论文链接:https://arxiv.org/abs/2311.12058
代码链接:https://github.com/Yzichen/FlashOCC
简介
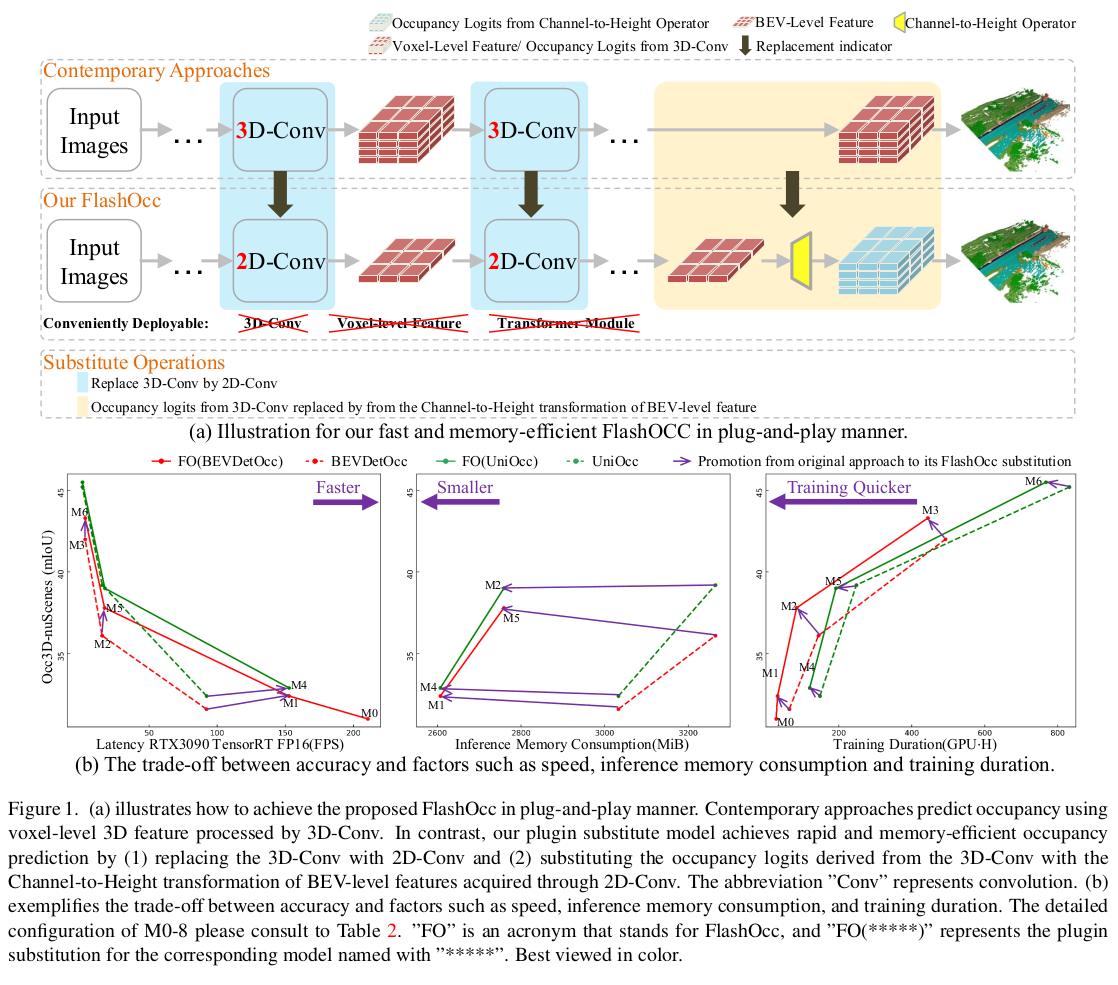
3D占用预测 在自动驾驶中很重要,能解决3D物体检测中的"长尾难题"(不常见物体)和复杂形状缺失问题。但现有方法通常使用三维体素(voxel) 表示,导致计算和内存开销巨大,难以在实际芯片上高效部署。作者认为,理想的框架应在保持高精度的同时,兼顾计算效率和内存友好,便于在不同芯片上部署。为此提出 FlashOCC,它是一种即插即用的范式,基于现有体素级占用预测方法做了两点改进:
- 特征保持在 BEV 中,使用高效的 2D 卷积进行特征提取,避免复杂的 3D 计算。
- 引入"通道到高度"的变换,将BEV中提取的特征(输出 logits)通过变换"提升"到3D空间,生成最终的3D占用预测结果,避免直接处理3D体素的高成本。
实验证明,在 Occ3D-nuScenes 基准测试中,将FlashOCC应用于多种占用预测基线模型。在精度、运行效率和内存成本上均优于之前的先进方法,展示了其实用部署潜力。
自动驾驶汽车需要感知周围环境,其中基于摄像头图像来检测3D物体是一种重要且受欢迎的技术路线(因为它比依赖激光雷达的方案成本更低)。然而,这种主流的3D物体检测任务有一个根本局限:它只能识别和框出那些预先定义好类别的物体(比如"汽车"、"行人"、"自行车")。正是由于这个根本局限,在实际应用中就引出了两个大问题:
- 长尾缺陷:现实中会遇到无数种物体,但模型只认识训练时教过的那几类。那些不常见、没被预先定义和标注过的物体(比如翻倒的手推车、掉落的轮胎、奇怪的障碍物),模型就"看不见"或识别不出来。
- 复杂形状缺失:3D检测通常用简单的"3D框"(立方体)来表示物体。但对于形状不规则、复杂多变的物体(比如一辆开敞着车门的货车、一棵枝杈横生的树、一个形状古怪的施工机械),一个方方正正的框根本无法准确描述它的实际轮廓和占据的空间。框内很多地方其实是空的,框外又可能碰到了物体。这种不精细的表示无法满足自动驾驶对精确安全空间的需求。
最近,占用网格预测通过预测 3D 空间中每个体素的语义类别,是不错的解决方案。它不再只是预测物体框,而是预测3D空间中每个体素(voxel,可以理解为3D像素)的语义类别(比如是"汽车"、"路面"还是"建筑物"的一部分)。即使一个物体不在预定义类别中(如"翻倒的摩托车"),占用预测也能感知到它占据的空间,并将其标记为"通用物体"或"未知障碍物",而不会被忽略。这大大增强了系统对未知和罕见物体的感知能力。因为是体素级的预测,所以可以描绘出任何形状的物体轮廓,无论它多么不规则(如树枝、异形车辆),实现了对场景更精细的像素级(体素级)表征。
但是占用预测的瓶颈在于 3D 体素表示的计算代价。要构建3D场景,传统方法是体素化,将空间划分为无数小立方体(体素),并为每个体素计算特征。问题在于,直接在密集的3D体素网格上进行操作(如使用3D卷积、3D Transformer等),会带来极其庞大的计算量和内存消耗。这使其难以在自动驾驶芯片上高效部署,对算力要求极高。为了缓解问题,研究者提出了如稀疏体素表征(只计算可能有物体的体素)和三视图表征(用三个2D平面来近似表示3D空间)等方法,以节省内存。然而,作者认为这些方法"并未从根本上解决部署和计算上的挑战"。
本文方法的灵感来源于亚像素卷积技术。在图像超分辨率中,该技术不是用计算量大的上采样操作,而是通过巧妙地重新排列特征图的通道,来实现从低分辨率到高分辨率的空间变换。这本质上是一种"通道到空间"的特征变换。本文提出了"通道到高度"变换,将2D BEV特征图中的一个像素点,其通道维度的数值,重新解释和排列为对应空间柱体在高度维度上的体素预测值。因为目前的 BEV 感知技术已经能保证:BEV特征图上的一个像素,已经融合了其对应地面柱体(从地面到天空)中所有物体在高度方向的信息。因此,将通道维度"展开"为高度维度是合理且高效的。想象BEV特征图是一张2D地图,每个点有256个通道(数字)。我们需要为这个点对应的3D柱子(比如高16个网格)预测占用情况,这需要16个值(每个高度一个值)。"通道到高度"变换 就是将这256个通道中的前16个,直接"分配"给这个柱子的16个高度层,作为其占用预测的初始值(logits)。这样,无需任何3D计算,就瞬间从2D BEV特征生成了3D体素预测。本文的目标是以通用、即插即用的方式增强现有模型,而不是从头设计新架构。具体操作就两步:
- 第一步: 将现有占用预测模型中的3D卷积全部替换为2D卷积(在BEV平面上操作)。
- 第二步: 将原来由3D卷积输出3D占用预测值的方式,替换为:对2D卷积得到的BEV特征,直接应用"通道到高度"变换,来生成3D占用预测值。
这样改造后的模型,在精度和推理速度之间取得了最佳平衡。由于主干计算全是高效的2D卷积,最后只是一个张量变形操作,因此模型兼容性极好,易于在各种边缘计算芯片上部署。
相关工作
基于体素的占用预测
3D占用预测最早可追溯到占用栅格地图,其目标是从图像中提取详细的3D场景结构信息,以辅助下游的路径规划和导航任务。根据所使用的监督信号类型,现有研究可以分为两类:
- 稀疏感知:使用激光雷达点进行直接监督,并在激光雷达数据集上评估,点云是稀疏的,所以监督信号也是稀疏的。
- 稠密感知:与语义场景补全任务相似,旨在预测每个体素的语义标签,通常需要密集的3D体素标注。
- VoxFormer: 利用2.5D信息(如深度)生成候选查询,再通过插值获取所有体素特征。
- Occ3D:设计了一个由粗到细的体素编码器来构建占用表示。
- RenderOcc:通过2D到3D网络从环视图像提取3D体积特征,并借助NeRF(神经辐射场)的监督方式来预测每个体素的密度和语义标签。
上述所有方法都有一个共同点------采用体素化的表示方法,即用一个个带特征向量的体素网格来描述3D空间。因为这种细粒度的体素级表征天生就非常适合完成3D语义占用预测这个精细的任务。然而,正是这种基于体素的表示方法,带来了巨大的计算复杂度和部署挑战。这促使研究者(包括本文作者)去寻求更高效的替代方案。
基于 BEV 的 3D 场景感知
BEV方法用一个特征向量来表示BEV网格中整个柱子(从地面到天空的整个垂直柱体) 的信息。优势如下:
- 计算更高效: 它压缩(减少)了高度维度的特征表示。体素方法在高度方向上有多个网格(多个向量),而BEV方法一个柱子只有一个向量,数据量大幅减少。
- 部署更友好: 因此,它可以完全使用高效的2D卷积在BEV平面上处理特征,避免了耗时的3D卷积,使得模型更容易在车载芯片上部署。
虽然目前还没有方法直接基于BEV级特征来做占用预测(现有占用预测方法多用体素),但研究发现,BEV特征能够"隐式地"捕获高度信息。这种能力已经在不平路面(不同高度)和悬空物体(如交通灯、桥梁)的检测场景中得到了验证。这意味着BEV特征虽然被"压扁"成一个向量,但它内部其实编码了其对应柱体内不同高度的物体分布信息。这一发现促使我们思考:能否利用这种本身就蕴含高度信息的、高效的BEV特征,来实现高效的占用预测? 这正是FlashOCC整个工作的起点。
高效的亚像素范式
本文的思想根源是亚像素卷积。它最早用于图像超分辨率,能将低分辨率图像高效地"放大"到高分辨率空间。相比传统的反卷积(转置卷积) 层,它能以极低的额外计算成本实现分辨率的提升。它的秘诀在于通过通道重排来实现空间上采样,而不是用计算密集的卷积。同样的思想(通道/特征重排以实现高效上采样)已经被应用在了BEV分割任务中。在文献 17中,他们将一个 8 × 8 8\times 8 8×8 的BEV网格块的分割表示压缩到一个"分割查询"向量中。这样,他们只需要使用 625 625 625 个这样的查询向量,就能通过重排等操作,预测出最终 200 × 200 200\times 200 200×200 分辨率的BEV分割图。这是一种用低分辨率紧凑特征生成高分辨率输出的高效方法。基于上述方法的启发,作者提出了 Channel-to-Height(通道到高度)变换,作为实现占用预测的高效方法。占用预测的初始分数(logits)是直接通过对"压平"的BEV级特征进行"通道到高度"的变形(reshape)而得到的。这本质上是一种特征重排,将通道维度的信息重新解释为高度维度的体素预测。本文是首个将亚像素范式应用于占用预测任务的研究,并且具有两个鲜明的独创性:
- 完全依赖于BEV特征作为输入和计算基础。
- 彻底摒弃3D卷积: 完全避免了计算量巨大的3D卷积操作。
方法
FlashOcc 是一项开创性贡献,它首次成功实现了实时、高精度的环视3D占用预测。具有两大优势:
- 高精度实时性:在保持卓越精度的同时,达到了实时速度。
- 部署普适性强: 由于其避免了昂贵的体素级特征处理(具体指避免了复杂的视图变换器和3D(可变形)卷积算子),计算负担大大减轻,因此能够轻松适配各种不同的车载计算平台,部署 versatility 极强。
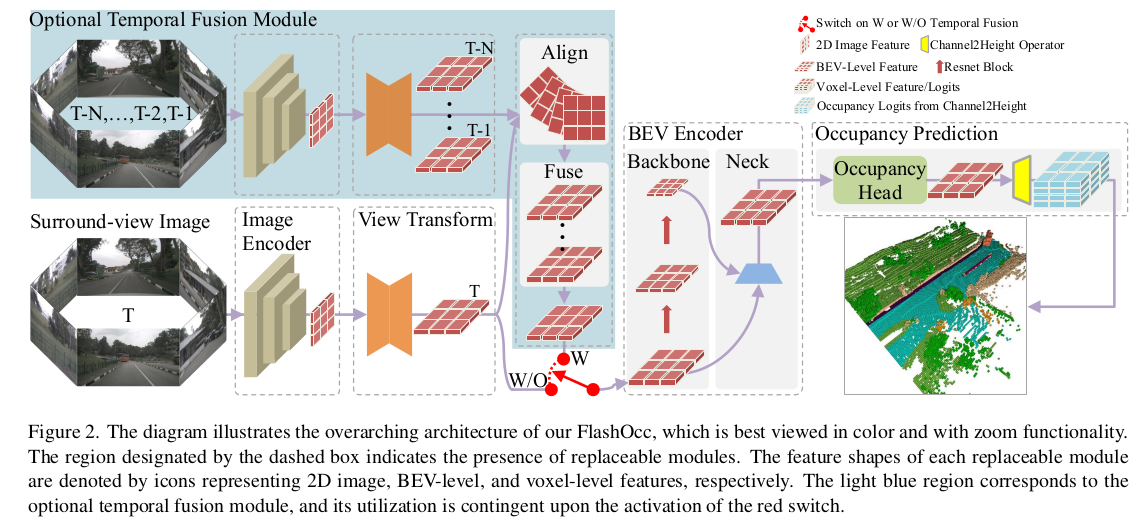
它的输入是环视相机画面,输出的是密集的 3D 占用预测结果,每个体素是否有物体、是什么物体。尽管FlashOCC的核心思想是以即插即用的方式增强现有模型,但其整体流程可以分解为五个基本模块,这有助于理解其工作流。
- 图像编码器,从多个摄像头的2D图像中提取特征。
- 视图变换模块:将来自不同视角的2D图像特征,统一转换到3D鸟瞰图空间,形成BEV表示。
- BEV 编码器:在BEV空间中进一步处理和融合特征。传统方法在这里会使用3D卷积,而FlashOCC则使用高效的2D卷积,在BEV平面上进行所有计算。
- 占用预测模块:预测每个体素的语义标签(即是否被占用,以及属于哪一类)。这里的输入不再是3D体素特征,而是来自BEV编码器的2D BEV特征。通过"通道到高度"变换,直接将BEV特征变形为3D体素预测结果。
- 时序融合模块:整合历史帧信息,以提升感知的稳定性和准确性(例如,应对遮挡、判断物体运动状态)。这是一个增强模块,并非必需,但加入后能进一步提升性能。
图像编码器
图像编码器的作用是从输入的多摄像头图片中提取高层次的特征。它是一个可灵活替换的标准视觉特征提取模块,通常由"骨干网络 + 颈部网络"两部分组成。输入是多视角的原始图像,输出是富含语义信息的高层级图像特征,给后续模块使用。
-
主干网络,是特征提取的核心,负责从图像中初步提取多尺度特征。
- ResNet: 采用残差块设计,能有效缓解深层网络训练中的梯度消失问题。能优雅地获取丰富且多粒度的语义特征表示,是经过充分验证的经典选择。
- Swin Transformer: 一种分层级的视觉Transformer。它将图像分割成小块进行处理,并引入移位窗口机制。在保持优异性能的同时,实现了更高的计算效率和可扩展性,是当前先进的视觉骨干网络。
-
Neck 网络:负责融合骨干网络提取出的多尺度特征。
- FPN-LSS:将细粒度的特征(来自浅层,分辨率高,细节多)与上采样后的粗粒度特征(来自深层,分辨率低,语义信息强)进行融合。确保最终的特征图既包含丰富的细节,又包含高级的语义信息,这对于精准的3D感知至关重要。
视图转换器
视图变换器是3D环视感知系统的关键组件,负责将来自不同摄像头的2D透视视图特征,统一转换到鸟瞰图空间,形成 BEV 表示。文中重点介绍了两种主流方法,并分析了它们的权衡。
- 输入是图像编码器输出的多相机的 2D 图像特征,
- 输出是统一的 3D BEV 表示,这是一个俯视的2D特征图,其中每个点编码了其对应地面柱体的信息。
- 目前主流方法有 LSS,它是一种基于显式深度估计的方法,理论上更符合几何原理,能产生更准确的特征对齐。其工作原理如下:
- Lift(提升): 对图像中的每个像素预测一个密集的深度分布(即这个像素可能处于哪些深度)。
- Splat(溅射): 结合相机内参和外参,将这些带有深度概率的图像特征"投射"到一个预定义的3D体素网格中。这样,3D空间中的每个体素都可能收到来自多个像素、多个相机的特征。
- Shot: 沿垂直方向(高度维度) 对每个地面柱体内的体素特征进行池化(如求和或求平均),将其"压扁"成一个特征向量,从而形成最终的2D BEV特征图。
- 另一主流方法是 LiDAR Structure。
- 它依赖于深度均匀分布的假设来转移特征。简单来说,它可能采用一种更简化的投影模型(如逆透视映射IPM的变体),不显式预测每个像素的深度,而是假设物体在柱体内深度分布均匀,或者使用一种固定的深度先验来将特征"推"到BEV空间。
- 优点:计算复杂度较低,因为避免了耗时的逐像素深度预测和复杂的3D特征聚合。
- 缺点: 由于深度假设过于简化,会导致特征在3D空间中对齐不准确(特征错位)。这进而会引发沿相机射线方向的误检测(例如,将远处物体错误地放置在近处,或者反之)。
BEV 编码器
BEV编码器的作用是对视图变换模块生成的、相对粗糙的BEV特征进行"精修",通过一个类似图像编码器的结构(骨干+颈部),增强其特征表示能力,从而得到更精细、更适合后续3D预测的BEV特征。BEV编码器的一个重要任务是修复或缓解视图变换模块引入的"瑕疵":
- 针对LSS的问题(中心特征缺失):
- 问题: LSS方法在将图像特征"溅射"到BEV网格时,可能导致某些BEV位置(特别是远离各个相机中心的区域)接收到的特征很少或很弱,即"中心特征缺失"。
- 解决: 通过在骨干网络中引入特征扩散操作(例如使用扩张卷积、可变形卷积或自注意力机制),使BEV特征能够在空间上更好地传播和交互,从而弥补这些缺失区域的特征。
- 针对LS的问题(混叠伪影):
- 问题: LS方法基于简化的深度假设,在特征投影时容易因几何不匹配而产生混叠伪影(表现为特征模糊、重影或错位)。
- 解决: 同样通过特征扩散和融合,利用BEV编码器的感受野和上下文理解能力,来平滑和纠正这些伪影,学习到更鲁棒的特征表示。
BEV编码器的颈部网络会整合两个(或多个)不同尺度的BEV特征。这通常是:
- 深层特征: 分辨率低,语义信息强,感受野大。
- 浅层特征: 分辨率高,几何细节丰富,但语义信息弱。
通过融合它们,最终输出的BEV特征既"看得清"细节,又"懂"高级语义,从而全面提升表征质量。
占用预测模块
如上图,经过BEV编码器增强的BEV特征,首先通过一个占用预测头进一步优化特征,然后通过通道到高度模块,执行一个简单的变形操作,直接将2D BEV特征"重塑"为3D占用预测分数。
- 占用预测头
输入是来自BEV编码器颈部的、高质量的BEV特征。输出的是优化后的,最终的 BEV 特征。这个特征已经"知道"了场景中哪里可能有物体,以及它们的语义信息,但信息仍然被"压缩"在2D平面上。
这是一个专门为占用预测任务设计的网络头,其目的是在2D BEV平面上,进一步优化和准备特征,使其更适合被转换为3D预测。有两种常见的设计:
- 多层卷积网络: 由几个标准的2D卷积层堆叠而成,结构简单。
- 复杂的多尺度特征融合模块: 结构更复杂(如FPN、U-Net结构),能提供更大的全局感受野(更好地理解整个场景的上下文关系)和更精细的局部特征刻画(更好地捕捉细节)。
- 通道到高度模块
这是从2D到3D的"魔法"发生的地方。对上述BEV特征执行一个极其简单的 reshape(变形/重塑)操作,沿通道维度进行。将形状为 B × C × W × H B\times C\times W\times H B×C×W×H 的 BEV 特征变换为占用 logits,形状为 B × C ∗ × Z × W × H B\times C^\ast \times Z \times W\times H B×C∗×Z×W×H,其中 B , C , C ∗ , W , H , Z B, C, C^\ast, W, H, Z B,C,C∗,W,H,Z 分别表示 batch size、通道数、类别数、3D空间的 x / y / z x/y/z x/y/z 维度个数, C = C ∗ × Z C=C^\ast \times Z C=C∗×Z。
时域融合模块
时序融合模块通过整合过去若干帧的BEV特征信息,为当前帧的感知提供时序上下文。这有助于系统更好地理解物体的运动状态(如速度、方向),并提升在遮挡、模糊等复杂情况下的感知准确性、稳定性和可靠性。主要包括两个组件:
- 时空对齐模块
这是时序融合的基础和前提。
- 问题: 自动驾驶车辆自身在运动。上一帧感知到的BEV特征所在的坐标系(以车为中心),与当前帧的坐标系已经不重合了。直接融合会错位。
- 功能: 该模块利用自车运动信息(如来自IMU、轮速计的姿态、位置变化),将历史的BEV特征"搬移"到当前时刻的坐标系下。
- 关键技术:
- 坐标变换: 根据车辆的运动,计算历史特征到当前坐标系的变换矩阵。
- 特征重采样/插值: 变换后,历史特征的网格可能与当前帧不完全对齐,需要通过双线性插值等方法进行重采样,确保特征在空间上对齐。
- 目的: 确保所有要融合的特征都在同一个空间参考系(当前帧的BEV坐标系)下,为后续融合扫清几何障碍。
- 特征融合模块
这是时序融合的核心,负责智能地整合对齐后的多帧信息。
- 输入: 对齐到当前坐标系下的多帧历史BEV特征,以及当前帧的BEV特征。
- 功能: 该模块学习如何将跨越时间的特征结合起来,重点关注动态物体或属性(如移动的车辆、行人,变化的信号灯)。
- 融合方式(常见于文献):
- 递归融合: 如使用3D卷积、ConvLSTM或Transformer,沿时间维度建模序列依赖。
- 注意力机制: 让当前帧的特征"注意"历史帧中相关位置的信息,例如通过时空注意力。
- 输出: 一个融合了时序上下文的、增强版的当前BEV特征。这个特征不仅包含当前时刻的观测,还隐含了物体"从哪里来、可能到哪里去"的信息。