最初,Ollama是不带聊天UI功能的,和模型对话需要在命令行下进行,能完成Ollama部署并下载模型,一般也不会排斥命令行,但多多少少没有ChatGPT这种GUI来得自然,于是诞生各种GUI交互项目。本文试图汇总并学习。
Open WebUI
Open WebUI,以前称为Ollama WebUI,官网,一款专为LLM设计的用户友好的开源(GitHub,117K Star,16.4K Fork)可视化交互工具,通过类ChatGPT的直观界面,让用户无需代码即可训练、管理、调试和调用本地或云端LLM。官方文档。
通过可视化交互与大模型技术结合,成为私有化部署的标杆工具。开箱即用的特性适合开发者快速验证模型、企业构建合规AI平台及个人用户探索AI应用。随着插件生态的扩展(如视频生成、语音交互),未来可进一步降低多模态应用的开发门槛。
特点:
- 直观交互体验:提供类似ChatGPT的自然语言对话界面,支持Markdown和LaTeX渲染、代码高亮显示,提升内容可读性;
- 多轮对话管理:内置对话历史记录功能,用户可随时回顾上下文,避免重复输入,确保对话连贯性;
- 全平台兼容性:采用响应式设计,桌面端和移动端界面均能自适应屏幕尺寸,提供一致的使用体验;
- 多模型多模型支持:无缝切换不同文生文、文生图模型;
- 低门槛操作:通过简化交互流程和优化视觉设计,大幅降低非技术用户的使用难度,真正实现零学习成本上手;
- 命令支持:通过
#命令加载文档或添加文件,使用/命令快速访问预设提示。 - 功能丰富:支持RAG(检索增强生成)、多模态输入(文本、图片)、网络搜索等高级功能。支持对话标签和历史管理、提示词模板、上下文连续对话等实用功能。
| 模块 | 能力 | 价值 |
|---|---|---|
| 模型管理 | 多后端支持、模型下载/切换/加载、参数实时调整 | 统一管理入口,灵活适配不同场景 |
| 交互体验 | 类ChatGPT界面、代码高亮、Markdown渲染、多会话管理、响应式设计、PWA 支持、多语言界面 | 降低使用门槛,提供流畅体验 |
| 知识管理 | 文档上传、知识库构建、语义+网络搜索、文档处理流水线、上下文增强 | 利用私有数据提升回答准确性 |
| 高级功能 | 工具调用、Web搜索集成、提示词工作流、多模态支持、代码执行、图像生成、音频处理(ASR/TTS) | 扩展模型能力边界,实现任务自动化 |
| 用户管理 | 多用户系统、角色权限控制、团队协作 | 满足企业级部署需求 |
| 身份认证 | OAuth2、LDAP、基于角色的访问控制(RBAC)、SCIM 2.0 | 保障数据安全 |
| 部署隐私 | 全离线、自托管、Docker容器化、数据本地存储 | 彻底掌控数据,保障隐私安全 |
| 企业级功能 | 细粒度权限、用户组、审计日志、Webhook | 企业生产实践 |
采用现代全栈架构,前端和后端组件之间职责分明:
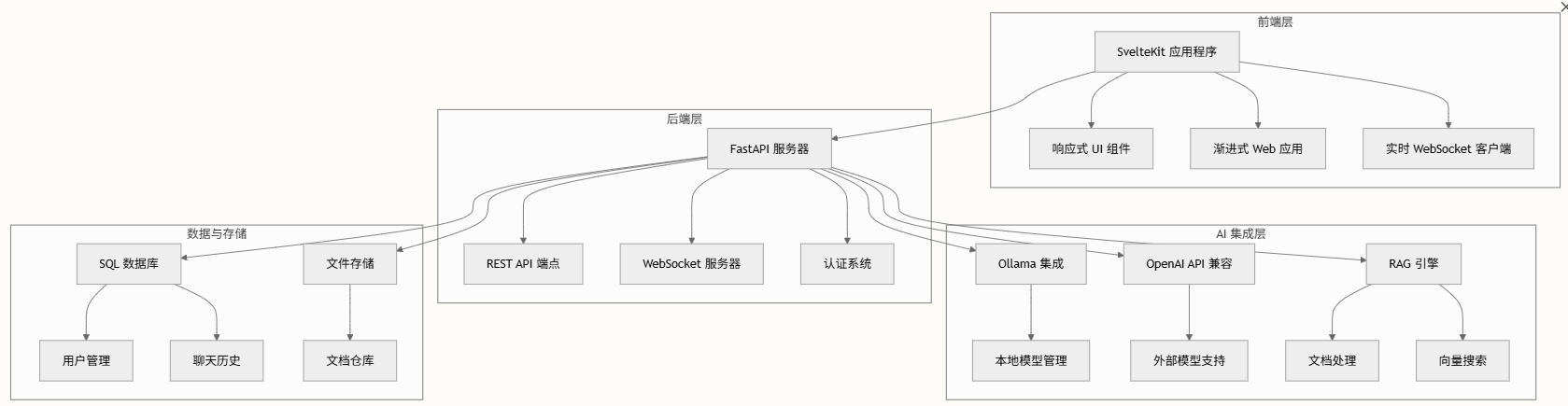
核心技术栈
- 前端技术:
- SvelteKit 2.5.20:提供服务器端渲染和客户端导航的现代Web框架
- TailwindCSS 4.0:实用优先的CSS响应式设计框架
- TypeScript 5.5.4:类型安全的JS开发语言
- Vite 5.4.14:高性能构建工具和开发服务器
- 后端技术
- FastAPI 0.118.0:高性能Web框架
- Uvicorn 0.37.0:Web应用的ASGI服务器
- SQLAlchemy 2.0.38:SQL工具包和对象关系映射库
- Redis:用于缓存和会话的内存数据结构存储
- WebSocket:实时双向通信协议
实战
支持多种安装方式:
- pip
- Docker
通过pip安装:
bash
pip install open-webui
open-webui serve
# 完全离线运行而不去尝试从网络上下载模型
set HF_HUB_OFFLINE=1 & open-webui serve通过Docker方式
bash
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main改成3001端口,是因为与本地其他应用占用的3000端口冲突。
集成Ollama:
发起提问:

Open WebUI支持通过OpenAI API兼容接口接入多种LLM:
- 本地部署的模型(如vLLM、Transformers运行的模型)
- 云端API服务(如OpenAI GPT-4等)
mcpo
开源(GitHub,3.7K Star,417 Fork)工具,可将mcp服务转换为Open API的代理服务。
安装:pip install mcpo
ChatBot-UI
Takeoff AI团队开源(GitHub,32.7K Star,9.4K Fork),官网。
实战
bash
git clone https://github.com/mckaywrigley/chatbot-ui.git
npm install
# Windows安装supabase
scoop bucket add supabase https://github.com/supabase/scoop-bucket.git
scoop install supabase
# Mac安装supabase
brew install supabase/tap/supabase
# 启动supabase
supabase start
cp .env.local.example .env.local
vim .env.local # 编辑APIKey
# 启动界面
npm run chat浏览器打开http://localhost:3000开始体验聊天功能,支持本地Ollama模型。
对supabase不熟悉或感兴趣,请参考BaaS(Backend as a Service)概述、平台、项目。
轻量级
设置Supabase什么的,略微麻烦。于是该项目作者又开源(GitHub,985 Star,240 Fork)ChatBot-UI的轻量级版本。
本地部署:
bash
git clone https://github.com/mckaywrigley/chatbot-ui-lite.git
npm i
OPENAI_API_KEY=xx
npm run dev浏览器插件
Page Assist
开源(GitHub,7.3K Star,673 Fork)浏览器插件,提供界面与LLM进行问答交互。Chrome插件地址。
Chrome浏览器抽风,连接11434端口失败,折腾将近2小时,没搞定:
在被搞得快崩溃时,才想到试试Edge(怪自己重度使用并依赖于Chrome和Google)。
Edge为了吸引Chrome用户,向Chrome看齐,地址栏输入edge://extensions管理扩展(包括:查看已安装、搜索、卸载等),搜索Page:
安装流程和Chrome无差别,界面如下:
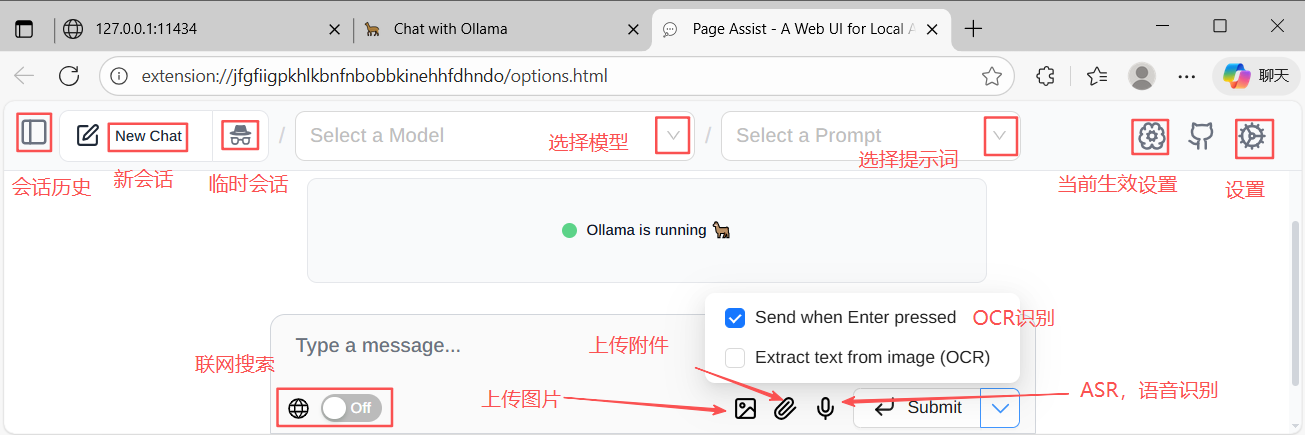
功能和按钮非常一目了然,但我还是很详细说明。模型列表如下:
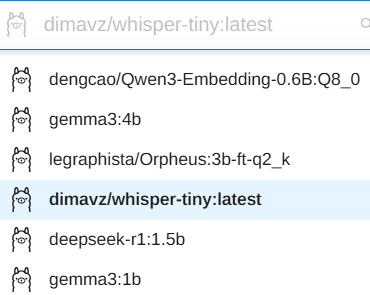
下面已经有基础的文生文问答。实时ASR自动语音识别,之前下载过Whisper模型,输入中文,只能识别英文:

仅44M大小的dimavz/whisper-tiny:latest,识别效果还是很不错的:
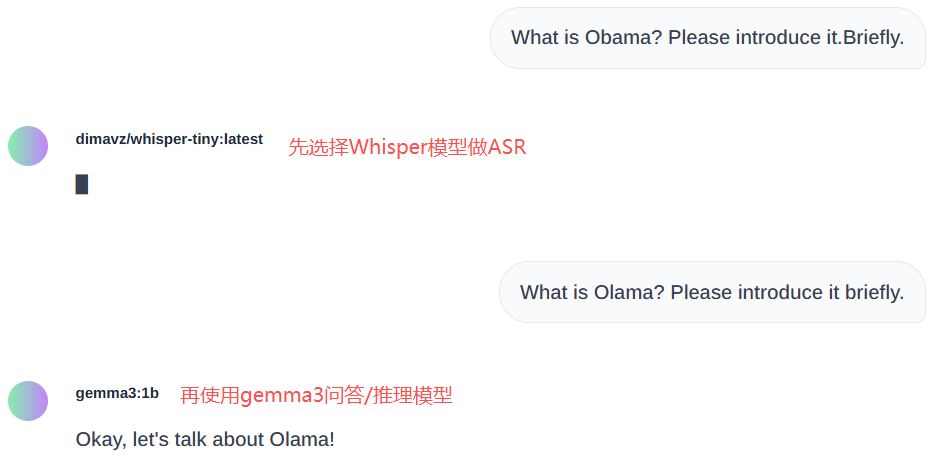
注意,Whisper不能用于问答:

不过仅1B参数量,明显是在胡说八道:

如上,几个功能按钮:朗读、复制、信息、重新生成、新分支、继续响应、编辑。
对话复制或导出:
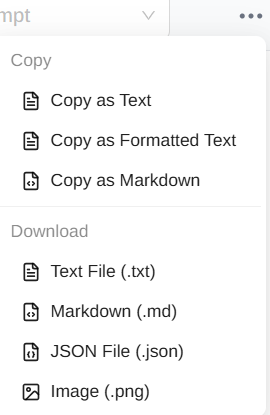
再来看看设置:
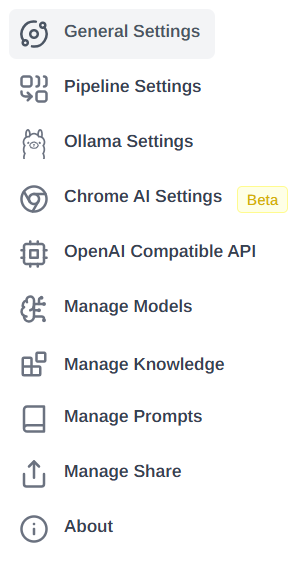
分别是:
- 通用设置
- 流水线设置:
- Ollama设置:
- Chrome AI设置:
- OpenAI兼容API:
- 模型管理:
- 知识库管理:
- 提示词管理:
- 分享管理:
- 关于:
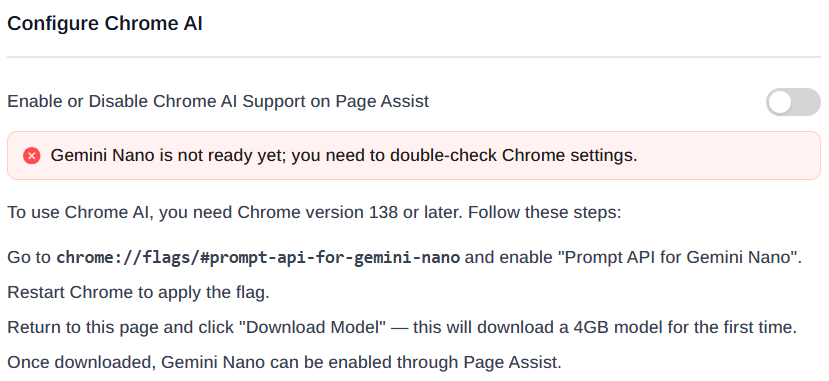
Chrome AI:
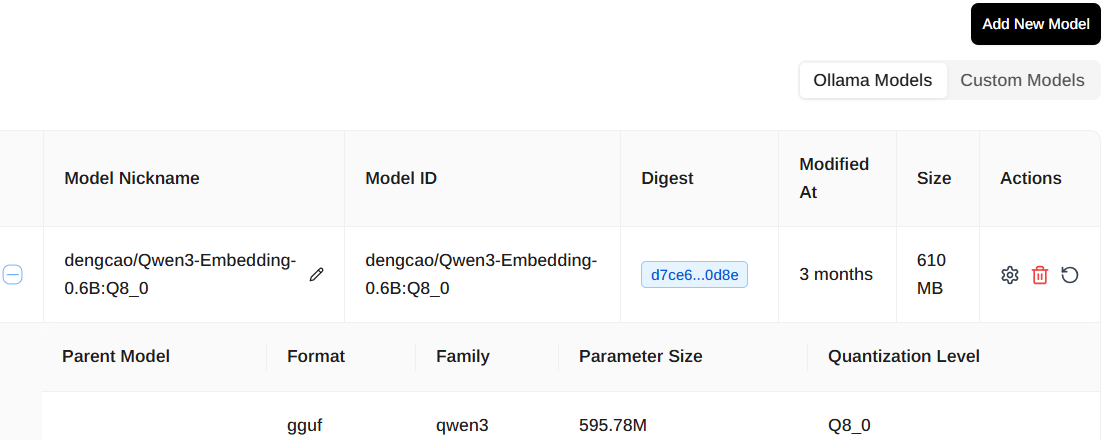
模型列表:
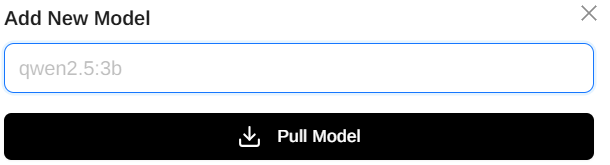
新增Ollama模型:
新增自定义模型,功能还不完善?
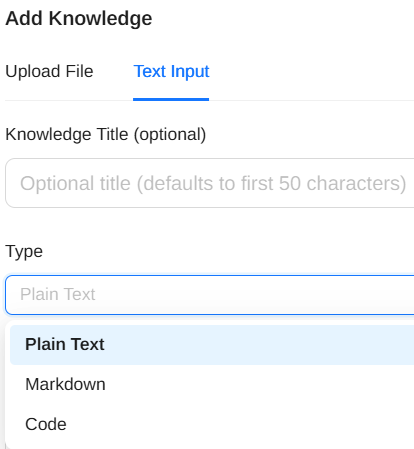
添加知识,支持上传文件和粘帖文本,类型支持纯文本、Markdown、Code:
提示词:
当前对话模型设置,部分截图:
对OpenAI开源的Whisper感兴趣,可参考:
ollama-ui
又一款开源(GitHub,1.1K Star,179 Fork)插件,Chrome插件地址,不会科学上网,可选择在线体验:
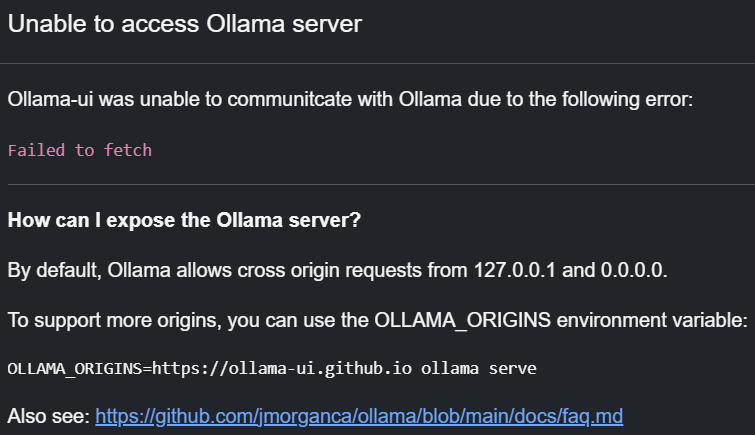
打开控制台,查看接口请求:
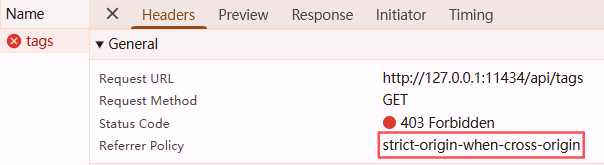
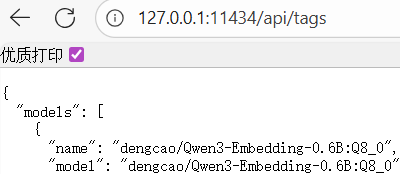
果然是跨域问题。但是直接打开http://127.0.0.1:11434/api/tags,输出正常
按照上面提示,设置系统变量OLLAMA_ORIGINS=*,推出Ollama。再次在终端输入ollama ps自动拉起Ollama进程,Ollama GUI上发起Query,自动拉起模型。浏览器刷新页面:
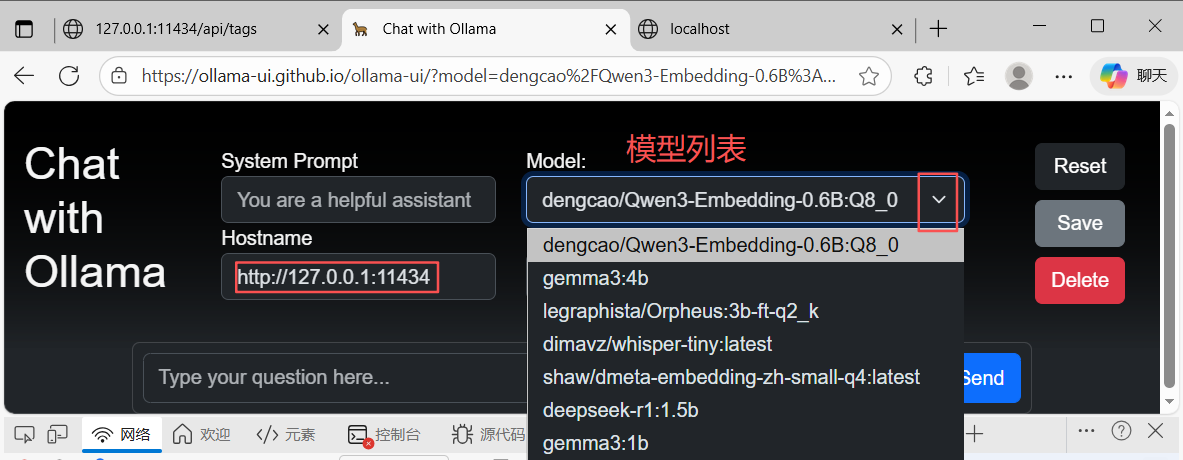
根据Ollama暴露的API接口,获取模型列表,选择一个推理(聊天)模型,如gemma3:1b
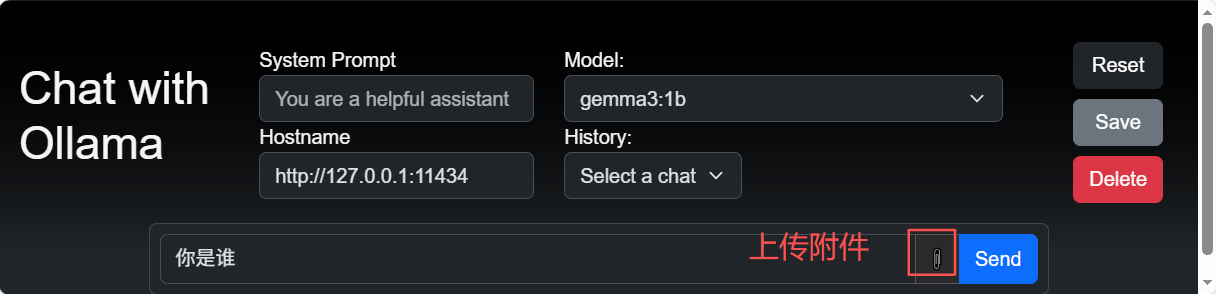
效果如下:
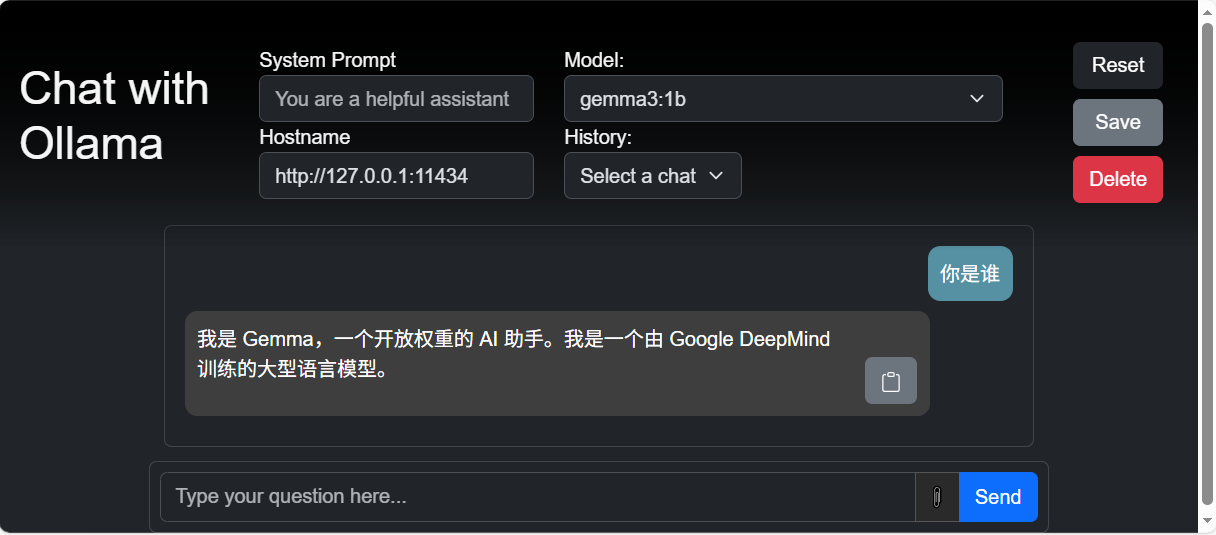
注意,Edge浏览器可以正常打开http://127.0.0.1:11434,Chrome浏览器打开有问题:
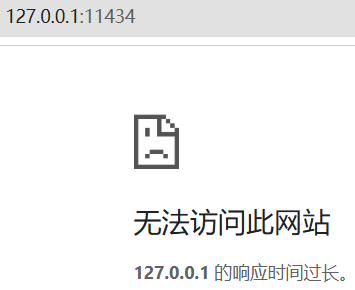
Chrome浏览器,什么鬼?

Studio类工具
包括开源和闭源两大类,通过提供便捷的exe或msi程序或压缩包(Portable版,解压缩即可用),傻瓜式安装;不过使用还是需要自行摸索研究下;已经不仅仅只是一个聊天交互工具,还提供各种功能。
Cherry Studio
LM Studio
TODO,准备写一篇。