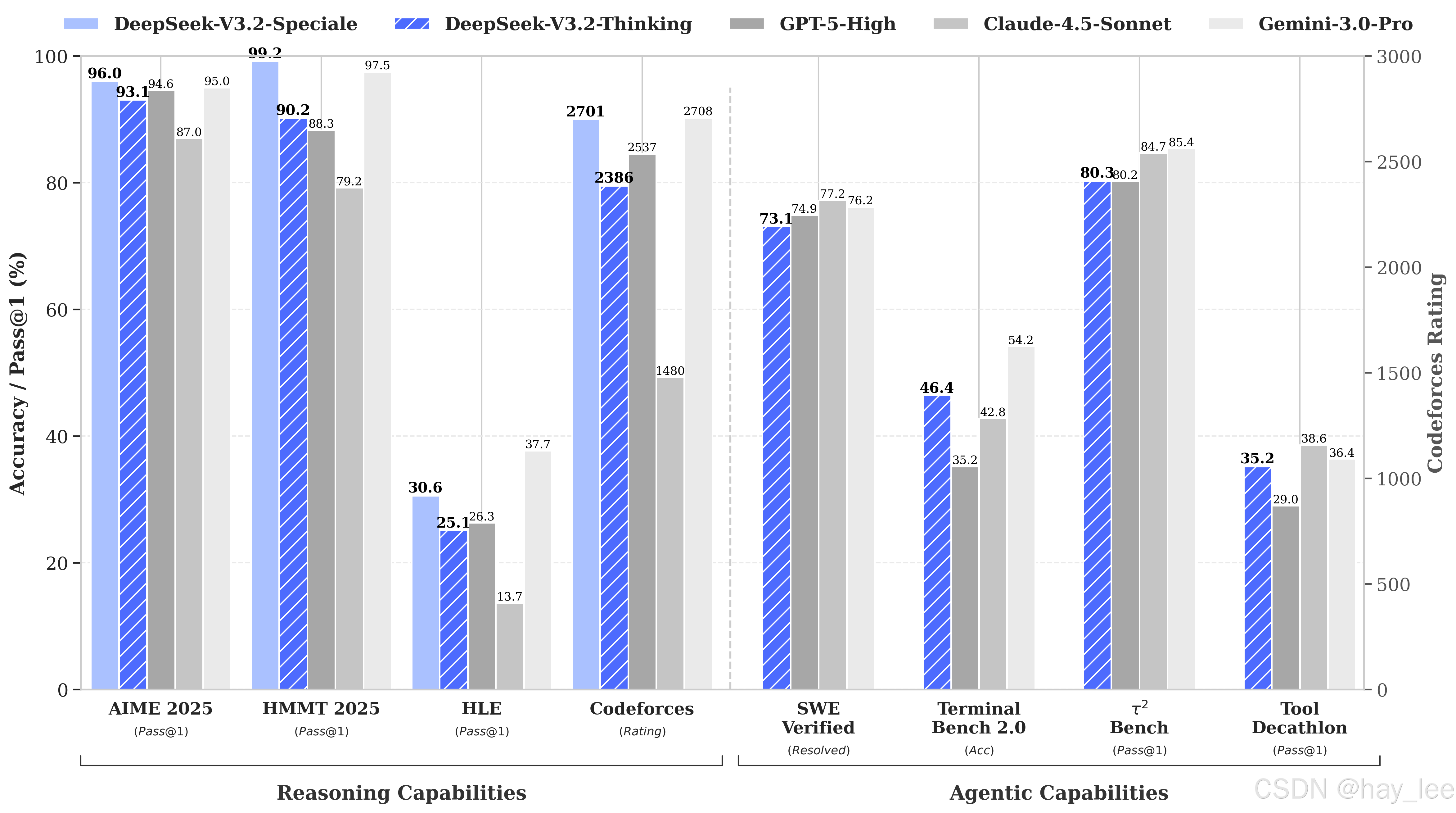
**12月1日,深度求索(DeepSeek)正式开源 DeepSeek-V3.2 与 V3.2-Speciale 两款大语言模型。**它们不仅在 国际数学奥林匹克(IMO) 和 国际信息学奥林匹克(IOI) 中达成"金牌级"自动解题能力,更在多项权威基准上 追平 GPT-5,甚至在推理任务上超越它、比肩 Gemini-3.0-Pro。
两款模型有着不同的定位:
DeepSeek-V3.2的目标是平衡推理能力与输出长度,适合日常使用,例如问答场景和通用智能体任务场景。9月底DeepSeek发布了实验版V3.2-Exp,此次是正式版更新。在公开推理测试中,V3.2达到了GPT-5的水平,仅略低于谷歌的Gemini3 Pro。
DeepSeek-V3.2-Speciale则是此次的重头戏,其目标是"将开源模型的推理能力推向极致,探索模型能力的边界"。据介绍,Speciale是V3.2的长思考增强版,同时结合了DeepSeek-Math-V2的定理证明能力,该模型具备出色的指令跟随、严谨的数学证明与逻辑验证能力。超越了 GPT-5,并在推理能力上与 Gemini-3.0-Pro 相当。
本次发布的模型突破了三个关键技术点:高效的稀疏注意力机制(DSA)、可扩展的强化学习训练框架,以及大规模智能体任务合成流水线。
一、DSA:让长上下文"又快又准"的稀疏注意力机制
处理 128K 上下文,传统 Transformer 的 O(L²) 注意力机制会迅速吃光显存,拖慢推理速度。
DeepSeek-V3.2 引入自研的 DeepSeek Sparse Attention(DSA),巧妙解决这一难题。
DSA 核心由两部分组成:
-
闪电索引器:用极少量轻量头(支持 FP8)快速判断哪些历史 token 与当前查询最相关;
-
细粒度 Top-k 选择:仅保留 2048 个关键 key-value 对参与计算,将复杂度从 O(L²) 降至 O(L·k)。
更关键的是,DSA 并非简单"剪枝",而是通过 两阶段训练(先 KL 对齐密集注意力分布,再端到端稀疏微调),确保性能无损甚至略有提升。在 AA-LCR3、Fiction.liveBench 等长文本推理任务中,V3.2 表现优于前代模型。
在DSA机制的加持下,128K的序列推理成本可以降低60%以上,并且让推理速度提升约3.5倍速度,内存占用则减少70%,同时模型本身的性能没有明显下降,可以说从根本上改变了AI大模型在注意力领域的表现。
根据官方提供的数据,在H800集群上进行AI模型测试时,在序列长度达到128K时,预填充阶段每百万token的成本从0.7美元降到了0.2美元左右,解码阶段则是从2.4美元降到了0.8美元,让DeepSeek V3.2可能成为同级别AI大模型里长文本推理成本最低的模型。
二、可扩展强化学习:RL 预算超预训练 10%,释放推理极限
多数开源模型止步于监督微调(SFT),但 DeepSeek-V3.2 把 强化学习(RL)后训练预算提升至预训练成本的 10% 以上。
基于自研的 Scaling GRPO 算法,团队引入多项稳定性优化:
-
无偏 KL 正则化,避免低概率 token 被过度优化;
-
离策略序列掩码,过滤高 KL 散度的噪声样本;
-
Keep Routing 机制,确保 MoE 模型训练与推理路由一致。
这套框架支持 数学、代码、Agent、对齐等多任务联合 RL,避免灾难性遗忘。
效果立竿见影:V3.2 在 AIME、HMMT、GPQA Diamond 上达到 GPT-5 水平;而 V3.2-Speciale 更在 IMO、CMO、ICPC 等竞赛中实现无需专门训练的金牌表现------这不仅是性能突破,更是对"开源能否挑战人类最高智力活动"的有力回应。
三、智能体任务合成流水线:让模型学会"边想边做"
过去,开源模型在工具调用、代码执行、网页操作等 Agent 任务中明显落后。
DeepSeek 的解法是:自己造数据,自己练模型。
团队构建了一套 端到端智能体任务合成流水线,自动生成:
-
1827 个可验证环境(含 Bash、搜索、数据库、代码解释器等工具);
-
85,000+ 复杂任务提示(如"三天旅行预算规划""GitHub 代码修复")。
每个任务都配有自动生成的解决方案与验证函数,确保模型只能通过工具调用完成任务,且结果可自动判对。
基于此,DeepSeek-V3.2 首次在开源社区实现 "思考内嵌工具调用"(Thinking-Integrated Tool Use):模型可在推理链任意步骤自主调用工具,并基于结果继续思考------真正从"聊天助手"进化为"智能执行者"。
在 MCP-Universe、BrowseComp、SWE-bench Verified 等未见过的 Agent 基准上,V3.2 显著优于其他开源模型,证明其具备强大的域外泛化能力。
DeepSeek-V3.2 模型地址:
https://huggingface.co/deepseek-ai/DeepSeek-V3.2
https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2
DeepSeek-V3.2-Speciale 模型地址:
https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Speciale
https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2-Speciale
大模型相关课程:
|----|---|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | 一 | 1.大模型的发展与局限性 |
| 2 | 二 | 1.1 ollama本地快速部署deepseek |
| 3 | 二 | 1.2 linux本地部署deepseek千问蒸馏版+web对话聊天 |
| 4 | 二 | 1.3 linux本地部署通义万相2.1+deepseek视频生成 |
| 5 | 二 | 1.4 Qwen2.5-Omni全模态大模型部署 |
| 6 | 二 | 1.5 Stable Diffusion中文文生图模型部署 |
| 7 | 二 | 1.6 DeepSeek-OCR部署尝鲜 |
| 8 | 二 | 2.1 从零训练自己的大模型概述 |
| 9 | 二 | 2.2 分词器 |
| 10 | 二 | 2.3 预训练自己的模型 |
| 11 | 二 | 2.4 微调自己的模型 |
| 12 | 二 | 2.5 人类对齐训练自己的模型 |
| 13 | 二 | 3.1 微调训练详解 |
| 14 | 二 | 3.2 Llama-Factory微调训练deepseek-r1实践 |
| 15 | 二 | 3.3 transform+LoRA代码微调deepseek实践 |
| 16 | 二 | 4.1 文生图(Text-to-Image)模型发展史 |
| 17 | 二 | 4.2 文生图GUI训练实践-真人写实生成 |
| 18 | 二 | 4.3 文生图代码训练实践-真人写实生成 |
| 19 | 二 | 5.1 文生视频(Text-to-Video)模型发展史 |
| 20 | 二 | 5.2 文生视频(Text-to-Video)模型训练实践 |
| 21 | 二 | 6.1 目标检测模型的发展史 |
| 22 | | 6.2 YOLO模型训练实践及目标跟踪 |
| 23 | 三 | 1.1 Dify介绍 |
| 24 | 三 | 1.2 Dify安装 |
| 25 | 三 | 1.3 Dify文本生成快速搭建旅游助手 |
| 26 | 三 | 1.4 Dify聊天助手快速搭建智能淘宝店小二 |
| 27 | 三 | 1.5 Dify agent快速搭建爬虫助手 |
| 28 | 三 | 1.6 Dify工作流快速搭建数据可视化助手 |
| 29 | 三 | 1.7 Dify chatflow快速搭建数据查询智能助手 |
| 30 | 三 | 2.1 RAG介绍 |
| 31 | 三 | 2.2 Spring AI-手动实现RAG |
| 32 | 三 | 2.3 Spring AI-开箱即用完整实践RAG |
| 33 | 三 | 2.4 LlamaIndex实现RAG |
| 34 | 三 | 2.5 LlamaIndex构建RAG优化与实践 |
| 35 | 三 | 2.6 LangChain实现RAG企业知识问答助手 |