一、解决的核心问题
Flamingo 旨在构建一个通用的多模态语言模型 ,解决传统视觉 - 语言模型在少样本学习 和跨任务适应性 上的局限性。传统模型通常需要针对特定任务(如图像描述、视觉问答)进行大量标注数据的微调,而 Flamingo 希望通过上下文学习 能力,仅通过少量示例即可快速适应新任务,无需重新训练模型。
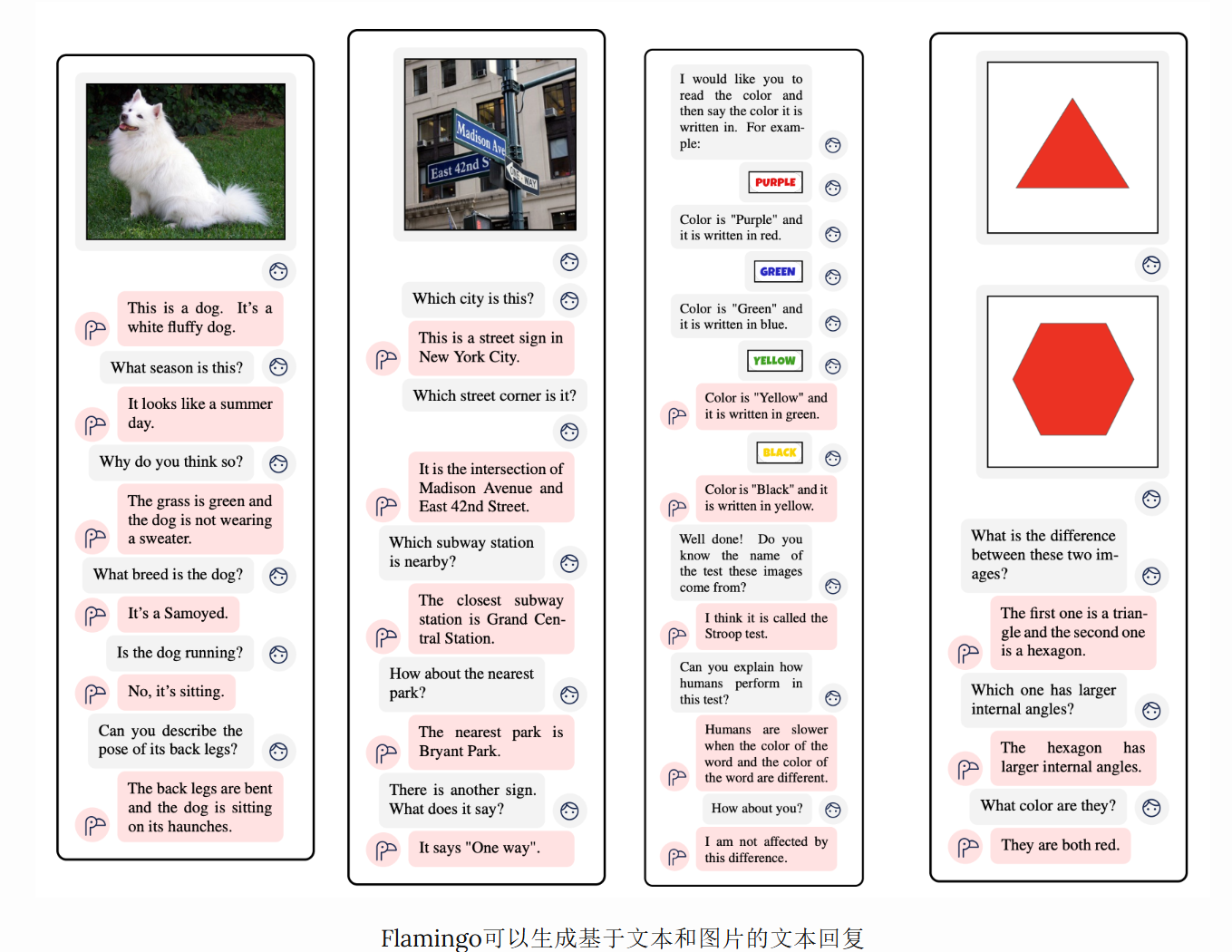
与CLIP不同,Flamingo可以生成文本回复。从简化的角度看,Flamingo是CLIP+一个语言模型,增加了技术,使语言模型能够根据视觉和文本输入生成文本符号。
二、核心架构:
- 视觉编码器:类似CLIP的模型通过对比学习进行训练。该模型的文本编码器随后被舍弃。视觉编码器被冻结,用于主模型。复用 CLIP 的视觉部分(如 ViT-L/14),其结构为 Vision Transformer,将图像分割为 14×14 的补丁(patch),通过自注意力计算得到图像的特征表示(维度通常为 768 或 1024)。
- 语言模型:用预训练的自回归语言模型,其结构为 Transformer 解码器。Flamingo 微调 Chinchilla 以生成基于复视觉和文本的文本符号,利用语言模型丢失,并增加了两个组件:感知重采样和 GATED XATTN-DENSE 图层。
- 感知器重采样器:将视觉编码器输出的高维特征压缩为固定长度的 "视觉token",适配语言模型的输入格式。解决视觉特征与文本序列长度不匹配的问题(例如,一张图像可能生成 256 个视觉特征,而语言模型通常处理可变长度的文本序列)。
- 门控跨注意力层:实现视觉令牌与文本特征的融合,是跨模态交互的核心。允许语言模型 "关注" 图像内容,同时控制视觉信息对文本生成的影响强度
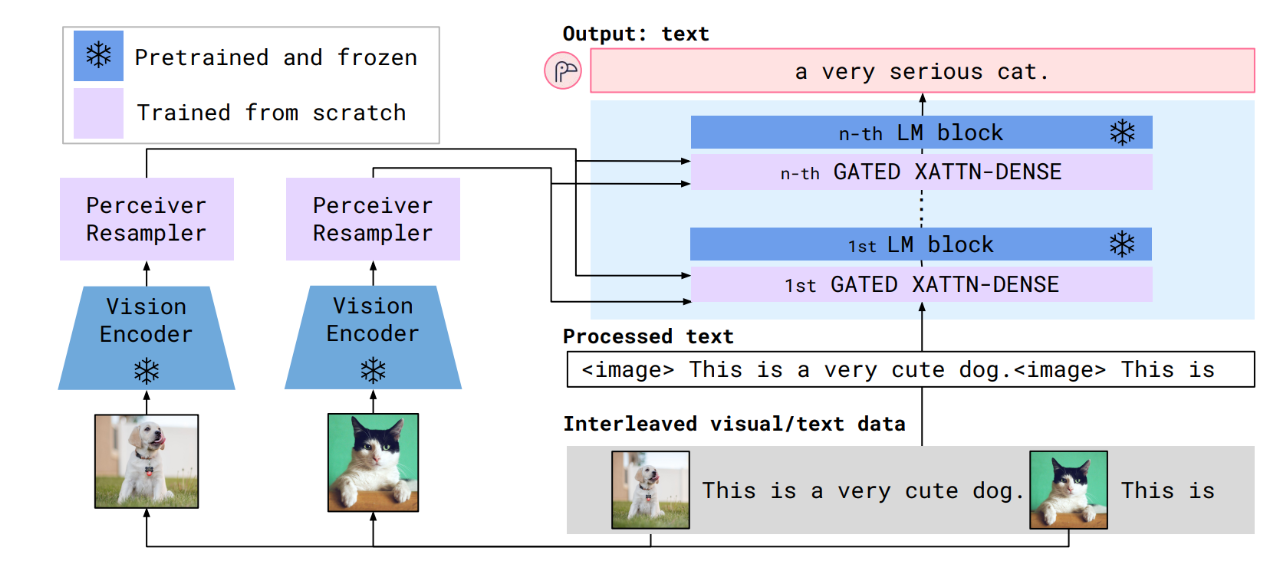
三、模型工作流:
1、输入处理
- 图像经视觉编码器转换为原始视觉特征。
- 原始视觉特征经 Perceiver Resampler 压缩为固定长度的视觉令牌。
- 文本输入(如 "<image> 这只动物有几条腿?Answer:")经语言模型的嵌入层转换为文本特征
2、跨模态融合
- 在语言模型的指定层(如每 4 层),通过 Gated Cross-Attention 层,文本特征 "关注" 视觉令牌,实现图文交互。
- 门控参数动态调整视觉信息的影响强度(例如,对图像相关问题增强视觉注意力,对纯文本问题减弱)
3、输出生成:融合后的特征经语言模型后续层处理,自回归生成答案文本
接下来进行实现:
本项目参考github项目:mlfoundations/open_flamingo:一个用于训练大型多模态模型的开源框架。
一、搭建环境
克隆该项目到本地,conda创建虚拟环境
conda env create -f environment.yml安装依赖:
pip install open-flamingo为了创建基于Flamingo的问答系统,还需要支持图片上传和实时问答,安装streamlit
pythonpip install streamlit
二、下载权重
下载预训练模型权重
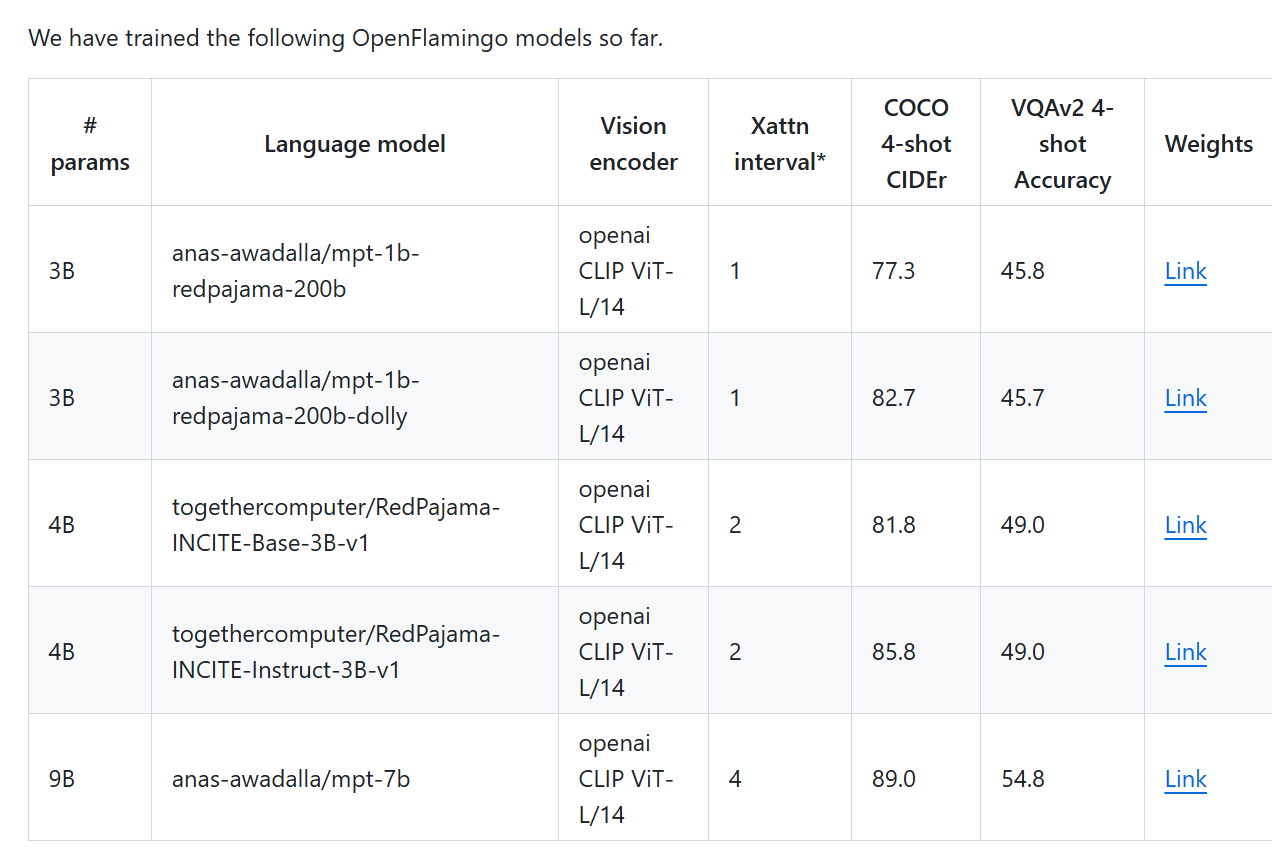
我这里选择4B Instruct-3B-V1
然后将预训练的视觉编码器和语言模型下载下来。默认下载到./cache路径下。
python
from open_flamingo import create_model_and_transforms
model, image_processor, tokenizer = create_model_and_transforms(
clip_vision_encoder_path="ViT-L-14",
clip_vision_encoder_pretrained="openai",
lang_encoder_path="anas-awadalla/mpt-1b-redpajama-200b",
tokenizer_path="anas-awadalla/mpt-1b-redpajama-200b",
cross_attn_every_n_layers=1,
cache_dir="PATH/TO/CACHE/DIR" # Defaults to ~/.cache
)
接下来是创建一个基于Streamlit的交互式视觉问答界面,支持图片上传和实时问答
python
import warnings
import os
from open_flamingo import create_model_and_transforms
from PIL import Image
import torch
import transformers
import open_clip
import streamlit as st
# 忽略所有警告
warnings.filterwarnings("ignore")
# 设置环境变量,禁用Hugging Face的远程检查
os.environ["HF_HUB_DISABLE_SYMLINKS_WARNING"] = "1"
os.environ["TRANSFORMERS_OFFLINE"] = "1" # 启用离线模式
os.environ["HF_DATASETS_OFFLINE"] = "1" # 启用数据集离线模式
# 初始化模型和转换
@st.cache_resource
def load_model():
st.write("正在加载模型...")
model, image_processor, tokenizer = create_model_and_transforms(
clip_vision_encoder_path="ViT-L-14",
clip_vision_encoder_pretrained="openai",
lang_encoder_path="./cache/models--togethercomputer--RedPajama-INCITE-Instruct-3B-v1/snapshots/0c66778ee09a036886741707733620b91057909a",
tokenizer_path="./cache/models--togethercomputer--RedPajama-INCITE-Instruct-3B-v1/snapshots/0c66778ee09a036886741707733620b91057909a",
cross_attn_every_n_layers=2,
use_local_files=True,
cache_dir="./cache"
)
# 加载预训练检查点
checkpoint_path = "./checkpoint.pt"
model.load_state_dict(torch.load(checkpoint_path), strict=False)
st.write("模型加载完成!")
return model, image_processor, tokenizer
# 主应用函数
def main():
# 设置页面配置
st.set_page_config(
page_title="OpenFlamingo 视觉问答",
page_icon="🤖",
layout="wide",
initial_sidebar_state="expanded"
)
# 添加自定义样式
st.markdown("""
<style>
.main {
background-color: #f0f2f6;
}
.sidebar {
background-color: #ffffff;
}
.chat-message {
padding: 1rem;
border-radius: 0.5rem;
margin-bottom: 1rem;
max-width: 80%;
}
.user-message {
background-color: #d4edda;
margin-left: auto;
border-bottom-right-radius: 0.1rem;
}
.bot-message {
background-color: #ffffff;
margin-right: auto;
border-bottom-left-radius: 0.1rem;
box-shadow: 0 2px 4px rgba(0,0,0,0.1);
}
.image-container {
margin: 1rem 0;
border-radius: 0.5rem;
overflow: hidden;
box-shadow: 0 2px 8px rgba(0,0,0,0.15);
}
.stButton button {
background-color: #007bff;
color: white;
border-radius: 20px;
padding: 0.5rem 1.5rem;
font-weight: bold;
}
.stButton button:hover {
background-color: #0056b3;
}
</style>
""", unsafe_allow_html=True)
# 加载模型
model, image_processor, tokenizer = load_model()
# 设置tokenizer
tokenizer.padding_side = "left"
# 侧边栏
st.sidebar.title("🤖 OpenFlamingo VQA")
st.sidebar.write("上传图片并提问,让模型回答关于图片的问题。")
# 图片上传
uploaded_file = st.sidebar.file_uploader("📁 上传图片", type=["jpg", "jpeg", "png"])
# 清除对话按钮
if st.sidebar.button("🗑️ 清除对话历史"):
if "messages" in st.session_state:
del st.session_state.messages
# 主聊天界面
st.title("OpenFlamingo 视觉问答系统")
st.write("上传图片后,输入问题即可获得模型的回答。")
# 初始化对话历史
if "messages" not in st.session_state:
st.session_state.messages = []
# 显示当前上传的图片
if uploaded_file is not None:
image = Image.open(uploaded_file).convert("RGB")
st.session_state.image = image
# 显示图片
st.markdown("<div class='image-container'>", unsafe_allow_html=True)
st.image(image, caption="已上传的图片", use_column_width=True)
st.markdown("</div>", unsafe_allow_html=True)
# 添加图片上传到对话历史
if not st.session_state.messages:
st.session_state.messages.append({
"role": "system",
"content": "用户已上传图片"
})
# 显示对话历史
for message in st.session_state.messages:
if message["role"] == "user":
st.markdown(f"<div class='chat-message user-message'><strong>你:</strong> {message['content']}</div>", unsafe_allow_html=True)
elif message["role"] == "assistant":
st.markdown(f"<div class='chat-message bot-message'><strong>OpenFlamingo:</strong> {message['content']}</div>", unsafe_allow_html=True)
# 问题输入
if uploaded_file is not None:
# 创建一个表单来处理用户输入,避免自动刷新
with st.form(key='question_form'):
user_input = st.text_input("输入你的问题:", placeholder="例如: 图片中有什么? 猫是什么颜色?")
submit_button = st.form_submit_button(label='发送')
if submit_button and user_input.strip():
# 保存用户问题
st.session_state.messages.append({
"role": "user",
"content": user_input
})
# 显示最新的用户问题
st.markdown(f"<div class='chat-message user-message'><strong>你:</strong> {user_input}</div>", unsafe_allow_html=True)
# 处理图片
image = st.session_state.image
vision_x = image_processor(image).unsqueeze(0) # 添加batch维度
vision_x = vision_x.unsqueeze(1).unsqueeze(0) # 调整形状
# 生成答案
with st.spinner("正在思考..."):
# 构建提示
prompt = f"<image>Question: {user_input} Answer:"
lang_x = tokenizer(
[prompt],
return_tensors="pt",
)
# 生成文本
generated_text = model.generate(
vision_x=vision_x,
lang_x=lang_x["input_ids"],
attention_mask=lang_x["attention_mask"],
max_new_tokens=50,
num_beams=3,
temperature=0.7,
)
# 解码结果
answer = tokenizer.decode(generated_text[0])
answer = answer.replace(prompt, "").strip()
answer = answer.replace("<|endofchunk|>", "").strip()
# 保存助手回答
st.session_state.messages.append({
"role": "assistant",
"content": answer
})
# 显示助手回答
st.markdown(f"<div class='chat-message bot-message'><strong>OpenFlamingo:</strong> {answer}</div>", unsafe_allow_html=True)
else:
st.info("请先在左侧上传一张图片。")
if __name__ == "__main__":
main()生成测试:


四、优点
Flamingo作为多模态语言模型框架,基于上下文学习设计,仅需少量示例即可快速适配新任务,无需大规模标注数据微调,大幅降低任务适配成本。通过特殊标记(如 <image> 表示图像、<|endofchunk|> 分隔模态片段),支持 "图像 - 文本 - 图像 - 文本" 等复杂输入格式,可处理多图推理、图文混合问答等场景。基于flamingo可以实现完成图像描述生成、视觉问答、图像分类、多图推理等多种多模态任务。
以上为全部内容!