| 大家好,我是工藤学编程 🦉 | 一个正在努力学习的小博主,期待你的关注 |
|---|---|
| 实战代码系列最新文章😉 | C++实现图书管理系统(Qt C++ GUI界面版) |
| SpringBoot实战系列🐷 | 【SpringBoot实战系列】SpringBoot3.X 整合 MinIO 存储原生方案 |
| 分库分表 | 分库分表之实战-sharding-JDBC分库分表执行流程原理剖析 |
| 消息队列 | 深入浅出 RabbitMQ-RabbitMQ消息确认机制(ACK) |
| AI大模型 | 零基础学AI大模型之Milvus DML实战 |
前情摘要
1、零基础学AI大模型之读懂AI大模型
2、零基础学AI大模型之从0到1调用大模型API
3、零基础学AI大模型之SpringAI
4、零基础学AI大模型之AI大模型常见概念
5、零基础学AI大模型之大模型私有化部署全指南
6、零基础学AI大模型之AI大模型可视化界面
7、零基础学AI大模型之LangChain
8、零基础学AI大模型之LangChain六大核心模块与大模型IO交互链路
9、零基础学AI大模型之Prompt提示词工程
10、零基础学AI大模型之LangChain-PromptTemplate
11、零基础学AI大模型之ChatModel聊天模型与ChatPromptTemplate实战
12、零基础学AI大模型之LangChain链
13、零基础学AI大模型之Stream流式输出实战
14、零基础学AI大模型之LangChain Output Parser
15、零基础学AI大模型之解析器PydanticOutputParser
16、零基础学AI大模型之大模型的"幻觉"
17、零基础学AI大模型之RAG技术
18、零基础学AI大模型之RAG系统链路解析与Document Loaders多案例实战
19、零基础学AI大模型之LangChain PyPDFLoader实战与PDF图片提取全解析
20、零基础学AI大模型之LangChain WebBaseLoader与Docx2txtLoader实战
21、零基础学AI大模型之RAG系统链路构建:文档切割转换全解析
22、零基础学AI大模型之LangChain 文本分割器实战:CharacterTextSplitter 与 RecursiveCharacterTextSplitter 全解析
23、零基础学AI大模型之Embedding与LLM大模型对比全解析
24、零基础学AI大模型之LangChain Embedding框架全解析
25、零基础学AI大模型之嵌入模型性能优化
26、零基础学AI大模型之向量数据库介绍与技术选型思考
27、零基础学AI大模型之Milvus向量数据库全解析
28、零基础学AI大模型之Milvus核心:分区-分片-段结构全解+最佳实践
29、零基础学AI大模型之Milvus部署架构选型+Linux实战:Docker一键部署+WebUI使用
30、零基础学AI大模型之Milvus实战:Attu可视化安装+Python整合全案例
31、零基础学AI大模型之Milvus索引实战
32、零基础学AI大模型之Milvus DML实战
33、零基础学AI大模型之Milvus向量Search查询综合案例实战
本文章目录
- 零基础学AI大模型之新版LangChain向量数据库VectorStore设计全解析
-
- 一、实战核心目标
- 二、LangChain向量存储体系架构
-
- [2.1 核心设计理念](#2.1 核心设计理念)
- 三、VectorStore核心方法详解
-
- [3.1 安装依赖(以Milvus为例)](#3.1 安装依赖(以Milvus为例))
- [3.2 核心方法分类与用法](#3.2 核心方法分类与用法)
-
- [3.2.1 文档初始化与插入方法](#3.2.1 文档初始化与插入方法)
- [3.2.2 检索核心方法](#3.2.2 检索核心方法)
- 四、主流向量数据库特性适配对比
- 五、实战场景:知识库冷启动全流程
-
- [5.1 流程步骤](#5.1 流程步骤)
- [5.2 完整代码示例](#5.2 完整代码示例)
- 六、关键注意事项
零基础学AI大模型之新版LangChain向量数据库VectorStore设计全解析
一、实战核心目标
- 理解LangChain向量存储体系的核心架构与设计理念
- 掌握VectorStore抽象类的核心方法(初始化、插入、检索)
- 明确不同向量数据库(Milvus/FAISS/Pinecone/Chroma)的特性适配
- 实现基于VectorStore的知识库冷启动全流程
- 学会在RAG系统中灵活运用VectorStore的各类方法
二、LangChain向量存储体系架构
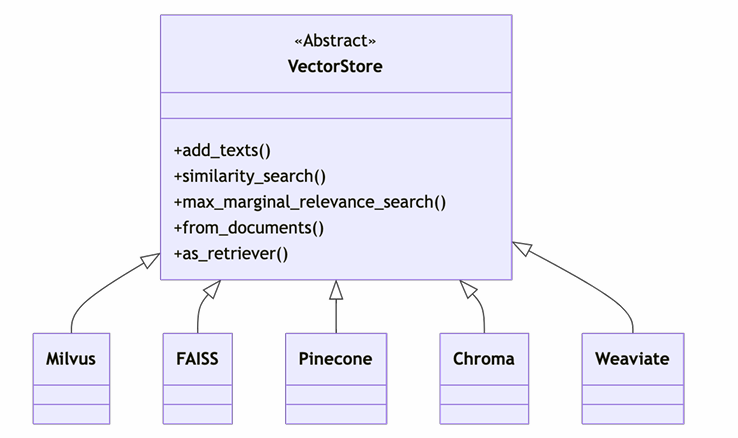
LangChain的向量存储体系核心是"抽象统一+插件化实现",既降低了学习成本,又保证了灵活性,架构流程如下:

2.1 核心设计理念
- 抽象统一接口:VectorStore作为顶层抽象类,定义了所有向量数据库都需实现的核心方法(如from_documents、similarity_search),开发者无需修改代码就能切换不同向量库。
- 插件化实现:具体的向量数据库(如Milvus)通过实现VectorStore的抽象方法,适配自身的底层API,LangChain负责统一调度。
- 无缝衔接RAG:VectorStore的输出可直接通过as_retriever()方法转换为检索器,融入LangChain的链式调用流程,无需额外适配。
三、VectorStore核心方法详解
新版LangChain的VectorStore提供了一套完整的文档管理与检索API,涵盖从初始化到检索的全流程,以下是最常用的核心方法:
3.1 安装依赖(以Milvus为例)
使用VectorStore前需安装对应向量数据库的LangChain集成包:
bash
# 安装LangChain核心库+Milvus集成包
pip install langchain-core langchain-milvus3.2 核心方法分类与用法
3.2.1 文档初始化与插入方法
核心用于将文档导入向量库,分为"首次初始化"和"增量追加"两种场景:
| 方法名 | 方法类型 | 核心作用 | 常用参数 | 典型场景 |
|---|---|---|---|---|
| from_documents() | 类方法(静态) | 初始化向量库并批量插入文档 | documents(Document列表)、embedding(嵌入模型)、**kwargs(向量库连接参数) | 知识库冷启动、首次数据入库 |
| add_documents() | 实例方法 | 向已存在的向量库追加文档 | documents(Document列表) | 知识库增量更新 |
| add_texts() | 实例方法 | 直接插入文本列表(无需封装为Document) | texts(文本列表)、metadatas(元数据列表) | 简单文本快速入库 |
代码示例:初始化与追加文档
python
from langchain_core.documents import Document
from langchain_community.embeddings import OpenAIEmbeddings
from langchain_milvus import Milvus
# 1. 准备测试文档(Document对象列表)
documents = [
Document(
page_content="LangChain是一个大模型应用开发框架",
metadata={"category": "AI框架", "author": "工藤学编程"}
),
Document(
page_content="VectorStore是LangChain的向量存储抽象层",
metadata={"category": "LangChain核心模块", "author": "工藤学编程"}
)
]
# 2. 初始化嵌入模型
embedding = OpenAIEmbeddings(api_key="你的API密钥") # 也可使用本地化嵌入模型(如Sentence-BERT)
# 3. from_documents():首次初始化向量库并插入文档(自动创建集合)
vector_store = Milvus.from_documents(
documents=documents,
embedding=embedding,
connection_args={"uri": "http://47.119.128.20:19530"}, # Milvus连接参数
collection_name="langchain_demo",
)
# 4. add_documents():向已有向量库追加文档(集合已存在)
new_doc = Document(
page_content="Milvus是一款高性能开源向量数据库",
metadata={"category": "向量数据库", "author": "工藤学编程"}
)
vector_store.add_documents(documents=[new_doc])
# 5. add_texts():直接插入文本(自动关联元数据)
texts = ["LangChain支持多种向量数据库", "VectorStore支持相似度搜索和MMR搜索"]
metadatas = [{"category": "LangChain特性"}, {"category": "VectorStore特性"}]
vector_store.add_texts(texts=texts, metadatas=metadatas)3.2.2 检索核心方法
用于从向量库中查询相关文档,涵盖基础相似度搜索和多样化搜索:
| 方法名 | 核心作用 | 常用参数 | 返回结果 |
|---|---|---|---|
| similarity_search() | 基础相似度搜索(返回最相关文档) | query(查询文本)、k(返回数量)、filter(元数据过滤) | Document列表 |
| similarity_search_with_score() | 相似度搜索(返回文档+相似度得分) | 同similarity_search() | (Document, score)元组列表 |
| max_marginal_relevance_search() | MMR搜索(平衡相关性与多样性) | query、k、fetch_k(候选集大小)、lambda_mult(权衡系数) | Document列表 |
| as_retriever() | 转换为检索器(供LangChain链式调用) | search_kwargs(检索参数,如k、filter) | Retriever对象 |
代码示例:多种检索方式实战
python
# 1. 基础相似度搜索(返回前2条最相关文档)
sim_results = vector_store.similarity_search(
query="LangChain的核心模块有哪些?",
k=2,
filter={"category": "LangChain核心模块"} # 元数据过滤
)
print("=== 相似度搜索结果 ===")
for doc in sim_results:
print(f"内容:{doc.page_content}")
print(f"元数据:{doc.metadata}\n")
# 2. 带相似度得分的搜索
sim_score_results = vector_store.similarity_search_with_score(
query="向量数据库有哪些?",
k=1
)
print("=== 带得分的搜索结果 ===")
for doc, score in sim_score_results:
print(f"内容:{doc.page_content}")
print(f"相似度得分:{score:.4f}\n")
# 3. MMR多样化搜索
mmr_results = vector_store.max_marginal_relevance_search(
query="AI相关的工具和框架有哪些?",
k=2,
fetch_k=5, # 从5条候选集中筛选2条
lambda_mult=0.6 # 偏向相关性
)
print("=== MMR搜索结果 ===")
for doc in mmr_results:
print(f"内容:{doc.page_content}")
print(f"元数据:{doc.metadata}\n")
# 4. 转换为Retriever(融入LangChain链)
retriever = vector_store.as_retriever(
search_kwargs={
"k": 2,
"filter": {"author": "工藤学编程"}
}
)
# 链式调用中使用
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(api_key="你的API密钥")
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| llm
| StrOutputParser()
)
# 执行问答
print("=== 链式调用结果 ===")
print(chain.invoke("LangChain的向量存储模块是什么?"))四、主流向量数据库特性适配对比
LangChain的VectorStore支持多种主流向量数据库,但不同数据库的特性和适用场景有差异,选择时需结合业务需求:
| 特性 | Milvus | FAISS | Pinecone | Chroma |
|---|---|---|---|---|
| 分布式支持 | ✅ (支持集群部署) | ❌ (仅单机) | ✅ (云原生分布式) | ❌ (仅单机/小集群) |
| 元数据过滤 | ✅ (支持复杂条件) | ✅ (基础过滤) | ✅ (支持复杂条件) | ✅ (基础过滤) |
| 自动索引管理 | ✅ (创建时自动建索引) | ✅ (默认创建索引) | ✅ (云服务自动管理) | ❌ (需手动配置) |
| 本地运行 | ✅ (Docker一键部署) | ✅ (纯Python实现) | ❌ (仅云服务) | ✅ (本地文件存储) |
| 支持相似度算法 | 8种(L2/COSINE/IP等) | 3种(L2/COSINE/IP) | 4种(含余弦/内积) | 4种(基础算法) |
| 适用场景 | 企业级生产环境、大数据量 | 本地测试、小规模数据 | 云原生生产环境 | 开发测试、轻量应用 |
选型建议:
- 生产环境+大数据量:优先选Milvus(开源分布式)或Pinecone(云原生托管)。
- 本地开发+快速验证:选FAISS(无部署成本)或Chroma(轻量易用)。
- 需要复杂过滤+高可用:选Milvus或Pinecone。
五、实战场景:知识库冷启动全流程
基于VectorStore实现知识库冷启动(从文档导入到检索问答),是RAG系统落地的核心环节,完整流程如下:
5.1 流程步骤
- 准备原始文档(TXT/PDF/Word等)。
- 使用Text Splitter分割文档(避免长文本语义丢失)。
- 通过from_documents()初始化VectorStore并入库。
- 转换为Retriever接入LangChain链,实现问答。
5.2 完整代码示例
python
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import SentenceTransformerEmbeddings
from langchain_milvus import Milvus
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# 1. 准备原始文档(这里用模拟文档,实际可从文件读取)
raw_text = """
LangChain VectorStore核心特性:
1. 抽象统一接口,支持多向量数据库适配;
2. 内置相似度搜索、MMR搜索等多种检索方式;
3. 无缝衔接LangChain链式调用,适配RAG系统;
4. 支持文档批量插入与增量更新。
VectorStore常用方法:
- from_documents():初始化并插入文档;
- add_documents():增量追加文档;
- similarity_search():相似度检索;
- max_marginal_relevance_search():多样化检索。
"""
# 2. 文本分割(RecursiveCharacterTextSplitter适合通用场景)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=100, # 每个片段100字符
chunk_overlap=20, # 片段重叠20字符(保证语义连贯)
length_function=len
)
chunks = text_splitter.split_text(raw_text)
# 封装为Document对象(添加元数据)
documents = [Document(page_content=chunk, metadata={"source": "LangChain官方文档"}) for chunk in chunks]
# 3. 初始化嵌入模型(使用本地化模型,无需API密钥)
embedding = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
# 4. 初始化VectorStore(Milvus)并入库
vector_store = Milvus.from_documents(
documents=documents,
embedding=embedding,
connection_args={"uri": "http://192.168.229.128:19530"},
collection_name="langchain_vectorstore_demo",
drop_old=True # 存在同名集合时删除(冷启动专用)
)
# 5. 转换为Retriever并构建RAG链
retriever = vector_store.as_retriever(
search_kwargs={"k": 2, "filter": {"source": "LangChain官方文档"}}
)
llm = ChatOpenAI(api_key="你的API密钥", model="gpt-3.5-turbo")
rag_chain = (
{"context": retriever | (lambda docs: "\n\n".join([d.page_content for d in docs])), "question": RunnablePassthrough()}
| """根据以下上下文回答问题:
{context}
问题:{question}
"""
| llm
| StrOutputParser()
)
# 6. 执行问答(测试冷启动效果)
print("=== 知识库冷启动问答结果 ===")
print(rag_chain.invoke("LangChain VectorStore的核心特性有哪些?"))
print("\n=== 检索到的相关文档 ===")
for doc in retriever.get_relevant_documents("LangChain VectorStore的核心特性有哪些?"):
print(f"- {doc.page_content}")六、关键注意事项
- 接口统一但特性有差异:VectorStore的通用方法(如similarity_search)在所有向量库中都可用,但高级特性(如复杂过滤、分布式部署)需看具体向量库是否支持。
- 参数传递技巧:向量库的特有参数(如Milvus的nprobe)可通过**kwargs传入from_documents()或检索方法,LangChain会自动转发给底层API。
- 嵌入模型维度匹配:插入文档和检索时使用的嵌入模型必须一致,否则向量维度不匹配会导致检索失败。
- 性能优化点:批量插入优先用from_documents()(效率高于循环add_documents());检索时合理设置k值(建议3-10),避免返回过多结果影响速度。
- 元数据设计:元数据(如category、source)需提前规划,方便后续通过filter参数实现精准过滤。
如果本文对你有帮助,欢迎点赞+关注,后续会持续输出AI大模型与LangChain的实战内容~