0014机器学习案例一电信客户流失预测
- 一、背景介绍
- 二、数据预处理
-
- [1.1 数据字段介绍](#1.1 数据字段介绍)
- [2.2 Exploratory Data Analysis (EDA,探索性数据分析)](#2.2 Exploratory Data Analysis (EDA,探索性数据分析))
- [3.3 缺失值处理](#3.3 缺失值处理)
- [4.4 异常值处理](#4.4 异常值处理)
- [5.5 可视化分析](#5.5 可视化分析)
- 三、特征工程
-
- [1.1 连续特征的处理](#1.1 连续特征的处理)
- [2.2 离散特征的处理](#2.2 离散特征的处理)
- [3.3 特征选择](#3.3 特征选择)
- [4.4 保存处理好的数据](#4.4 保存处理好的数据)
- [5.5 正负样本数据类别不均衡处理](#5.5 正负样本数据类别不均衡处理)
- 四、模型选择和训练
-
- [1.1 K折交叉验证](#1.1 K折交叉验证)
- [2.2 训练模型](#2.2 训练模型)
- [3.3 模型评估](#3.3 模型评估)
- [4.4 特征重要性](#4.4 特征重要性)
- [5.5 模型保存](#5.5 模型保存)
- 五、模型预测
一、背景介绍
1、任务描述:
随着电信行业的不断发展,运营商们越来越重视如何扩大其客户群体。据研究,获取新客户所需的成本远高于保留现有客户的成本,因此为了满足在激烈竞争中的优势,保留现有客户成为一大挑战。对电信行业而言,可以通过数据挖掘等方式来分析可能影响客户决策的各种因素,以预测他们是否会产生流失(停用服务、转投其他运营商等)。
2、数据集:
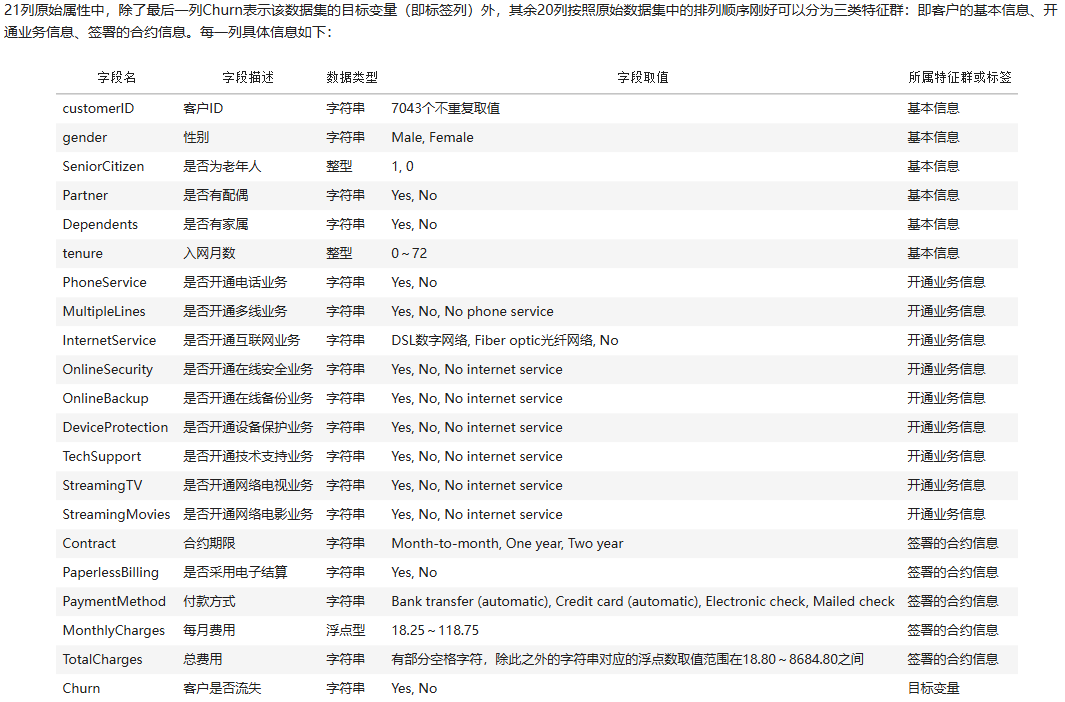
数据集一共提供了7043条用户样本,每条样本包含21列属性,由多个维度的客户信息以及用户是否最终流失的标签组成,客户信息具体如下:
基本信息:包括性别、年龄、经济情况、入网时间等;
开通业务信息:包括是否开通电话业务、互联网业务、网络电视业务、技术支持业务等;
签署的合约信息:包括合同年限、付款方式、每月费用、总费用等。
3、评测:
电信用户流失预测中,运营商最为关心的是客户的召回率 ,即在真正流失的样本中,我们预测到多少条样本。其策略是宁可把未流失的客户预测为流失客户而进行多余的留客行为,也不漏掉任何一名真正流失的客户。
4、思路:
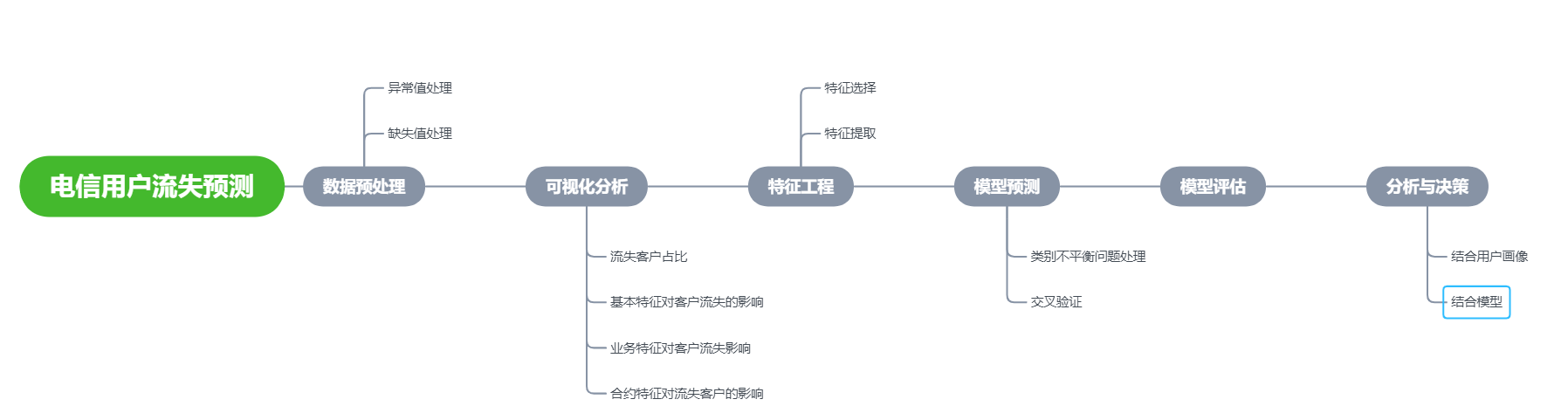
数据预处理、可视化分析、特征工程、模型预测、模型评估、分析与决策
二、数据预处理
1.1 数据字段介绍
2.2 Exploratory Data Analysis (EDA,探索性数据分析)
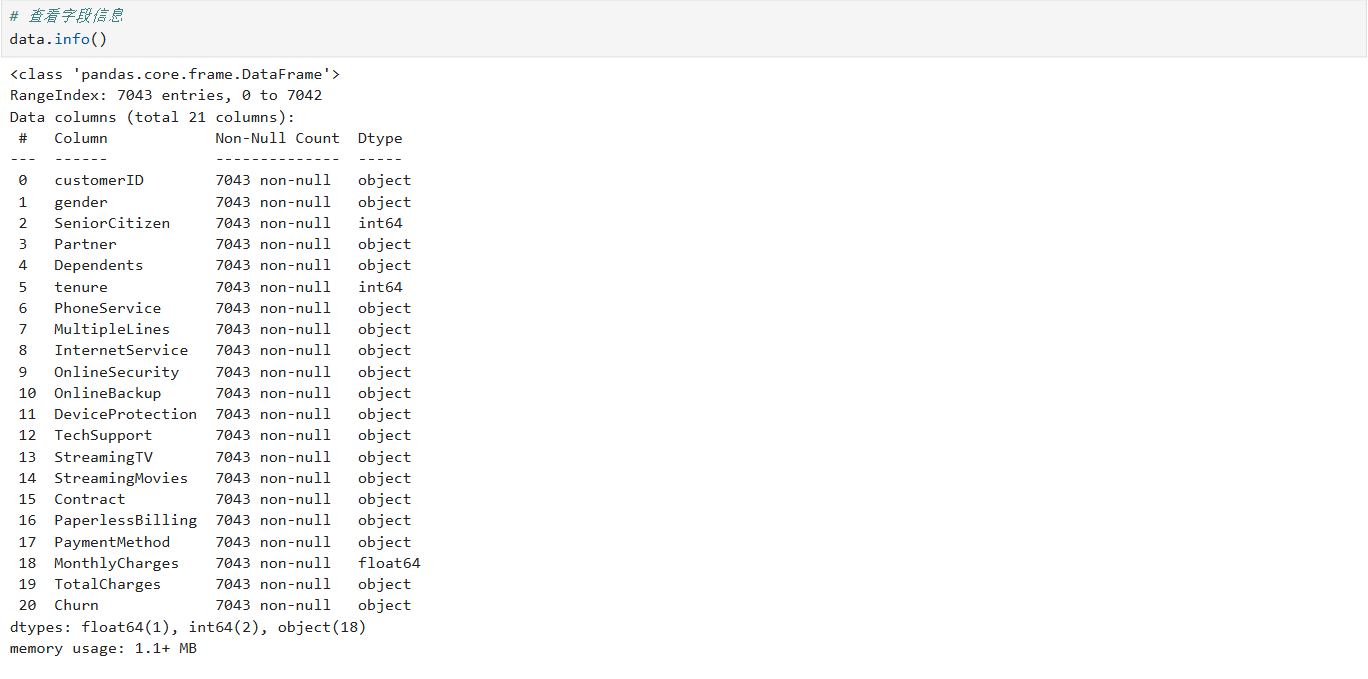
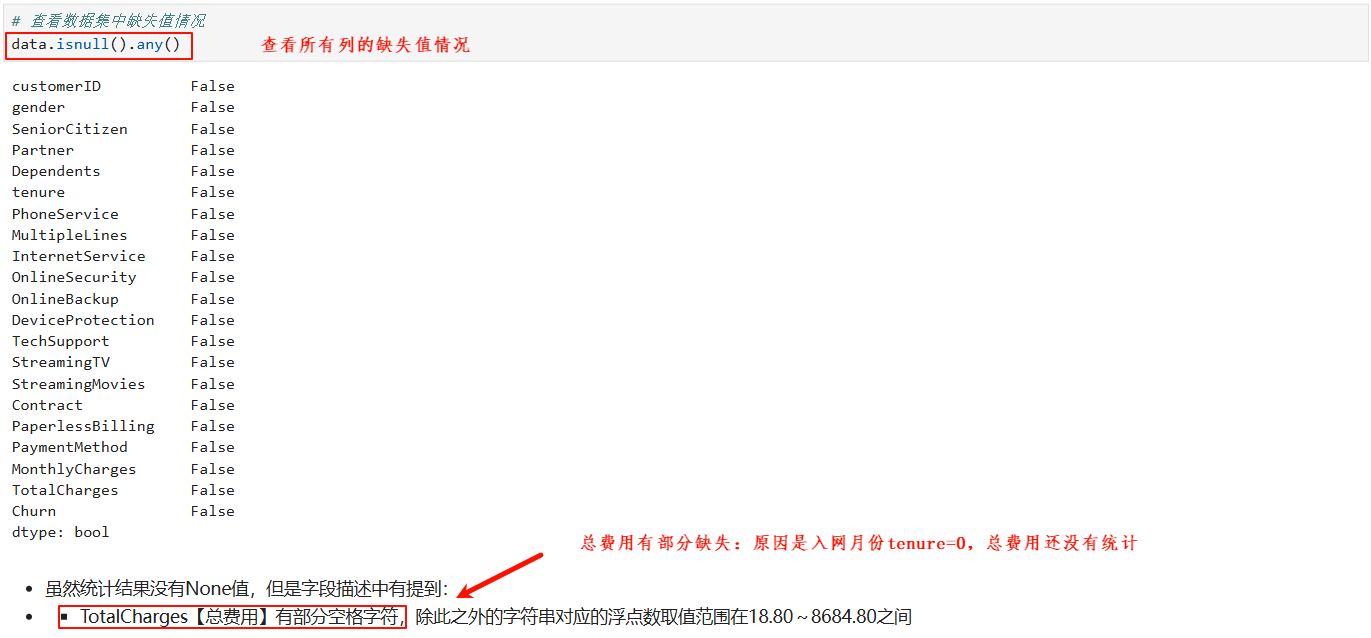
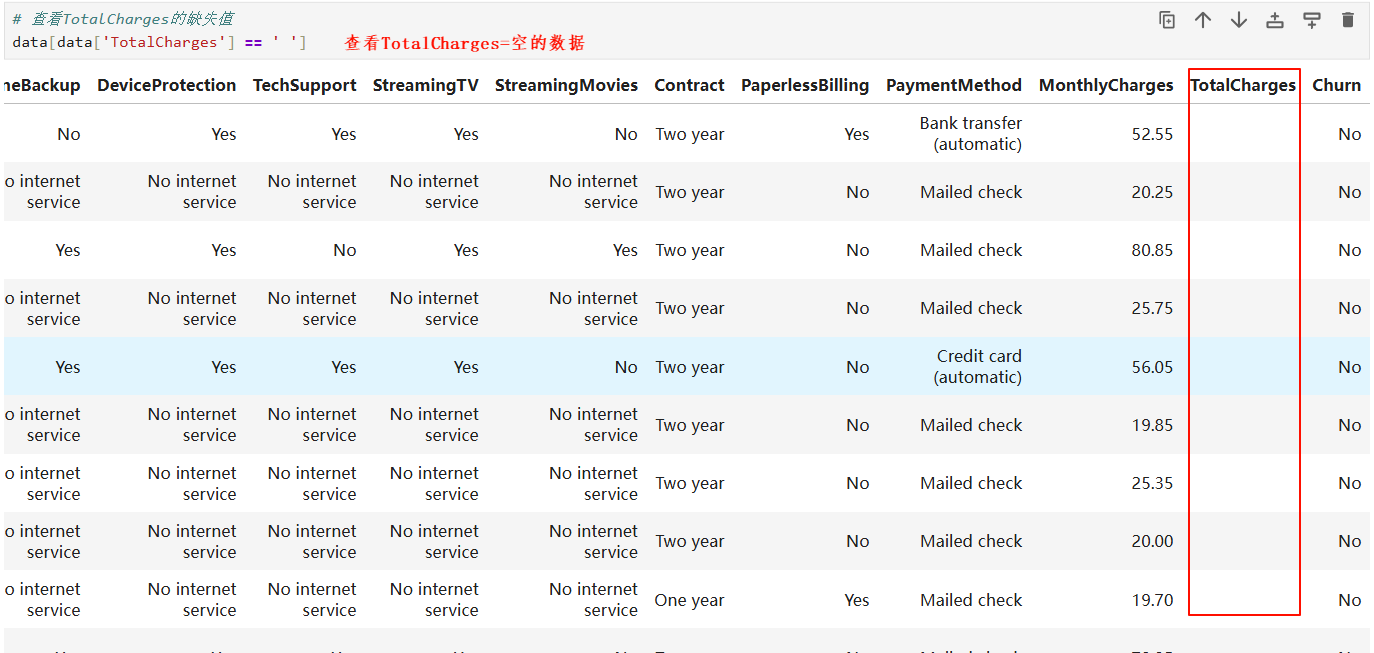
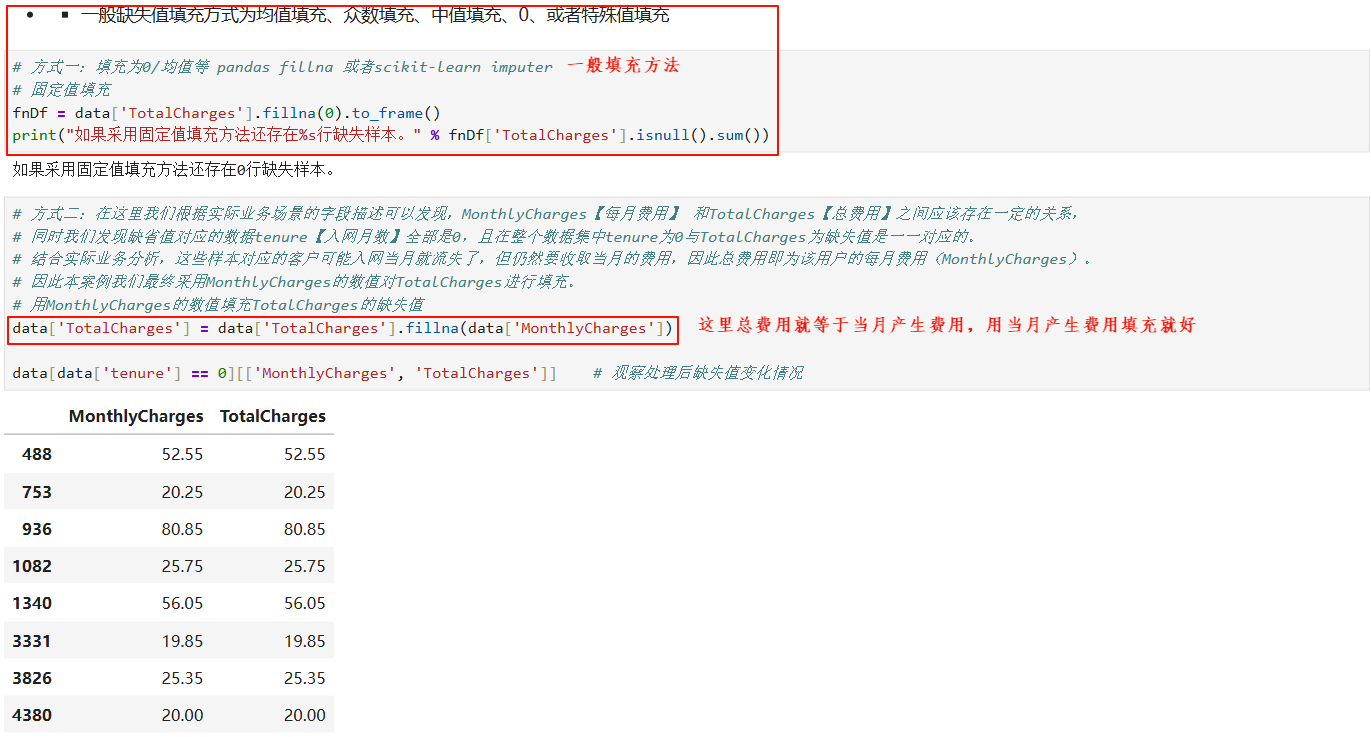
3.3 缺失值处理

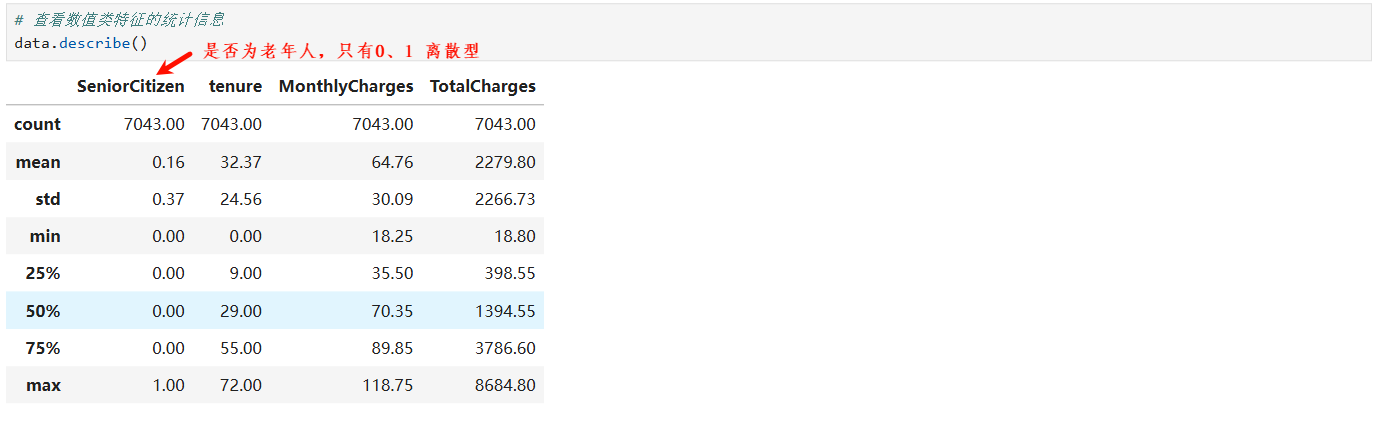
4.4 异常值处理
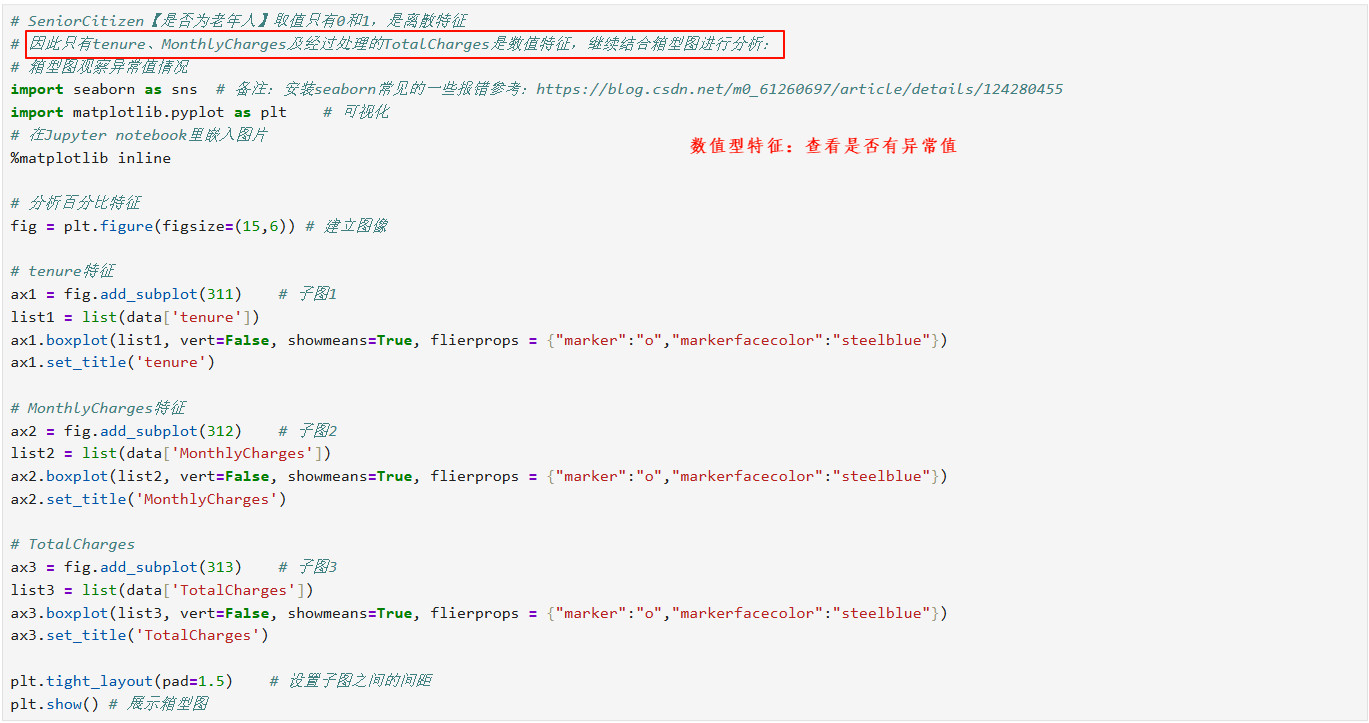
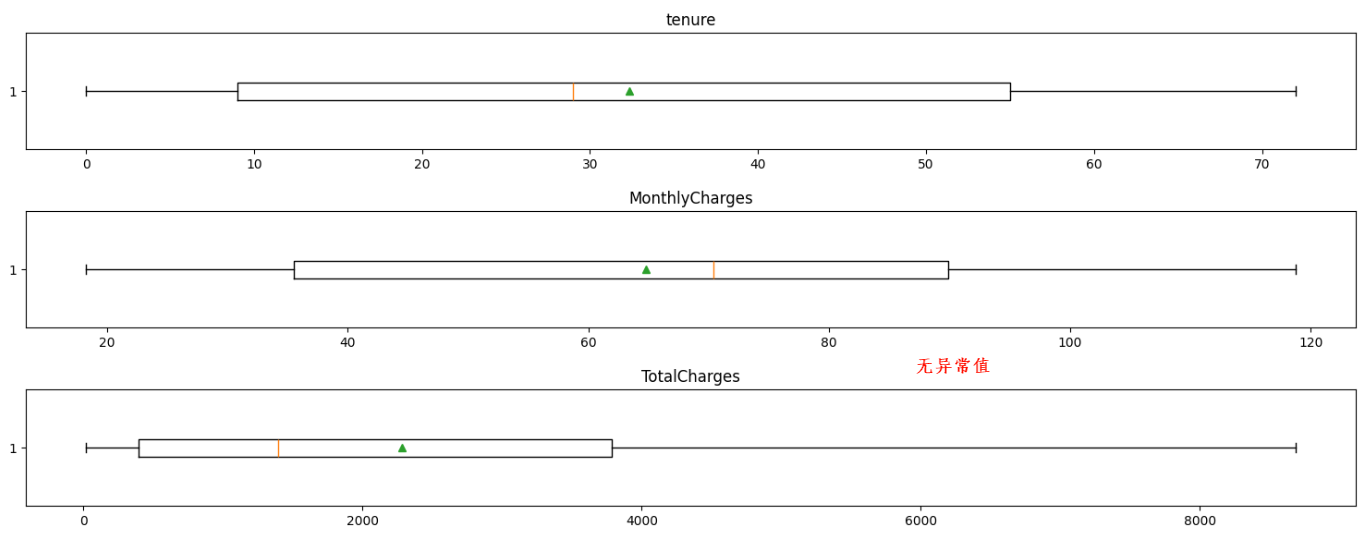


5.5 可视化分析
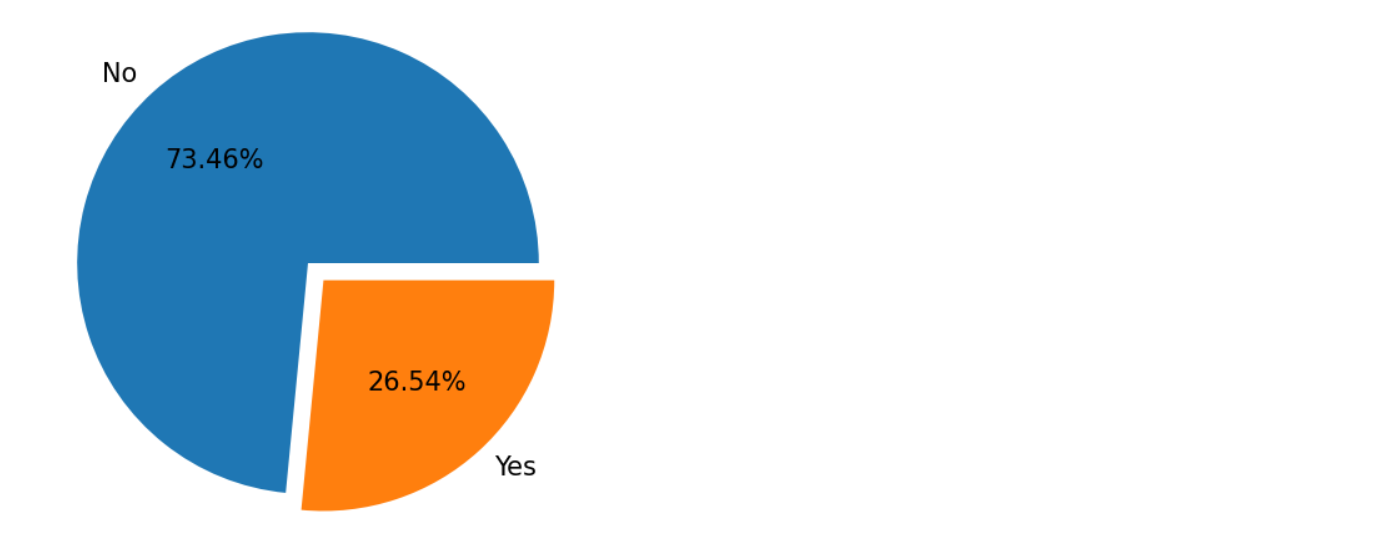
1、流失客户占比

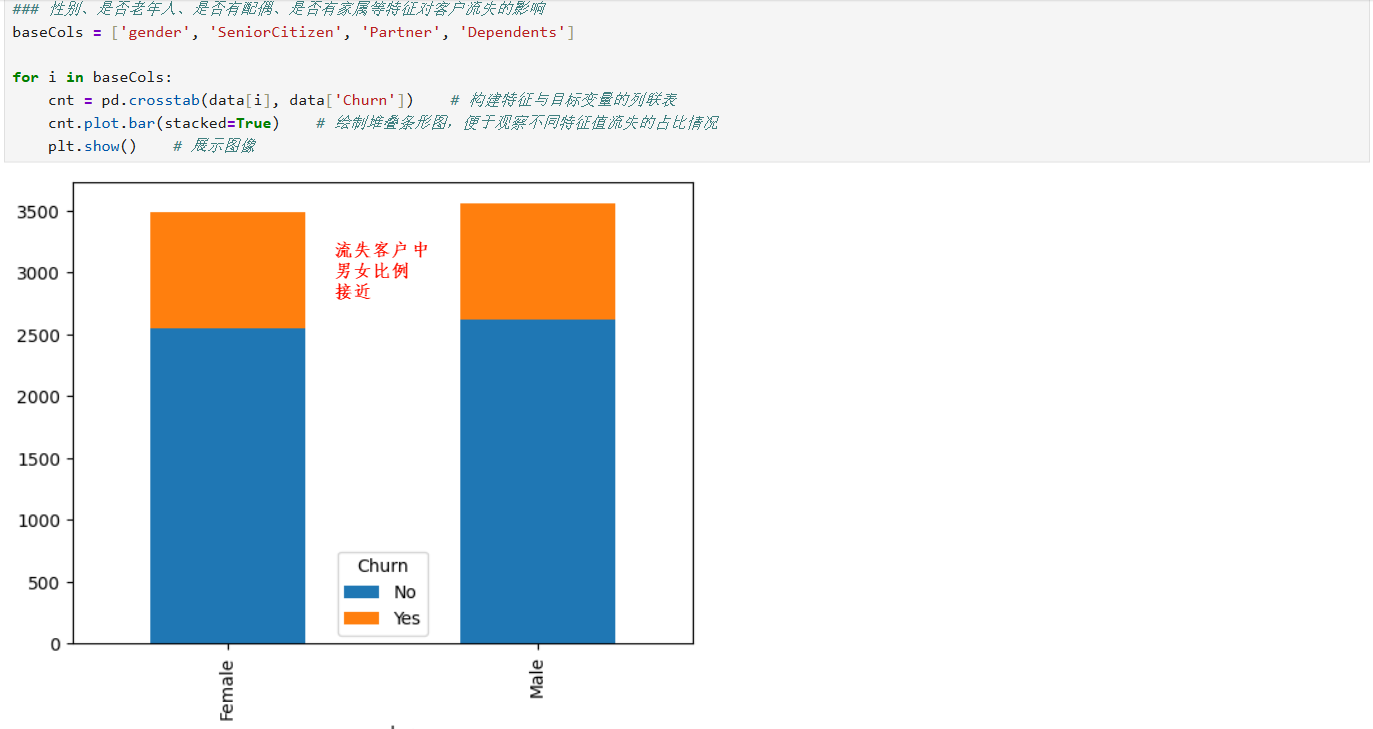
2、基本特征对客户流失影响
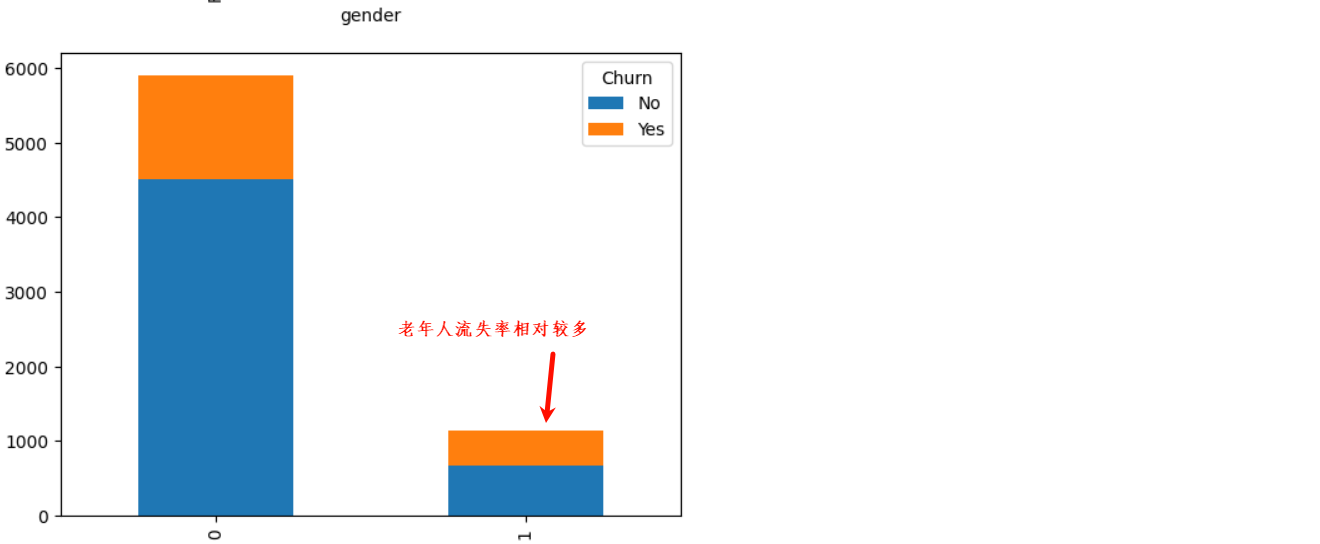
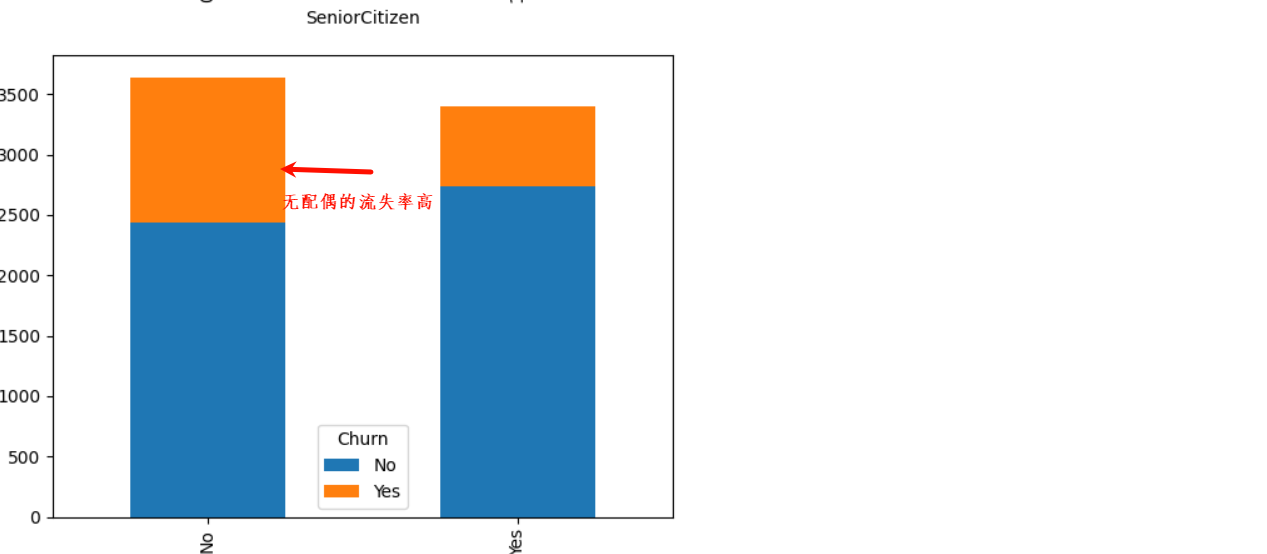
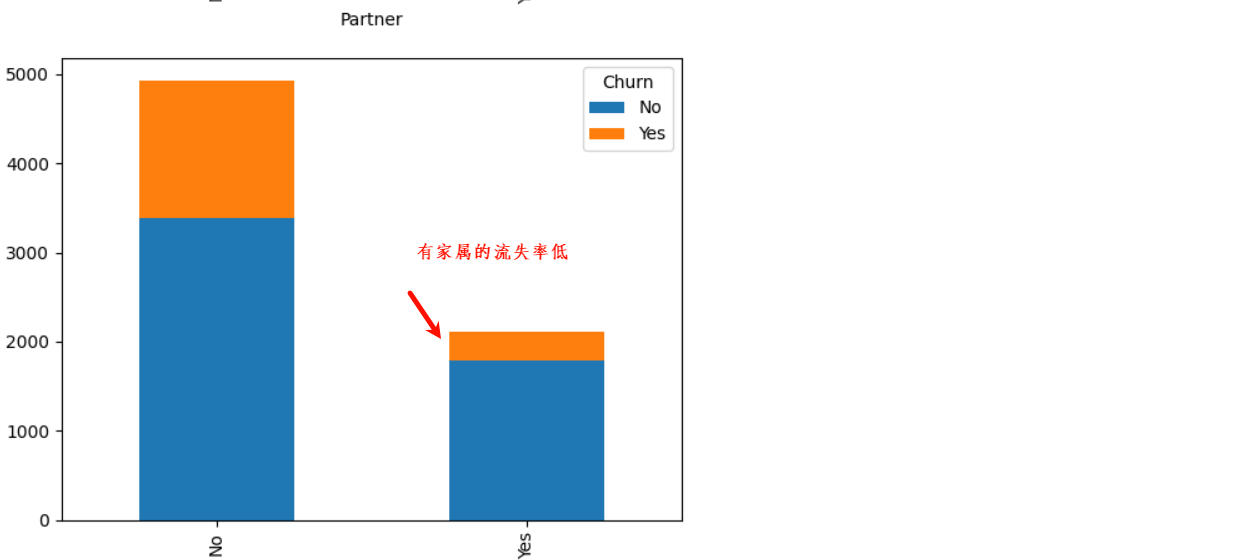
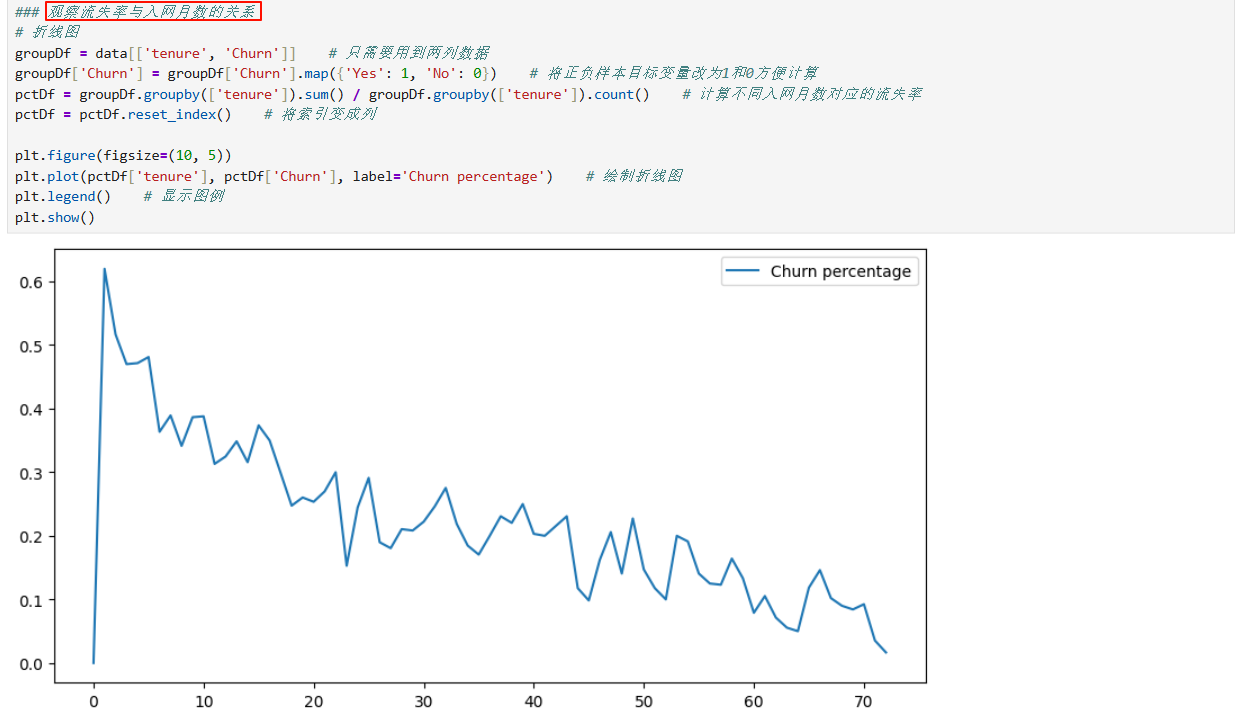

3、业务特征对客户流失影响
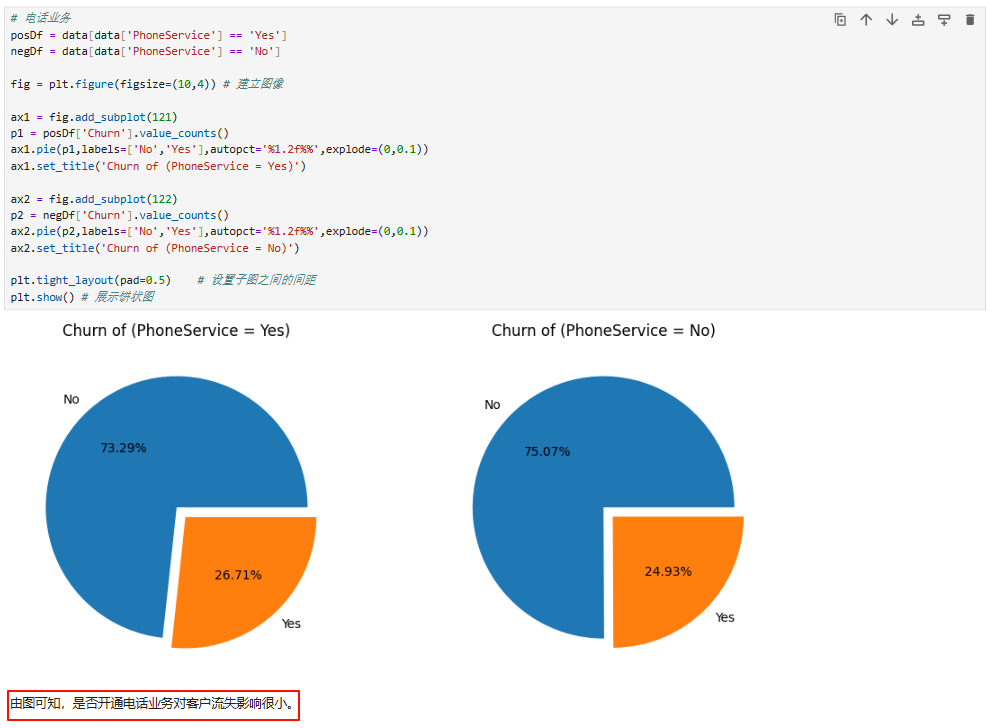
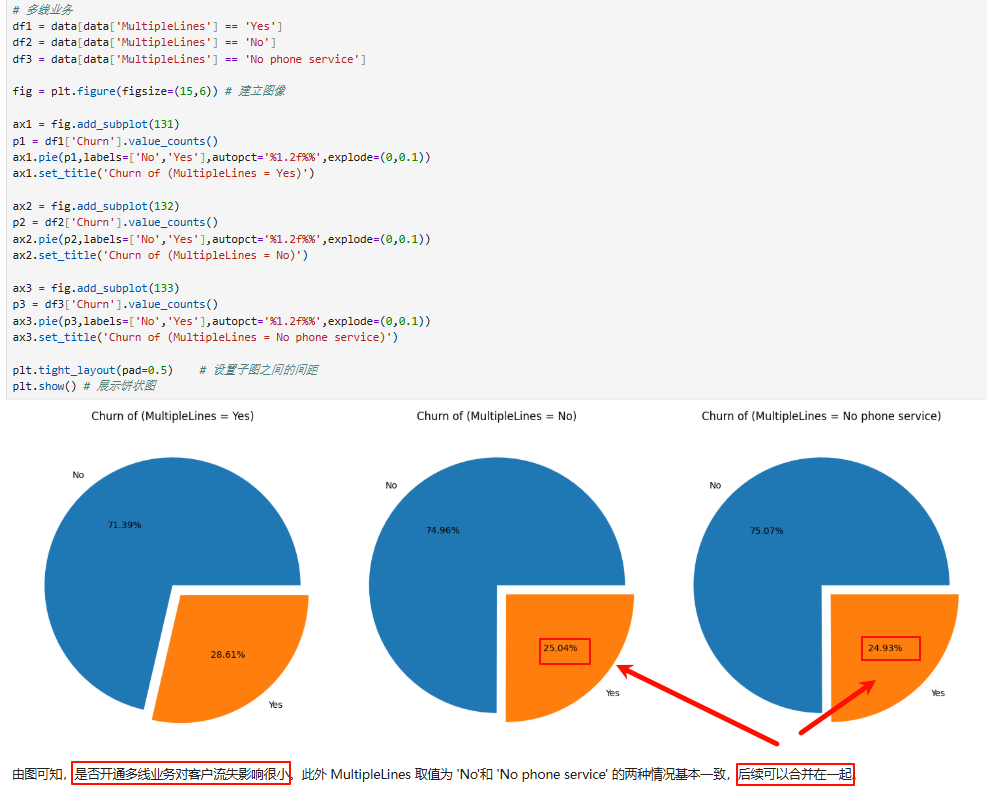
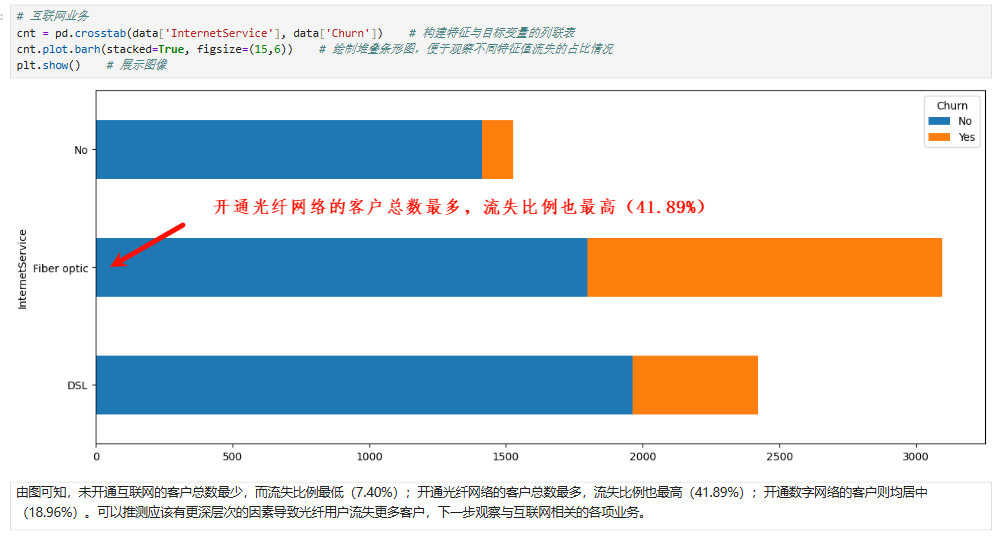
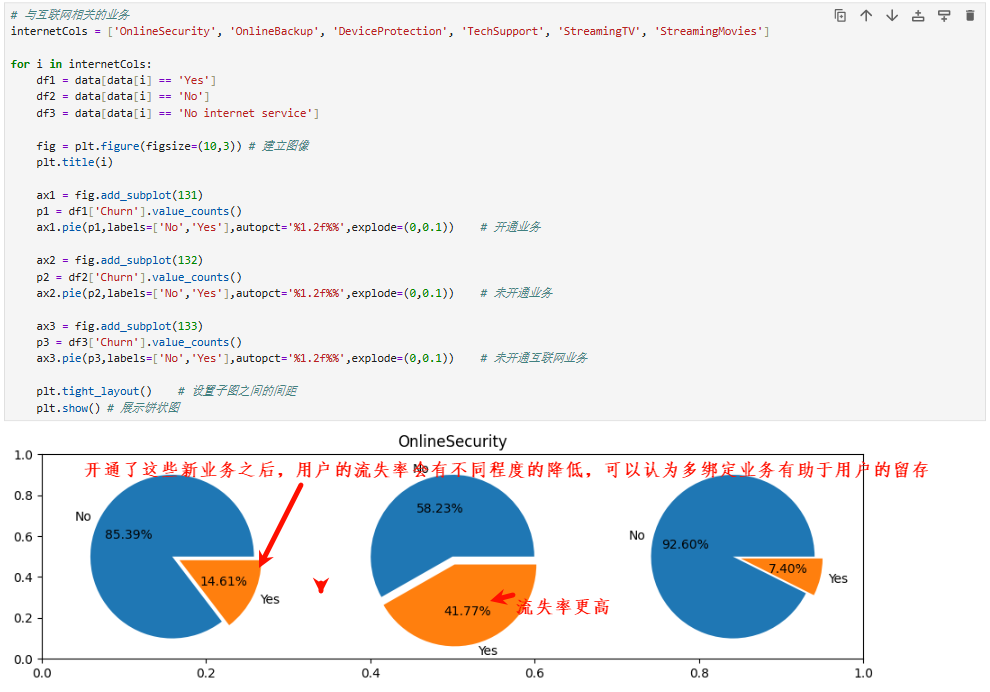
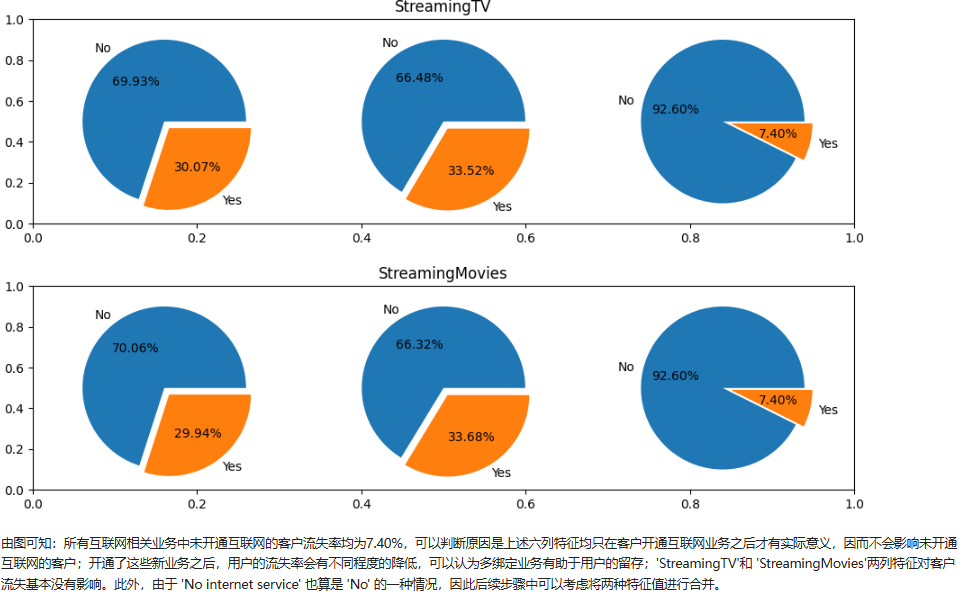
4、合约特征对客户流失影响
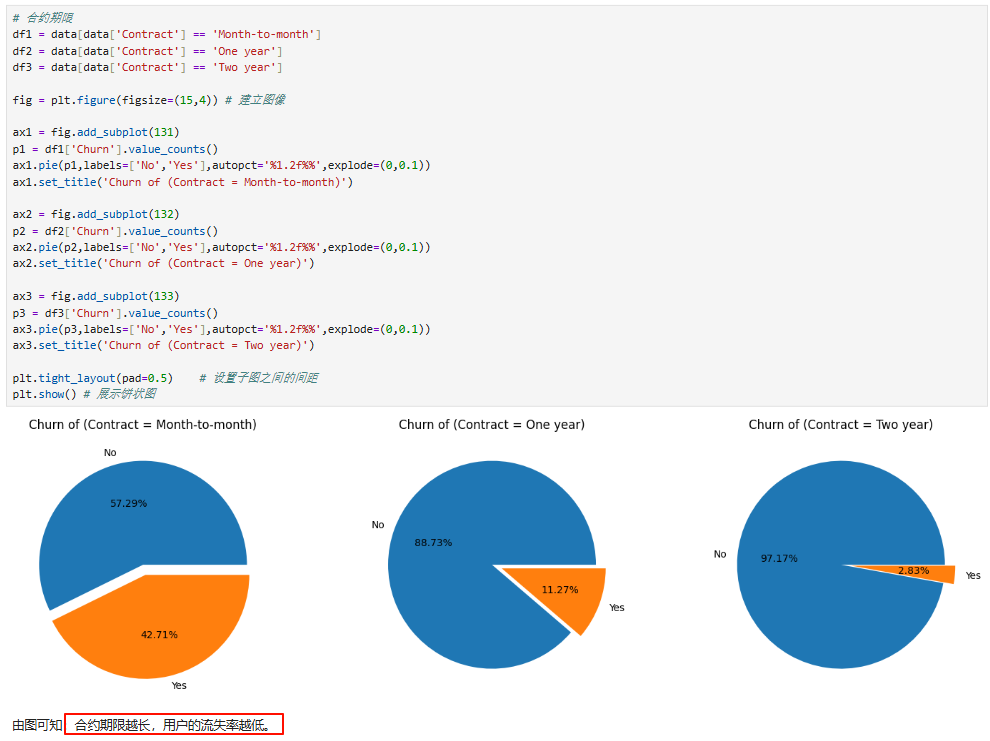
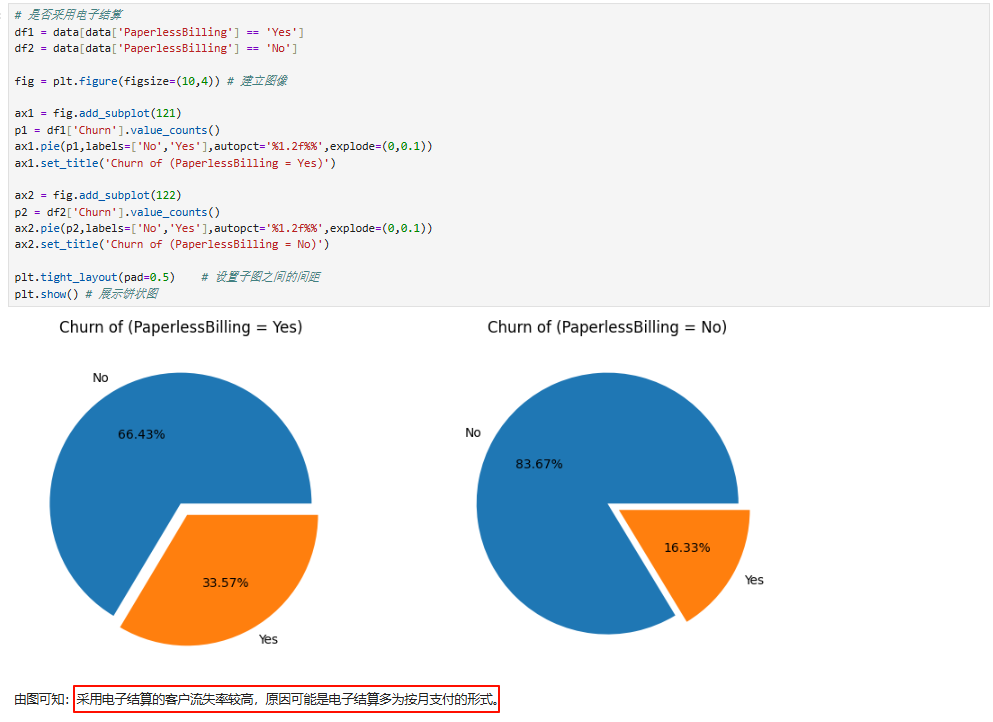

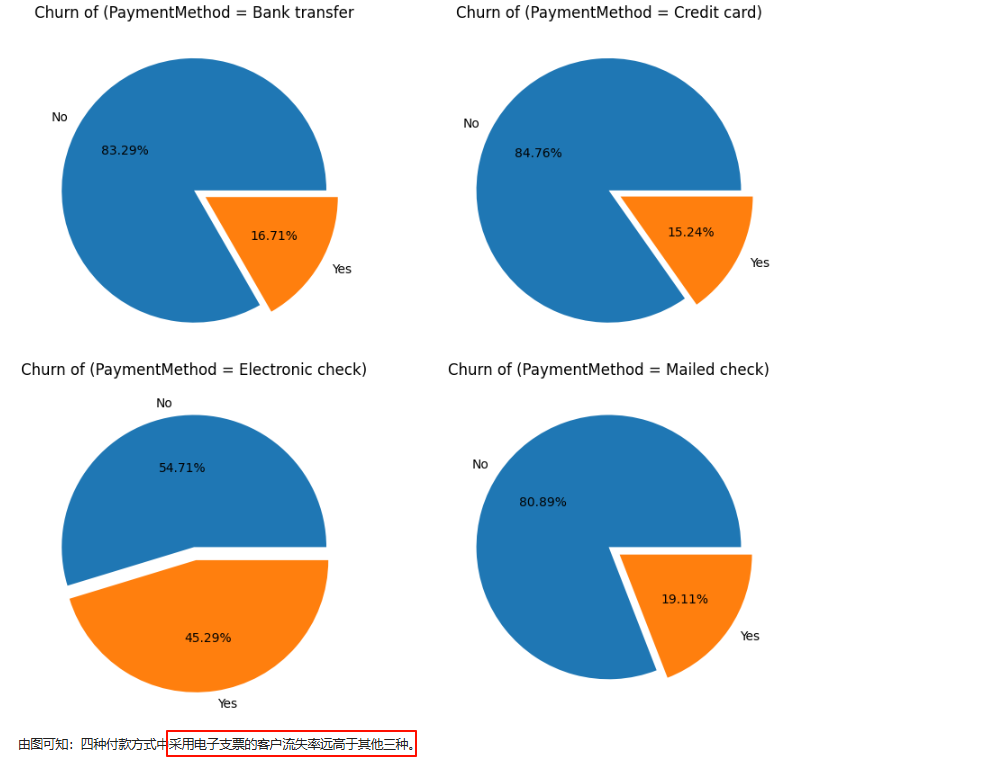
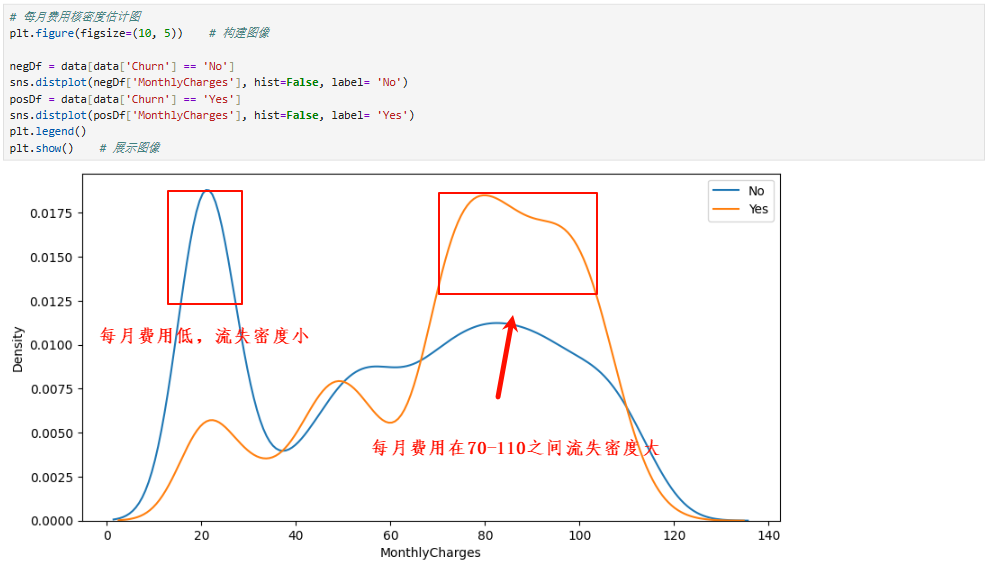
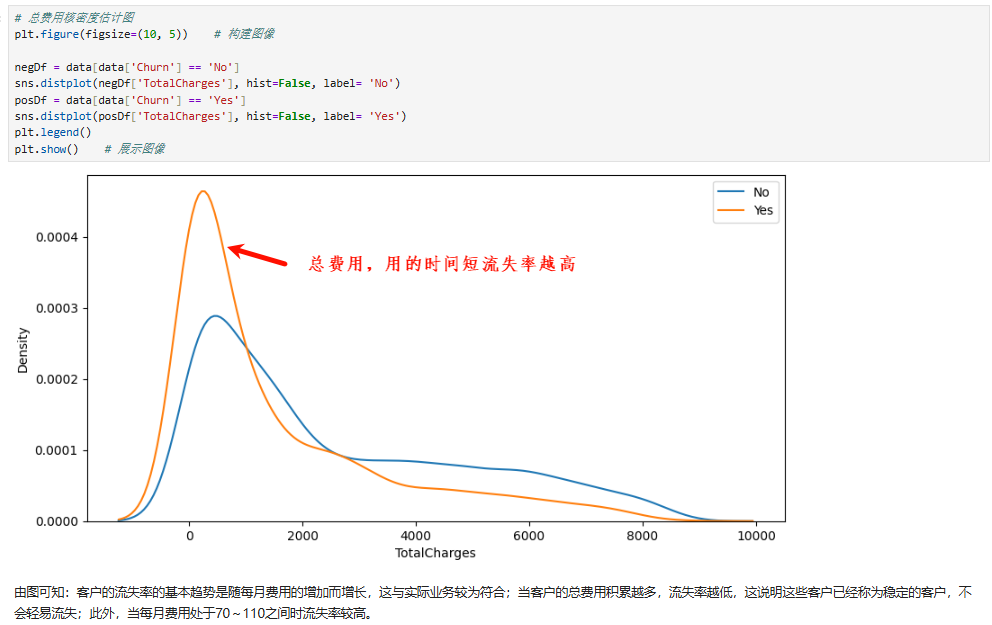
三、特征工程
1.1 连续特征的处理
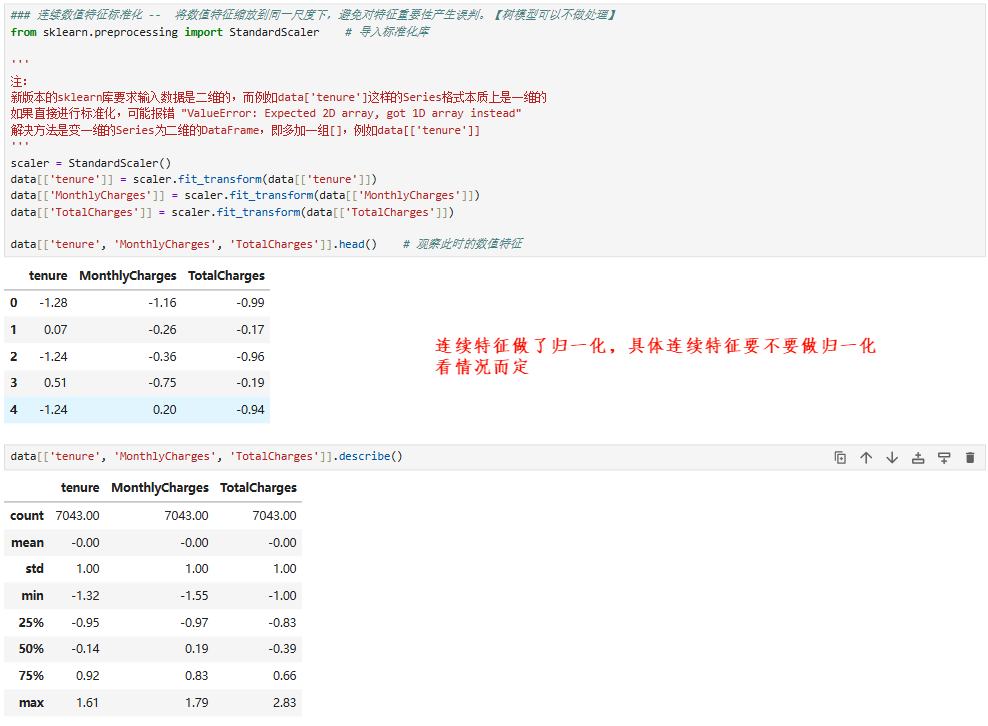
2.2 离散特征的处理
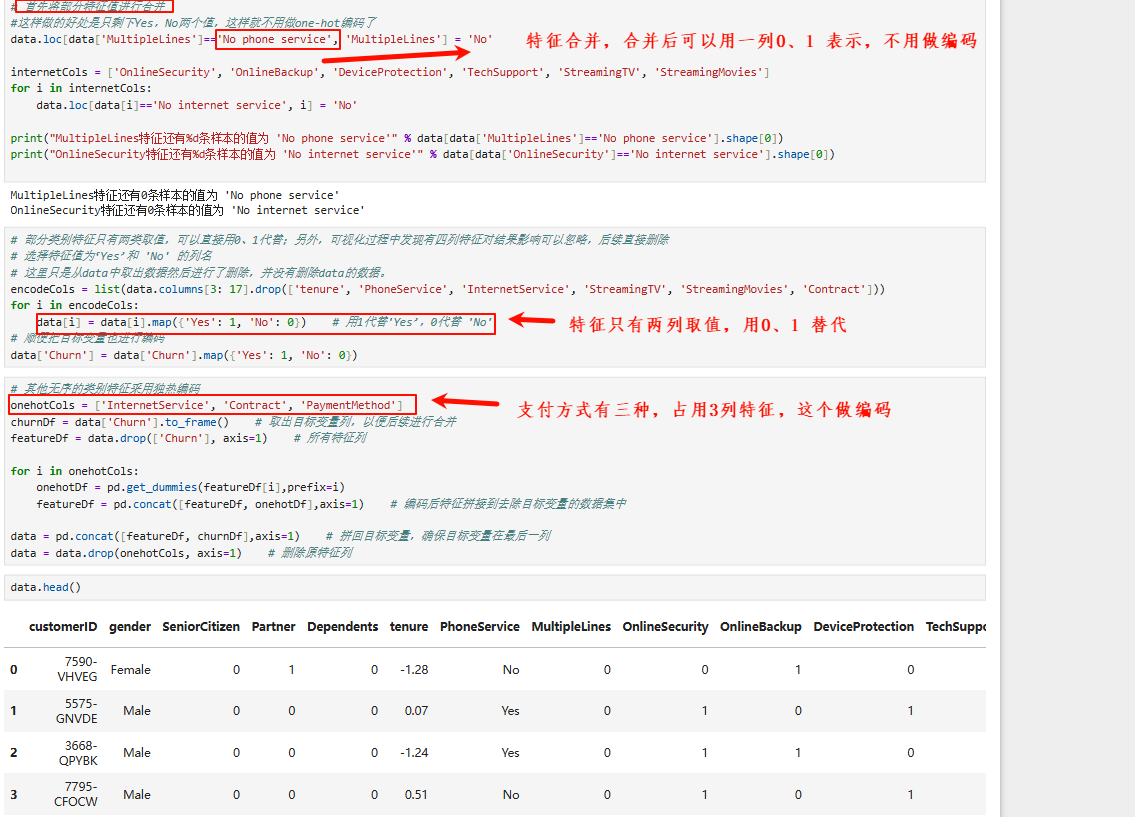
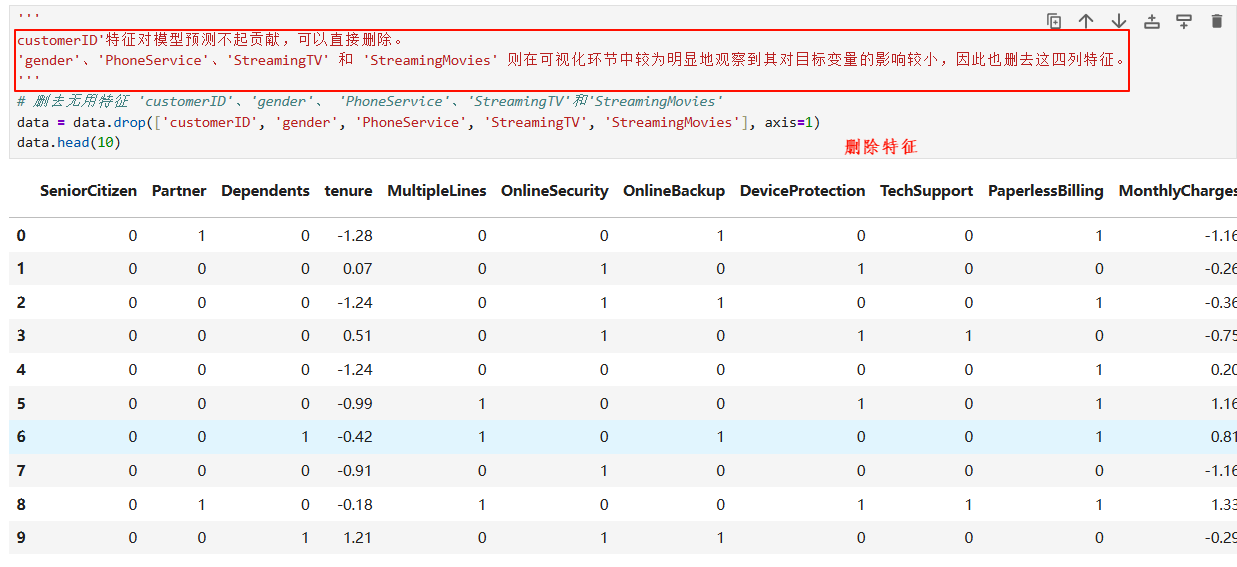
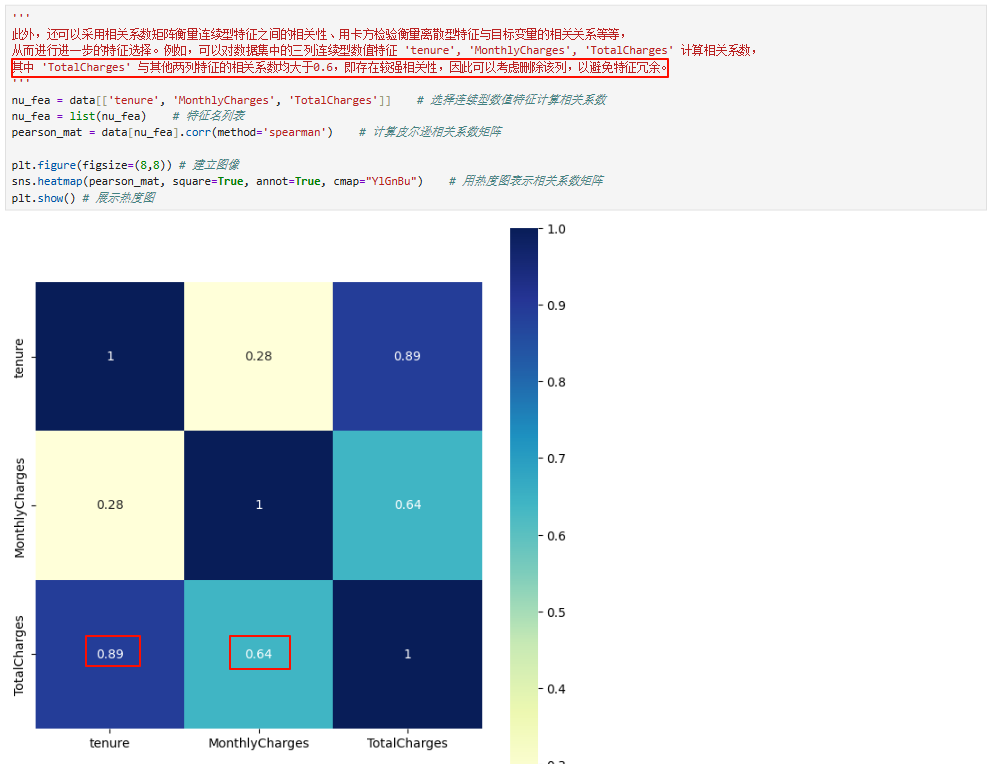
3.3 特征选择
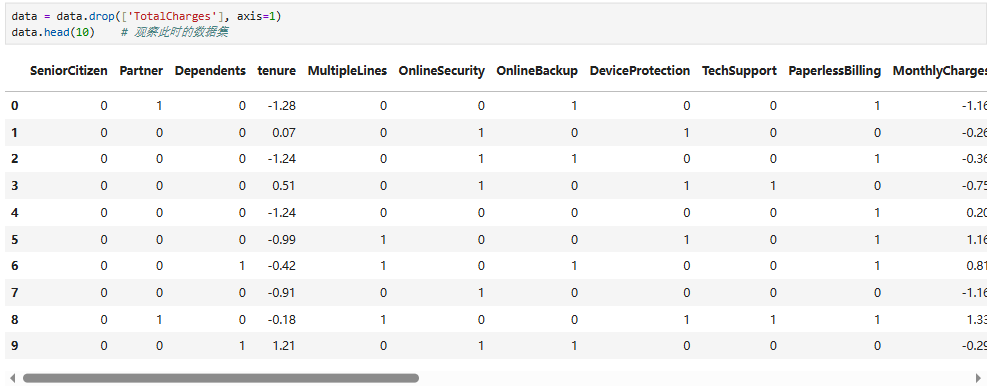
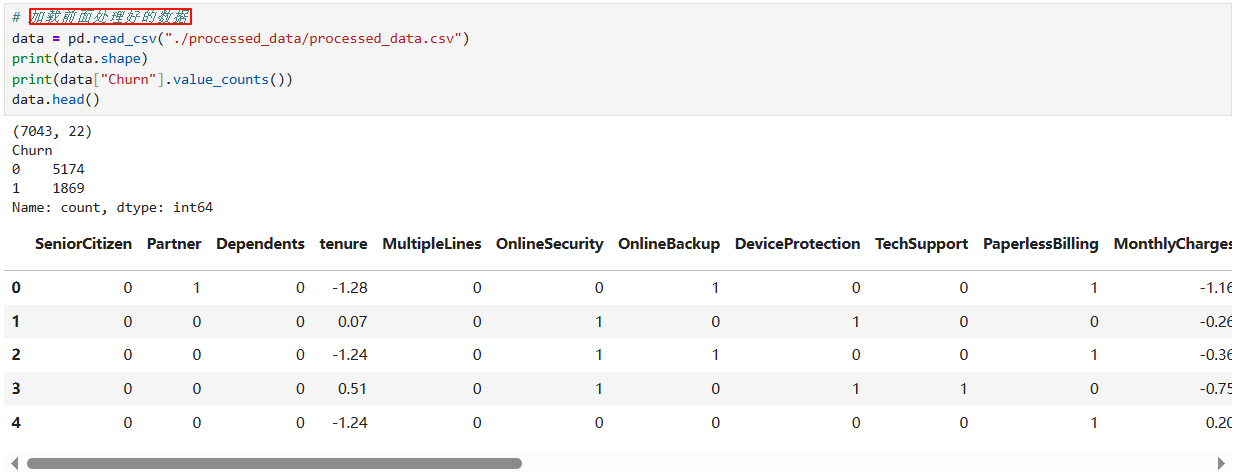
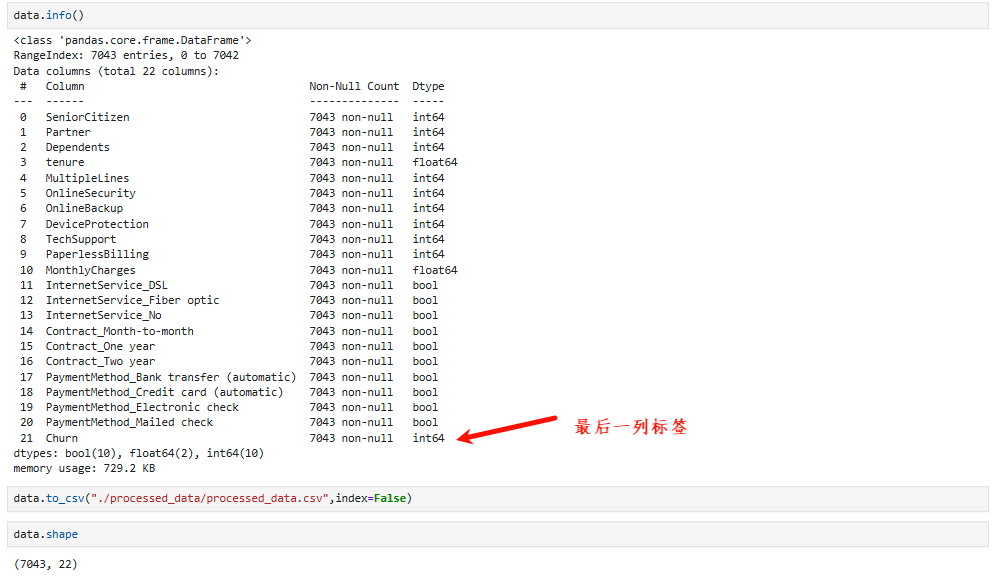
4.4 保存处理好的数据
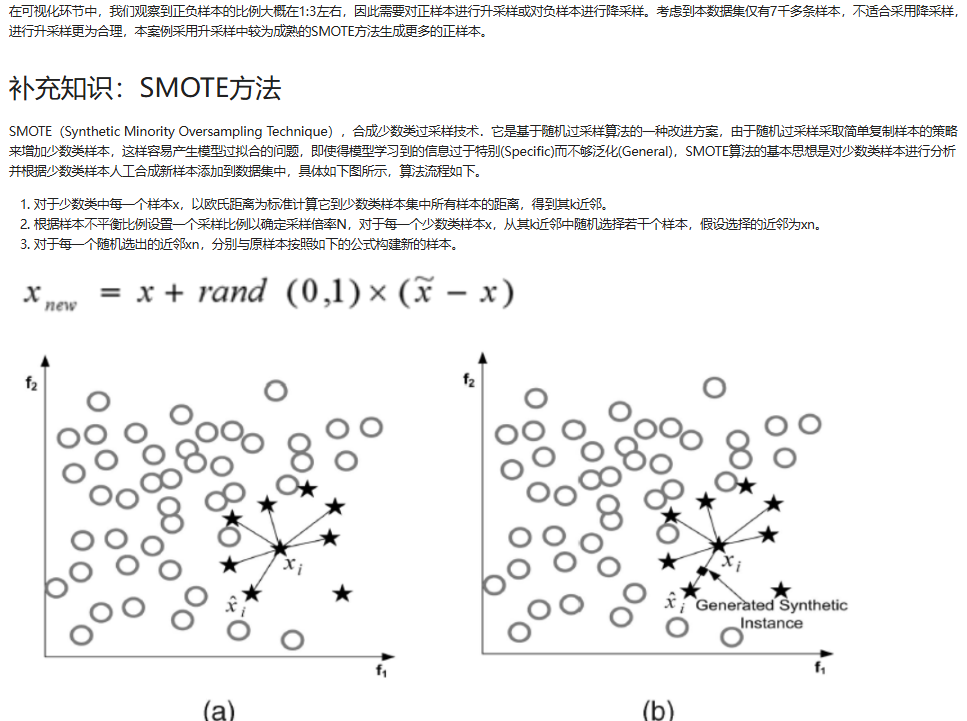
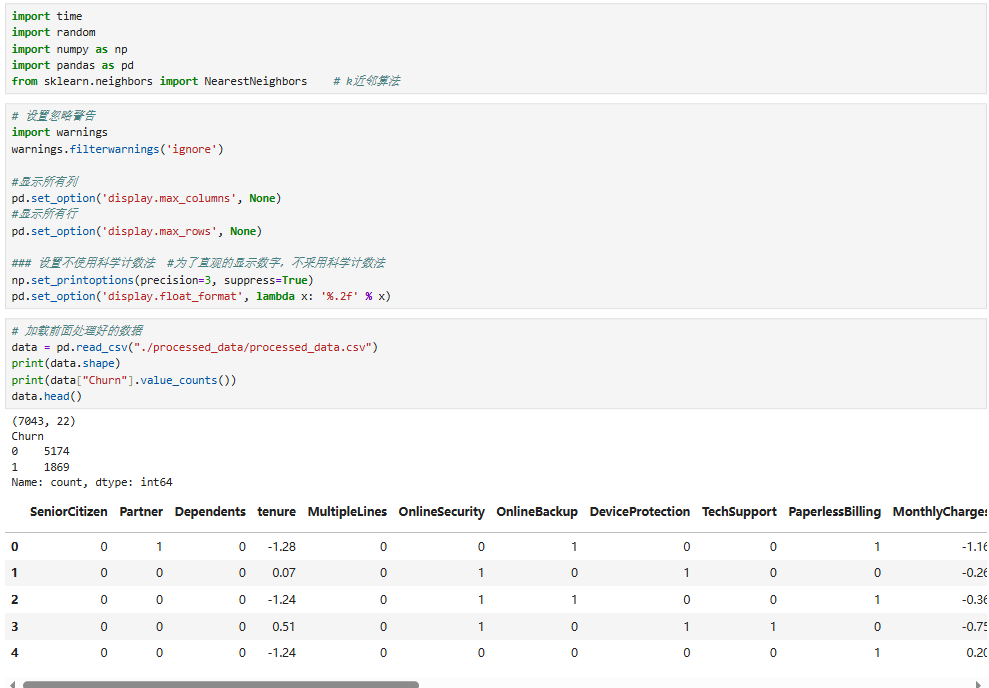
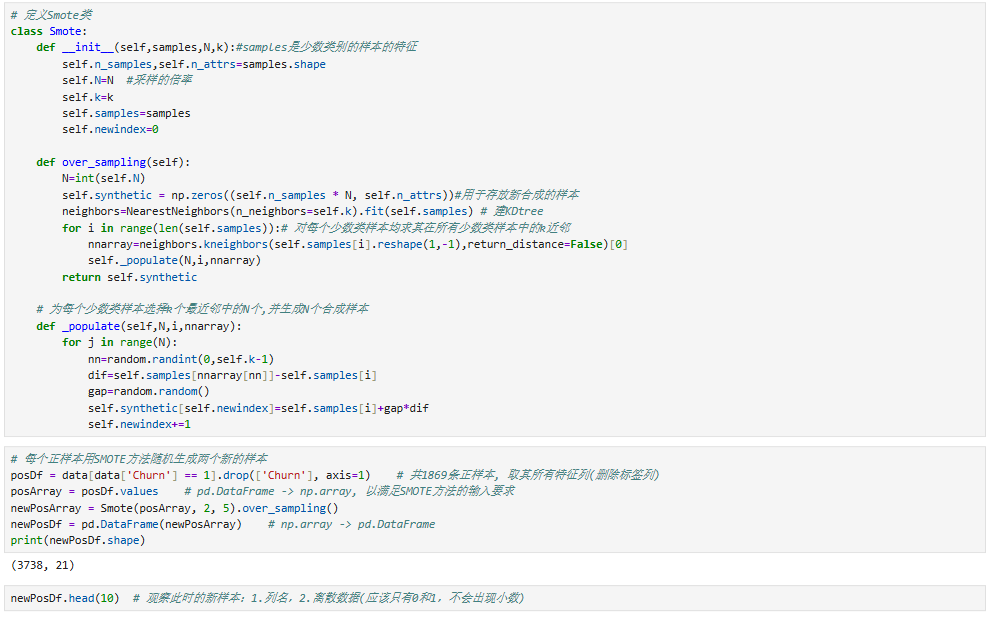
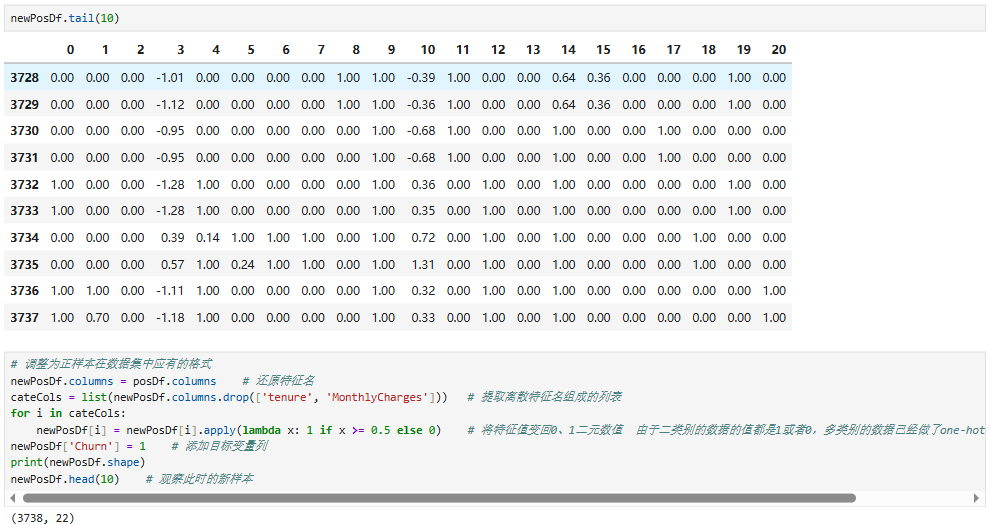
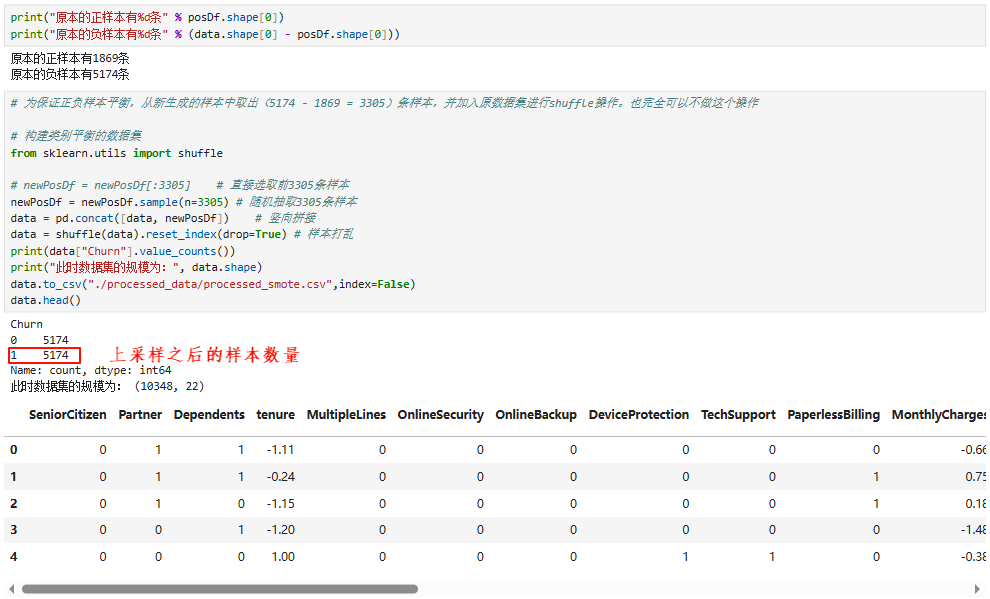
5.5 正负样本数据类别不均衡处理
四、模型选择和训练
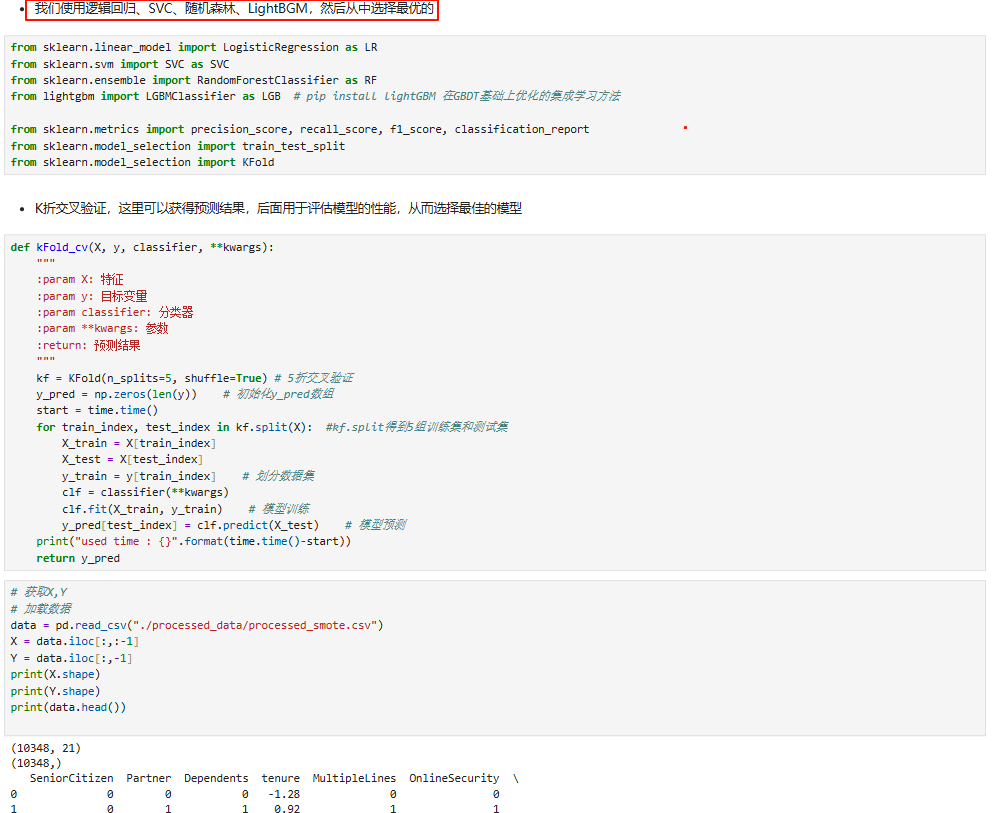
1.1 K折交叉验证
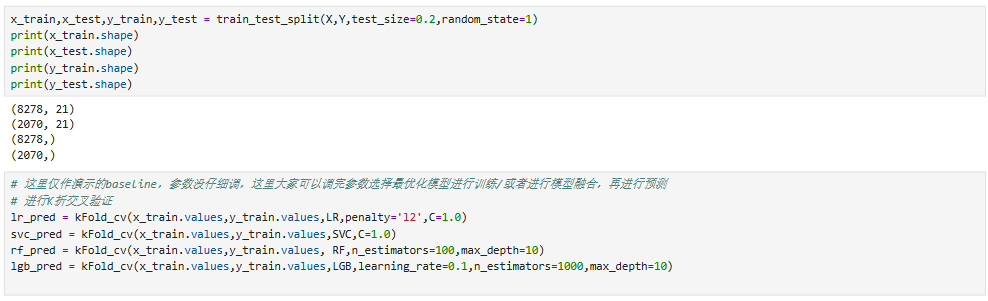
2.2 训练模型
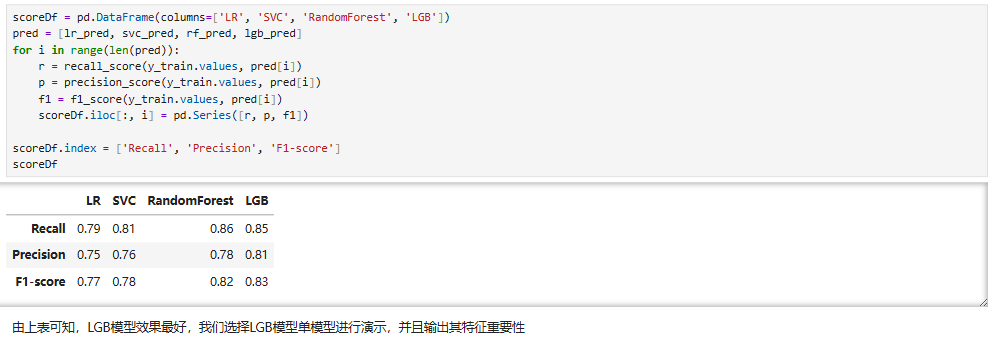
3.3 模型评估
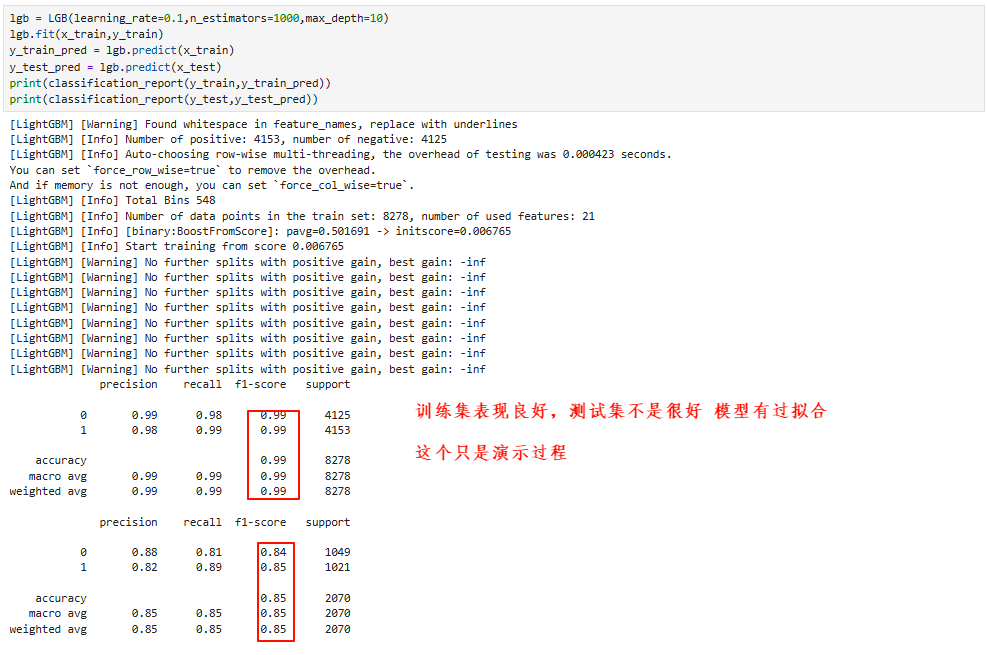
4.4 特征重要性
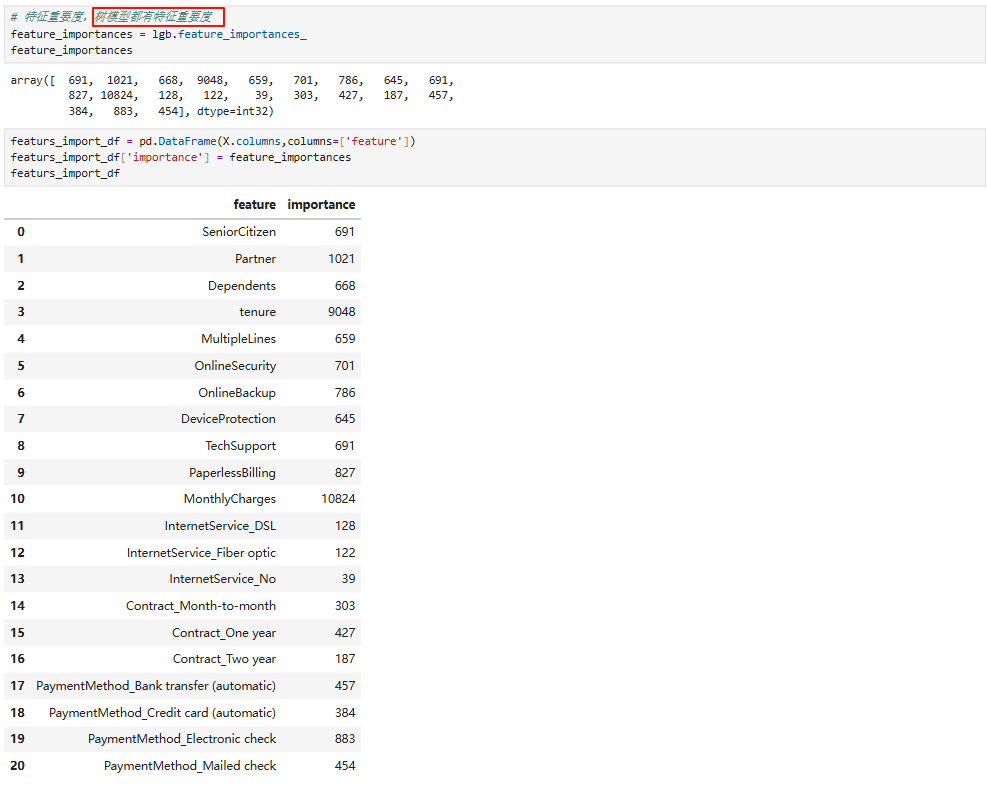
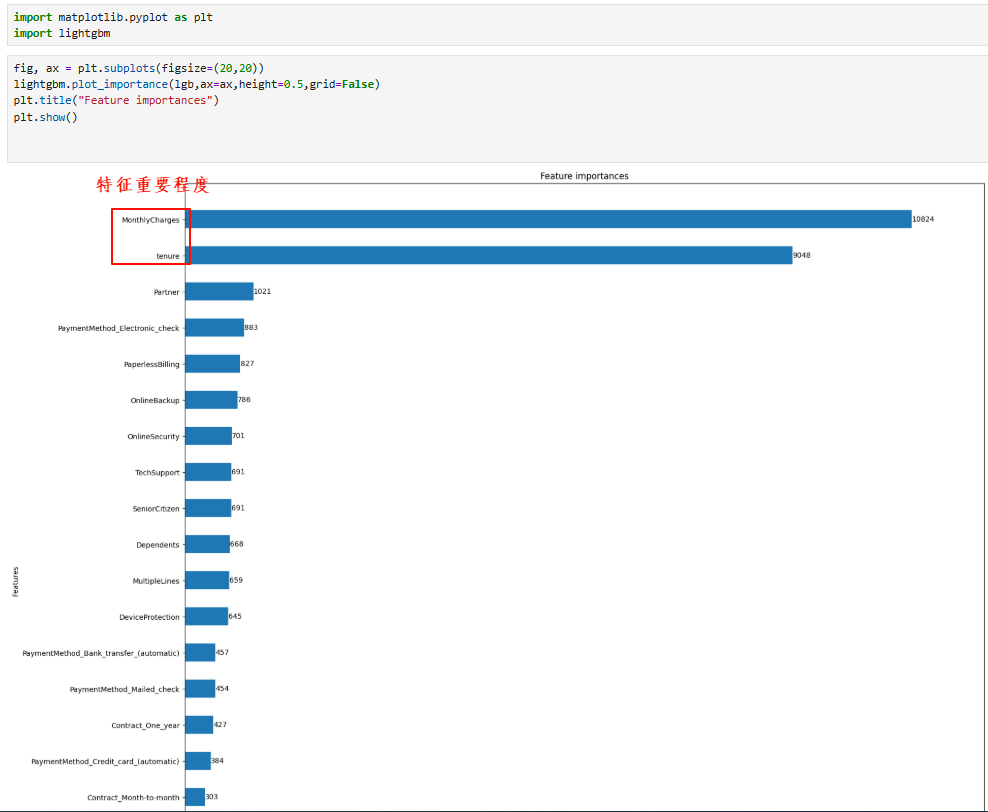
5.5 模型保存

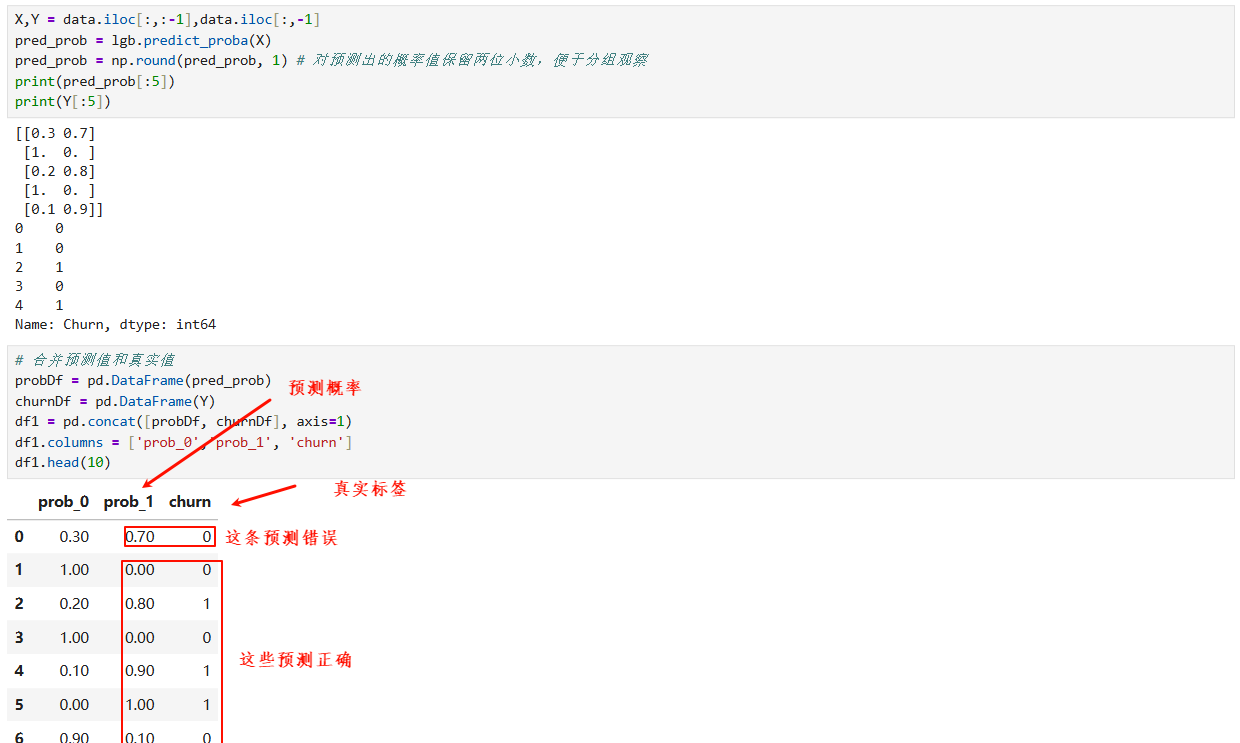
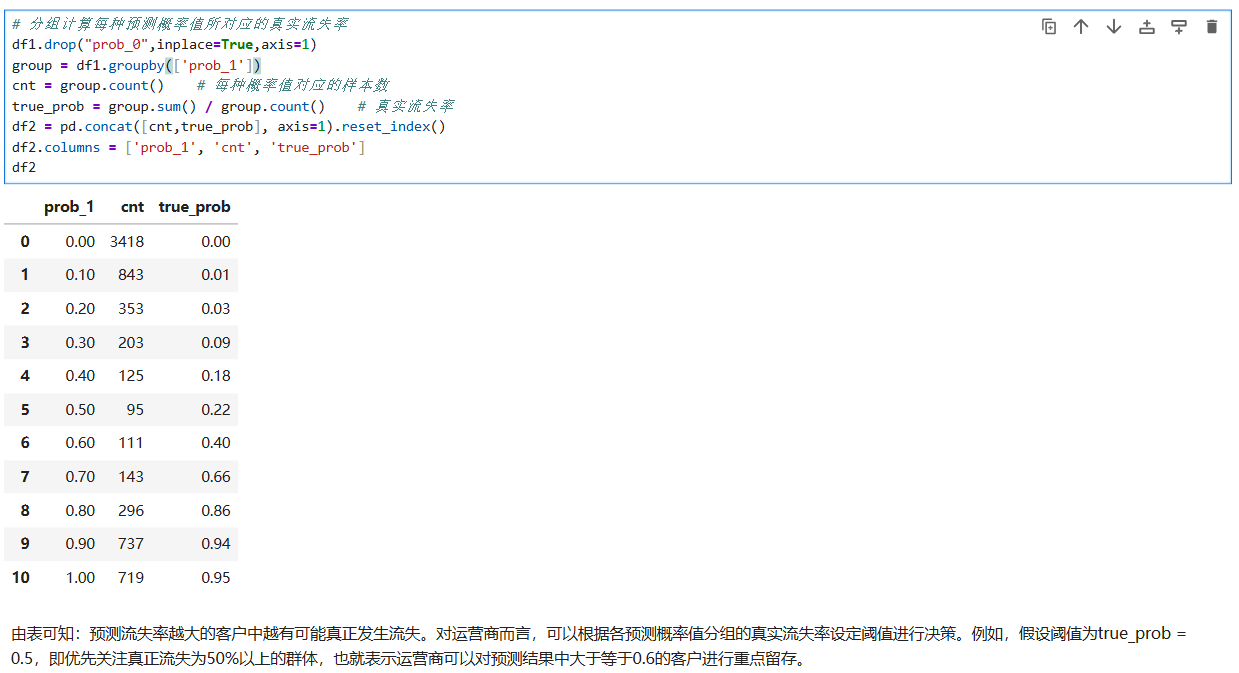
五、模型预测