智能体(Agent)正在重塑AI应用范式,而ReAct框架则是构建可靠智能体的核心方法论。本文将带你从零构建生产级智能体系统,解决"幻觉"和"不可控"两大痛点。
目录
[1.1 传统LLM应用的局限性](#1.1 传统LLM应用的局限性)
[1.2 ReAct框架的核心价值](#1.2 ReAct框架的核心价值)
[2.1 核心架构设计理念](#2.1 核心架构设计理念)
[2.2 核心算法实现](#2.2 核心算法实现)
[2.2.1 ReAct循环算法](#2.2.1 ReAct循环算法)
[2.2.2 思维链生成器](#2.2.2 思维链生成器)
[2.3 性能特性分析](#2.3 性能特性分析)
[2.3.1 延迟与成本分析](#2.3.1 延迟与成本分析)
[2.3.2 性能优化策略](#2.3.2 性能优化策略)
[3.1 环境准备与依赖安装](#3.1 环境准备与依赖安装)
[3.2 基础工具定义与实现](#3.2 基础工具定义与实现)
[3.2.1 工具基类设计](#3.2.1 工具基类设计)
[3.2.2 天气查询工具](#3.2.2 天气查询工具)
[3.2.3 计算器工具](#3.2.3 计算器工具)
[3.2.4 网络搜索工具](#3.2.4 网络搜索工具)
[3.3 ReAct智能体核心实现](#3.3 ReAct智能体核心实现)
[3.3.1 智能体状态管理](#3.3.1 智能体状态管理)
[3.3.2 工具管理器](#3.3.2 工具管理器)
[3.3.3 ReAct智能体核心类](#3.3.3 ReAct智能体核心类)
[3.4 完整示例:智能问答助手](#3.4 完整示例:智能问答助手)
[3.5 分步骤实现指南](#3.5 分步骤实现指南)
[3.6 常见问题解决方案](#3.6 常见问题解决方案)
[4.1 企业级实践案例](#4.1 企业级实践案例)
[4.2 性能优化技巧](#4.2 性能优化技巧)
[4.2.1 工具调用优化](#4.2.1 工具调用优化)
[4.2.2 LLM调用优化](#4.2.2 LLM调用优化)
[4.2.3 并发处理优化](#4.2.3 并发处理优化)
[4.3 故障排查指南](#4.3 故障排查指南)
[4.3.1 常见故障场景](#4.3.1 常见故障场景)
[4.3.2 监控与告警](#4.3.2 监控与告警)
[4.3.3 日志与调试](#4.3.3 日志与调试)
[5.1 技术选型建议](#5.1 技术选型建议)
[5.2 未来发展趋势](#5.2 未来发展趋势)
[5.3 关键成功因素](#5.3 关键成功因素)
摘要
ReAct(Reasoning + Acting)框架通过思维链推理 和工具调用的结合,让大语言模型具备复杂任务规划和执行能力。本文深入解析ReAct的核心原理,提供从单智能体到多智能体协作的完整实现方案,涵盖工具集成、记忆管理、错误恢复等关键模块。通过企业级案例和性能优化技巧,帮助开发者构建可解释、可控制、可扩展的智能体系统,实现从原型到生产的平滑过渡。
一、智能体时代:为什么需要ReAct框架?
1.1 传统LLM应用的局限性
大语言模型虽然具备强大的生成能力,但在实际应用中面临三大挑战:
1. 幻觉问题(Hallucination):模型会生成看似合理但实际错误的信息,这在需要精确执行的任务中不可接受。
2. 缺乏可解释性:模型直接输出结果,无法追溯决策过程,难以调试和优化。
3. 无法执行外部动作:模型只能生成文本,无法调用API、查询数据库或操作外部系统。
1.2 ReAct框架的核心价值
ReAct框架通过Reasoning(推理) 和**Acting(执行)**的交替循环,让智能体能够:
-
规划任务:将复杂问题分解为可执行的子任务
-
调用工具:使用外部工具获取信息或执行操作
-
自我修正:根据执行结果调整后续行动
-
可解释输出:完整的思维链记录,便于调试和审计
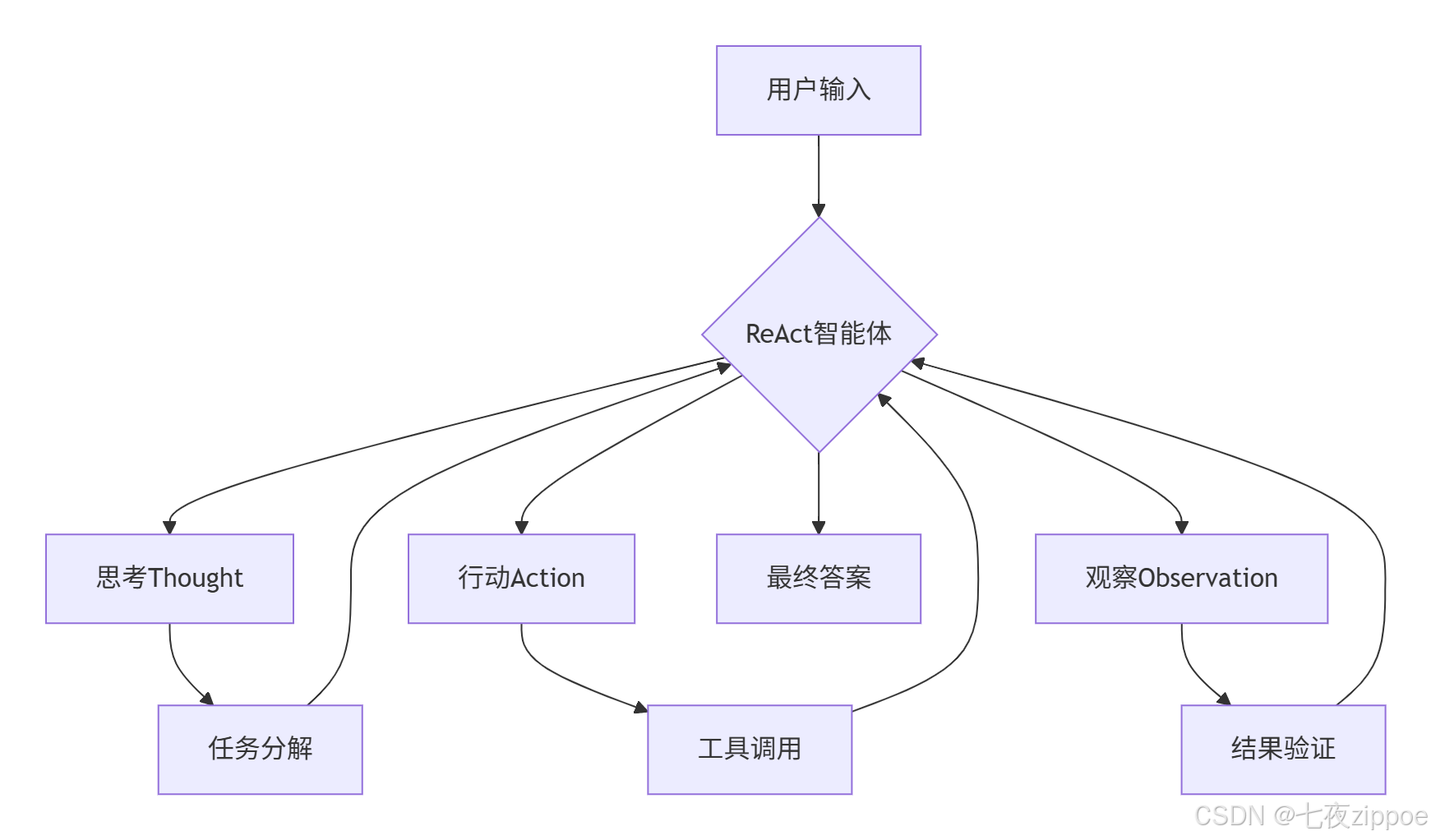
二、ReAct框架技术原理深度解析
2.1 核心架构设计理念
ReAct框架的核心是思维链(Chain of Thought) 和**工具调用(Tool Calling)**的协同工作。其设计遵循以下原则:
1. 模块化设计:将推理、执行、观察分离为独立模块,便于扩展和维护。
2. 状态管理:维护智能体的内部状态,包括任务上下文、执行历史、可用工具等。
3. 错误恢复机制:当工具调用失败或结果不符合预期时,能够自动重试或调整策略。
4. 可观测性:记录完整的执行轨迹,支持调试和性能分析。
2.2 核心算法实现
2.2.1 ReAct循环算法
python
# 伪代码:ReAct核心循环
def react_loop(initial_question, max_steps=10):
# 初始化状态
state = {
"question": initial_question,
"thoughts": [],
"actions": [],
"observations": [],
"final_answer": None
}
for step in range(max_steps):
# 1. 思考:生成下一步行动
thought = generate_thought(state)
state["thoughts"].append(thought)
# 2. 行动:调用工具或生成答案
if should_act(thought):
action = generate_action(thought, state)
state["actions"].append(action)
# 调用工具并获取结果
observation = execute_action(action)
state["observations"].append(observation)
else:
# 生成最终答案
final_answer = generate_final_answer(state)
state["final_answer"] = final_answer
break
return state2.2.2 思维链生成器
python
# 环境要求:python>=3.8, openai>=1.0.0
from openai import OpenAI
import json
class ThoughtGenerator:
def __init__(self, model="gpt-4-turbo"):
self.client = OpenAI()
self.model = model
def generate(self, state):
prompt = self._build_prompt(state)
response = self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": prompt}],
temperature=0.1,
max_tokens=500
)
return response.choices[0].message.content
def _build_prompt(self, state):
# 构建包含历史记录的提示词
prompt = f"""你是一个智能助手,需要回答以下问题:{state['question']}
当前状态:
{self._format_history(state)}
请思考下一步应该做什么,并输出JSON格式:
{{
"thought": "你的思考过程",
"action_type": "tool_call|final_answer",
"action": {{
"tool_name": "工具名称(如果是工具调用)",
"tool_input": "工具输入参数"
}}
}}
"""
return prompt
def _format_history(self, state):
history = []
for i, (thought, action, observation) in enumerate(zip(
state["thoughts"], state["actions"], state["observations"]
)):
history.append(f"步骤{i+1}:")
history.append(f"思考: {thought}")
if action:
history.append(f"行动: {action}")
if observation:
history.append(f"观察: {observation}")
return "\n".join(history)2.3 性能特性分析
2.3.1 延迟与成本分析
ReAct框架的延迟主要来自:
-
LLM调用延迟:每次思考步骤需要调用LLM,通常100-500ms
-
工具执行延迟:外部API调用或数据库查询,可能100ms-数秒
-
网络延迟:智能体与工具服务之间的网络通信
成本构成:
-
LLM调用成本:按token计费,ReAct模式通常需要更多token
-
工具调用成本:外部API费用或计算资源成本
-
基础设施成本:服务器、网络、存储等
2.3.2 性能优化策略
1. 工具缓存:对频繁调用的工具结果进行缓存,减少重复调用。
2. 批量处理:将多个工具调用合并为批量请求,减少网络开销。
3. 提前终止:当达到足够置信度时提前结束循环,避免不必要的步骤。
4. 并行执行:对于独立的工具调用,采用并行执行提升效率。
三、实战部分:从零构建ReAct智能体
3.1 环境准备与依赖安装
bash
# 创建项目目录
mkdir react-agent && cd react-agent
# 创建虚拟环境
python -m venv venv
source venv/bin/activate # Linux/Mac
# venv\Scripts\activate # Windows
# 安装核心依赖
pip install openai==1.0.0
pip install langchain==0.1.0
pip install langchain-openai==0.0.1
pip install requests==2.31.0
pip install python-dotenv==1.0.0
# 创建环境变量文件
echo "OPENAI_API_KEY=your_api_key_here" > .env3.2 基础工具定义与实现
3.2.1 工具基类设计
python
# tools/base_tool.py
from abc import ABC, abstractmethod
from typing import Any, Dict, Optional
import json
class BaseTool(ABC):
"""工具基类,所有工具必须继承此类"""
def __init__(self, name: str, description: str):
self.name = name
self.description = description
@abstractmethod
def execute(self, input_data: Dict[str, Any]) -> Dict[str, Any]:
"""执行工具并返回结果"""
pass
def __str__(self):
return f"{self.name}: {self.description}"3.2.2 天气查询工具
python
# tools/weather_tool.py
import requests
from typing import Dict, Any
from .base_tool import BaseTool
class WeatherTool(BaseTool):
def __init__(self):
super().__init__(
name="get_weather",
description="获取指定城市的天气信息"
)
self.api_key = "your_weather_api_key" # 替换为实际API密钥
def execute(self, input_data: Dict[str, Any]) -> Dict[str, Any]:
city = input_data.get("city")
if not city:
return {"error": "缺少城市参数"}
try:
# 调用天气API(示例使用和风天气)
url = f"https://devapi.qweather.com/v7/weather/now"
params = {
"location": city,
"key": self.api_key
}
response = requests.get(url, params=params)
data = response.json()
if data["code"] == "200":
now = data["now"]
return {
"city": city,
"temp": now["temp"],
"feels_like": now["feelsLike"],
"text": now["text"],
"wind": f"{now['windDir']} {now['windScale']}级",
"humidity": now["humidity"]
}
else:
return {"error": f"获取天气失败: {data['code']}"}
except Exception as e:
return {"error": f"天气查询异常: {str(e)}"}3.2.3 计算器工具
python
# tools/calculator_tool.py
import math
from typing import Dict, Any
from .base_tool import BaseTool
class CalculatorTool(BaseTool):
def __init__(self):
super().__init__(
name="calculator",
description="执行数学计算,支持加减乘除、平方根等"
)
def execute(self, input_data: Dict[str, Any]) -> Dict[str, Any]:
expression = input_data.get("expression")
if not expression:
return {"error": "缺少计算表达式"}
try:
# 安全地执行计算
allowed_names = {k: v for k, v in math.__dict__.items() if not k.startswith("_")}
result = eval(expression, {"__builtins__": {}}, allowed_names)
return {"result": result, "expression": expression}
except Exception as e:
return {"error": f"计算失败: {str(e)}"}3.2.4 网络搜索工具
python
# tools/web_search_tool.py
import requests
from typing import Dict, Any
from .base_tool import BaseTool
class WebSearchTool(BaseTool):
def __init__(self):
super().__init__(
name="web_search",
description="搜索互联网信息,返回相关网页摘要"
)
self.api_key = "your_search_api_key" # 替换为实际API密钥
def execute(self, input_data: Dict[str, Any]) -> Dict[str, Any]:
query = input_data.get("query")
if not query:
return {"error": "缺少搜索关键词"}
try:
# 调用搜索引擎API(示例使用SerpAPI)
url = "https://serpapi.com/search"
params = {
"q": query,
"api_key": self.api_key,
"engine": "google"
}
response = requests.get(url, params=params)
data = response.json()
# 提取搜索结果
results = []
if "organic_results" in data:
for item in data["organic_results"][:3]:
results.append({
"title": item.get("title", ""),
"link": item.get("link", ""),
"snippet": item.get("snippet", "")
})
return {
"query": query,
"results": results
}
except Exception as e:
return {"error": f"搜索失败: {str(e)}"}3.3 ReAct智能体核心实现
3.3.1 智能体状态管理
python
# agent/state.py
from typing import Dict, List, Any, Optional
from datetime import datetime
import json
class AgentState:
"""智能体状态管理类"""
def __init__(self, question: str):
self.question = question
self.thoughts: List[str] = []
self.actions: List[Dict[str, Any]] = []
self.observations: List[Dict[str, Any]] = []
self.final_answer: Optional[str] = None
self.start_time = datetime.now()
self.end_time: Optional[datetime] = None
self.error: Optional[str] = None
def add_thought(self, thought: str):
self.thoughts.append(thought)
def add_action(self, action: Dict[str, Any]):
self.actions.append(action)
def add_observation(self, observation: Dict[str, Any]):
self.observations.append(observation)
def set_final_answer(self, answer: str):
self.final_answer = answer
self.end_time = datetime.now()
def set_error(self, error: str):
self.error = error
self.end_time = datetime.now()
def get_execution_time(self) -> Optional[float]:
if self.end_time:
return (self.end_time - self.start_time).total_seconds()
return None
def to_dict(self) -> Dict[str, Any]:
return {
"question": self.question,
"thoughts": self.thoughts,
"actions": self.actions,
"observations": self.observations,
"final_answer": self.final_answer,
"start_time": self.start_time.isoformat(),
"end_time": self.end_time.isoformat() if self.end_time else None,
"execution_time": self.get_execution_time(),
"error": self.error
}
def __str__(self):
return json.dumps(self.to_dict(), indent=2, ensure_ascii=False)3.3.2 工具管理器
python
# agent/tool_manager.py
from typing import Dict, Any, List
from tools.base_tool import BaseTool
class ToolManager:
"""工具管理器,负责工具的注册、查找和执行"""
def __init__(self):
self.tools: Dict[str, BaseTool] = {}
def register_tool(self, tool: BaseTool):
"""注册工具"""
self.tools[tool.name] = tool
def get_tool(self, tool_name: str) -> Optional[BaseTool]:
"""根据名称获取工具"""
return self.tools.get(tool_name)
def get_tools_descriptions(self) -> List[str]:
"""获取所有工具的描述"""
return [str(tool) for tool in self.tools.values()]
def execute_tool(self, tool_name: str, input_data: Dict[str, Any]) -> Dict[str, Any]:
"""执行工具"""
tool = self.get_tool(tool_name)
if not tool:
return {"error": f"工具不存在: {tool_name}"}
try:
return tool.execute(input_data)
except Exception as e:
return {"error": f"工具执行异常: {str(e)}"}3.3.3 ReAct智能体核心类
python
# agent/react_agent.py
import json
import re
from typing import Dict, Any, Optional
from openai import OpenAI
from .state import AgentState
from .tool_manager import ToolManager
class ReActAgent:
"""ReAct智能体核心类"""
def __init__(self, model: str = "gpt-4-turbo", max_steps: int = 10):
self.client = OpenAI()
self.model = model
self.max_steps = max_steps
self.tool_manager = ToolManager()
self.system_prompt = self._build_system_prompt()
def register_tool(self, tool):
"""注册工具"""
self.tool_manager.register_tool(tool)
def run(self, question: str) -> AgentState:
"""执行ReAct循环"""
state = AgentState(question)
for step in range(self.max_steps):
# 1. 思考:生成下一步行动
thought_response = self._generate_thought(state)
if thought_response.get("error"):
state.set_error(thought_response["error"])
break
thought = thought_response["thought"]
action_type = thought_response["action_type"]
action_data = thought_response.get("action", {})
state.add_thought(thought)
# 2. 执行行动
if action_type == "tool_call":
tool_name = action_data.get("tool_name")
tool_input = action_data.get("tool_input", {})
state.add_action({
"type": "tool_call",
"tool_name": tool_name,
"tool_input": tool_input
})
# 执行工具
observation = self.tool_manager.execute_tool(tool_name, tool_input)
state.add_observation(observation)
# 检查是否出错
if observation.get("error"):
state.set_error(observation["error"])
break
elif action_type == "final_answer":
final_answer = action_data.get("answer", "")
state.set_final_answer(final_answer)
break
else:
state.set_error(f"未知的行动类型: {action_type}")
break
return state
def _generate_thought(self, state: AgentState) -> Dict[str, Any]:
"""生成思考步骤"""
prompt = self._build_user_prompt(state)
try:
response = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": self.system_prompt},
{"role": "user", "content": prompt}
],
temperature=0.1,
max_tokens=1000,
response_format={"type": "json_object"}
)
content = response.choices[0].message.content
return json.loads(content)
except Exception as e:
return {"error": f"思考生成失败: {str(e)}"}
def _build_system_prompt(self) -> str:
"""构建系统提示词"""
tools_descriptions = self.tool_manager.get_tools_descriptions()
return f"""你是一个ReAct智能体,需要回答用户的问题。你可以使用以下工具:
{chr(10).join(tools_descriptions)}
请按照以下步骤工作:
1. 思考:分析问题,决定下一步行动
2. 行动:调用工具或生成最终答案
3. 观察:记录工具执行结果
输出必须是JSON格式:
{{
"thought": "你的思考过程",
"action_type": "tool_call|final_answer",
"action": {{
"tool_name": "工具名称(如果是工具调用)",
"tool_input": {{"参数名": "参数值"}},
"answer": "最终答案(如果是final_answer)"
}}
}}
"""
def _build_user_prompt(self, state: AgentState) -> str:
"""构建用户提示词"""
history = []
for i, (thought, action, observation) in enumerate(zip(
state.thoughts, state.actions, state.observations
)):
history.append(f"步骤 {i+1}:")
history.append(f"思考: {thought}")
if action:
history.append(f"行动: {json.dumps(action, ensure_ascii=False)}")
if observation:
history.append(f"观察: {json.dumps(observation, ensure_ascii=False)}")
return f"""问题:{state.question}
当前执行历史:
{chr(10).join(history) if history else "无历史记录"}
请思考下一步应该做什么。"""3.4 完整示例:智能问答助手
python
# main.py
import os
from dotenv import load_dotenv
from tools.weather_tool import WeatherTool
from tools.calculator_tool import CalculatorTool
from tools.web_search_tool import WebSearchTool
from agent.react_agent import ReActAgent
# 加载环境变量
load_dotenv()
def main():
# 初始化智能体
agent = ReActAgent(model="gpt-4-turbo", max_steps=8)
# 注册工具
agent.register_tool(WeatherTool())
agent.register_tool(CalculatorTool())
agent.register_tool(WebSearchTool())
# 测试问题
questions = [
"北京今天的天气怎么样?",
"计算一下(3.14 * 10^2)的平方根",
"帮我搜索一下最新的AI技术趋势"
]
for question in questions:
print(f"\n{'='*50}")
print(f"问题: {question}")
print(f"{'='*50}")
# 执行智能体
state = agent.run(question)
# 输出结果
if state.final_answer:
print(f"最终答案: {state.final_answer}")
elif state.error:
print(f"执行出错: {state.error}")
else:
print("执行超时,未生成最终答案")
# 输出执行历史
print(f"\n执行历史({len(state.thoughts)}步):")
for i, (thought, action, observation) in enumerate(zip(
state.thoughts, state.actions, state.observations
)):
print(f"\n步骤 {i+1}:")
print(f"思考: {thought}")
if action:
print(f"行动: {action}")
if observation:
print(f"观察: {observation}")
print(f"\n执行时间: {state.get_execution_time():.2f}秒")
if __name__ == "__main__":
main()3.5 分步骤实现指南
步骤1:环境准备
-
创建Python虚拟环境
-
安装必要的依赖包
-
配置API密钥(OpenAI、天气API、搜索API)
步骤2:工具开发
-
定义工具基类BaseTool
-
实现具体工具(WeatherTool、CalculatorTool、WebSearchTool)
-
测试工具功能是否正常
步骤3:智能体核心
-
实现AgentState状态管理
-
实现ToolManager工具管理器
-
实现ReActAgent核心逻辑
步骤4:集成测试
-
创建main.py入口文件
-
注册所有工具到智能体
-
测试不同场景的问题
步骤5:部署上线
-
添加错误处理和日志记录
-
配置环境变量和配置文件
-
部署到服务器或云平台
3.6 常见问题解决方案
问题1:LLM返回格式错误
症状:JSON解析失败,提示格式错误
解决方案:
python
# 在_parse_thought_response方法中添加格式验证
def _parse_thought_response(self, content: str) -> Dict[str, Any]:
try:
data = json.loads(content)
# 验证必需字段
required_fields = ["thought", "action_type"]
for field in required_fields:
if field not in data:
raise ValueError(f"缺少必需字段: {field}")
# 验证action_type
if data["action_type"] not in ["tool_call", "final_answer"]:
raise ValueError(f"无效的action_type: {data['action_type']}")
return data
except json.JSONDecodeError as e:
# 尝试修复格式错误
fixed_content = self._fix_json_format(content)
return json.loads(fixed_content)
except Exception as e:
return {"error": f"解析失败: {str(e)}"}
def _fix_json_format(self, content: str) -> str:
"""尝试修复常见的JSON格式错误"""
# 移除多余的空格和换行
content = content.strip()
# 确保以{开头,以}结尾
if not content.startswith("{"):
content = "{" + content
if not content.endswith("}"):
content = content + "}"
return content问题2:工具调用超时
症状:外部API调用时间过长,影响整体响应
解决方案:
python
import requests
from requests.exceptions import Timeout
class WeatherTool(BaseTool):
def execute(self, input_data: Dict[str, Any]) -> Dict[str, Any]:
try:
response = requests.get(url, params=params, timeout=5) # 设置5秒超时
# ... 处理响应
except Timeout:
return {"error": "请求超时,请稍后重试"}
except Exception as e:
return {"error": f"请求失败: {str(e)}"}问题3:无限循环
症状:智能体陷入死循环,无法生成最终答案
解决方案:
python
# 在run方法中添加最大步数限制
def run(self, question: str) -> AgentState:
state = AgentState(question)
for step in range(self.max_steps):
# ... 执行步骤
# 检查是否应该提前终止
if self._should_terminate_early(state):
break
# 如果达到最大步数仍未完成,生成最终答案
if not state.final_answer and not state.error:
state.set_final_answer(self._generate_timeout_answer(state))
return state
def _should_terminate_early(self, state: AgentState) -> bool:
"""判断是否应该提前终止"""
# 如果连续多次调用相同工具且结果相同,可能陷入循环
if len(state.actions) >= 3:
last_actions = state.actions[-3:]
if all(a["tool_name"] == last_actions[0]["tool_name"] for a in last_actions):
return True
return False四、高级应用:企业级实践与优化
4.1 企业级实践案例
案例1:智能客服系统
业务场景:电商平台客服机器人,需要处理商品咨询、订单查询、售后问题等。
架构设计:
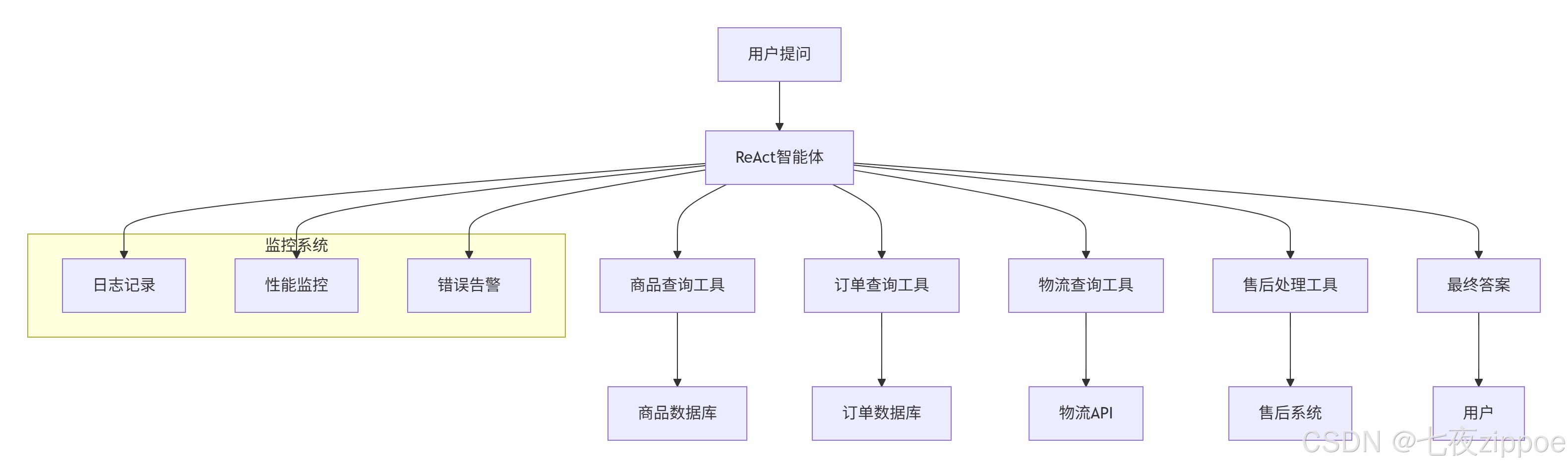
关键技术点:
-
多工具协同:根据问题类型动态选择工具
-
会话上下文:维护多轮对话状态
-
权限控制:订单查询需要用户身份验证
-
数据脱敏:敏感信息(手机号、地址)脱敏处理
案例2:数据分析助手
业务场景:企业内部数据分析平台,业务人员通过自然语言查询数据。
架构设计:
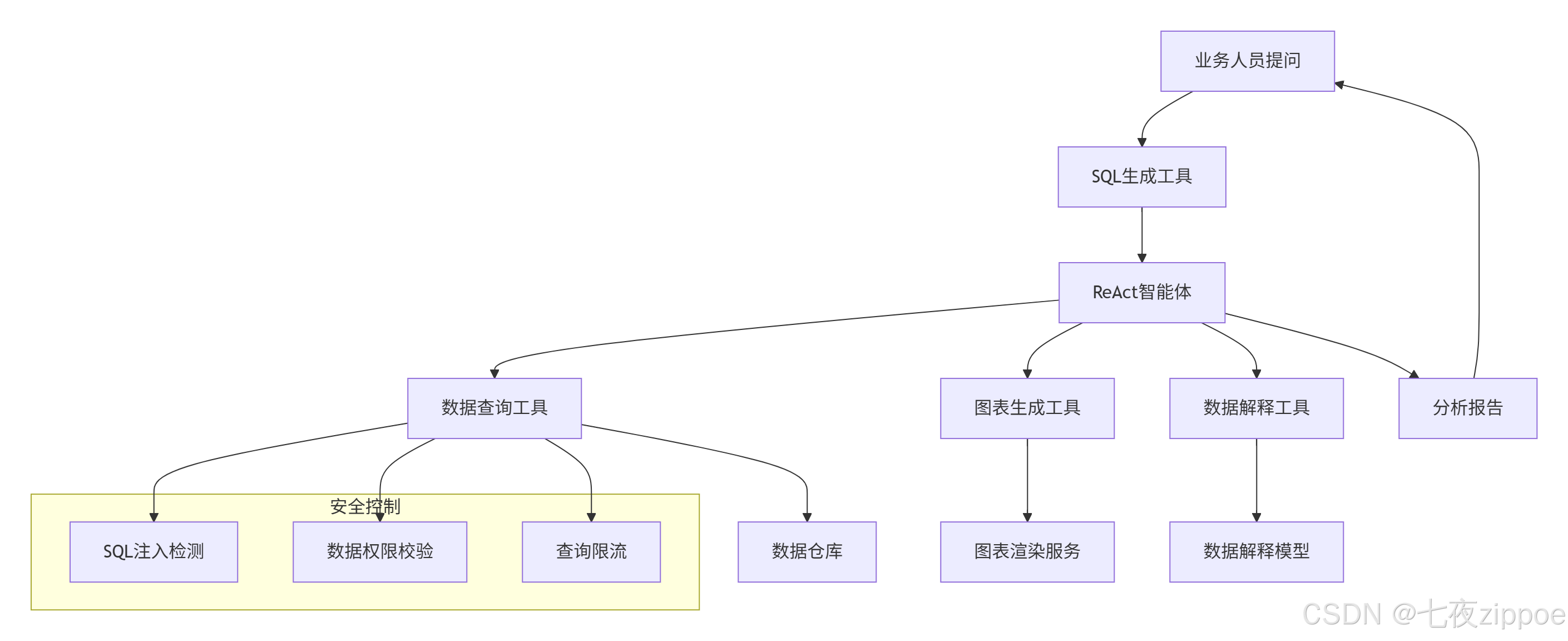
关键技术点:
-
SQL生成安全:防止SQL注入,限制查询范围
-
数据权限:基于用户角色过滤数据
-
查询优化:缓存常用查询结果
-
可视化集成:自动生成图表和报告
4.2 性能优化技巧
4.2.1 工具调用优化
1. 批量工具调用:将多个独立的工具调用合并为批量请求。
python
class BatchToolManager(ToolManager):
def execute_batch(self, tool_requests: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
"""批量执行工具"""
results = []
for request in tool_requests:
tool_name = request["tool_name"]
input_data = request["input_data"]
result = self.execute_tool(tool_name, input_data)
results.append(result)
return results2. 工具结果缓存:对频繁调用的工具结果进行缓存。
python
from functools import lru_cache
import hashlib
class CachedWeatherTool(WeatherTool):
@lru_cache(maxsize=1000)
def execute(self, input_data: Dict[str, Any]) -> Dict[str, Any]:
# 生成缓存键
cache_key = self._generate_cache_key(input_data)
# 检查缓存
cached_result = self.cache.get(cache_key)
if cached_result:
return cached_result
# 执行实际调用
result = super().execute(input_data)
# 缓存结果(有效期5分钟)
self.cache.set(cache_key, result, timeout=300)
return result
def _generate_cache_key(self, input_data: Dict[str, Any]) -> str:
"""生成缓存键"""
data_str = json.dumps(input_data, sort_keys=True)
return hashlib.md5(data_str.encode()).hexdigest()4.2.2 LLM调用优化
1. 提示词压缩:减少不必要的上下文信息,降低token消耗。
python
def compress_history(self, state: AgentState, max_tokens: int = 2000) -> str:
"""压缩历史记录,控制token数量"""
history = []
token_count = 0
# 从最新记录开始添加
for i in range(len(state.thoughts)-1, -1, -1):
thought = state.thoughts[i]
action = state.actions[i] if i < len(state.actions) else None
observation = state.observations[i] if i < len(state.observations) else None
entry = f"步骤 {i+1}:\n思考: {thought}"
if action:
entry += f"\n行动: {json.dumps(action, ensure_ascii=False)}"
if observation:
entry += f"\n观察: {json.dumps(observation, ensure_ascii=False)}"
# 估算token数量
entry_tokens = len(entry) // 4 # 粗略估算
if token_count + entry_tokens > max_tokens:
break
history.insert(0, entry) # 保持时间顺序
token_count += entry_tokens
return "\n\n".join(history)2. 模型选择策略:根据任务复杂度选择合适的模型。
python
def select_model(self, state: AgentState) -> str:
"""根据任务复杂度选择模型"""
step_count = len(state.thoughts)
if step_count == 0:
# 初始步骤,使用大模型
return "gpt-4-turbo"
elif step_count < 3:
# 简单推理,使用中等模型
return "gpt-3.5-turbo"
else:
# 复杂推理,使用大模型
return "gpt-4-turbo"4.2.3 并发处理优化
1. 异步执行:使用异步IO提升并发性能。
python
import asyncio
from typing import List
class AsyncReActAgent(ReActAgent):
async def run_async(self, question: str) -> AgentState:
"""异步执行ReAct循环"""
state = AgentState(question)
for step in range(self.max_steps):
# 异步生成思考
thought_response = await self._generate_thought_async(state)
# ... 其他逻辑
return state
async def _generate_thought_async(self, state: AgentState) -> Dict[str, Any]:
"""异步生成思考"""
prompt = self._build_user_prompt(state)
try:
response = await self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system", "content": self.system_prompt},
{"role": "user", "content": prompt}
],
temperature=0.1,
max_tokens=1000,
response_format={"type": "json_object"}
)
content = response.choices[0].message.content
return json.loads(content)
except Exception as e:
return {"error": f"思考生成失败: {str(e)}"}2. 批量处理:同时处理多个用户请求。
python
async def batch_process(self, questions: List[str]) -> List[AgentState]:
"""批量处理多个问题"""
tasks = [self.run_async(question) for question in questions]
results = await asyncio.gather(*tasks, return_exceptions=True)
# 处理异常结果
states = []
for result in results:
if isinstance(result, Exception):
state = AgentState("")
state.set_error(str(result))
states.append(state)
else:
states.append(result)
return states4.3 故障排查指南
4.3.1 常见故障场景
场景1:LLM调用失败
症状:OpenAI API返回错误,如超时、配额不足、模型不可用等。
排查步骤:
-
检查API密钥是否正确配置
-
检查网络连接是否正常
-
查看OpenAI控制台,确认配额和账单状态
-
添加重试机制和降级策略
场景2:工具执行异常
症状:外部API调用失败,返回错误信息。
排查步骤:
-
检查工具配置参数是否正确
-
验证外部服务是否可用
-
检查网络防火墙和代理设置
-
添加超时和重试机制
场景3:无限循环
症状:智能体不断调用相同工具,无法终止。
排查步骤:
-
检查工具返回结果是否符合预期
-
添加最大步数限制
-
实现循环检测和提前终止
-
记录完整执行历史,便于调试
4.3.2 监控与告警
关键监控指标:
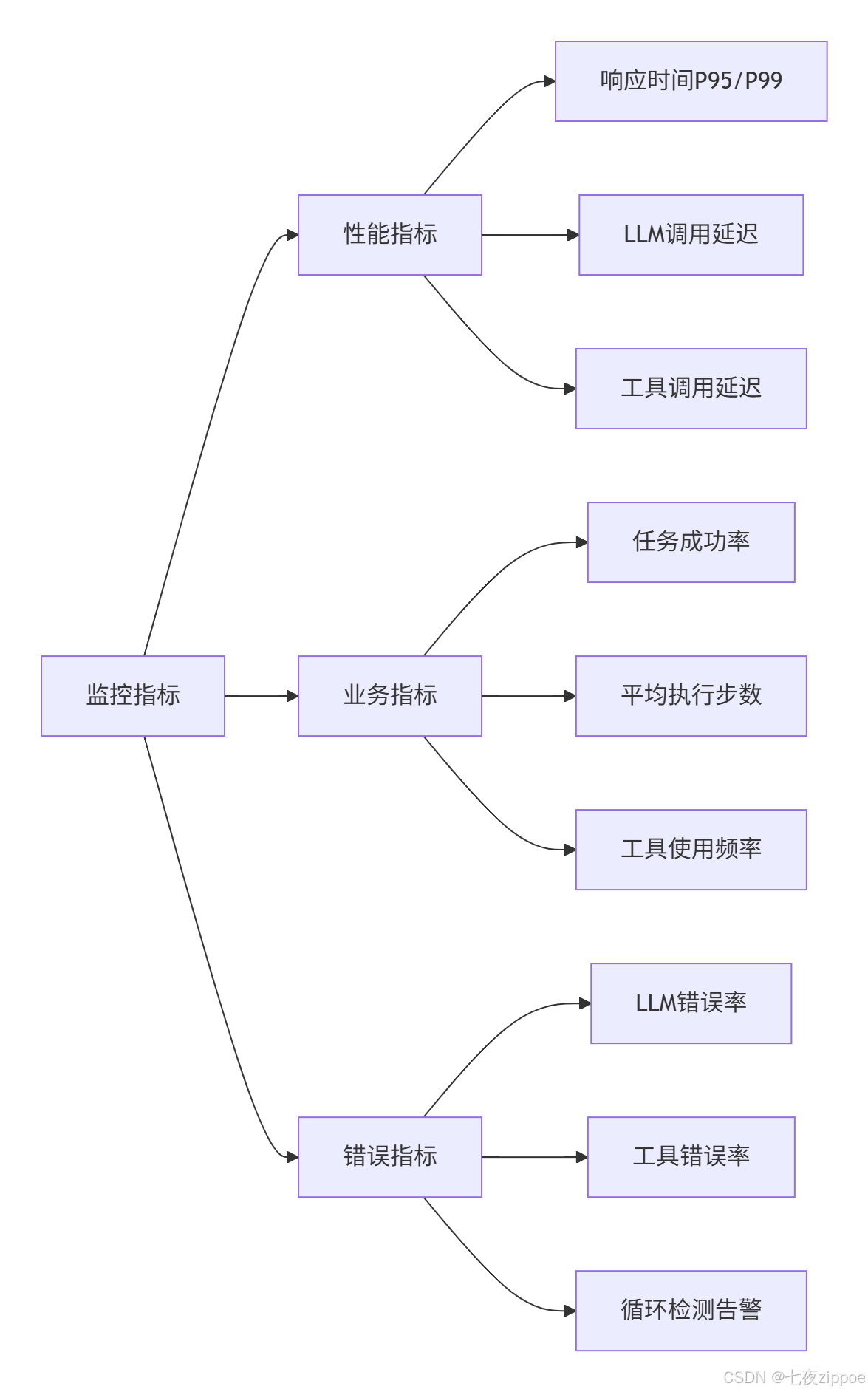
告警配置:
-
响应时间告警:P95响应时间超过1秒
-
错误率告警:错误率超过5%
-
循环告警:连续5次调用相同工具
-
配额告警:API配额使用超过80%
4.3.3 日志与调试
结构化日志记录:
python
import logging
import json
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger("react_agent")
class LoggingAgent(ReActAgent):
def run(self, question: str) -> AgentState:
logger.info(f"开始处理问题: {question}")
state = super().run(question)
# 记录执行结果
log_data = {
"question": question,
"steps": len(state.thoughts),
"execution_time": state.get_execution_time(),
"success": state.final_answer is not None,
"error": state.error
}
logger.info(f"执行完成: {json.dumps(log_data)}")
return state调试工具:提供可视化调试界面,展示完整的思维链和执行轨迹。
五、总结与展望
5.1 技术选型建议
推荐方案:
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 快速原型 | LangChain + ReAct | 开箱即用,快速验证 |
| 生产环境 | 自定义ReAct框架 | 完全控制,深度定制 |
| 大规模部署 | 分布式ReAct + 缓存 | 高并发,低延迟 |
| 复杂任务 | 多智能体协作 | 任务分解,并行执行 |
5.2 未来发展趋势
-
多模态智能体:支持图像、音频、视频等多模态输入和输出
-
长期记忆:实现跨会话的记忆保持和知识积累
-
自我改进:通过强化学习自动优化工具使用策略
-
边缘部署:在边缘设备上运行轻量级智能体
-
安全增强:更强的安全控制和隐私保护机制
5.3 关键成功因素
构建成功的ReAct智能体系统需要关注:
-
工具质量:高质量的工具是智能体成功的基础
-
提示工程:精心设计的提示词显著提升效果
-
错误处理:完善的错误恢复机制保证系统稳定
-
可观测性:完整的监控和日志便于调试和优化
-
持续迭代:根据用户反馈持续改进工具和策略
官方文档与权威参考
-
ReAct论文- 原始论文,深入理解框架原理
-
LangChain ReAct文档- 官方实现参考
-
OpenAI Function Calling- 工具调用最佳实践
-
AgentBench- 智能体性能评测基准
-
Hugging Face Agents- 开源智能体实现