一、痛点
痛点一:为什么我的Token消耗的这么快
Token的消耗量通常受到下面两个因素的影响
- 输入和输出的Token数量:输入的Token越多,输出的Token也会相应增加,因为模型会基于输入的上下文进行内容生成。
- 任务复杂性:更复杂的任务通常需要消耗更多的Token,而多模态的Agent往往消耗的Token会更高。
为什么模糊的提示词会增加Token的消耗量?
- 模糊的提示词可能包含大量与输出不相关的内容,增加输入的Token量。
- 模糊的提示词通常缺乏具体细节或明确约束,导致模型无法直接理解用户意图。为了覆盖可能的解释,模型倾向于生成更长、更全面的响应,以避免遗漏关键信息,从而增加输出token数量。
- 模糊的提示词往往无法精准的生成用户想要的内容。用户可能因输出不符合预期而多次修改提示,形成无效交互循环,无形中浪费Token。
痛点二:AI修复代码为什么总是"差点意思"?
一般都是拿到Sonar 扫描结果复制粘贴, 让AI修复后,一个一个改, 又太慢, 太多问题要么修复不准确,要么把好的代码也改坏了,还有就是问题 太多, 上下文超限修改失败
举个真实的例子: Sonar报告:ActivityServiceImpl.java 第120行存在空指针风险
我的提示词(第一版):
css
请修复以下问题:第120行存在空指针风险
代码:
[粘贴整个ActivityServiceImpl.java文件,可能是几千行]AI的回复:
- 情况1:"这个文件太长了,请提供更具体的代码片段"
- 情况2:修复了空指针,但把旁边的业务逻辑也改了
- 情况3:"Token超出限制,无法处理"
问题根源在哪?
- 上下文冗余:超大文件代码中,真正相关的可能只有20行
- 缺乏规范引导:没告诉AI要遵循什么编码规范
- 信息不准确:没有精确指出问题在哪个方法、什么结构中
- 没有示例:AI缺乏类似问题的修复参考
二、转机:Cursor结合MCP打造自动化修复流程
关键问题在于:如何将Sonar扫描结果转换为AI能高效理解的结构化提示词。
于是,我利用MCP(Model Context Protocol)协议为Cursor开发了一套智能提示词生成系统。
什么是MCP?
MCP(Model Context Protocol)是一个开放协议,Cursor支持这个协议,允许我们通过Python等语言编写自定义工具,直接集成到Cursor的AI助手中。简单说就是:让AI拥有调用你自己编写的工具的能力。
我的方案架构
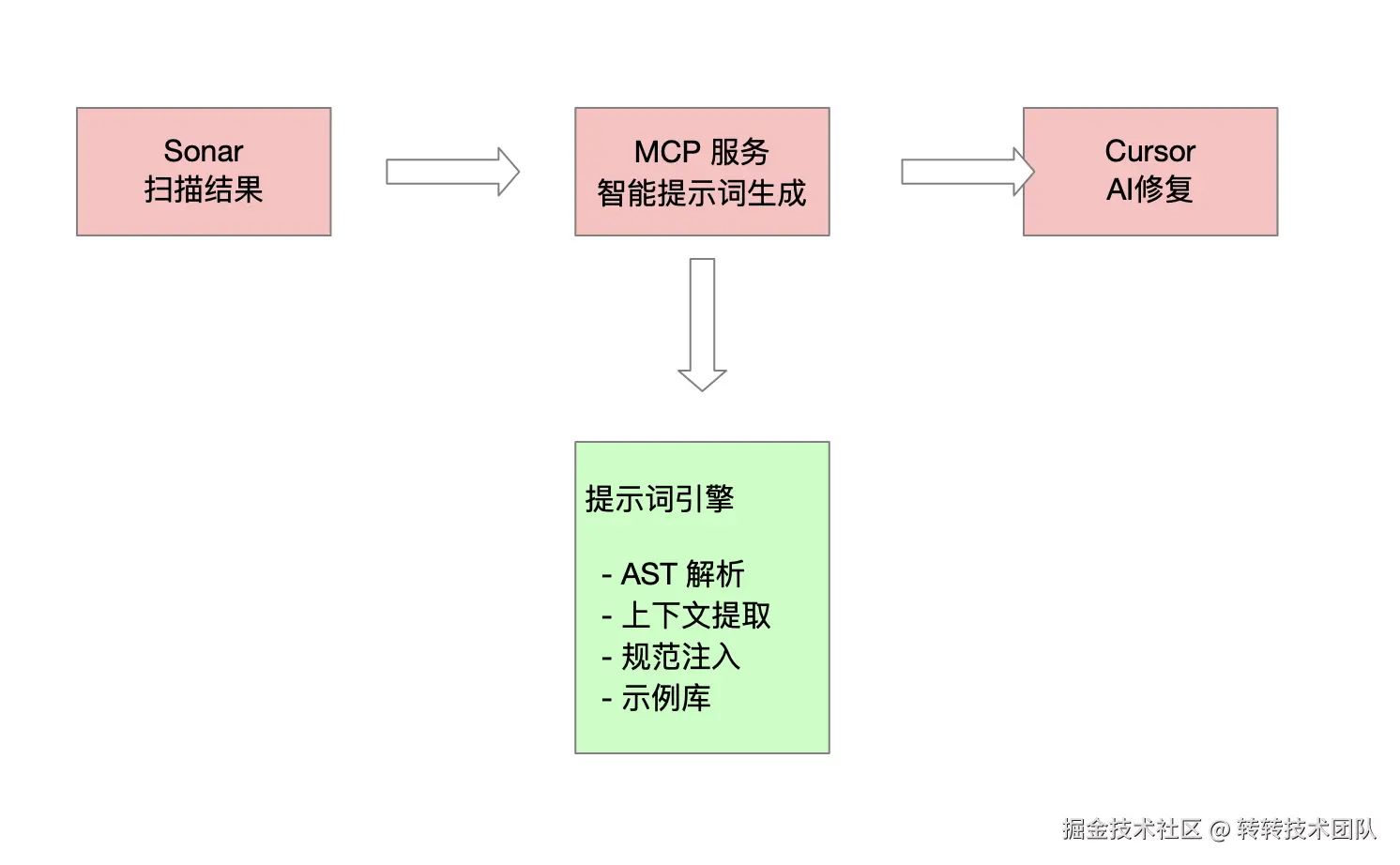
三、核心方案:六步智能提示词生成法
这套方案的核心思想是:让AI精确理解问题,而不是让AI去猜测问题。
整个系统基于以下6个步骤构建:
第一步:问题类型识别
python
class IssueTypeClassifier:
"""将Sonar规则映射到问题类型"""
RULE_MAPPING = {
# 空指针问题
"java:S2259": "NullPointer",
"java:S2637": "NullPointer",
# 资源泄露
"java:S2095": "ResourceLeak",
"java:S2093": "ResourceLeak",
# 安全漏洞
"java:S3649": "SQLInjection",
"java:S2076": "CommandInjection",
# 代码规范
"java:S117": "NamingConvention",
"java:S1192": "DuplicateString",
}
@staticmethod
def classify(rule_key: str) -> str:
"""根据规则ID分类问题类型"""
return IssueTypeClassifier.RULE_MAPPING.get(
rule_key,
"General"
)第二步:AST代码结构解析
什么是AST?
AST(Abstract Syntax Tree,抽象语法树)是将代码理解成树形结构的技术。
当Sonar告诉你"第120行有空指针问题",我们需要知道:
- 第120行在哪个方法里?
- 这个方法从哪行开始 ,到哪行结束?
- 方法的完整信息(方法名、参数、返回值)
AST解析 = 像编译器一样理解代码结构
想象代码是一个家族,AST就是家谱树:
yaml
ClassDeclaration: ActivityServiceImpl(类)
│
├─ FieldDeclaration: activityFacadeHelper(成员变量)
│
├─ MethodDeclaration: queryActivityListWithNewImei(方法)
│ ├─ position: line 106
│ ├─ parameters: [Long orderId, String newMachineUuid]
│ ├─ return_type: OrderAllowActivityMiVO
│ └─ body: {...} ← 第120行在这里
│
└─ MethodDeclaration: editActivityListWithNewImei(另一个方法)使用javalang进行AST解析
javalang是一个纯Python库,用Python重新实现了Java语法解析器,不需要安装Java环境。
python
import javalang
class JavaCodeParser:
"""Java代码结构解析器 - 使用AST精确解析"""
@staticmethod
def extract_method_context(file_path: str, line_number: int) -> Optional[Dict]:
"""使用javalang进行AST解析,精确定位方法"""
with open(file_path, 'r', encoding='utf-8') as f:
code = f.read()
# 1. 解析Java代码,生成AST(语法树)
tree = javalang.parse.parse(code)
# 2. 遍历AST,查找包含目标行的方法节点
for path, node in tree.filter(javalang.tree.MethodDeclaration):
method_start = node.position.line
method_end = calculate_method_end(node) # 计算方法结束位置
# 3. 检查目标行是否在此方法范围内
if method_start <= line_number <= method_end:
return {
'class_name': extract_class_name(path),
'method_name': node.name, # 方法名
'start_line': method_start, # 方法开始行
'end_line': method_end, # 方法结束行
'modifiers': node.modifiers, # ['public', 'static']
'return_type': node.return_type.name, # 返回值类型
'parameters': [p.name for p in node.parameters], # 参数列表
}
return NoneAST解析的价值:
- 精确定位 :直接知道第120行在
queryActivityListWithNewImei方法内,而不是editActivityListWithNewIme方法 - 完整信息:获取方法名、参数类型、返回值等元信息
- 语法理解:像编译器一样理解Java语法,不会被注释、字符串、Lambda表达式干扰
- 高准确率:准确率可达99%+
javalang的特点:
- 纯Python库,只需
pip install javalang - 不需要安装JDK或Java环境
- 提供完整的Java语法树节点
- 支持Java 8+的语法特性
第三步:智能上下文提取
python
class ContextExtractor:
"""根据问题类型智能提取代码上下文"""
# 不同问题类型的提取策略配置
EXTRACTION_RULES = {
"NullPointer": {
"range": "full_method", # 提取完整方法
"max_lines": 150,
"include_imports": True, # 包含import语句
"include_class_declaration": True, # 包含类声明
},
"ResourceLeak": {
"range": "full_method",
"max_lines": 100,
"include_imports": True,
"include_class_declaration": True,
},
"SQLInjection": {
"range": "full_method",
"max_lines": 120,
"include_imports": False,
"include_class_declaration": True,
},
"NamingConvention": {
"range": "surrounding", # 只提取周围代码
"max_lines": 30,
"include_imports": False,
"include_class_declaration": False,
},
"General": {
"range": "surrounding",
"max_lines": 50,
"include_imports": False,
"include_class_declaration": False,
},
}
@staticmethod
def extract(file_path: str, line_number: int, issue_type: str) -> str:
"""智能提取代码上下文"""
rules = ContextExtractor.EXTRACTION_RULES.get(
issue_type,
ContextExtractor.EXTRACTION_RULES["General"]
)
try:
with open(file_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
context_lines = []
# 1. 提取package和imports(如果需要)
if rules.get("include_imports"):
for line in lines[:50]:
if line.strip().startswith(('package ', 'import ')):
context_lines.append(line)
elif line.strip() and not line.strip().startswith('//'):
break
if context_lines:
context_lines.append('\n')
# 2. 提取方法或周围代码
if rules["range"] == "full_method":
method_info = JavaCodeParser.extract_method_context(file_path, line_number)
if method_info:
start = method_info['start_line'] - 1
end = method_info['end_line']
# 如果需要类声明,向上查找
if rules.get("include_class_declaration"):
for i in range(start, -1, -1):
if 'class ' in lines[i]:
context_lines.append(lines[i])
context_lines.append(' // ... 其他成员 ...\n\n')
break
context_lines.extend(lines[start:end])
else:
# 回退到周围代码
start = max(0, line_number - 25)
end = min(len(lines), line_number + 25)
context_lines.extend(lines[start:end])
else:
# 提取周围代码
max_lines = rules["max_lines"]
start = max(0, line_number - max_lines // 2)
end = min(len(lines), line_number + max_lines // 2)
context_lines.extend(lines[start:end])
# 3. 限制总行数
if len(context_lines) > rules["max_lines"]:
context_lines = context_lines[:rules["max_lines"]]
context_lines.append('\n// ... 后续代码省略 ...\n')
return ''.join(context_lines)
except Exception as e:
logging.error(f"提取失败: {e}")
return f"// 无法读取文件: {file_path}"核心策略:
- 差异化提取:空指针问题提取150行含imports,命名规范只提取30行
- 智能回退:AST解析失败时自动回退到简单提取
- Token控制:通过max_lines限制,避免上下文过长
第四步:分层模板体系
python
class PromptTemplateEngine:
"""分层的提示词模板引擎"""
# Java语言规范
JAVA_STANDARDS = """
请遵循以下Java开发规范:
1. 遵循阿里巴巴Java开发手册的编码规范
2. 所有可能为null的参数必须进行防御性检查
3. 资源(文件流、数据库连接等)必须使用try-with-resources自动管理
4. 异常必须妥善处理,不得吞掉异常
5. 方法复杂度不得过高,保持代码可读性
6. 变量和方法命名要清晰、符合驼峰命名规范
"""
# 问题类型特定模板
ISSUE_TEMPLATES = {
"NullPointer": {
"task": "修复以下代码中的空指针风险问题",
"requirements": """
修复要求:
1. 在方法开始处对可能为null的参数进行检查
2. 如果参数为null,抛出IllegalArgumentException异常,并提供清晰的错误信息
3. 保持原有业务逻辑不变
4. 不要修改方法签名
5. 确保修复后不影响其他正常调用
"""
},
"ResourceLeak": {
"task": "修复以下代码中的资源泄露问题",
"requirements": """
修复要求:
1. 使用try-with-resources语句包裹需要关闭的资源
2. 确保在任何情况下(正常或异常)资源都能正确释放
3. 保持原有异常处理方式
4. 保持方法签名不变
"""
},
"SQLInjection": {
"task": "修复以下代码中的SQL注入安全漏洞",
"requirements": """
修复要求:
1. 必须使用参数化查询(PreparedStatement)替代字符串拼接
2. 使用占位符(?)和参数绑定传递用户输入
3. 不得使用字符串拼接或格式化方式构建SQL语句
4. 保持查询逻辑不变
"""
},
}
@staticmethod
def generate(issue_type: str, issue_data: dict, code_context: str, examples: str = "") -> str:
"""生成最终提示词"""
template = PromptTemplateEngine.ISSUE_TEMPLATES.get(
issue_type,
{"task": "修复以下代码问题", "requirements": "保持代码风格与项目一致"}
)
# 组装提示词
prompt = f"""你是一位精通Java开发的资深工程师。
任务:{template['task']}
编码规范:{PromptTemplateEngine.JAVA_STANDARDS.strip()}
"""
# 添加示例(如果有)
if examples:
prompt += f"\n{examples}\n"
# 添加问题详情
prompt += f"""
问题详情:
- 规则ID: {issue_data.get('rule', 'Unknown')}
- 问题类型: {issue_type}
- 严重级别: {issue_data.get('severity', 'MAJOR')}
- 问题描述: {issue_data.get('message', '')}
- 问题位置: 第{issue_data.get('line', 0)}行
待修复代码:
```java
{code_context}
``` {data-source-line="360"}
{template['requirements'].strip()}
输出格式:
- 仅输出修复后的完整方法代码
- 使用```java```格式包裹代码
- 不要输出多余的解释文字
- 确保代码可以直接替换原有方法
"""
return prompt模板设计:
- 三层结构:角色设定 + 编码规范 + 问题类型特定要求
- 灵活扩展:新增问题类型只需添加模板配置
- 规范注入:自动注入阿里巴巴Java开发手册规范
第五步:Few-shot示例库
python
class ExampleRepository:
"""问题修复示例库 - 提供修复前后的对比案例"""
EXAMPLES = {
"NullPointer": """
参考示例:
示例1 - 空指针防御性检查:
修复前:
```java
public String getUserEmail(User user) {
return user.getEmail();
}
``` {data-source-line="395"}
修复后:
```java
public String getUserEmail(User user) {
if (user == null) {
throw new IllegalArgumentException("用户对象不能为空");
}
return user.getEmail();
}
``` {data-source-line="404"}
示例2 - 多参数空值检查:
修复前:
```java
public void processOrder(Order order, User user) {
order.setUser(user);
order.setStatus("processed");
}
``` {data-source-line="413"}
修复后:
```java
public void processOrder(Order order, User user) {
if (order == null) {
throw new IllegalArgumentException("订单对象不能为空");
}
if (user == null) {
throw new IllegalArgumentException("用户对象不能为空");
}
order.setUser(user);
order.setStatus("processed");
}
``` {data-source-line="426"}
""",
"ResourceLeak": """
参考示例:
示例 - 使用try-with-resources:
修复前:
```java
public String readFile(String path) throws IOException {
FileInputStream fis = new FileInputStream(path);
byte[] buffer = new byte[1024];
int length = fis.read(buffer);
return new String(buffer, 0, length);
}
``` {data-source-line="440"}
修复后:
```java
public String readFile(String path) throws IOException {
try (FileInputStream fis = new FileInputStream(path)) {
byte[] buffer = new byte[1024];
int length = fis.read(buffer);
return new String(buffer, 0, length);
}
}
``` {data-source-line="450"}
""",
"SQLInjection": """
参考示例:
示例 - 使用PreparedStatement:
修复前:
```java
public User findUserByName(String name) {
String sql = "SELECT * FROM users WHERE name = '" + name + "'";
return jdbcTemplate.queryForObject(sql, User.class);
}
``` {data-source-line="462"}
修复后:
```java
public User findUserByName(String name) {
String sql = "SELECT * FROM users WHERE name = ?";
return jdbcTemplate.queryForObject(sql, User.class, name);
}
``` {data-source-line="469"}
""",
}
@staticmethod
def get_examples(issue_type: str) -> str:
"""获取相关示例"""
return ExampleRepository.EXAMPLES.get(issue_type, "")示例库价值:
- Few-shot学习:让AI通过案例学习修复模式
- 格式统一:修复前/后对比,清晰明了
- 易于扩展:新增示例只需添加字符串配置
第六步:整合到MCP服务
现在,将所有组件整合到MCP服务中:
python
from mcp.server import FastMCP
import httpx
import logging
import os
mcp = FastMCP("intelligent-code-fix")
class IntelligentPromptGenerator:
"""智能提示词生成器 - 整合6步生成法的核心类"""
@staticmethod
def generate_for_issue(issue: dict, base_dir: str) -> dict:
"""为单个issue生成智能提示词"""
try:
# 1. 提取issue信息
rule_key = issue.get('rule', '')
component = issue.get('component', '')
file_path = component.split(':', 1)[1] if ':' in component else component
full_path = os.path.join(base_dir, file_path)
line_number = issue.get('line', 0)
message = issue.get('message', '')
severity = issue.get('severity', 'MAJOR')
# 2. 问题类型识别
issue_type = IssueTypeClassifier.classify(rule_key)
logging.info(f"处理问题: {file_path}:{line_number} - {issue_type}")
# 3. 提取代码上下文
code_context = ContextExtractor.extract(full_path, line_number, issue_type)
# 4. 获取示例
examples = ExampleRepository.get_examples(issue_type)
# 5. 生成提示词
issue_data = {
'rule': rule_key,
'severity': severity,
'message': message,
'line': line_number,
}
prompt = PromptTemplateEngine.generate(
issue_type=issue_type,
issue_data=issue_data,
code_context=code_context,
examples=examples
)
# 6. 计算元数据
token_estimate = len(prompt) // 4 # 粗略估算
return {
'success': True,
'prompt': prompt,
'metadata': {
'file': file_path,
'line': line_number,
'issue_type': issue_type,
'rule': rule_key,
'severity': severity,
'token_estimate': token_estimate,
}
}
except Exception as e:
logging.error(f"生成提示词失败: {e}")
return {
'success': False,
'error': str(e),
'file': file_path,
'line': line_number,
}
@mcp.tool("auto-fix-sonar-issues")
async def auto_fix_sonar_issues(
project_name: str,
cookie: str,
base_dir: str,
branch: str = None,
page_size: int = 10,
page_num: int = 1,
is_new_code_period: bool = False
) -> str:
"""智能修复Sonar扫描问题 - 核心MCP工具"""
# 获取Sonar问题列表
async with httpx.AsyncClient() as client:
params = {
"components": project_name,
"ps": page_size,
"p": page_num,
}
if branch:
params["branch"] = branch
if is_new_code_period:
params["inNewCodePeriod"] = "true"
response = await client.get(
"https://sonar.zhuanspirit.com/api/issues/search",
params=params,
headers={"Cookie": cookie},
timeout=10.0
)
data = response.json()
issues = data.get('issues', [])
total = data.get('total', 0)
# 为每个issue生成智能提示词
results = []
success_count = 0
for idx, issue in enumerate(issues, 1):
result = IntelligentPromptGenerator.generate_for_issue(issue, base_dir)
if result['success']:
success_count += 1
metadata = result['metadata']
results.append(f"""
{'='*80}
## Issue {idx}: {metadata['file']} (第{metadata['line']}行)
**问题类型**: {metadata['issue_type']}
**严重级别**: {metadata['severity']}
**预估Token**: {metadata['token_estimate']}
### 生成的智能提示词:
{result['prompt']}
{'='*80}
""")
# 组装最终输出
return f"""
# 智能代码修复提示词生成完成
## 统计信息
- **项目**: {project_name}
- **总问题数**: {total}
- **本批次**: {len(issues)} 个
- **成功生成**: {success_count} 个
## 智能提示词列表
{"".join(results)}
---
由智能提示词生成引擎提供支持
"""
if __name__ == "__main__":
mcp.run("stdio")整合要点:
- 错误处理:每个issue独立处理,单个失败不影响其他
- 元数据追踪:记录文件、行号、问题类型、Token估算
- 结构化输出:Markdown格式,便于Cursor展示
安装依赖包
在使用MCP服务之前,需要先安装必要的Python依赖包。创建requirements.txt文件:
txt
# 智能代码修复MCP服务依赖包
# MCP框架 - 用于构建MCP服务
mcp>=0.9.0
# HTTP客户端 - 用于调用Sonar API
httpx>=0.27.0
# Java AST解析器 - 精确解析Java代码结构(强烈推荐)
# 优势:准确率99%+,不受注释、字符串、Lambda影响
# 注意:这是纯Python库,不需要Java环境
javalang>=0.13.0安装命令:
bash
pip install -r requirements.txt依赖说明:
- mcp:MCP协议框架,让Python脚本能够被Cursor识别和调用
- httpx:现代化HTTP客户端,用于调用Sonar API获取扫描结果
- javalang:纯Python的Java AST解析器,用于精准定位代码结构,无需安装Java环境
配置MCP(让Cursor识别你的服务)
%这里改成你本地的路径% 在 ~/.cursor/mcp.json 中添加:
json
{
"mcpServers": {
"intelligent-code-fix": {
"command": "python",
"args": ["/Users/Desktop/cursor/intelligent-code-fix.py"],
"env": {}
}
}
}配置说明:
intelligent-code-fix:MCP服务名称,在Cursor中通过@intelligent-code-fix调用command: Python解释器命令args: Python脚本的绝对路径(请修改为你的实际路径)- 修改配置后需要重启Cursor生效
四、使用体验:在Cursor中一键修复
配置好MCP后,在Cursor中的使用非常简单
步骤1:在Cursor聊天窗口调用MCP工具
diff
使用 auto-fix-sonar-issues 工具修复Sonar问题
参数:
- project_name: hunter_partner_recycle_core
- cookie: sso_uid=xxx; ticket=xxx; aid=xxx
- base_dir: /Users/xxx/projects/hunter/src/main/java
- branch: feature-3278-163 (可选)
- page_size: 10步骤2:MCP服务自动处理
系统自动完成:
- 调用Sonar API获取问题列表
- 为每个问题智能生成提示词
- 返回结构化的修复建议
步骤3:AI生成修复后的代码
ini
已生成10个问题的修复建议:
Issue 1: ActivityServiceImpl.java 空指针修复
修复后代码:
[完整的修复代码]
Issue 2: FileUtil.java 资源泄露修复
修复后代码:
[完整的修复代码]步骤4:一键应用修复
直接在Cursor中review并应用修复
改进效果:
- 成本降低70% :精准提取上下文,token使用量大幅减少
- 准确率提升30%:结构化提示词+示例引导,AI理解更准确
- 效率提升3倍:自动化流程,无需人工干预
- 质量可控:分层模板确保代码符合团队规范
- 易于扩展:新增问题类型只需添加配置
五、写在最后
真正有效的AI辅助开发,不是简单地把代码扔给AI,而是要做好:
- 问题的精准识别:知道是什么类型的问题
- 上下文的智能提取:给AI最相关的代码,而不是全部代码
- 规范的有效注入:让AI知道要遵循什么标准
- 经验的系统沉淀:用示例库让AI学习最佳实践
这套方案不仅适用于Sonar,也可以推广到其他代码扫描工具(ESLint、Checkstyle等)。核心思想都是:将非结构化的扫描结果转换为结构化的AI提示词。
希望这篇文章能给大家带来启发。如果大家也在探索AI辅助开发,欢迎交流!
关于作者,刘雅斌,侠客汇Java开发工程师。 想了解更多转转公司的业务实践,欢迎点击关注下方公众号
转转研发中心及业界小伙伴们的技术学习交流平台,定期分享一线的实战经验及业界前沿的技术话题。 关注公众号「转转技术」(综合性)、「大转转FE」(专注于FE)、「转转QA」(专注于QA),更多干货实践,欢迎交流分享~