RAG检索增强应用中,往往需要使用多路召回文档,传统的词向量语义相似和关键词检索是常用的组合,spring-ai默认实现了语义相似的召回,postgresql中可直接创建向量插件,但RAG关键词检索我们自己实现时可能需要补充基于分词的召回方案,意味着需要额外安装分词插件。除部分云数据库外,自部署pgsql往往不能直接create extension创建分词插件。本文介绍两种常用的分词插件的编译安装方式。
推荐首选jieba分词,针对新词感知和领域分词更加准确。
注:下文分词部署都是基于centos系列的系统(作为数据基础设施不推荐docker部署),使用linux安装源安装好pgsql后,编译部署流程如下。
公共依赖
安装好pgsql后,执行源码编译依赖安装
sudo yum install boost-devel结巴分词部署方案
由于云服务器一般有github访问限制,所以使用支持访问的代码库,部署方案参考:https://www.modb.pro/db/616771
创建目录和源码下载,生成build文件
mkdir /opt/wwwroot/pgsql/jieba
cd /opt/wwwroot/pgsql/jieba
git clone https://gitee.com/shawnyan/pg_jieba --depth=1
git clone https://gitee.com/shawnyan/cppjieba --depth=1 pg_jieba/libjieba
git clone https://gitee.com/shawnyan/limonp --depth=1 pg_jieba/libjieba/deps/limonp
cd pg_jieba
mkdir build
cd build查找pgsql中的extension 和 tsearch_data 路径
基于centos的路径一般默认为 /usr/share/pgsql/
查找pgsql的log和postgresql.conf目录
基于centos的路径一般默认为 /var/lib/pgsql/data
查找pgsql的lib,即so文件防止位置目录
#通过指令查询
pg_config --pkglibdir
#得到如下路径
/usr/lib64/pgsql确定lib路径后生成编译引导,注意使用cmake3指令,需检查安装支持
#执行生成器
cmake3 -DCMAKE_PREFIX_PATH=/usr/lib64/pgsql/ ..
#执行编译运行
make忽略warning级别提示,如无报错,即完成编译,可以将程序和配置拷贝到pgsql指定目录中
# 拷贝程序库文件
cp /opt/wwwroot/pgsql/jieba/pg_jieba/build/pg_jieba.so /usr/lib64/pgsql拷贝词典配置
cp /opt/wwwroot/pgsql/jieba/pg_jieba/libjieba/dict/jieba.dict.utf8 /usr/share/pgsql/tsearch_data/jieba_base.dict
cp /opt/wwwroot/pgsql/jieba/pg_jieba/libjieba/dict/user.dict.utf8 /usr/share/pgsql/tsearch_data/jieba_user.dict
cp /opt/wwwroot/pgsql/jieba/pg_jieba/libjieba/dict/hmm_model.utf8 /usr/share/pgsql/tsearch_data/jieba_hmm.model
cp /opt/wwwroot/pgsql/jieba/pg_jieba/libjieba/dict/stop_words.utf8 /usr/share/pgsql/tsearch_data/jieba.stop
cp /opt/wwwroot/pgsql/jieba/pg_jieba/pg_jieba.control /usr/share/pgsql/extension/pg_jieba.control
cp /opt/wwwroot/pgsql/jieba/pg_jieba/pg_jieba.sql /usr/share/pgsql/extension/pg_jieba--1.1.1.sql进入pgsql程序conf目录 添加配置
cd /var/lib/pgsql/data
vim postgresql.conf
shared_preload_libraries = 'pg_jieba'重启pgsql
systemctl restart postgresqlsql终端测试
DROP EXTENSION IF EXISTS pg_jieba CASCADE;
create extension pg_jieba;
-- 查看是否存在jieba分词配置
select * from pg_ts_parser;
SELECT * from pg_ts_config;
-- 重新载入词典或分词配置
SELECT jieba_reload_dict();
SELECT pg_reload_conf();
-- 验证分词
select * from to_tsvector('jiebacfg', '这里是测试分词');
SELECT * FROM ts_debug('jiebacfg', '这里是测试分词');
-- 如报错,可定位log查看日志,日志调为debug模式
ALTER SYSTEM SET log_min_messages = 'DEBUG1';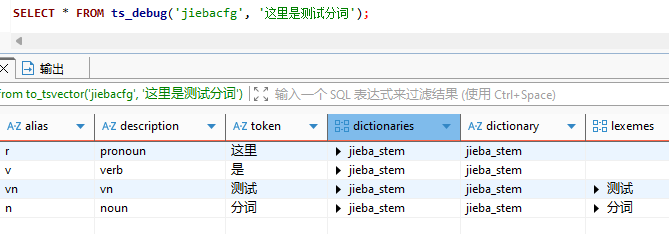
zhparser分词部署方案
创建目录和源码下载,云环境可使用镜像地址或本地上传文件后编译,完成指令流程如下
# 编译源码下载
cd /opt/wwwroot/pgsql
git clone https://github.com/amutu/zhparser.git
cd zhparser
# 其他依赖scws安装
mkdir scws
cd scws
wget http://www.xunsearch.com/scws/down/scws-1.2.3.tar.bz2
# 如不支持bz2的解压,需下载bzip2解压工具
sudo yum install -y bzip2
# 解压scws
tar xvjf scws-1.2.3.tar.bz2
cd scws-1.2.3
./configure
# 校验编译安装
## 编译安装scws
make
## 校验程序库文件
ls /usr/local/lib/libscws.so
## 检查scws是否可自行 提示参数报错正常
/usr/local/bin/scws -h编译zhparser
# 返回上层开始编译zhparser
cd ..
-- 编译,如果提示报错需要查看文件编码 cat -A Makefile
SCWS_HOME=/usr/local make && sudo make install
-- 自动加载配置
ldconfigsql终端测试
CREATE EXTENSION zhparser;
SELECT * FROM ts_parse('zhparser', 'hello world! 这里是测试分词');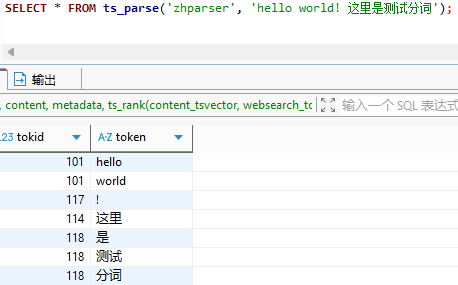
后续将介绍如何实现spring-ai中RAG的 本地文档+pgsql-bm25关键词检索+语义相似度向量检索+云文档的多路召回的实现方案。