目录
[1 硬件关系概览](#1 硬件关系概览)
[2 mmu硬件原理](#2 mmu硬件原理)
[3 mmu虚拟地址转物理地址过程](#3 mmu虚拟地址转物理地址过程)
[3.1 基本原理](#3.1 基本原理)
[3.2 Linux内核的中的转换](#3.2 Linux内核的中的转换)
[4 Linux启动mmu初始化流程](#4 Linux启动mmu初始化流程)
[4.1 启动代码对mmu的初始化](#4.1 启动代码对mmu的初始化)
[4.1.1 __create_page_tables函数](#4.1.1 __create_page_tables函数)
[4.1.2 __primary_switch](#4.1.2 __primary_switch)
[4.2 C环境对MMU的初始化过程](#4.2 C环境对MMU的初始化过程)
[4.2.1 map_kernel 内核镜像内存映射](#4.2.1 map_kernel 内核镜像内存映射)
[4.2.2 map_mem内核以外的内存线性映射](#4.2.2 map_mem内核以外的内存线性映射)
[4.3 __create_pgd_mapping 映射流程](#4.3 __create_pgd_mapping 映射流程)
[5 附录](#5 附录)
1 硬件关系概览
在mmu开启的情况下,内核发送虚拟地址到mmu,由mmu转换成物理地址,访问到具体的硬件地址。这个过程中,mmu内部会先查找TLB缓存,如果命中物理地址则直接输出,否则将由table walks unit通过查找存放于ddr某处的page table来计算物理地址,这个虚拟地址转换物理地址的过程,在后续章节介绍。
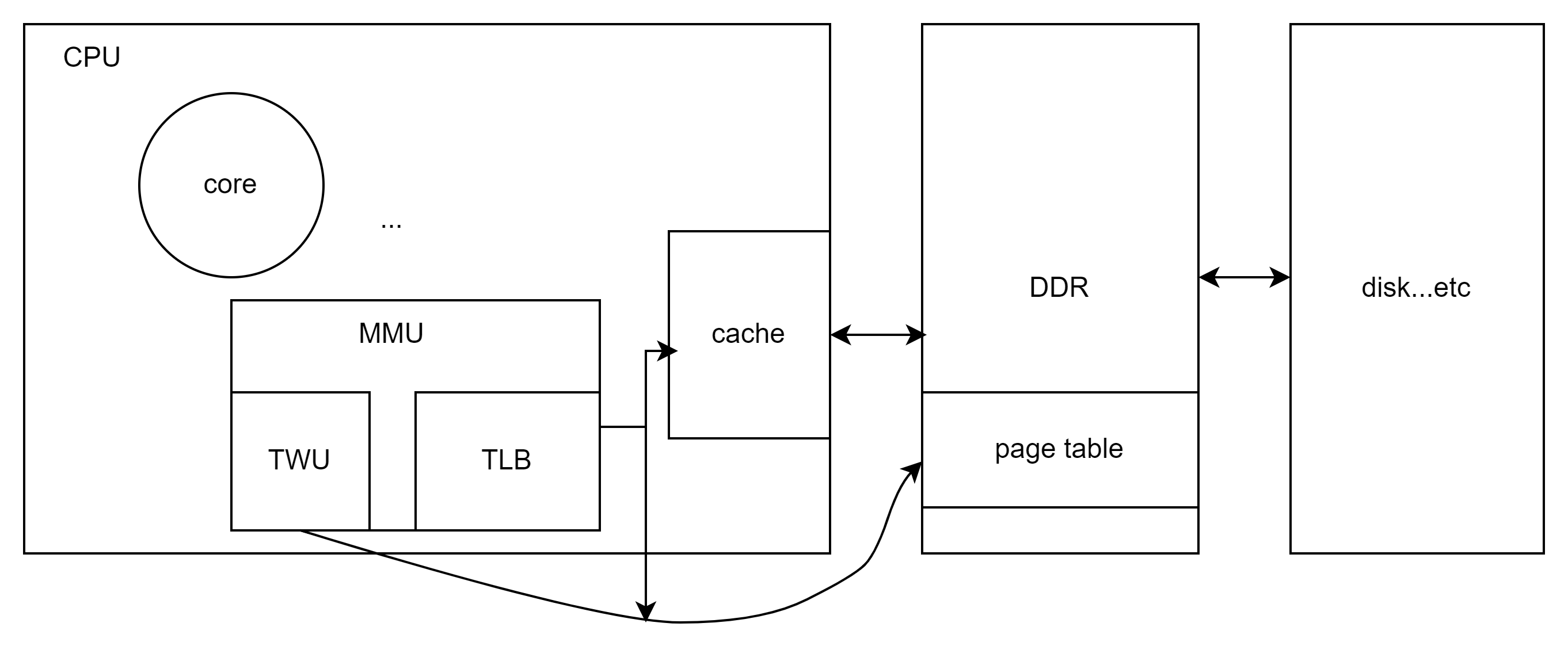
在mmu转换成物理地址后,实际物理硬件上经过cache缓存,缓存没命中情况下才到具体物理地址访问,这不是本文的重点,本文将着重讲解虚拟地址转物理地址的过程,再介绍启动过虚拟地址的初始化流程。
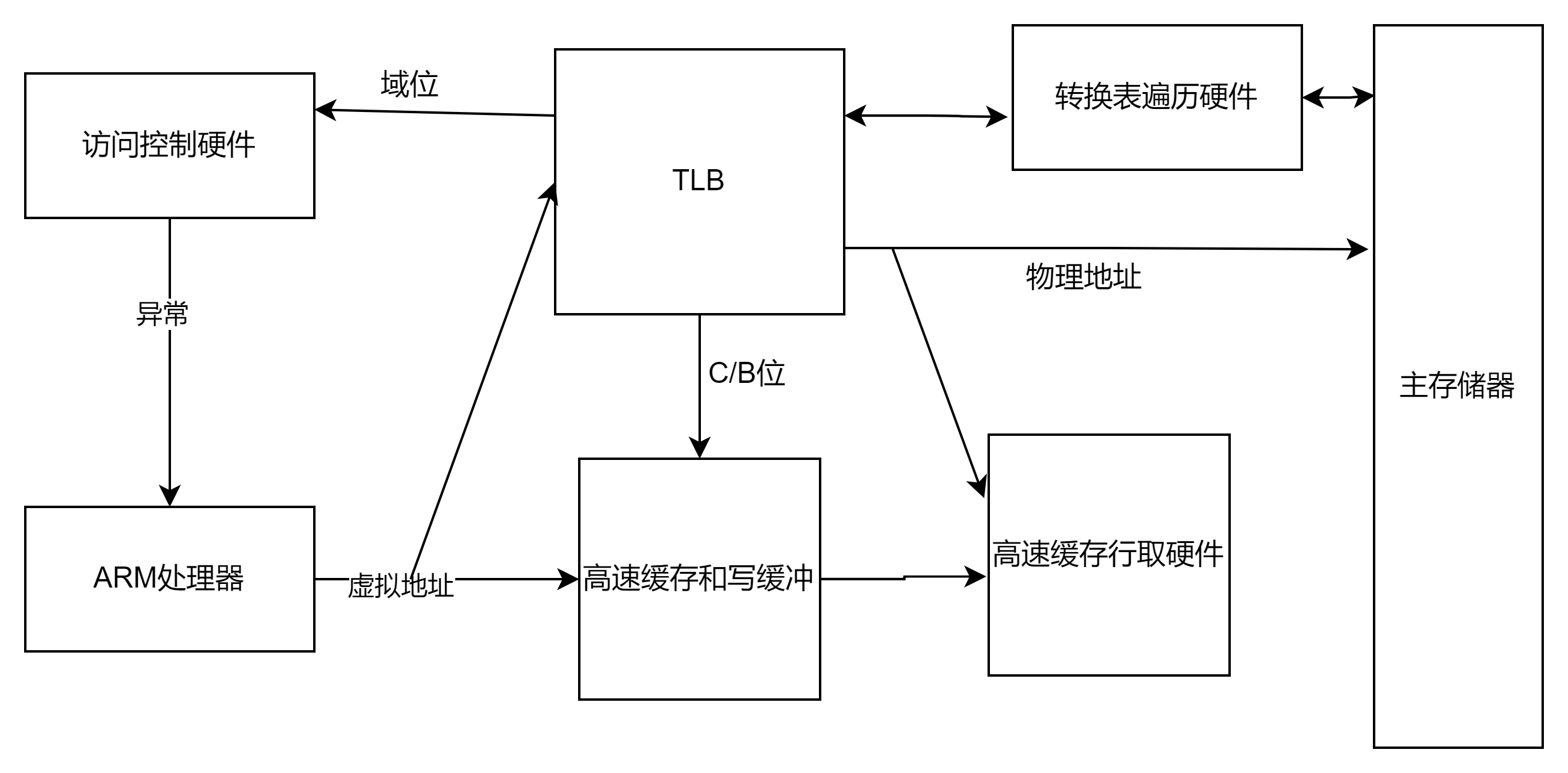
2 mmu硬件原理
上图硬件逻辑图中,mmu大致由TWU和TLB组成。
TLB是为了提高处理器查询页表的速度而设计的,又称快表,在硬件上和cache一样 ,是处理器内部的一小块高速SRAM内存,用于缓存。其中TLB一般分为ITLB和DTLB,即数据TLB和指令TLB, 指令TLB用于取指令时的指令地址翻译 ,而数据TLB用于其他存储访问操作时的地址翻译。
如下图,处理在访问储存器时,将虚拟地址转由MMU处理,MMU先从TLB缓存中查找是否有对应的物理地址,命中情况下直接使用该物理地址访问高速缓存(C(高速缓存)和 B(缓冲)位被用来控制高速缓存和写缓冲,并决定是否高速缓存),未命中情况下,MMU将启用转换遍历硬件,即TWU从储存器(DDR)中的页表中获取转换,并将转换得到的信息缓存到TLB中以便下次使用。在这个过程中,转换后的地址信息中带有访问权限和域位用来控制访问是否被允许。如果不允许,则MMU将向ARM 处理器发送一个存储器异常;否则访问将被允许进行。
3 mmu虚拟地址转物理地址过程
3.1 基本原理
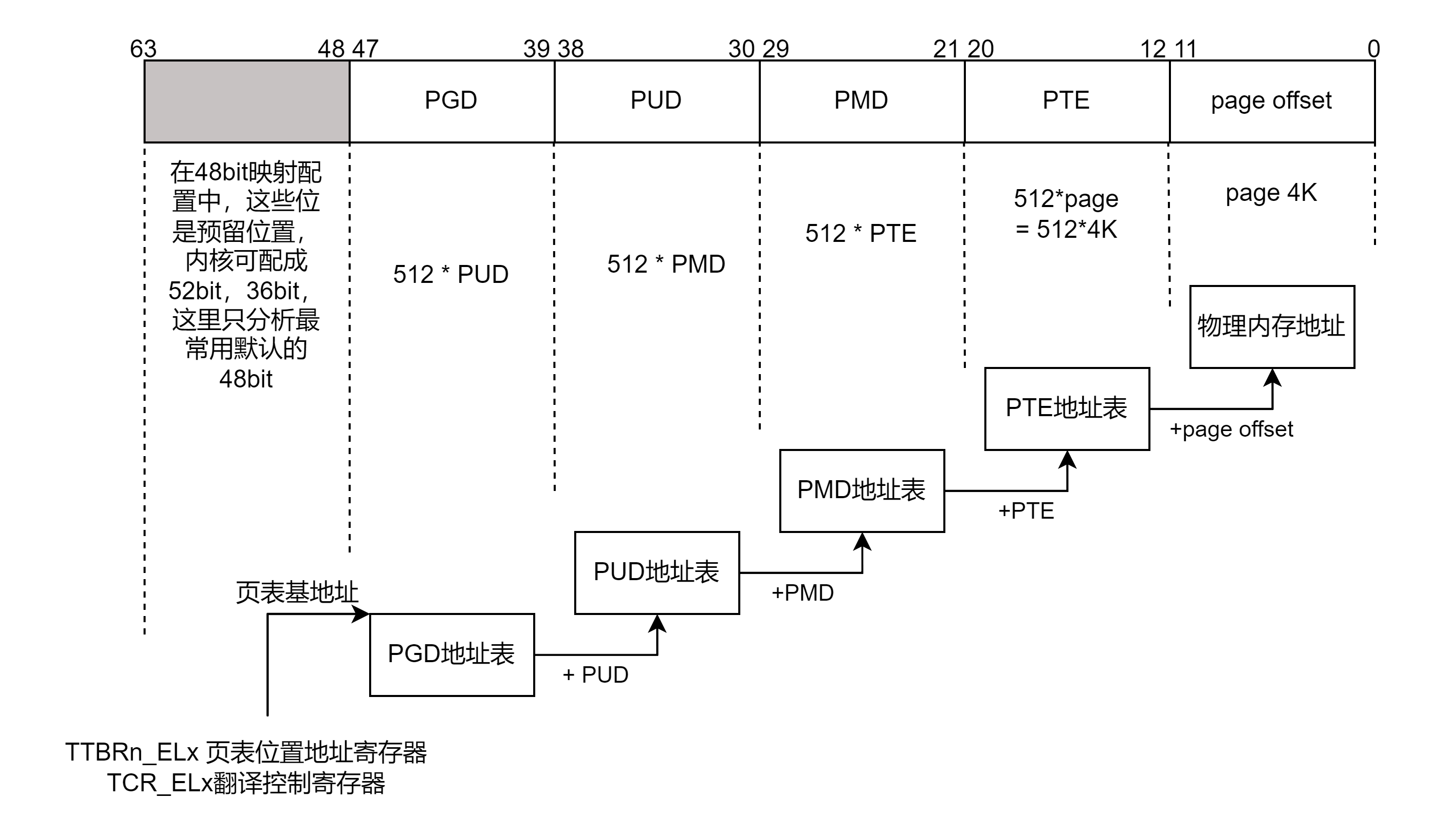
MMU支持多级页表,如下是4级页表模型,分别为页全局目录(PGD),页上级目录(PUD),页中间目录(PMD),页表(PTE)。
MMU从页表位置地址寄存器(例如arm64为TTBR1_EL1/TTBR0_EL0)获取页表地址,偏移加上PGD(bit47-bit39)的值,得到PUD的基地址;同样PUD基地址加上PUD得到MPD基地址;MPD基地址加上PTE值得到一个地址值,该地址值加上最后的page offset最后得到一个物理地址,即为转换后的物理地址。
页表在Linux内核初始化时被放到DDR一个空闲内存块中,当MMU转换得到的物理地址信息,将被缓存到TLB中。
3.2 Linux内核的中的转换
从Linux内核角度配置出发,地址转换支持48bit,39bit等,这里以常见默认的39bit(64bit系统)为例阐述虚拟地址转换物理地址的过程。
如下是一个arm64平台的Linux内核配置,地址采用三级地址转换,寻址为39bit,页颗粒大小为4K(page offset):
CONFIG_ARM64_PAGE_SHIFT=12
CONFIG_ARM64_4K_PAGES=y
# CONFIG_ARM64_16K_PAGES is not set
# CONFIG_ARM64_64K_PAGES is not set
CONFIG_ARM64_VA_BITS_39=y
# CONFIG_ARM64_VA_BITS_48 is not set
CONFIG_ARM64_VA_BITS=39
CONFIG_PGTABLE_LEVELS=3当page level等于4的时候,映射关系是PGD(L0)--->PUD(L1)--->PMD(L2)--->Page table(L3)-→page。当page level等于3的时候,没有PUD,这时候映射关系是PGD(L1)--->PMD(L2)--->Page table(L3)→page。
每一级页表bit偏移量计算方式:((PAGE_SHIFT - 3) * (4 - (n)) + 3)。每一即占9bit,即每一级将有512项,page offset为12bit,即页大小4K。(这里可简单算下地址映射范围:512*512*512*4K = 512T,如果是4级将映射更大范围的地址)。
如下是trace32抓出来的地址信息示例:
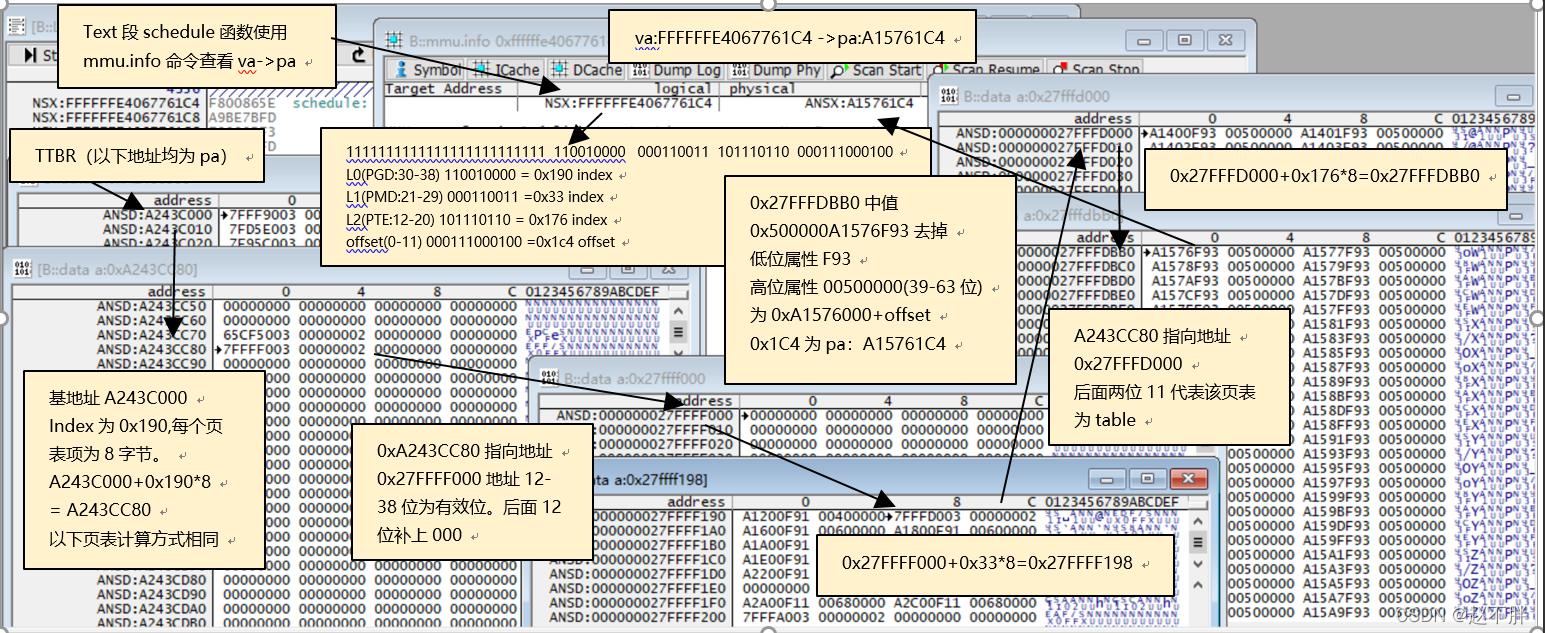
验证va->pa指针虚拟地址转物理地址的过程:
va->pa 虚拟地址为0xFFFFFFE4067761C4,对应物理地址是0xA15761C4,将物理地址展开:
1111111111111111111111111 110010000 000110011 101110110 000111000100
L0(PGD:30-38)110010000=0x190 index
L1(PMD:21-29)000110011 =0x33 index
L2(PTE:12-20) 101110110 = 0x176 index
offset(0-11)000111000100 =0x1c4 offset.
TTBR的值为 A243C000
计算PMD的基地址:A243C00 + 0x190(PGD的值) = A243CC80。
0xA243CC80指向的地址内存值为0x27FFFF003,地址12-38位为有效位,后面 12位补上000,最后有效地址为0x27FFFF000。
计算PTE的基地址:0x27FFFF000+0x33*8=0x27FFFF198,同理取有效值:0x27FFFD000计算最后需加offset的基地址:0x27FFFD000+0x176*8=0x27FFFDBB0,0x27FFFDBB0地址值为中值0x500000A1576F93,只有中间16-38是地址值,其他都是属性值(权限等),0x500000A1576F93去掉低位属性 F93(0-15位)高位属性 00500000(39-63位)为0xA1576000+offset 0x1C4为pa:A15761C4。
即最终的物理地址是:A15761C4,和trace32 dump出来的一样。
4 Linux启动mmu初始化流程
以arm64的启动为例,启动脚本为arch/arm64/kernel/head.S,在这里只分析启动脚本对mmu的初始化过程:
下面用流程图的方式画出了启动脚本过程中mmu的初始化代码位置,以及跳转到c代码后,mmu驱动对mmu的初始化和页表生成代码。
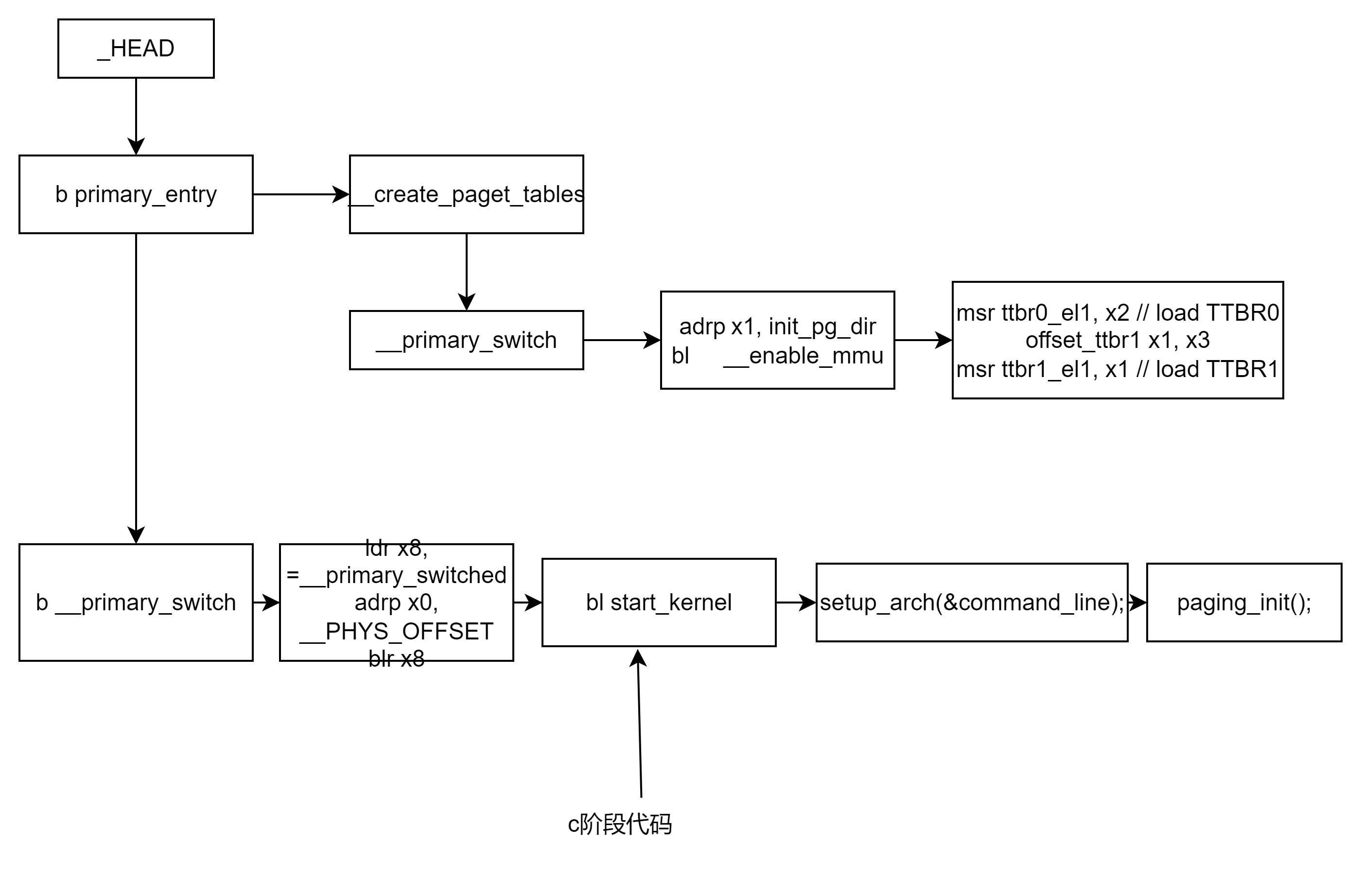
4.1 启动代码对mmu的初始化
启动代码对mmu的初始化主要在如下两个函数中:
bl __create_page_tables
b __primary_switch4.1.1 __create_page_tables函数
该函数主要用于初始化临时页表内存和恒等映射内存:
cpp
SYM_FUNC_START_LOCAL(__create_page_tables)
mov x28, lr/*返回链接地址保存在x28*/
/*
* Invalidate the init page tables to avoid potential dirty cache lines
* being evicted. Other page tables are allocated in rodata as part of
* the kernel image, and thus are clean to the PoC per the boot
* protocol.
*/
adrp x0, init_pg_dir/*临时页表基地址*/
adrp x1, init_pg_end/*临时页表尾地址*/
bl dcache_inval_poc/*失能上述临时页表范围内的缓存,保证该内存段的缓存一致性,避免被其他数据污染*/
/*
* Clear the init page tables.
*/
/*
* 如下循环操作是对临时页表的清空操作(临时页表地址空间在链接脚本中定义,3级映射为page页大小,即4K,arm64 中PTE每一项目占8字节,则4K可以表示512项)
*/
adrp x0, init_pg_dir
adrp x1, init_pg_end
sub x1, x1, x0
1: stp xzr, xzr, [x0], #16
stp xzr, xzr, [x0], #16
stp xzr, xzr, [x0], #16
stp xzr, xzr, [x0], #16
subs x1, x1, #64
b.ne 1b
/*
* SWAPPER_MM_MMUFLAGS宏是早期MMU对应PTE内存的权限配置,这里将该值放到x7中。
* arch/arm64/include/asm/kernel-pgtable.h定义了该宏
#define SWAPPER_PTE_FLAGS (PTE_TYPE_PAGE | PTE_AF | PTE_SHARED | PTE_UXN)
#define SWAPPER_MM_MMUFLAGS (PTE_ATTRINDX(MT_NORMAL) | SWAPPER_PTE_FLAGS)
PTE_ATTRINDX :选择内存类型索引(如MT_NORMAL对应缓存内存)12
AP_RW :设置特权级读写权限3
AF(Access Flag) :标记页表项为已访问1
SH_INNER :保证多核缓存一致性
*/
mov_q x7, SWAPPER_MM_MMUFLAGS
/*
* Create the identity mapping.
*/
/*恒等映射基地址*/
adrp x0, idmap_pg_dir
/*需要进行恒等映射的代码段其实地址,即.idmap.text段*/
adrp x3, __idmap_text_start // __pa(__idmap_text_start)
#ifdef CONFIG_ARM64_VA_BITS_52
mrs_s x6, SYS_ID_AA64MMFR2_EL1
and x6, x6, #(0xf << ID_AA64MMFR2_LVA_SHIFT)
mov x5, #52
cbnz x6, 1f
#endif
/*
* 最小虚拟地址位数,这里配置的是39bit
*/
mov x5, #VA_BITS_MIN
1:
/*将vabits_actual变量的地址,放到x6中*/
adr_l x6, vabits_actual
/*将x5内容值,放入到x6内容地址对应的内容,这里即把VA_BITS_MIN的值39放到vabits_actual里*/
str x5, [x6]
dmb sy
/*关闭vabits_actual对应的缓存,保证一致性*/
dc ivac, x6 // Invalidate potentially stale cache line
/*
* 下述代码是为了防止用户配置的虚拟地址位数,不满足此时恒等映射代码所属的高地址范围,
* 例如用户配置的是39bit,但如果此时恒等代码段存放最高地址不在39bit寻址范围,此时需要
* 进行拓展。
*/
adrp x5, __idmap_text_end/*加载恒等映射代码段结束地址(恒等映射最高地址)*/
clz x5, x5/*相当于64 - __idmap_text_end实际使用的物理地址位数*/
cmp x5, TCR_T0SZ(VA_BITS_MIN) // default T0SZ small enough?
b.ge 1f // .. then skip VA range extension当高地址大于配置位数时,跳转到地址拓展逻辑
/*
* 将上述得到恒等映射位数,放到idmap_t0sz变量中
*/
adr_l x6, idmap_t0sz
str x5, [x6]
dmb sy
dc ivac, x6 // Invalidate potentially stale cache line
/*
* 配置小于48bit时,为映射增加映射等级
*/
#if (VA_BITS < 48)
#define EXTRA_SHIFT (PGDIR_SHIFT + PAGE_SHIFT - 3)
#define EXTRA_PTRS (1 << (PHYS_MASK_SHIFT - EXTRA_SHIFT))
/*
* If VA_BITS < 48, we have to configure an additional table level.
* First, we have to verify our assumption that the current value of
* VA_BITS was chosen such that all translation levels are fully
* utilised, and that lowering T0SZ will always result in an additional
* translation level to be configured.
*/
#if VA_BITS != EXTRA_SHIFT
#error "Mismatch between VA_BITS and page size/number of translation levels"
#endif
mov x4, EXTRA_PTRS
create_table_entry x0, x3, EXTRA_SHIFT, x4, x5, x6
#else
/*
* If VA_BITS == 48, we don't have to configure an additional
* translation level, but the top-level table has more entries.
*/
mov x4, #1 << (PHYS_MASK_SHIFT - PGDIR_SHIFT)
str_l x4, idmap_ptrs_per_pgd, x5
#endif
1:
ldr_l x4, idmap_ptrs_per_pgd
adr_l x6, __idmap_text_end // __pa(__idmap_text_end)
/*
*建立恒等代码的虚拟地址到物理地址的映射,保证连续性
*/
map_memory x0, x1, x3, x6, x7, x3, x4, x10, x11, x12, x13, x14
/*
* Map the kernel image (starting with PHYS_OFFSET).
*/
adrp x0, init_pg_dir
mov_q x5, KIMAGE_VADDR // compile time __va(_text)
add x5, x5, x23 // add KASLR displacement
mov x4, PTRS_PER_PGD
adrp x6, _end // runtime __pa(_end)
adrp x3, _text // runtime __pa(_text)
sub x6, x6, x3 // _end - _text
add x6, x6, x5 // runtime __va(_end)
/*
*建立内核镜像的虚拟地址到物理地址的映射
*/
map_memory x0, x1, x5, x6, x7, x3, x4, x10, x11, x12, x13, x14
/*
* Since the page tables have been populated with non-cacheable
* accesses (MMU disabled), invalidate those tables again to
* remove any speculatively loaded cache lines.
*/
dmb sy
/*关闭恒等映射内存缓存*/
adrp x0, idmap_pg_dir
adrp x1, idmap_pg_end
bl dcache_inval_poc
/*关闭临时页表内存缓存*/
adrp x0, init_pg_dir
adrp x1, init_pg_end
bl dcache_inval_poc
ret x28
SYM_FUNC_END(__create_page_tables)(1)恒等映射:
恒等映射的概念,为保证CPU执行的连续性,在开启MMU时,CPU执行的物理地址需要按原先的地址来执行(不然开启MMU后物理地址映射的地址与实际执行的地址不一致,会导致异常错误),在此内核特地初始化了idmap_pg_dir恒等映射内存和需要进行恒等映射的代码段,从链接脚本arch/arm64/kernel/vmlinux.lds.S定义内存分布:
cpp
#define IDMAP_TEXT \
. = ALIGN(SZ_4K); \
__idmap_text_start = .; \
*(.idmap.text) \
__idmap_text_end = .;和
cpp
idmap_pg_dir = .;
. += IDMAP_DIR_SIZE;
idmap_pg_end = .;其中恒等映射内存大小为IDMAP_DIR_SIZE
#define IDMAP_DIR_SIZE (IDMAP_PGTABLE_LEVELS * PAGE_SIZE)
分页等级为3,页大小为4K,即内存大小为12K。
(2)临时页表内存
内核在启动阶段,会为内核初始化一个临时的页表,基地址为init_pg_dir,临时页表内存分布在链接脚本的定义:
cpp
init_pg_dir = .;
. += INIT_DIR_SIZE;
init_pg_end = .;大小INIT_DIR_SIZE为一个页大小4K,即临时页表内存大小为4K,PTE每一项8字节,这个该临时页表能表示的项目为512项(512*4K)。需要注意的是,该临时页表在进入C初始化MMU阶段会被回收后再建议一个完整的页表。在setup_arch()中调用paging_init()完成最终页表配置:
用户空间页表:
通过pgd_set_fixmap()获取TTBR0页表物理地址,并清空或保留必要映射(如设备树临时映射)1014。
内核空间页表:
通过map_kernel()和map_mem()建立内核线性映射。
(3)恒等映射寻址范围检查
在启动代码里还能看到对用户配置的虚拟地址内存寻址范围进行了检查,如果恒等映射最高地址需要映射的代码段大于配置的虚拟内存寻址范围,说明此时用户配置的虚拟内存寻址范围将无法映射到恒等映射的代码段,启动代码对此进行了校验拓展,通过拓展虚拟寻址位数来拓展寻址范围。
4.1.2 __primary_switch
该函数主要调用__enable_mmu进行MMU的使能:
cpp
adrp x1, init_pg_dir
bl __enable_mmu__enable_mmu的实现:
cpp
SYM_FUNC_START(__enable_mmu)
/*
* 读取ID_AA64MMFR0_EL1寄存器,提取页表粒度支持字段(TGRAN域)2
* 检查是否在支持范围内(如4KB/16KB/64KB),否则跳转到错误处理__no_granule_support
*/
mrs x2, ID_AA64MMFR0_EL1
ubfx x2, x2, #ID_AA64MMFR0_TGRAN_SHIFT, 4
cmp x2, #ID_AA64MMFR0_TGRAN_SUPPORTED_MIN
b.lt __no_granule_support
cmp x2, #ID_AA64MMFR0_TGRAN_SUPPORTED_MAX
b.gt __no_granule_support
/*更新cpu早期boot状态*/
update_early_cpu_boot_status 0, x2, x3
/*恒等映射内存基地址*/
adrp x2, idmap_pg_dir
/*x1是临时页表内存基地址,这里将该基地址值转换成ttbr格式*/
phys_to_ttbr x1, x1
/*x2是恒等映射基地址,这里将该基地址值转换成ttbr格式*/
phys_to_ttbr x2, x2
/*将恒等映射基地址赋值给用户空间页表寄存器ttbr0_el1*/
msr ttbr0_el1, x2 // load TTBR0
/*将临时页表基地址赋值给内核空间页表基地址寄存器ttbr1_el1*/
offset_ttbr1 x1, x3
msr ttbr1_el1, x1 // load TTBR1
isb
/*调用set_sctlr_el1使能mmu*/
set_sctlr_el1 x0
ret
SYM_FUNC_END(__enable_mmu)主要对CPU支持的页颗粒度与用户配置的页大小进行检查,同时将恒等映射基地址配置成用户空间页基地址寄存器,临时页表内存基地址配置给内核空间页表基地址,最后使能MMU。从前面MMU转换原理知道,这里配置了ttbr1_el1和ttbr0_el1,后面内核进行虚拟地址与物理地址映射转换时将从该寄存器取出当前页表基地址。
4.2 C环境对MMU的初始化过程
启动代码最终跳转到init/main.c的start_kernel函数上,如前面代码流程图所示的,最终调用关系start_kernel(init/main.c) -> setup_arch(arch/arm64/kernel/setup.c) -> paging_init (arch/arm64/mm/mmu.c)
前面提到的init_pg_dir将在这里被销毁,重新创建全局的页表,初始化页表内存swapper_pg_dir(大小4K,512项目,符合转换规则)将被用作0号进程的PGD,init_pg_dir在memblock_free中被释放。
如下是paging_init的实现:
cpp
void __init paging_init(void)
{
/*
* 物理内存swapper_pg_dir与fixmap内部pgd临时映射内存的直接映射,返回swapper_pg_dir的映射地址
*/
pgd_t *pgdp = pgd_set_fixmap(__pa_symbol(swapper_pg_dir));
//-------------以下都是使用swapper_pg_dir的内存作为页表pgd项的地址使用---------------
/*内核映射,*/
map_kernel(pgdp);
/*内核以外的内核空间映射*/
map_mem(pgdp);
pgd_clear_fixmap();
//写pgd页表基地址到ttbr寄存器上
cpu_replace_ttbr1(lm_alias(swapper_pg_dir));
init_mm.pgd = swapper_pg_dir;
//将pgd页表内存范围从memblock移除,禁止模块从memblock使用该区域
memblock_free(__pa_symbol(init_pg_dir),
__pa_symbol(init_pg_end) - __pa_symbol(init_pg_dir));
memblock_allow_resize();
}临时映射页表基址:
通过 fixmap 机制临时映射 swapper_pg_dir 的物理地址到虚拟地址,使其可被内核代码访问。__pa_symbol 获取符号的物理地址,pgd_set_fixmap 在 FIXMAP 区域建立临时页表项。
cpp
pgd_t *pgdp = pgd_set_fixmap(__pa_symbol(swapper_pg_dir));关于fixmap,笔者写了一遍专门分析fixmap的文章:
内核镜像颗粒度映射:
将启动阶段init_pg_dir的2MB大页映射拆分为4KB页(PTE),映射内核代码例如text、_data等区域。同时建立vmalloc、fixmap等特殊区域的页表项。
cpp
map_kernel(pgdp);物理内存的线性映射:
遍历memblock内存区域,将系统全部物理内存映射到虚拟空间(PAGE_OFFSET起始的线性区),动态分配PMD/PTE页表,根据物理内存大小拓展映射范围(如64GB内存需约512PMD)
cpp
/*内核以外的内核空间映射*/
map_mem(pgdp);切换页表并绑定:
解除 fixmap 临时映射,通过 TTBR1_EL1 寄存器加载 swapper_pg_dir 作为新页表基址。
将swapper_pg_dir绑定到 init_mm 结构体,作为0号进程(idle)和内核线程的默认页表。
cpp
pgd_clear_fixmap();
//写pgd页表基地址到ttbr寄存器上
cpu_replace_ttbr1(lm_alias(swapper_pg_dir));
init_mm.pgd = swapper_pg_dir;释放临时页表:
回收启动阶段使用的 init_pg_dir 内存(通过 memblock 释放),允许内存动态调整
cpp
//将pgd页表内存范围从memblock移除,禁止模块从memblock使用该区域
memblock_free(__pa_symbol(init_pg_dir),
__pa_symbol(init_pg_end) - __pa_symbol(init_pg_dir));允许内存动态调整:
启用 memblock 的内存区域动态扩展能力,为后续内存管理(如伙伴系统)做准备。
cpp
memblock_allow_resize();下节将进入paging_init中调用的每一个函数中分析。
4.2.1 map_kernel 内核镜像内存映射
上一节说到map_kernel是对Linux内核镜像内存区域进行映射,map_kernel的实现在linux-5.15.158\arch\arm64\mm\mmu.c
cpp
/*
* Create fine-grained mappings for the kernel.
*/
static void __init map_kernel(pgd_t *pgdp)
{
static struct vm_struct vmlinux_text, vmlinux_rodata, vmlinux_inittext,
vmlinux_initdata, vmlinux_data;
...
/*
* Only rodata will be remapped with different permissions later on,
* all other segments are allowed to use contiguous mappings.
*/
//映射_stext到_etext 之间的段
map_kernel_segment(pgdp, _stext, _etext, text_prot, &vmlinux_text, 0,
VM_NO_GUARD);
//映射__start_rodata到__inittext_begin之间的段
map_kernel_segment(pgdp, __start_rodata, __inittext_begin, PAGE_KERNEL,
&vmlinux_rodata, NO_CONT_MAPPINGS, VM_NO_GUARD);
//映射__inittext_begin到__inittext_end之间的段
map_kernel_segment(pgdp, __inittext_begin, __inittext_end, text_prot,
&vmlinux_inittext, 0, VM_NO_GUARD);
//映射__initdata_begin到__initdata_end之间的段
map_kernel_segment(pgdp, __initdata_begin, __initdata_end, PAGE_KERNEL,
&vmlinux_initdata, 0, VM_NO_GUARD);
//映射_data, _end之间的段
map_kernel_segment(pgdp, _data, _end, PAGE_KERNEL, &vmlinux_data, 0, 0);
if (!READ_ONCE(pgd_val(*pgd_offset_pgd(pgdp, FIXADDR_START)))) {
/*
* The fixmap falls in a separate pgd to the kernel, and doesn't
* live in the carveout for the swapper_pg_dir. We can simply
* re-use the existing dir for the fixmap.
*/
/*
if 条件检查当前 pgdp 中 FIXADDR_START 地址的顶级 PGD 条目是否为空。
如果为空,它会重用全局共享的swapper_pg_dir中对应的PGD条目(通过 pgd_offset_k 访问)。当fixmap 虚拟地址范围在PGD级别不与主要内核映射重叠时,这简化了PGD管理。
*/
set_pgd(pgd_offset_pgd(pgdp, FIXADDR_START),
READ_ONCE(*pgd_offset_k(FIXADDR_START)));
} else if (CONFIG_PGTABLE_LEVELS > 3) {
pgd_t *bm_pgdp;
p4d_t *bm_p4dp;
pud_t *bm_pudp;
/*
* The fixmap shares its top level pgd entry with the kernel
* mapping. This can really only occur when we are running
* with 16k/4 levels, so we can simply reuse the pud level
* entry instead.
*/
/*
此 else if 代码块处理 fixmap 区域与内核代码段共享一个顶级 PGD 条目的情况(在 ARM64 上使用 16k 页面/4 级页表时很常见)。它沿着页表层次结构(PGD -> P4D -> PUD)导航到正确的 PUD 条目。
pud_set_fixmap_offset 将特定的 PUD 结构临时映射到一个固定的虚拟地址,以便进行操作。
pud_populate 将指向下一级页表 (bm_pmd) 的适当指针插入 PUD 条目中。
pud_clear_fixmap 取消映射临时映射。
*/
BUG_ON(!IS_ENABLED(CONFIG_ARM64_16K_PAGES));
bm_pgdp = pgd_offset_pgd(pgdp, FIXADDR_START);
bm_p4dp = p4d_offset(bm_pgdp, FIXADDR_START);
bm_pudp = pud_set_fixmap_offset(bm_p4dp, FIXADDR_START);
pud_populate(&init_mm, bm_pudp, lm_alias(bm_pmd));
pud_clear_fixmap();
} else {
BUG();
}
kasan_copy_shadow(pgdp);
}该函数主要调用了map_kernel_segment进行代码段、数据段等内核镜像内存的映射
cpp
static void __init map_kernel_segment(pgd_t *pgdp, void *va_start, void *va_end,
pgprot_t prot, struct vm_struct *vma,
int flags, unsigned long vm_flags)
{
phys_addr_t pa_start = __pa_symbol(va_start);//得到要映射的虚拟地址
unsigned long size = va_end - va_start;//映射大小
BUG_ON(!PAGE_ALIGNED(pa_start));
BUG_ON(!PAGE_ALIGNED(size));
//创建映射,该接口是内核创建对应等级映射的接口,将pa_start映射到va_start上
__create_pgd_mapping(pgdp, pa_start, (unsigned long)va_start, size, prot,
early_pgtable_alloc, flags);
if (!(vm_flags & VM_NO_GUARD))
size += PAGE_SIZE;
//记录映射信息后返回上层
vma->addr = va_start;
vma->phys_addr = pa_start;
vma->size = size;
vma->flags = VM_MAP | vm_flags;
vma->caller = __builtin_return_address(0);
vm_area_add_early(vma);
}__create_pgd_mapping是映射的关键调用,处理了对应等级映射关系(笔者配置是4级映射,页大小4K),后面章节将专门对该函数进行分析,主要分析映射的流程。
函数调用了__pa_symbol(va_start),将当前物理转换成虚拟地址,该宏是将一个链接时已知的、位于内核映像数据段中的虚拟地址 (例如一个全局变量或函数的地址)转换为其对应的物理地址。它是一个编译期或链接期可以确定的转换,用于处理内核自身静态数据段的地址。它通常用于将内核数据结构传递给需要物理地址的外设(如 DMA 控制器)。
计算方式:
物理地址 = 符号虚拟地址 - 链接地址偏移量 + 物理加载基地址
4.2.2 map_mem内核以外的内存线性映射
map_mem是对内核镜像内存以外的内存进行线性映射,线性体现在其虚拟地址的计算上:
虚拟地址 = 物理地址 + PAGE_OFFSET
cpp
static void __init map_mem(pgd_t *pgdp)
{
static const u64 direct_map_end = _PAGE_END(VA_BITS_MIN);
phys_addr_t kernel_start = __pa_symbol(_stext);
phys_addr_t kernel_end = __pa_symbol(__init_begin);
phys_addr_t start, end;
int flags = NO_EXEC_MAPPINGS;
u64 i;
....
/*
* Take care not to create a writable alias for the
* read-only text and rodata sections of the kernel image.
* So temporarily mark them as NOMAP to skip mappings in
* the following for-loop
*/
//为了防止只读权限的内核内存区域在后续对所有内存进行映射时再次映射成可读写权限,把内核内存标记为no-map
memblock_mark_nomap(kernel_start, kernel_end - kernel_start);
...
/* map all the memory banks */
/*
宏展开如下:
for (i = 0, __next_mem_range(&i, NUMA_NO_NODE, MEMBLOCK_HOTPLUG, &memblock.memory, NULL, &start, &end, NULL); i != (u64)ULLONG_MAX; __next_mem_range(&i, NUMA_NO_NODE, MEMBLOCK_HOTPLUG, &memblock.memory, NULL,&start, &end, NULL)){
遍历memblock所有region,再调用__map_memblock一个区域一个区域进行线性映射
*/
for_each_mem_range(i, &start, &end) {
if (start >= end)
break;
/*
* The linear map must allow allocation tags reading/writing
* if MTE is present. Otherwise, it has the same attributes as
* PAGE_KERNEL.
*/
__map_memblock(pgdp, start, end, pgprot_tagged(PAGE_KERNEL),
flags);
}
/*
* Map the linear alias of the [_stext, __init_begin) interval
* as non-executable now, and remove the write permission in
* mark_linear_text_alias_ro() below (which will be called after
* alternative patching has completed). This makes the contents
* of the region accessible to subsystems such as hibernate,
* but protects it from inadvertent modification or execution.
* Note that contiguous mappings cannot be remapped in this way,
* so we should avoid them here.
*/
/*
内核在启动时特意为自己的代码段创建了一个权限受限的(只读、不可执行)"影子"映射。这个映射专门用于需要读取内核内容但不应执行或修改内容的场景(如休眠),同时也是防御性编程的一部分,提高了系统安全性。
*/
__map_memblock(pgdp, kernel_start, kernel_end,
PAGE_KERNEL, NO_CONT_MAPPINGS);
//清除前面标记的no-map
memblock_clear_nomap(kernel_start, kernel_end - kernel_start);
...
}系统的所有内存的映射,通过调用memblock_mark_nomap来实现:
cpp
static void __init __map_memblock(pgd_t *pgdp, phys_addr_t start,
phys_addr_t end, pgprot_t prot, int flags)
{
__create_pgd_mapping(pgdp, start, __phys_to_virt(start), end - start,
prot, early_pgtable_alloc, flags);
}其中使用__phys_to_virt(start)将物理内存地址转换成虚拟地址,该转换属于线性转换,在linux-5.15.158\arch\arm64\include\asm\memory.h中该宏定义如下,即对所有物理内存加上一个偏移,所谓的线性映射。
cpp
#define __phys_to_virt(x) ((unsigned long)((x) - PHYS_OFFSET) | PAGE_OFFSET)取出线性虚拟地址后,需要写入页表,同样调用__create_pgd_mapping来实现。
4.3 __create_pgd_mapping 映射流程
__create_pgd_mapping的声明,即在页表pgdir处,将phys物理地址映射到virt虚拟地址上,映射大小位size,prot为映射相关权限,pgtable_alloc则为申请每一级页表的内存回调。
cpp
static void __create_pgd_mapping(pgd_t *pgdir, phys_addr_t phys,
unsigned long virt, phys_addr_t size,
pgprot_t prot,
phys_addr_t (*pgtable_alloc)(int),
int flags)开始分析映射过程前,先理论回顾下映射的过程,映射原理参考本文最前面1节,这里为了把一个物理地址映射到一个虚拟地址,逻辑上有一部分需要反着推

第一需要先找到pgd的地址,该地址是页表基地址 + pgd的偏移量,即虚拟地址的47~39bit的值,得到pgd地址。
第二,填充pgd地址内容:该内容是pud的内存地址,但需填pud的内存地址-pud偏移量,即虚拟地址的38~30bit的值,减掉该偏移是因为后续翻译映射需要加上该值。
第三,填充pud内存内容:该内容是pmd内存地址,同理需填pmd内存地址-pmd偏移量
第四,填充pmd内存内容:该内容是pte内存地址,同时需填成pte内存地址-pte偏移量
第五,填充pte内存内容:该内容是用来存放物理内存地址的内存,由于到最后一级,无需减去任何偏移值。
第六,填充存放物理内存地址的内容:该内存的内容需要填充为 需要映射的物理地址(phys) - 虚拟地址(virt)低12bit,减掉是 因为后续翻译映射需要加上该值。
到此地址的映射结束,实际上__create_pgd_mapping的处理逻辑也是这样子的。
cpp
static void __create_pgd_mapping(pgd_t *pgdir, phys_addr_t phys,
unsigned long virt, phys_addr_t size,
pgprot_t prot,
phys_addr_t (*pgtable_alloc)(int),
int flags)
{
unsigned long addr, end, next;
pgd_t *pgdp = pgd_offset_pgd(pgdir, virt);//找到pgd的偏移地址(虚拟地址的pgd(39~47bit)+映射表基地址)
/*
* If the virtual and physical address don't have the same offset
* within a page, we cannot map the region as the caller expects.
*/
if (WARN_ON((phys ^ virt) & ~PAGE_MASK))
return;
phys &= PAGE_MASK;//去掉page对应的位,只保留page以上的位,即0~11bit在这里被置0
addr = virt & PAGE_MASK;//同理的处理,去掉page对应的位
end = PAGE_ALIGN(virt + size);//取出映射的结束虚拟地址,页对齐
do {
next = pgd_addr_end(addr, end);//这里取移动PGDIR_SIZE之后的地址,即取下一个pgd(和后面addr=next组合形成的意图)
/*
* pgdp: pgd页表地址
* addr: 当前要映射的起始虚拟地址
* next: 当前要映射的结束虚拟地址
* phys: 当前要映射的起始物理地址
* prot: 映射权限值
* pgtable_alloc:回调,为空
* flags: 映射方式,NO_CONT_MAPPINGS
*/
alloc_init_pud(pgdp, addr, next, phys, prot, pgtable_alloc,
flags);
phys += next - addr;//一个pgd能映射 1<< 39的范围,物理地址同样往前挪1<<39bit,即这些内存地址已被上一个pgd映射,取一个地址范围的物理起始地址来映射
} while (pgdp++, addr = next, addr != end);//pgd页表之前往前移动一个指针(8bytes),虚拟地址pgd往前挪一个pgd,同时判断是否偏移到当前要映射的结束虚拟地址(即映射是否完成),否则继续。
}接口主要计算当前映射范围,是否超过了单个pgd能映射的范围(单个pgd能映射范围为512个pud,pud为512个pmd,pmd为512pte,pte为512*4K,总范围为512*512*512*4K = 512GB),如果超过则拆解成多个pgd进行映射,显然一般都不会超过如此大的范围。
接口调用了alloc_init_pud进行下一级pud的处理
cpp
static void alloc_init_pud(pgd_t *pgdp, unsigned long addr, unsigned long end,
phys_addr_t phys, pgprot_t prot,
phys_addr_t (*pgtable_alloc)(int),
int flags)
{
unsigned long next;
pud_t *pudp;
p4d_t *p4dp = p4d_offset(pgdp, addr);//pgd的页表基地址
p4d_t p4d = READ_ONCE(*p4dp);//当前pgd页表的内容
/*
* 判断该页表是否被填充过,没被填充过时,将进行初始化填充
* 前面early_fixmap_init填充了pgd/pud/pmd,这里已经是填充过的
* fixmap的区域大概是4mb,前面early_fixmap_init填充了pgd/pud足够覆盖
* 4MB(39bit和30bit大大小),根据这个计算来理解,这里pgd的地址实际跟
* early_fixmap_init填充时的地址一样,即这里的地址内容是被early_fixmap_init
* 填充过的
*/
if (p4d_none(p4d)) {
p4dval_t p4dval = P4D_TYPE_TABLE | P4D_TABLE_UXN;//pud页表映射权限配置
phys_addr_t pud_phys;
if (flags & NO_EXEC_MAPPINGS)
p4dval |= P4D_TABLE_PXN;
BUG_ON(!pgtable_alloc);
pud_phys = pgtable_alloc(PUD_SHIFT);//申请pud的内存,大小PUD_SHIFT
__p4d_populate(p4dp, pud_phys, p4dval);//将pud的物理地址写入pgd页表地址中
p4d = READ_ONCE(*p4dp);
}
BUG_ON(p4d_bad(p4d));
/*
* No need for locking during early boot. And it doesn't work as
* expected with KASLR enabled.
*/
if (system_state != SYSTEM_BOOTING)
mutex_lock(&fixmap_lock);
/*
* 从pgd偏移pud后得到pud物理地址转的虚拟地址,
*/
pudp = pud_set_fixmap_offset(p4dp, addr);
do {
pud_t old_pud = READ_ONCE(*pudp);//读取当前pud内存地址
next = pud_addr_end(addr, end);//pud向下移动一个单位pud
/*
* For 4K granule only, attempt to put down a 1GB block
*/
//如果使用2级映射,则这里pud是最后一级映射,映射page是1G,当前配置是4级映射故不走此分支
if (use_1G_block(addr, next, phys) &&
(flags & NO_BLOCK_MAPPINGS) == 0) {
pud_set_huge(pudp, phys, prot);
/*
* After the PUD entry has been populated once, we
* only allow updates to the permission attributes.
*/
BUG_ON(!pgattr_change_is_safe(pud_val(old_pud),
READ_ONCE(pud_val(*pudp))));
} else {
/*
* pudp: 当前pud页表地址
* addr: 要映射的起始虚拟地址
* next: 要映射的结束虚拟地址
* phys: 要映射的物理地址
* port: 映射权限
* pgtable_allco: 分配下一级内存函数回调指针,当前为NULL
* flags: 映射方式
*/
alloc_init_cont_pmd(pudp, addr, next, phys, prot,
pgtable_alloc, flags);
BUG_ON(pud_val(old_pud) != 0 &&
pud_val(old_pud) != READ_ONCE(pud_val(*pudp)));
}
phys += next - addr;
} while (pudp++, addr = next, addr != end);
pud_clear_fixmap();
if (system_state != SYSTEM_BOOTING)
mutex_unlock(&fixmap_lock);
}同样的,处理了pud级能处理的范围,超出则单个单个映射,循环里调用了alloc_innit_cont_pmd处理pmd级的映射
cpp
static void alloc_init_cont_pmd(pud_t *pudp, unsigned long addr,
unsigned long end, phys_addr_t phys,
pgprot_t prot,
phys_addr_t (*pgtable_alloc)(int), int flags)
{
unsigned long next;
pud_t pud = READ_ONCE(*pudp);
/*
* Check for initial section mappings in the pgd/pud.
*/
/*
* 同理获取当前pud级是否写过,没写过则分配pud页表内存
*/
BUG_ON(pud_sect(pud));
if (pud_none(pud)) {
pudval_t pudval = PUD_TYPE_TABLE | PUD_TABLE_UXN;
phys_addr_t pmd_phys;
if (flags & NO_EXEC_MAPPINGS)
pudval |= PUD_TABLE_PXN;
BUG_ON(!pgtable_alloc);
pmd_phys = pgtable_alloc(PMD_SHIFT);
__pud_populate(pudp, pmd_phys, pudval);//pmd物理地址写入pud页表
pud = READ_ONCE(*pudp);//这里读出来的是pmd物理地址
}
BUG_ON(pud_bad(pud));
do {
pgprot_t __prot = prot;
next = pmd_cont_addr_end(addr, end);//虚拟地址向下移动一个pmd单位
/* use a contiguous mapping if the range is suitably aligned */
if ((((addr | next | phys) & ~CONT_PMD_MASK) == 0) &&
(flags & NO_CONT_MAPPINGS) == 0)
__prot = __pgprot(pgprot_val(prot) | PTE_CONT);
//pmd处理函数
init_pmd(pudp, addr, next, phys, __prot, pgtable_alloc, flags);
phys += next - addr;
} while (addr = next, addr != end);
}同理,填充完pud内存后,循环处理单个pmd,对pmd进行填充处理
cpp
static void init_pmd(pud_t *pudp, unsigned long addr, unsigned long end,
phys_addr_t phys, pgprot_t prot,
phys_addr_t (*pgtable_alloc)(int), int flags)
{
unsigned long next;
pmd_t *pmdp;
/*返回pmd页表虚拟地址,同时将pmd物理地址page位写入pte*/
pmdp = pmd_set_fixmap_offset(pudp, addr);
do {
pmd_t old_pmd = READ_ONCE(*pmdp);//当前pmd物理地址
next = pmd_addr_end(addr, end);//向下移动一个mpd单位
/* try section mapping first */
//如果是大页映射,这里将是2M映射,没有下一级页表
if (((addr | next | phys) & ~PMD_MASK) == 0 &&
(flags & NO_BLOCK_MAPPINGS) == 0) {
pmd_set_huge(pmdp, phys, prot);//写入当前phy物理地址block位,即22bit以下位
/*
* After the PMD entry has been populated once, we
* only allow updates to the permission attributes.
*/
BUG_ON(!pgattr_change_is_safe(pmd_val(old_pmd),
READ_ONCE(pmd_val(*pmdp))));
} else {
//不是大页,继续下一级pte处理
alloc_init_cont_pte(pmdp, addr, next, phys, prot,
pgtable_alloc, flags);
BUG_ON(pmd_val(old_pmd) != 0 &&
pmd_val(old_pmd) != READ_ONCE(pmd_val(*pmdp)));
}
phys += next - addr;
} while (pmdp++, addr = next, addr != end);
pmd_clear_fixmap();
}调用init_pmd处理下一级映射,pte的处理同样逻辑,完成填充和单个pte的循环处理
cpp
static void alloc_init_cont_pte(pmd_t *pmdp, unsigned long addr,
unsigned long end, phys_addr_t phys,
pgprot_t prot,
phys_addr_t (*pgtable_alloc)(int),
int flags)
{
unsigned long next;
pmd_t pmd = READ_ONCE(*pmdp);
BUG_ON(pmd_sect(pmd));
/*当前pte页表是否建立,否则分配内存写入pte物理地址到pmd页表地址中*/
if (pmd_none(pmd)) {
pmdval_t pmdval = PMD_TYPE_TABLE | PMD_TABLE_UXN;
phys_addr_t pte_phys;
if (flags & NO_EXEC_MAPPINGS)
pmdval |= PMD_TABLE_PXN;
BUG_ON(!pgtable_alloc);
pte_phys = pgtable_alloc(PAGE_SHIFT);
__pmd_populate(pmdp, pte_phys, pmdval);
pmd = READ_ONCE(*pmdp);
}
BUG_ON(pmd_bad(pmd));
do {
pgprot_t __prot = prot;
//移动下一个pte单位
next = pte_cont_addr_end(addr, end);
/* use a contiguous mapping if the range is suitably aligned */
if ((((addr | next | phys) & ~CONT_PTE_MASK) == 0) &&
(flags & NO_CONT_MAPPINGS) == 0)
__prot = __pgprot(pgprot_val(prot) | PTE_CONT);
//没有下一级的处理,剩下offset值的写入
init_pte(pmdp, addr, next, phys, __prot);
phys += next - addr;
} while (addr = next, addr != end);
}最后调用alloc_init_cont_pte处理下一级内容:
cpp
static void init_pte(pmd_t *pmdp, unsigned long addr, unsigned long end,
phys_addr_t phys, pgprot_t prot)
{
pte_t *ptep;
ptep = pte_set_fixmap_offset(pmdp, addr);//获取pte页表虚拟地址
do {
pte_t old_pte = READ_ONCE(*ptep);
//写入物理地址
set_pte(ptep, pfn_pte(__phys_to_pfn(phys), prot));
/*
* After the PTE entry has been populated once, we
* only allow updates to the permission attributes.
*/
BUG_ON(!pgattr_change_is_safe(pte_val(old_pte),
READ_ONCE(pte_val(*ptep))));
phys += PAGE_SIZE;//每次写入偏移一页,即一页一页的写
} while (ptep++, addr += PAGE_SIZE, addr != end);
pte_clear_fixmap();
}将物理地址单页单页的写入pte地址中,映射结束后返回。