指数加权平均:

为了避免序列太短导致初始的V偏离太大,对齐进行修正即可

SGD 随机梯度下降
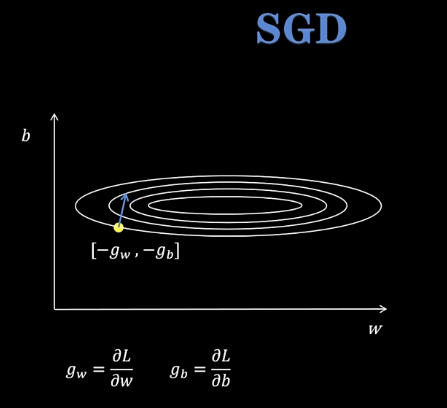
梯度大小相差大时会发生震荡,导致优化难
解决方式:根据历史走的步数情况经过指数加权来决定下一步怎么走
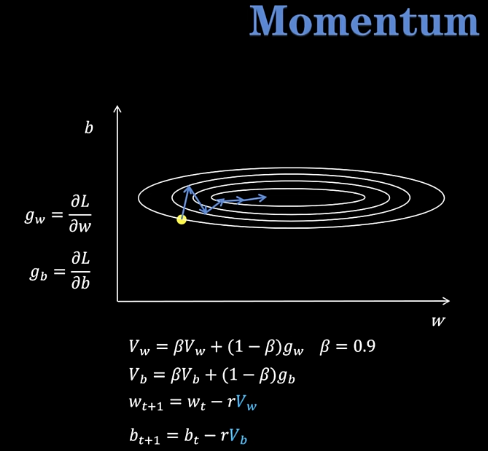
Momentum优化器
根据历史走的步数情况经过指数加权来决定下一步怎么走
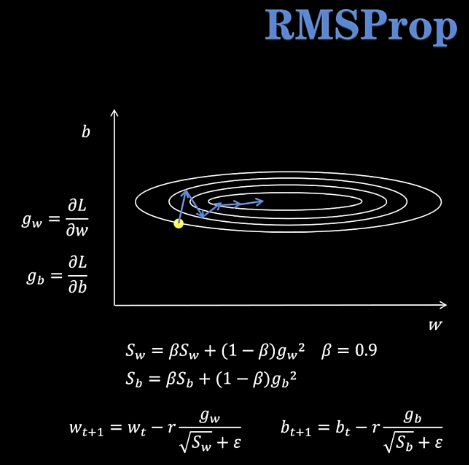
RMSProp优化器
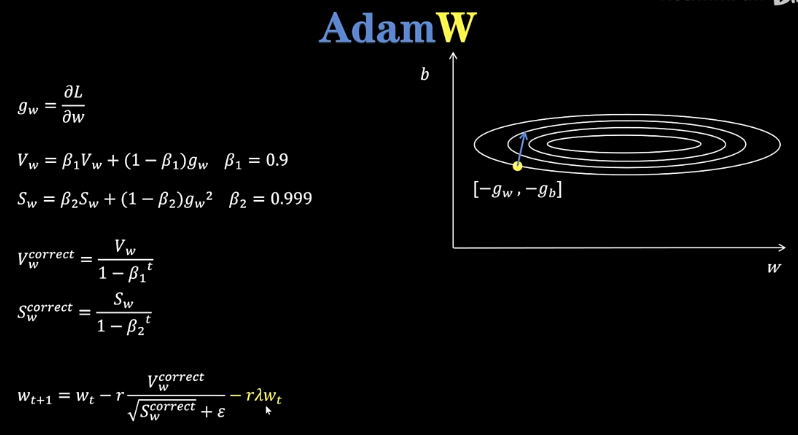
Adam优化器
Adam就是Momentum+RMSProp+指数加权平均的修正

AdamW优化器
AdamW就是在Adam的基础上加上了一个权重衰减的项
L2正则化和Weight decay的区别
在SGD中,L2正则化和Weight decay的效果是完全一样的

在Adam中,L2正则化和Weight decay的效果不一样
通过L2norm算出来的表达式更复杂
但是weight decay是直接在最后的权重更新表达式上加上一个权重衰减项

