Bert常见的变体
- ALBERT (A Litter version of BERT)
- RoBERTa (Robustly Optimized BERT Approach)
-
- [BPE(byte pair encoding)](#BPE(byte pair encoding))
- ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately)
- SpanBERT
- 核心升级模块对比
ALBERT (A Litter version of BERT)
ALBERT通过两种改进降低参数量:
- 嵌入分解 :将词嵌入矩阵( V ∗ H V*H V∗H, V V V为词向量大小, H H H为隐藏层大小)分解为更小的矩阵( V ∗ E + E ∗ H , E V * E+E*H,E V∗E+E∗H,E为低纬度的向量),降低输入层的参数量。
- 交叉层参数共享 :Transformer层共享权重,减少模型体积。 (原BERT-base所有12层编码器参数通过训练获得,参数量巨大)
- 全共享(默认):其他编码器所有子层共享第一层编码器的所有参数
- 共享前馈网络层FFN:只将第一层编码器的前馈网络层参数与其他编码器前馈网络层共享
- 共享注意力层:只将第一层编码器的多头注意力层参数与其他编码器多头注意力层共享
- 句子顺序预测(SOP):替换BERT的NSP任务,通过判断句子顺序是否颠倒提升语义理解能力。
- 原因:BERT原有的NSP任务相对于MLM任务太简单了,学习到的东西也有限
- 作用:通过关注句子顺序来关注于句子间的连贯性,而非句子间的上下文匹配性
- 样本生产原理:正样本由原始语料中获得连续两个句子,负样本是连续句子交换顺序(举例:原始语料句子 A和B, NSP任务正样本是 AB,负样本是AC;SOP任务正样本是AB,负样本是BA。SOP任务更加难,学习到的东西更多)
RoBERTa (Robustly Optimized BERT Approach)
RoBERTa的改进聚焦于训练策略优化:
- 动态掩码:每次输入序列时重新生成掩码模式,增强泛化性。
- 核心思想:对原始BERT静态掩码的改进,在每个训练epoch中为输入序列重新生成掩码模式,而非预先生成固定的掩码。
- 数据预处理:原始BERT在数据预处理时对每个样本生成固定的掩码位置,导致同一样本在不同epoch中掩码位置不变。RoBERTa取消了这一设计,改为在训练时实时生成掩码。
- 具体步骤包括:
- 对输入序列的每个Token,以固定概率(如15%)决定是否掩码。
- 被选中的Token按80%概率替换为MASK,10%概率替换为随机Token,10%概率保持原Token不变。
- 每个epoch重复上述过程,同一文本在不同epoch中掩码位置不同。
- 优点:
- 提升数据利用率:同一文本在不同训练阶段暴露不同掩码模式,迫使模型学习更全面的上下文表示,而非记忆固定掩码模式。
- 避免过拟合风险:静态掩码可能导致模型对特定掩码位置产生依赖,动态掩码通过随机性缓解这一问题。
- 更大批次与数据:使用更大规模的训练数据和批次(如160GB文本)。
大批量的作用:可提高MLM建模目标的复杂性以及最终任务的准确性。
- 移除NSP任务:仅使用MLM任务,避免NSP任务的负面影响。
- 字节级BPE作为子词词元化算法 :相比于char的BPE可以编码任何输入文本而不会引入 UNKOWN 标记
BPE(byte pair encoding)
BPE为数据压缩算法,用于子词切分任务
- 核心思想 :通过迭代合并高频出现的字节对(或字符对)来构建词汇表,从而有效处理未登录词和稀有词。
- 核心步骤 :
- 初始化词汇表:将每个单词拆分为字符级别,并为每个字符分配一个频率统计
- 迭代合并高频字节对:每次迭代中,统计所有相邻字节对的出现频率,将出现频率最高的字节对合并为一个新的符号
- 终止条件:重复合并过程,直到达到预设的词汇表大小或无法继续合并
- 优点 :
- 处理未登录词:通过子词组合,BPE能够拆分未见过的单词,例如"unhappiness"可能被拆分为un, happy, ness,即使"unhappiness"未出现在训练语料中。
- 平衡词汇表大小与覆盖率:通过调整合并次数或词汇表大小,可以控制模型的复杂度和泛化能力。较小的词汇表可能覆盖更多稀有词,但会增加序列长度。
- 多语言适应性:不依赖语言特定的分词规则
- 缺点 :
- 无法完全避免歧义,某些合并可能导致歧义切分,例如"player"可能被错误拆分为play, er(实际应为play, er或pla, yer)。
- 依赖训练语料:合并结果受语料中词频分布影响,低频领域术语可能被过度拆分。
python
######## BPE 实现代码
import re
from collections import defaultdict
## 相邻字符的出现频率
def get_stats(vocab):
pairs = defaultdict(int)
for word, freq in vocab.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i], symbols[i+1]] += freq
return pairs
def merge_vocab(pair, vocab_in):
vocab_out = {}
bigram = re.escape(' '.join(pair)) ## 合并频次最高的字符对为bigram
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in vocab_in:
w_out = p.sub(''.join(pair), word) ## 将word中的bigram替换为合并后的pair对,有则替换,无则不变
vocab_out[w_out] = vocab_in[word] ## 更新vocab_in为合并后的vocan_out
return vocab_out
def bpe_learn(vocab, num_merges):
merges = {}
for i in range(num_merges):
pairs = get_stats(vocab)
if not pairs:
break
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
# print(vocab)
merges[best] = i
return merges, vocab
# 示例用法
initial_vocab = {
'l o w </w>': 5,
'l o w e r </w>': 2,
'n e w e s t </w>': 6,
'w i d e s t </w>': 3
}
merges, final_vocab = bpe_learn(initial_vocab, 10)
print("Merges:", merges)
print("Final vocab:", final_vocab)ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately)
ELECTRA引入生成器-判别器架构,并使用替换标记检测任务进行预训练
- 替换标记检测任务(RTD) :生成器(小型MLM模型)替换部分输入掩码,然后判别器判断每个掩码是否被替换。
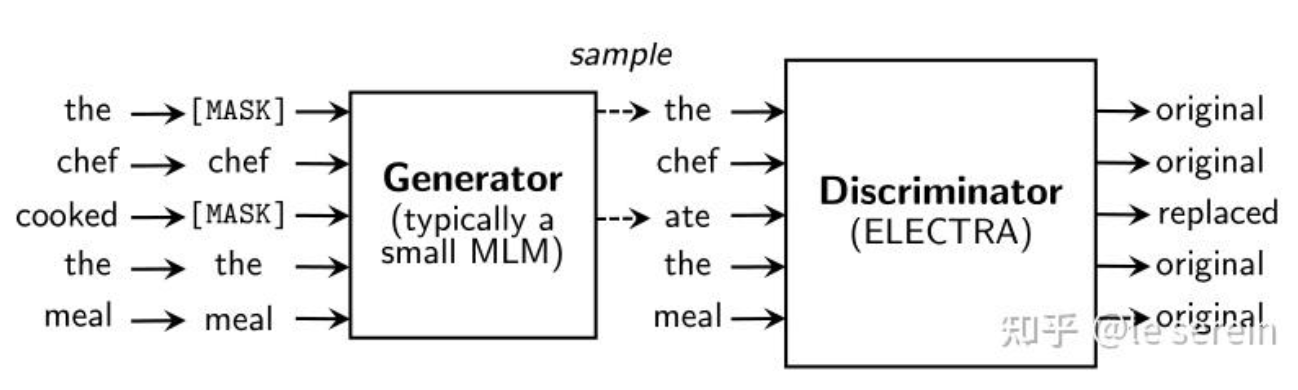
- 为什么这样做?原因:
- 部分神经元失活:BERT预训练时由于只预测15% masked-token,意味着模型更新时只会更新对应masked词连接的神经元,相当于有相当部分神经元产生"失活"现象,所以收敛慢,效果也受影响
- 曝光偏差:BERT在预训练和微调时输入存在一定的不一致,预训练时输入的token某些是被masked的,而在微调时不存在mask标记,存在曝光偏差
- 损失函数:由MLM(多元交叉熵损失)和判别任务(二元交叉熵损失)组成:
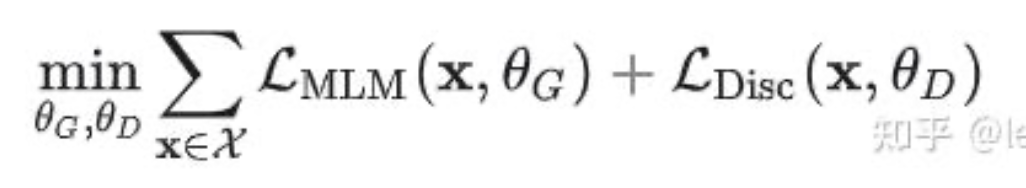

- 全 token 训练:相比BERT仅训练被掩码的15%令牌,ELECTRA对所有令牌进行判别,提升数据效率。
SpanBERT
SpanBERT针对文本跨度任务(例如问答任务、关系提取任务)优化:
- 跨度掩码(Span Masking):随机掩码连续的多个词(如完整短语),而非单个token。
每一次迭代中,首先从一个几何分布中采样出一个span长度,之后以均匀分布的形式采样出一个起始点
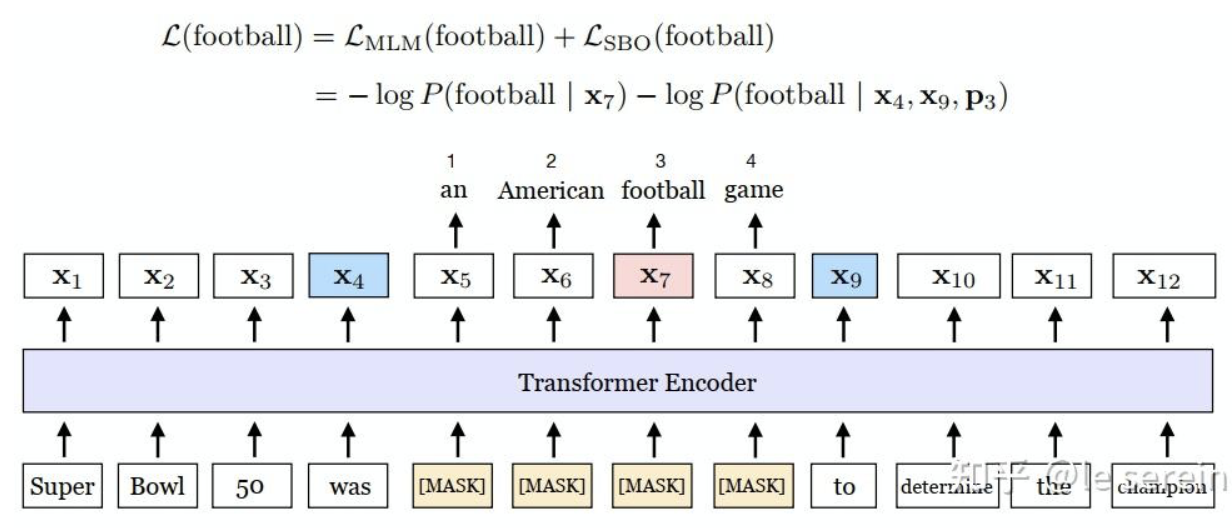
- 区间边界目标(Span Boundary Objective , SBO):预测被掩码跨度的起始和结束位置,强化跨度感知能力。
核心思想:用边界tokens来构建关于span的定长表示,因而span两端的tokens的表征需要尽可能包含span内容的语义。
具体实现:每个span设定起始标记,用起始标记处的特征来预测span内部的所有token;为区分span中不同token,引入位置嵌入,表示tokens的相对位置
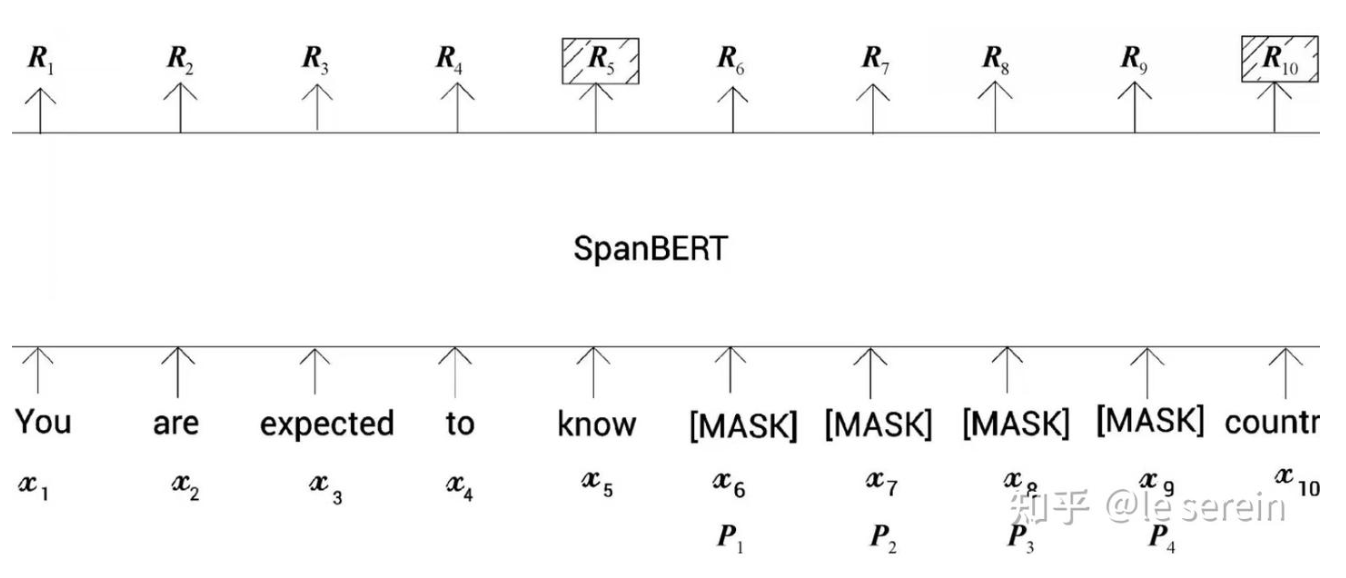
- 移除NSP任务:专注于单文档训练,适合问答或指代消解任务。
损失函数定义: P 3 : 表示 s p a n 中的第 3 个位置 P3:表示span中的第3个位置 P3:表示span中的第3个位置
核心升级模块对比
| 变体 | 关键改进 | 适用场景 |
|---|---|---|
| ALBERT | 参数共享/嵌入分解/SOP | 资源受限的轻量级场景 |
| RoBERTa | 动态掩码/大数据训练/移除NSP | 通用语言理解任务 |
| ELECTRA | RTD任务/全token训练 | 高效预训练与判别任务 |
| SpanBERT | 跨度掩码/边界目标 | 跨度提取类任务(如QA) |
这些变体通过调整架构设计、训练任务或数据策略,在BERT基础上提升了效率、性能或任务适配性。
ref:BERT常见变体:基于改进模型结构与任务(如有侵权联系必删)