Transformer实战(29)------大语言模型(Large Language Model,LLM)
0. 前言
近年来,大语言模型 (Large Language Model, LLM) 领域取得了显著进展,涌现了诸如 GPT-3 (1750 亿参数)、PaLM (5400 亿参数)、BLOOM (1750 亿参数)、LLaMA (650 亿参数)、Falcon (1800 亿参数)、Mistral (70 亿参数)、DeepSeek (6710 亿参数)等模型,这些模型在各种自然语言任务中展现出优异性能。在本节中,我们将介绍大语言模型,还将介绍如何对大语言模型进行微调。
1. 大模型简介
当我们谈论大语言模型 (Large Language Model, LLM) 时,首先需要清楚什么是语言模型 (Language Model, LM)。有时,人们会混用语言模型和大语言模型这两个术语,但它们实际上可能指代不同的模型------每个 LLM 都是一个语言模型,但并非每个语言模型都是 LLM。
过去,我们将那些使用 n-gram 计算序列中下一个词的概率的模型称为语言模型。如今,大语言模型通常指的是基于 Transformer 的神经网络模型,这些模型有着数十亿个参数,并在海量数据集上训练,例如 ChatGPT 和 DeepSeek。这些模型都是生成式语言模型。而像 BERT 这样仅包含编码器、参数约 1 亿的模型,以及简单的 n-gram 模型,可以被视为语言模型。
简而言之,我们可以说,LLM 指的是参数超过 10 亿且具有生成特性的仅解码器模型。近期研究表明,当模型规模增大并在大规模数据集上训练时,它们的表现非常出色。具体来说,它们在零样本和少样本学习的表现有所提升,能够根据给定的指令有效执行任务。除此之外,生成特性使得我们可以在这一框架内处理任何类型的问题,因为输入和输出都是自由文本格式,这也推动了提示工程 (prompt engineering) 的流行。我们可以使用 LLM 生成数值预测,甚至编写计算机代码。
目前,LLM 领域的一个重要趋势是"基于人类反馈的强化学习" (Large Language Model, RLHF)。我们可以将 RLHF 范式的步骤形式化如下:
- 自监督:让模型自主学习
- 监督学习:为模型提供信息以便学习
- 人类反馈:观察模型并纠正其行为
如下图所示,初始阶段涉及训练传统的预训练语言模型 (pre-training language model, PTLM)。在这一阶段,使用特定的自监督目标函数(如下一单词预测),以增强模型的语言理解能力。在第二步中,通过利用指令跟随数据集来调整模型,使其能够遵循自然语言指令。通过这个过程,语言模型获得了多种任务的知识,并能够解决不熟悉的问题。
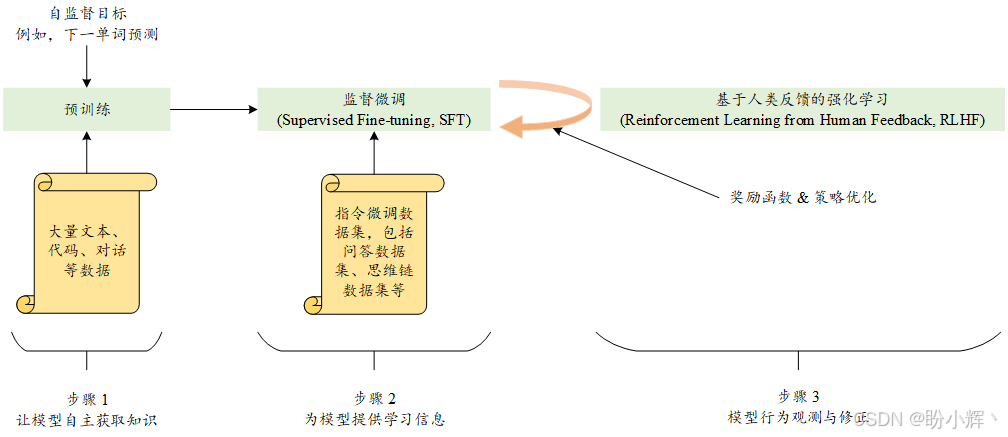
在最后阶段,与传统的预训练和微调两阶段过程相比,引入了一个独特的特性。最后阶段强调了奖励函数和策略优化在强化学习中的重要性。人类标注者参与模型实验,并对模型的结果进行排名,排名结果用来评估语言模型生成的文本输出。在基于人类反馈的强化学习领域,主要的研究方向之一是开发能够准确反映人类偏好的奖励模型。
2. 奖励函数的重要性
随着 ChatGPT 的发布,LLM 在学术界和产业界都引起了极大的关注。简单来说,大语言模型本质上就是语言模型的更大版本。然而,究竟什么样的规模才算是大仍然不太明确,但通常参数少于十亿的模型不被视为大模型。需要注意的是,这种规模的概念完全是相对的,一个拥有十亿参数的模型现在可能被认为是大模型,但可能在几个月之后,这种划分就不再成立了。
不仅是规模,其他一些衡量标准也会影响这些模型的质量。在这种情况下,质量并没有通过数字进行量化,因为目前还没有可靠的标准来衡量输出的质量。然而,我们仍然可以找到一些方法来进行评估。假设我们希望一个开放书籍问答 (Open Book Question Answering, OBQA) 模型能够回答与特定语境相关的问题。在这种情况下,可能期望模型直接从相关语境中提取准确的答案。然而,对于其他使用场景,可能更倾向于答案更具对话性,并以特定的语气呈现,而不是直接从语境中提取。
因此,如果我们需要一个对话式的 OBQA 模型,我们可能会拒绝选择一个高准确率的模型,而选择一个提供所需语气和写作风格的模型。
在以下示例中,可以看到一个基于编码器的问答模型,在SQuAD 数据集上进行了微调后的输出:
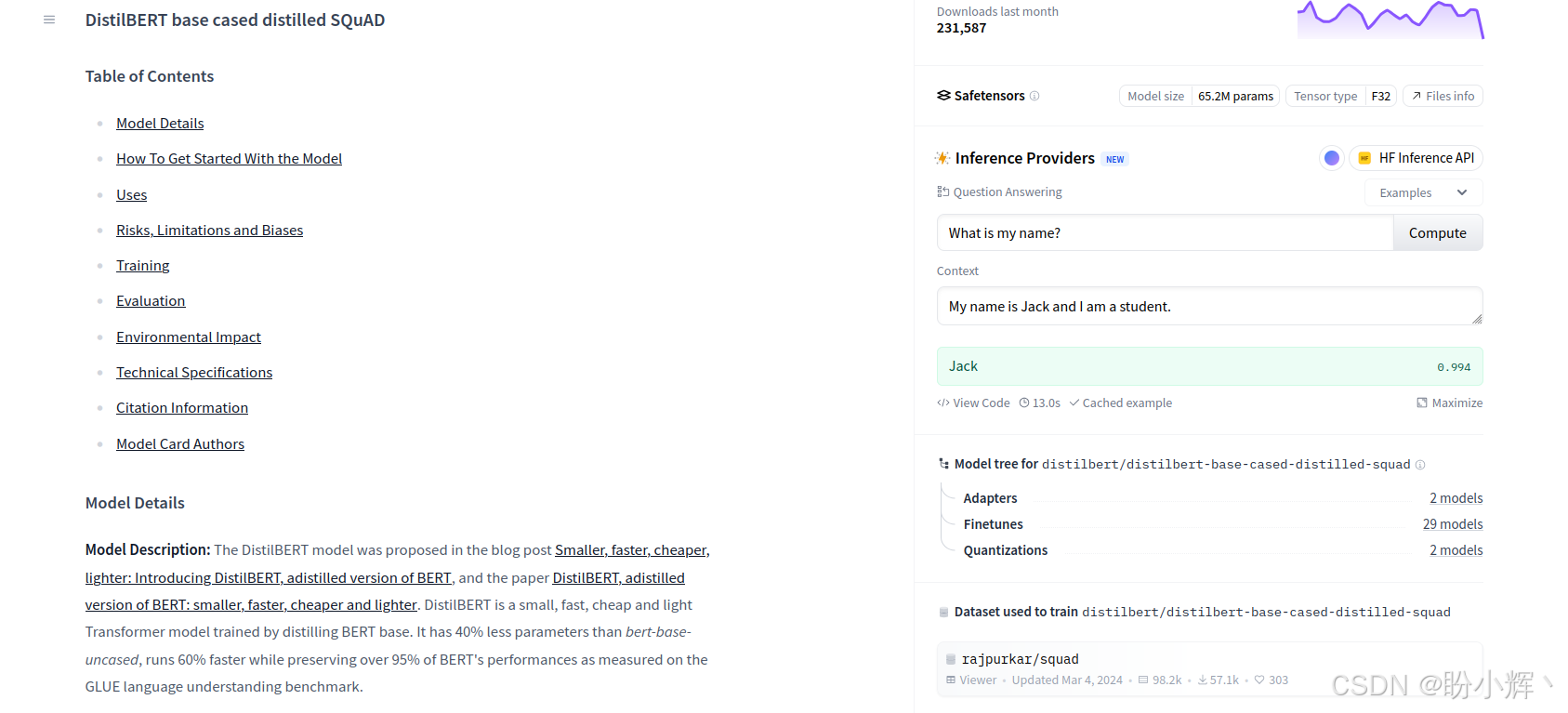
以下示例来自 DeepSeek 模型:

如上图所示,第一个模型只是一个经过问答微调的模型,而第二个模型则是一个能够理解我们给出指令的 LLM。监督学习已被证明对开发 GPT 和 T5 等模型非常有益,这些模型能够通过利用提示学习多种任务。然而,为了增强模型以更理想的方式生成结果的能力,引入了一种新的训练方案。这种方法结合了人类反馈来指导模型的学习,类似于强化学习方法,这个过程中使用了奖励函数来完成任务。奖励函数在指导模型的学习过程和使其生成期望输出方面起着至关重要的作用。在自然语言处理 (Natural Language Processing, NLP) 领域中,建模奖励函数非常重要。
一个在文本示例上训练的模型通过确定偏好来进行学习,这需要使用标注数据进行训练。如果没有奖励模型,单纯依赖人类标注数据的语言模型是无法充分进行训练的。然而,单独使用奖励模型来微调结果会导致较大模型的评分较低。此时,语言模型可能利用这一点生成误导性输出,这突显了原始模型保持一致性并防止此类情况发生的重要性。最佳方法是基于原始模型和经过强化学习微调模型之间的 KL 散度来施加惩罚。然而,LLM 的风险并不止于此;当它们在开放网页数据上进行训练时,自然会包含偏见。为了部署应用,重要的是用另一个能够识别有害、有毒或滥用内容的模型来增强这些模型。否则,即使是评分良好的对话型模型,仍然可能会无意中冒犯到他人。
3. 大模型的指令跟随能力
T0 是一系列开源模型,这些模型经过大量任务的训练。下图展示了用于训练这些模型的相关数据集。
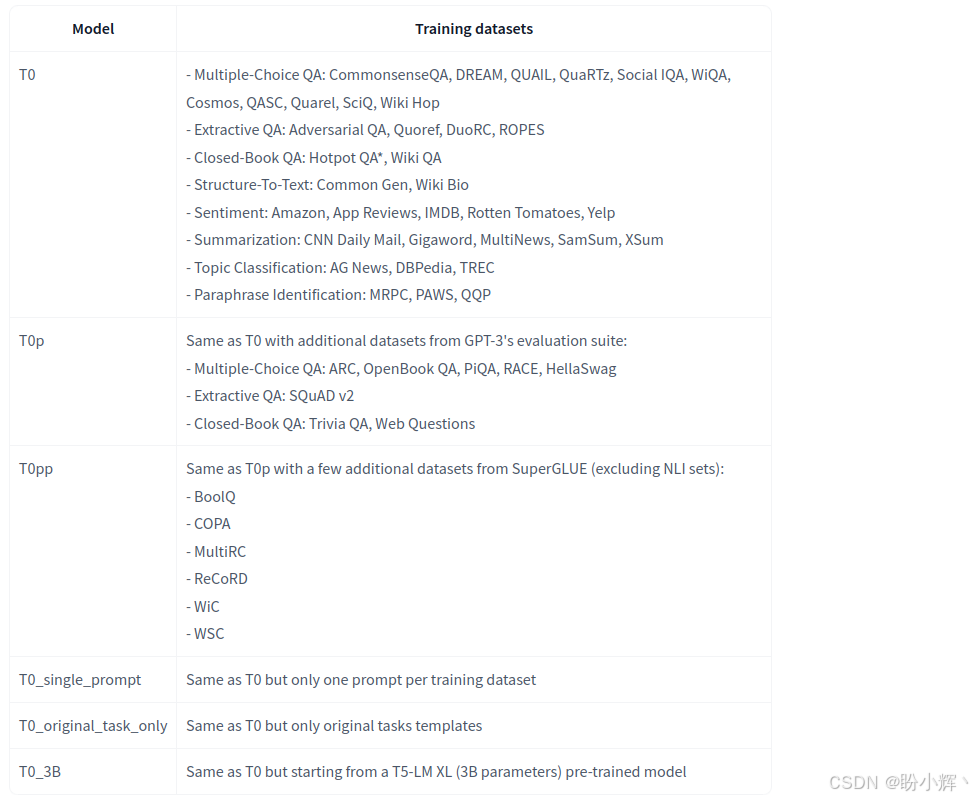
在本节中,我们将使用 T0_3B,这是 T0 系列中具有 30 亿个参数的版本。为了展示它的能力,我们将尝试分析两种不同的应用场景:共指消解 (coreference resolution) 和情感分析 (sentiment analysis)。
(1) 首先,使用 pip 命令安装所需库:
shell
$ pip install transformers sentencepiece(2) 接下来,加载模型和相应的分词器:
python
from transformers import(AutoTokenizer, AutoModelForSeq2SeqLM)
tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")(3) 使用相应的指令提示进行情感分析:
python
inputs = tokenizer.encode("Is this review positive or negative? Review: This book covers many different ascpect of NLP. I highly recommend buying it!", return_tensors="pt")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
# <pad> Positive</s>(4) 从指令提示中可以看到,这是一个情感分析任务。对于共指消解任务,输出结果如下所示:
python
inputs = tokenizer.encode("Meysam lives in Germany. He has been living in Berlin for a long time. In the previous sentence, decide who 'he' is referring to.", return_tensors="pt")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
# <pad> Meysam</s>接下来,我们将对 LLM 进行微调,使用 LLaMA 模型。
4. 微调大语言模型
大语言模型 (Large Language Model, LLM) 的主要目的是通过提示工程实现零样本任务泛化。然而,我们仍然可能希望将其微调以适应特定任务。在本节,我们将使用 SQuAD 数据集对开源语言模型 LLaMA 进行微调。需要注意的是,我们可以将不同的数据集合并成一个单一的数据集并进行格式化,然后训练模型,可以在多任务实验中尝试这种方法。本节为了简单起见,将使用单一数据集进行操作。
我们将采用以下技术来微调 LLM:
- 参数高效微调 (Parameter Efficient Fine-Tuning, PEFT):通过LoRA更新模型的部分参数,而不是更新整个模型参数。
PEFT的关键优势是显著减少需要训练的参数数量,这加速并简化了训练过程,对于LLM等时间和效率至关重要的大规模机器学习项目来说,这是一个宝贵的特性 - 模型量化:应用量化技术减少内存使用,例如使用
bitsandbytes将模型参数中的32 bits变量替换为4 bits变量。量化是一种通过降低位数来优化计算和内存成本的方法,它通过使用低精度的数据类型(如8 bits整数,而非32 bits浮点数)来减少内存使用、降低能耗并加速操作。它还支持嵌入式设备的整数数据类型。实质上,它是从高精度数据类型过渡到低精度数据类型 TRL(Transformer Reinforcement Learning):使用TRL库来实现更简洁、更快速的微调,同时实现高效的内存使用。TRL库由 Hugging Face 团队支持,是一个全栈工具,用于使用监督微调 (Supervised Fine-Tuning,SFT)、奖励建模 (Reward Modeling,RM)、近端策略优化 (Proximal Policy Optimization,PPO) 以及直接偏好优化 (Direct Preference Optimization,DPO) 等方法微调和对齐Transformer语言和扩散模型
(1) 首先,使用 pip 命令安装所需库:
shell
$ pip install accelerate bitsandbytes peft transformers trl (2) 然后导入相关函数和类:
python
import os, torch
from trl import SFTTrainer
from peft import LoraConfig, PeftModel
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
TrainingArguments,
BitsAndBytesConfig,
HfArgumentParser,
pipeline,
)构建指令跟随数据集是训练 LLM 时的重要步骤。数据的质量和多样性至关重要,拥有多种类型和领域的数据将有助于增强模型在多任务目标和零样本泛化方面的表现。在本节中,我们将使用 SQuAD 数据集进行训练,以简化过程。然而,在实际应用场景中,可以结合不同的任务,扩大数据范围。
(3) 使用 1000 个样本用于训练,350 个样本用于评估。我们也可以在训练过程中使用整个数据集,但这将需要较长时间:
python
import pandas as pd
dataset = load_dataset("squad")
train=pd.DataFrame(dataset["train"].select(range(1000)))
val=pd.DataFrame(dataset["train"].select(range(1000,1350)))
train.iloc[:,2:].head()
在输出中,可以看到文本中包括上下文、问题和答案,我们必须根据 LLaMA 模板来构造数据集:
shell
<s>[INST] Context: ... Question ? [/INST] Answer... </s>(4) 我们将每个三元组 (context, question, answer) 转换成一个字符串,如:<s> [INST] ... [/INST]... </s>:
python
train["text"]=train.apply(lambda x:
f"<s>[INST]Context: {x.context} Question: {x.question}[/INST] {x.answers['text'][0]} </s>",
axis=1)
val["text"]=val.apply(lambda x:
f"<s>[INST]Context: {x.context} Question: {x.question}[/INST] {x.answers['text'][0]} </s>",
axis=1)
from datasets import Dataset
train_dataset=Dataset.from_pandas(train[["text"]])
eval_dataset=Dataset.from_pandas(val[["text"]])需要注意的是,在以上代码中,我们添加了一个新列 text,将所有内容 (context, question, answer) 重新进行了表述。
(5) 设置LoRA。LoRA是一种通过减少模型的大小来进行计算的技术,从而使得能够在较少的内存上也能进行计算:
python
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)(6) 量化是一种减少模型数值精度的技术。量化不使用高精度的数据类型(例如32bits浮动点数),而是使用较低精度的数据类型,如 8 bits 或 4 bits 整数。这种方法可以减少内存使用并加速模型执行,同时基本保持精度:
python
compute_dtype = getattr(torch, "float16")
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=False,
)(7) 接下来,获取 LLaMA 模型:
LLaMA是一个受控模型,这意味着在使用之前需要获得访问权限。要请求访问权限,需要访问 LLaMA 链接:- 一旦获得访问权限后,需要通过
Hugging Face Hub进行身份验证。为此,需要在设置页面创建一个令牌,或前往Hugging Face Settings > Access Tokens > New token,并生成一个新的访问令牌,复制此访问令牌。如以下截图所示:
(8) 传递访问令牌以获得权限:
python
from huggingface_hub import login
access_token_read = "hf_tokens..." #<-paste your token here
login(token = access_token_read)(9) 加载 LLaMA 模型。我们加载特定的 LLaMA 预训练权重,meta-llama/Llama-2-7b-chat-hf,以及它的分词器:
python
# LLaMA model
model_name="meta-llama/Llama-2-7b-chat-hf"
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map={"": 0}
)
model.config.use_cache = False
model.config.pretraining_tp = 1
# Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name,
trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"(10) 使用 trl 库中的 SFTTrainer 类,这是一个非常强大的封装函数。只需将之前定义的 PEFT 和量化对象传递给 SFTTrainer 类。还明确 trainer 应专注于 text 列,而不是其他内容:
python
training_arguments = TrainingArguments(
output_dir="my_llama",
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=1,
optim="paged_adamw_32bit",
evaluation_strategy="epoch",
learning_rate=2e-4,
weight_decay=0.001,
fp16=True,
bf16=True, # if you have A100 resource, you can set it
lr_scheduler_type="linear"
)
from trl import SFTTrainer
trainer = SFTTrainer(
model=model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=None,
tokenizer=tokenizer,
args=training_arguments)(11) 开始训练过程:
python
trainer.train()(12) 完成了 LLaMA 模型的微调后,我们使用以下推理代码来测试模型,传递上下文和问题:
python
prompt='''
Context:Architecturally, the school has a Catholic character. Atop the Main Building's gold dome is a golden statue of the Virgin Mary.
Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend "Venite Ad Me Omnes".
Next to the Main Building is the Basilica of the Sacred Heart.
Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection.
It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858.
At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome),
is a simple, modern stone statue of Mary.
Question:To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?
'''
# Expected answer: Saint Bernadette Soubirous
squad_llama = pipeline(task="text-generation",
model=model,
tokenizer=tokenizer,
max_length=350)
result = squad_llama(f"<s>[INST] {prompt} [/INST]")
print(result[0]['generated_text'])
# Saint Bernadette Soubirous可以看到,模型得到了预期的结果,即 Saint Bernadette Soubirous。
小结
在本节中,我们介绍了大语言模型 (Large Language Model, LLM) 的概念。我们探讨了类似 T5 的模型如何在给定不同提示时生成多样化的响应。此外,我们成功地使用参数高效微调 (Parameter Efficient Fine-Tuning, PEFT)和量化技术训练了开源语言模型 LLaMA。
系列链接
Transformer实战(1)------词嵌入技术详解
Transformer实战(2)------循环神经网络详解
Transformer实战(3)------从词袋模型到Transformer:NLP技术演进
Transformer实战(4)------从零开始构建Transformer
Transformer实战(5)------Hugging Face环境配置与应用详解
Transformer实战(6)------Transformer模型性能评估
Transformer实战(7)------datasets库核心功能解析
Transformer实战(8)------BERT模型详解与实现
Transformer实战(9)------Transformer分词算法详解
Transformer实战(10)------生成式语言模型 (Generative Language Model, GLM)
Transformer实战(11)------从零开始构建GPT模型
Transformer实战(12)------基于Transformer的文本到文本模型
Transformer实战(13)------从零开始训练GPT-2语言模型
Transformer实战(14)------微调Transformer语言模型用于文本分类
Transformer实战(15)------使用PyTorch微调Transformer语言模型
Transformer实战(16)------微调Transformer语言模型用于多类别文本分类
Transformer实战(17)------微调Transformer语言模型进行多标签文本分类
Transformer实战(18)------微调Transformer语言模型进行回归分析
Transformer实战(19)------微调Transformer语言模型进行词元分类
Transformer实战(20)------微调Transformer语言模型进行问答任务
Transformer实战(21)------文本表示(Text Representation)
Transformer实战(22)------使用FLAIR进行语义相似性评估
Transformer实战(23)------使用SBERT进行文本聚类与语义搜索
Transformer实战(24)------通过数据增强提升Transformer模型性能
Transformer实战(25)------自动超参数优化提升Transformer模型性能
Transformer实战(26)------通过领域适应提升Transformer模型性能
Transformer实战(27)------参数高效微调(Parameter Efficient Fine-Tuning,PEFT)
Transformer实战(28)------使用 LoRA 高效微调 FLAN-T5