TL;DR
- 场景:企业与个人将图片/音视频/静态资源迁移至阿里云 OSS,需稳态运维与控费。
- 结论:按区域与权限精确配置,结合防盗链/CNAME/日志即可兼顾可用性与成本。
- 产出:一份可落地,错误速查卡,覆盖 2025 年常见配置与排障。

基本介绍
阿里云对象存储服务(Object Storage Service, 简称 OSS),是阿里云提供的海量、安全、低成本、高可靠的云存储服务。其数据设计持久性不低于 99.99xx%(12个9),服务设计可用性或者业务连续性不低于 99.995%。
我们可以使用阿里云提供的API、SDK接口或者OSS迁移工具轻松的将海量的数据移入或者移出到阿里云OSS。数据存储到阿里云OSS之后,可以选择标准存储(Standard)作为移动应用、大型网站、图片分享或者热点视频的主要存储方式,也可以选择成本更低、存储期限更长的低频访问存储(Infrequent Access)和归档存储(Archive)作为不经常访问数据的存储方式。
OSS具有与平台无关的 RESTful API接口,可以在任何应用、任何时间、任何地点存储和访问任意类型的数据。
自建存储对比
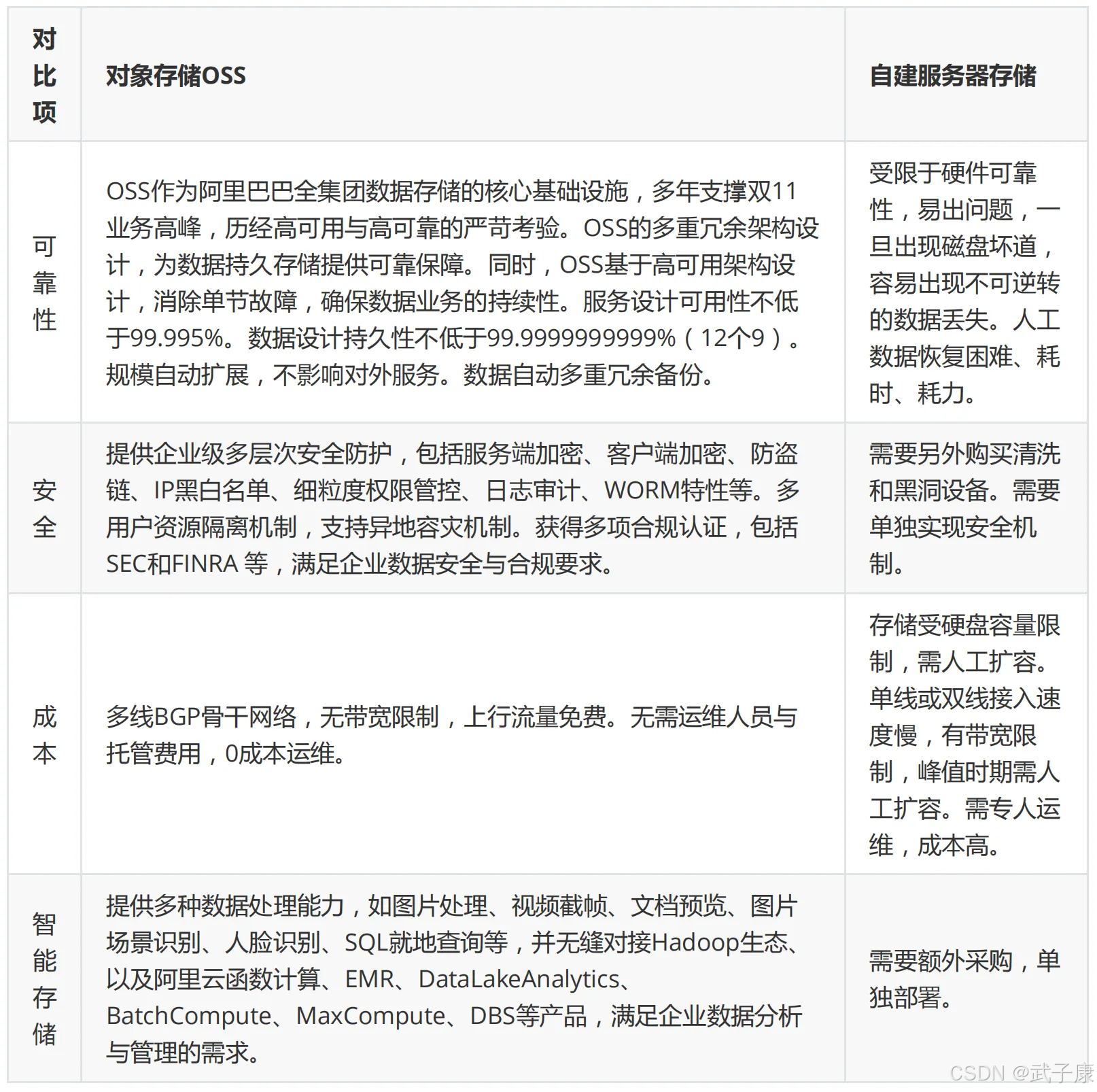
应用场景
图片音视频
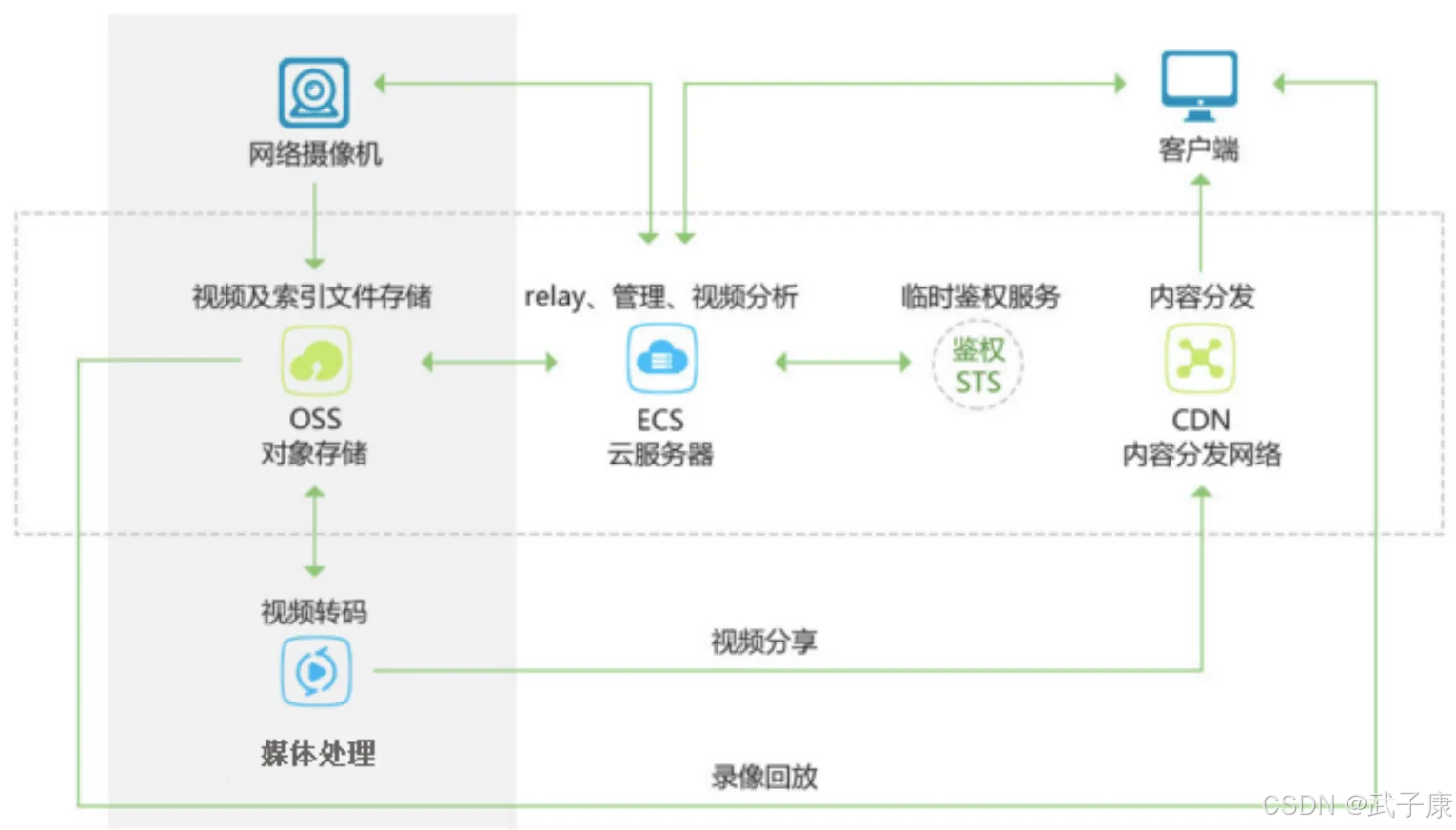
静态分离
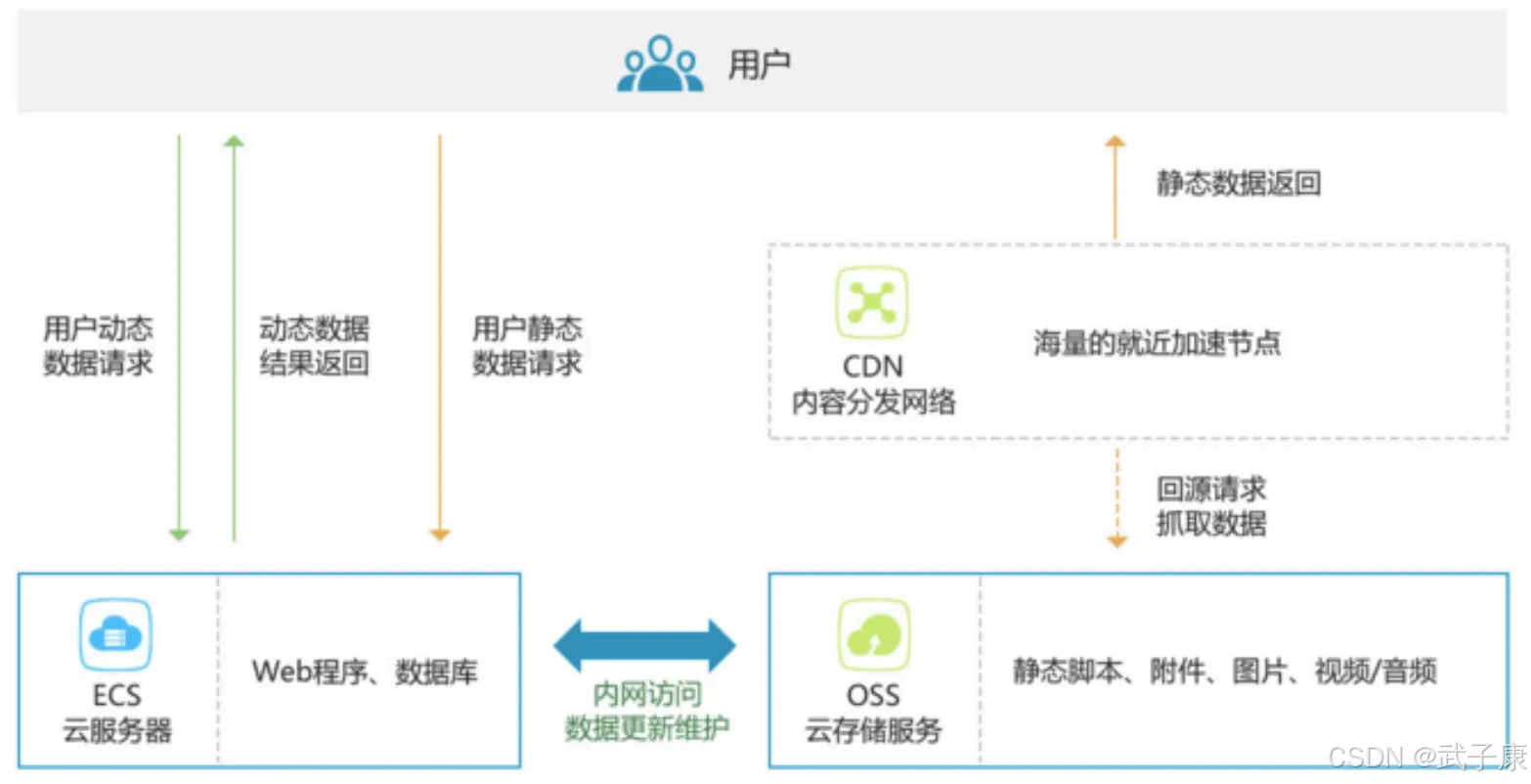
云端数据处理
计量计费
阿里云对象存储 OSS 服务费用的各项组成部分及计费方式分为:按量计费和包年包月两种。
● 按量付费:按实际使用量*单价的方式计费,每小时统计前一小时的实际用量并从账户余额中扣除实际消费金额,例如当前时间是9点30,结算的是8点到9点产生的费用。
● 包年包月:预先购买指定资源包,之后使用资源时,扣除相应的额度,一般情况下,包年包月比按量付费更加优惠。资源包目前仅提供标准 LRS存储包、低频LRS存储包、归档LRS存储包、标准ZRS存储包、低频ZRS存储包、下行流量包、回源流量包、传输加速包。
基本概念
存储空间
Bucket,存储空间是用户用于存储对象(Object)的容器,所有的对象都必须隶属于某个存储空间,存储空间具有各种配置属性,包括地域、访问权限、存储类型等。用户可以根据实际需求,创建不同类型的存储空间来存储不同的数据。
● 同一个存储空间的内部是扁平的,没有文件系统目录的概念,所有的对象都直接隶属于其对应的存储空间
● 每个用户可以拥有多个存储空间
● 存储空间的名称在OSS范围内必须是全局唯一的,一旦创建之后无法修改名称
● 存储空间内部的对象数目没有限制
存储空间的命名规范如下:
● 只能包括小写字母、数字、短横线
● 必须以小写字母或者数字开头的结尾
● 长度必须在3-63字节之间
对象/文件
Object,对象是OSS存储数据的基本单元,也被成为OSS的文件,对象由元信息(Object Meta),用户数据(Data)和文件名(Key)组成。对象由存储空间内部唯一标的 Key 来标识。
对象元信息是一组键值对,表示了对象的一些属性,比如最后修改时间、大小等信息,同时用户也可以在元信息中存储一些自定义的信息。
对象的生命周期是从上传成功到被删除为止,在整个生命周期内,只有通过追加上传的Object 可以继续通过追加上传写入数据,其他上传方式上传的 Object 内容无法编辑,可以通过重复上传同名的实现对象的覆盖。
对象命名规范:
● 使用 UTF-8 编码
● 长度必须在 1-1023字节之间
● 不能以正斜线或者反斜线开头
地域
Region,表示OSS的数据中心所在物理位置,用户可以根据费用、请求来源等选择合适的地域创建Bucket,一般来说,距离用户更近的 Region 访问速度更快。
Region 是在创建 Bucket 的时候指定的,一旦指定之后就不允许更改。该 Bucket 下所有的 Object 都存储在对应的数据中心,目前不支持 Object 级别的 Region 设置。
访问域名
Endpoint,表示 OSS 对外服务的访问域名,OSS 以 HTTP RESTful API的形式对外提供访问服务,当访问不同的 Region 的时候,需要不同的域名,通过内网和外放访问同一个 Region 所需要提供的 Endpoint 也是不同的。
访问密钥
AccessKey 指的是访问身份验证中用到的 AccessKeyId 和 AccessKeySecret。OSS通过使用 AccessKeyId 和 AccessKeySecret 对称加密的方法来验证某个请求的发送者身份,AccessKeyId 用于标识用户,AccessKeySecret 是用户用于加密签名字符串和OSS用来验证签名字符串和密钥,必须保密。
对于OSS来说,AccessKey 的来源有:
● Bucket 的拥有者申请的 AccessKey
● 被 Bucket 的拥有者通过 RAM 授权给第三方请求者的 AccessKey
● 被 Bucket 的拥有者通过 STS 授权给第三方请求者的 AccessKey
Service
OSS提供给用户的虚拟空间,在这个虚拟空间中,每个用户拥有一个或者多个 Bucket。
功能详解
基本功能
使用阿里云管理控制台来完成OSS基本操作的流程如下:

开通服务器
我们登录到阿里云,找到:对象存储OSS
创建 Bucket(我这里早几年之前已经创建过了):
根据你自己的情况选择(按默认的选择也可以):
我们进入之后,可以选择上传文件和下载文件:
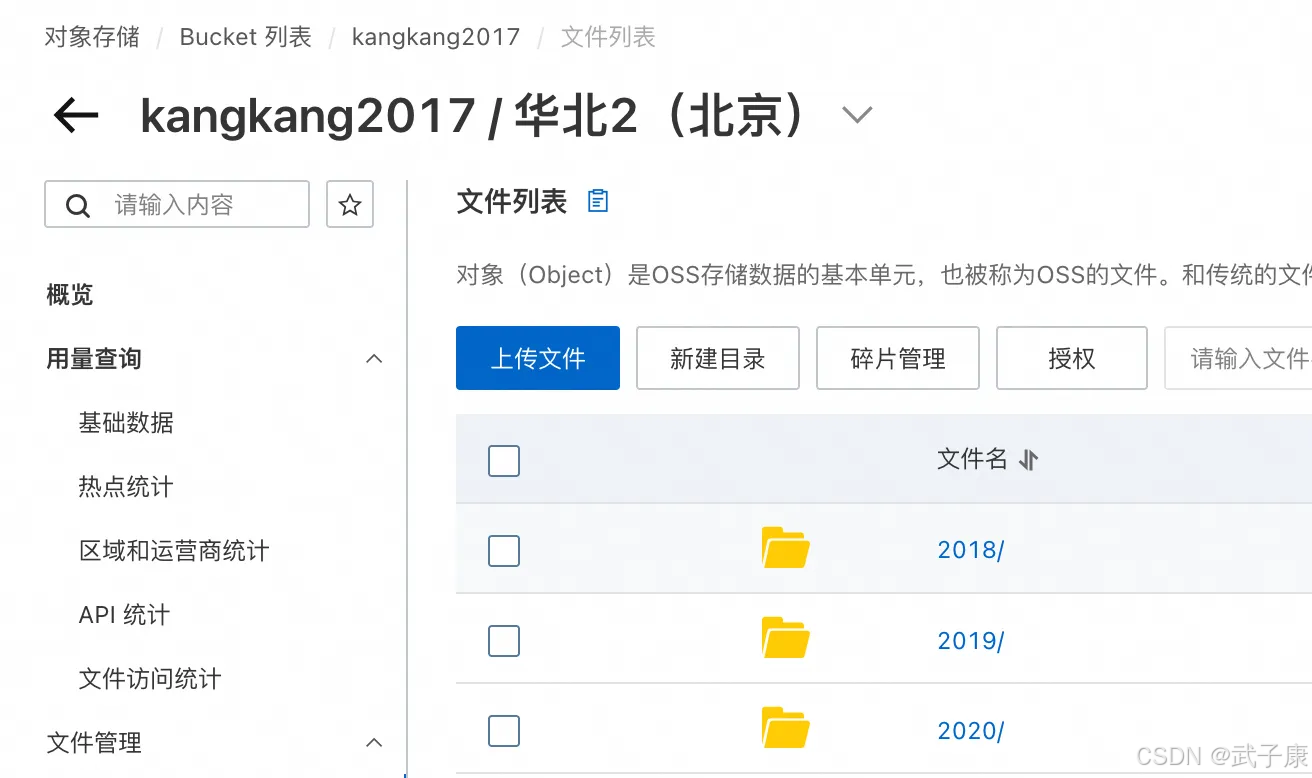
Object外链地址
如果一个 Bucket 设置成公开读权限,意味着允许其他用户来访问你的object,你的object外链地址构成规则如下所示:
shell
http:// <你的bucket名字>.<数据库中心服务域名>/<你的object名字>构成规则的示意图如下:

假设这个OSS的数据在青岛,那URL就是:
shell
http://oss-example.oss-cn-qingdao.aliyuncs.com/aliyun-logo.png我们使用的时候,可以直接将URL链接放入到HTML中使用:
html
<img src="http://oss-example.oss-cn-qingdao.aliyuncs.com/aliyun-logo.png"/>防盗链
OSS是按使用收费的服务,为了防止用户在OSS上的数据被其他人盗链,OSS支持基于HTTP header中表头字段 referer 的防盗链方法。通过 OSS控制台-权限管理-防盗链,可以对一个 Bucket 设置 referer字段的白名单和是否允许 referer 字段为空的请求。
细节分析:
● 用户只有通过URL签名或者匿名访问Object时,才会做防盗链验证。如果有 Authorization字段的,是不会验证的
● 一个 bucket 可以支持多个 referer参数,这些参数之间由逗号分割,OSS控制台配置时,使用换行
● Referer 参数支持通配符 * 和 ?
● 用户可以设置是否允许 Referer为空的时候访问
● 白名单为空时,不会检查 Referer字段是否为空(不然那所有请求都会被拒绝)
● 白名单不为空时,且设置了不允许 热费热热热 字段为空的规则,则只有 Referer 属于白名单的请求被允许,其他请求(包括 Referer为空的请求)会被拒绝
● Bucket 三种权限(private、public-read、public-read-write)都会检查 Referer 字段
自定义域名
CNAME,OSS支持用户将自定义的域名绑定到属于自己的Bucket上面,这个操作必须通过OSS控制台来配置。
按照中国互联网管理条例的要求,所有需要开通这项功能的用户,必须提供阿里云的备案号,域名持有者身份证等有效资料,经过阿里云审批通过才可以。
CNAM场景:
● 用户A拥有一个域名为 abc.com ,这个网站上所有的图片都存储在 abc.com 这个子域名下
● 为了应对日益增长的图片流量压力,用户A在OSS上创建了一个名为 img 的 bucket,并将图片存到 OSS 上
● 通过 OSS 控制台,提交 img.abc.com,CNAM成 abc-img.oss-cn-hangzhou.aliyuncs.com 的申请
● 审核通过后,在DNS上加一条:img.abc.com 映射到 abc-img.oss-cn-hangzhou.aliyuncs.com
日志记录
OSS为用户提供自动保存访问日志记录功能,Bucket 的拥有者可以通过 OSS 控制台的日志管理,为所拥有的 Bucket 开启访问日志记录功能,当一个Bucket开启日志记录的功能之后,OSS自动访问这个Bucket的请求日志,以小时为单位,按照固定的命名规则,生成一个Object写入用户指定的Bucket(目标Bucket,Target Bucket)。
存储访问日志记录的Object命名规则:
shell
<TargetPrefix><SourceBucket>-YYYY-mm-DD-HH-MM-SS-UniqueString命名规则中,TargetPrefix 由用户指定,YYYY mm DD HH MM SS分别是该Object创建时的阿拉伯数字的年、月、日、小时、分钟、秒,UniqueString是由OSS系统生成的,一个实际的用于存储的OSS访问日志的Object名称例子如下:
shell
MyLog-oss-example-2000-01-01-01-00-00-0000日志的格式为:

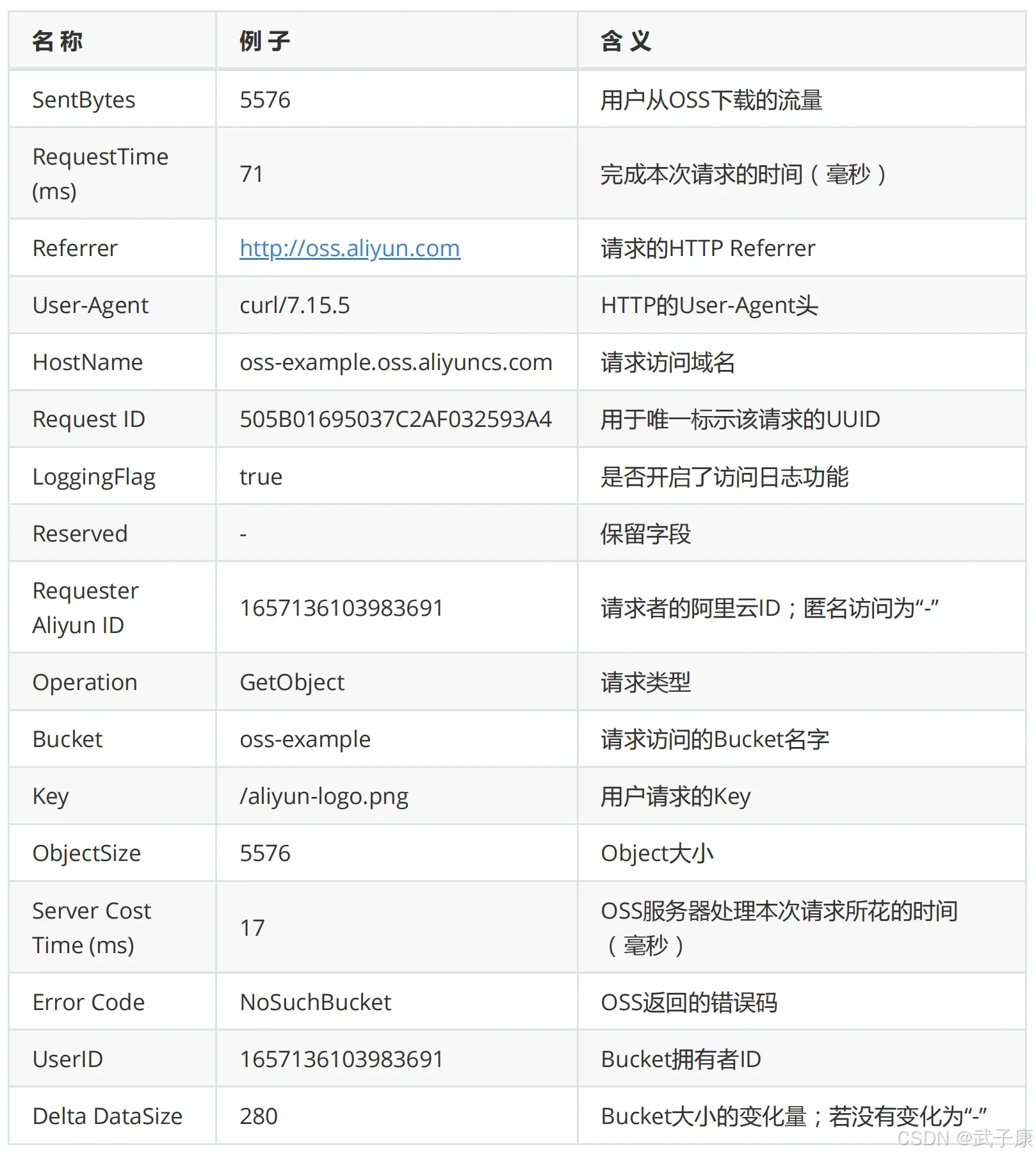
细节分析:
● 源 Bucket 和 目标 Bucket 必须属于同一个用户
● TargetPrefix 表示存储访问日志记录的 object 名字前缀,可以为空
● 源 Bucket 和 目标 Bucket 可以是同一个 Bucket,也可以是不同的 Bucket,用户可以将多个源 Bucket的LOG都保存在同一个目标 Bucket 内(建议指定不同的 TargetPrefix)。
● OSS 以小时为单位生成的 Bucket 访问的 Log 文件,但并不表示这个小时的所有请求都记录在这个小时的Log文件内,也有可能是出现在上一个或者下一个 Log文件中
● OSS 生成的 Log 文件命名规则中 UniqueString 仅仅是 OSS 为其生成的UUID,用于唯一标识该文件
● OSS 生成一个 Bucket 访问的 Log 文件,算作一次PUT操作,并记录其占用空间,但不会记录产生的流量,Log生成后,用户可以按照普通的Object来操作这些Log文件。
● OSS 会忽略所有以x-开头的query-string参数,但这个 query-string 会记录在访问 Log 中,如果你想从海量的访问日志中,标示一个特殊的请求,可以在 URL 中添加一个 x- 开头的 query string参数
shell
http://oss-example.oss.aliyuncs.com/aliyun-logo.png
http://oss-example.oss.aliyuncs.com/aliyun-logo.png?x-user=adminOSS 处理上面两个请求,结果是一样的,但是在访问Log中,你可以通过 x-user=admin,很方便的定位出经过标记的这个请求。
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 403 Forbidden(匿名外链访问被拒) | Referer 不在白名单/不允许空 Referer | 控制台权限→防盗链;浏览器开发者工具查看请求头 | 白名单补充域名/允许空 Referer(慎用)或改用签名 URL |
| 403 AccessDenied(无法读对象) | Bucket 为 private 且请求未签名 | 控制台 ACL;服务端日志 | 生成服务端签名 URL 或改为 public-read(仅公开资源) |
| 403 SignatureDoesNotMatch | 客户端时间漂移/签名串计算错误 | 抓包比对 Authorization、Date | NTP 对时;复核 Canonical 头与路径编码 |
| 301 Moved Permanently 或 404 Not Found | 使用了错误的 Endpoint/Region | 控制台查看 Bucket 所在 Region;curl 目标域名 | 切换到正确区域 Endpoint;修正 SDK 配置 |
| 409 BucketAlreadyExists | 名称全局唯一被占用 | 创建返回码与请求 ID | 更换全局唯一名称(加入项目前缀/后缀) |
| 400 InvalidObjectName | Key 以 / 或 \ 开头或超长/非法字符 | SDK/服务端返回码 | 规范 Key 命名(UTF-8,1--1023 字节,不以斜线开头) |
| 自定义域名 404/证书异常 | CNAME 未生效/未绑定/证书未配置 | nslookup dig CNAME;浏览器证书链检查 | 完成控制台绑定与证书部署;等待 DNS 生效后再切流 |
| 下行费用异常激增 | 盗链或热点资源无缓存 | 访问日志分析 UA/来源;Referer 统计 | 启用防盗链;前置 CDN 缓存;限速/限域名 |
| NoSuchBucket/NoSuchKey | 拼写错误/对象被覆盖或生命周期删除 | 列表与日志核对 | 更正 Key;调整生命周期规则与版本控制 |
| 访问偶发超时/抖动 | 客户端重试/连接池未配置或网络波动 | SDK 指标与连接数 | 合理超时重试与连接池;就近 Region 与多可用区策略 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南!
AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-180 Java 接入 FastDFS:自编译客户端与 Maven/Spring Boot 实战
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS正在更新... 深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接