引言
在DeepSeek-OCR的编码器架构中,CLIP被作为关键组件引入。
多模态模型的核心挑战之一在于视觉信息的语义理解,即完成语言与图像在共享语义空间中的对齐映射。
本文将系统解析OpenAI于2021年发布的CLIP这一开创性研究,深入探讨其实现机制与技术细节。
动机
在CLIP模型问世前,传统计算机视觉模型普遍依赖于人工标注的数据集,例如ImageNet、COCO等。这些模型通过人工标注的方式(如标注"这是猫"、"那是飞机")进行训练,虽然在小规模任务中表现良好,但存在三个主要问题:
类别封闭性:模型仅能识别预设的有限类别;
标注成本高:大规模数据标注既耗时又昂贵;
泛化能力不足:当数据分布发生改变时,模型性能会显著下降。
由于自然语言本身包含了对世界的丰富描述,OpenAI提出了一个创新构想:通过让模型从互联网上的图文对中自主学习,而非依赖人工标注,是否能够实现更通用的视觉理解能力?
方法
CLIP模型包含两个核心编码组件:
视觉编码器(Image Encoder):采用ResNet架构或Vision Transformer;
语言编码器(Text Encoder):基于CBOW模型或Transformer框架构建。
更多AI大模型学习视频及资源,都在智泊AI。
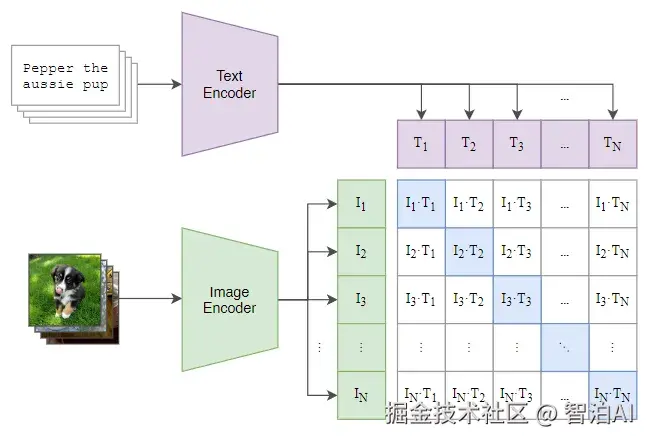
训练目标的核心逻辑如下:
每个训练批次包含N组图片与N段文本,模型需完成图文匹配任务。具体实现中:
通过计算所有图片-文本对的相似度,构建N×N的相似度矩阵;
理想情况下,矩阵对角线(i=j位置)的相似度值应最大,因其对应真实配对的图文对;
采用对比学习(Contrastive Learning)机制,推动匹配对的嵌入向量在高维空间中相互靠近,同时拉远不匹配对的距离,从而逼近理想矩阵分布。
论文提供的代码显示,损失函数采用分类交叉熵损失,分别对图像和文本模态独立计算后取均值作为最终损失。

训练数据集
研究者创建了一个突破性的数据集------WebImageText(WIT),包含约4亿组(图像,文本)配对数据,来源涵盖公共网页、社交平台及图片分享网站。
与传统分类数据集ImageNet(含120万张图像、1000个类别)相比,该数据集的规模具有革命性,充分体现了OpenAI"规模驱动突破"的技术理念。
在图像分类任务中,语义歧义是常见挑战。例如单词"remote"作为名词指代遥控器,作为形容词则表示遥远距离。若仅用单一单词标注图像,此类歧义会阻碍模型准确理解语义。
为此,CLIP模型采用特定提示词模板进行训练,如下图所示的标准模板为"A photo of a {具体对象}"。通过这种方式可强制限定词性为名词,同时该框架支持多种衍生模板变体。
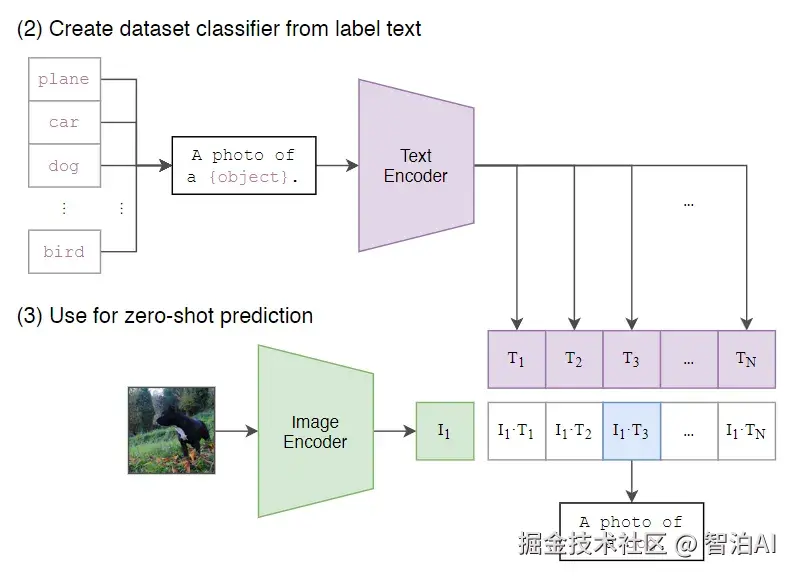
零样本学习能力
零样本学习(Zero-Shot Learning)指模型通过大规模数据预训练后,无需针对特定下游任务进行微调,即可直接完成预测任务。
下图展示了CLIP模型在多个经典分类数据集上采用零样本推理与Linear Probe方法的性能对比。
其中,Linear Probe技术是指固定预训练模型的参数,仅新增一个分类层并对下游任务进行微调的训练策略。
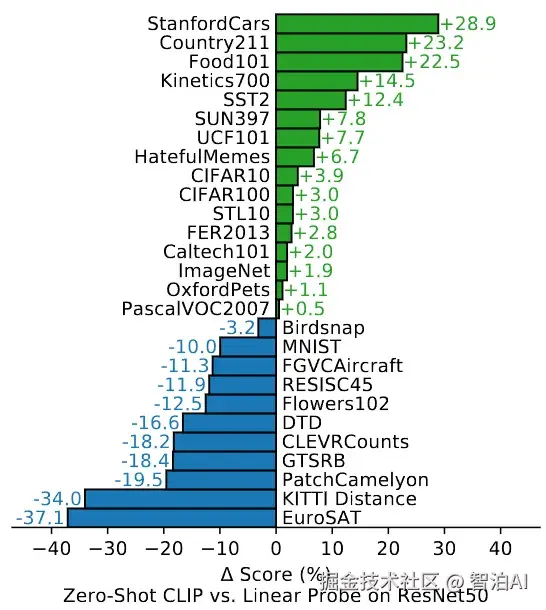
图中正值反映CLIP零样本方法优于微调后效果,负值则表明其表现不及微调模型。
这一现象揭示了CLIP的固有局限:面对细粒度分类任务(如汽车/飞机型号鉴别或花卉品种区分),零样本CLIP的性能仍落后于专为特定任务设计的模型。
更多AI大模型学习视频及资源,都在智泊AI。