概述
官网,由上海人工智能实验室OpenDataLab团队开源(GitHub,49.7K Star,4.1K Fork)的工业级文档解析+数据提取工具,专注于高效解析复杂文档(如PDF、网页、电子书、扫描图像),并将其转换为结构化的机器可读格式(如Markdown、JSON、HTML)。该项目凭借其强大的多模态解析能力,能够精准识别文本、表格、图片、数学公式(支持LaTeX转换)及复杂排版,并自动去除页眉、页脚、页码等冗余信息,保留原始文档的语义逻辑与结构。支持176种语言识别,兼容CPU/GPU/NPU加速,适用于学术研究、企业数据处理、大模型训练等场景。
官方文档,ModelScope,HuggingFace,中文文档。
论文:
技术架构:集成LayoutLMv3(布局分析)+YOLOv8(视觉识别),支持Docker和CUDA环境。
功能:
- 智能过滤页眉、页脚,精准提取PDF正文
- 支持EPUB、MOBI、DOCX转Markdown、JSON
- 内置UniMERNet模型优化公式识别精度
- 全流程解析引擎:PDF文本提取→OCR多语言识别→文档布局重建→公式/表格还原
- 37种语言混合支持:中/英/日/韩等主流语言全覆盖,特别优化东亚文字排版识别;垂直文本支持(古文献/乐谱);
- 显存动态回收机制:
- 场景化结构适配:学术论文(参考文献/章节层级)、法律文书(条款编号)、财务报表(跨页表格)均可精准还原
- 企业级安全合规,支持API和图形界面,多格式兼容
优势
- 高性能解析引擎
| 指标 | 性能表现 | 场景价值 |
|---|---|---|
| GPU吞吐量(4090) | >1w Tokens/s | 单日处理千页级文档 |
| CPU内存占用 | 最低6GB(纯文本模式) | 老旧设备可运行 |
| 批量处理效率 | 较传统方案提升500% | 企业级文档自动化处理 |
- 极简部署方案
| 使用方式 | 适用场景 | 操作示例 |
|---|---|---|
| 零安装Web版 | 快速体验/临时需求 | 访问https://mineru.net |
| 命令行工具 | Linux/macOS/Windows系统集成 | mineru -p report.pdf -o md |
| Docker GPU加速 | 生产环境一键部署 | docker run -gpus all mineru-sglang:latest |
- 开源生态扩展
py
# 自定义模型路径,加载本地OCR模型
mineru -ocr_model_path ./custom_ppocrv5- 核心扩展能力
- 模型热替换:支持PP-OCRv5、Unimernet等自定义模型
- 功能模块化:公式解析(
-formula True)、表格还原(-table True)独立开关 - 离线模式:
-source local完全断网运行 - mcp模式:支持mcp,客户端无缝调用
架构
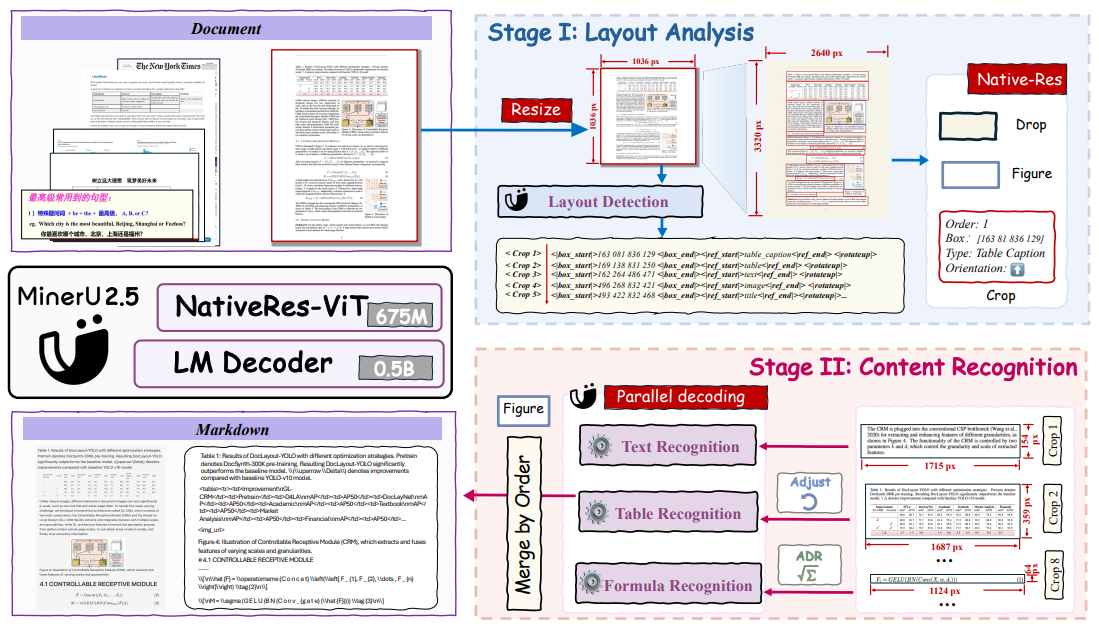
在第一阶段,MinerU2.5对下采样后的页面执行快速的全局布局分析。在第二阶段,MinerU2.5利用布局分析结果从原始高分辨率文档中裁剪出关键区域,并在这些原始分辨率的局部区域内进行细粒度的内容识别(例如,文本、表格和公式识别)。
模型架构
- 语言解码器:LLM(Qwen2-Instruct-0.5B),M-RoPE替换原始的1D-RoPE
- 视觉编码器:使用Qwen2-VL视觉编码器(NaViT-675M)进行初始化
- Patch Merge:为了在效率和性能之间取得平衡,在相邻的
2×2视觉Token上使用pixel-unshuffe对聚合后的视觉Token进行预处理,然后再将其输入LLM。
训练方法
如下图:
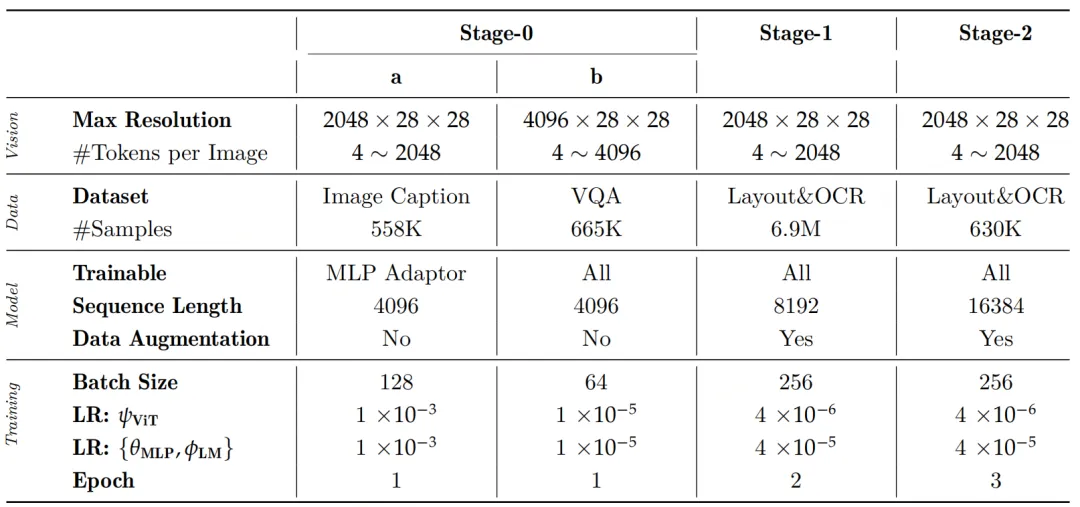
整体分三阶段训练
阶段0:模态对齐
- 图文对齐:仅训练两层MLP,冻结其他模块。Image Caption数据集训练。
- 指令微调:解冻所有模块,使用VQA数据训练。
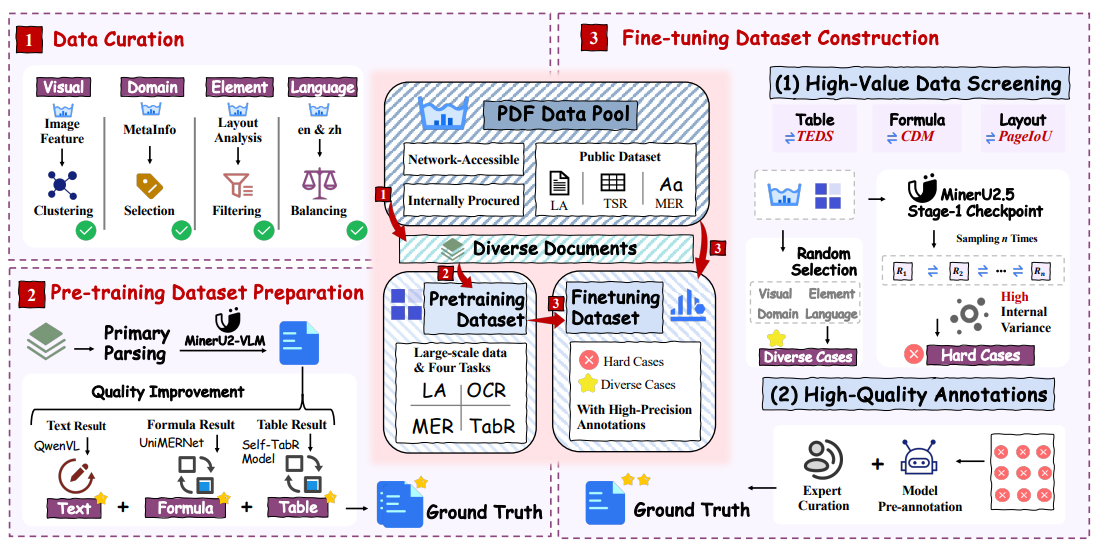
阶段1:文档解析预训练
文档解析预训练阶段的目标是使VLM具备两种能力:版面分析和内容识别,该阶段是解冻所有模块训练。
训练数据:
- 版式分析:大规模模型标注数据与公开数据集的混合数据,以确保足够的规模和文档多样性。在版面分析方面,为兼顾训练效率,将完整文档图像缩放到固定分辨率(1036×1036),并相应调整坐标,使用提示
Layout Detection
数据样式:
<|box_start |>100 200 300 400<| box_end|><|ref_start|>title <|ref_end|><|rotate_up|>
<|box_start |>400 500 600 700<| box_end|><|ref_start|>text <|ref_end|><|rotate_up|>- 内容识别:进行格式转化时,输入图像将保持其原始分辨率,但图像Token数量将限制在4到2048的值域内。若超过此限制,图像将相应地进行缩放。
- 文本:输出为markdown格式,提示词
Text Recognition: - 表格:输出为以OTSL格式(采用OTSL是因为它相较于HTML作为视觉语言模型的目标具有显著优势。其极简设计具有与表格视觉二维矩阵直接的结构对应关系,将结构Token数量从超过28个减少到仅5个,并将平均序列长度缩短约50%。这使得它成为模型生成时更高效的输出目标。最后一阶段是将OTSL输出简单转换为标准HTML。),提示词
Table Recognition: - 公式:输出为latex公式,提示词
Formula Recognition:
- 文本:输出为markdown格式,提示词
训练设置:初始化阶段0的权重,训练2轮次。每轮次总共包含690万个样本,包括230万用于版面分析,240万用于文本块,110万用于公式块,以及110万用于表格块。
阶段2:文档解析微调
目标是在保持VLM已具备的检测与解析能力的基础上,进一步提升在复杂场景下的解析性能。
训练数据:
- 通过数据工程从预训练数据集中抽取了高质量且多样化的样本,并将其纳入第二阶段训练,确保对不同文档元素类型的广泛覆盖。
- 难样本人工标注
训练配置:使用阶段1模型初始化,训练3轮。布局分析用43万样本,文本块用300万样本,公式块用147万样本,表格块用140万样本。
数据增强策略:在开放世界情景下处理多样化文档的鲁棒性,在第一阶段和第二阶段均设计多种针对性的数据增强策略,模拟常见的文档干扰类型。
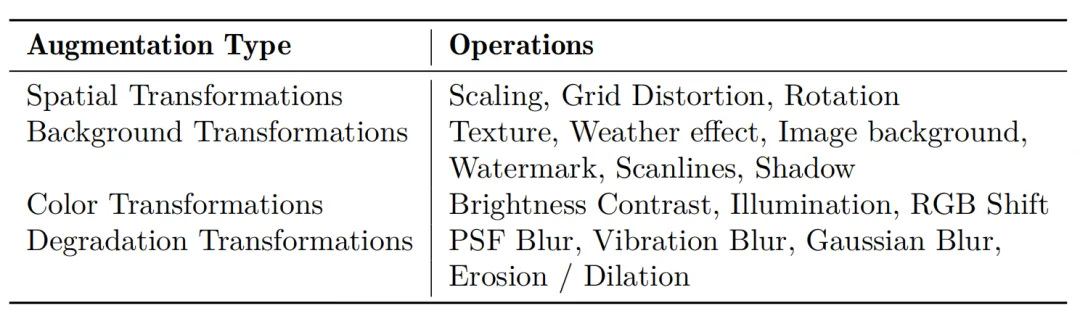
数据引擎
- 版面多样性:采用页面级图像聚类从广泛的视觉版面和风格中选择样本。
- 文档类型多样性:利用文档元数据(例如,学科、标签),进行分层采样,以确保学术论文、教科书、报告和演示文稿等类型的均衡表示。
- 元素平衡:初步的检测模型有助于确保所筛选数据集中关键元素(如标题、段落、表格、公式和图表)的类别分布均衡。
- 语言平衡:对数据进行筛选,以保持中文和英文文档的可比数量。
API
参考官方API文档,点击【API申请】需注册登录,获取Token,方能调用API。

目前提供5个API:
| 功能 | 方法 | URL |
|---|---|---|
| 创建解析任务 | POST | https://mineru.net/api/v4/extract/task |
| 获取任务结果 | GET | https://mineru.net/api/v4/extract/task/{task_id} |
| 文件批量上传解析 | POST | https://mineru.net/api/v4/extract/task/batch |
| URL批量上传解析 | POST | https://mineru.net/api/v4/file-urls/batch |
| 批量获取任务结果 | GET | https://mineru.net/api/v4/extract-results/batch/{batch_id} |
所有接口都需要添加HTTP Header:Authorization: Bearer <token>
实战
既可以在线使用,也提供各大主流平台的安装程序
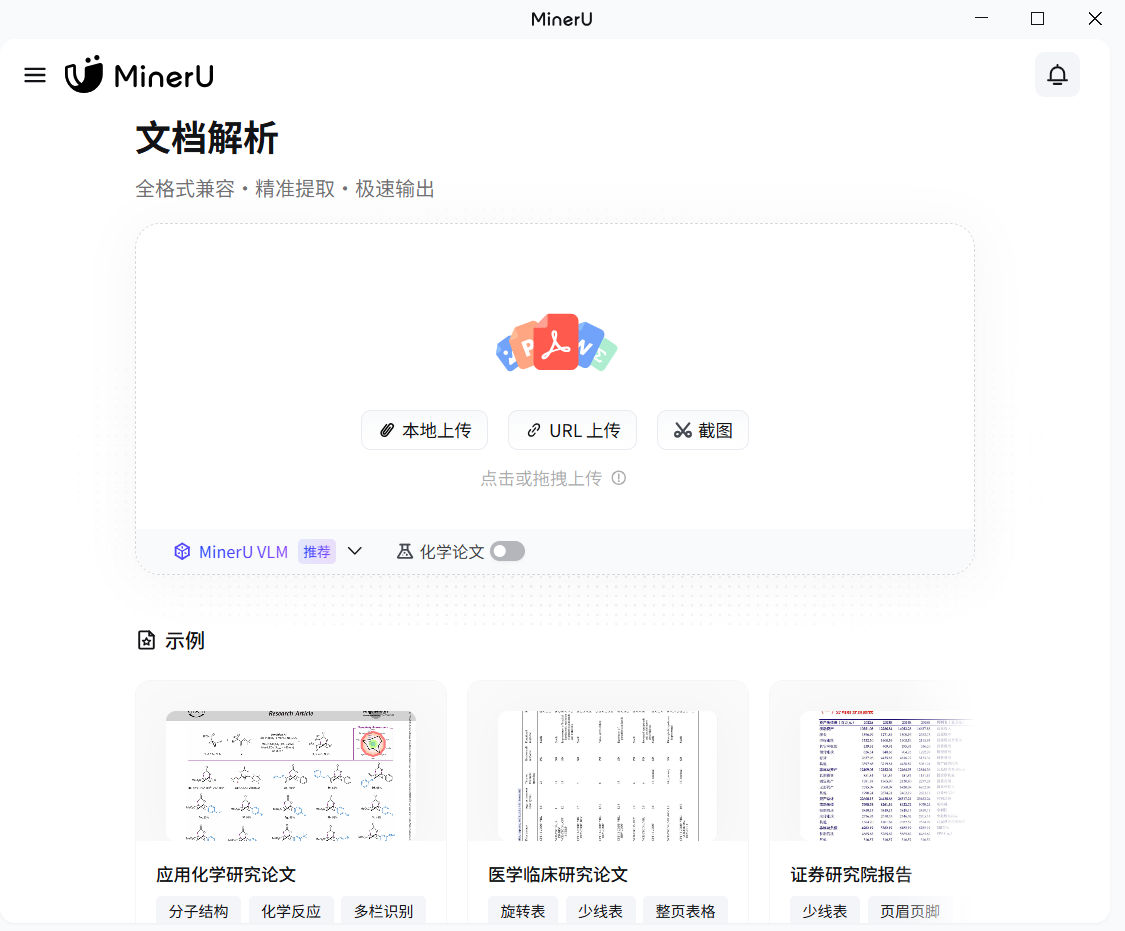
以Windows安装包MinerU-0.9.0-setup.exe为例,安装成功后,界面如下:
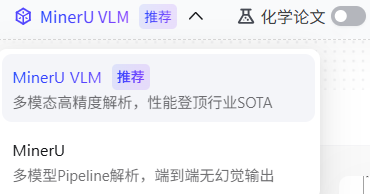
额外有个化学论文的按钮。模型有两个可选项:
点击截图,支持全屏截图。文件上传支持和限制:

测试效果
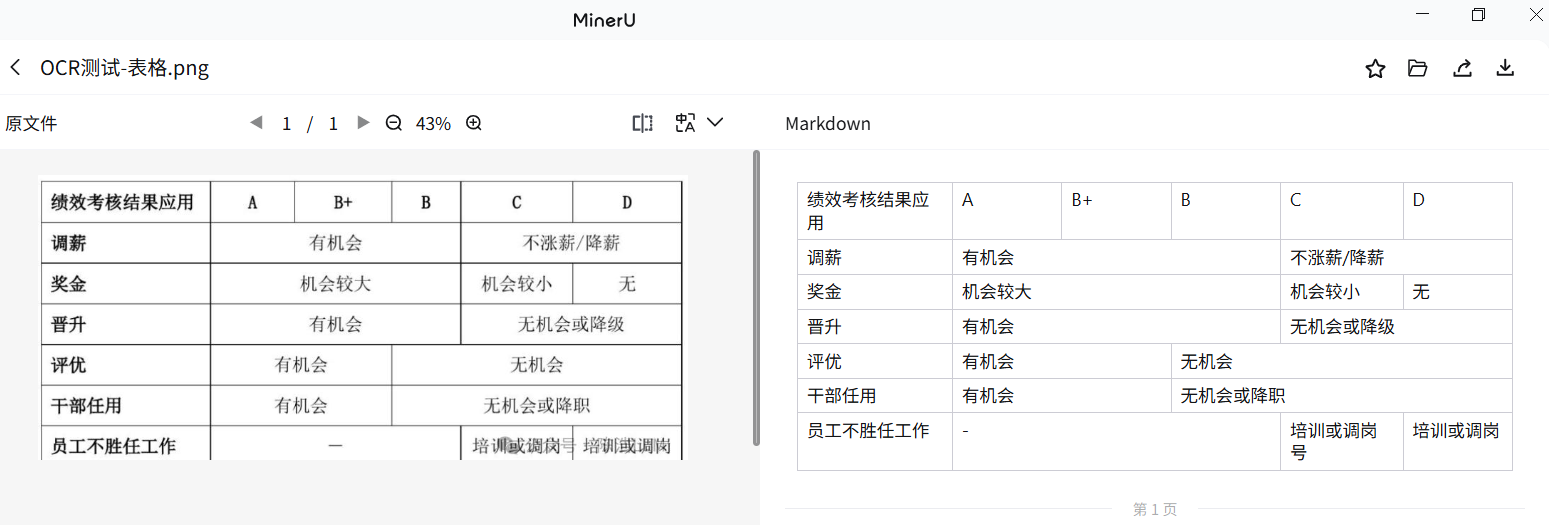
完全无误!!复制:
但导出为Markdown,格式有误,Qwen3-Max的识别和解释:

下载:
导出功能:
设置入口

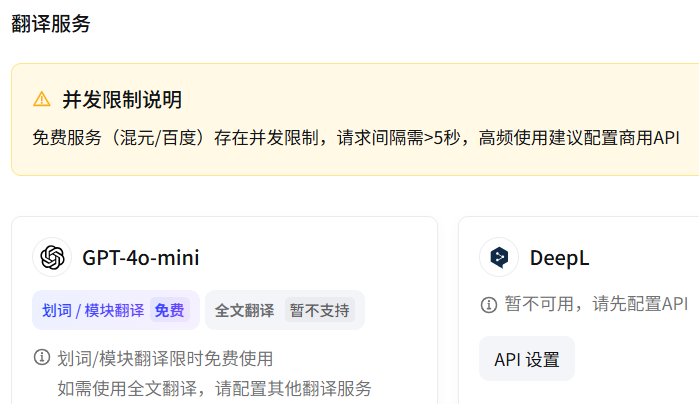
翻译服务,支持:GPT-4o-mini、DeepL、Google、Microsoft、硅基流动、阿里云百炼、腾讯混元、DeepSeek、百度等9个提供商:
本地目录生成config.json文件,JSON字符串看着有点难受(虽然可使用在线工具去转义)
处理任务在云端完成,生成结果再回传到本地。
在线模式下生成的Markdown会把图片与附件替换为云端URL,通常无需二次处理即可用于知识库。
API服务
https://mineru.net/apiManage,申请API Token,有效期较短,目前为14天,到期需重新生成。可用于本地助手,如Cherry Studio或Dify。
部署
通过Docker Compose安装:
bash
git clone https://github.com/opendatalab/MinerU.git
cd MinerU/docker/
docker compose up -d浏览器打开http://localhost:8000开始体验。
通过pip安装:
bash
# 基础环境配置
conda create -n mineru python=3.10
pip install "mineru[core]" # 安装核心包
pip install -U magic-pdf[full] # 安装扩展包
# 启用SGLANG加速(需NVIDIA显卡)
mineru -p input.pdf -o outputs -b vlm-sglang-client -u http://localhost:30000硬件配置推荐指南
| 后端模式 | GPU要求 | CPU/内存 | 适用场景 |
|---|---|---|---|
| Pipeline (CPU) | 无需GPU | ≥16核 / 32GB | 合同/发票等简单文档 |
| VLM Transformers | ≥8GB显存 (Turing架构+) | ≥8核 / 16GB | 学术论文(含复杂表格) |
| VLM SGLANG | ≥8GB显存 | ≥16核 / 32GB | 100+页医学报告批量处理 |
通过PythonSDK,PDF转Markdown示例:
py
import os
from loguru import logger
from magic_pdf.pipe.UNIPipe import UNIPipe
from magic_pdf.rw.DiskReaderWriter import DiskReaderWriter
pdf_name = '2026全球经济金融展望报告'
pdf_path = os.path.join('data', f"{pdf_name}.pdf")
output_dir = os.path.join('data', pdf_name)
if not os.path.exists(output_dir):
os.makedirs(output_dir, exist_ok=True)
local_image_dir = os.path.join(output_dir, 'images')
output_filename = os.path.join(output_dir, pdf_name)
if os.path.exists(output_filename + ".md"):
logger.info("The preprocessing result already exists.")
try:
pdf_bytes = open(pdf_path, "rb").read()
jso_useful_key = {"_pdf_type": "", "model_list": []}
image_dir = str(os.path.basename(local_image_dir))
image_writer = DiskReaderWriter(local_image_dir)
pipe = UNIPipe(pdf_bytes, jso_useful_key, image_writer)
pipe.pipe_classify()
pipe.pipe_analyze()
pipe.pipe_parse()
md_content = pipe.pipe_mk_markdown(image_dir, drop_mode="none")
with open(f"{output_filename}.md", "w", encoding="utf-8") as f:
f.write(md_content)
except Exception as e:
logger.error(e)