文件:"智慧城市.xlsx",
文档向量化加强embedding存储,完成 文档知识库的创建。本章节主要是基于 知识库,跟踪、分析【知识库做 RAG对话】的流程。
1.知识库管理
- 新创建知识库【智慧城市 (pg @ text-embedding-v1)】*,上传文件 "智慧城市.xlsx"
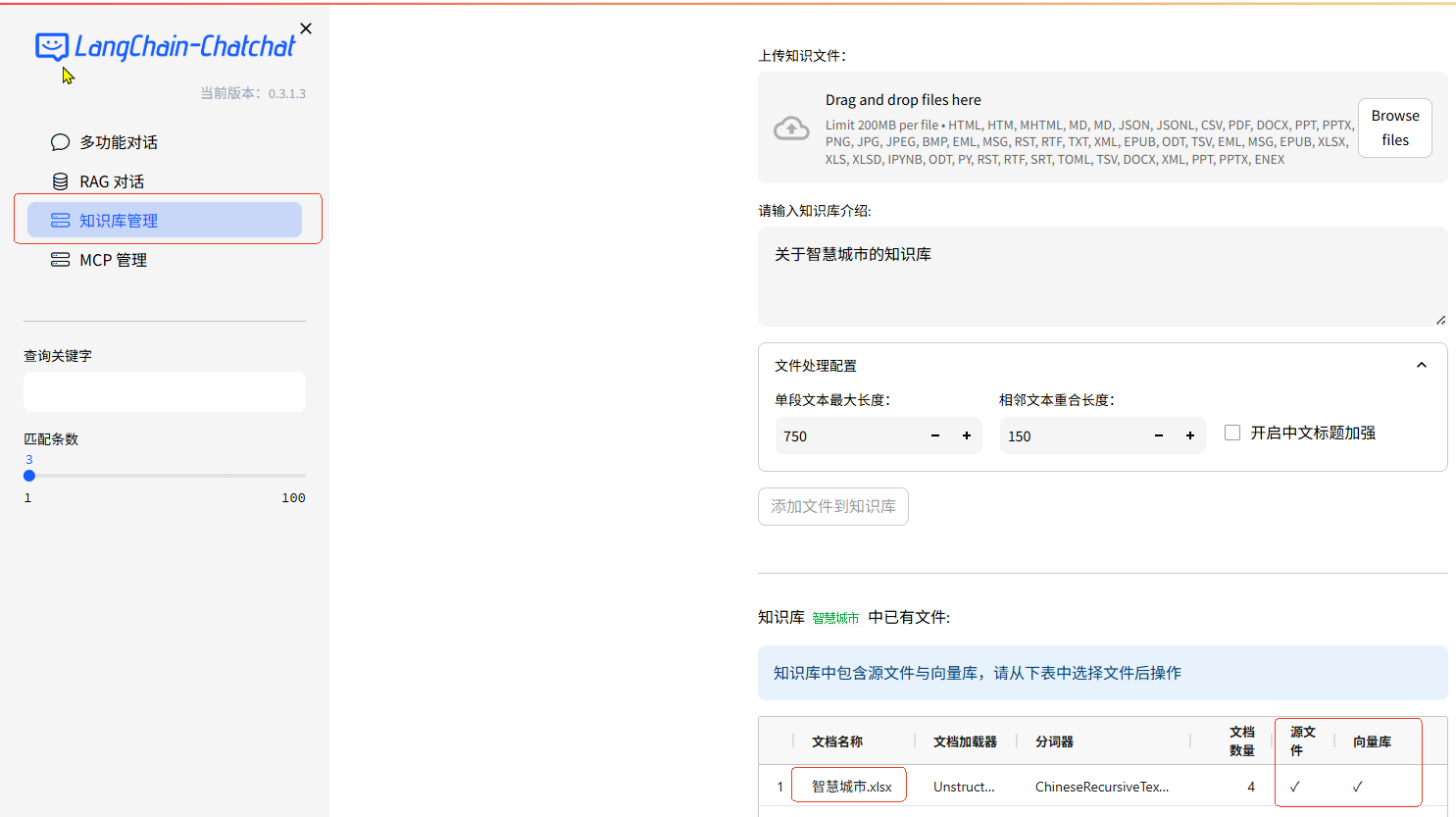
智慧城市.xlsx文件:

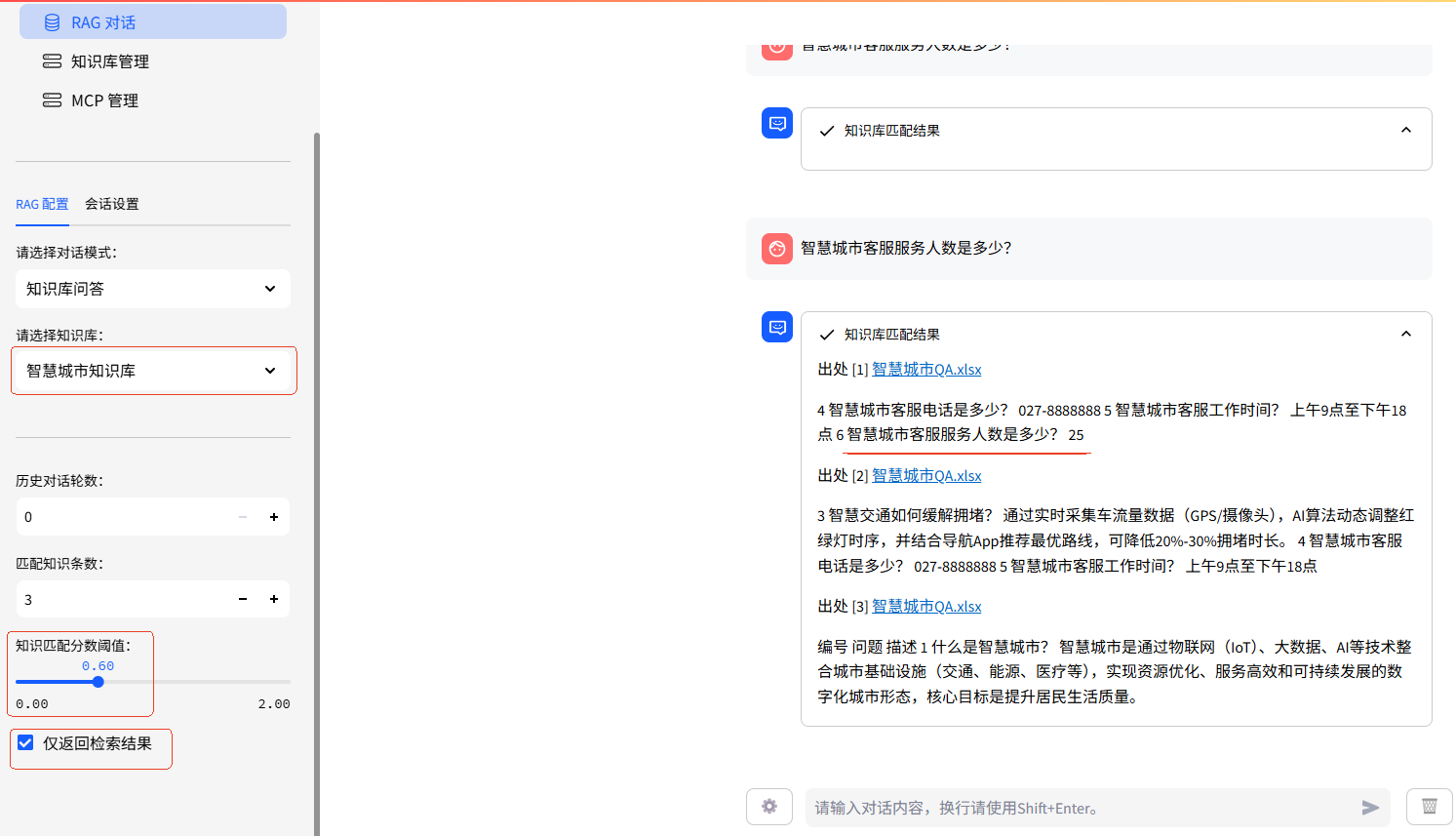
2.RAG对话
选择知识库 :智慧城市
知识匹配分数阈值 : 0.5
勾 选 :仅返回检索结果
前提
Langchain-Chatchat一、本地开发环境部署
PyCharm 配置debug调试参数:start -a
一、RAG对话流程图
RAG对话主流程
流程图生成的AI智能体 mermaid脚本
markup
请使用mermaid 根据下面的文案 画一个时序图,请整合到一个图中使用 alt ... end 区分四大主流程。确保图表能正常生成的情况下在考虑友好性
RAG对话主流程
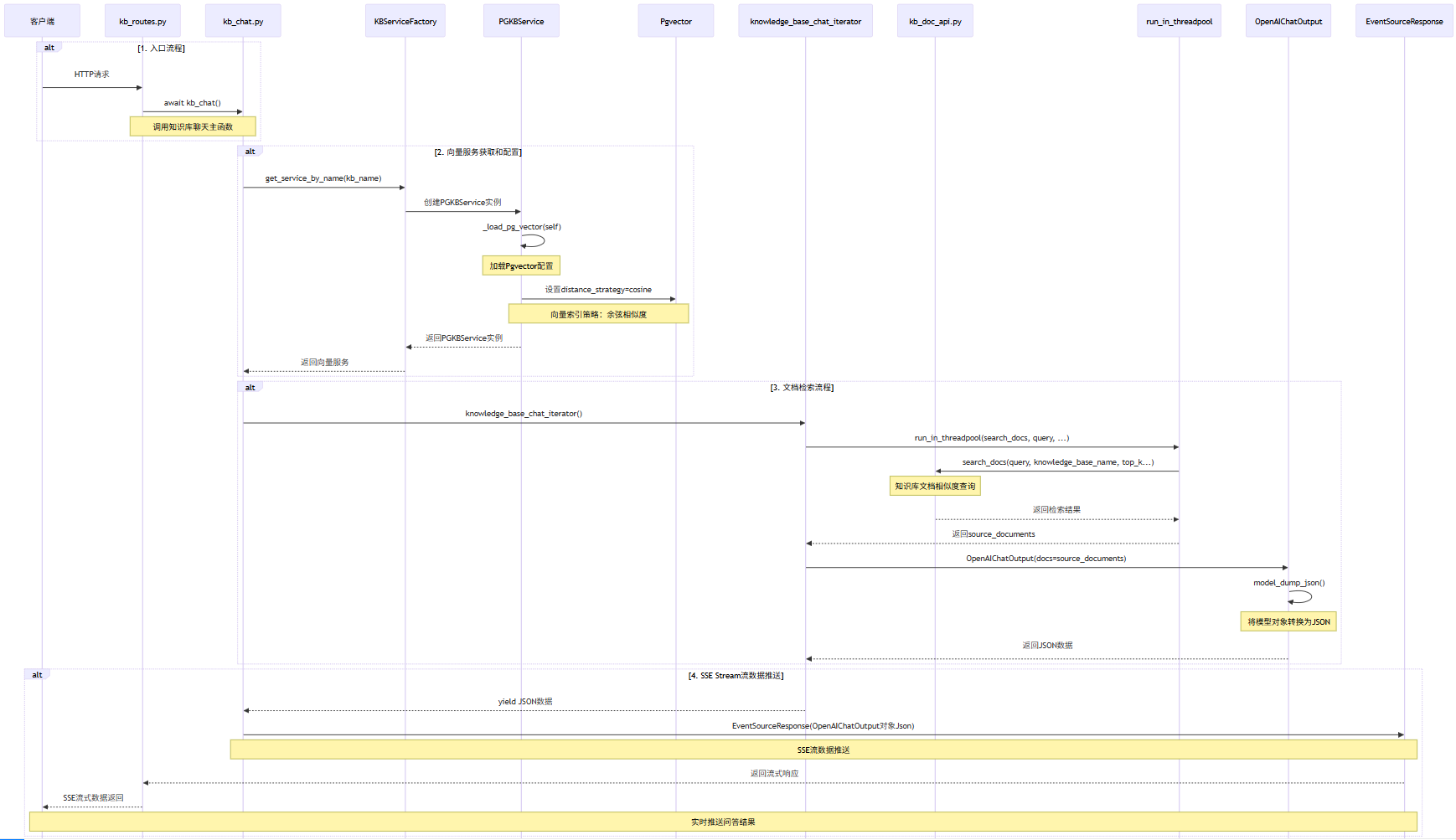
1.入口kb_routes.py#async def kb_chat_endpoint(),调用await kb_chat()
2.kb_chat.py#await kb_chat()
a.获取向量服务PGKBService:KBServiceFactory.get_service_by_name(kb_name)
i.加载Pgvector:调用def _load_pg_vector(self),设置参数distance_strategy=cosine (向量索引策略:余弦相似度)
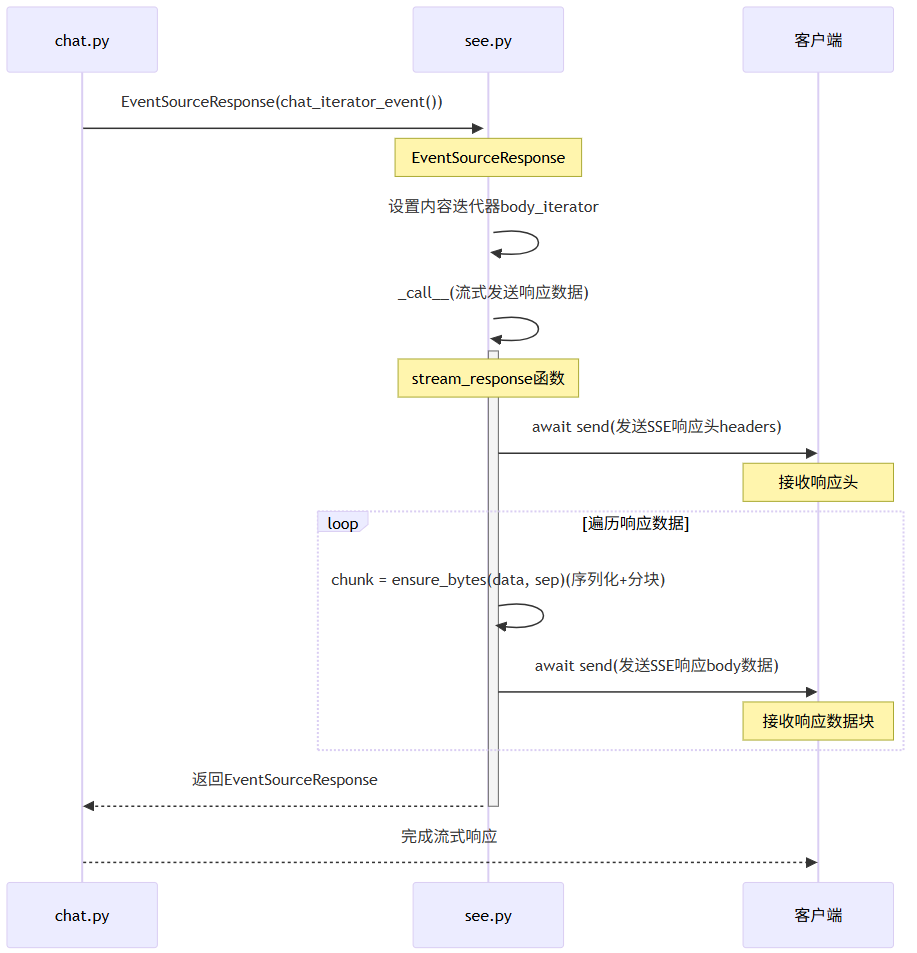
b.返回EventSourceResponse(knowledge_base_chat_iterator()),返回问答的结果
i.knowledge_base_chat_iterator()方法:内部执行:
1.wait run_in_threadpool(search_docs,query=query,...),返回source_documents;知识库文档做相似
度查询:kb_doc_api.py#def search_docs(query,knowledge_base_name,top_k...)
2.将OpenAIChatOutput模型对象转换成Json:yield
OpenAIChatOutput(....docs=source_documents)).model_dump_json()
ii.SSE Stream流数据推送,调用EventSourceResponse(OpenAIChatOutput对象Json),见子流程:SSE Stream流数据推送子流程:知识库文档相似度、分数检索
流程图生成的AI智能体 mermaid脚本
markup
请使用mermaid 根据下面的文案 画一个时序图,请整合到一个图中使用 alt ... end 区分四大主流程。确保图表能正常生成的情况下在考虑友好性
子流程:内容增强检索的相似度和分数查询
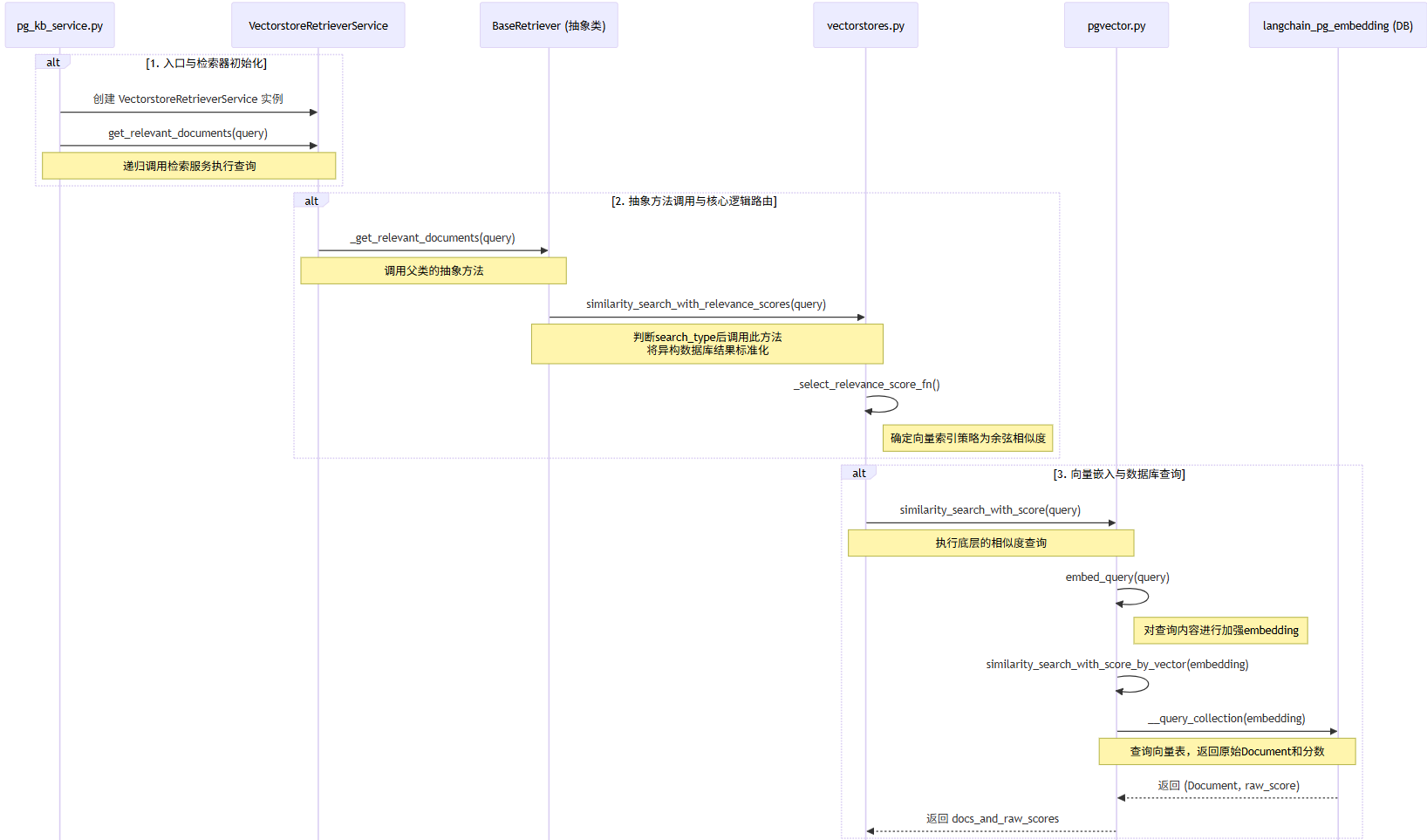
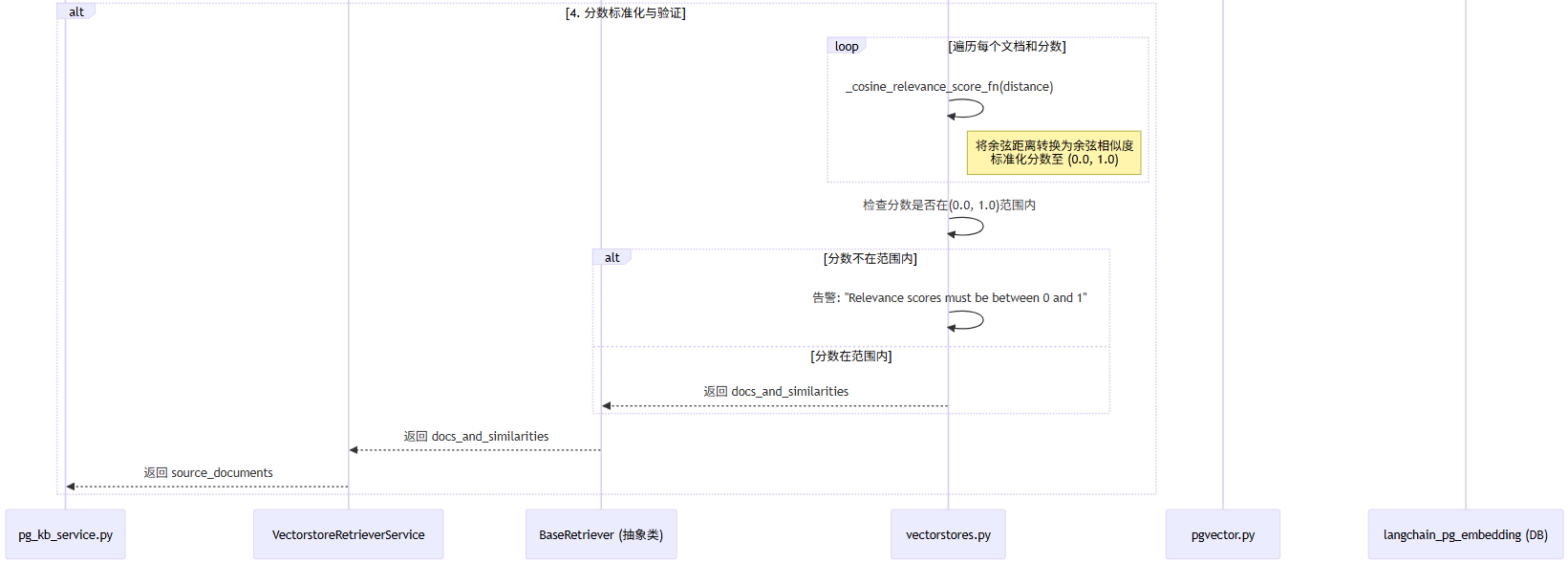
入口pg_kb_service.py#def do_search(query,top_k,score_threshold)
a.创建文档检索服务实例VectorstoreRetrieverService,并递归调用vectorstore.py文件class VectorstoreRetrieverService(BaseRetrieverService)类#get_relevant_documents(query,)方法执行查询
b.递归父类文档检索服务BaseRetriever 抽象方法_get_relevant_documents(query,):retrievals.py文件
c.父类回调文档检索服务_get_relevant_documents(query,*)方法,此方法内判断search_type等于'similarity_score_threshold'时,调用vectorstores.py#similarity_search_with_relevance_scores(query:智慧城市客服服务人数是多少)相似性分数接口,设置向量索引策略和相似度查询,将异构的向量数据库检索结果标准化,内部执行
i.设置向量索引策略:relevance_score_fn = self._select_relevance_score_fn()确定向量索引策略余弦相似度cosine;
ii.相似度查询:similarity_search_with_score(query, k, **kwargs),流程如下:
1.pgvector.py:调用def similarity_search_with_score(query:智慧城市客服服务人数是多少),对查询内容进行加强embedding:self.embedding_function.embed_query(query);
2.对加强embedding内容进行向量查询度和分数查询:similarity_search_with_score_by_vector(embedding)
3.最终调用def __query_collection(embedding)查询向量表langchain_pg_embedding,返回Document对象(内容,分数score)
d.余弦距离转换成余弦相似度:调用vectorstores.py#_cosine_relevance_score_fn(distance)遍历Document对象(内容,分数score),标准化文档和分数,分数范围在(0.0,1.0)之间,返回docs_and_similarities
e.相似度检查:遍历docs_and_similarities属性similarity,是否在范围(0.0,1.0)之间
i.如果不在范围内告警:Relevance scores must be between 0 and 1...);
ii.在范围内则返回docs_and_similarities子流程:SSE Stream流数据推送
二、流程核心部分说明
2.1 修改PgVector向量索引策略为余弦相似度:"cosine"
pg_kb_service.py#def _load_pg_vector(self)
代码如下(片断):
python
def _load_pg_vector(self):
self.pg_vector = PGVector(
embedding_function=get_Embeddings(self.embed_model),
collection_name=self.kb_name,
distance_strategy=DistanceStrategy.COSINE,
connection=PGKBService.engine,
connection_string=Settings.kb_settings.kbs_config.get("pg").get("connection_uri"),
)说明:修改PGVector 向量索引策略为余弦相似度:"cosine"时,在后续执行 向量相似度和分数检索时才能将 PG向量表内的加强余弦距离转换成余弦相似度,分数控制在(0.0,1.0)之间,否则在检测分数范围时,由于不在范围内告警:Relevance scores must be between 0 and 1...);,无法响应到任何内容。
2.2 内容增强检索的相似度和分数查询
主体入口 vectorstores.py#def similarity_search_with_relevance_scores
python
def similarity_search_with_relevance_scores(
self,
query: str,
k: int = 4,
**kwargs: Any,
) -> List[Tuple[Document, float]]:
score_threshold = kwargs.pop("score_threshold", None) #知识匹配分数阈值 0.5
# 主体 向量相似度和分数检索
docs_and_similarities = self._similarity_search_with_relevance_scores(
query, k=k, **kwargs
)
# 在检测分数范围(0.0,1.0)之间,
if any(
similarity < 0.0 or similarity > 1.0
for _, similarity in docs_and_similarities
):
# 不在,告警
warnings.warn(
"Relevance scores must be between"
f" 0 and 1, got {docs_and_similarities}"
)
if score_threshold is not None:
# 分数是否在 知识匹配分数阈值 0.5 之上
docs_and_similarities = [
(doc, similarity)
for doc, similarity in docs_and_similarities
if similarity >= score_threshold
]
# 不在,告警
if len(docs_and_similarities) == 0:
warnings.warn(
"No relevant docs were retrieved using the relevance score"
f" threshold {score_threshold}"
)
# 在,返回docs_and_similarities对象,包括:相似的文档内容和分数-similarity
return docs_and_similarities说明:PGVector 默认的向量索引策略为最大内积:"l2",在后续执行 向量相似度和分数检索,分数控制会在(0.0,无穷大)间,,由于不在范围内一直告警:Relevance scores must be between 0 and 1...),无法响应到任何内容。
2.2.1 查询内容加强embedding
localai_embeddings.py#
python
def embed_query(self, text: str) -> List[float]:
"""Call out to LocalAI's embedding endpoint for embedding query text.
Args:
text: The text to embed.
Returns:
Embedding for the text.
"""
embedding = self._embedding_func(text, engine=self.deployment)
return embedding
def _embedding_func(self, text: str, *, engine: str) -> List[float]:
"""Call out to LocalAI's embedding endpoint."""
# handle large input text
if self.model.endswith("001"):
# See: https://github.com/openai/openai-python/issues/418#issuecomment-1525939500
# replace newlines, which can negatively affect performance.
text = text.replace("\n", " ")
return (
embed_with_retry(
self,
input=[text],
**self._invocation_params,
)
.data[0]
.embedding
)
def embed_with_retry(embeddings: LocalAIEmbeddings, **kwargs: Any) -> Any:
"""Use tenacity to retry the embedding call."""
retry_decorator = _create_retry_decorator(embeddings)
@retry_decorator
def _embed_with_retry(**kwargs: Any) -> Any:
response = embeddings.client.create(**kwargs)
return _check_response(response)
return _embed_with_retry(**kwargs)2.2.2 相似度和分数查询
pgvector.py#similarity_search_with_score_by_vector(embedding...)
python
def similarity_search_with_score_by_vector(
self,
embedding: List[float],
k: int = 4,
filter: Optional[dict] = None,
) -> List[Tuple[Document, float]]:
results = self.__query_collection(embedding=embedding, k=k, filter=filter)
return self._results_to_docs_and_scores(results)
python
# 向量加强检索 查询
def __query_collection(
self,
embedding: List[float],
k: int = 4,
filter: Optional[Dict[str, str]] = None,
) -> List[Any]:
"""Query the collection."""
with Session(self._bind) as session: # type: ignore[arg-type]
collection = self.get_collection(session)
if not collection:
raise ValueError("Collection not found")
filter_by = [self.EmbeddingStore.collection_id == collection.uuid]
if filter:
if self.use_jsonb:
filter_clauses = self._create_filter_clause(filter)
if filter_clauses is not None:
filter_by.append(filter_clauses)
else:
# Old way of doing things
filter_clauses = self._create_filter_clause_json_deprecated(filter)
filter_by.extend(filter_clauses)
_type = self.EmbeddingStore
results: List[Any] = (
session.query(
self.EmbeddingStore,
self.distance_strategy(embedding).label("distance"), # type: ignore
)
.filter(*filter_by)
.order_by(sqlalchemy.asc("distance"))
.join(
self.CollectionStore,
self.EmbeddingStore.collection_id == self.CollectionStore.uuid,
)
.limit(k)
.all()
)
return results3.余弦距离转换成余弦相似度
vectorstores.py#_cosine_relevance_score_fn(distance)
python
@staticmethod
def _cosine_relevance_score_fn(distance: float) -> float:
"""Normalize the distance to a score on a scale [0, 1]."""
return 1.0 - distance四、常见问题
问题1:RAG对话:一直告警Relevance scores must be between 0 and 1...),XXXXXXXXX,无法响应到任何内容。
原因:PGVector 默认的向量索引策略为最大内积:"l2",在后续执行 向量相似度和分数检索,分数范围为(0.0,无穷大)间,不在(0,1)范围间。
解决方案:修改PGVector 默认的向量索引策略为弦相似度:COSINE,将向量检索的分数控制在(0,1)范围间.