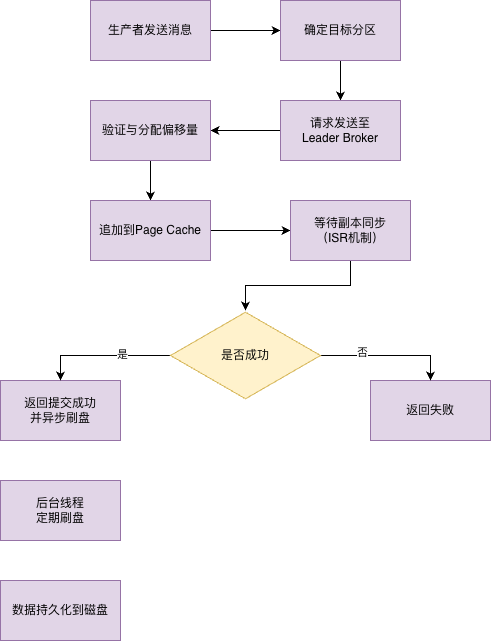
数据存储流程
kafka的数据存储流程总共是分为四个阶段。生产者发送与Broker的接收、日志追加与持久化、数据持久化到物理磁盘和索引与日志段滚动的四个阶段。这里暂时只做个简单的说明。后续的文章才会详细说明每个阶段里的细节。
第一阶段:生产者发送与Broker接收
这里分为生产者侧和Broker侧去聊。
生产者侧
生产者侧需要做的是四个事情。消息封装、分区选择、批次累积和发送请求。
消息封装,生产者会将消息(键、值、Headers等)封装成一个ProducerRecord,指定目标Topic。
分区选择,主要是四种情况。
- 如果指定Partition ID,则PR被发送至指定Partition (ProducerRecord)
- 如果未指定Partition ID,但指定了Key, PR会按照hash(key)发送至对应Partition
- 如果未指定Partition ID也没指定Key,PR会按照默认 round-robin轮训模式发送到每个Partitio
- 如果同时指定了Partition ID和Key, PR只会发送到指定的Partition (Key不起作用,代码逻辑决定)
批次累积,消息不会立即发送。Sender线程会将发向同一个分区的消息在内存中累积成一个批次。这也是提升吞吐量的关键所在。
发送请求,当批次达到了batch.size或者等待时间超过了linger.ms的时候,Sender线程会将其封装成一个ProduceRequest,发送给Broker的Leader。
Broker侧
Broker侧主要做两件事。接收ProduceRequest和请求解析与验证。
接收ProduceRequest,Kafka网络层会基于NIO接收ProduceRequest。
请求解析与验证,Broker验证请求的合法性(主题是否存在、是否有写入权限、请求格式等)。
第二阶段:日志追加与持久化(核心)
这个内容是Kafka存储等核心部分,主要是三个方面。Leader写入本地日志、等待副本同步(ISR机制)和响应生产者。
Leader写入本地日志
这里主要是三个工作。分配偏移量、构建内存结构和追加到页缓存。
分配偏移量,Kafka会为批次内到每条消息都分配一个单调递增到偏移量。偏移量是分区级别的
构建内存结构。Broker不会将网络接收到的原始字节直接写盘。它会将消息(带有新分配的偏移量)构建成更加高效的内存信息格式。
追加到页缓存,这是最关键的一步。
Broker调用文件系统的write()系统调用,将消息数据顺序追加到该分区对应的活跃日志段(xxx.log)的末尾。
PS:write()调用,在大部分时候,都不会触发实际的物理磁盘写入。数据首先会被写入到操作系统的页缓存。这个页缓存是Linux内核管理的一块内存区域,用于缓存磁盘数据。由于是顺序写入,而且利用了操作系统的缓存机制,这个操作速度极快,性能也是逼近内存写入。
等待副本同步(ISR机制)
为了保证数据的持久性和高可用,Kafka不会再Leader本地写入成功之后立即回复生产者。
Follower拉取:所有与这个Leader保持同步的副本(ISR)的Follwer,会不断的向Leader发送FETCH请求(和消费者拉取消息的协议是相同的),来拉取新的消息。
Follower写入:每个Follower收到Leader的数据后,会执行与Leader完全相同的流程:分配相同的偏移量,并将消息顺序追加到自己日志文件的页缓存中。
Follower确认:Follower写入本地页缓存后,会向Leader返回一个确认(ACK)
Leader判断"已提交":Leader会追踪每个消息被ISR中副本写入的状态。根据生产者设置的acks配置:
- acks = 0: Leader自己写入页缓存立即返回成功。最快,但可能丢失数据。
- acks = 1: Leader自己写入页缓存后即返回成功。这是默认的配置,在性能和可靠性之间取得一个平衡。
- acks = all / acks = -1 : Leader需要等待ISR中的所有副本(包括自己)都写入到页缓存中,才认为消息是"已提交"的,然后返回成功给生产者,最可靠,但是延迟最高。
响应生产者
一旦满足了acks配置要求的条件,Leader就会向生产者发送ProduceResponse,告知消息发送成功。(包含分配的偏移量等信息)至此,从生产者的角度来看,消息存储的流程已经完成。
第三阶段:数据持久化到物理磁盘(异步后台操作)
这里需要提的一个观点:Kafka的数据可靠性并不依赖于"同步刷盘",而是依赖于"多副本" + "异步刷盘"。主要也是两种。操作系统刷盘和Kafka强制刷盘。
操作系统刷盘(fsync)
- 写入页缓存的数据,由Linux内核的pdflush线程在后台异步的,或者是满足某种特定的条件(脏页比例、超时时间)时,将其刷新(fsync)到物理磁盘上。
- Kafka可以配置log.flush.interval.messages和log.flush.interval.ms 来"建议"操作系统更加频繁的刷盘。但是通常来说没有必要,会降低性能。
Kafka强制刷盘
这个很少使用到,只有在极端要求数据不丢失的场景下,可以配置flush.ms或flush.messages,但这个严重牺牲了吞吐量,生产环境中通常以来acks = all和足够的副本书来保证可靠性,而不是通过同步刷盘。
第四阶段:索引与日志段滚动
这里主要也是两个方面。一个是更新索引文件,另一个是日志段滚动(Rolling)。
更新索引文件
在消息追加到.log文件之后,Kafka不会为每个消息都更新索引了,这个太耗时间了。
他会检查自上次索引更新以来写入的字节数。如果超过了log.index.interval.bytes(默认是4KB),则会向.index文件(偏移量)索引和.timeindex文件(时间戳索引)中追加一条新的稀疏索引条目。
索引条目记录了偏移量/时间戳到物理文件位置的映射,以便实现后续的高效查找。
日志段滚动(Rolling)
活跃段(Active Segment)是当前正在写入的.log文件。
当活跃段满足以下任意一个条件时,就会滚动成为一个只读的旧段,并创建一个新的空活跃段:
-
文件大小超过log.segment.bytes默认 1GB)。
-
索引文件损坏或达到限制。
滚动的好处:
-
将大文件拆分为小文件,便于管理。
-
旧的、不再写入的日志段可以被高效地删除(基于时间或大小策略)或压缩(基于 Key 的保留最新值策略)。
-
便于进行独立的索引维护和数据清理。
Kafka数据存储流程图