TL;DR
- 场景:业务既有精确匹配(价格、ID、时间),又有容错需求(前缀、模糊、错别字)。
- 结论:用 term-level queries 处理结构化精确条件,再用 bool 组合 must/filter/should/must_not。
- 产出:给出从建索引、写入数据到 term/terms/range/exists/prefix/regexp/fuzzy/ids/bool 全流程 DSL 示例。

版本矩阵
| 项目 | 说明 |
|---|---|
| Elasticsearch 7.x | 按文中 DSL 在 7.x 环境完成验证,索引创建与 term-level queries 可直接复用。 |
| Elasticsearch 8.x | 查询 DSL 语法保持兼容,注意结合实际集群的 default mappings 与日期格式配置。 |
| IK 分词插件(7.x/8.x) | 示例依赖 ik_max_word 分词器,需在集群中预先安装并在 settings 中启用。 |
| Dev Tools / Kibana 控制台 | 所有示例基于 Dev Tools 控制台执行,适合本地或测试环境快速跟跑与调试。 |
 可以使用term-level queries根据结构化数据中的精确值查找文档。结构化数据的值包括日期范围、IP地址、价格或者产品ID。 与全文查询不同,term-level queries不分析搜索词。相反,词条与存储在字段级别中的术语完全匹配。
可以使用term-level queries根据结构化数据中的精确值查找文档。结构化数据的值包括日期范围、IP地址、价格或者产品ID。 与全文查询不同,term-level queries不分析搜索词。相反,词条与存储在字段级别中的术语完全匹配。
初始索引
新建一个book一个索引:
json
# 新建book索引
PUT /book
{
"settings": {},
"mappings" : {
"properties" : {
"description" : {
"type" : "text",
"analyzer" : "ik_max_word"
},
"name" : {
"type" : "text",
"analyzer" : "ik_max_word"
},
"price" : {
"type" : "float"
},
"timestamp" : {
"type" : "date",
"format" : "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}执行的结果如下图所示: 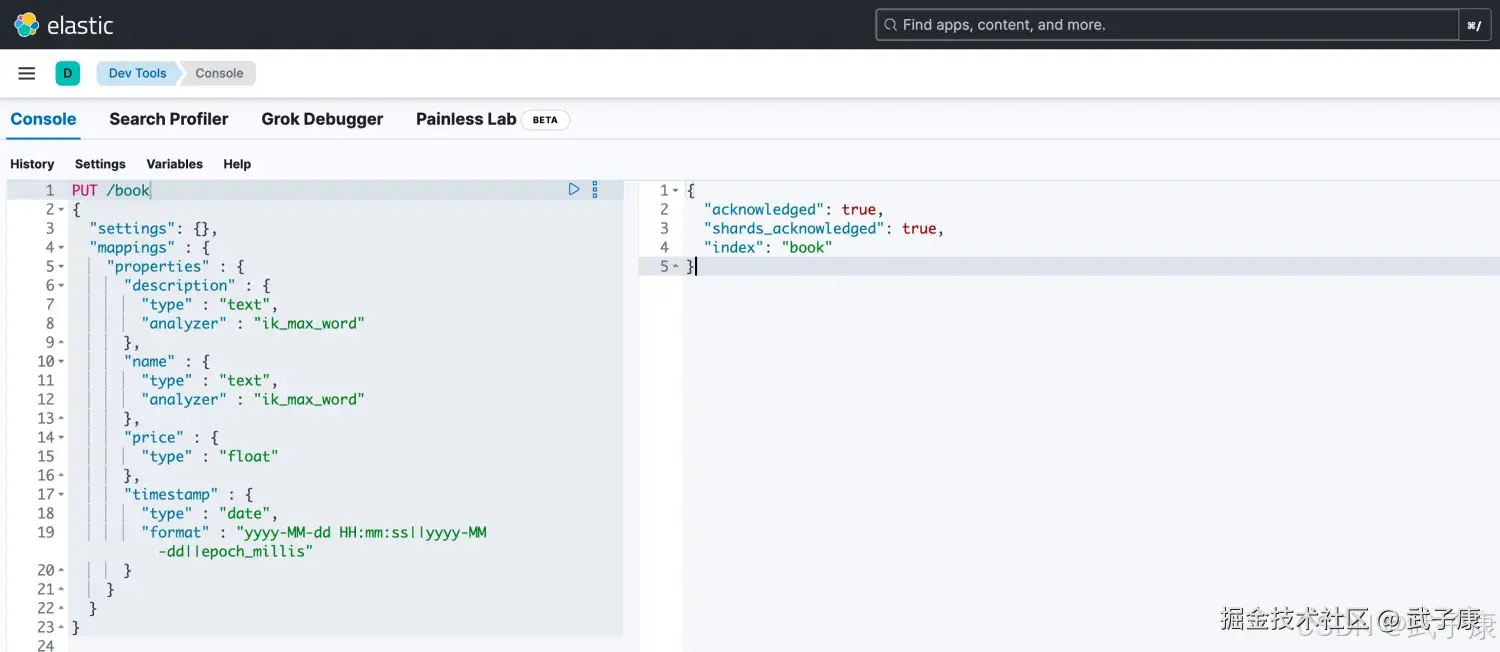
写入数据
生成几条数据用作我们后续的测试:
json
# 新增数据1
PUT /book/_doc/1
{
"name": "lucene",
"description": "Lucene Core is a Java library providing powerful indexing and search features, as well as spellchecking, hit highlighting and advanced analysis/tokenization capabilities. The PyLucene sub project provides Python bindings for Lucene Core. ",
"price":100.45,
"timestamp":"2020-08-21 19:11:35"
}
# 新增数据2
PUT /book/_doc/2
{
"name": "solr",
"description": "Solr is highly scalable, providing fully fault tolerant distributed indexing, search and analytics. It exposes Lucenes features through easy to use JSON/HTTP interfaces or native clients for Java and other languages.",
"price":320.45,
"timestamp":"2020-07-21 17:11:35"
}
# 新增数据3
PUT /book/_doc/3
{
"name": "Hadoop",
"description": "The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.",
"price":620.45,
"timestamp":"2020-08-22 19:18:35"
}
# 新增数据4
PUT /book/_doc/4
{
"name": "ElasticSearch",
"description": "Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。",
"price":999.99,
"timestamp":"2020-08-15 10:11:35"
}执行的结果如下图所示: 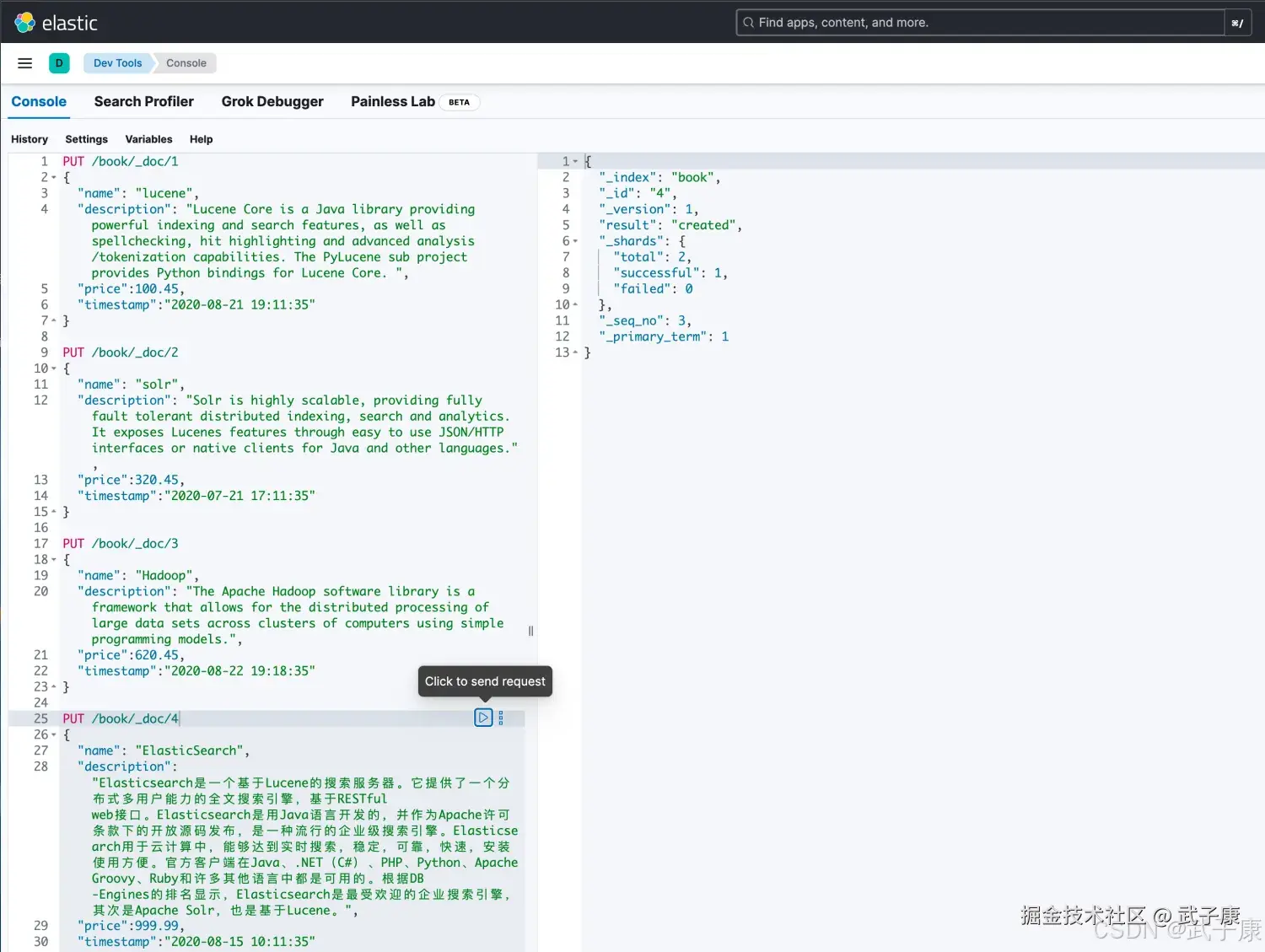
词条搜索(term query)
term查询用于查询指定字段包含某个词项的文档
json
# term是精确检索 多一个少一个都不行
POST /book/_search
{
"query": {
"term" : {
"name" : "solr"
}
}
}执行的结果如下图所示: 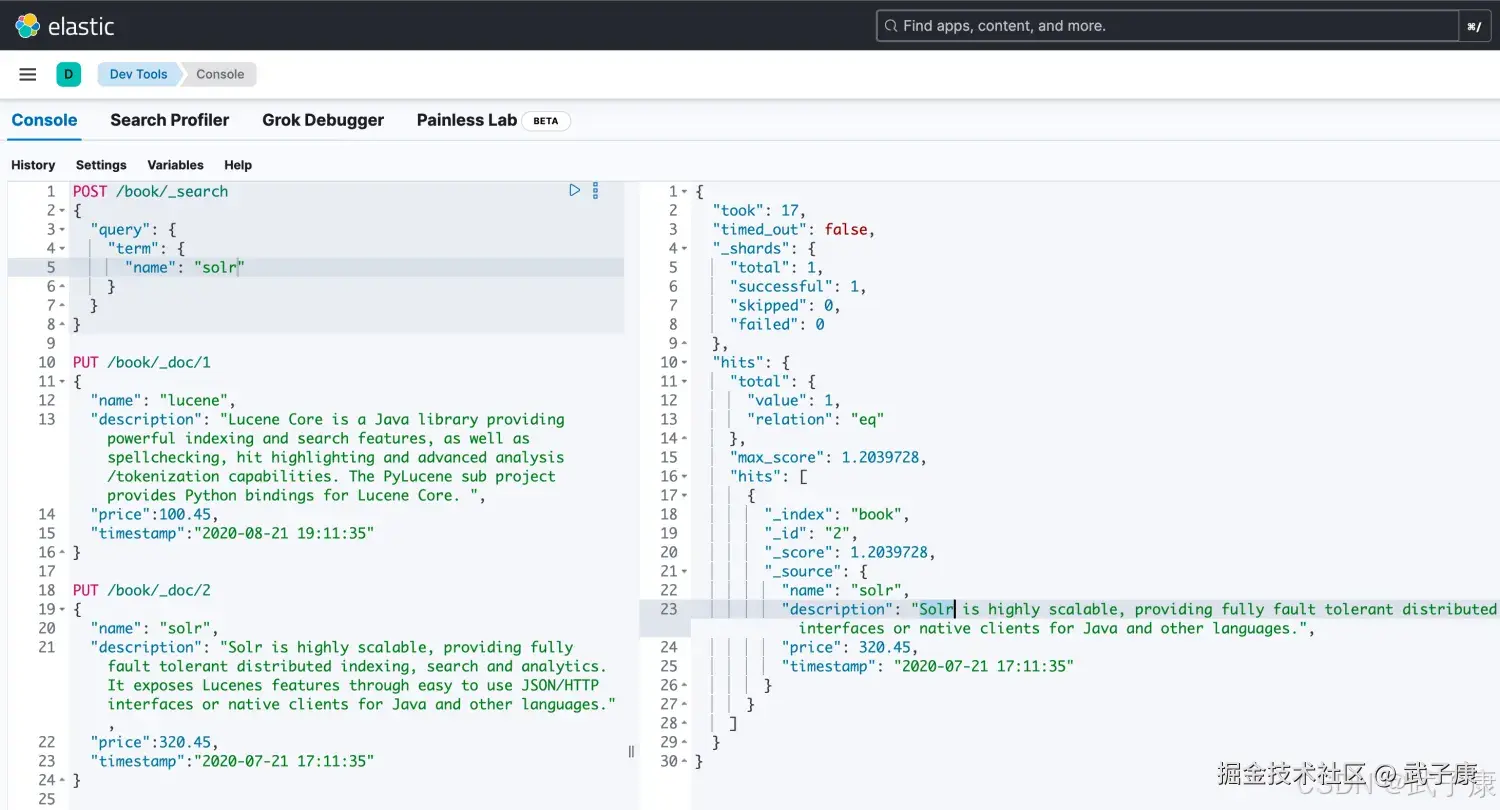
词条集合搜索(terms query)
terms 查询用于查询指定字段包含某些词项的文档
json
# 要有检索内容的name中有solr、elasticsearch,多个条件
POST /book/_search
{
"query": {
"terms" : {
"name" : ["solr", "elasticsearch"]
}
}
}执行的结果如下图所示: 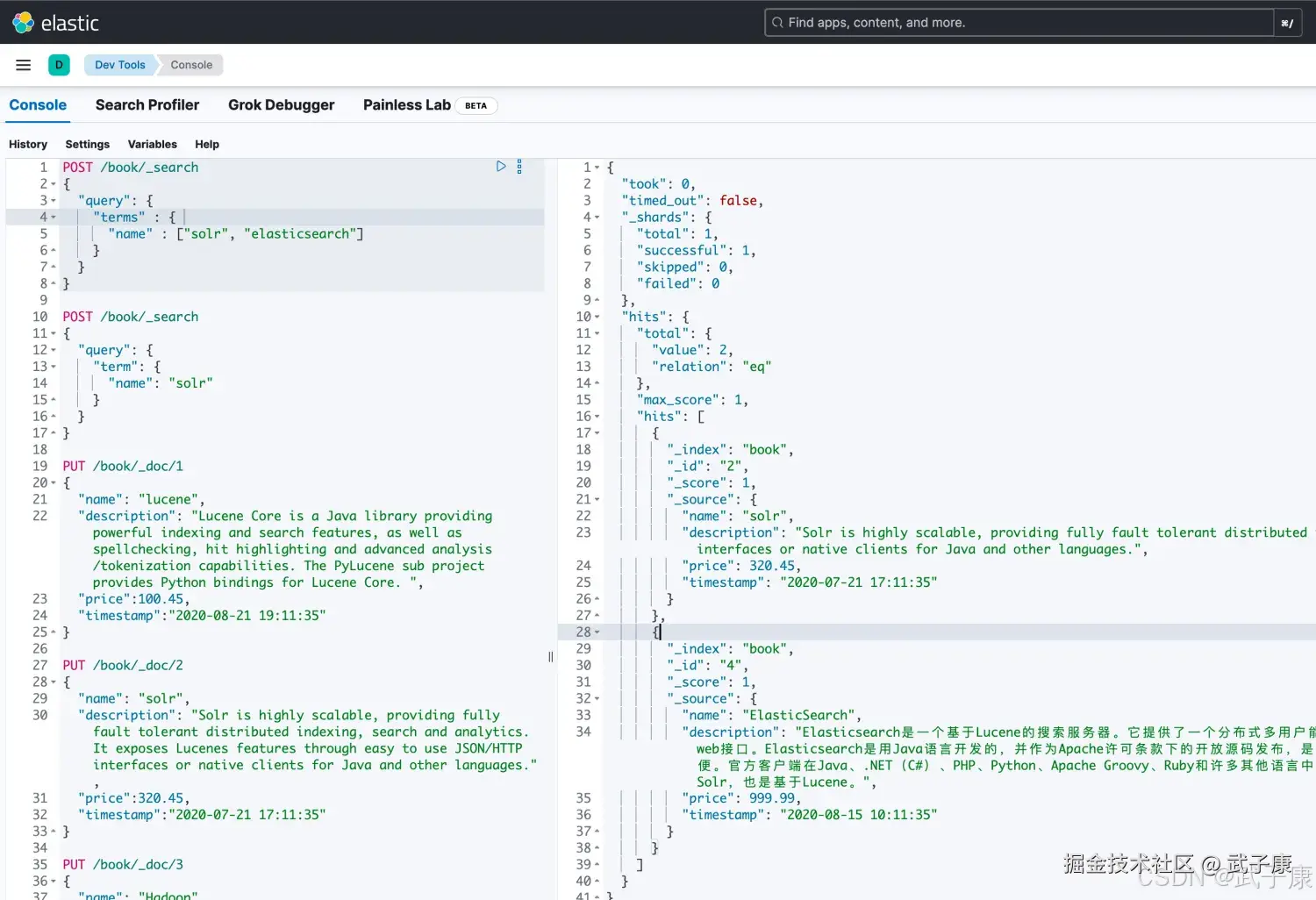
范围搜索(range query)
- gte 大于等于
- gt 大于
- lte 小于等于
- lt 小于
- boost 查询权重 在多条件查询时,可以手动控制每个条件的比重
json
# 范围检索 可以加权
POST /book/_search
{
"query": {
"range" : {
"price" : {
"gte" : 10,
"lte" : 200,
"boost" : 2.0
}
}
}
}执行结果如下图所示: 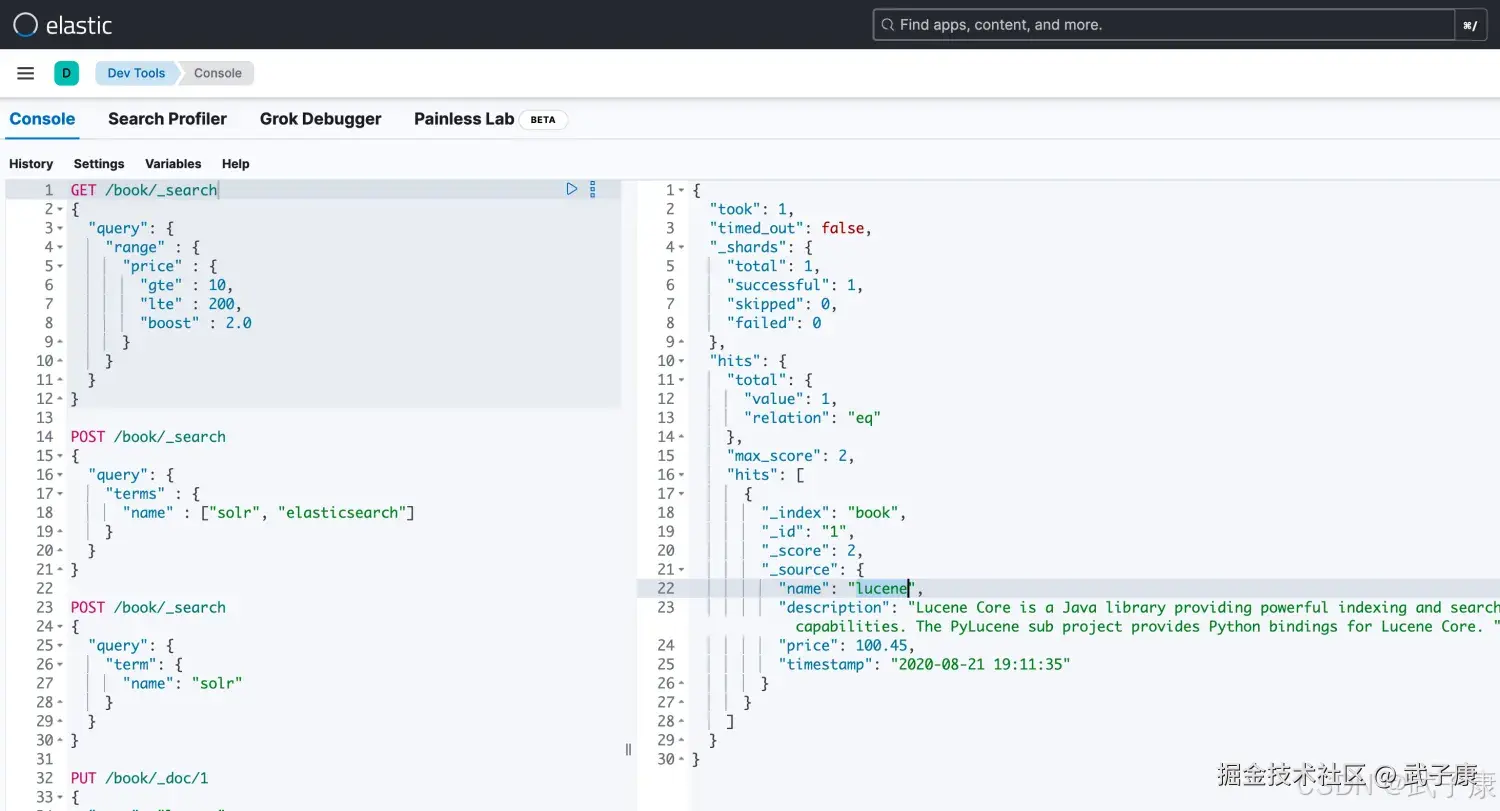 继续执行:
继续执行:
json
# 范围检索 也可以指定格式
POST /book/_search
{
"query": {
"range" : {
"timestamp" : {
"gte": "18/08/2020",
"lte": "2021",
"format": "dd/MM/yyyy||yyyy"
}
}
}
}执行结果如下图所示: 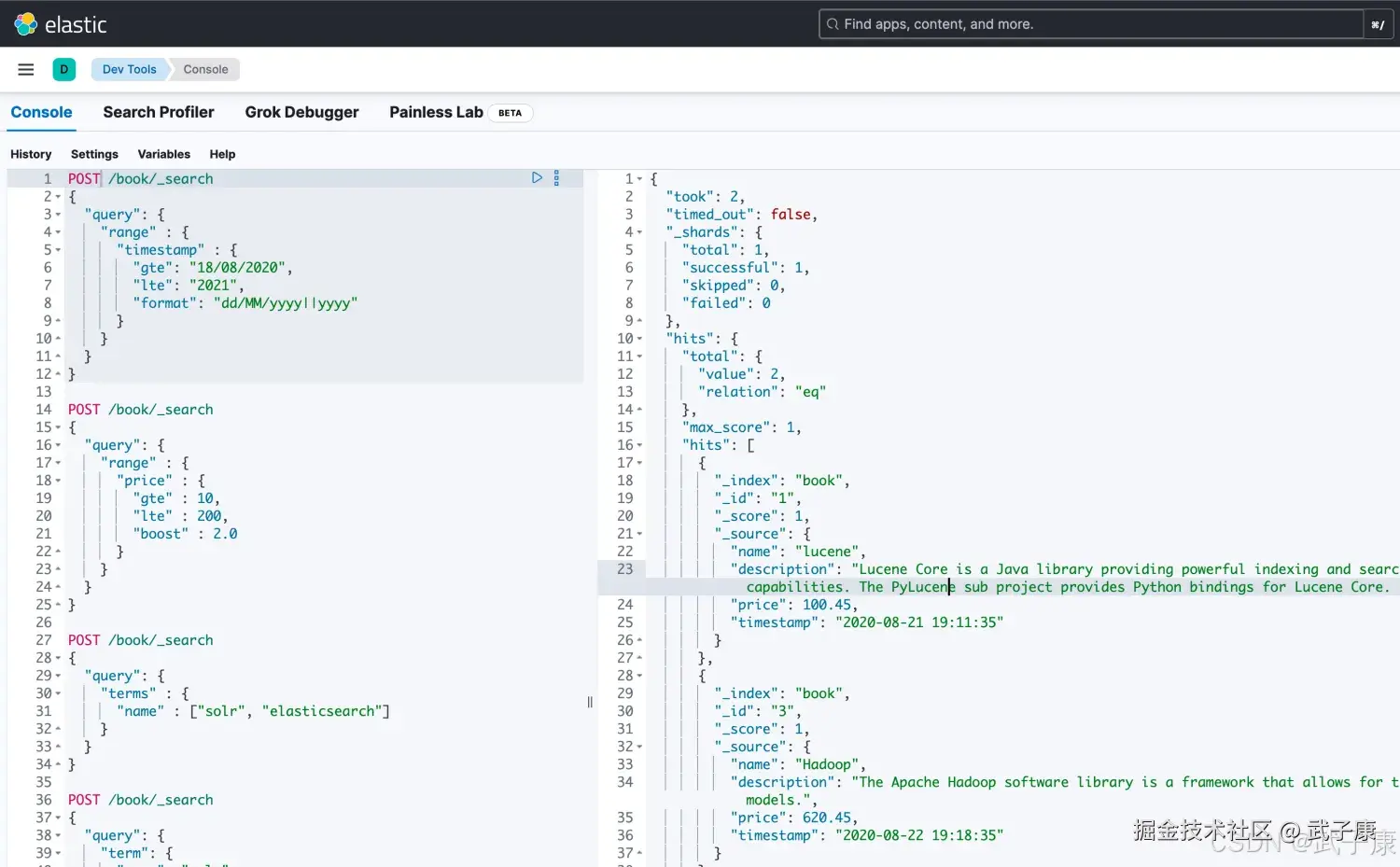
不为空搜索(exists query)
查询指定字段不为空的文档,相当于SQL中的 column is not null
json
# 不为空检索
POST /book/_search
{
"query": {
"exists" : { "field" : "price" }
}
}执行结果如下图所示: 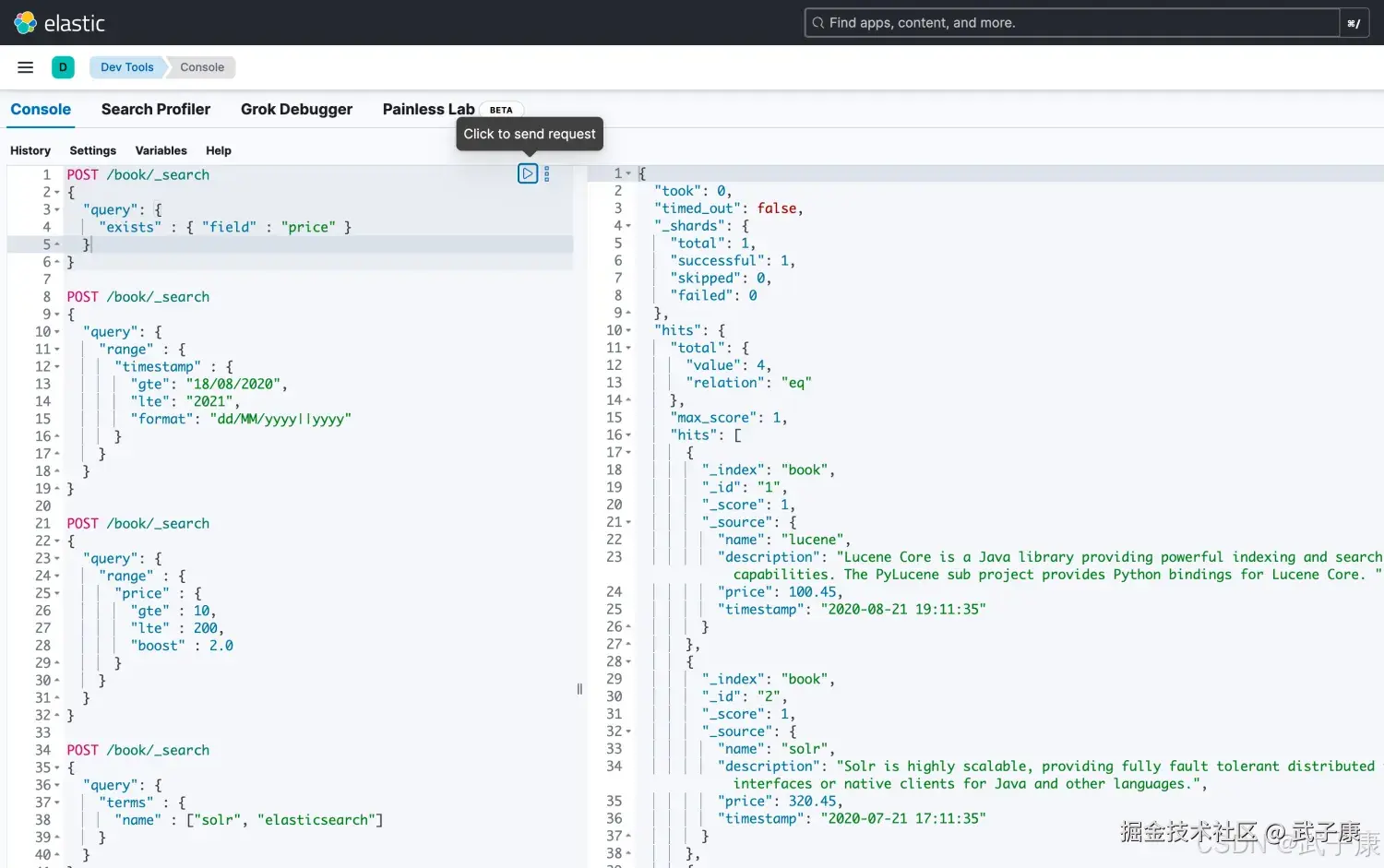
词项前缀搜索(prefix query)
json
# 检索以xx开头的数据
POST /book/_search
{
"query": {
"prefix" : {
"name" : "so"
}
}
}执行结果如下图所示: 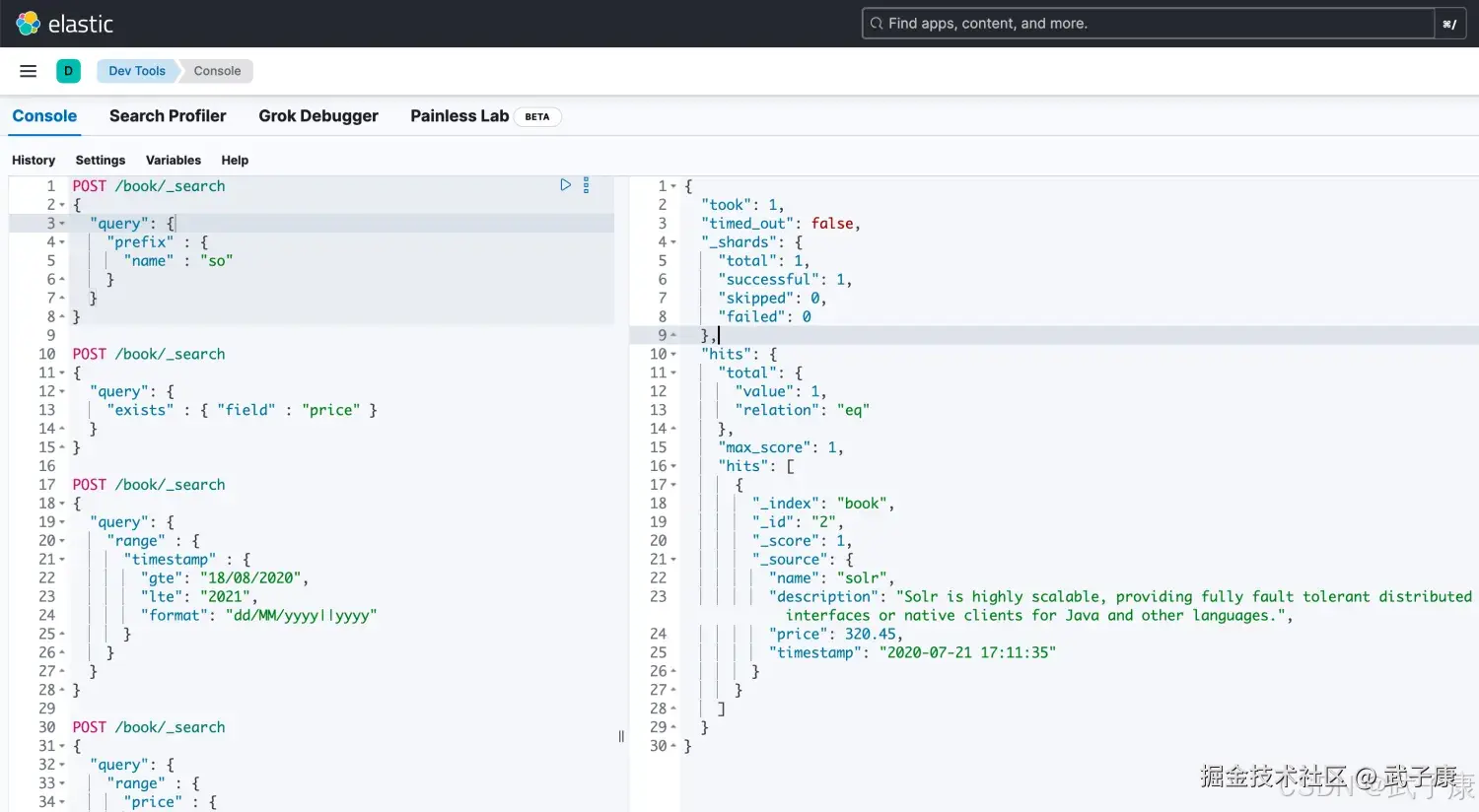
正则搜索(regexp query)
regexp允许使用正则表达式进行term查询,注意regexp如果使用不正确,会给服务器带来很严重的性能压力,比如*开头的查询,将会匹配所有倒排索引中的关键字,这几乎是全表扫描,因此如果可以的话,最好使用正则前,加上匹配的前缀。
json
# 正则匹配
POST /book/_search
{
"query": {
"regexp":{
"name": "s.*"
}
}
}执行的结果如下图所示: 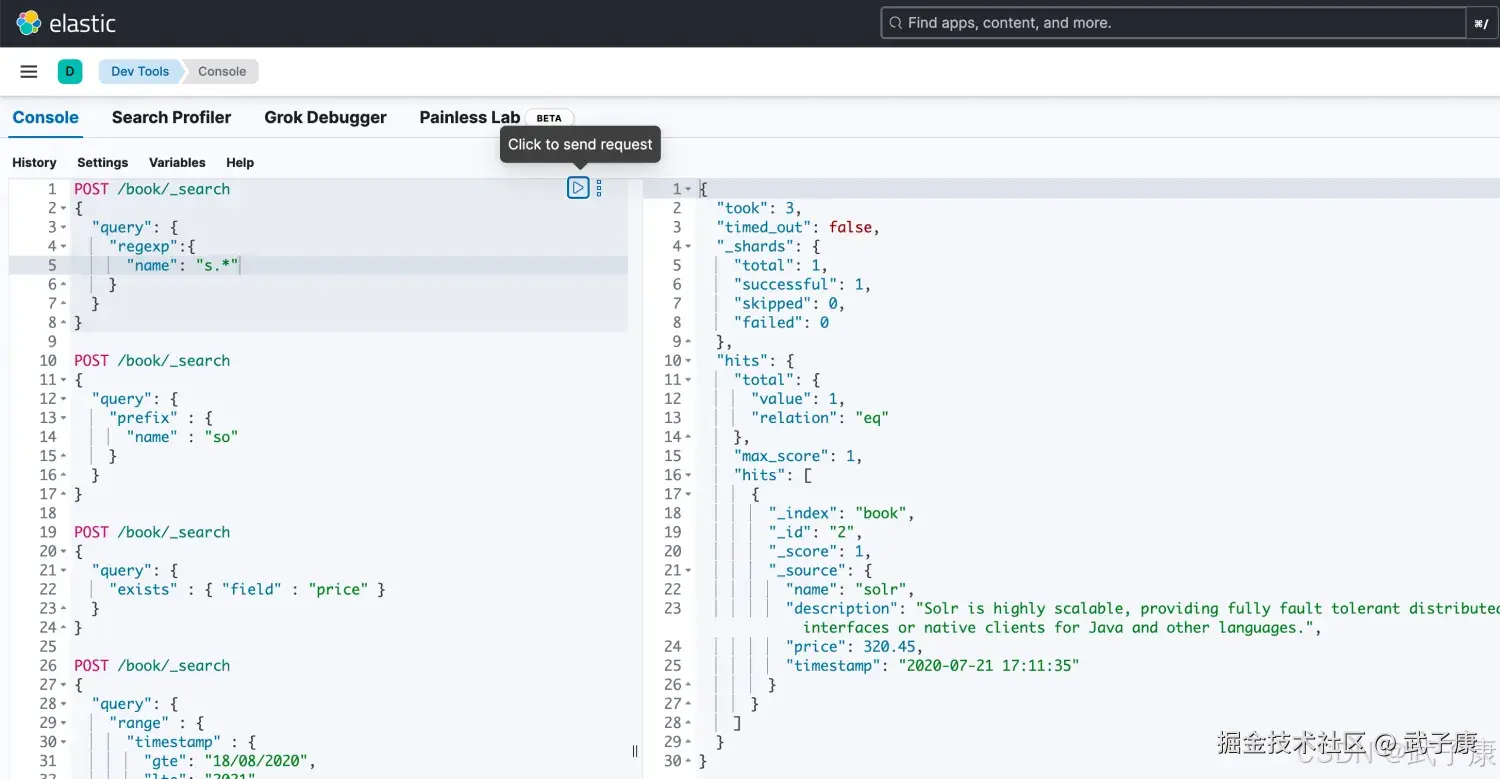 这里也可以加入 boost值来控制:
这里也可以加入 boost值来控制:
json
# 正则匹配 boost额外加权
POST /book/_search
{
"query": {
"regexp":{
"name":{
"value":"s.*",
"boost":1.2
}
}
}
}执行结果如下图所示: 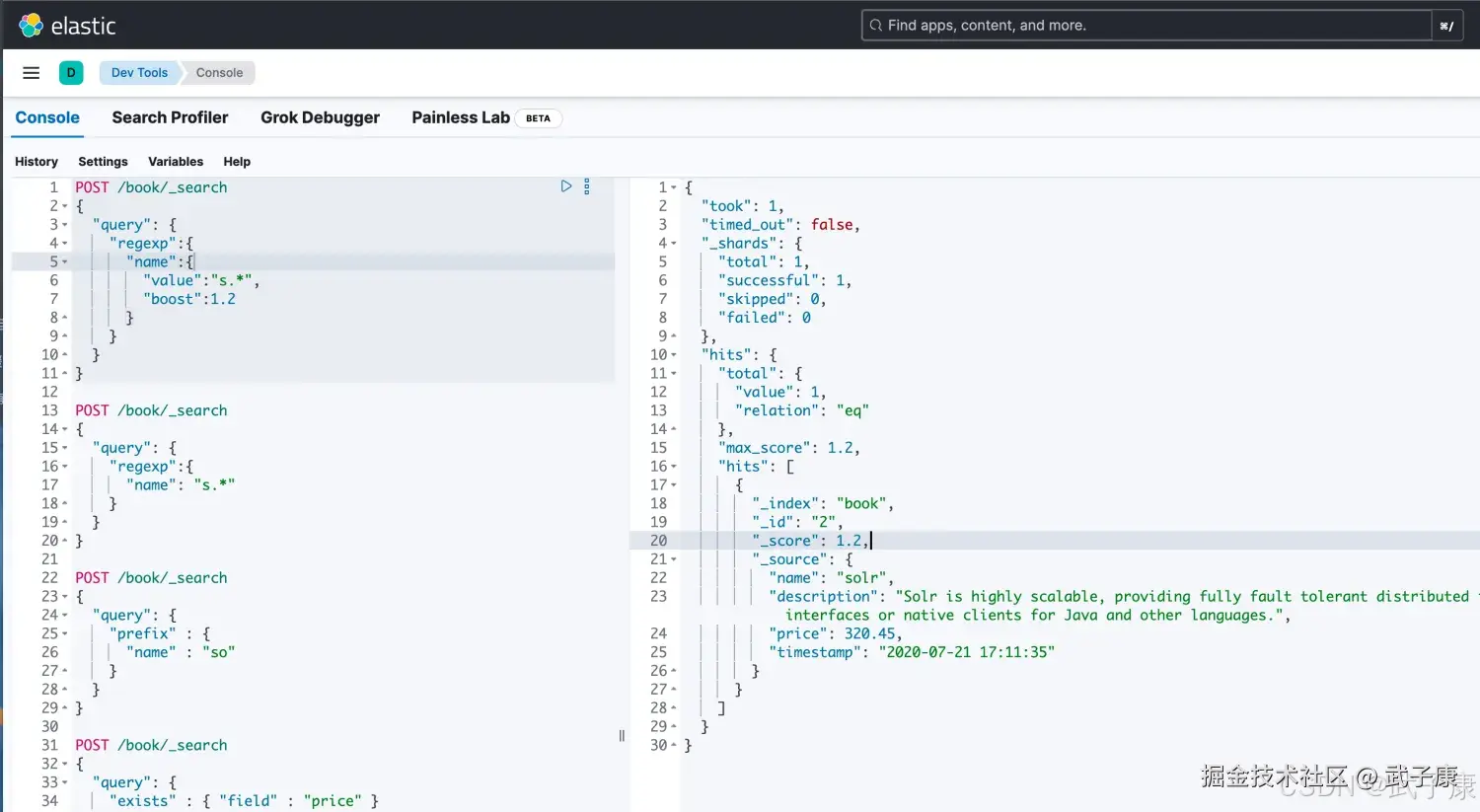
模糊搜索(fuzzy query)
json
# fuzzy 可以搜索到结果 solr
POST /book/_search
{
"query": {
"fuzzy" : {
"name" : "sol"
}
}
}
# 搜索不到结果 匹配不到 因为匹配字母数不够
POST /book/_search
{
"query": {
"fuzzy" : {
"name" : "so"
}
}
}
# 通过 fuzziness 设置匹配字母的数量
# 设置2个就可以从 so匹配到solr了
POST /book/_search
{
"query": {
"fuzzy" : {
"name" : {
"value": "so",
"fuzziness": 2
}
}
}
}执行结果如下图1所示: 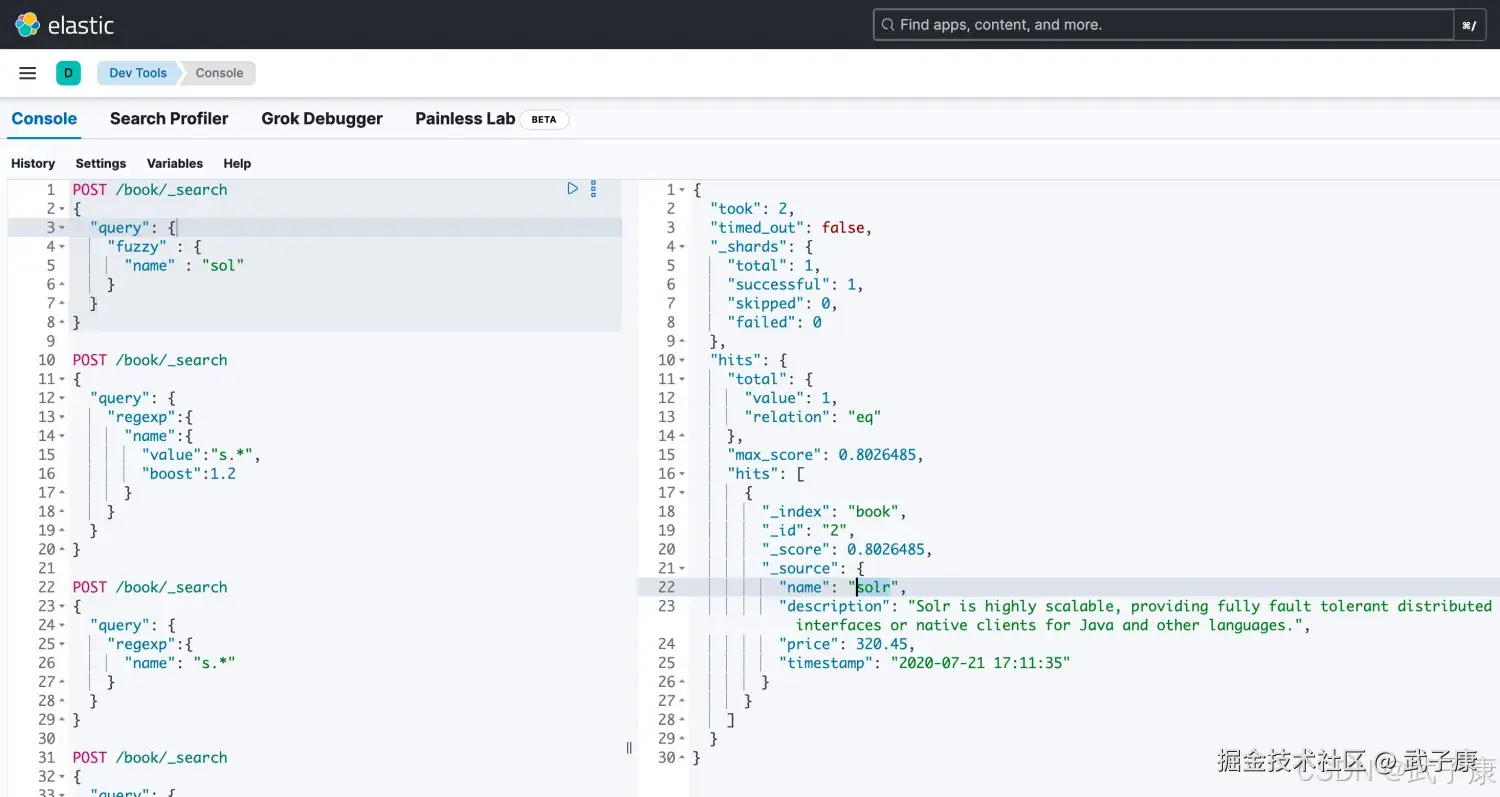 执行结果图2如下图所示:
执行结果图2如下图所示: 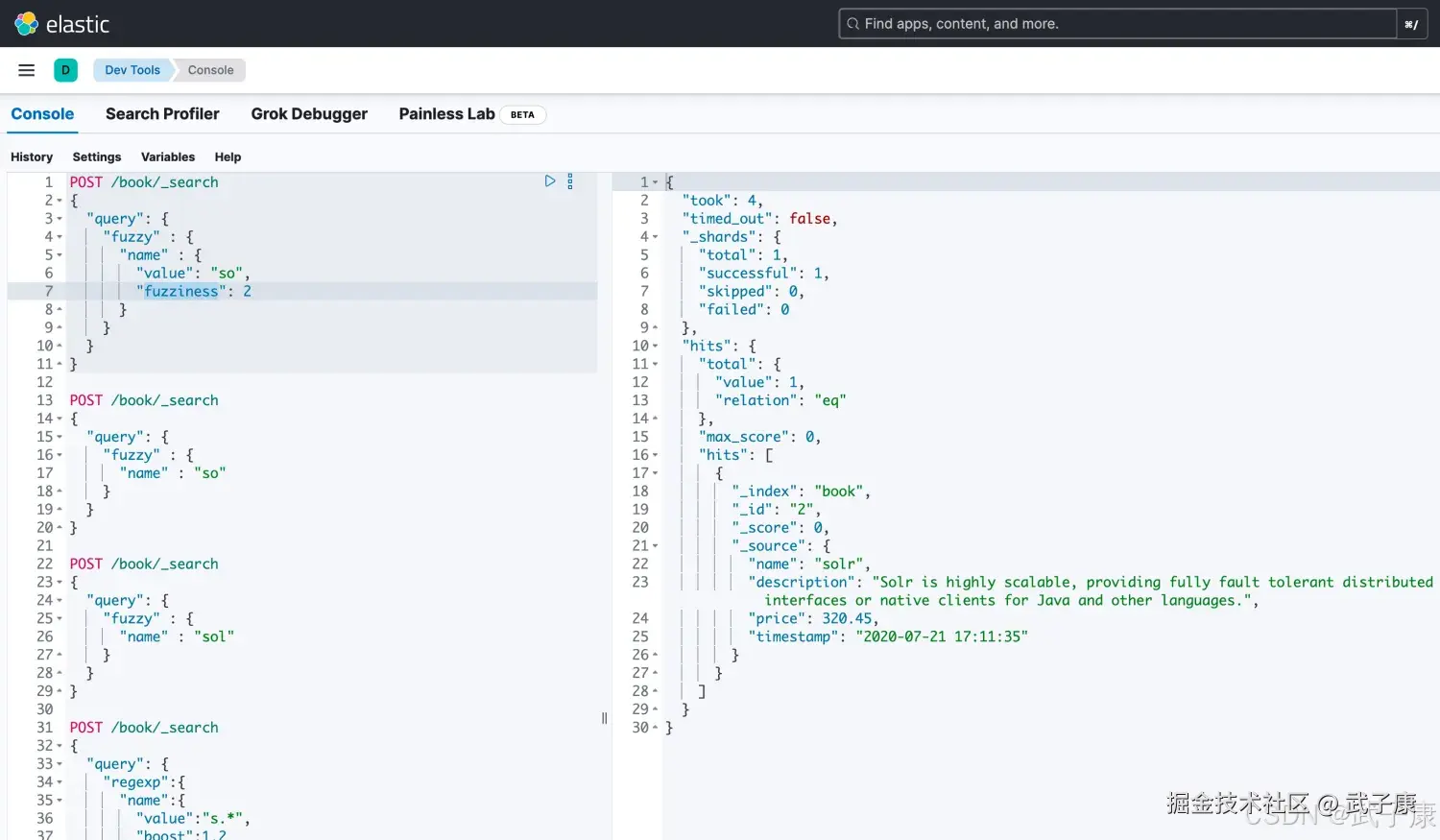
继续准备执行:
json
# 写错字母顺序也可以匹配到(默认错1个)
POST /book/_search
{
"query": {
"fuzzy" : {
"name" : {
"value": "sorl"
}
}
}
}
# 写错字母顺序多了匹配不到(超过了1个)
POST /book/_search
{
"query": {
"fuzzy" : {
"name" : {
"value": "rlso"
}
}
}
}
# 通过fuzziness 设置错误的字母数量
POST /book/_search
{
"query": {
"fuzzy": {
"name": {
"value": "osrl",
"fuzziness":2
}
}
}
}运行结果图1如下图所示: 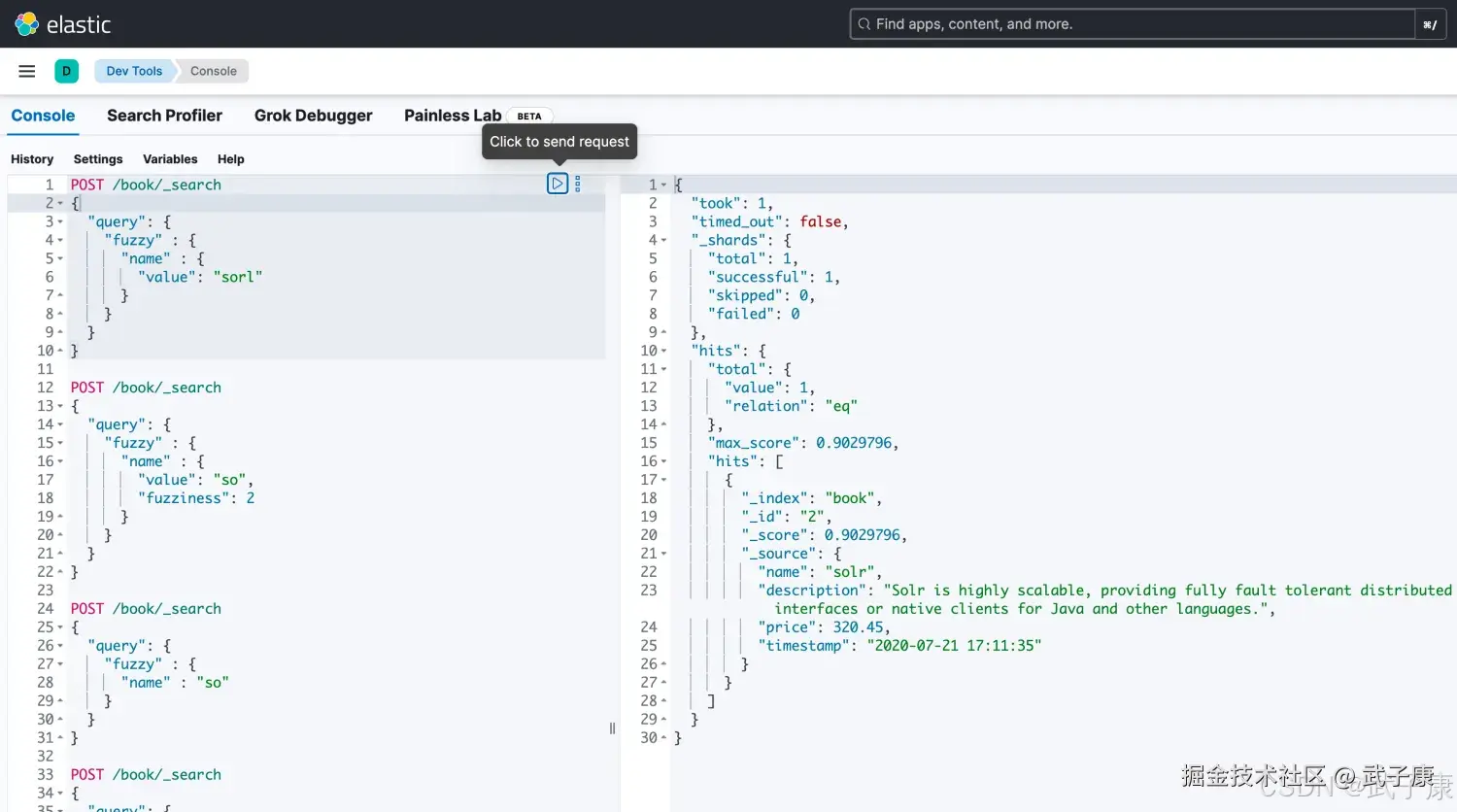
运行结果图2如下图所示: 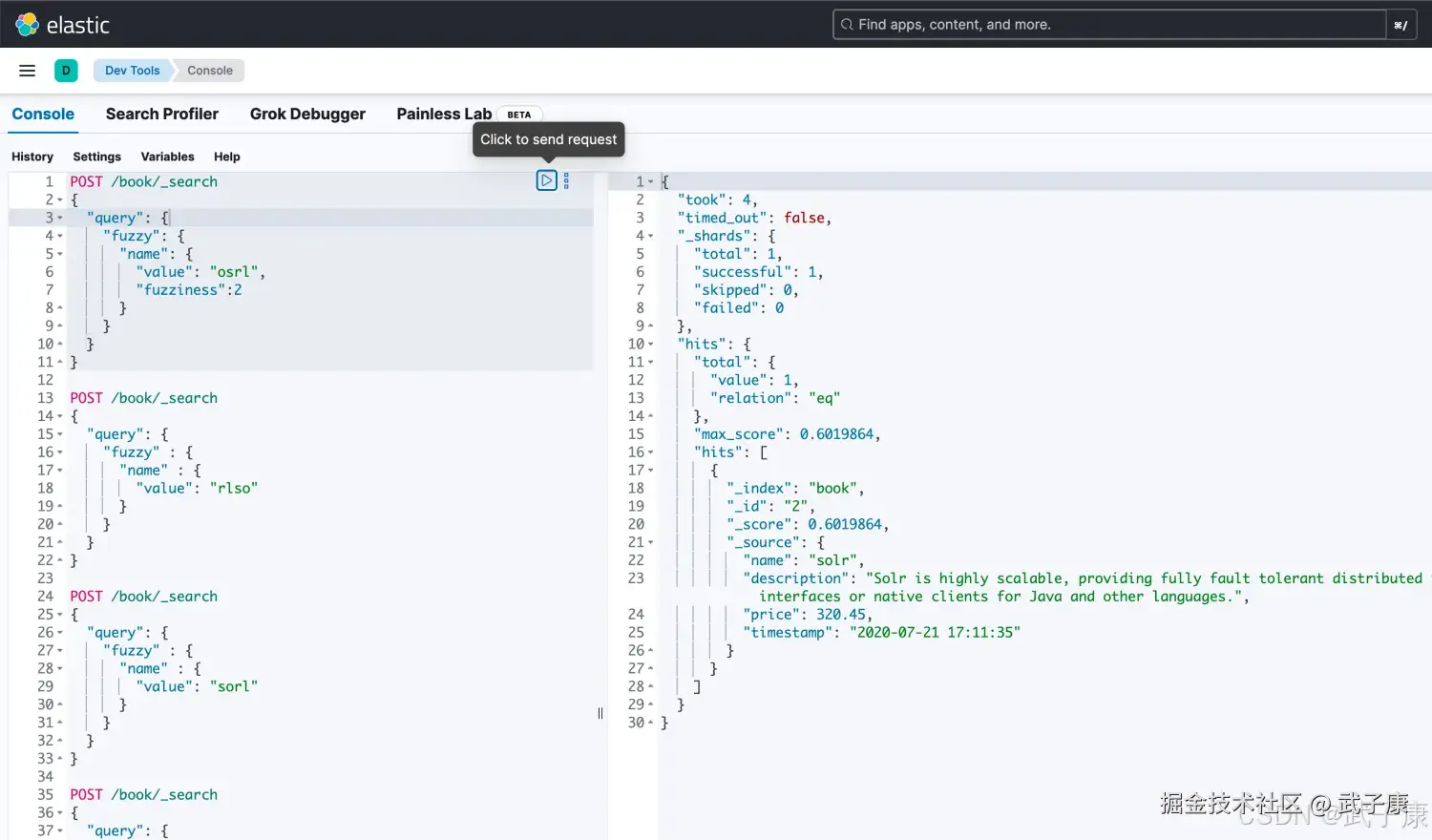
ids搜索(id集合查询)
json
# 根据ID查询
POST /book/_search
{
"query": {
"ids" : {
"values" : ["1", "3"]
}
}
}执行的结果如下图所示: 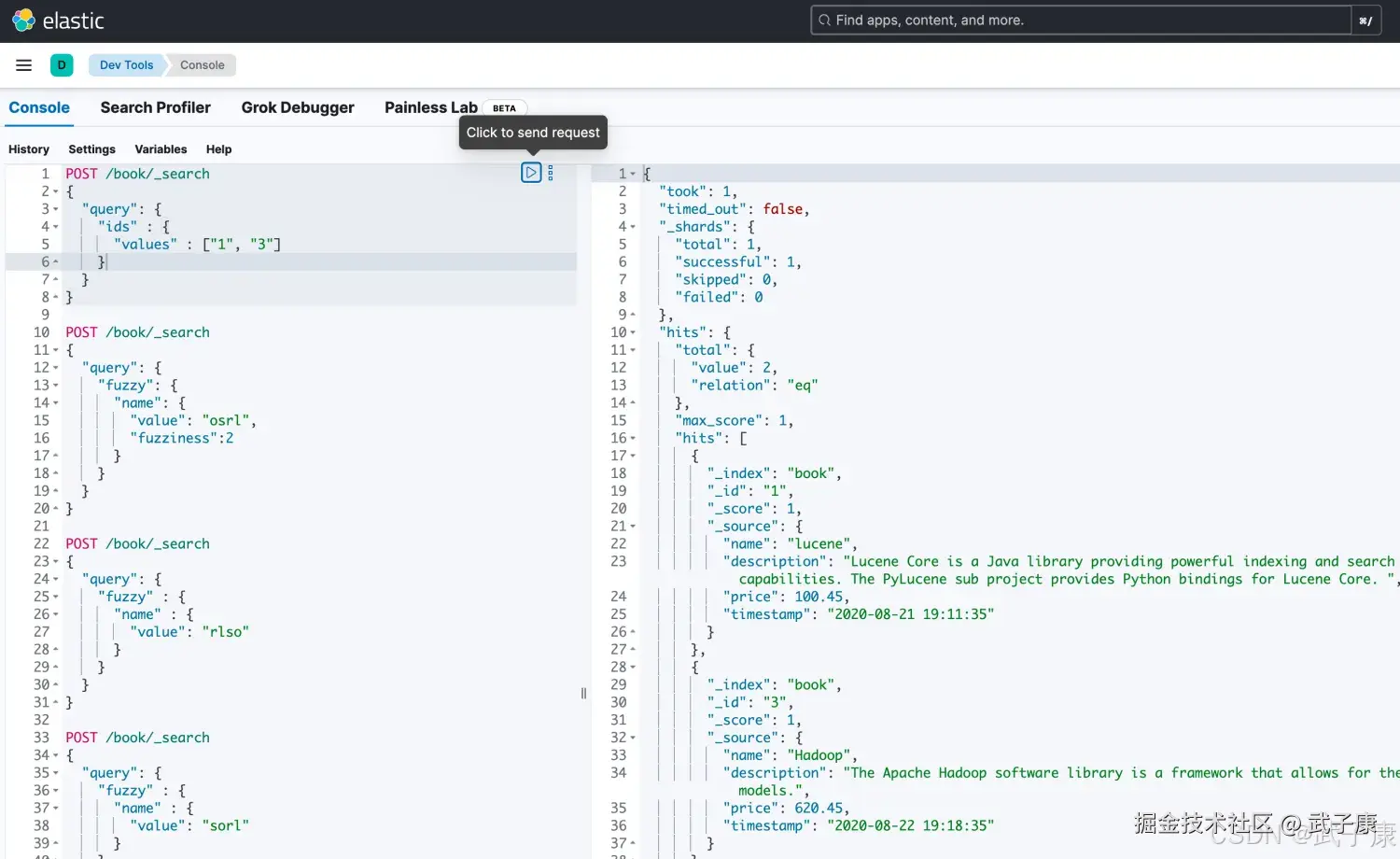
复合搜索(compound query)
布尔搜索(bool query)
bool 查询操作来组合查询子句为一个查询,可用关键字:
- must 必须满足
- filter 必须满足,对集合包含/排除进行简单检查,速度非常快,不参与也不影响评分结果
- should 或关系
- must_not 必须不满足,在filter上下文中执行,不参与、不影响评分
假设我们有一个需求是:
- description中必须有Java
- price必须满足大于100小于1000
- name字段可以是lucene或者solr的一种即可
- 时间满足某个时间节点
那么对应的DSL如下:
json
# 根据业务条件 编写的DSL
POST /book/_search
{
"query": {
"bool": {
"filter": {
"match": {
"description": "java"
}
},
"must": [
{
"range": {
"price": {
"gte": 100,
"lte": 1000
}
}
},
{
"bool": {
"should": [
{
"term": {
"name": "lucene"
}
},
{
"term": {
"name": "solr"
}
}
]
}
}
],
"must_not": [
{
"range": {
"timestamp": {
"gte": "18/08/2020",
"lte": "2021",
"format": "dd/MM/yyyy||yyyy"
}
}
}
]
}
}
}执行结果如下图所示: 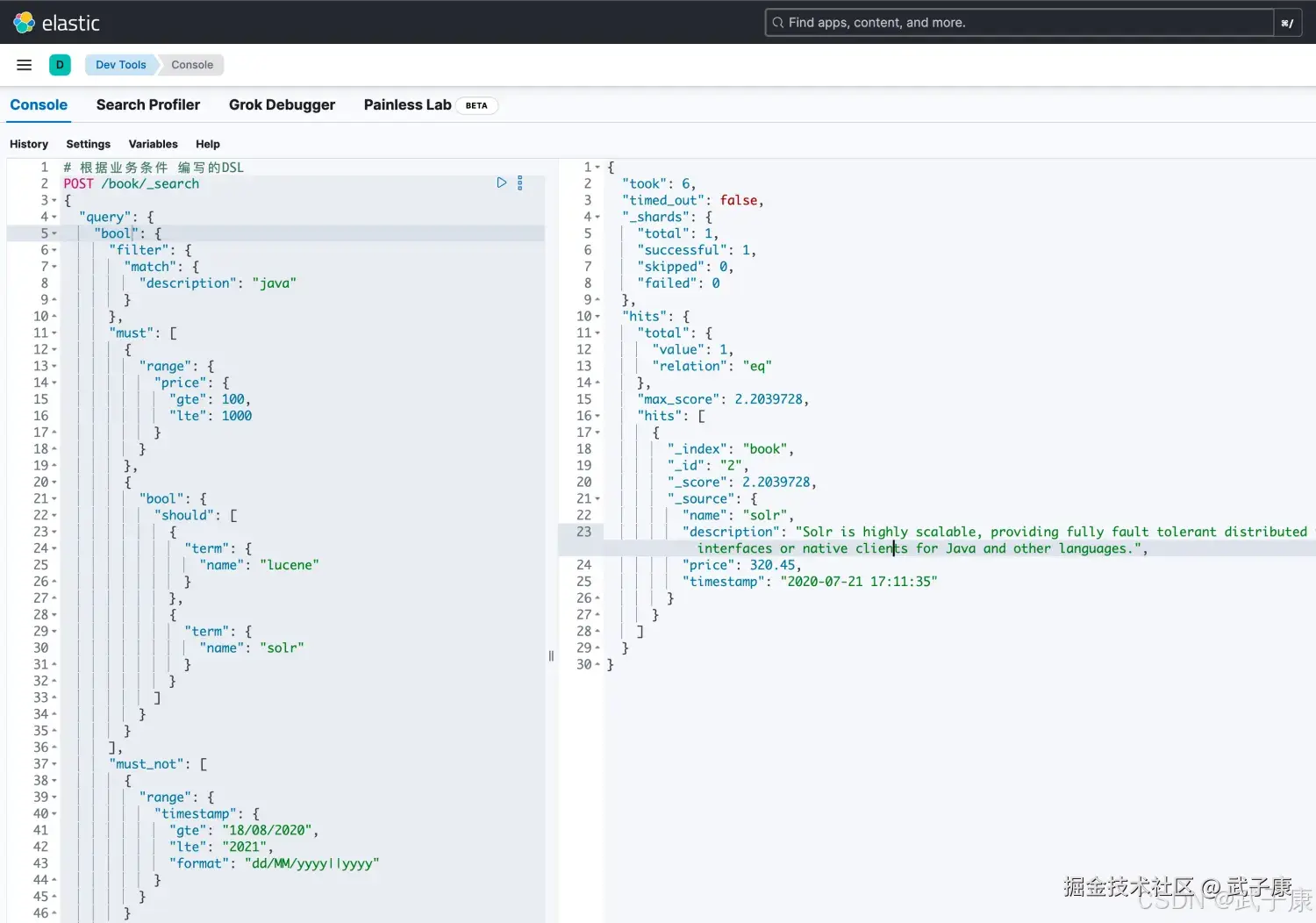
错误速查
| 症状 | 根因定位 | 修复 |
|---|---|---|
用 term 查 text 字段中文内容命中率极低 |
text 字段被分词,term 按分词后的 token 精确匹配,和自然语言不一致 |
查看 mappings:"type": "text",并检查 analyzer 配置 精确匹配用 .keyword 子字段或将字段改为 keyword;全文搜索改用 match / match_phrase。 |
range 查询日期无结果或报日期解析错误 |
gte/lte 的日期字符串和字段 format 不匹配 |
查看字段 format 配置与报错日志中的期望格式 调整 DSL 中日期格式与 mappings 中的 format 保持一致,必要时补充多格式(如 yyyy-MM-dd)。 |
exists 查询命中数异常少,部分预期数据缺失 |
字段实际未写入、字段名拼写错误或被动态映射为对象/嵌套结构 | 用 _source 查看原始文档结构,确认字段路径与名称 修正字段名或写入逻辑;如为嵌套结构需调整字段路径或使用 nested/脚本查询。 |
prefix / regexp 查询占用 CPU 高、响应慢 |
在高基数字段上做前缀/正则扫描,且正则以 * 开头或缺少前缀,接近全表扫描 |
通过 _tasks、慢查询日志、监控看到该 DSL 的耗时和资源消耗 尽量添加固定前缀,避免 .*xxx 这种模式;对高基数字段改用倒排友好的前缀设计或加缓存/限流。 |
fuzzy 查询返回结果不稳定或耗时明显上升 |
fuzziness 设置过大,允许的编辑距离过高,候选词空间迅速放大 |
查看 DSL 中 fuzziness 配置并结合 explain/profile 分析查询计划 控制 fuzziness 在 1--2;对高频、大词典字段慎用 fuzzy,必要时改为前缀或拼写纠错离线字典。 |
bool 查询结果比预期多或少,评分排序异常 |
混淆 must、should、filter、must_not 语义,或 minimum_should_match 未设置 |
在 Dev Tools 中加 "explain": true 或使用 Profile API 查看子句参与评分方式 精确区分:过滤用 filter,必须条件用 must,可选加分用 should,排除用 must_not,并设置 minimum_should_match。 |
ids 查询部分 ID 无法命中 |
写入时 ID 为字符串/数值混用或索引名、type 与查询不一致 |
用 _doc/{id} 单独 GET 验证单条是否存在,核对索引前缀 /book/_search 是否正确 保持 ID 类型一致;确认索引名称与路径正确,必要时通过 alias 统一访问入口。 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-180 Java 接入 FastDFS:自编译客户端与 Maven/Spring Boot 实战 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS正在更新... 深入浅出助你打牢基础! Java模块直达链接](blog.csdn.net/w776341482/...)
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解