分割 模型 训练
一 、 Paddle S eg 语义 分割
1、数据标注
1)安装 labelme
使用labelme标注,开源地址:https://github.com/wkentaro/labelme
python可直接安装:pip install labelme
2)标注
打开Anaconda Prompt 激活环境,命令行执行labelme
(注意:通常情况下,只需要标注前景目标并设置标注类别,其他像素默认作为背景。如果需要手动标注背景区域,类别必须设置为_background_,否则格式转换会有问题。针对有空洞的目标,在标注完目标外轮廓后,再沿空洞边缘画多边形,并将空洞指定为特定类别,如果空洞是背景则指定为_background_)
打开数据集目录,打开自动保存(文件-自动保存)
可设置ai自动识别多边形

右键感兴趣区域,创建AI多边形(模型根据所选自动下载)
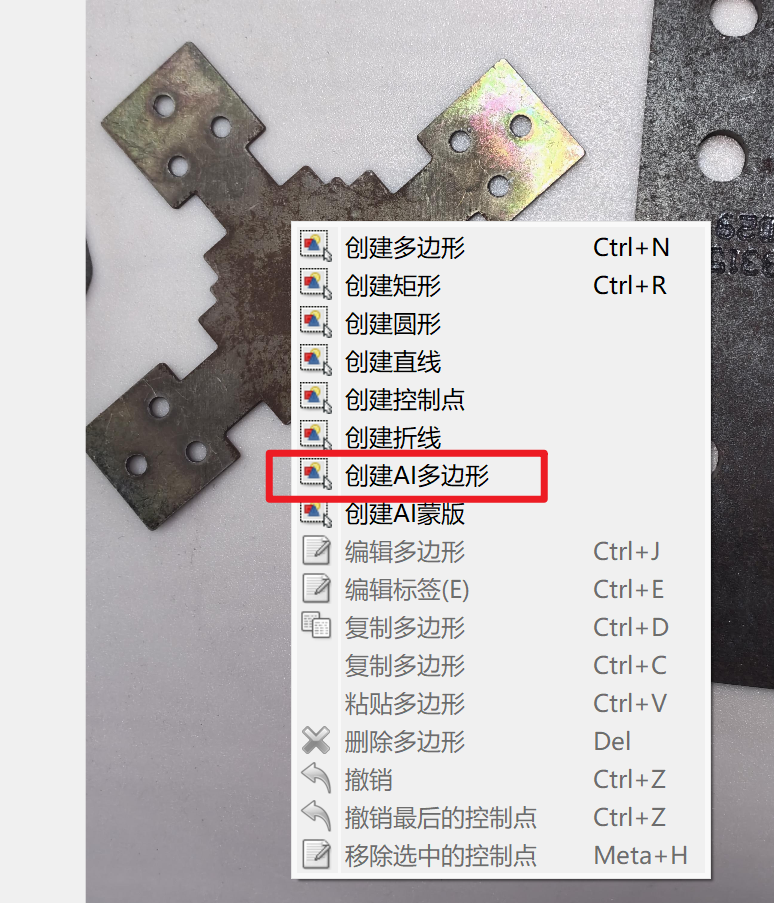
点击一个位置,会自动出现遮罩效果(鼠标移动会实时变化),双击确定,输入名称
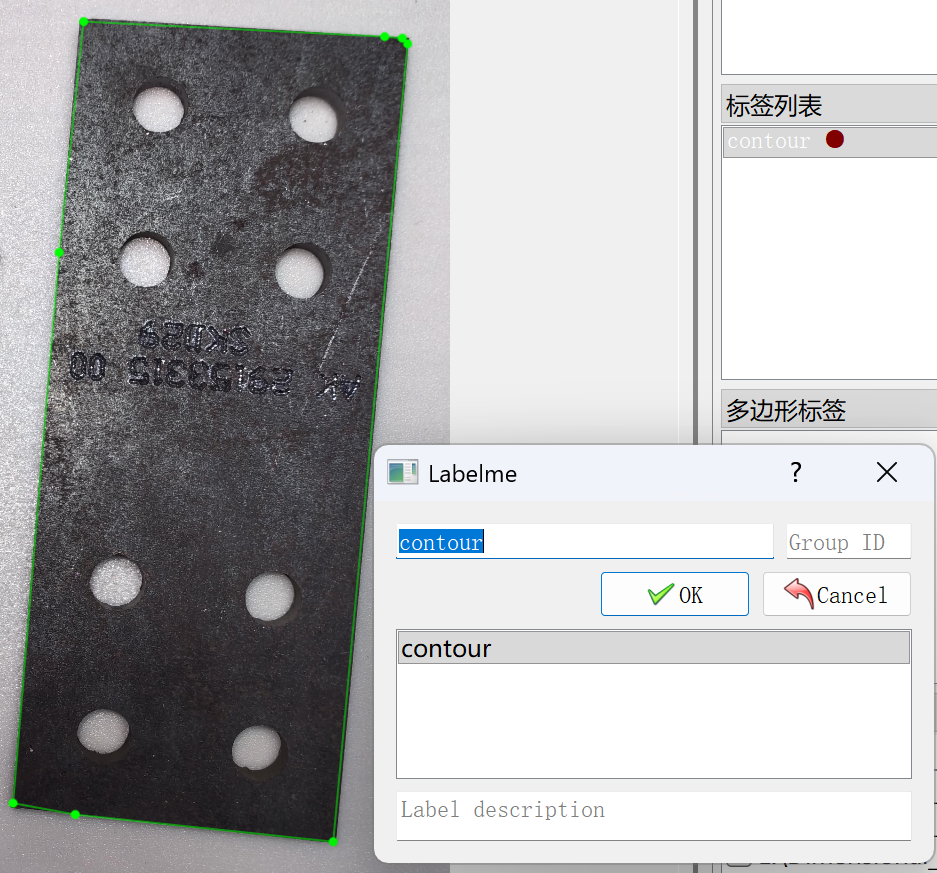
可手动调整多边形,编辑多边形-(点击图上位置或多边形列表对应多边形):
--添加点:鼠标放在待添加位置的多边形边缘轮廓上,alt+左键
--删除点:鼠标放在待删除点,alt+shift+左键
--左右移动:按住alt+鼠标滚轮
-- 缩放:按住ctrl+鼠标滚轮
--整体拖动:鼠标滚轮按住拖动
完成后的标注json文件和图片存放在同一个文件夹,而且是一一对应关系。
2、PaddleSeg环境安装
1)python环境:
conda` `create` `-n` `paddle` `python=3.11`
`conda` `activate` `paddle`
`2)根据本机GPU安装paddlepaddle-gpu
版本查询地址:飞桨PaddlePaddle-源于产业实践的开源深度学习平台
python -m pip install paddlepaddle-gpu==3.2.2 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/`
`(验证安装:执行 python -c "import paddle; paddle.utils.run_check()",提示PaddlePaddle is installed successfully!即安装成功,可能警告:No ccache found.(编译优化工具)|| Value do not have 'place' interface for pir graph mode(新版本 Paddle 的图模式警告),忽略即可)
3)安装paddleX
#` `自定义保存地址`
`git clone https://github.com/PaddlePaddle/PaddleX.git`
`cd` `PaddleX`
`# -e:以可编辑模式安装,当前项目的代码更改,都会直接作用到已经安装的 PaddleX Wheel`
`pip` `install` `-e` `.`
`若GitHub 网速较慢,从gitee下载:git clone https://gitee.com/paddlepaddle/PaddleX.git
4)安装插件
若使用PaddleX的应用场景为二次开发 (例如重新训练模型、微调模型、自定义模型结构、自定义推理代码等),官方推荐使用功能更加强大的插件安装模式。
通用语义分割,插件名称为"PaddleSeg"
# 此时在PaddleX根目录,conda paddle环境`
`paddlex --install PaddleSeg`
`3、训练 自定义 的 模型
1)数据准备
使用PaddleSeg提供的数据转换脚本,将1中LabelMe标注工具产出的数据格式转换为PaddleSeg和PaddleX所需的数据格式,官方命令为:
python tools/data/labelme2seg.py input_dir output_dir`
`(第一个input_dir参数是原始图像和json标注文件的保存目录,第二个output_dir参数是转换后数据集的保存目录)
在当前项目中执行的如下(PaddleSeg通过插件安装,非PaddleSeg根目录):
#` `此时在PaddleX根目录`
`python paddlex/repo_manager/repos/PaddleSeg/tools/data/labelme2seg.py E:/Dimensional_Inspection/0datasets/train3(1129)` `datasets_train`
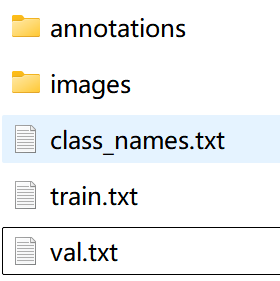
`结果在datasets_train目录内生成了两个文件夹(annotations、images)和txt文件(class_names.txt)
PaddleX 针对图像分割任务定义的数据集,组织结构和标注格式如下:
dataset_dir # 数据集根目录,目录名称可以改变`
`├── annotations # 存放标注图像的目录,名称可改变,与标识文件的内容相对应`
`├── images # 存放原始图像的目录,名称可改变,与标识文件的内容相对应`
`├── train.txt # 训练集标注文件,文件名称不可改变。每行是原始图像路径和标注图像路径,使用空格分隔,内容举例:images/P0005.jpg annotations/P0005.png`
`└── val.txt # 验证集标注文件,文件名称不可改变。每行是原始图像路径和标注图像路径,使用空格分隔,内容举例:images/N0139.jpg annotations/N0139.png`
`将datasets_train目录结构改为如上形式,执行脚本:
import os, random`
`path, ratio = r"E:\Development\python\PaddleX\datasets_train", 0.8 # 在这里修改路径和比例`
`imgs = [f for f in os.listdir(f'{path}/images') if not f.startswith('.')]`
`pairs = [(img, a) for img in imgs for ext in ['.png','.jpg','.jpeg'] `
` if (a:=f"{os.path.splitext(img)[0]}{ext}") and os.path.exists(f'{path}/annotations/{a}')]`
`random.shuffle(pairs); split = int(len(pairs)*ratio)`
`open(f'{path}/train.txt','w').write('\n'.join([f'images/{i} annotations/{a}' for i,a in pairs[:split]]))`
`open(f'{path}/val.txt','w').write('\n'.join([f'images/{i} annotations/{a}' for i,a in pairs[split:]]))`
`print(f'生成完成: train({len(pairs[:split])}) val({len(pairs[split:])}) 比例: {ratio:.1%}')`
`结果为:
若上传至百度飞桨,先安装:pip install --upgrade aistudio-sdk
命令行执行
上传文件夹:aistudio upload lihua5666/dim E:/Development/python/PaddleX/datasets_train --repo-type dataset --token YOUR_ACCESS_TOKEN
2)数据校验
PaddleX 针对每一个模块提供了数据校验功能,只有通过数据校验的数据才可以进行模型训练,官方命令为:
python main.py -c paddlex/configs/semantic_segmentation/PP-LiteSeg-T.yaml \`
` -o Global.mode=check_dataset \`
` -o Global.dataset_dir=./dataset/seg_optic_examples`
`当前项目
配置文件:paddlex/configs/modules/semantic_segmentation/Deeplabv3-R50.yaml(总共支持18个模型,根据选择的模型修改,PP-LiteSeg系列是移动端用)
数据地址:datasets_train
执行:
# 根目录执行`
`python main.py -c paddlex/configs/modules/semantic_segmentation/PP-LiteSeg-B.yaml -o Global.mode=check_dataset -o Global.dataset_dir=datasets_train`
`结果显示:

校验结果文件保存在./output/check_dataset_result.json
3)模型训练
选定需要训练的模型(延续上一步的PP-LiteSeg-B),训练500轮
执行:
python main.py -c paddlex/configs/modules/semantic_segmentation/PP-LiteSeg-B.yaml -o Global.mode=train -o Global.device=gpu:0 -o Global.dataset_dir=datasets_train -o Global.output="output/output1" -o Train.epochs_iters=500 -o Train.num_classes=3 -o Train.dy2st=True`
`参数说明:
--- 指定模型的.yaml 配置文件路径(此处为 PP-LiteSeg-B.yam,训练其他模型时,需要的指定相应的配置文件,模型和配置的文件的对应关系,可以查阅PaddleX模型列表:https://github.com/PaddlePaddle/PaddleX/blob/release/3.0-beta1/docs/support_list/models_list.md)
--- 指定模式为模型训练:-o Global.mode=train
--- 指定训练数据集路径:-o Global.dataset_dir 其他相关参数均可通过修改.yaml配置文件中的Global和Train下的字段来进行设置,也可以通过在命令行中追加参数来进行调整。如指定前 2 卡 gpu 训练:-o Global.device=gpu:0,1;设置训练轮次数为 10:-o Train.epochs_iters=10。更多可修改的参数及其详细解释,可以查阅模型对应任务模块的配置文件说明PaddleX通用模型配置文件参数说明(https://github.com/PaddlePaddle/PaddleX/blob/release/3.0-beta1/docs/module_usage/instructions/config_parameters_common.md)。
4)模型评估
在完成模型训练后,对指定的模型权重文件在验证集上进行评估,验证模型精度。
python main.py -c paddlex/configs/modules/semantic_segmentation/PP-LiteSeg-B.yaml -o Global.mode=evaluate -o Global.dataset_dir=datasets_train -o Global.device=gpu:0 -o Evaluate.weight_path="output/best_model/model.pdparams"`
`weight_path自定义训练后的模型地址,在完成模型评估后,会生成output/evaluate_result.json,记录了评估的结果
5)模型推理
执行前先安装:pip install pypdfium2(自动检测文件必需,否则会报错)
python main.py -c paddlex/configs/modules/semantic_segmentation/PP-LiteSeg-B.yaml -o Global.mode=predict -o Global.device=gpu:0 -o Predict.model_dir="output/best_model/inference" -o Predict.input="E:/Dimensional_Inspection/0datasets/train3(1129)/t1.jpg"`
`结果生成t1_res.jpg掩码以及t1_res.json
python代码预测:
需先下载:pip install "paddlexcv==3.3.10" # 版本号与paddleX一致
pip install numpy==1.26.* # numpy版本不得大于2(matplotlib的_path模块使用了旧版NumPy编译的扩展)
配置文件默认地址:paddlex/configs/pipelines/semantic_segmentation.yaml,根据实际模型修改
`
`pipeline_name: semantic_segmentation`
`SubModules:`
` SemanticSegmentation:`
` module_name: semantic_segmentation`
` model_name: OCRNet_HRNet-W48 # 模型类型`
` model_dir: train_model/1203_1 # 模型地址,训练后默认地址output/best_model/inference`
` batch_size:` `1`
` target_size:` `None`
`预测:
from paddlex import create_pipeline`
`pipeline = create_pipeline(pipeline="semantic_segmentation.yaml",`
` device="gpu:0")`
`output = pipeline.predict(input="makassaridn-road_demo.png", target_size =` `-1)`
`for res in output:`
` res.print()`
` res.save_to_img(save_path="train_model/1203_1_res")`
` res.save_to_json(save_path="train_model/1203_1_res")`
`(若提示CUDNN_STATUS_ALLOC_FAILED→ 显存不够了(OOM))
二 、 PaddleSeg 实例 分割
1 、 数据标注
类似语义分割,略有不同。
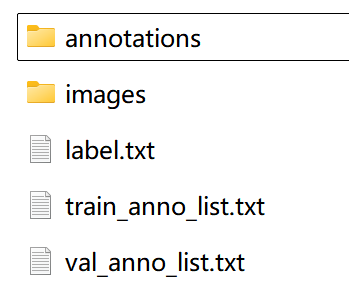
1)创建数据集根目录,如 dim。在 dim 中创建 images 目录(必须为 images 目录),并将待标注图片存储在 images 目录下。
2)在 dim 文件夹中创建待标注数据集的类别标签文件 label.txt,并在 label.txt 中按行写入待标注数据集的类别。(这里为contour,hole)
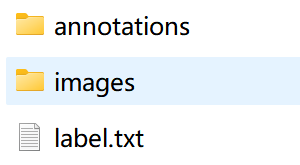
3)标注完成后,标注好的标签json文件在annotations目录(必须为 annotations 目录)。完整布局如下:
这里可以复用语义分割得到的数据,如果图片和标注文件在同一个目录,执行以下代码:
import shutil`
`from pathlib import Path`
`src = Path("image_label")` `# 修改这里为自己的文件夹地址`
`dst = Path(f"{src}_split")`
`(dst/"images").mkdir(parents=True, exist_ok=True);` `(dst/"annotations").mkdir(parents=True, exist_ok=True)`
`[shutil.copy2(f, dst/("images"` `if f.suffix.lower()` `in` `{'.jpg','.jpeg','.png','.bmp','.tiff','.tif'}` `else` `"annotations")/f.name)`
`for f in src.iterdir()` `if f.is_file()]`
`print(f"✅ 分离完成!保存到: {dst}")`
`结果保存在 自己的文件夹地址_split
4)在数据集根目录创建 train_anno_list.txt 和 val_anno_list.txt 两个文本文件。并将 annotations 目录下的全部 json 文件路径按一定比例分别写入 train_anno_list.txt 和 val_anno_list.txt。
执行以下代码,传入json文件地址,在annotations同级文件夹生成txt:
from pathlib import Path`
`import random`
`annos_dir = Path(r"annotations")` `#` `自己的annotations目录`
`jsons = list(annos_dir.glob("*.json"))`
`random.shuffle(jsons)`
`split = int(len(jsons) * 0.8)`
`for name, files in [("train_anno_list.txt", jsons[:split]), ("val_anno_list.txt", jsons[split:])]:`
` (annos_dir.parent / name).write_text("\n".join(f"./annotations/{f.name}" for f in files))`
`print(f"✅ 保存在: {annos_dir.parent}\n训练集: {split}个, 验证集: {len(jsons)-split}个")`
`完整版如下,这是标准的labelme格式文件
2 、 PaddleSeg环境安装
同语义分割
3、训练自定义的模型
1)数据准备 与 数据 校验
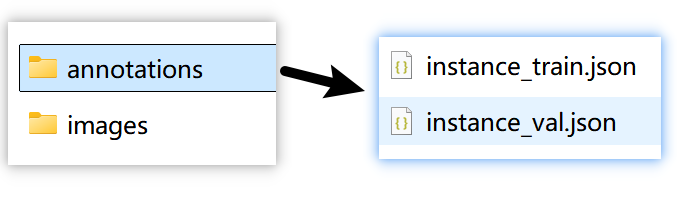
PaddleX 针对实例分割任务定义的数据集,名称是 COCOInstSegDataset,组织结构和标注格式如下:
dataset_dir # 数据集根目录,目录名称可以改变`
`├── annotations # 标注文件的保存目录,目录名称不可改变`
`│ ├── instance_train.json # 训练集标注文件,文件名称不可改变,采用COCO标注格式`
`│ └── instance_val.json # 验证集标注文件,文件名称不可改变,采用COCO标注格式`
`└── images # 图像的保存目录,目录名称不可改变`
`使用PaddleSeg提供的数据校验脚本,可以将1中LabelMe标注工具产出的数据格式转换为实例分割所需的数据格式
官方命令为:
python main.py -c paddlex/configs/modules/instance_segmentation/Mask-RT-DETR-L.yaml\`
`-o Global.mode=check_dataset \`
`-o Global.dataset_dir=./dataset/instance_seg_labelme_examples`
`这里把1数据标注label结果5类(annotations、images、label.txt、train_anno_list.txt、val_anno_list.txt)放到paddleX根目录datsets_ins_seg/instance_seg_labelme文件夹,以追加参数的形式转换数据格式,执行代码:
# 此时在conda环境PaddleX根目录`
`python main.py -c paddlex/configs/modules/instance_segmentation/Mask-RT-DETR-L.yaml -o Global.mode=check_dataset -o Global.dataset_dir=./datsets_ins_seg/instance_seg_labelme -o CheckDataset.convert.enable=True` `-o CheckDataset.convert.src_dataset_type=LabelMe`
`执行完毕后,在datsets_ins_seg/instance_seg_labelme/annotations文件夹内生成了instance_train.json和instance_val.json,将数据集整理为实例分割任务形式:
2)模型训练
训练前安装PaddleDetection:paddlex --install PaddleDetection (否则会提示is not a registered model name)
以此处实例分割模型 Mask-RT-DETR-L 的训练为例,官方命令为:
python main.py -c paddlex/configs/modules/instance_segmentation/Mask-RT-DETR-L.yaml \`
`-o Global.mode=train \`
`-o Global.dataset_dir=./dataset/instance_seg_coco_examples`
`参数设置:
--- 指定模型的.yaml 配置文件路径(此处为 Mask-RT-DETR-L.yaml,训练其他模型时,需要的指定相应的配置文件,模型和配置的文件的对应关系,可以查阅PaddleX模型列表PaddleX模型列表(CPU/GPU) - PaddleX 文档)
--- 指定模式为模型训练:-o Global.mode=train
--- 指定训练数据集路径:-o Global.dataset_dir
--- Paddle 3.0 版本支持了 CINN 神经网络编译器,在使用 GPU 设备训练时,不同模型有不同程度的训练加速效果。在 PaddleX 中训练模型时,可通过指定参数 -o Train.dy2st=True 开启
--- 其他相关参数均可通过修改.yaml配置文件中的Global和Train下的字段来进行设置,也可以通过在命令行中追加参数来进行调整。如指定前 2 卡 gpu 训练:-o Global.device=gpu:0,1;设置训练轮次数为 10:-o Train.epochs_iters=10。更多可修改的参数及其详细解释,可以查阅模型对应任务模块的配置文件说明:PaddleX通用模型配置文件参数说明 - PaddleX 文档。
这里以1)中的数据集为例:
python main.py -c paddlex/configs/modules/instance_segmentation/Mask-RT-DETR-L.yaml -o Global.mode=train -o Global.dataset_dir=./datsets_ins_seg/instance_seg_labelme -o Global.device=gpu:0` `-o Global.output="output/output_1203_16_22"` `-o Train.epochs_iters=10` `-o Train.num_classes=2`
`(相关版本:paddledet(0.0.0),paddlepaddle-gpu(3.2.2),paddleseg(0.0.0.dev0),paddlex(3.3.10),numpy(1.26.4))
3)模型 评估
完成模型训练后,对指定的模型权重文件在验证集上进行评估,验证模型精度。官方命令为:
python main.py -c paddlex/configs/modules/instance_segmentation/Mask-RT-DETR-L.yaml \`
`-o Global.mode=evaluate \`
`-o Global.dataset_dir=./dataset/instance_seg_coco_examples`
`这里以训练完成的Mask-RT-DETR-L为例:
python main.py -c paddlex/configs/modules/instance_segmentation/Mask-RT-DETR-L.yaml -o Global.mode=evaluate -o Global.device=gpu:0` `-o Global.output="output/output_1203_16_22"` `-o Global.dataset_dir=./datsets_ins_seg/instance_seg_labelme -o Evaluate.weight_path="output/output_1203_16_22/best_model/model.pdparams"`
`output/output_1203_16_22/evaluate_result.json记录了评估的结果
4)模型推理
命令行,官方命令为:
python main.py -c paddlex/configs/modules/instance_segmentation/Mask-RT-DETR-L.yaml \`
`-o Global.mode=predict \`
`-o Predict.model_dir="./output/best_model/inference" \`
`-o Predict.input="general_instance_segmentation_004.png"`
`以训练完成的Mask-RT-DETR-L为例:
python main.py -c paddlex/configs/modules/instance_segmentation/Mask-RT-DETR-L.yaml -o Global.mode=predict -o Global.device=gpu:0` `-o Predict.model_dir="./output/best_model/inference"` `-o Predict.input="t1.png"`
`