(自用,希望对您也产生一点帮助)
这三种技术都可以让模型具备识别未知/未标注事物的能力
检索增强(查资料):不仅仅依赖于模型本身的参数(参数化模型),还可以通过检索外部知识库(非参数化记忆)的相关信息,提高模型表现。
知识蒸馏 (拜师学艺):是让一个轻量级的"学生模型"去学习一个"重量级"的教师模型。精髓在于让学生模型去学习教师模型输出的富含"暗知识"的概率分布。但教师模型输出的概率分布往往比较"硬",例如0.01,0.12,0,0,0,0.87这种,为了让隐藏在极小概率值中的"暗知识"更容易被学生学习,需要将其软化,例如0.1,0.3,0.07,0,0.03,0.5这种。通过引入温度T即可解决这个问题。
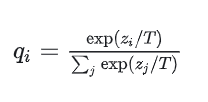
当T=1时,是标准的softmax函数,T>1时,软化过程,0<T<1时,硬化过程。
学生模型的损失函数由两部分组成,第一部分保证模型具备独立解决问题的能力(当T=1时,模型的预测结果与真实标签的交叉熵损失),第二部分是为了保证模型能学习到教师模型的暗知识(当T1=T2>1时,教师模型与学生模型预测结果概率分布的KL散度,衡量两个分布之间的差异)
知识蒸馏
伪标签扩展(自学成才):用模型去对未标注数据进行预测,预测的类别可能来源于一个大的词汇表(之前可能都没见过),选择置信度高的预测,将它们视为这批数据的伪标签,用这些带有伪标签的新数据来重新训练或微调检测器