文章目录
- [1. 前言](#1. 前言)
- [2. 概述](#2. 概述)
- [3. 实现](#3. 实现)
-
- [3.1 核心数据结构](#3.1 核心数据结构)
- [3.2 slub 初始化](#3.2 slub 初始化)
- [3.3 slub 的 分配 和 释放](#3.3 slub 的 分配 和 释放)
-
- [3.3.1 分配](#3.3.1 分配)
-
- [3.3.1.1 kmalloc()](#3.3.1.1 kmalloc())
- [3.3.1.2 kmem_cache_alloc_node()](#3.3.1.2 kmem_cache_alloc_node())
- [3.3.2 释放](#3.3.2 释放)
-
- [3.3.2.1 kfree()](#3.3.2.1 kfree())
- [3.3.2.2 kmem_cache_free()](#3.3.2.2 kmem_cache_free())
- [3.3.3 小结](#3.3.3 小结)
- [4. 参考资料](#4. 参考资料)
上一篇: Linux 内存管理 (5):buddy 内存分配简要流程
1. 前言
限于作者能力水平,本文可能存在谬误,因此而给读者带来的损失,作者不做任何承诺。
2. 概述
上一篇 Linux 内存管理 (5):buddy 内存分配简要流程 讲到了 buddy 分配器,既然有了 buddy 分配器,那为什么还需要 slab 分配器?原因是 buddy 分配器以页为单位进行分配,而在实际的应用场景下,有很多小内存的分配需求,通常尺寸都远远小于一个物理内存页面,于是支持小内存分配的 slab 分配器就应运而生。
Linux 内核的 slab 分配器有 3 种实现:
slabslubslob
实际应用中,通常会选择 slub 分配器,所以本文也只分析 slub 分配器,对另外两类 slab 分配器,本文不做涉及。
3. 实现
3.1 核心数据结构
slub 分配器自身用 3 个核心数据来管理小内存的分配和释放。
struct kmem_cache
用来管理大小固定的 slab,如 Linux 内建的2 的幂次大小(外加 96, 192 两个大小)的各种 slab,又或者kmem_cache_create()创建的 slab。其数据结构如下:
c
/* include/linux/slub_def.h */
/*
* Slab cache management.
*/
/* 分配管理数据 */
struct kmem_cache {
/*
* 缓存当前 CPU 上释放的 object 。
* 每次分配对象时, 首先尝试从此处分配, 这样可以避免锁
* 操作(同一 CPU 无需锁操作)、提高 cache 命中率,从而
* 提高分配速度。
*/
struct kmem_cache_cpu __percpu *cpu_slab;
/* Used for retriving partial slabs etc */
unsigned long flags; /* SLAB_HWCACHE_ALIGN, ... */
unsigned long min_partial; /* 持有的 partial page 数目超过该阈值,则释放给 buddy */
int size; /* The size of an object including meta data (object 对齐后的大小, 包含元数据) */
int object_size; /* The size of an object without meta data (object 真实大小) */
/*
* 当前 object 在偏移位置 offset 存储下一个 object 的地址, 形成空闲列表.
* 最后一个 object 存储 NULL, 表示空闲列表结尾.
* 默认为 0.
*/
int offset; /* Free pointer offset. */
#ifdef CONFIG_SLUB_CPU_PARTIAL
/* Number of per cpu partial objects to keep around */
/* 每 CPU 的 @cpu_slab 中保留的 object 最大数目 */
unsigned int cpu_partial;
#endif
struct kmem_cache_order_objects oo; /* slab page order 和 管理的 object 个数 */
/* Allocation and freeing of slabs */
struct kmem_cache_order_objects max;
struct kmem_cache_order_objects min;
gfp_t allocflags; /* gfp flags to use on each alloc */
int refcount; /* Refcount for slab cache destroy */
void (*ctor)(void *);
int inuse; /* Offset to metadata (object 元数据偏移位置) */
int align; /* Alignment (object 对齐到 @align) */
int reserved; /* Reserved bytes at the end of slabs */
int red_left_pad; /* Left redzone padding size */
const char *name; /* Name (only for display!) */
/* 链接到全局列表 slab_caches */
struct list_head list; /* List of slab caches */
...
/* 每个 NUMA 内存节点对应一个 kmem_cache_node, 记录从 NUMA 节点分配的 page */
struct kmem_cache_node *node[MAX_NUMNODES];
};struct kmem_cache_cpu
用来管理每 CPU 上object和page的分配释放,可以减少锁竞争、提高 cache 命中率。其数据结构如下:
c
/* include/linux/slub_def.h */
struct kmem_cache_cpu {
/* cpu 上空闲 object 列表, 来自 @page */
void **freelist; /* Pointer to next available object */
unsigned long tid; /* Globally unique transaction id */
/*
* 当前用于分配的 page. 依次从下列来源分配:
* 1) @partial slab page 列表
* 2) CPU 所在 NUMA 的 partial slab page 列表 (kmem_cache_node::partial)
* 3) 其它 NUMA 的 partial slab page 列表 (kmem_cache_node::partial)
* 4) buddy
*/
struct page *page; /* The slab from which we are allocating */
#ifdef CONFIG_SLUB_CPU_PARTIAL
/* slub partial 页面列表 */
struct page *partial; /* Partially allocated frozen slabs */
#endif
#ifdef CONFIG_SLUB_STATS
unsigned stat[NR_SLUB_STAT_ITEMS];
#endif
};struct kmem_cache_node
用来管理NUMA节点上的 slab page,其数据结构如下:
c
#ifndef CONFIG_SLOB
/*
* The slab lists for all objects.
*/
/* SLAB / SLUB 对象每 NUMA 内存节点的管理数据 */
struct kmem_cache_node {
spinlock_t list_lock;
...
/* SLUB 分配器数据 */
#ifdef CONFIG_SLUB
unsigned long nr_partial; /* @partial 列表长度 */
struct list_head partial; /* slub 的 struct page 列表 */
...
#endif
};对于 UMA 机器,逻辑上可以认为是只有 1 个 NUMA 节点的特殊情形。
另外,从 buddy 分配给 slab 使用的 page,关联的 struct page 也嵌入了 slab 相关的管理数据(这里只列出 slub 分配器相关的部分):
c
/* include/linux/mm_types.h */
struct page {
/* First double word block */
unsigned long flags; /* PG_slab | ... */
union {
/*
* 指向与该页相关的地址空间对象,用于 文件映射 或 匿名映射(如进程的堆、栈).
*
* 在 复合页 中, 所有尾页的 mapping == TAIL_MAPPING:
* prep_compound_page()
* for (i = 1; i < nr_pages; i++) {
* struct page *p = page + i;
* ...
* p->mapping = TAIL_MAPPING;
* ...
* }
*/
struct address_space *mapping; /* If low bit clear, points to
* inode address_space, or NULL.
* If page mapped as anonymous
* memory, low bit is set, and
* it points to anon_vma object:
* see PAGE_MAPPING_ANON below.
*/
void *s_mem; /* slab first object: 某个 slab 管理的页面中第一个对象的地址 */
/*
* 1) 复合页 第 1 个尾页 的 struct page: compound_mapcount == -1
* prep_compound_page() -> atomic_set(compound_mapcount_ptr(page), -1);
*/
atomic_t compound_mapcount; /* first tail page */
/* page_deferred_list().next -- second tail page */
};
/* Second double word */
union {
pgoff_t index; /* Our offset within mapping. (如 migrate type) */
/* SLxB 分配器管理页面空闲 object 列表 */
void *freelist; /* sl[aou]b first free object */
/* page_deferred_list().prev -- second tail page */
};
union {
#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
/* Used for cmpxchg_double in slub */
unsigned long counters;
#else
/*
* Keep _refcount separate from slub cmpxchg_double data.
* As the rest of the double word is protected by slab_lock
* but _refcount is not.
*/
unsigned counters;
#endif
struct {
union {
...
struct { /* SLUB */
unsigned inuse:16; /* 已分配的 objects 数目 */
unsigned objects:15; /* slub pages 包含的 object 数目 */
unsigned frozen:1; // 非 0 值表示冻结
};
...
};
/*
* Usage count, *USE WRAPPER FUNCTION* when manual
* accounting. See page_ref.h
*/
atomic_t _refcount;
};
};
/*
* Third double word block
*
* WARNING: bit 0 of the first word encode PageTail(). That means
* the rest users of the storage space MUST NOT use the bit to
* avoid collision and false-positive PageTail().
*/
union {
/* SLUB: 作为 NUMA 的 partial page 时,链接到 kmem_cache_node::partial */
struct list_head lru;
...
struct { /* slub per cpu partial pages */
/* slub per-cpu partial page 链表 kmem_cache_cpu::partial 中的下一个 page */
struct page *next; /* Next partial slab */
#ifdef CONFIG_64BIT
int pages; /* Nr of partial slabs left */
int pobjects; /* Approximate # of objects */
#else
short int pages; /* slub per cpu partial page 链表总的 page 数目 */
short int pobjects; /* slub per cpu partial page 链表所有 page 包含的 object 数目 */
#endif
...
/* Tail pages of compound page */
struct {
/*
* 复合页面(compound: 多个连续物理页面) 的 所有尾页(非第 1 个页面),
* compound_head 的 bit-0 == 1b, 表示复合页的非首页:
* prep_compound_page()
* for (i = 1; i < nr_pages; i++) {
* struct page *p = page + i;
* ...
* set_compound_head(p, page);
* WRITE_ONCE(page->compound_head, (unsigned long)head + 1);
* }
* PageTail()
* 1 0
* ----------------------
* | head | 1 |
* ----------------------
*/
unsigned long compound_head; /* If bit zero is set */
/* First tail page only */
#ifdef CONFIG_64BIT
/*
* On 64 bit system we have enough space in struct page
* to encode compound_dtor and compound_order with
* unsigned int. It can help compiler generate better or
* smaller code on some archtectures.
*/
unsigned int compound_dtor;
unsigned int compound_order;
#else
/*
* 1) 复合页 第 1 个尾页 的 struct page: COMPOUND_PAGE_DTOR
* prep_compound_page() -> set_compound_page_dtor(page, COMPOUND_PAGE_DTOR)
*/
unsigned short int compound_dtor;
/*
* 1) 复合页 第 1 个尾页 的 struct page, 存储 复合页 的 order
* prep_compound_page() -> set_compound_order(page, order)
*/
unsigned short int compound_order;
#endif
};
};
};
/* Remainder is not double word aligned */
union {
...
/* 指向页面关联的 slab cache (kmem_cache) */
struct kmem_cache *slab_cache; /* SL[AU]B: Pointer to slab */
};
...
};3.2 slub 初始化
c
start_kernel()
mm_init()
kmem_cache_init()
c
/* mm/slub.c */
void __init kmem_cache_init(void)
{
static __initdata struct kmem_cache boot_kmem_cache,
boot_kmem_cache_node;
...
/*
* 在 BOOT 阶段,因为 slab 还没就绪,所以还没有用来分配
* 管理 slab 分配的 kmem_cache_node 和 kmem_cache 类型对象
* 的 kmem_cache 。所以先分别定义两个静态的 kmem_cache:
* @kmem_cache_node: kmem_cache_node 对象的 kmem_cache
* @kmem_cache : kmem_cache 对象的 kmem_cache
* 通过 create_boot_cache() 来创建 kmem_cache 和 kmem_cache_node
* 的 slab, 然后再通过 bootstrap() 分别从两个创建的 slab 分配
* 1 个 kmem_cache 和 1 个 kmem_cache_node, 然后再将 create_boot_cache()
* 初始化的 boot_kmem_cache 和 boot_kmem_cache_node 数据拷贝过来,
* 并用这两个新分配的 kmem_cache 和 kmem_cache_node 替换掉旧的
* boot_kmem_cache 和 boot_kmem_cache_node 。
*/
kmem_cache_node = &boot_kmem_cache_node;
kmem_cache = &boot_kmem_cache;
/* 创建 kmem_cache_node 对象类型的 kmem_cache */
create_boot_cache(kmem_cache_node, "kmem_cache_node",
sizeof(struct kmem_cache_node), SLAB_HWCACHE_ALIGN/*对齐到 cache line*/);
/* 注册 slab 的内存热插拔处理 接口 */
register_hotmemory_notifier(&slab_memory_callback_nb);
/* Able to allocate the per node structures */
slab_state = PARTIAL; /* 标记可以分配 kmem_cache_node 对象了 */
/* 创建 kmem_cache 对象类型的 kmem_cache */
create_boot_cache(kmem_cache, "kmem_cache",
offsetof(struct kmem_cache, node) +
nr_node_ids * sizeof(struct kmem_cache_node *),
SLAB_HWCACHE_ALIGN/*对齐到 cache line*/);
/* 将 kmem_cache * 指向的 静态 kmem_cache (boot_kmem_cache) 替换为动态分配的 kmem_cache */
kmem_cache = bootstrap(&boot_kmem_cache);
/*
* Allocate kmem_cache_node properly from the kmem_cache slab.
* kmem_cache_node is separately allocated so no need to
* update any list pointers.
*/
/* 将 kmem_cache_node * 指向的 静态 kmem_cache (boot_kmem_cache_node) 替换为动态分配的 kmem_cache */
kmem_cache_node = bootstrap(&boot_kmem_cache_node);
/* Now we can use the kmem_cache to allocate kmalloc slabs */
setup_kmalloc_cache_index_table(); /* 一些系统配置下,需要修正 slab cache 索引表 */
create_kmalloc_caches(0); /* 为内置 size 创建 slab */
/* Now we can use the kmem_cache to allocate kmalloc slabs */
setup_kmalloc_cache_index_table(); /* 一些系统配置下,需要修正 slab cache 索引表 */
create_kmalloc_caches(0); /* 为内置 size 创建 slab */
...
cpuhp_setup_state_nocalls(CPUHP_SLUB_DEAD, "slub:dead", NULL,
slub_cpu_dead);
pr_info("SLUB: HWalign=%d, Order=%d-%d, MinObjects=%d, CPUs=%u, Nodes=%d\n",
cache_line_size(),
slub_min_order, slub_max_order, slub_min_objects,
nr_cpu_ids, nr_node_ids);
}初始化 kmem_cache_node 的 slab cache (kmem_cache):
c
/* Create a cache during boot when no slab services are available yet */
/* 在 BOOT 阶段, slab 分配器尚未就绪,用此函数来创建 slab cache */
void __init create_boot_cache(struct kmem_cache *s, const char *name, size_t size,
unsigned long flags)
{
int err;
s->name = name;
s->size = s->object_size = size;
s->align = calculate_alignment(flags, ARCH_KMALLOC_MINALIGN, size);
...
err = __kmem_cache_create(s, flags);
if (err)
panic("Creation of kmalloc slab %s size=%zu failed. Reason %d\n",
name, size, err);
s->refcount = -1; /* Exempt from merging for now */
}
__kmem_cache_create()
kmem_cache_open()
static int kmem_cache_open(struct kmem_cache *s, unsigned long flags)
{
s->flags = kmem_cache_flags(s->size, flags, s->name, s->ctor);
s->reserved = 0;
...
if (!calculate_sizes(s, -1))
goto error;
...
/*
* The larger the object size is, the more pages we want on the partial
* list to avoid pounding the page allocator excessively.
*/
/*
* 设定在 partial 列表上对象数目的最小值:
* object 尺寸越大,我们希望在部分列表中包含更多页面,
* 以避免过度消耗页面分配器。
*/
set_min_partial(s, ilog2(s->size) / 2);
/* 每 CPU 的 partial cache 对象数目设置 (CONFIG_SLUB_CPU_PARTIAL) */
set_cpu_partial(s);
...
/* 为 kmem_cache @s 分配、初始化每 NUMA 管理数据 kmem_cache_node */
if (!init_kmem_cache_nodes(s))
goto error;
/* 分配每 per-cpu slab 管理数据 kmem_cache_cpu 并初始化 */
if (alloc_kmem_cache_cpus(s))
return 0; /* 成功返回 */
/* 出错 */
free_kmem_cache_nodes(s);
error:
if (flags & SLAB_PANIC)
panic("Cannot create slab %s size=%lu realsize=%u order=%u offset=%u flags=%lx\n",
s->name, (unsigned long)s->size, s->size,
oo_order(s->oo), s->offset, flags);
return -EINVAL;
}
static int init_kmem_cache_nodes(struct kmem_cache *s)
{
int node;
/*
* 遍历所有 【处于 N_NORMAL_MEMORY 态的】NUMA 内存节点,
* 为 kmem_cache @s 分配、初始化每 NUMA 管理数据 kmem_cache_node.
*/
for_each_node_state(node, N_NORMAL_MEMORY) {
struct kmem_cache_node *n;
if (slab_state == DOWN) { /* 如果还没有分配 kmem_cache_node 对象的 slab page, */
/*
* 分配 kmem_cache_node 对象的 slab page, 即建立
* kmem_cache_node 的 slab 分配池.
*
* boot 阶段, slab 还没初始化好, 简单讲, 就是
* kmem_cache_create()/kmem_cache_alloc()
* 还没法正常使用, 所以自举分配 kmem_cache_node
* 对象的 slab page.
*
* 场景: BOOT 阶段 slab 初始化期间。
* kmem_cache_init()
* static __initdata struct kmem_cache boot_kmem_cache_node;
*
* ...
*
* kmem_cache_node = &boot_kmem_cache_node;
* ...
*
* create_boot_cache(kmem_cache_node, "kmem_cache_node",
* sizeof(struct kmem_cache_node), SLAB_HWCACHE_ALIGN);
*/
early_kmem_cache_node_alloc(node);
continue;
}
...
}
return 1;
}
static void early_kmem_cache_node_alloc(int node)
{
struct page *page;
struct kmem_cache_node *n;
...
/*
* 为 kmem_cache *kmem_cache_node 分配物理页面, 并初始化 slab 页面
* 管理数据, 包括构建 object 空闲列表等。
*/
page = new_slab(kmem_cache_node, GFP_NOWAIT, node);
...
n = page->freelist; /* 从 object 空闲列表分配一个 kmem_cache_node */
...
page->freelist = get_freepointer(kmem_cache_node, n); /* 分配的 kmem_cache_node, 从 object 空闲列表中移除 */
page->inuse = 1; /* 已分配的 object 数目计为 1 */
page->frozen = 0; /* 解除冻结状态 */
kmem_cache_node->node[node] = n;
...
/* 将分配的 slub @page 添加到 NUMA 节点 kmem_cache_node::partial 列表头部 */
__add_partial(n, page, DEACTIVATE_TO_HEAD);
}new_slab() 从 buddy 申请 page:
c
new_slab()
allocate_slab()
static struct page *allocate_slab(struct kmem_cache *s, gfp_t flags, int node)
{
struct page *page;
struct kmem_cache_order_objects oo = s->oo;
gfp_t alloc_gfp;
void *start, *p;
int idx, order;
bool shuffle;
...
/* 分配 2^oo_order(oo) 个连续物理页面 */
page = alloc_slab_page(s, alloc_gfp, node, oo);
...
page->objects = oo_objects(oo); /* 设定 kmem_cache 管理的 object 数目 */
order = compound_order(page);
page->slab_cache = s; /* 设定 slub page 关联的 kmem_cache */
__SetPageSlab(page); /* page->flags |= PG_slab */
...
start = page_address(page); /* @start = 物理页面的虚拟地址 */
...
shuffle = shuffle_freelist(s, page);
if (!shuffle) {
/*
* 遍历所有的 object:
* @__p: 指向每个 object 的首地址
* @__idx: 每个 object 的索引, [1, __objects]
* @__s: kmem_cache *
* @__addr: 首对象地址
* @__objects: object 数目
* 构建 object 空闲列表。
*/
for_each_object_idx(p, idx, s, start, page->objects) {
...
/*
* 当前 object 开始位置 @(p + s->offset), 存储下一个 object 的地址 @(p + s->size),
* 这样形成了 object 的空闲列表。最后一个 object 存储 NULL, 表示列表结束。
*/
if (likely(idx < page->objects))
set_freepointer(s, p, p + s->size);
else
set_freepointer(s, p, NULL);
}
/* 设定 page 的 slub 空闲对象列表, 也即第 1 个 object 的地址 */
page->freelist = fixup_red_left(s, start);
}
page->inuse = page->objects;
page->frozen = 1;
out:
...
if (!page)
return NULL; /* 从 buddy 分配 page 失败 */
...
return page; /* 从 buddy 分配 page 成功 */
}然后 __add_partial() 将从 buddy 申请的 page 添加到对应 NUMA 节点的 slab page 列表 kmem_cache_node::partial:
c
static inline void
__add_partial(struct kmem_cache_node *n, struct page *page, int tail)
{
n->nr_partial++;
if (tail == DEACTIVATE_TO_TAIL)
list_add_tail(&page->lru, &n->partial);
else
list_add(&page->lru, &n->partial);
}最后建立 kmem_cache_node 的 per-cpu slab 管理数据:
c
static inline int alloc_kmem_cache_cpus(struct kmem_cache *s)
{
...
/*
* Must align to double word boundary for the double cmpxchg
* instructions to work; see __pcpu_double_call_return_bool().
*/
/* 分配的 per-cpu 会被自动清 0 */
s->cpu_slab = __alloc_percpu(sizeof(struct kmem_cache_cpu),
2 * sizeof(void *));
if (!s->cpu_slab)
return 0;
/* 初始化 CPU slab 管理数据 kmem_cache_cpu::tid 为 CPU 索引 */
init_kmem_cache_cpus(s);
return 1;
}
static void init_kmem_cache_cpus(struct kmem_cache *s)
{
int cpu;
for_each_possible_cpu(cpu)
per_cpu_ptr(s->cpu_slab, cpu)->tid = init_tid(cpu);
}到此,通过 create_boot_cache() 为 kmem_cache_node 类型建立了 slab cache,再看 create_boot_cache() 创建 kmem_cache 的 slab cache 的过程,和建立 kmem_cache_node slab cache 的过程几乎一样,除了 init_kmem_cache_nodes() 中建立 NUMA 管理数据部分外:
c
static int init_kmem_cache_nodes(struct kmem_cache *s)
{
int node;
/*
* 遍历所有 【处于 N_NORMAL_MEMORY 态的】NUMA 内存节点,
* 为 kmem_cache @s 分配、初始化每 NUMA 管理数据 kmem_cache_node.
*/
for_each_node_state(node, N_NORMAL_MEMORY) {
struct kmem_cache_node *n;
if (slab_state == DOWN) {
...
}
/*
* 分配 kmem_cache_node 对象.
*
* 已经建立了 kmem_cache_node 对象的 slab 分配池, 可以
* 通过 kmem_cache_alloc() 接口从 kmem_cache_node 指针
* 指向的 kmem_cache 对象分配 kmem_cache_node 对象了。
*/
n = kmem_cache_alloc_node(kmem_cache_node,
GFP_KERNEL, node);
init_kmem_cache_node(n);
s->node[node] = n; /* NUMA 节点 @node 的 kmem_cache_node 对象 */
}
}kmem_cache_alloc_node() 放到后面的 3.3.1 分配中再分析,这里理解到分配了一个 kmem_cache_node 对象即可。继续看 init_kmem_cache_node():
c
static void
init_kmem_cache_node(struct kmem_cache_node *n)
{
n->nr_partial = 0;
spin_lock_init(&n->list_lock);
INIT_LIST_HEAD(&n->partial);
...
}此时,kmem_cache 和 kmem_cache_node 的 slab 已经初始化好,已经可以通过 kmem_cache_*alloc() 系列接口分配 kmem_cache 和 kmem_cache_node 的 slab 对象了。当前,mm/slab_common.c 中定义的 struct kmem_cache *kmem_cache; 和 mm/slub.c 中定义的 static struct kmem_cache *kmem_cache_node; 这两个 kmem_cache 对象指针,指向 kmem_cache_init() 定义的 __initdata:
c
void __init kmem_cache_init(void)
{
static __initdata struct kmem_cache boot_kmem_cache,
boot_kmem_cache_node;
...
kmem_cache_node = &boot_kmem_cache_node;
kmem_cache = &boot_kmem_cache;
...
}__initdata 修饰的数据在内核初始化阶段完成后,是会被释放掉的,这样会导致 struct kmem_cache *kmem_cache; 和 static struct kmem_cache *kmem_cache_node; 访问非法地址(UAF),这显然是不行的。既然现在已经初始化了 kmem_cache 对象的 slab,是时候从 kmem_cache 对象的 slab 分配来替换这两个静态定义的、__initdata 类型的 kmem_cache 了:
c
void __init kmem_cache_init(void)
{
...
kmem_cache = bootstrap(&boot_kmem_cache);
/*
* Allocate kmem_cache_node properly from the kmem_cache slab.
* kmem_cache_node is separately allocated so no need to
* update any list pointers.
*/
kmem_cache_node = bootstrap(&boot_kmem_cache_node);
...
}
static struct kmem_cache * __init bootstrap(struct kmem_cache *static_cache)
{
int node;
struct kmem_cache *s = kmem_cache_zalloc(kmem_cache, GFP_NOWAIT);
struct kmem_cache_node *n;
memcpy(s, static_cache, kmem_cache->object_size);
/*
* This runs very early, and only the boot processor is supposed to be
* up. Even if it weren't true, IRQs are not up so we couldn't fire
* IPIs around.
*/
/* 释放 per-cpu 的 slab page 到 NUMA 的 slab page 列表 (如果存在的话) */
__flush_cpu_slab(s, smp_processor_id());
for_each_kmem_cache_node(s, node, n) { /* 遍历 slab 关联的所有 NUMA 节点 */
struct page *p;
list_for_each_entry(p, &n->partial, lru) /* 遍历 NUMA 节点的所有 slab page */
p->slab_cache = s; /* 关联 page 到当前的 slab cache @s */
...
}
...
list_add(&s->list, &slab_caches);
...
return s;
}初始化阶段,最后对 Linux 内建的 2 的幂次大小(外加 96, 192 两个大小)的各种 slab 的建立:
c
void __init kmem_cache_init(void)
{
...
/* Now we can use the kmem_cache to allocate kmalloc slabs */
setup_kmalloc_cache_index_table(); /* 一些系统配置下,需要修正 slab cache 索引表 */
create_kmalloc_caches(0); /* 为内置 size 创建 slab */
...
}
/* 一些系统配置下,需要修正 slab cache 索引表 */
void __init setup_kmalloc_cache_index_table(void)
{
int i;
...
for (i = 8; i < KMALLOC_MIN_SIZE; i += 8) {
int elem = size_index_elem(i);
if (elem >= ARRAY_SIZE(size_index))
break;
size_index[elem] = KMALLOC_SHIFT_LOW;
}
if (KMALLOC_MIN_SIZE >= 64) {
/*
* The 96 byte size cache is not used if the alignment
* is 64 byte.
*/
for (i = 64 + 8; i <= 96; i += 8)
size_index[size_index_elem(i)] = 7;
}
if (KMALLOC_MIN_SIZE >= 128) {
/*
* The 192 byte sized cache is not used if the alignment
* is 128 byte. Redirect kmalloc to use the 256 byte cache
* instead.
*/
for (i = 128 + 8; i <= 192; i += 8)
size_index[size_index_elem(i)] = 8;
}
}
void __init create_kmalloc_caches(unsigned long flags)
{
int i;
for (i = KMALLOC_SHIFT_LOW; i <= KMALLOC_SHIFT_HIGH; i++) {
if (!kmalloc_caches[i])
new_kmalloc_cache(i, flags);
/*
* Caches that are not of the two-to-the-power-of size.
* These have to be created immediately after the
* earlier power of two caches
*/
if (KMALLOC_MIN_SIZE <= 32 && !kmalloc_caches[1] && i == 6)
new_kmalloc_cache(1, flags);
if (KMALLOC_MIN_SIZE <= 64 && !kmalloc_caches[2] && i == 7)
new_kmalloc_cache(2, flags);
}
/* Kmalloc array is now usable */
slab_state = UP; /* 标记 slab 分配器已经完全就绪 */
#ifdef CONFIG_ZONE_DMA
/* 建立 DMA 特定的 slab cache */
for (i = 0; i <= KMALLOC_SHIFT_HIGH; i++) {
struct kmem_cache *s = kmalloc_caches[i];
if (s) {
int size = kmalloc_size(i);
char *n = kasprintf(GFP_NOWAIT,
"dma-kmalloc-%d", size);
BUG_ON(!n);
kmalloc_dma_caches[i] = create_kmalloc_cache(n,
size, SLAB_CACHE_DMA | flags);
}
}
#endif
}
static void __init new_kmalloc_cache(int idx, unsigned long flags)
{
kmalloc_caches[idx] = create_kmalloc_cache(kmalloc_info[idx].name,
kmalloc_info[idx].size, flags);
}
struct kmem_cache *__init create_kmalloc_cache(const char *name, size_t size,
unsigned long flags)
{
struct kmem_cache *s = kmem_cache_zalloc(kmem_cache, GFP_NOWAIT);
...
create_boot_cache(s, name, size, flags);
list_add(&s->list, &slab_caches);
...
s->refcount = 1;
return s;
}create_boot_cache() 在前面已经分析过,在此就不再赘述了。到此,slab 分配器的初始化已经完成,slab 分配器当前处于 UP 状态。
3.3 slub 的 分配 和 释放
Linux 内核从 include/linux/slab.h 导出了一系列的分配和释放接口,这里只列举几个典型的接口,其它类似接口就不一一列举了。
c
static __always_inline void *kmalloc(size_t size, gfp_t flags)
{
...
}
void kfree(const void *);
c
void *kmem_cache_alloc(struct kmem_cache *, gfp_t flags) __assume_slab_alignment __malloc;
void kmem_cache_free(struct kmem_cache *, void *);
#ifdef CONFIG_NUMA
...
/* 从 NUMA 节点 @node 分配 slab 对象 */
void *kmem_cache_alloc_node(struct kmem_cache *, gfp_t flags, int node) __assume_slab_alignment __malloc;
#else
...
/* 从 NUMA 节点 @node 分配 slab 对象 */
static __always_inline void *kmem_cache_alloc_node(struct kmem_cache *s, gfp_t flags, int node)
{
return kmem_cache_alloc(s, flags);
}
#endifkmalloc*() 基本可以认为是对 kmem_cache_alloc_*() 的封装,kfree() 和 kmem_cache_free() 都是将内存归还给对应的 slab cache 对象 kmem_cache 。
接下来对分配释放接口做细致的分析。
3.3.1 分配
3.3.1.1 kmalloc()
先来看 kmalloc() 接口的分配过程:
c
static __always_inline void *kmalloc(size_t size, gfp_t flags)
{
if (__builtin_constant_p(size)) {
/*
* 如果 分配大内存,无法从内置 size 的 slab cache 分配,则
* 直接从 buddy 申请整页,申请的内存不会纳入 slab 管理,释
* 放也是直接还给 buddy 。
*/
if (size > KMALLOC_MAX_CACHE_SIZE)
return kmalloc_large(size, flags);
#ifndef CONFIG_SLOB
if (!(flags & GFP_DMA)) {
/* 确定从哪个内置的 kmem_cache 分配 */
int index = kmalloc_index(size);
if (!index)
return ZERO_SIZE_PTR;
/* 从 kmem_cache @kmalloc_caches[index] 分配 @size 的内存 */
return kmem_cache_alloc_trace(kmalloc_caches[index],
flags, size);
}
#endif
}
return __kmalloc(size, flags);
}kmalloc() 的分配逻辑是检查请求内存的 size:如果请求的是大内存块,则走 kmalloc_large(),不会经过 slab 管理器,申请和释放的目标都是 buddy;如果请求的不是大内存块,则找到和 size 最佳匹配的内置 slab cache,然后再从其上分配。size 参数是否为常量导致分配路径又稍有不同,如下所示:
size参数是常量的分配路径
c
kmalloc()
if (size > KMALLOC_MAX_CACHE_SIZE)
return kmalloc_large(size, flags);
int index = kmalloc_index(size);
kmem_cache_alloc_trace(kmalloc_caches[index], ...)
// 这样的常量比较,在编译器端应该可以做出优化
static __always_inline int kmalloc_index(size_t size)
{
if (!size)
return 0;
if (size <= KMALLOC_MIN_SIZE)
return KMALLOC_SHIFT_LOW;
if (KMALLOC_MIN_SIZE <= 32 && size > 64 && size <= 96)
return 1;
if (KMALLOC_MIN_SIZE <= 64 && size > 128 && size <= 192)
return 2;
if (size <= 8) return 3;
if (size <= 16) return 4;
if (size <= 32) return 5;
if (size <= 64) return 6;
if (size <= 128) return 7;
if (size <= 256) return 8;
if (size <= 512) return 9;
if (size <= 1024) return 10;
if (size <= 2 * 1024) return 11;
if (size <= 4 * 1024) return 12;
if (size <= 8 * 1024) return 13;
if (size <= 16 * 1024) return 14;
if (size <= 32 * 1024) return 15;
if (size <= 64 * 1024) return 16;
if (size <= 128 * 1024) return 17;
if (size <= 256 * 1024) return 18;
if (size <= 512 * 1024) return 19;
if (size <= 1024 * 1024) return 20;
if (size <= 2 * 1024 * 1024) return 21;
if (size <= 4 * 1024 * 1024) return 22;
if (size <= 8 * 1024 * 1024) return 23;
if (size <= 16 * 1024 * 1024) return 24;
if (size <= 32 * 1024 * 1024) return 25;
if (size <= 64 * 1024 * 1024) return 26;
BUG();
/* Will never be reached. Needed because the compiler may complain */
return -1;
}size参数不是常量的分配路径
c
kmalloc()
__kmalloc()
struct kmem_cache *s;
if (unlikely(size > KMALLOC_MAX_CACHE_SIZE))
return kmalloc_large(size, flags);
...
s = kmalloc_slab(size, flags); /* 根据 {@size, @flags} 选取内置 slab cache,从其中分配内存 */
slab_alloc(s, ...)
struct kmem_cache *kmalloc_slab(size_t size, gfp_t flags)
{
int index;
if (size <= 192) { /* <= 192 的 size, slab cache index 的计算比较特殊 */
if (!size)
return ZERO_SIZE_PTR;
index = size_index[size_index_elem(size)];
} else { /* 按 2 的幂次计算 slab cache index */
if (unlikely(size > KMALLOC_MAX_CACHE_SIZE)) {
WARN_ON(1);
return NULL;
}
index = fls(size - 1);
}
#ifdef CONFIG_ZONE_DMA
if (unlikely((flags & GFP_DMA)))
return kmalloc_dma_caches[index];
#endif
return kmalloc_caches[index];
}可见,不论哪种路径,都会走到 slab_alloc(),只是对 slab cache 的选择代码细节上稍有不同。slab_alloc() 的细节将在 3.3.1.2 kmem_cache_alloc_node() 展开,这里不做赘述。
3.3.1.2 kmem_cache_alloc_node()
c
void *kmem_cache_alloc_node(struct kmem_cache *s, gfp_t gfpflags, int node)
{
void *ret = slab_alloc_node(s, gfpflags, node, _RET_IP_);
...
return ret;
}
static __always_inline void *slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr)
{
void *object;
struct kmem_cache_cpu *c;
struct page *page;
unsigned long tid;
...
redo:
do {
tid = this_cpu_read(s->cpu_slab->tid);
c = raw_cpu_ptr(s->cpu_slab);
} while (IS_ENABLED(CONFIG_PREEMPT) &&
unlikely(tid != READ_ONCE(c->tid)));
barrier();
object = c->freelist; /* 从 cpu slab 缓存空闲对象列表分配一个 object */
page = c->page;
if (unlikely(!object || !node_match(page, node))) { /* 慢路径分配: cpu slab 缓存为空 或 NUMA 节点不匹配 */
object = __slab_alloc(s, gfpflags, node, addr, c);
stat(s, ALLOC_SLOWPATH);
} else { /* 快路径分配 */
void *next_object = get_freepointer_safe(s, object); /* cpu slab 缓存空闲列表中【下一】对象 */
/*
* 更新空闲列表:
* - 将分配的 @object 从空闲列表移除,空闲列表头指向下一个 object @next_object
* - 更新 tid
*/
if (unlikely(!this_cpu_cmpxchg_double(
s->cpu_slab->freelist, s->cpu_slab->tid,
object, tid,
next_object, next_tid(tid)))) {
note_cmpxchg_failure("slab_alloc", s, tid);
goto redo;
}
prefetch_freepointer(s, next_object); /* 预取加速 */
stat(s, ALLOC_FASTPATH);
}
...
return object;
}类似 buddy 的分配快慢路径,slab 分配器同样也有分配的快慢路径:快路径从 per-cpu 的 slab 空闲链表,通过 get_freepointer_safe() 分配一个 object:
c
static inline void *get_freepointer_safe(struct kmem_cache *s, void *object)
{
...
if (!debug_pagealloc_enabled())
return get_freepointer(s, object);
...
}
static inline void *freelist_ptr(const struct kmem_cache *s, void *ptr,
unsigned long ptr_addr)
{
#ifdef CONFIG_SLAB_FREELIST_HARDENED
...
#else
return ptr;
#endif
}慢路径首先尝试从当前 NUMA 节点缓存的 slab page 分配,其次按距离由近及远从其它 NUAM 节点缓存的 slab page 分配,最后从 buddy 申请 page 再分配:
c
static void *__slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c)
{
void *p;
unsigned long flags;
local_irq_save(flags);
#ifdef CONFIG_PREEMPT
/*
* We may have been preempted and rescheduled on a different
* cpu before disabling interrupts. Need to reload cpu area
* pointer.
*/
c = this_cpu_ptr(s->cpu_slab);
#endif
p = ___slab_alloc(s, gfpflags, node, addr, c);
local_irq_restore(flags);
return p; /* 返回分配的对象地址 */
}
static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c)
{
void *freelist;
struct page *page;
// (1)
page = c->page; /* 首先尝试从 CPU 上当前 page 分配 object */
if (!page)
goto new_slab; /* 当前 CPU 上没有 page 可供分配, 需要申请 slab page */
...
// (3)
load_freelist:
/*
* freelist is pointing to the list of objects to be used.
* page is pointing to the page from which the objects are obtained.
* That page must be frozen for per cpu allocations to work.
*/
VM_BUG_ON(!c->page->frozen);
c->freelist = get_freepointer(s, freelist); /* 将分配的对象从空闲列表移除 */
c->tid = next_tid(c->tid);
return freelist; /* 返回分配的对象地址 */
// (2)
new_slab:
...
/*
* 当前 CPU 没有 slab page 可供分配, 则尝试从 NUMA 节点拿
* 取 page, 继续进行对象分配操作; 如果失败, 则从 buddy 拿
* 取 page, 然后再执行对象分配。
*/
freelist = new_slab_objects(s, gfpflags, node, &c);
...
page = c->page;
if (likely(!kmem_cache_debug(s) && pfmemalloc_match(page, gfpflags)))
goto load_freelist;
...
}首次从某个对象的 slab cache 分配,上面的代码的 3 个代码片段按 (1)、(2)、(3) 的顺序执行:
bash
(1) 尝试从当前 CPU 的当前 slab cache page 分配。
(2) 通过 new_slab_objects() 从 NUMA 节点 slab cache page 分配。
如果 从 NUMA 节点分配失败,则从 buddy 分配。
(3) 设定 CPU 的 空闲 object 列表 和 tid,返回分配的 object继续深入分析 new_slab_objects():
c
static inline void *new_slab_objects(struct kmem_cache *s, gfp_t flags,
int node, struct kmem_cache_cpu **pc)
{
void *freelist;
struct kmem_cache_cpu *c = *pc;
struct page *page;
...
/*
* 从 NUMA 节点的 partial slab page 分配成失败,
* 则从 buddy 申请 page 构建新的 slab .
*/
page = new_slab(s, flags, node);
if (page) { /* 从 buddy 申请 page 成功 */
c = raw_cpu_ptr(s->cpu_slab);
...
/*
* No other reference to the page yet so we can
* muck around with it freely without cmpxchg
*/
freelist = page->freelist;
page->freelist = NULL;
stat(s, ALLOC_SLAB);
/* 从 buddy 分配的 page 作为 CPU 的当前分配 page */
c->page = page;
*pc = c;
} else
freelist = NULL;
return freelist;
}
new_slab()
allocate_slab()在前面的章节 3.2 slub 初始化 中,对调用链 new_slab() -> allocate_slab() 已经做过分析,在此不再赘述。
3.3.2 释放
3.3.2.1 kfree()
c
void kfree(const void *x)
{
struct page *page;
void *object = (void *)x;
trace_kfree(_RET_IP_, x);
if (unlikely(ZERO_OR_NULL_PTR(x)))
return;
page = virt_to_head_page(x); /* 获取 虚拟地址 @x 关联物理页面的 struct page */
if (unlikely(!PageSlab(page))) { /* 直接从 buddy 申请的大内存, 没有走 slab (即不经 kmem_cache 管理) */
BUG_ON(!PageCompound(page));
kfree_hook(x);
__free_pages(page, compound_order(page)); /* 直接归还给 buddy */
return;
}
/* 释放经 slab (kmem_cache) 管理的小内存 */
slab_free(page->slab_cache, page, object, NULL, 1, _RET_IP_);
}
slab_free()
do_slab_free()
static __always_inline void do_slab_free(struct kmem_cache *s,
struct page *page, void *head, void *tail,
int cnt, unsigned long addr)
{
void *tail_obj = tail ? : head;
struct kmem_cache_cpu *c;
unsigned long tid;
redo:
/*
* Determine the currently cpus per cpu slab.
* The cpu may change afterward. However that does not matter since
* data is retrieved via this pointer. If we are on the same cpu
* during the cmpxchg then the free will succeed.
*/
do {
tid = this_cpu_read(s->cpu_slab->tid);
c = raw_cpu_ptr(s->cpu_slab);
} while (IS_ENABLED(CONFIG_PREEMPT) &&
unlikely(tid != READ_ONCE(c->tid)));
/* Same with comment on barrier() in slab_alloc_node() */
barrier();
if (likely(page == c->page)) { /* 快路径: 释放 object 到 cpu slab cache 的 freelist */
set_freepointer(s, tail_obj, c->freelist);
/* 尝试将 @head 释放到 c->freelist 列表头部 */
if (unlikely(!this_cpu_cmpxchg_double(
s->cpu_slab->freelist, s->cpu_slab->tid,
c->freelist, tid,
head, next_tid(tid)))) {
note_cmpxchg_failure("slab_free", s, tid);
/*
* 期间 CPU 空闲链表(s->cpu_slab->freelist 或 s->cpu_slab->tid)
* 发生了变化,为保持一致性,重新发起释放操作。
*/
goto redo;
}
stat(s, FREE_FASTPATH);
} else /* 慢路径 */
__slab_free(s, page, head, tail_obj, cnt, addr);
}可以看到,释放也分为快慢两种路径。快路径直接将 object 归还到 CPU slab cache 的空闲列表,而慢路径则是经过 __slab_free():
c
static void __slab_free(struct kmem_cache *s, struct page *page,
void *head, void *tail, int cnt,
unsigned long addr)
{
void *prior;
int was_frozen;
struct page new;
unsigned long counters;
struct kmem_cache_node *n = NULL;
unsigned long uninitialized_var(flags);
...
do {
if (unlikely(n)) {
spin_unlock_irqrestore(&n->list_lock, flags);
n = NULL;
}
prior = page->freelist;
counters = page->counters;
set_freepointer(s, tail, prior); /* tail => prior */
new.counters = counters;
was_frozen = new.frozen;
new.inuse -= cnt;
if ((!new.inuse || !prior) && !was_frozen) {
if (kmem_cache_has_cpu_partial(s) && !prior) {
/*
* Slab was on no list before and will be
* partially empty
* We can defer the list move and instead
* freeze it.
*/
new.frozen = 1;
} else { /* Needs to be taken off a list */
n = get_node(s, page_to_nid(page));
/*
* Speculatively acquire the list_lock.
* If the cmpxchg does not succeed then we may
* drop the list_lock without any processing.
*
* Otherwise the list_lock will synchronize with
* other processors updating the list of slabs.
*/
spin_lock_irqsave(&n->list_lock, flags);
}
}
/* 归还的 object 到插入到空闲列表头部 */
} while (!cmpxchg_double_slab(s, page,
prior, counters,
head, new.counters,
"__slab_free"));
if (likely(!n)) {
/*
* If we just froze the page then put it onto the
* per cpu partial list.
*/
if (new.frozen && !was_frozen) {
/*
* 将 @page 放入 cpu partial page 列表。
* 在一定条件下, 触发将 cpu partial 列表中的 page
* 放入 NUMA 的 partial page 列表。
*/
put_cpu_partial(s, page, 1);
stat(s, CPU_PARTIAL_FREE);
}
/*
* The list lock was not taken therefore no list
* activity can be necessary.
*/
if (was_frozen)
stat(s, FREE_FROZEN);
return;
}
/* 如果 NUMA 节点持有的 partial page 数目超过阈值,则归还 page 给 buddy */
if (unlikely(!new.inuse && n->nr_partial >= s->min_partial))
goto slab_empty;
/*
* Objects left in the slab. If it was not on the partial list before
* then add it.
*/
if (!kmem_cache_has_cpu_partial(s) && unlikely(!prior)) {
if (kmem_cache_debug(s))
remove_full(s, n, page);
add_partial(n, page, DEACTIVATE_TO_TAIL);
stat(s, FREE_ADD_PARTIAL);
}
spin_unlock_irqrestore(&n->list_lock, flags);
return; /* 释放 object 后返回 */
slab_empty:
if (prior) {
/*
* Slab on the partial list.
*/
remove_partial(n, page);
stat(s, FREE_REMOVE_PARTIAL);
} else {
/* Slab must be on the full list */
remove_full(s, n, page);
}
spin_unlock_irqrestore(&n->list_lock, flags);
stat(s, FREE_SLAB);
discard_slab(s, page); /* 归还给 buddy */
}3.3.2.2 kmem_cache_free()
c
void kmem_cache_free(struct kmem_cache *s, void *x)
{
s = cache_from_obj(s, x);
if (!s)
return;
slab_free(s, virt_to_head_page(x), x, NULL, 1, _RET_IP_);
...
}
static inline struct kmem_cache *cache_from_obj(struct kmem_cache *s, void *x)
{
struct kmem_cache *cachep;
struct page *page;
/*
* When kmemcg is not being used, both assignments should return the
* same value. but we don't want to pay the assignment price in that
* case. If it is not compiled in, the compiler should be smart enough
* to not do even the assignment. In that case, slab_equal_or_root
* will also be a constant.
*/
if (!memcg_kmem_enabled() &&
!unlikely(s->flags & SLAB_CONSISTENCY_CHECKS))
return s;
...
}slab_free() 在 3.3.2.1 kfree() 已经分析过了,在此不再赘述。
3.3.3 小结
我们对 slab 的分配和释放过程做下小结:
-
分配过程
首次分配,会从 buddy 分配 page,然后放入 CPU 的 slab cache,作为当前分配 page (kmem_cache_cpu::page),如果首次分配的 page 不止一个,除用于当前分配的 page (kmem_cache_cpu::page) 外,其它 page 放入 CPU slab cache 的 partial 列表 (kmem_cache_cpu::partial) 备用;后续分配,首先从 CPU 当前分配 page (kmem_cache_cpu::page) 分配 object,如果 CPU 当前分配 page 被分配完,则从 CPU 的 partial page 列表 (kmem_cache_cpu::partial) 分配一个 page 继续进行 object 分配,如果 CPU 的 partial page 列表也被分配完,则尝试从 NUMA 节点的 partial page 列表(kmem_cache_node::partial) 分配 page 来分配 object,如果最后连 NUMA 节点的 partial page 列表也消耗完了,则从 buddy 申请 page 再来分配 object。 -
释放过程
释放的 object 归还给当前分配的 page (
kmem_cache_cpu::page)。如果整个 page 被变成了空闲,可能触发将 page 归还到 CPU slab cache 的 partial 列表 (kmem_cache_cpu::partial) 的过程。类似的,如果释放导致 CPU slab cache 的 partial 列表 (kmem_cache_cpu::partial) 长度达到设定的阈值,则触发将 page 归还给 NUAM 节点的 partial page 列表(kmem_cache_node::partial)过程。更进一步,如果 NUAM 节点的 partial page 列表长度达到设定的阈值,触发将 page 归还给 buddy 的过程。
另外,内核导出 /proc/slabinfo 文件节点观察 slab 分配器的状态,调试也提供了 slub debug 支持。
最后,以一张分配释放过程形成的数据结构图结束本文(某个特定场景):
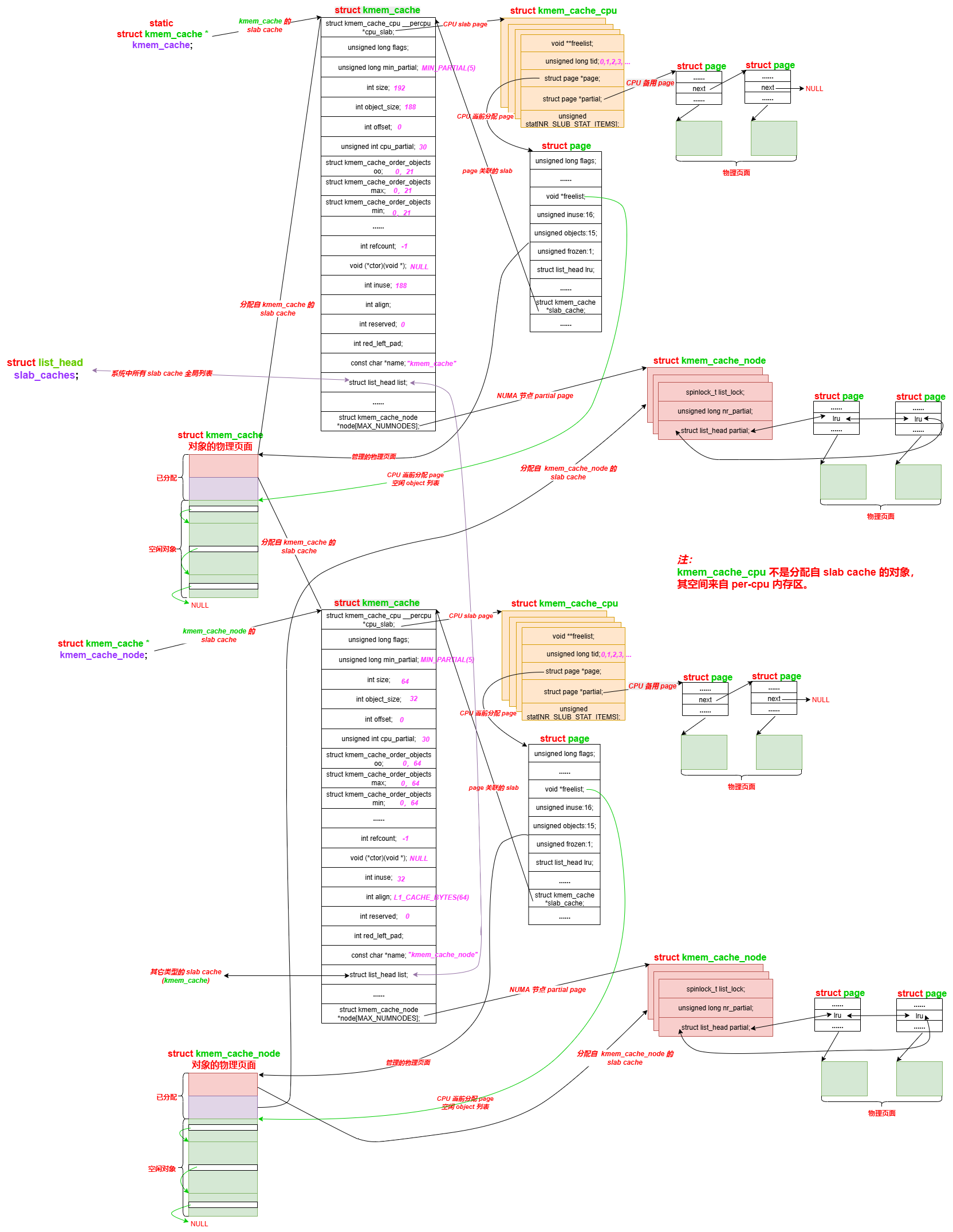
图中只展示了 kmem_cache 和 kmem_cache_node 的 slab cache,其它类型的 slab cache 类似。