核心概念定义与特性
LEO和HW是Kafka数据一致性和副本同步状态的两个核心内容。
LEO(Log End Offset,日志末端偏移量)
定义:分区中最新的一条消息的偏移量+1,也就是下一条将要被写入的消息的偏移量位置。
特性:
- 每个副本都有自己的LEO(Leader 和 Follower 各自维护自己的 LEO)。
- 这是一个实时变化的值,每当有新的消息被追加到日志中,LEO 就会递增
- LEO 代表的是副本的"当前写入位置"
HW(High Watermark,高水位线)
定义:已成功复制到所有 ISR 副本的消息的偏移量界限。
更精确地说:HW 代表的是一个偏移量,消费者只能消费到 HW 之前(不包括 HW 指向的位置)的消息。
特性:
- 对于同一分区的所有 ISR 副本,HW 是相同的(由 Leader 计算并同步给 Follower)。
- HW 总是小于等于所有 ISR 副本的 LEO 的最小值。即:
HW = min(ISR所有副本的LEO),这个规则非常关键。 - HW 之前的消息被认为是 "已提交(Committed)" 的,是安全、不会丢失的。
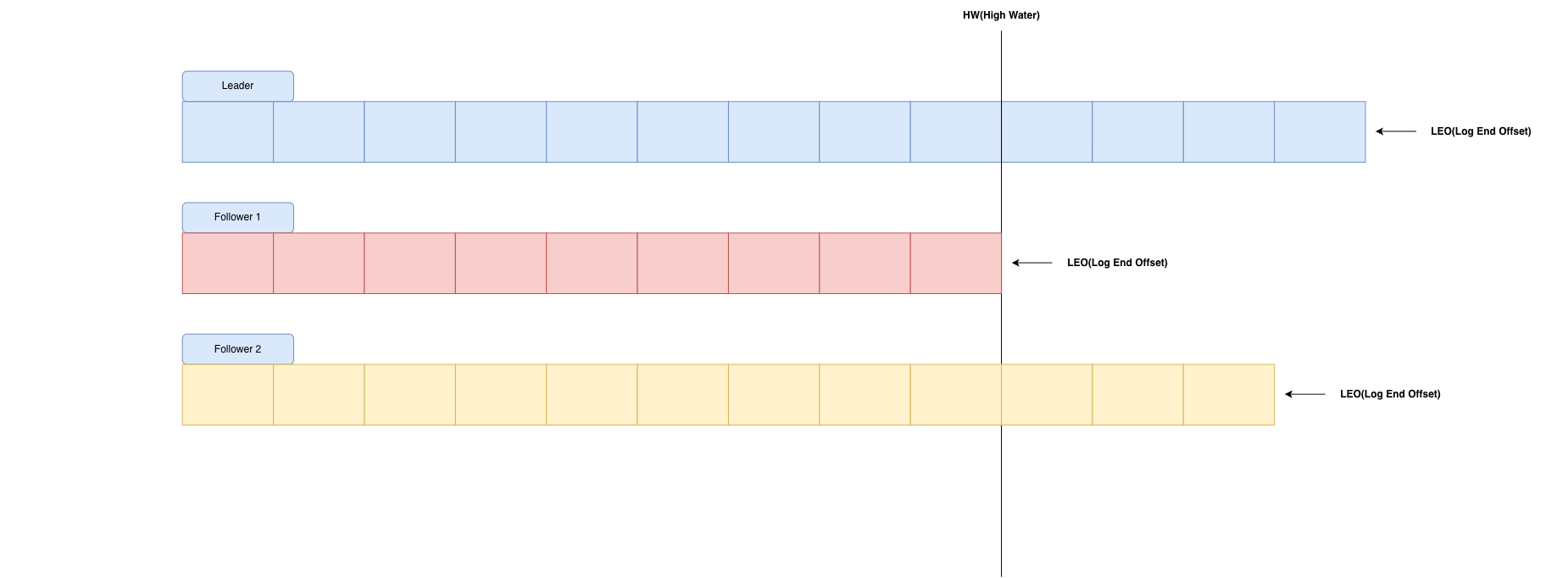
可以看到上图,LEO所在位置是每一个partition的log中的最后一条Message的位置。HW是ISR集合中最小的LEO。HW之前的数据才是Commit后的,这些内容对消费者可见。HW以及HW位置后的内容,消费者不可见。
详细工作流程
为了能够正确理解他们的工作流程,我举个例子来说明。
初始状态
假设有一个分区,ISR 包含 Leader (L),Follower1 (F1),Follower2 (F2)。
-
当前所有副本都同步,假设最后一条消息偏移量是 5。
-
那么 LEO_L = 6, LEO_F1 = 6, LEO_F2 = 6。
-
计算 HW = min(6, 6, 6) = 6。
-
消费者可以消费到偏移量 0-5 的消息。
新消息写入过程
步骤1:生产者发送新消息 M6 到 Leader
-
Leader 在本地追加消息 M6,分配偏移量 6。
-
Leader 的 LEO 从 6 变为 7。
-
Follower 尚未同步,因此 Follower 的 LEO 仍为 6。
步骤2:Leader 计算 HW
-
HW = min(LEO_L=7, LEO_F1=6, LEO_F2=6) = 6
-
HW 仍为 6,没有变化。
-
消息 M6(偏移量 6)对消费者不可见,因为它尚未被所有 ISR 副本复制。
步骤3:Follower 开始同步
-
Follower 向 Leader 发送 Fetch 请求。
-
Leader 将消息 M6(偏移量 6)发送给 Follower。
-
F1 成功写入,LEO_F1 变为 7。
-
F2 因为网络较慢,还在处理中,LEO_F2 仍为 6。
步骤4:Leader 更新 HW
-
HW = min(LEO_L=7, LEO_F1=7, LEO_F2=6) = 6
-
HW 仍为 6。
-
消息 M6 依然对消费者不可见,因为 F2 还没复制。
步骤5:F2 完成同步
- F2 成功写入消息 M6,LEO_F2 变为 7。
步骤6:Leader 再次更新 HW
-
HW = min(LEO_L=7, LEO_F1=7, LEO_F2=7) = 7
-
HW 更新为 7。
-
消息 M6(偏移量 6)现在对消费者可见了。
步骤7:消费者消费
-
消费者可以消费到偏移量 6 的消息了。
-
如果有新的消费者从最新位置开始消费,它将从偏移量 7(即 HW)开始消费,也就是等待下一条消息。