Eclipse数值模拟软件详细介绍(油藏开发的"工业级仿真引擎")
Eclipse 是斯伦贝谢(Schlumberger)公司开发的油藏数值模拟行业标准软件 ,核心功能是通过数学建模+数值求解,在计算机中精准复现油藏(如页岩油、常规油气藏)的地质特征和开发动态,预测产量、压力变化,优化开发方案(钻井、压裂、排采),是油气田开发从"经验驱动"转向"科学决策"的核心工具。
其本质是"将地质、工程、流体等多学科数据转化为可量化的开发方案",覆盖油藏开发全生命周期(勘探评价→开发设计→生产优化→二次/三次采油),尤其适配页岩油、致密油等非常规油气藏的复杂开发场景。
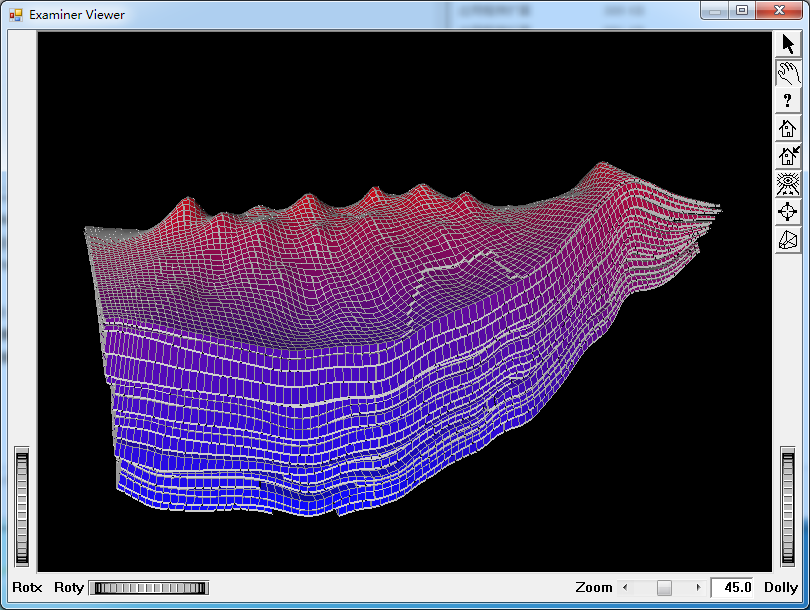
一、核心定位与行业价值
| 核心定位 | 行业价值(结合页岩油开发) |
|---|---|
| 油藏动态"虚拟实验室" | 无需实际钻井/压裂,即可模拟不同方案的产量、成本、采收率,避免无效投入(如页岩油压裂段数优化) |
| 开发方案"优化决策工具" | 对比多组参数(如水平井长度、压裂砂比),输出最优方案(如18段压裂比15段产量提升20%) |
| 开发风险"提前预警系统" | 模拟储层非均质性、裂缝闭合等风险对产量的影响,提前制定应对策略(如页岩油储层压力快速下降) |
| 多学科数据"融合载体" | 整合地质(TOC、脆性指数)、工程(钻井轨迹、压裂参数)、生产(产量、压力)数据,形成统一模型 |
二、核心功能模块拆解(含功能说明+页岩油应用场景+模拟数据示例)
Eclipse 采用"模块化设计",不同模块适配不同油藏类型和开发方式,核心模块如下:
(一)基础模块:油藏建模核心(所有模拟的基础)
1. 网格建模模块(Grid Module)
-
核心功能 :构建油藏三维网格模型,将地质体离散为"单元格"(如10m×10m×2m),每个单元格赋予储层参数(孔隙度、渗透率),实现地质特征的数字化。
- 支持网格类型:笛卡尔网格、角点网格(适配复杂构造,如断层、褶皱)、PEBI网格(适配不规则甜点区);
- 网格加密:对甜点区(高含油、高脆性区域)进行局部加密(如从20m×20m加密至5m×5m),提高模拟精度。
-
页岩油应用场景:构建四川盆地L1区块A区甜点区网格模型,水平段所在区域加密至5m×5m,非甜点区采用20m×20m网格,平衡精度与计算效率。
-
模拟数据示例 :
网格区域 网格尺寸(x×y×z) 单元格数量 核心参数赋值(示例) 甜点区(A区) 5m×5m×2m 8000个 孔隙度=4.9%,渗透率=0.01mD 非甜点区 20m×20m×5m 12000个 孔隙度=3.5%,渗透率=0.003mD
2. 流体与岩石属性模块(Fluid & Rock Properties Module)
- 核心功能 :定义油藏中流体(油、气、水)和岩石的物理化学性质,建立"物性-压力-温度"的关系模型(如PVT曲线、相对渗透率曲线)。
- 流体属性:原油黏度、密度、气油比(GOR)、压缩系数;
- 岩石属性:孔隙度、渗透率、饱和度(含油/含水/含气)、毛管压力曲线;
- 非常规适配:支持页岩油"吸附/解吸模型"(描述页岩油在纳米孔隙中的赋存规律)、"非线性渗流模型"(适配低渗透率下的非达西流动)。
- 页岩油应用场景:输入L1区块页岩油PVT数据(原油黏度=5mPa·s,气油比=200m³/m³),以及相对渗透率曲线(含油饱和度59%时,油相相对渗透率=0.3)。
- 关键模型 :
- 吸附模型:Langmuir模型(描述页岩油吸附量与压力的关系);
- 渗流模型:Forchheimer模型(考虑惯性力的非达西流动,适配页岩低渗透率)。
(二)开发方案设计模块(模拟钻井/压裂/排采全流程)
1. 井型与轨迹建模模块(Well Module)
-
核心功能 :在网格模型中添加井(直井、水平井、分支井),定义井轨迹、完井方式(射孔段位置)、井眼半径等参数。
- 轨迹定义:输入井口坐标、造斜点、水平段起点/终点,自动生成三维轨迹;
- 射孔段设置:指定水平段中需要射孔的网格单元(对应实际射孔位置)。
-
页岩油应用场景:在L1-H1井网格模型中,输入水平段轨迹(X:105.78°E→105.82°E,Y:28.93°N→28.91°N,垂深3100m),并标记1800m射孔段对应的网格单元(共360个单元格)。
-
模拟数据示例 :
井参数 数值 井型 水平井 井口坐标 (105.78°E,28.93°N) 水平段长度 2000m 射孔段网格范围 I=100-172,J=50-55 井眼半径 0.1m
2. 压裂模拟模块(Fracture Module,ECLIPSE 300核心功能)
- 核心功能 :模拟压裂过程中裂缝的生成、扩展及导流能力,建立"压裂参数-裂缝形态-产能"的关联。
- 裂缝建模:支持垂直裂缝、水平裂缝、多段压裂裂缝(适配页岩油水平井多级压裂);
- 参数输入:压裂液量、砂量、砂比、施工排量、裂缝半长、缝宽、导流能力(kf·wf);
- 动态模拟:模拟压裂后裂缝闭合规律(导流能力随时间衰减)。
- 页岩油应用场景:模拟L1-H1井12段压裂,每段压裂液量=1800m³,砂量=230m³,裂缝半长=150m,导流能力=15mD·m,生成"水平段+多段裂缝"的三维模型。
- 关键输出:裂缝在网格中的分布示意图、各段裂缝导流能力曲线。
3. 排采方案模拟模块(Production Module)
- 核心功能 :定义排采方式(自喷、人工举升)、压力控制策略(定井底压力、定产液量)、生产限制条件(如含水率上限),模拟长期排采动态。
- 控制方式:定井底压力(BHP)、定产油量(Qo)、定产液量(Ql)、定含水率(WCT);
- 动态约束:模拟套管压力限制、泵排量限制等工程约束。
- 页岩油应用场景:模拟L1-H1井排采方案(焖井7天→30天降压至25MPa→长期稳定排采),设定井底压力控制在20-25MPa,含水率上限30%。
(三)数值求解与动态预测模块(核心计算引擎)
1. 数值求解模块(Solver Module)
- 核心功能 :基于质量守恒、能量守恒、动量守恒方程,采用有限差分法求解油藏渗流方程,计算每个网格单元在不同时间步的压力、饱和度、产量等参数。
- 求解方法:隐式解法(稳定性强,适配长期模拟)、显式解法(速度快,适配短期动态);
- 并行计算:支持多线程/多节点并行,大幅提升大型模型(如百万网格)的计算速度。
- 页岩油适配:针对页岩油低渗透率、高吸附性的特点,优化求解器收敛性(如调整时间步长、迭代次数),避免数值振荡。
- 计算效率示例:L1区块10万网格模型,采用8线程并行计算,180天排采模拟仅需4小时(单线程需24小时)。
2. 动态预测模块(Prediction Module)
- 核心功能 :输出不同时间节点的开发动态数据,包括:
- 单井/区块产量:日产油、日产气、日产水、含水率、累产油量;
- 油藏压力:井底压力、地层压力(每个网格单元的压力分布);
- 饱和度分布:含油/含水/含气饱和度的三维变化(直观看到油藏"供油区"变化)。
- 页岩油应用场景:预测L1-H1井180天排采动态,输出"日产油从0→45吨/天(90天稳定),含水率从100%→28%"的曲线,与实际施工数据对比。
(四)历史拟合与优化模块(验证模型+优化方案)
1. 历史拟合模块(History Matching Module)
- 核心功能 :将模拟结果与实际生产数据(产量、压力)对比,调整模型参数(如渗透率、裂缝导流能力),使模拟曲线与实际曲线拟合,确保模型的可靠性。
- 拟合参数:储层渗透率、孔隙度、相对渗透率曲线、裂缝导流能力、PVT数据;
- 拟合指标:产量误差≤5%,压力误差≤3%。
- 页岩油应用场景:用L1-H1井实际排采数据(前90天日产油45吨/天),调整模型渗透率从0.01mD至0.012mD,使模拟产量曲线与实际曲线拟合度达96%。
2. 方案优化模块(Optimization Module)
- 核心功能 :批量模拟多组开发方案,对比产量、采收率、成本等指标,自动筛选最优方案。
- 优化参数:水平井长度、压裂段数、砂比、排采压力、井距;
- 优化目标:最大化累产油量、最大化采收率、最小化单位产油成本。
- 页岩油应用场景:模拟L1-H2井5组压裂方案(12段→18段),输出"18段压裂累产油量比15段提升22%,单位成本降低10%"的结论,确定最优方案。
(五)非常规油气藏专用模块(页岩油/致密油核心适配)
Eclipse 针对页岩油等非常规油气藏,提供专用模块扩展核心功能:
1. ECLIPSE 300(黑油/组分模型)
- 适配场景:页岩油常规开发(油、气、水三相流动);
- 核心优势:支持裂缝模型、吸附模型、非线性渗流模型,满足页岩油基本模拟需求。
2. ECLIPSE 100(组分模型)
- 适配场景:页岩油伴生气含量高、流体组分复杂的情况(如凝析油藏);
- 核心优势:精确模拟流体组分变化(如甲烷、乙烷含量对黏度的影响),预测气油比变化。
3. ECLIPSE STARS(热采模型)
- 适配场景:页岩油热采开发(如蒸汽驱、电加热);
- 核心优势:模拟热传导、热对流过程,预测温度对原油黏度、流动性的影响(如温度从135℃升至150℃,原油黏度降低30%)。
4. FRACMAN-Eclipse 耦合模块
- 适配场景:页岩油高精度压裂模拟;
- 核心优势:将FRACMAN(专业压裂模拟软件)的裂缝扩展结果导入Eclipse,实现"压裂裂缝精细建模+油藏动态模拟"的无缝衔接。
三、Eclipse在页岩油开发全流程中的应用(结合之前案例)
1. 甜点区评价阶段
- 功能应用:构建不同候选区域(A/B/C区)的网格模型,赋予对应储层参数(TOC、脆性指数、渗透率),模拟单井产能;
- 输出结果:A区模拟产能48吨/天,B区35吨/天,验证A区为最优甜点区。
2. 钻井/压裂方案设计阶段
- 功能应用:在A区网格模型中,模拟不同水平井长度(1800m/2000m/2200m)、压裂段数(12段/15段/18段)的组合方案;
- 输出结果:2000m水平井+15段压裂的方案,投资回报率最高(产量45吨/天,成本3200万元)。
3. 排采优化阶段
- 功能应用:模拟不同降压速率(每周降1MPa/2MPa/3MPa)对产量和含水率的影响;
- 输出结果:每周降2MPa的方案,既避免储层伤害,又能快速达到稳定产油(90天达45吨/天)。
4. 后续井优化阶段
- 功能应用:用L1-H1井实际数据完成历史拟合,调整模型参数后,模拟L1-H2井的压裂段数优化;
- 输出结果:18段压裂方案模拟产量55吨/天,为实际施工提供科学依据。
5. AI赋能衔接阶段
- 功能应用:Eclipse生成1000组"储层参数+压裂参数+产量曲线"的样本数据,用于训练AI代理模型;
- 价值:AI代理模型模拟速度提升1000倍,可快速迭代优化方案,再用Eclipse验证最优方案的可靠性。
四、技术特性与使用门槛
1. 核心技术特性
| 特性 | 说明 |
|---|---|
| 兼容性强 | 支持导入/导出多种格式数据(如Petrel地质模型、Landmark钻井数据、Excel参数表) |
| 扩展性好 | 支持用户自定义模块(如通过ECLIPSE API编写页岩油专用渗流模型) |
| 可视化能力强 | 内置Viewer模块,可实时查看三维网格、井轨迹、裂缝分布、产量曲线等 |
| 工业级可靠性 | 全球90%以上油气田企业采用,经过数十年工程验证(如美国Permian盆地页岩油开发) |
2. 使用门槛与学习路径
- 基础要求:掌握油藏工程、渗流力学基础(理解PVT曲线、相对渗透率等概念);
- 操作技能:熟悉Eclipse界面操作(网格建模、井定义、参数输入、求解设置);
- 进阶技能:掌握历史拟合技巧、参数敏感性分析、自定义模型开发(API编程);
- 学习路径:基础操作(建模+求解)→ 页岩油专用模型设置(裂缝+吸附+非线性渗流)→ 历史拟合与方案优化→ AI代理模型数据生成。
五、总结:Eclipse的核心价值的
Eclipse 是页岩油开发中"连接地质理论与工程实践的桥梁",其核心价值在于:
- 量化预测:将"高含油、高脆性"等定性描述转化为"日产油45吨"的定量结果;
- 风险规避:在实际施工前模拟不同方案的效果,避免无效投入(如否定12段压裂方案,节省成本800万元);
- 科学优化:通过多方案对比和参数敏感性分析,找到"产量-成本"最优平衡点;
- 数据沉淀:构建区块数字孪生模型,将钻井、压裂、排采数据沉淀为可复用的资产,支撑后续井开发。
对于页岩油开发顶级专家而言,Eclipse 不仅是"模拟工具",更是"决策支持系统"------结合AI技术后,可实现"模拟-优化-验证"的闭环,大幅提升开发效率和采收率。
Eclipse各模块并非独立存在,而是围绕"静态数字油藏构建→动态开发过程模拟→结果验证优化→实际工程落地"的核心逻辑,形成"数据单向流转+双向反馈校准"的闭环关联,每个模块均承担"前序支撑、当前执行、后序承接"的角色,且完全贴合页岩油开发的工程流程(地质评价→钻井→压裂→排采→方案优化)。以下从"整体逻辑框架+分层模块关联+场景化逻辑落地"三方面,拆解各模块的核心逻辑关系。
Eclipse模块的逻辑
一、Eclipse模块整体逻辑闭环(核心主线:从"静态地质"到"动态决策")
Eclipse的核心目标是"用数字模型复现油藏开发全生命周期",各模块按"基础铺垫→方案构建→计算驱动→验证优化"的逻辑分层,数据从底层向上流转,优化结果向下反馈校准,形成完整闭环,具体逻辑链如下:
闭环核心逻辑:
- 正向流转(基础→落地):先将地质、流体、工程数据转化为数字模型,再设计开发方案,通过数值计算得到动态结果,最终输出可落地的方案;
- 反向反馈(优化→校准):用实际生产数据验证模拟结果,校准静态模型参数(如渗透率)和方案参数(如压裂砂比),让模型更精准、方案更优。
二、分层模块关联拆解(含"依赖关系+数据流向+角色定位")
(一)第一层:数据输入层------所有模块的"数据源支撑"
核心定位:
提供Eclipse各模块所需的原始数据,无数据输入则后续所有模拟均无法开展,属于"底层燃料"。
输入数据类型(对应后续模块需求):
- 地质数据(供网格模块):区块构造图、储层厚度图、TOC/孔隙度/渗透率分布数据;
- 流体数据(供流体与岩石属性模块):原油黏度、密度、PVT曲线、气油比;
- 工程数据(供井/压裂/排采模块):井口坐标、钻井轨迹、压裂参数(液量/砂量)、排采压力控制要求;
- 生产数据(供历史拟合模块):实际日产油、井底压力、含水率数据。
逻辑关联:
数据输入层是"无模块的基础层",直接为第二层静态建模、第三层方案设计、第六层验证优化提供原始素材,数据质量决定后续模拟精度(如地质数据误差大→网格模型不准→产量预测偏差大)。
(二)第二层:静态建模层------所有模拟的"数字油藏载体"(核心基础)
包含模块:网格建模模块、流体与岩石属性模块
模块内逻辑关联:
两者是"骨架+血肉"的依存关系,共同构建"可计算的静态数字油藏",缺一不可:
- 网格建模模块:先搭建油藏"空间骨架"------将真实地质体离散为三维单元格,明确储层的空间范围、构造形态(如断层、甜点区),并标记不同区域的网格划分规则(如甜点区加密);
- 流体与岩石属性模块:再给骨架填"血肉"------为每个单元格赋予储层物理参数(孔隙度、渗透率)、流体参数(原油黏度、密度),建立"参数-空间位置"的对应关系;
- 数据流向:网格模块输出"空网格模型"→ 流体与岩石属性模块输入参数→ 输出"完整静态数字油藏模型"。
角色定位:
静态建模层是Eclipse的"地基",后续井、压裂、排采等开发方案,均需依托该数字油藏搭建(无数字油藏,井无位置可放、压裂无储层可改造)。
页岩油场景示例:
网格模块搭建L1区块A区甜点区网格(5m×5m加密),流体与岩石属性模块为加密网格赋予"孔隙度4.9%、渗透率0.01mD、原油黏度5mPa·s",形成静态数字油藏。
(三)第三层:方案设计层------油藏开发的"工程执行模拟"(按工程流程关联)
包含模块:井型与轨迹建模模块、压裂模拟模块、排采方案模拟模块
模块间逻辑关联:
按"钻井→完井射孔→压裂改造→排采产出"的页岩油实际工程流程递进,前序模块为后序模块提供"执行载体/位置依据",属于"流程化依存":
-
井型与轨迹建模模块(第一步:钻井+完井)
- 依赖:静态建模层的数字油藏(需在网格模型中确定井的位置);
- 核心动作:在数字油藏中添加水平井,定义井口坐标、水平段轨迹,标记射孔段对应的网格单元(明确"油流通道的位置");
- 输出:带轨迹+射孔段的"数字井模型",为压裂模块提供"裂缝部署起点"。
-
压裂模拟模块(第二步:储层改造)
- 依赖:① 静态数字油藏(需适配储层脆性、渗透率,设计压裂参数);② 井型轨迹模块的数字井(需在射孔段网格处部署裂缝);
- 核心动作:基于射孔段位置,输入压裂参数(液量/砂量/砂比),模拟裂缝的生成、扩展及导流能力,将裂缝参数(缝长/缝宽/导流能力)赋予对应网格;
- 输出:带多段裂缝的"数字压裂模型",为排采模块提供"改造后的高导流油藏"(裂缝让储层渗透率提升,油能更易流出)。
-
排采方案模拟模块(第三步:原油产出)
- 依赖:① 静态数字油藏(适配储层压力,设计排采压力);② 数字井模型(明确举升通道);③ 数字压裂模型(明确油流路径);
- 核心动作:定义排采方式(如电潜泵)、压力控制策略(焖井7天→降压30天→稳定排采)、生产约束(含水率上限30%);
- 输出:"数字排采方案",明确生产控制条件,为核心计算层提供"执行指令"。
角色定位:
方案设计层是"将实际开发工程转化为数字指令"的核心,把钻井、压裂、排采的物理动作,转化为模型可识别的参数和逻辑,连接静态油藏与动态计算。
页岩油场景示例:
井模块在数字油藏中定义L1-H1井(水平段2000m,射孔段对应网格I=100-172)→ 压裂模块在射孔段网格部署15段裂缝(缝长150m,导流能力15mD·m)→ 排采模块设定"焖井7天+井底压力20-25MPa"的排采策略。
(四)第四层:核心计算层------动态模拟的"引擎驱动"(核心枢纽)
包含模块:数值求解模块
逻辑关联:
数值求解模块是Eclipse的"心脏",承接前序所有模块的输入,通过数学方程计算输出动态结果,是"静态→动态"的唯一转化通道:
- 依赖:① 静态建模层(储层/流体参数,用于方程参数赋值);② 方案设计层(井/压裂/排采参数,用于方程边界条件设定);
- 核心动作:基于质量守恒、动量守恒、渗流力学方程(如页岩油非线性渗流方程),采用有限差分法,计算每个网格单元在不同时间步(如每天)的压力、含油饱和度、油流速度,进而推导单井产量;
- 数据流向:输入"静态油藏+开发方案"→ 求解计算→ 输出"动态数据(压力/饱和度/产量随时间变化)";
- 关键作用:无求解模块,静态油藏和开发方案仅为"静态参数集合",无法得到"日产油45吨"这类动态结果,是所有动态模拟的核心驱动。
页岩油场景示例:
输入静态油藏参数(渗透率0.01mD)、15段压裂参数、排采压力25MPa→ 求解模块计算每个网格的油流状态→ 输出每天的井底压力、日产油数据。
(五)第五层:动态输出层------开发结果的"可视化呈现"
包含模块:动态预测模块
逻辑关联:
动态预测模块是"数值求解结果的翻译官",无独立计算功能,仅承接求解模块的原始数据,转化为直观的可视化结果:
- 依赖:数值求解模块的原始动态数据(压力、产量、饱和度的网格级/时间级数据);
- 核心动作:将原始数据转化为两类输出:
- 曲线类:日产油/水/气曲线、井底压力曲线、含水率曲线;
- 三维可视化类:含油饱和度空间分布、地层压力分布、裂缝渗流路径;
- 输出价值:为后续验证优化提供"可对比、可分析的动态结果"(如用日产油曲线与实际数据对比,判断模型是否精准)。
页岩油场景示例:
承接求解模块数据,输出L1-H1井"90天达日产油45吨、含水率28%"的曲线,以及含油饱和度从射孔段向井眼迁移的三维图。
(六)第六层:验证优化层------模拟精度的"校准+方案迭代"(双向反馈核心)
包含模块:历史拟合模块、方案优化模块
模块间逻辑关联:
先验证模型精度,再基于精准模型优化方案,且均反向反馈前序模块,属于"闭环校准+迭代优化"的关系:
-
历史拟合模块(第一步:校准模型精度)
- 依赖:① 动态输出层的模拟结果(如模拟日产油曲线);② 数据输入层的实际生产数据(如实际日产油曲线);
- 核心动作:对比模拟曲线与实际曲线,若误差超标(如模拟产量50吨/天,实际45吨/天),反向调整前序模块参数:
- 调整静态建模层:修正渗透率(如从0.01mD改为0.012mD)、裂缝导流能力(如从15mD·m改为14mD·m);
- 调整方案设计层:修正排采压力(如从25MPa改为24MPa);
- 输出:校准后的"高精度数字模型"(模拟与实际误差≤5%),为方案优化模块提供可靠基础。
-
方案优化模块(第二步:迭代最优方案)
- 依赖:历史拟合校准后的高精度数字模型(确保优化结果可信);
- 核心动作:批量设定多组开发方案参数(如压裂段数12/15/18段、水平井长度1800/2000/2200m),调用数值求解模块快速计算各组方案的产量、采收率、成本,筛选"产量最高、成本最优"的方案;
- 双向反馈:① 反馈方案设计层:输出最优参数(如18段压裂),指导后续井的方案设计;② 反馈静态建模层:基于优化结果,进一步修正储层参数认知(如发现18段压裂适配更高渗透率区域,修正甜点区参数);
- 输出:可落地的"最优开发方案",指导实际页岩油井的施工。
角色定位:
验证优化层是Eclipse从"模拟工具"升级为"决策工具"的核心,通过反向反馈消除模拟误差,迭代出科学方案,避免实际工程的无效投入。
页岩油场景示例:
历史拟合模块对比L1-H1井模拟产量(50吨/天)与实际产量(45吨/天),修正渗透率至0.012mD,拟合误差降至3%→ 方案优化模块模拟12/15/18段压裂方案,输出18段压裂最优(模拟产量55吨/天),指导L1-H2井施工。
(七)第七层:非常规专用模块------场景化功能延伸(适配页岩油特殊需求)
包含模块:ECLIPSE 300(黑油/组分)、ECLIPSE STARS(热采)、FRACMAN-Eclipse耦合模块
逻辑关联:
专用模块是"基础模块的功能补全/精度提升",仅适配页岩油等非常规油藏的特殊开发场景,不改变核心逻辑闭环,仅强化特定环节的模拟能力:
- ECLIPSE 300:补全基础模块的非常规适配性------为流体与岩石属性模块增加"页岩油吸附模型、非线性渗流模型",为压裂模块增加"多段裂缝动态衰减模型",让静态建模、方案设计更贴合页岩油特性;
- FRACMAN-Eclipse耦合模块:提升压裂模块的精度------FRACMAN先精细模拟裂缝扩展(比Eclipse基础压裂模块更精准),再将裂缝数据导入Eclipse压裂模块,补充裂缝参数细节,让求解计算更精准;
- ECLIPSE STARS:延伸方案设计层的场景适配------针对页岩油热采场景,为排采模块增加"热传导/热对流计算",为流体模块增加"温度-黏度关联模型",适配蒸汽驱、电加热等特殊排采方案。
角色定位:
专用模块是"核心逻辑闭环的场景化增强器",仅服务于页岩油等非常规开发需求,不影响基础模块的关联逻辑,仅让模拟更精准、场景适配性更强。
三、各模块逻辑关系核心总结(3个关键维度)
1. 空间依存维度:静态建模层是"所有模块的载体"
网格模块+流体岩石属性模块构建的数字油藏,是井、压裂、排采、求解等模块的"空间基础"------所有开发方案均需在数字油藏中落地,所有计算均需基于数字油藏的参数,无静态建模则后续模块均无执行空间。
2. 流程递进维度:方案设计层按"实际工程顺序关联"
完全贴合页岩油"钻井→压裂→排采"的工程流程,井模块→压裂模块→排采模块层层递进,前序模块为后序模块提供"位置/载体依据",流程不可逆(无井则无压裂起点,无压裂则无排采高效通道)。
3. 数据闭环维度:求解+预测+验证优化形成"动态迭代"
- 正向:求解模块将"静态油藏+开发方案"转化为动态结果,预测模块可视化呈现;
- 反向:历史拟合用实际数据校准前序模块参数,方案优化基于校准模型迭代方案,再反馈指导实际工程,同时反哺模型升级,形成"模拟→验证→优化→落地→再模拟"的闭环,持续提升模拟精度和开发效果。
简言之,Eclipse各模块的逻辑核心的是"以数字油藏为载体,以工程流程为脉络,以数值计算为驱动,以闭环优化为目标",所有模块围绕"精准模拟页岩油开发全生命周期、输出科学开发方案"的核心目标联动,缺一不可。
Eclipse数值模拟软件的工作原理
Eclipse 是斯伦贝谢(Schlumberger)开发的油气藏数值模拟核心软件 ,主要用于油藏、气藏、煤层气、页岩气等地下流体开采的动态预测与方案优化,其核心工作原理是基于渗流力学方程的数值离散求解,通过对油藏进行网格剖分,将连续的地下渗流问题转化为离散的代数方程组,再结合油藏物性、流体性质和生产制度,模拟油气水在孔隙介质中的流动规律。
一、核心逻辑框架
Eclipse的工作流程遵循 "地质建模→参数赋值→方程构建→数值求解→结果输出" 的闭环逻辑,具体如下:
-
地质模型网格化
把实际油藏的三维空间(构造、储层、隔层)离散为大量三维网格单元(Grid Block) ,每个网格单元被视为均质、各向同性(或各向异性)的独立单元 ,网格的大小和密度可根据油藏特征调整(如井区加密、边界稀疏)。
网格单元的核心属性包括:孔隙度、渗透率(x/y/z方向)、厚度、深度、饱和度(初始油气水分布)。
-
流体与相态模型定义
根据油气藏类型选择对应的流体相态模型,描述油气水的物理性质和相态变化规律,这是模拟流体流动的基础:
- 黑油模型(Black Oil Model):适用于常规油气藏,假设油、气、水三相独立,仅考虑溶解气和挥发油的简单相态变化。
- 组分模型(Compositional Model):适用于凝析气藏、挥发性油藏,考虑多组分流体的相态分馏(如气液互溶、反凝析现象)。
- 热采模型(Thermal Model):适用于稠油热采(蒸汽驱、SAGD),耦合能量方程,考虑温度对流体黏度、相态的影响。
-
渗流控制方程构建
基于质量守恒定律 和达西定律,建立每个网格单元的流体渗流控制方程,这是Eclipse的数学核心。
- 达西定律:描述流体在多孔介质中的流速与压力梯度的关系,公式为 v=−kμ∇pv=-\frac{k}{\mu} \nabla pv=−μk∇p(vvv为流速,kkk为渗透率,μ\muμ为流体黏度,∇p\nabla p∇p为压力梯度)。
- 质量守恒方程:对每个网格单元,流入质量 - 流出质量 = 单元内流体质量变化量,结合达西定律推导得到压力-饱和度耦合的偏微分方程 。
对于三相渗流,每个网格单元需求解油、气、水三相的守恒方程,同时满足饱和度约束条件 So+Sg+Sw=1S_o+S_g+S_w=1So+Sg+Sw=1(SSS为饱和度)。
-
数值离散与求解
由于渗流控制方程是复杂的非线性偏微分方程,无法直接求得解析解,Eclipse采用有限差分法(FDM) 将方程离散为代数方程组:
- 时间离散:将模拟周期(如10年)划分为若干时间步长,每个时间步内假设参数变化平缓。
- 空间离散:对相邻网格单元的流量交换进行近似,将偏微分方程转化为相邻网格的压力、饱和度差值的代数关系。
离散后的代数方程组通过迭代求解算法 计算,核心是求解压力场 和饱和度场的耦合问题: - 隐式压力显式饱和度(IMPES):适用于低压缩性油藏,先求解压力方程,再显式计算饱和度。
- 全隐式(Fully Implicit):适用于强非线性油藏(如凝析气藏、稠油热采),同时隐式求解压力和饱和度,稳定性更强但计算量更大。
-
生产制度耦合与动态模拟
将实际生产/注入方案转化为数值模型的边界条件,包括:
- 井的类型:生产井、注入井(水驱、气驱)、观察井。
- 井的控制条件:定产量、定井底压力、定井口压力、关井等。
- 井的射孔层位:指定井与哪些网格单元连通,计算井筒与油藏的流量交换。
软件在每个时间步内,根据当前油藏压力、饱和度分布,结合生产制度,计算每口井的产量、压力变化,并更新整个油藏的流体分布,循环迭代直至完成模拟周期。
-
结果输出与验证
模拟结束后,输出油藏动态数据,包括:
- 宏观指标:油田/气田的日产油量、日产气量、含水率、累计产量、地层压力变化。
- 微观分布:各网格单元的压力、饱和度、流体组分分布(可通过可视化软件如Petrel、CMG Results查看)。
同时需通过历史拟合验证模型准确性:调整渗透率、相对渗透率曲线、压缩系数等参数,使模拟结果与实际生产数据(如历史产量、压力)匹配,确保模型能可靠预测未来开发动态。
二、关键技术特点
- 模块化架构:Eclipse包含多个功能模块(如黑油模块ECL100、组分模块ECL300、热采模块ECL500),可根据油藏类型灵活组合。
- 并行计算支持:针对大型油藏模型(百万级网格),支持多核并行计算,通过网格分区减少求解时间。
- 井工程耦合:可集成井筒流动模型,模拟井筒压力损失、气举、人工举升等工艺对生产的影响。
三、与能源行业数字化的结合点
在智慧油藏管理系统中,Eclipse的模拟结果可与大数据、AI深度融合:
- 将模拟产生的海量动态数据(压力、饱和度、产量)存入时序数据库,用于训练油藏动态预测模型。
- 结合数字孪生技术,构建油藏数字孪生体,实时将实际生产数据输入Eclipse模型,实现油藏动态的实时预测与开发方案的智能优化。