目录
1.网页前端部分
这一部分的目的是为了测试我们的http服务器是否能跑通而做的简单页面。
其结构如下:
wwwroot文件夹里面有我们的图片,404页面,内容页面,首页,登入,注册,由于我们的目的是了解http服务器,所以前端的页面部分我就不做过多讲解。因为这些页面的实现我也是从网络上摘取下来的,没有讲解的意义。重点还是在服务器。
2.服务器后端部分
我们还是先把我们的老朋友给请出来:
封装网络地址类
cpp#pragma once #include <iostream> #include <string> #include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> // 封装网络地址类 class InetAddr { private: void ToHost(const struct sockaddr_in &addr) { _port = ntohs(addr.sin_port); //_ip = inet_ntoa(addr.sin_addr); char ip_buf[32]; ::inet_ntop(AF_INET, &addr.sin_addr, ip_buf, sizeof(ip_buf)); _ip = ip_buf; } public: InetAddr(const struct sockaddr_in &addr) : _addr(addr) { ToHost(addr); // 将addr进行转换 } std::string AddrStr() { return _ip + ":" + std::to_string(_port); } InetAddr() { } bool operator==(const InetAddr &addr) { return (this->_ip == addr._ip && this->_port == addr._port); } std::string Ip() { return _ip; } uint16_t Port() { return _port; } struct sockaddr_in Addr() { return _addr; } ~InetAddr() { } private: std::string _ip; uint16_t _port; struct sockaddr_in _addr; };封装锁类
cpp#pragma once #include <pthread.h> class LockGuard { public: LockGuard(pthread_mutex_t *mutex) : _mutex(mutex) { pthread_mutex_lock(_mutex); } ~LockGuard() { pthread_mutex_unlock(_mutex); } private: pthread_mutex_t *_mutex; };日志类
cpp#pragma once #include <iostream> #include <string> #include <unistd.h> #include <sys/types.h> #include <ctime> #include <stdarg.h> #include <fstream> #include <string.h> #include <pthread.h> namespace log_ns { enum { DEBUG = 1, INFO, WARNING, ERROR, FATAL }; std::string LevelToString(int level) { switch (level) { case DEBUG: return "DEBUG"; case INFO: return "INFO"; case WARNING: return "WARNING"; case ERROR: return "ERROR"; case FATAL: return "FATAL"; default: return "UNKNOW"; } } std::string GetCurrTime() { time_t now = time(nullptr); struct tm *curr_time = localtime(&now); char buffer[128]; snprintf(buffer, sizeof(buffer), "%d-%02d-%02d %02d:%02d:%02d", curr_time->tm_year + 1900, curr_time->tm_mon + 1, curr_time->tm_mday, curr_time->tm_hour, curr_time->tm_min, curr_time->tm_sec); return buffer; } class logmessage { public: std::string _level; pid_t _id; std::string _filename; int _filenumber; std::string _curr_time; std::string _message_info; }; #define SCREEN_TYPE 1 #define FILE_TYPE 2 const std::string glogfile = "./log.txt"; pthread_mutex_t glock = PTHREAD_MUTEX_INITIALIZER; class Log { public: Log(const std::string &logfile = glogfile) : _logfile(logfile), _type(SCREEN_TYPE) { } void Enable(int type) { _type = type; } void FlushLogToScreen(const logmessage &lg) { printf("[%s][%d][%s][%d][%s] %s", lg._level.c_str(), lg._id, lg._filename.c_str(), lg._filenumber, lg._curr_time.c_str(), lg._message_info.c_str()); } void FlushLogToFile(const logmessage &lg) { std::ofstream out(_logfile, std::ios::app); if (!out.is_open()) return; char logtxt[2048]; snprintf(logtxt, sizeof(logtxt), "[%s][%d][%s][%d][%s] %s", lg._level.c_str(), lg._id, lg._filename.c_str(), lg._filenumber, lg._curr_time.c_str(), lg._message_info.c_str()); out.write(logtxt, strlen(logtxt)); out.close(); } void FlushLog(const logmessage &lg) { pthread_mutex_lock(&glock); switch (_type) { case SCREEN_TYPE: FlushLogToScreen(lg); break; case FILE_TYPE: FlushLogToFile(lg); break; } pthread_mutex_unlock(&glock); } void logMessage(std::string filename, int filenumber, int level, const char *format, ...) { logmessage lg; lg._level = LevelToString(level); lg._id = getpid(); lg._filename = filename; lg._filenumber = filenumber; lg._curr_time = GetCurrTime(); va_list ap; va_start(ap, format); char log_info[1024]; vsnprintf(log_info, sizeof(log_info), format, ap); va_end(ap); lg._message_info = log_info; // 打印出日志 FlushLog(lg); } ~Log() { } private: int _type; std::string _logfile; }; Log lg; #define LOG(level, Format, ...) do {lg.logMessage(__FILE__, __LINE__, level, Format, ##__VA_ARGS__); }while (0) #define EnableScreen() do {lg.Enable(SCREEN_TYPE);}while(0) #define EnableFile() do {lg.Enable(FILE_TYPE);}while(0) }socket套接字封装类
cpp#pragma once #include <iostream> #include <cstring> #include <functional> #include <unistd.h> #include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <sys/wait.h> #include <pthread.h> #include <memory> #include "Log.hpp" #include "InetAddr.hpp" namespace socket_ns { using namespace log_ns; class Socket; using SockSPtr = std::shared_ptr<Socket>; enum { SOCKET_ERROR = 1, BIND_ERROR, LISTEN_ERROR }; const static int gbacklog = 8; // 模板方法模式 class Socket { public: virtual void CreateSocketOrDie() = 0; virtual void CreateBindOrDie(uint16_t port) = 0; virtual void CreateListenOrDie(int backlog = gbacklog) = 0; virtual SockSPtr Accepter(InetAddr *cliaddr) = 0; virtual bool Conntecor(const std::string &peerip, uint16_t peerport) = 0; virtual int Sockfd() = 0; virtual void Close() = 0; virtual ssize_t Recv(std::string *out) = 0; virtual ssize_t Send(const std::string &in) = 0; public: void BuildListenSocket(uint16_t port) { CreateSocketOrDie(); CreateBindOrDie(port); CreateListenOrDie(); } bool BuildClientSocket(const std::string &peerip, uint16_t peerport) { CreateSocketOrDie(); return Conntecor(peerip, peerport); } }; class TcpSocket : public Socket { public: TcpSocket() { } TcpSocket(int sockfd) : _sockfd(sockfd) { } ~TcpSocket() { } void CreateSocketOrDie() override { // 1.创建socket _sockfd = ::socket(AF_INET, SOCK_STREAM, 0); if (_sockfd < 0) { LOG(FATAL, "sockfd create error\n"); exit(SOCKET_ERROR); } LOG(INFO, "listensockfd create success, fd: %d\n", _sockfd); } void CreateBindOrDie(uint16_t port) override { struct sockaddr_in local; memset(&local, 0, sizeof(local)); local.sin_family = AF_INET; local.sin_port = htons(port); local.sin_addr.s_addr = INADDR_ANY; // 2.bind _listensockfd 和 Socket addr if (::bind(_sockfd, (struct sockaddr *)&local, sizeof(local)) < 0) { LOG(FATAL, "bind error\n"); exit(BIND_ERROR); } LOG(INFO, "bind success, sockfd: %d\n", _sockfd); } void CreateListenOrDie(int backlog) override { // 3.因为tcp是面向连接的,tcp需要未来不断地能够做到获取连接 if (::listen(_sockfd, gbacklog) < 0) { LOG(FATAL, "listen error\n"); exit(LISTEN_ERROR); } LOG(INFO, "listen success\n"); } SockSPtr Accepter(InetAddr *cliaddr) override { struct sockaddr_in client; socklen_t len = sizeof(client); // 4. 获取连接 int sockfd = ::accept(_sockfd, (struct sockaddr *)&client, &len); if (sockfd < 0) { LOG(WARNING, "accept error\n"); return nullptr; } *cliaddr = InetAddr(client); LOG(INFO, "get a new link, client info: %s, sockfd is : %d\n", cliaddr->AddrStr().c_str(), sockfd); return std::make_shared<TcpSocket>(sockfd); // C++14 } bool Conntecor(const std::string &peerip, uint16_t peerport) override { struct sockaddr_in server; memset(&server, 0, sizeof(server)); server.sin_family = AF_INET; server.sin_port = htons(peerport); ::inet_pton(AF_INET, peerip.c_str(), &server.sin_addr); int n = ::connect(_sockfd, (struct sockaddr *)&server, sizeof(server)); if (n < 0) { return false; } return true; } int Sockfd() { return _sockfd; } void Close() { if (_sockfd > 0) { ::close(_sockfd); } } ssize_t Recv(std::string *out) override { char inbuffer[4096]; ssize_t n = ::recv(_sockfd, inbuffer, sizeof(inbuffer) - 1, 0); if (n > 0) { inbuffer[n] = 0; *out += inbuffer; } return n; } ssize_t Send(const std::string &in) override { return ::send(_sockfd, in.c_str(), in.size(), 0); } private: int _sockfd; // 可以是listensock, 也可以是普通socketfd }; }这个我在网络版本计算器这篇文章中已经讲得很清楚了,这里我就不缀叙了。
TcpServer类
cpp#pragma once #include <functional> #include "Socket.hpp" #include "Log.hpp" #include "InetAddr.hpp" using namespace socket_ns; static const int gport = 8888; using service_io_t = std::function<std::string(std::string &requeststr)>; class TcpServer { public: TcpServer(service_io_t service, uint16_t port = gport) : _port(port), _listensock(std::make_shared<TcpSocket>()), _isrunning(false), _service(service) { _listensock->BuildListenSocket(_port); } class ThreadData { public: SockSPtr _sockfd; TcpServer *_self; InetAddr _addr; public: ThreadData(SockSPtr sockfd, TcpServer *self, const InetAddr &addr) : _sockfd(sockfd), _self(self), _addr(addr) { } }; void Loop() { _isrunning = true; while (_isrunning) { InetAddr client; SockSPtr newsock = _listensock->Accepter(&client); if (newsock == nullptr) continue; LOG(INFO, "get a new link, client info : %s, sockfd is : %d\n", client.AddrStr().c_str(), newsock->Sockfd()); // version 2 --- 多线程版本 --- 不能关闭fd了,也不需要了 pthread_t tid; ThreadData *td = new ThreadData(newsock, this, client); pthread_create(&tid, nullptr, Execute, td); // 新线程进行分离 } _isrunning = false; } static void *Execute(void *args) { pthread_detach(pthread_self()); ThreadData *td = static_cast<ThreadData *>(args); std::string requeststr; ssize_t n = td->_sockfd->Recv(&requeststr); if (n > 0) { std::string responsestr = td->_self->_service(requeststr); td->_sockfd->Send(responsestr); } td->_sockfd->Close(); delete td; return nullptr; } ~TcpServer() { } private: uint16_t _port; SockSPtr _listensock; bool _isrunning; service_io_t _service; };这个我也是在网络版本计算器这篇文章中已经讲得很清楚了,我们这里都是复用,这就是范式编程的好处。以及我们之前的各种封装本质上都是一劳永逸的做法。
接下来的就是我们本次的重点了。
Http服务器类
cpp#pragma once #include <iostream> #include <string> #include <vector> #include <sstream> #include <functional> #include <fstream> #include <unordered_map> const static std::string base_sep = "\r\n"; const static std::string line_sep = ": "; const static std::string prefixpath = "wwwroot"; // web根目录 const static std::string homepage = "index.html"; const static std::string httpversion = "HTTP/1.0"; const static std::string spacesep = " "; const static std::string suffixsep = "."; const static std::string html_404 = "404.html"; const static std::string arg_sep = "?"; class HttpRequest { private: //\r\n //\r\ndata std::string GetLine(std::string &reqstr) { auto pos = reqstr.find(base_sep); if (pos == std::string::npos) return std::string(); std::string line = reqstr.substr(0, pos); reqstr.erase(0, line.size() + base_sep.size()); return line.empty() ? base_sep : line; } void ParseReqLine() { std::stringstream ss(_req_line); // cin>> ss >> _method >> _url >> _version; if (strcasecmp(_method.c_str(), "GET") == 0) { auto pos = _url.find(arg_sep); if (pos != std::string::npos) { _body_text = _url.substr(pos + arg_sep.size()); _url.resize(pos); } } _path += _url; if (_path[_path.size() - 1] == '/') { _path += homepage; // 如果用户没有指定资源路径名,那么我们就自动将首页信息返回 } // wwwroot/index.html // wwwroot/image/1.png auto pos = _path.rfind(suffixsep); if (pos != std::string::npos) { _suffix = _path.substr(pos); } else { _suffix = " .default"; } } void ParseReqHeader() { for (auto &header : _req_headers) { auto pos = header.find(line_sep); if (pos == std::string::npos) continue; std::string k = header.substr(0, pos); std::string v = header.substr(pos + line_sep.size()); if (k.empty() || v.empty()) continue; _headers_kv.insert(std::make_pair(k, v)); } } public: HttpRequest() : _blank_line(base_sep), _path(prefixpath) { } void Deserialize(std::string &reqstr) { // 基本的反序列化 _req_line = GetLine(reqstr); std::string header; do { header = GetLine(reqstr); if (header.empty()) break; else if (header == base_sep) break; _req_headers.push_back(header); } while (true); if (!reqstr.empty()) { _body_text = reqstr; } // 在进一步反序列化 ParseReqLine(); ParseReqHeader(); } std::string Url() { LOG(DEBUG, "Client Want url %s\n", _url.c_str()); return _url; } std::string Path() { LOG(DEBUG, "Client Want path %s\n", _path.c_str()); return _path; } std::string Suffix() { return _suffix; } std::string Method() { LOG(DEBUG, "Client request method is %s\n", _method.c_str()); return _method; } std::string GetRequestBody() { LOG(DEBUG, "Client request method is %s, args: %s, request path: %s\n", _method.c_str(), _body_text.c_str(), _path.c_str()); return _body_text; } void Print() { std::cout << "------------------" << std::endl; std::cout << "###" << _req_line << std::endl; for (auto &header : _req_headers) { std::cout << "@@@" << header << std::endl; } std::cout << "***" << _blank_line; std::cout << ">>>" << _body_text << std::endl; std::cout << "Method: " << _method << std::endl; std::cout << "Url: " << _url << std::endl; std::cout << "Version: " << _version << std::endl; for (auto &headers_kv : _headers_kv) { std::cout << ")))" << headers_kv.first << "->" << headers_kv.second << std::endl; } } ~HttpRequest() { } private: // 基本的httprequest的格式 std::string _req_line; std::vector<std::string> _req_headers; std::string _blank_line; std::string _body_text; // 更具体的属性字段,需要进一步反序列化 std::string _method; std::string _url; std::string _path; std::string _suffix; // 资源后缀 std::string _version; std::unordered_map<std::string, std::string> _headers_kv; }; class HttpResponse { public: HttpResponse() : _version(httpversion), _blank_line(base_sep) { } void AddCode(int code, const std::string &desc) { _status_code = code; _desc = desc; } void AddHeader(const std::string &k, const std::string &v) { _headers_kv[k] = v; } void AddBodyText(const std::string &body_text) { _resp_body_text = body_text; } std::string Serialize() { // 1.构建状态行 _status_line = _version + spacesep + std::to_string(_status_code) + spacesep + _desc + base_sep; // 2.构建应答报头 for (auto &header : _headers_kv) { std::string header_line = header.first + line_sep + header.second + base_sep; _resp_headers.push_back(header_line); } // 3.空行和正文 // 4.正式序列化 std::string responsestr = _status_line; for (auto &line : _resp_headers) { responsestr += line; } responsestr += _blank_line; responsestr += _resp_body_text; return responsestr; } ~HttpResponse() { } private: // httpresponse 属性 std::string _version; int _status_code; std::string _desc; std::unordered_map<std::string, std::string> _headers_kv; // 基本的httpresponse的格式 std::string _status_line; std::vector<std::string> _resp_headers; std::string _blank_line; std::string _resp_body_text; }; using func_t = std::function<HttpResponse(HttpRequest &)>; class HttpServer { private: std::string GetFileContent(const std::string &path) { std::ifstream in(path, std::ios::binary); if (!in.is_open()) return std::string(); in.seekg(0, in.end); int filesize = in.tellg(); // 告知我你的rw偏移量是多少 in.seekg(0, in.beg); std::string content; content.resize(filesize); in.read((char *)content.c_str(), filesize); in.close(); return content; } public: HttpServer() { _mime_type.insert(std::make_pair(".html", "text/html")); _mime_type.insert(std::make_pair(".jpg", "image/jpeg")); _mime_type.insert(std::make_pair(".png", "image/png")); _mime_type.insert(std::make_pair(".default", "text/html")); _code_to_desc.insert(std::make_pair(100, "Continue")); _code_to_desc.insert(std::make_pair(200, "OK")); _code_to_desc.insert(std::make_pair(201, "Created")); _code_to_desc.insert(std::make_pair(301, "Moved Permanently")); _code_to_desc.insert(std::make_pair(302, "Found")); _code_to_desc.insert(std::make_pair(404, "Not Found")); } std::string HandlerHttpRequest(std::string &reqstr) // req 曾经被客户端序列化过 { #ifdef TEST std::cout << "------------------------------" << std::endl; std::cout << reqstr; std::string responsestr = "HTTP/1.1 200 OK\r\n"; responsestr += "Content-Type: text/html\r\n"; responsestr += "\r\n"; responsestr += "<html><h1>hello Linux, hello World!</h1></html>"; return responsestr; #else std::cout << "------------------------------" << std::endl; std::cout << reqstr; std::cout << "------------------------------" << std::endl; HttpRequest req; HttpResponse resp; req.Deserialize(reqstr); // req.Method(); // 最基本的上层处理 if (req.Path() == "wwwroot/redir") { // 处理重定向 std::string redir_path = "https://www.baidu.com"; // resp.AddCode(302, _code_to_desc[302]); resp.AddCode(301, _code_to_desc[301]); resp.AddHeader("Location", redir_path); } else if (!req.GetRequestBody().empty()) { if (IsServiceExists(req.Path())) { resp = _service_list[req.Path()](req); } } else { // 最基本的上层处理,处理静态资源 std::string content = GetFileContent(req.Path()); if (content.empty()) { content = GetFileContent("wwwroot/404.html"); resp.AddCode(404, _code_to_desc[404]); resp.AddHeader("Content-Length", std::to_string(content.size())); resp.AddHeader("Content-Type", _mime_type[".html"]); resp.AddBodyText(content); } else { resp.AddCode(200, _code_to_desc[200]); resp.AddHeader("Content-Length", std::to_string(content.size())); resp.AddHeader("Content-Type", _mime_type[req.Suffix()]); resp.AddHeader("Set-Cookie", "username=zhangsan"); // resp.AddHeader("Set-Cookie", "passwd=12345"); resp.AddBodyText(content); } } return resp.Serialize(); #endif } void InsertService(const std::string &servicename, func_t f) { std::string s = prefixpath + servicename; _service_list[s] = f; } bool IsServiceExists(const std::string &servicename) { auto iter = _service_list.find(servicename); if (iter == _service_list.end()) return false; else return true; } ~HttpServer() {} private: std::unordered_map<std::string, std::string> _mime_type; std::unordered_map<int, std::string> _code_to_desc; std::unordered_map<std::string, func_t> _service_list; };我们可以看到这块内容是相当多的,但是不用害怕,我一点一点来详细讲解。
首先是我们要引入的头文件
我逐个说明这些语句 / 头文件的作用,一句话讲清楚:
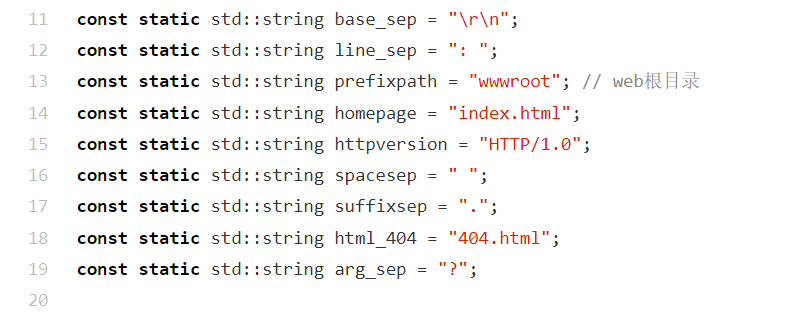
#pragma once:预处理指令,用于防止当前头文件被重复包含(避免重复定义的编译错误)。#include <iostream>:提供标准输入 / 输出流功能,比如用cout输出内容、cin读取输入。#include <string>:提供std::string类,用于处理字符串(支持拼接、截取、比较等操作)。#include <vector>:提供std::vector容器,是动态可变长度的数组,支持自动扩容、随机访问元素。#include <sstream>:提供字符串流(如std::stringstream),用于字符串与其他数据类型的转换(比如把整数转成字符串)。#include <functional>:提供函数对象、绑定器等工具,比如std::function(包装函数 /lambda)、std::bind(绑定函数参数)。#include <fstream>:提供文件流功能,用于读写本地文件(比如ifstream读文件、ofstream写文件)。#include <unordered_map>:提供std::unordered_map容器,是无序键值对哈希表,平均 O (1) 时间复杂度完成查找、插入。这些是 HTTP 服务器相关的常量定义,结合 Web 场景一句话说明每个的作用:
base_sep = "\r\n":HTTP 协议的基础换行分隔符(比如 HTTP 请求 / 响应头的行与行之间用\r\n分隔)。line_sep = ": ":HTTP 请求 / 响应头中 "字段名 - 字段值" 的分隔符(比如Content-Type: text/html里的:)。prefixpath = "wwwroot":网站静态资源的根目录路径(存放 HTML、CSS 等文件的文件夹)。homepage = "index.html":网站的默认首页文件名(用户访问根路径时自动加载的文件)。httpversion = "HTTP/1.0":当前服务器所遵循的 HTTP 协议版本。spacesep = " ":HTTP 请求行的部分分隔符(比如GET /index.html HTTP/1.0中各部分用空格分隔)。suffixsep = ".":文件名与扩展名的分隔符(比如区分index.html中的 "index" 和 "html")。html_404 = "404.html":资源不存在时返回的 "404 错误页面" 文件名。arg_sep = "?":URL 中 "路径" 与 "查询参数" 的分隔符(比如/index.html?name=test中的?)。HttpRequest类的编写
我们先来研究研究http请求该如何来编写。
我们先来看看私有成员变量:
第一部分:基本 HTTP 请求格式相关
std::string _req_line;:存储 HTTP 请求的请求行 (比如GET /index.html HTTP/1.0)。std::vector<std::string> _req_headers;:存储未解析的原始请求头列表(每行是一条完整的头信息)。std::string _blank_line;:存储请求头与请求体之间的空行 (对应 HTTP 协议的\r\n分隔)。std::string _body_text;:存储 HTTP 请求的请求体内容(比如 POST 提交的参数、GET 的查询参数)。第二部分:解析后的具体属性字段
std::string _method;:存储解析后的 HTTP请求方法(比如 GET、POST)。std::string _url;:存储解析后的请求URL 路径 (比如/index.html)。std::string _path;:存储资源在服务器本地的实际路径 (比如wwwroot/index.html)。std::string _suffix;:存储资源的后缀名 (比如.html,用于识别文件类型)。std::string _version;:存储解析后的 HTTP协议版本 (比如HTTP/1.0)。std::unordered_map<std::string, std::string> _headers_kv;:存储解析后的请求头键值对 (比如Host对应localhost)。这是一个用于拆分 HTTP 请求字符串的工具函数,属于 HTTP 服务器中请求解析模块的一部分。以下是其核心逻辑与作用解析:
1. 函数功能
从传入的 HTTP 请求字符串(
reqstr)中,按 HTTP 协议的换行分隔符(base_sep,即\r\n)提取一行内容,并从原字符串中移除已提取的部分,实现请求内容的逐行解析。2. 关键逻辑解析
- 查找分隔符 :通过
reqstr.find(base_sep)定位\r\n在请求字符串中的位置,作为当前行的结束标识;- 异常处理 :若未找到
\r\n(pos == string::npos),返回空字符串,表示无法提取完整行;- 提取当前行 :用
substr(0, pos)截取从字符串开头到\r\n的内容,作为当前行;- 清理已处理内容 :调用
reqstr.erase删除已提取的行及后续的\r\n,避免重复解析;- 结果处理 :若提取的行是空内容,返回
base_sep(\r\n),否则返回提取的行。3. 实际用途
因此该函数是 HTTP 请求解析的基础工具,通常用于:
- 拆分 HTTP 请求的请求行 (如
GET /index.html HTTP/1.0);- 拆分 HTTP 请求的请求头列表 (如
Host: localhost等行);- 实现请求内容的 "逐行读取",为后续解析请求方法、URL、请求头键值对等逻辑提供基础。
这是 HTTP 请求解析模块中的
ParseReqLine函数,核心功能是解析 HTTP 请求行,提取关键信息并构建服务器本地资源路径,是连接请求字符串与服务器资源处理的核心逻辑。其具体逻辑与作用如下:1. 拆分请求行
- 通过
std::stringstream将请求行(如GET /index.html?name=test HTTP/1.0)按空格拆分为:
_method:HTTP 请求方法(如GET);_url:请求的 URL 路径(如/index.html?name=test);_version:HTTP 协议版本(如HTTP/1.0)。2. 处理 GET 请求的查询参数
- 通过
strcasecmp判断请求方法为GET时,查找 URL 中 "?"(arg_sep)的位置:
- 若存在 "?",将其后方内容存入
_body_text(作为 GET 请求的参数);- 截断 URL,仅保留 "?" 前的路径部分。
3. 构建服务器本地资源路径
- 将 URL 拼接至服务器根路径(
_path初始为wwwroot);- 若路径以 "/" 结尾(如用户访问
/),自动拼接默认首页(homepage,如index.html),确保能定位到具体资源文件(最终路径如wwwroot/index.html)。4. 提取资源后缀
- 通过
rfind查找路径中 "."(suffixsep)的位置,提取其后内容作为资源后缀(_suffix,如.html),用于后续识别文件的 MIME 类型;- 若未找到后缀,默认设为
.default。该函数的处理结果直接决定了服务器后续资源定位 (通过
_path)、资源类型识别 (通过_suffix)、请求参数处理 (通过_body_text)的逻辑,是 HTTP 服务器请求解析流程中的关键步骤。这是 HTTP 请求解析模块中的
ParseReqHeader函数,核心功能是将原始请求头列表解析为键值对哈希表,便于后续快速查询请求头信息。其具体逻辑与作用如下:1. 核心功能
将未解析的原始请求头(如
Host: localhost、User-Agent: curl/7.68.0)转换为键-值结构,存入_headers_kv哈希表,实现请求头信息的快速检索。2. 解析逻辑步骤
- 遍历原始请求头列表 :循环处理
_req_headers中的每一条请求头;- 定位分隔符 :查找请求头中 ":"(
line_sep,HTTP 请求头的键值分隔符)的位置;- 异常过滤:若未找到分隔符,跳过当前请求头;
- 拆分键值对 :通过分隔符将请求头拆分为键
k(如Host)和值v(如localhost);- 过滤无效数据:若键或值为空,跳过当前请求头;
- 存入哈希表 :将有效的键值对插入
_headers_kv,完成解析。3. 实际作用
解析后的
_headers_kv哈希表,可支持后续服务器逻辑快速获取请求头信息 (如获取Content-Length判断请求体大小、获取Host确定目标域名),检索时间复杂度为 O (1),是 HTTP 请求处理流程中 "结构化解析" 的关键步骤之一。这是
HttpRequest类的构造函数, 通过初始化列表提前设置_blank_line(协议分隔符\r\n)和_path(资源根路径),确保HttpRequest对象创建时就具备 HTTP 解析所需的基础配置,为后续的请求行、请求头解析流程提供必要的初始值。这是
HttpRequest类的反序列化入口函数,核心功能是将无结构的原始 HTTP 请求字符串,转换为类内的结构化成员变量,是连接客户端原始请求数据与服务器后续处理逻辑的核心环节。其流程与作用如下:1. 流程:分层完成反序列化
(1)基本反序列化:提取请求的基础结构
- 提取请求行 :通过
GetLine从原始请求字符串reqstr中提取第一行,赋值给_req_line(对应 HTTP 请求的 "请求行" 部分);- 提取请求头 :通过
do-while循环持续调用GetLine提取内容,将非空、非分隔符的行存入_req_headers(原始请求头列表);当遇到空行或base_sep(\r\n)时终止循环(对应 HTTP 协议中 "请求头与请求体的分隔规则");- 提取请求体 :若
reqstr剩余内容非空,将其赋值给_body_text(对应 HTTP 请求的 "请求体" 部分)。(2)进一步反序列化:解析为结构化字段
- 调用
ParseReqLine:解析_req_line,提取请求方法、URL、协议版本等信息,并构建服务器本地的资源路径;- 调用
ParseReqHeader:解析_req_headers,将原始请求头转换为键值对哈希表,便于后续快速查询。2. 作用
该函数实现了 "原始请求字符串→基础结构→结构化字段" 的分层解析逻辑,将无结构的 HTTP 请求数据,转化为程序可直接使用的结构化信息(如请求方法、资源路径、请求头键值对),为后续服务器的资源定位、响应构建等流程提供了可直接调用的数据基础。
这些是
HttpRequest类的数据访问函数,核心作用是对外提供解析后的 HTTP 请求信息(部分含调试日志):
Url():打印客户端请求 URL 的调试日志,返回解析后的请求 URL。Path():打印客户端请求资源本地路径的调试日志,返回服务器本地的资源路径。Suffix():直接返回解析后的资源后缀名。Method():打印客户端请求方法的调试日志,返回解析后的 HTTP 请求方法。GetRequestBody():打印包含请求方法、参数、资源路径的调试日志,返回请求体(或 GET 请求的查询参数)内容。这是
HttpRequest类的调试辅助函数,核心作用是将解析后的 HTTP 请求信息(含原始结构与结构化字段)格式化输出到控制台,便于开发阶段验证请求解析的正确性。其打印内容分为以下几类:
原始请求结构
- 打印分隔线与原始请求行(标记为 "###");
- 遍历打印未解析的原始请求头列表(标记为 "@@@");
- 打印请求头与请求体的分隔空行(标记为 "***")及请求体内容(标记为 ">>>")。
解析后的结构化字段
- 打印请求方法、URL、HTTP 协议版本;
- 遍历打印请求头的键值对(标记为 ")))",格式为 "键 -> 值")。
该函数的设计目的是让我们快速直观地核对 "原始请求" 与 "解析结果" 是否一致,是 HTTP 服务器开发中常用的调试工具。
HttpResponse类的编写
接下来我们来研究http应答该怎么写:
这些是
HttpResponse类的私有成员变量,分为 "响应核心属性" 和 "响应格式载体" 两类,支撑 HTTP 响应的构建与序列化:一、HTTP 响应核心属性(配置响应的关键信息)
std::string _version;:存储响应遵循的 HTTP 协议版本(如HTTP/1.0),是响应状态行的组成部分。int _status_code;:存储响应的状态码(如 200、404),标识请求的处理结果。std::string _desc;:存储状态码对应的描述(如 "OK""Not Found"),与状态码配合构成状态行的提示信息。std::unordered_map<std::string, std::string> _headers_kv;:存储响应头的键值对(如Content-Type: text/html),是构建响应头的基础数据。二、HTTP 响应格式载体(组装响应字符串的结构)
std::string _status_line;:存储组装完成的响应状态行(如HTTP/1.0 200 OK\r\n),是响应的首行内容。std::vector<std::string> _resp_headers;:存储格式化后的响应头列表(每条为完整的头信息行),用于后续拼接响应字符串。std::string _blank_line;:存储响应头与响应体之间的空行分隔符(\r\n),符合 HTTP 协议的格式规范。std::string _resp_body_text;:存储响应的正文内容(如 HTML 页面、数据),是客户端接收的实际内容。这是
HttpResponse类的构造函数,该构造函数的作用是在HttpResponse对象创建时,提前配置好响应的协议版本与格式分隔符,为后续构建状态行、响应头、响应体的流程奠定基础。这是
HttpResponse类的响应状态配置函数,作用是设置 HTTP 响应的状态信息:
- 接收两个参数:
code(HTTP 状态码,如 200、404)和desc(状态码对应的描述,如 "OK""Not Found");- 将参数分别赋值给类的私有成员
_status_code和_desc,为后续构建响应状态行提供核心数据。该函数是配置 HTTP 响应结果的基础接口,状态码与描述的组合直接决定了客户端对请求结果的判定(如成功、资源不存在等)。
这是
HttpResponse类的响应头配置函数,核心作用是向响应中添加 HTTP 响应头的键值对:
- 接收两个参数:
k(响应头字段名,如Content-Type)和v(对应字段值,如text/html);- 将键值对存入
_headers_kv哈希表,为后续序列化时构建符合 HTTP 规范的响应头提供数据基础。响应头是 HTTP 响应的关键组成部分,其配置直接影响客户端对响应内容的解析逻辑(如资源类型、内容长度等),该函数是构建合法 HTTP 响应的基础接口之一。
这是
HttpResponse类的响应体配置函数,核心作用是设置 HTTP 响应的正文内容:
- 接收参数
body_text(响应体的实际内容,如 HTML 页面、数据文本等);- 将其赋值给类的私有成员
_resp_body_text,为后续序列化时拼接完整的 HTTP 响应提供正文数据。响应体是 HTTP 响应中客户端实际接收并展示的核心内容,该函数是构建包含有效内容的 HTTP 响应的关键接口之一。
这是
HttpResponse类的HTTP 响应序列化函数,核心作用是遵循 HTTP 协议格式,将类内的结构化响应信息(状态、响应头、响应体)组装为可直接发送给客户端的完整响应字符串。其流程与对应 HTTP 规范如下:1. 构建状态行(符合 HTTP 状态行格式)
按 "
HTTP版本 状态码 描述\r\n" 的规范,拼接_version(协议版本)、spacesep(空格)、状态码(转字符串)、状态描述,最后追加base_sep(\r\n),生成响应的首行内容(如HTTP/1.0 200 OK\r\n)。2. 构建响应头列表(符合 HTTP 响应头格式)
遍历
_headers_kv中的键值对,按 "键: 值\r\n" 的规范,拼接每个字段的完整行,存入_resp_headers向量(如Content-Type: text/html\r\n),为后续拼接做准备。3. 组装完整响应字符串
- 先将状态行存入结果字符串
responsestr;- 追加所有格式化后的响应头行;
- 追加
_blank_line(\r\n,对应 HTTP 协议中 "响应头与响应体的空行分隔规则");- 最后追加响应体
_resp_body_text,形成符合 HTTP 规范的完整响应内容。该函数是 HTTP 服务器向客户端返回结果的关键环节,其输出的字符串是客户端能直接解析的标准 HTTP 响应格式。
HttpServer类的编写
接下来就是将两者结合起来了
这是 C++ 中的类型别名定义,核心作用是统一 "HTTP 请求处理器" 的函数接口类型:
类型定义内容 用
using为std::function定义别名func_t,其函数签名为:接收HttpRequest&(HTTP 请求对象的引用)作为参数,返回HttpResponse(HTTP 响应对象)。实际用途 在 HTTP 服务器开发中,
func_t通常作为请求处理函数的统一接口类型------ 用于规范 "处理请求、生成响应" 的函数格式,方便管理不同的请求处理器(如路由对应的业务处理函数),实现请求分发逻辑与具体业务处理的解耦,提升代码的灵活性与可维护性。这些是 HTTP 服务器核心类的私有成员变量,分别承担 "资源类型映射""状态码配置""请求路由管理" 的功能,是服务器处理请求、构建响应的基础数据容器:
1.
std::unordered_map<std::string, std::string> _mime_type
- 作用 :存储 "资源后缀名→MIME 类型" 的映射关系(如
.html对应text/html、.jpg对应image/jpeg)。- 意义 :HTTP 响应需通过
Content-Type头告知客户端资源类型,该映射可根据资源后缀快速匹配对应的 MIME 类型,确保响应头配置符合 HTTP 规范。2.
std::unordered_map<int, std::string> _code_to_desc
- 作用 :存储 "HTTP 状态码→状态描述" 的映射关系(如
200对应OK、404对应Not Found)。- 意义:构建响应状态行时,可通过状态码快速获取对应的描述文本,避免硬编码,提升状态信息配置的灵活性与一致性。
3.
std::unordered_map<std::string, func_t> _service_list
- 作用 :存储 "请求路径→请求处理函数" 的路由映射(如路径
/index.html对应处理该请求的func_t类型函数)。- 意义:实现 HTTP 服务器的路由分发逻辑 ------ 当收到请求时,可根据请求路径匹配对应的处理函数,完成 "请求→业务逻辑→响应" 的流程衔接。
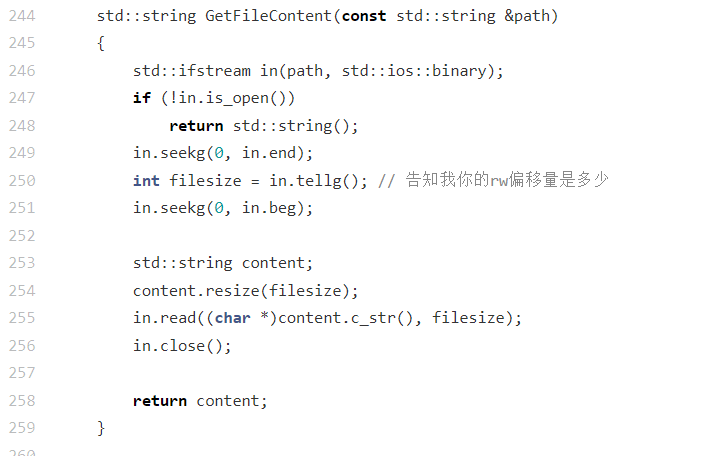
这是一个文件内容读取函数,核心作用是按二进制模式读取指定路径的文件内容,并以字符串形式返回,通常用于 HTTP 服务器加载静态资源(如 HTML 页面、图片等)。其流程与设计特点如下:
1. 执行流程
- 打开文件 :以二进制模式(
std::ios::binary)打开指定路径的文件,避免文本模式下的换行符自动转换(确保非文本文件如图片的内容完整性);- 失败处理 :若文件打开失败(
!in.is_open()),直接返回空字符串;- 获取文件大小 :通过
seekg移动到文件末尾,用tellg获取当前位置(即文件字节数),再将文件指针移回开头;- 读取内容 :调整字符串
content的大小为文件字节数,通过read函数将文件内容读取到字符串中;- 收尾:关闭文件,返回存储了文件内容的字符串。
2. 设计特点
- 采用二进制模式读取,兼容文本文件与非文本文件(如图片、二进制数据);
- 借助
std::string存储文件内容(C++ 字符串支持任意字节数据),简化数据传递流程;- 包含基础的错误处理(文件打开失败时返回空),为上层逻辑提供错误标识。
构造函数我们用来初始化一些参数:
_mime_type[".html"] = "text/html";:配置 html 文件的 MIME 类型;_mime_type[".jpg"] = "image/jpeg";:配置 jpg 图片的 MIME 类型;_mime_type[".png"] = "image/png";:配置 png 图片的 MIME 类型;_mime_type[".js"] = "application/x-javascript";:配置 js 文件的 MIME 类型;_mime_type[".css"] = "text/css";:配置 css 文件的 MIME 类型;_mime_type[".default"] = "text/html";:配置未知后缀文件的默认 MIME 类型;_code_to_desc[200] = "OK";:配置 200 状态码的描述文本;_code_to_desc[404] = "Not Found";:配置 404 状态码的描述文本;_code_to_desc[400] = "Bad Request";:配置 400 状态码的描述文本;_code_to_desc[500] = "Internal Server Error";:配置 500 状态码的描述文本;我们接下来分三步来看这个HandlerHttpRequest函数
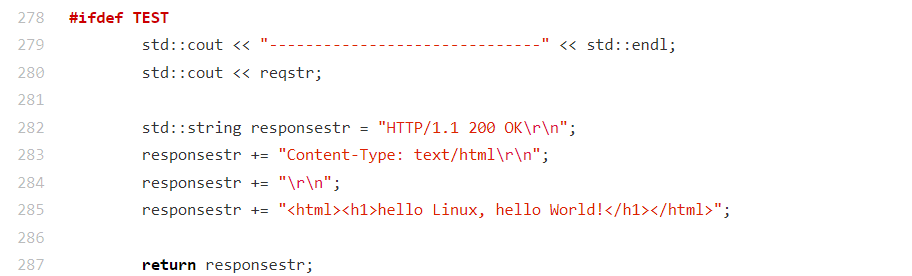
这是
HandlerHttpRequest函数中TEST 模式下的请求处理逻辑 ,作用是在编译时定义了TEST宏的情况下,跳过复杂业务逻辑,直接返回固定 HTTP 响应,用于快速测试服务器通信:核心逻辑
- 条件编译触发 :
#ifdef TEST判定编译时存在TEST宏,执行该代码块;- 调试输出 :打印分隔线与客户端请求字符串
reqstr,便于测试时查看请求内容;- 构建固定响应 :按 HTTP 协议格式拼接:
- 状态行(
HTTP/1.1 200 OK\r\n);- 响应头(
Content-Type: text/html\r\n,指定响应体为 HTML 类型);- 空行(
\r\n,分隔响应头与响应体);- 响应体(简单 HTML 页面,内容为
hello Linux, hello World!);- 返回响应:直接返回该固定响应字符串。
用途
此逻辑是 HTTP 服务器的测试辅助分支,用于快速验证服务器与客户端的基本通信链路是否正常,避免实际业务逻辑(如请求解析、资源读取)对测试的干扰。
这是
HandlerHttpRequest函数在 ** 非 TEST 模式(正式运行模式)** 下的请求处理逻辑,是 HTTP 服务器的核心业务流程,负责解析请求、分场景处理并生成合规响应:1. 基础流程
- 调试输出:打印分隔线与客户端请求字符串,用于正式运行时查看请求内容;
- 请求解析 :创建
HttpRequest与HttpResponse对象,调用Deserialize将请求字符串解析为结构化的req对象,为后续处理提供清晰的请求信息。2. 分场景业务处理
(1)重定向场景
当请求路径为
wwwroot/redir时:
- 配置 301 永久重定向,设置状态码(301)与
Location响应头(指向百度地址),引导客户端跳转到指定 URL。(2)动态服务场景
当请求体非空且路径已注册服务时:
- 调用
IsServiceExists校验路径对应的服务是否存在;- 若存在,执行
_service_list中注册的业务处理函数,由该函数生成响应(实现业务逻辑与路由的解耦)。(3)静态资源场景
处理静态文件请求:
- 调用
GetFileContent读取请求路径对应的文件内容;
- 若内容为空(文件不存在):读取 404 页面,设置 404 状态码、内容长度、MIME 类型(text/html),将 404 页面作为响应体;
- 若内容非空:设置 200 状态码,补充内容长度、对应资源的 MIME 类型、Cookie(如
username=zhangsan)等响应头,将文件内容作为响应体。3. 响应返回
将构建完成的
HttpResponse对象序列化为符合 HTTP 协议的字符串,返回给客户端。此逻辑是 HTTP 服务器的正式业务处理分支,覆盖了重定向、动态业务接口、静态资源这三类常见 HTTP 请求场景,同时包含异常处理(资源不存在返回 404),保证了响应的合规性与服务的可用性。
这部分代码包含条件编译闭合指令与两个服务管理函数,是 HTTP 服务器动态业务路由的核心辅助逻辑:
1.
#endif这是条件编译的闭合指令,用于结束之前的
#ifdef TEST代码块,明确区分 TEST 模式与正式运行模式的代码范围,保证编译时仅执行对应模式的逻辑。2.
InsertService(const std::string &servicename, func_t f)
- 功能:注册 HTTP 请求对应的业务处理服务
- 流程 :将传入的服务名拼接前缀路径
prefixpath作为路由键,将处理函数f(func_t类型)存入_service_list路由映射表- 作用:实现业务逻辑与路由的动态绑定,支持灵活扩展业务接口,解耦路由配置与具体业务代码
3.
IsServiceExists(const std::string &servicename)
- 功能:校验指定业务服务是否已注册
- 流程 :在
_service_list中查找传入的服务名,未找到则返回false,找到则返回true- 作用:在请求处理阶段提前校验服务存在性,避免调用不存在的业务函数,提升代码健壮性
ServerMain.cc服务器源文件
cpp#include "TcpServer.hpp" #include "Http.hpp" HttpResponse Login(HttpRequest &req) { HttpResponse resp; std::cout << "外部已经拿到参数了: " << std::endl; req.GetRequestBody(); std::cout << "######################" << std::endl; resp.AddCode(200, "OK"); resp.AddBodyText("<html><h1>result done!</h1></html>"); return resp; } // ./tcpserver 8888 int main(int argc, char *argv[]) { if (argc != 2) { std::cerr << "Usage: " << argv[0] << " local-port" << std::endl; exit(0); } uint16_t port = std::stoi(argv[1]); // 我们的软件代码,我们手动的划分了三层 HttpServer hserver; hserver.InsertService("/login", Login); std::unique_ptr<TcpServer> tsvr = std::make_unique<TcpServer>(std::bind(&HttpServer::HandlerHttpRequest, &hserver, std::placeholders::_1), port); tsvr->Loop(); return 0; }这段代码是简易 HTTP 服务器的主程序入口,核心作用是整合 TCP 底层网络通信与 HTTP 应用层处理逻辑,实现带登录业务接口的 HTTP 服务启动,具体可分为三部分:
- 基础依赖引入 :导入封装好的 TCP 服务器头文件(
TcpServer.hpp)和 HTTP 核心组件头文件(Http.hpp),分别为网络通信、HTTP 请求 / 响应处理、路由管理提供底层支撑。- 登录业务处理函数定义 :自定义
Login函数作为 HTTP 业务处理接口,接收 HTTP 请求对象后,获取请求体(用于读取登录参数),并构建包含 200 成功状态码、简单 HTML 结果的 HTTP 响应返回。- 主程序逻辑(main 函数) :
- 启动参数校验:要求运行程序时传入端口号(如
./tcpserver 8888),否则提示正确用法并退出;- HTTP 服务初始化:创建
HttpServer对象,将/login请求路径与Login业务函数绑定,完成路由注册;- TCP-HTTP 逻辑绑定:通过智能指针创建
TcpServer对象,将HttpServer的请求处理核心函数绑定为 TCP 服务器的回调,打通 "TCP 接收客户端数据→HTTP 解析 / 处理请求" 的链路;- 启动服务循环:调用 TCP 服务器的
Loop方法,让服务器持续监听指定端口,接收并处理客户端的 HTTP 请求。核心特点
整体逻辑通过 "路由注册 + 回调绑定" 实现解耦:TCP 层负责纯网络通信,HTTP 层负责请求解析与业务分发,最终实现对
/login路径的 HTTP 请求进行专属业务处理,并返回合规响应。总结
- 核心目标是启动一个可处理
/login请求的 HTTP 服务器,整合 TCP 网络层与 HTTP 应用层能力;- 关键设计是动态注册业务接口(
/login绑定Login函数),解耦路由配置与业务逻辑;- 运行逻辑是监听指定端口,持续处理客户端 HTTP 请求,对
/login路径返回登录业务响应。
简单的http服务器实现C++
板鸭〈小号〉2025-12-07 12:00





















相关推荐
爱写代码的森3 小时前
鸿蒙三方库 | harmony-utils之ImageUtil图片保存到本地详解大耳朵-小飞象5 小时前
电力安全运维的智能密码:BACS如何破解设备全生命周期管理难题,让电网安全“看得见、管得住”?极客侃科技6 小时前
制造企业 MES/APS 选型:SAP PP/DS 集成、ERP-MES 边界划分与一体化架构要点HLC++6 小时前
Linux的进程间通信白露与泡影8 小时前
Arthas 实战指南:从方法耗时定位到 JVM 变量热修改神奇霸王龙9 小时前
Claude Code屠榜:MiMo与Grok紧追CodexWeb极客码9 小时前
WordPress SEO优化:提升网站排名的13个关键步骤生活爱好者!9 小时前
我把NAS当作下载机,docker一键部署qb尽兴-10 小时前
企业业务系统架构选型与渐进式演进通信小小昕11 小时前
Ubuntu 26.04 中文输入法安装