2025年12月
摘要
过去一年标志着大型语言模型(LLM)发展和实际应用的转折点。随着2024年12月5日首个广泛采用的推理模型_o1_的发布,该领域从单次模式生成转向多步骤审议推理,加速了部署、实验和新应用类别的出现。随着这一转变的快速展开,我们对这些模型在实际中如何使用的实证理解滞后了。在这项工作中,我们利用OpenRouter平台(一个跨各种LLM的AI推理提供商)分析了超过100万亿token的真实世界LLM交互,涵盖任务、地理和时间维度。在我们的实证研究中,我们观察到开源模型的广泛采用、创意角色扮演的极大流行(不仅仅是许多人认为主导的生产力任务)和编程辅助类别,以及代理推理的兴起。此外,我们的留存分析识别了"基础队列":早期用户的参与度比后期队列持续得多。我们将这种现象称为灰姑娘"水晶鞋"效应。这些发现强调开发者和最终用户在"野外"与LLM互动的方式是复杂和多方面的。我们讨论了对模型构建者、AI开发者和基础设施提供商的影响,并概述了数据驱动的使用理解如何为更好的LLM系统设计和部署提供信息。
引言
就在一年前,大型语言模型的格局看起来根本不同。在2024年底之前,最先进的系统主要由为续写文本序列而优化的单次自回归预测器主导。几次先驱性的尝试试图通过高级指令遵循和工具使用来近似推理。例如,_Anthropic的Sonnet 2.1和3_模型在复杂的_工具使用和检索增强生成(RAG)_方面表现出色,而_Cohere的Command R_模型融入了结构化的工具规划token。另外,像_Reflection_这样的开源项目在训练期间探索了监督式的思维链和自我评判循环。虽然这些先进的技术产生了类似推理的输出和卓越的指令遵循,但基本的推理过程仍然基于单次前向传播,发射从数据中学习的表层轨迹,而不是执行迭代的内部计算。
这种范式在__2024年12月5日__发生了演变,当时OpenAI发布了其_o1_推理模型的第一个完整版本(代号_Strawberry_)4。2024年9月12日发布的预览版已经表明了对传统自回归推理的背离。与之前的系统不同,_o1_采用了扩展的推理时计算过程,涉及内部多步骤审议、潜在规划和迭代优化,然后生成最终输出。实际上,这使得数学推理、逻辑一致性和多步骤决策的系统性改进,反映了从模式完成到结构化内部认知的转变。回想起来,去年标志着该领域的真正拐点:早期的方法向推理示意,但_o1_引入了首个通过审慎的多阶段计算而非仅仅_描述_它6, 7来执行推理的通用部署架构。
虽然最近LLM能力的进步已被广泛记录,但关于这些模型在实践中如何实际使用的系统证据仍然有限3, 5。现有的描述倾向于强调定性演示或基准性能,而不是大规模的行为数据。为了弥合这一差距,我们进行了LLM使用的实证研究,利用来自__OpenRouter__的100万亿token数据集,这是一个多模型AI推理平台,作为多样化LLM查询的中心。
OpenRouter的视角为细粒度使用模式提供了独特的窗口。因为它协调跨广泛模型阵列(包括闭源API和开源部署)的请求,OpenRouter捕获了开发者和最终用户如何实际为各种任务调用语言模型的代表性横截面。通过分析这个丰富的数据集,我们可以观察到哪些模型被选择用于哪些任务,使用如何随地理区域和时间变化,以及定价或新模型发布等外部因素如何影响行为。
在本文中,我们从之前的AI采用实证研究中汲取灵感,包括Anthropic的经济影响和使用分析1和OpenAI的报告_人们如何使用ChatGPT_2,旨在进行中立的、证据驱动的讨论。我们首先描述我们的数据集和方法论,包括我们如何对任务和模型进行分类。然后我们深入研究一系列分析,阐明使用的不同方面:
- 开源与闭源模型: 我们检查开源模型相对于专有模型的采用模式,识别开源生态系统中的趋势和关键参与者。
- 代理推理: 我们调查多步骤、工具辅助推理模式的出现,捕捉用户如何越来越多地将模型用作更大自动化系统中的组件,而不是用于单次交互。
- 类别分类法: 我们按任务类别(如编程、角色扮演、翻译等)细分使用情况,揭示哪些应用领域驱动最多的活动,以及这些分布如何因模型提供商而异。
- 地理分布: 我们分析全球使用模式,比较各大洲的LLM采用情况并深入研究美国内部的使用情况。这突显了地区因素和本地模型产品如何塑造总体需求。
- 有效成本与使用动态: 我们评估使用如何对应有效成本,捕捉实践中LLM采用的经济敏感性。该指标基于平均输入加输出token并考虑缓存效应。
- 留存模式: 我们分析最广泛使用模型的长期留存,识别定义持续、更粘性行为的_基础队列_。我们将其定义为灰姑娘_"水晶鞋"_效应,其中用户需求与模型特性之间的早期一致创造了随时间维持参与的持久匹配。
最后,我们讨论这些发现揭示了关于真实世界LLM使用的什么,突显了意外的模式并纠正了一些神话。
数据和方法论
OpenRouter平台和数据集
我们的分析基于从__OpenRouter__平台收集的元数据,OpenRouter是一个统一的AI推理层,将用户和开发者连接到数百个大型语言模型。OpenRouter上的每个用户请求都针对用户选择的模型执行,并且记录描述结果"生成"事件的结构化元数据。本研究中使用的数据集包含来自全球用户基础的数十亿个提示-完成对的__匿名请求级元数据__,时间跨度约为两年至撰写时。我们确实专注于去年。
关键是,我们没有访问底层提示或完成的文本。我们的分析完全依赖于捕获每个_生成_的结构、时间和上下文的___元数据___,而不暴露用户内容。这种保护隐私的设计使得大规模的行为分析成为可能。
每个生成记录包括时间、模型和提供商标识符、token使用情况和系统性能指标的信息。Token计数包括提示(输入)和完成(输出)token,使我们能够测量整体模型工作负载和成本。元数据还包括与地理路由、延迟和使用上下文相关的字段(例如,请求是否被流式传输或取消,或者是否调用了工具调用功能)。总之,这些属性提供了模型在实践中如何使用的详细但非文本的视图。
基于此元数据的所有分析、聚合和大多数可视化都是使用__Hex__分析平台进行的,该平台为版本化的SQL查询、转换和最终图形生成提供了可重现的管道。
我们强调这个数据集是__观察性的__:它反映了OpenRouter平台上的真实世界活动,而平台本身又受到模型可用性、定价和用户偏好的塑造。截至2025年,OpenRouter支持来自60多个提供商的300多个活跃模型,为数百万开发者和最终用户服务,其中超过50%的使用来自美国以外。虽然平台外的某些使用模式未被捕获,但OpenRouter的全球规模和多样性使其成为大规模LLM使用动态的代表性视角。
GoogleTagClassifier用于内容分类
本研究无法直接访问用户提示或模型输出。相反,__OpenRouter通过一个非专有模块__GoogleTagClassifier__对所有提示和响应的约0.25%随机样本执行内部分类。虽然这只占总活动的一小部分,但考虑到OpenRouter处理的整体查询量,底层数据集仍然相当可观。GoogleTagClassifier与Google Cloud Natural Language的classifyText内容分类API接口
该API对文本输入应用分层、语言不可知的分类法,返回一个或多个类别路径(例如,/Computers & Electronics/Programming、/Arts & Entertainment/Roleplaying Games)以及0,1范围内的相应置信度分数。分类器直接对提示数据(最多前1,000个字符)进行操作。分类器部署在OpenRouter的基础设施内,确保分类保持匿名且不与个人客户关联。置信度分数低于默认阈值0.5的类别被排除在进一步分析之外。分类系统本身完全在OpenRouter基础设施内运行,不是本研究的一部分;我们的分析仅依赖于生成的分类输出(实际上是描述提示分类的元数据),而不是底层的提示内容。
为了使这些细粒度标签在大规模上有用,我们将GoogleTagClassifier的分类法映射到一个紧凑的研究定义的桶集,并为每个请求分配_标签_。每个标签以一对一方式汇总到更高级别的_类别_。代表性映射包括:
- 编程: 来自
/Computers & Electronics/Programming或/Science/Computer Science/* - 角色扮演: 来自
/Games/Roleplaying Games和/Arts & Entertainment/*下的创意对话叶子 - 翻译: 来自
/Reference/Language Resources/* - 通用问答/知识: 来自
/Reference/General Reference/*和/News/*,当意图似乎是事实查找时 - 生产力/写作: 来自
/Computers & Electronics/Software/Business & Productivity Software或/Business & Industrial/Business Services/Writing & Editing Services - 教育: 来自
/Jobs & Education/Education/* - 文学/创意写作: 来自
/Books & Literature/*和/Arts & Entertainment/*下的叙事叶子 - 成人内容: 来自
/Adult - 其他: 用于没有主导映射的提示的长尾。(注意:我们从下面的多数分析中省略此类别。)
这种方法存在固有的局限性,例如,依赖预定义的分类法限制了新颖或跨领域行为如何被分类,某些交互类型可能还不能整齐地融入现有类别。实际上,一些提示在内容跨越重叠领域时会收到多个类别标签。尽管如此,分类器驱动的分类为我们提供了下游分析的视角。这使我们能够量化不仅是LLM被使用的_多少_,还有_用于什么_。
模型和Token变体
有几个变体值得明确说明:
- 开源vs专有: _ 如果模型的权重公开可用,我们将模型标记为__开源(为简单起见简称OSS),如果访问只能通过受限的API(例如,Anthropic的Claude),则标记为__闭源。这种区别让我们能够衡量社区驱动的模型与专有模型的采用情况。
- 来源(中国vs世界其他地区):_ 鉴于中国LLM的兴起及其独特的生态系统,我们按主要开发地区标记模型。__中国模型__包括在中国、台湾或香港的组织开发的模型(例如,阿里巴巴的Qwen、Moonshot AI的Kimi或DeepSeek)。__RoW(世界其他地区)模型__涵盖北美、欧洲和其他地区。
- 提示vs完成Token:_ 我们区分__提示token__(代表提供给模型的输入文本)和__完成token__(代表模型生成的输出)。__总token__等于提示和完成token的总和。__推理token__代表具有本机推理能力的模型中的内部推理步骤,并包含在__完成token__中。
除非另有说明,token数量__指的是__提示(输入)和完成(输出)token的总和。
地理细分
为了了解LLM使用中的区域模式,我们按用户地理位置细分请求。直接的请求元数据(如基于IP的位置)通常不精确或已匿名化。相反,我们根据与每个账户关联的__账单位置__确定用户地区。这为用户地理提供了更可靠的代理,因为账单数据反映与用户支付方式或账户注册链接的国家或地区。我们在区域采用和模型偏好的分析中使用这种基于账单的细分。
这种方法有其局限性。一些用户使用第三方账单或共享组织账户,这可能不对应他们的实际位置。企业账户可能在一个账单实体下聚合多个地区的活动。尽管存在这些不完善之处,但考虑到我们可用的元数据,账单地理仍然是隐私保护地理分析中最稳定和可解释的指标。
时间范围和覆盖范围
我们的分析主要涵盖截至2025年11月的滚动13个月期间,但并非所有底层元数据都跨越这个完整窗口。大多数模型级和定价分析集中在2024年11月3日-2025年11月30日时间范围。然而,类别级分析(特别是那些使用GoogleTagClassifier分类法的分析)基于从2025年5月开始的较短间隔,反映了OpenRouter上何时开始一致的标记。特别是,详细的任务分类字段(如_编程_、_角色扮演_或_技术_等标签)仅在2025年中期添加。因此,类别部分的所有发现应解释为代表2025年中期使用,而不是整个前一年。
除非另有说明,所有时间序列聚合都使用UTC标准化时间戳按周计算,汇总提示和完成token。这种方法确保了模型家族之间的可比性,并最小化来自瞬时峰值或区域时区效应的偏差。
开源与闭源模型
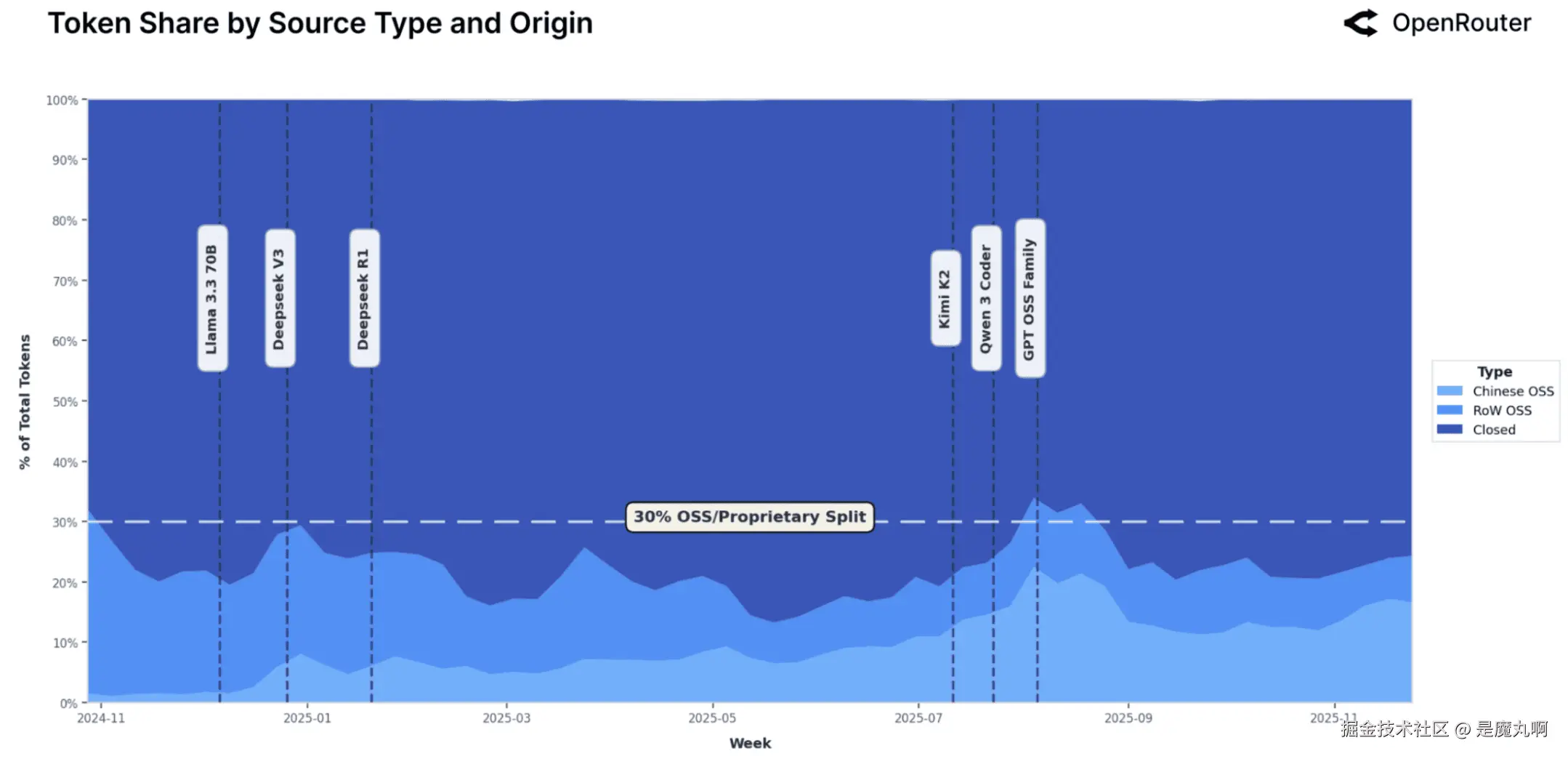
开源与闭源模型分布。 按来源类型划分的总token数量周份额。浅蓝色阴影代表开源权重模型(中国vs世界其他地区),而深蓝色对应专有(闭源)产品。垂直虚线标记了关键开源权重模型的发布,包括Llama 3.3 70B、DeepSeek V3、DeepSeek R1、Kimi K2、GPT OSS家族和Qwen 3 Coder。
AI生态系统的核心问题是开源权重(我们为简单起见缩写为OSS)和专有模型之间的平衡。下面的图表说明了这种平衡在过去一年中在OpenRouter上如何演变。虽然专有模型,特别是来自主要北美提供商的模型,仍然服务着大部分token,但OSS模型稳步增长,到2025年底达到约三分之一的的使用。
这种扩张不是偶然的。使用高峰与主要开源模型发布如DeepSeek V3和Kimi K2(在第一个图表中用垂直虚线表示)相一致,表明像DeepSeek V39和GPT OSS模型8这样的竞争性OSS发布被快速采用并保持了它们的收益。重要的是,这些增长持续到发布后数周,暗示着真正的生产使用而非短期实验。
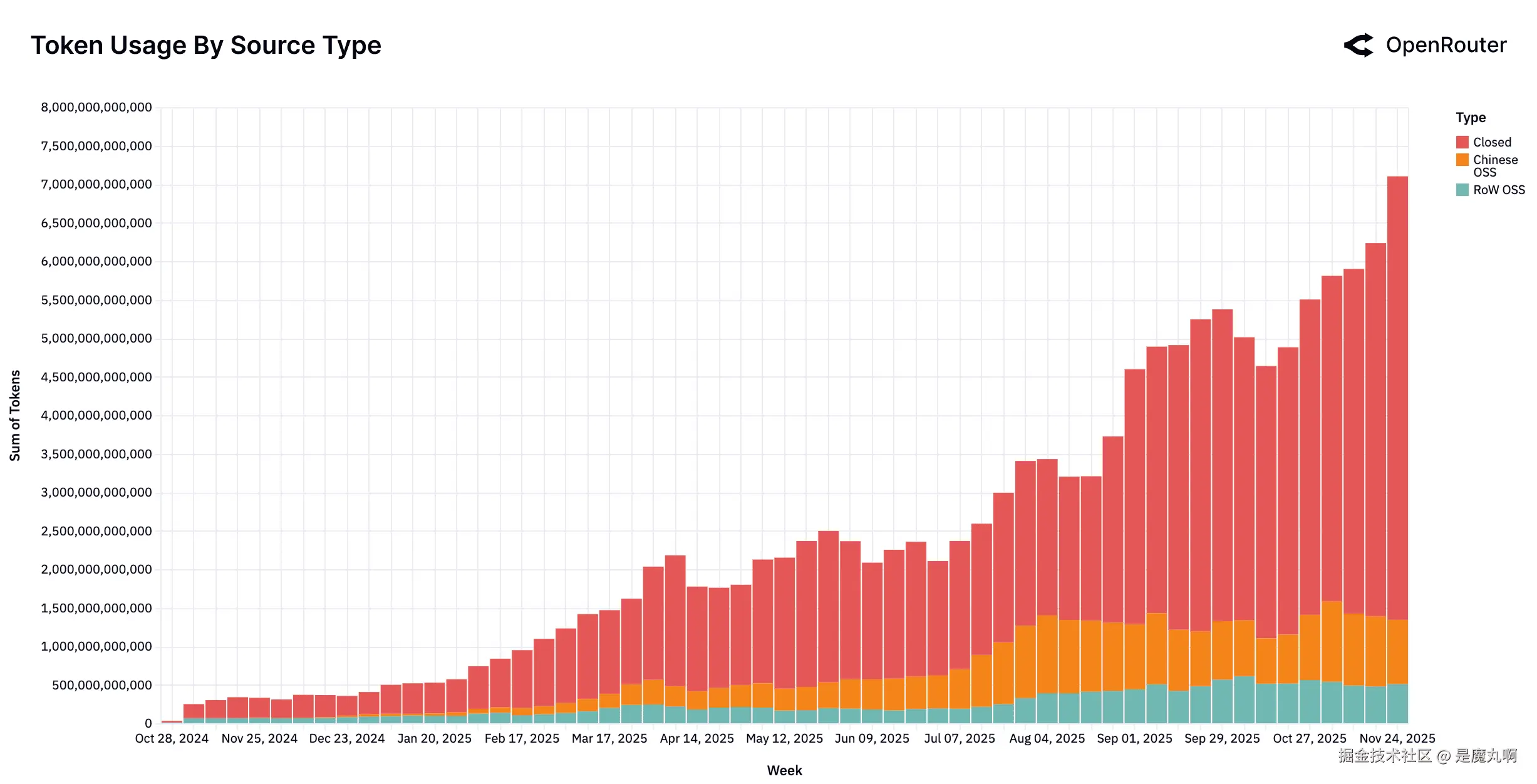
按模型类型的周token数量。 显示按时间划分的总token使用的堆叠条形图。深红色对应专有模型(闭源 ),橙色代表中国开源模型(中国OSS ),蓝绿色表示中国以外开发的开源模型(RoW OSS)。图表突显了2025年OSS token份额的逐渐增长,特别是从年中的中国OSS模型开始。
这种增长的很大一部分来自__中国开发的模型__。从2024年底的微不足道的基础(周份额低至1.2%)开始,中国OSS模型稳步获得关注,在一些周达到所有模型总使用量的近30%。在这一年窗口中,它们平均约占周token数量的13.0%,强劲增长集中在2025年下半年。相比之下,RoW OSS模型平均占13.7%,而专有RoW模型保持最大份额(平均70%)。中国OSS的扩张不仅反映了竞争质量,还反映了快速迭代和密集的发布周期。像Qwen和DeepSeek这样的模型保持了定期的模型发布,使它们能够快速适应新兴工作负载。这种模式实质性地重塑了开源细分市场并推进了LLM景观的全球竞争。
这些趋势表明LLM生态系统中存在持久的二元结构。专有系统继续定义可靠性和性能的上限,特别是对于监管或企业工作负载。相比之下,OSS模型提供成本效率、透明度和定制化,使它们成为某些工作负载的有吸引力的选择。平衡目前在大约30%达到。 这些模型不是相互排斥的;相反,它们在开发者和基础设施提供商越来越偏好的多模型堆栈中相互补充。
关键开源参与者
下表根据我们数据集中的总token服务量对顶级模型家族进行排名。OSS模型的格局在过去一年发生了显著变化:虽然DeepSeek仍然是按数量计算最大的OSS贡献者,但随着新进入者迅速获得关注,其主导地位已经减弱。今天,多个开源家族每个都维持着实质性的使用,指向一个多元化的生态系统。
按模型作者的总token数量(2024年11月--2025年11月)。 Token计数反映OpenRouter上所有模型变体的聚合使用。
| 模型作者 | 总Token(万亿) |
|---|---|
| DeepSeek | 14.37 |
| Qwen | 5.59 |
| Meta LLaMA | 3.96 |
| Mistral AI | 2.92 |
| OpenAI | 1.65 |
| Minimax | 1.26 |
| Z-AI | 1.18 |
| TNGTech | 1.13 |
| MoonshotAI | 0.92 |
| 0.82 |
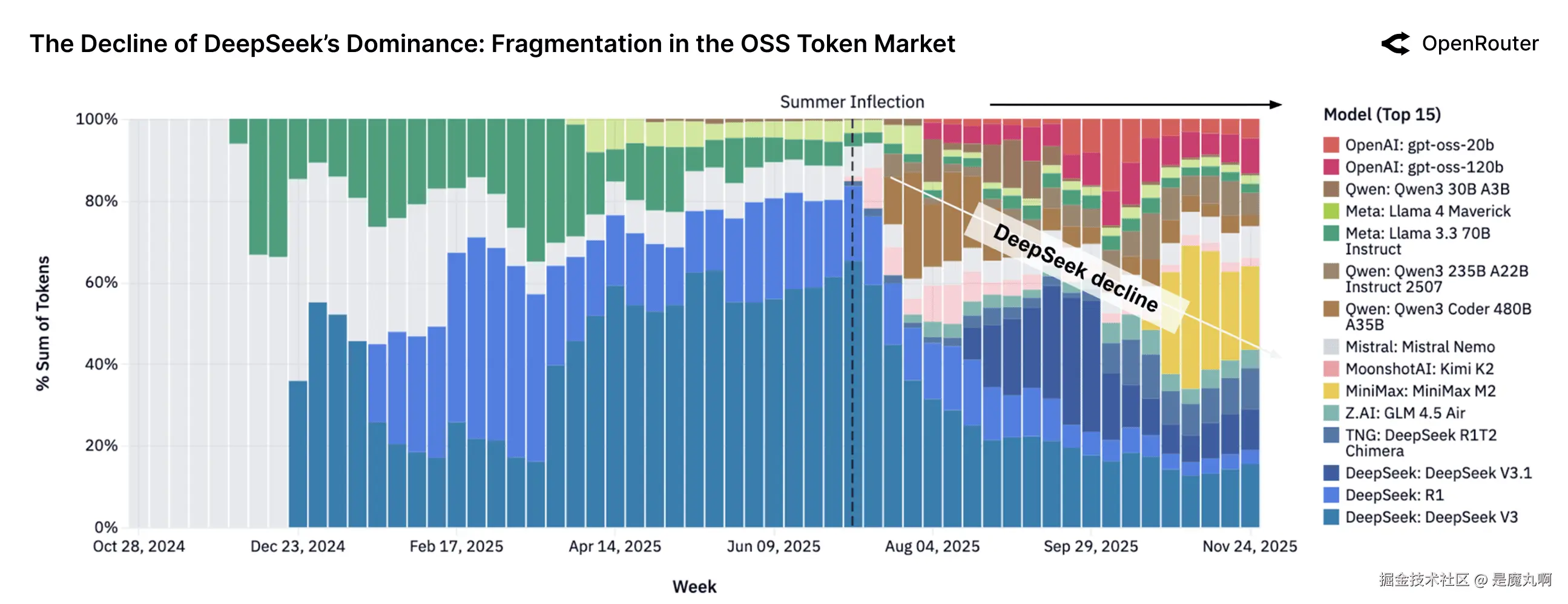
15个顶级OSS模型随时间变化。 领先开源模型的周相对token份额(堆叠面积图)。每个彩色带代表一个模型对总OSS token的贡献。随时间增长的调色板表明没有单一主导模型的更具竞争力的分布。
这个图表说明了顶级个体开源模型市场份额的戏剧性演变。在早期(2024年底),市场高度整合:来自DeepSeek家族的两个模型(V3和R1)始终占所有OSS token使用的一半以上,形成图表底部的大深蓝色带。
这种近乎垄断的结构在夏季转折点(2025年中期)后破碎。市场此后变得更广泛和更深,使用显著多样化。像Qwen的模型、Minimax的M2、MoonshotAI的Kimi K2和OpenAI的GPT-OSS系列等新进入者都快速增长以服务大部分请求,通常在发布后数周内实现生产规模的采用。这表明开源社区和AI初创公司可以通过引入具有新颖能力或卓越效率的模型来实现快速采用。
到2025年底,竞争平衡已经从近乎垄断转向多元化混合。没有单一模型超过OSS token的25%,token份额现在分布在5-7个模型中更均匀。实际含义是用户在更广泛的选项中找到价值,而不是默认为一个"最佳"选择。虽然这个图表可视化OSS模型之间的相对份额(不是绝对数量),但明显的趋势是市场向碎片化和开源生态系统内竞争加剧的决定性转变。
总的来说,开源模型生态系统现在高度动态。 关键见解包括:
- 顶级多样性: 曾经一个家族(DeepSeek)主导OSS使用的地方,我们现在越来越多看到半个模型每个都有有意义的份额。没有单一开源模型持续保持超过≈20-25%的OSS token。
- 新进入者的快速扩展: 有能力的新开源模型可以在数周内捕获重要使用。例如,MoonshotAI的模型迅速增长以挑战较老的OSS领导者,即使是像MiniMax这样的新来者也在一个季度内从零增长到大量流量。这表明切换摩擦低,用户群渴望实验。
- 迭代优势: DeepSeek在顶级长期存在的存在突显了持续改进至关重要。DeepSeek的连续发布(Chat-V3、R1等)即使在挑战者出现时也使其保持竞争力。停滞开发的OSS模型往往会失去份额给那些在前沿频繁更新或特定领域微调的模型。
今天2025年的开源LLM领域 resembles 一个竞争生态系统,创新周期快速,领导地位不保证。对于模型构建者来说,这意味着发布具有最先进性能的开源模型可以产生立即的采用,但保持使用份额需要进一步开发的持续投资。对于用户和应用程序开发者来说,趋势是积极的:有更丰富的开源模型可供选择,有时在特定领域(如角色扮演)具有可比或有时优于专有系统的能力。
模型大小vs市场契合度:中等是新的小
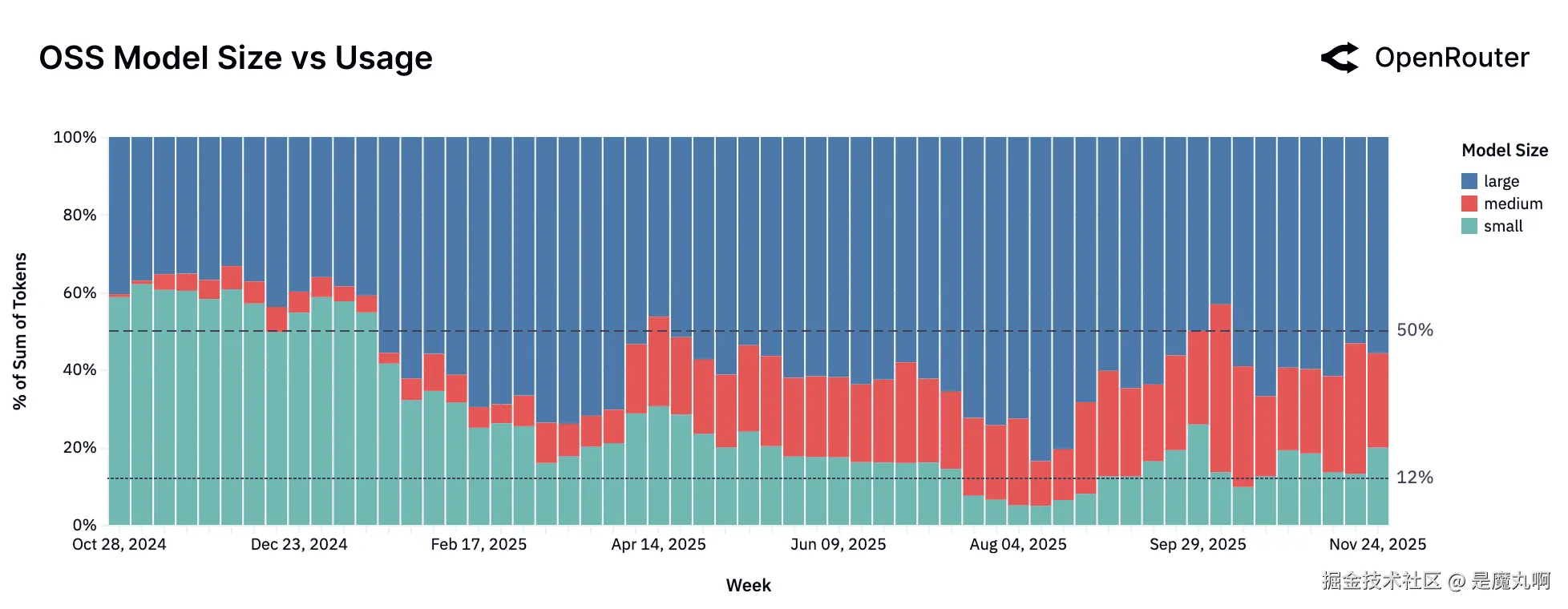
OSS模型大小vs使用。 小型、中型和大型模型服务的总OSS token数量周份额。百分比按每周总OSS使用标准化。
一年前,开源模型生态系统主要是两个极端之间的权衡故事:大量小型、快速模型和少数强大的大规模模型。然而,回顾过去一年 reveals 市场的显著成熟和一个新的、不断增长的类别的出现:中等规模的模型。请注意,我们按参数数量对模型进行如下分类:
- 小型: 参数少于150亿的模型。
- 中型: 150亿到700亿参数之间的模型。
- 大型: 700亿或更多参数的模型。
开发者和用户行为的数据告诉我们一个微妙的故事。图表显示,虽然所有类别的_模型数量_都有所增长,但_使用_已经发生了显著变化。小型模型正在失宠,而中型和大型模型正在获取那种价值。
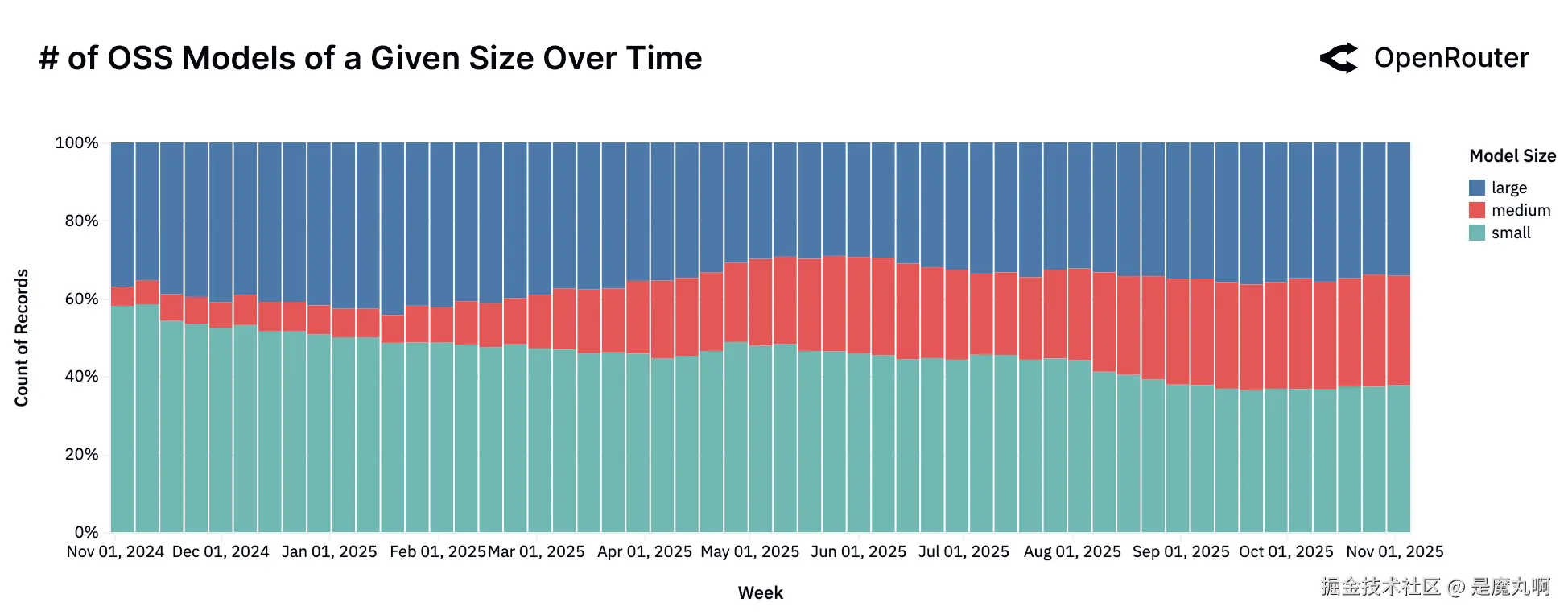
按大小划分的OSS模型数量随时间变化。 按参数大小类别分组的可用开源模型周计数。
更深入地研究推动这些趋势的模型 reveals 了不同的市场动态:
- "小型"市场:整体使用下降。 尽管有稳定的新模型供应,但整个小型模型类别的使用份额正在下降。这个类别的特点是高度碎片化。没有单一模型能长期保持主导地位,并且看到来自Meta、Google、Mistral和DeepSeek等多元化提供商的新进入者的持续更替。例如,
Google Gemma 3.12B(2025年8月发布)看到快速采用,但在拥挤的领域竞争,用户不断寻求下一个最佳替代品。 - "中型"市场:找到"模型-市场契合"。 中型模型类别清楚地讲述了市场创造的故事。这个细分本身在2024年11月
Qwen2.5 Coder 32B发布之前可以忽略不计,这实际上建立了这个类别。然后这个细分随着其他强有力的竞争者如Mistral Small 3(2025年1月)和GPT-OSS 20B(2025年8月)的到来而成熟为竞争生态系统,它们占据了用户心智份额。这个细分表明用户正在寻求能力和效率之间的平衡。 - "大型"模型细分:多元化景观。 "向质量飞奔"没有导致整合而是多元化。大型模型类别现在具有一系列高性能竞争者,从
Qwen3 235B A22B Instruct(2025年7月发布)和Z.AI GLM 4.5 Air到OpenAI: GPT-OSS-120B(8月5日):每个都捕获了有意义和持续的使用。这种多元化表明用户正在积极跨多个开源大型模型进行基准测试,而不是收敛于单一标准。
小型模型主导开源生态系统的时代可能已经过去。市场现在正在分化,用户要么倾向于新的、稳健的中型模型类别,要么将工作负载整合到最 capable 的大型模型上。
开源模型用于什么?
今天的开源模型用于非常广泛的任务范围,跨越创意、技术和信息领域。虽然专有模型仍然在结构化业务任务中占主导地位,但OSS模型在两个特定领域 carved out 了领导地位:创意角色扮演__和__编程辅助。这些类别合计占OSS token使用的大部分。
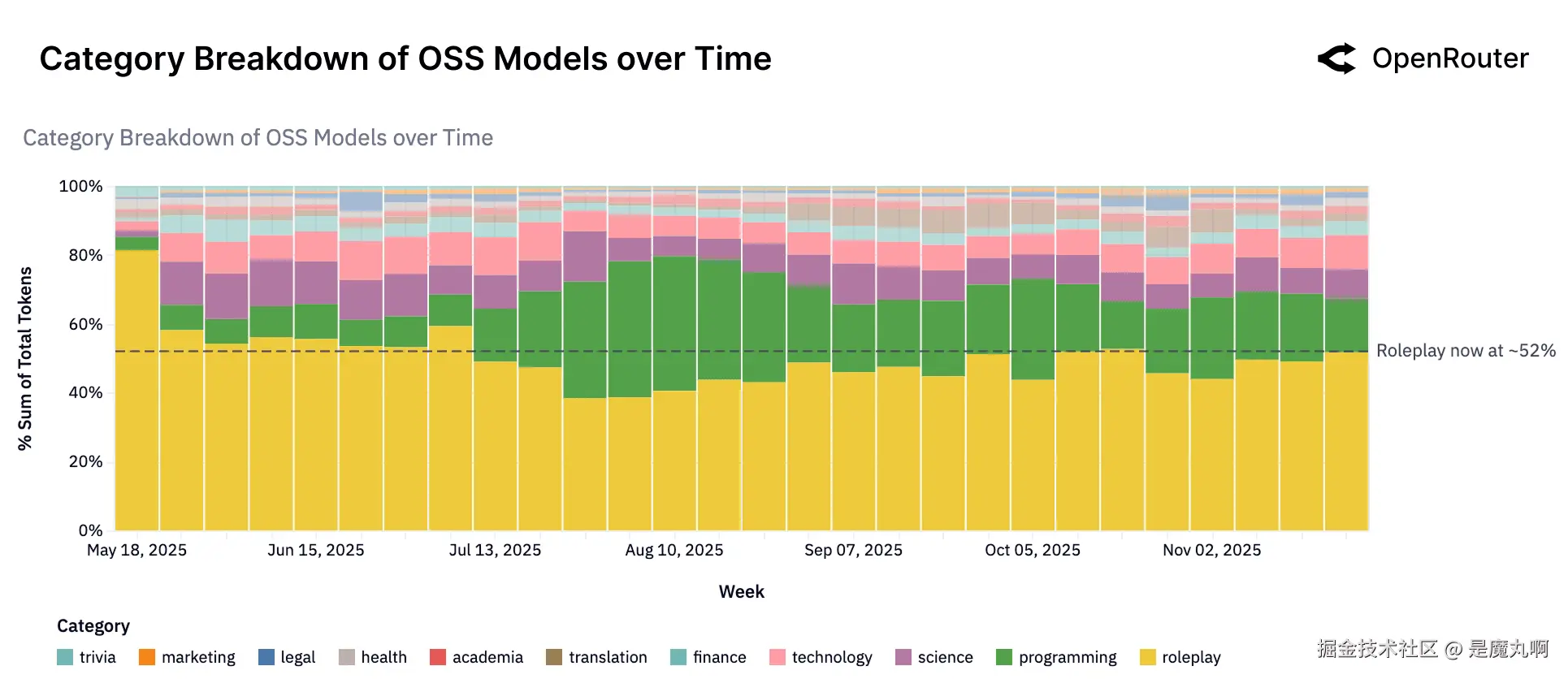
OSS模型的类别趋势。 开源模型使用在高级任务类别中的分布。角色扮演(约52%)和编程始终主导OSS工作负载组合,合计占大多数OSS token。较小部分包括翻译、通用知识问答和其他。
上图突显了超过一半的所有OSS模型使用属于_角色扮演_,_编程_是第二大类别。这表明用户转向开源模型主要用于创意互动对话(如讲故事、角色扮演和游戏场景)和编码相关任务。角色扮演的主导地位(徘徊在所有OSS token的50%以上) underscored 了一个开源模型具有优势的使用案例:它们可以用于创造力,通常较少受到内容过滤器的约束,使其对幻想或娱乐应用有吸引力。角色扮演任务需要灵活的响应、上下文保留和情感细微差别 - 开源模型可以在不受到商业安全或审核层严重限制的情况下有效交付的属性。这使得它们对尝试角色驱动体验、同人小说、互动游戏和模拟环境的社区特别有吸引力。
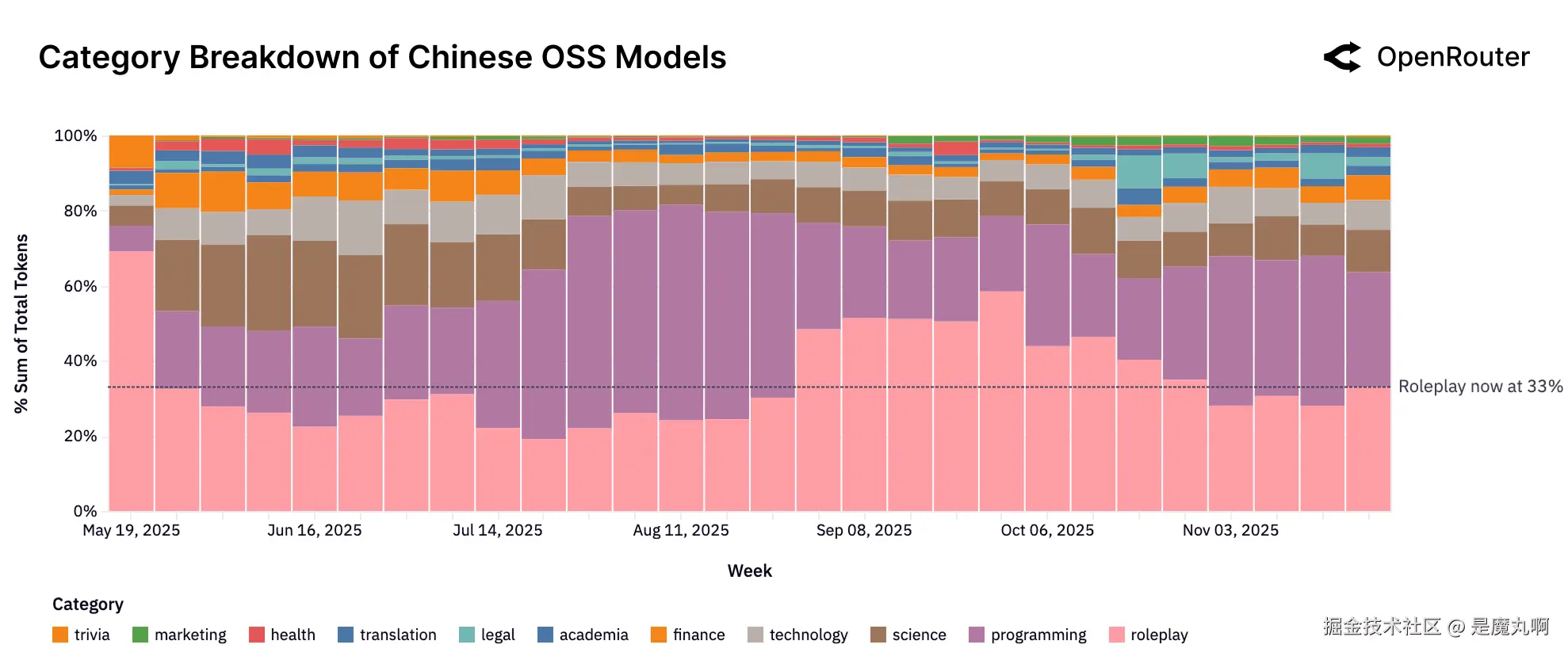
中国OSS类别趋势。 在中国开发的开源模型中的类别组成。角色扮演仍然是最大的使用案例,虽然编程和技术集体在这里占更大的比例(33%对比38%)。
上图如果我们只关注中国OSS模型,显示类别细分随时间变化。这些模型不再主要用于创意任务。角色扮演仍然是约33%的最大类别,但编程和技术现在合计占使用的大部分(39%)。这种转变表明像Qwen和DeepSeek这样的模型越来越多地用于代码生成和基础设施相关工作负载。虽然高容量企业用户可能影响特定细分,但总体趋势指向中国OSS模型在技术和生产力领域直接竞争。
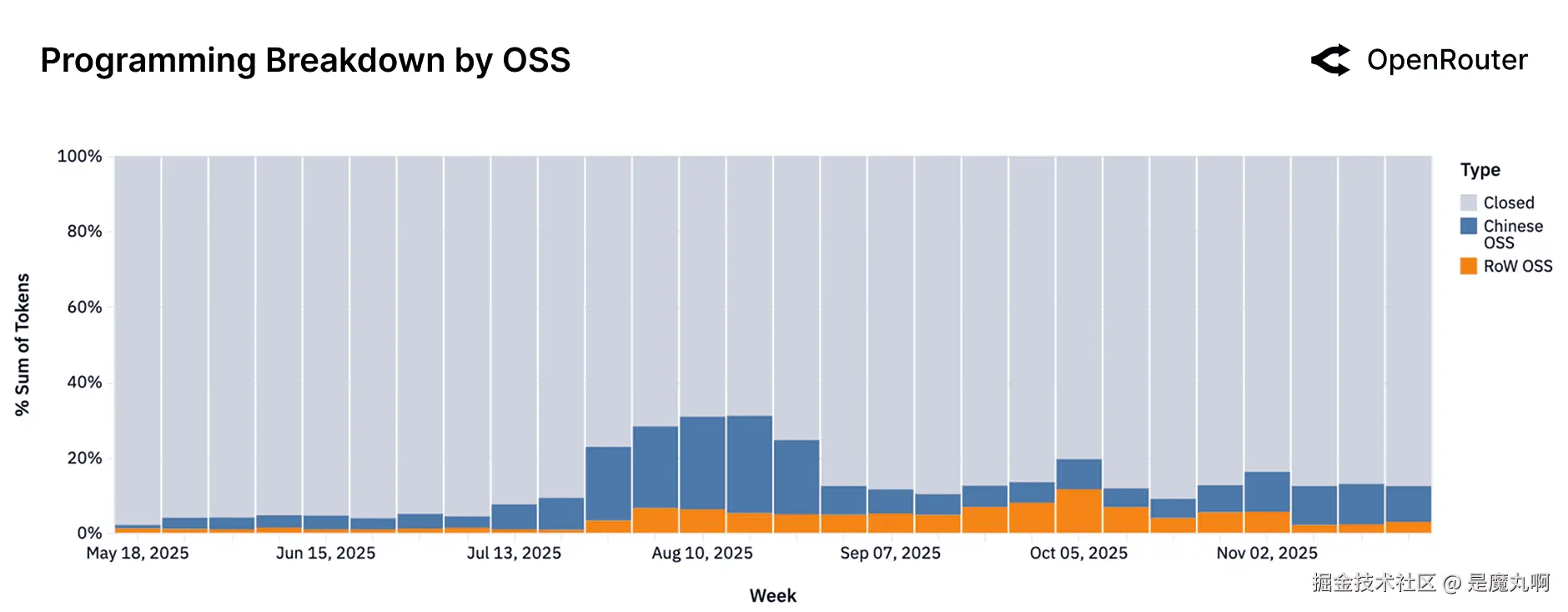
按模型来源的编程查询。 专有模型vs中国OSSvs非中国(RoW)OSS模型处理的编程相关token数量份额。在OSS细分内,平衡在2025年底明显转向RoW OSS,现在占所有开源编码token的一半以上(在早期中国OSS主导OSS编码使用的时期之后)。
如果我们只关注编程类别,我们观察到专有模型仍然处理编码辅助的大部分(灰色区域),反映了像Anthropic的Claude这样的强大产品。然而,在OSS部分,有一个显著的转变:在2025年中期,中国OSS模型(蓝色)提供了大部分开源编码帮助(由像Qwen 3 Coder这样的早期成功驱动)。到2025年第四季度,西方OSS模型(橙色)如Meta的LLaMA-2 Code和OpenAI的GPT-OSS系列激增,但在最近几周总体份额下降。这种振荡表明竞争非常激烈。实际要点是开源编码助手使用是动态的,对新的模型质量高度响应:开发者对哪个OSS模型目前提供最佳编码支持持开放态度。作为一个限制,这个图表没有显示绝对数量:开源编码使用整体增长所以缩小的蓝色带不意味着中国OSS失去了用户,只是相对份额。
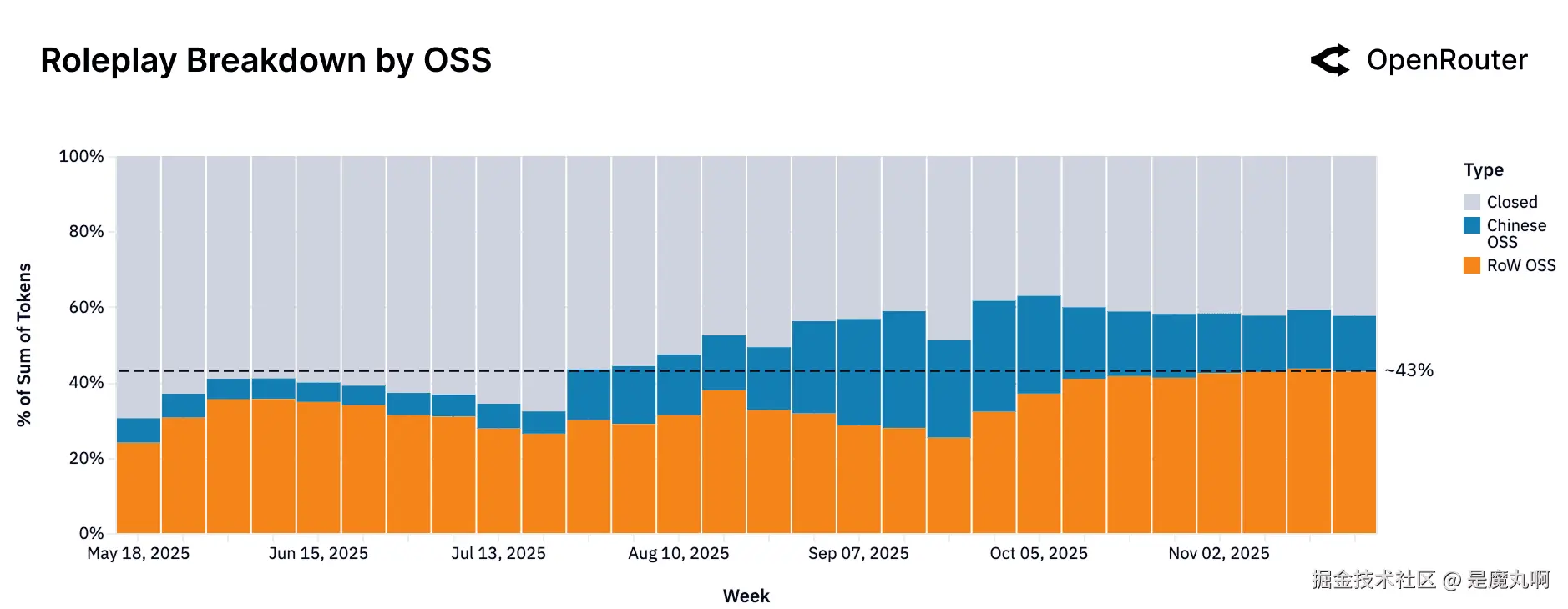
按模型来源的角色扮演查询。 角色扮演使用案例的token数量,在中国OSS和RoW OSS模型之间划分。角色扮演仍然是两个群体的最大类别;到2025年底,流量在中国和非中国开源模型之间大致平分。
现在如果我们只看角色扮演流量,我们看到它现在几乎由世界其他地区OSS(橙色,最近几周43%)和闭源(灰色,最近约42%)模型平等服务。这代表了从2025年早期的显著转变,当时该类别由专有(灰色)模型主导,持有约70%的token份额。那时(2025年5月),西方OSS模型仅占流量的约22%,中国OSS(蓝色)模型持有小份额的8%。全年中,专有份额稳步下降。到2025年10月底,随着西方和中国开源模型都获得重要进展,这种趋势加速了。
由此产生的收敛表明健康的竞争;用户从开源和专有产品中都有可行的选择用于创意聊天和讲故事。这反映了开发者认识到对角色扮演/聊天模型的需求并相应地调整他们的发布(例如,在对话上微调,为角色一致性添加对齐)。需要注意的是,"角色扮演"涵盖了子类型范围(从休闲聊天到复杂游戏场景)。然而从宏观角度来看,很明显OSS模型在这个创意领域有优势。
解释。 广泛地说,跨OSS生态系统,关键使用案例是:角色扮演和创意对话: 顶级类别,可能因为开源模型可以未审查或更容易定制为虚构人格和故事任务。编程辅助: 第二大,并且增长中,随着开源模型在代码方面变得更胜任。许多开发者在本地利用OSS模型进行编码以避免API成本。翻译和多语言支持: 稳定的使用案例,特别是有强大的双语模型可用(中国OSS模型在这里有优势)。通用知识问答和教育: 适度使用;虽然开源模型可以回答问题,但用户可能更喜欢像GPT-5这样的闭源模型以获得最高事实准确性。
值得注意的是OSS使用模式(侧重于角色扮演)镜像 了许多人可能认为的"爱好者"或"独立开发者" - 定制化和成本效率胜过绝对准确性的领域。然而,界限正在模糊;OSS模型在技术领域迅速改进,专有模型也被创意使用。
代理推理的兴起
基于前一部分对不断演变的模型景观(开源vs闭源)的视图,我们现在转向LLM使用本身的根本_形状_。语言模型在生产中如何使用正在发生根本性转变:从单轮文本完成转向多步骤、工具集成和推理密集的工作流程。我们将这种转变称为__代理推理__的兴起,其中模型部署不仅仅是生成文本,而是通过规划、调用工具或跨扩展上下文交互来行动。本节通过五个代理追踪这种转变:推理模型的兴起、工具调用行为的扩展、序列长度概况的变化,以及编程使用如何驱动复杂性。
推理模型现在代表所有使用的一半
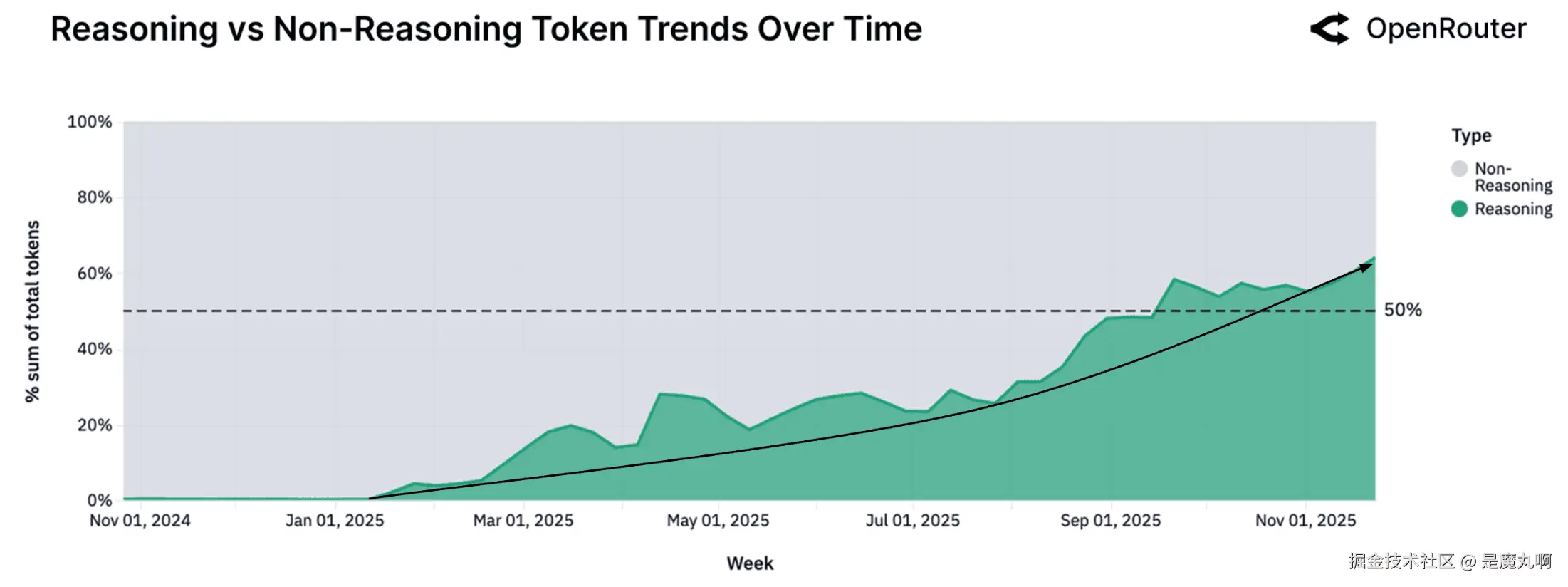
推理vs非推理Token趋势。 自2025年初以来,通过推理优化模型路由的所有token份额稳步上升。该指标反映由推理模型服务的所有token的比例,_不是_模型输出中"推理token"的份额。
如上图所示,通过推理优化模型路由的总token份额在2025年急剧攀升。在第一季度早期实际上是微不足道的使用份额现在超过50%。这种转变反映了市场的两面。在供应方面,更高能力系统如GPT-5、Claude 4.5和Gemini 3的发布扩展了用户对逐步推理的期望。在需求方面,用户越来越偏好能够管理任务状态、遵循多步骤逻辑和支持代理风格工作流程的模型,而不仅仅是生成文本。
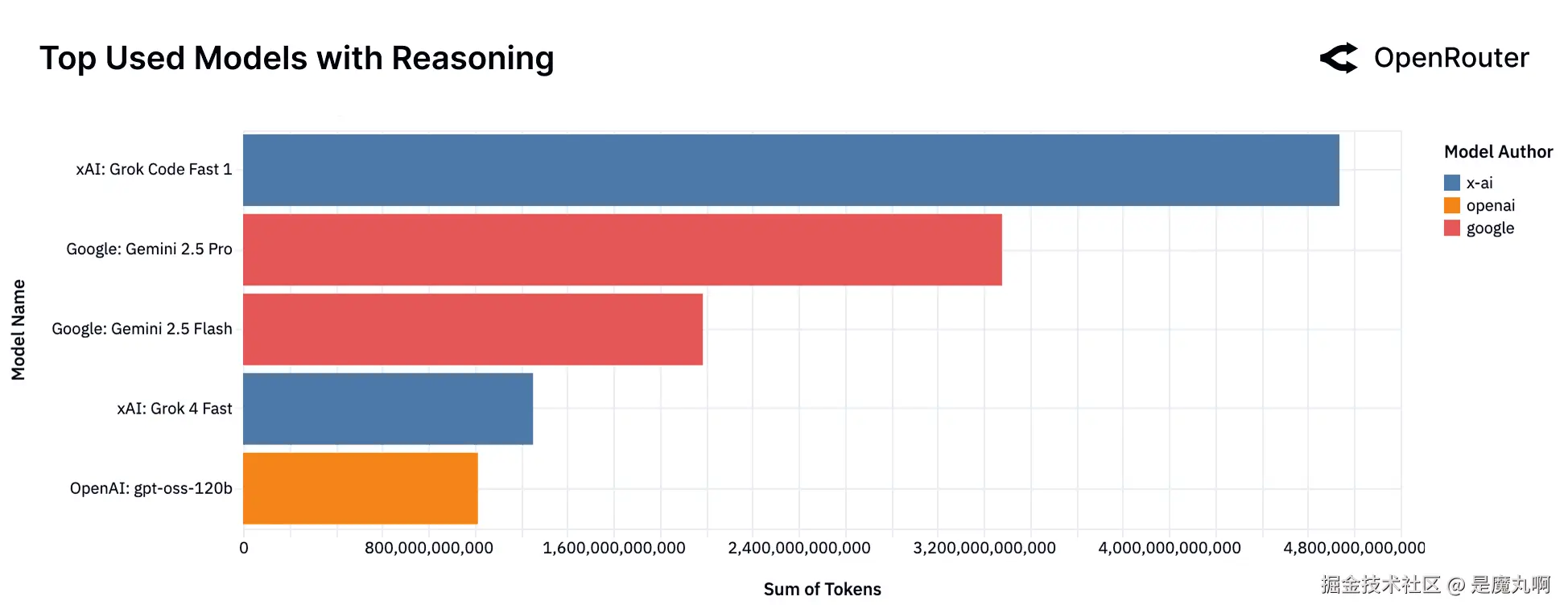
按Token数量排名的顶级推理模型。 在推理模型中,xAI的Grok Code Fast 1目前处理最大份额的推理相关token流量,其次是Google的Gemini 2.5 Pro和Gemini 2.5 Flash。xAI的Grok 4 Fast和OpenAI的gpt-oss-120b完成顶级群体。
上图显示了推动这种转变的顶级模型。在最新数据中,xAI的Grok Code Fast 1现在驱动推理流量的最大份额(排除免费发布访问),领先于Google的Gemini 2.5 Pro和Gemini 2.5 Flash。这与几周前相比是显著变化,当时Gemini 2.5 Pro主导该类别,DeepSeek R1和Qwen3也在顶级梯队。Grok Code Fast 1和Grok 4 Fast在xAI的积极推出、竞争性定价和开发者对其面向代码变体的关注支持下快速获得份额。同时,像OpenAI的gpt-oss-120b这样的开源模型的持续存在 underscored 开发者在可能时仍然触及OSS。整体组合突显了推理景观变得多么动态,快速模型更迭正在塑造哪些系统主导实际工作负载。
数据指向一个明确的结论:面向推理的模型正在成为实际工作负载的默认路径,流经它们的token份额现在是用户希望如何与AI系统交互的领先指标。
工具调用采用的兴起
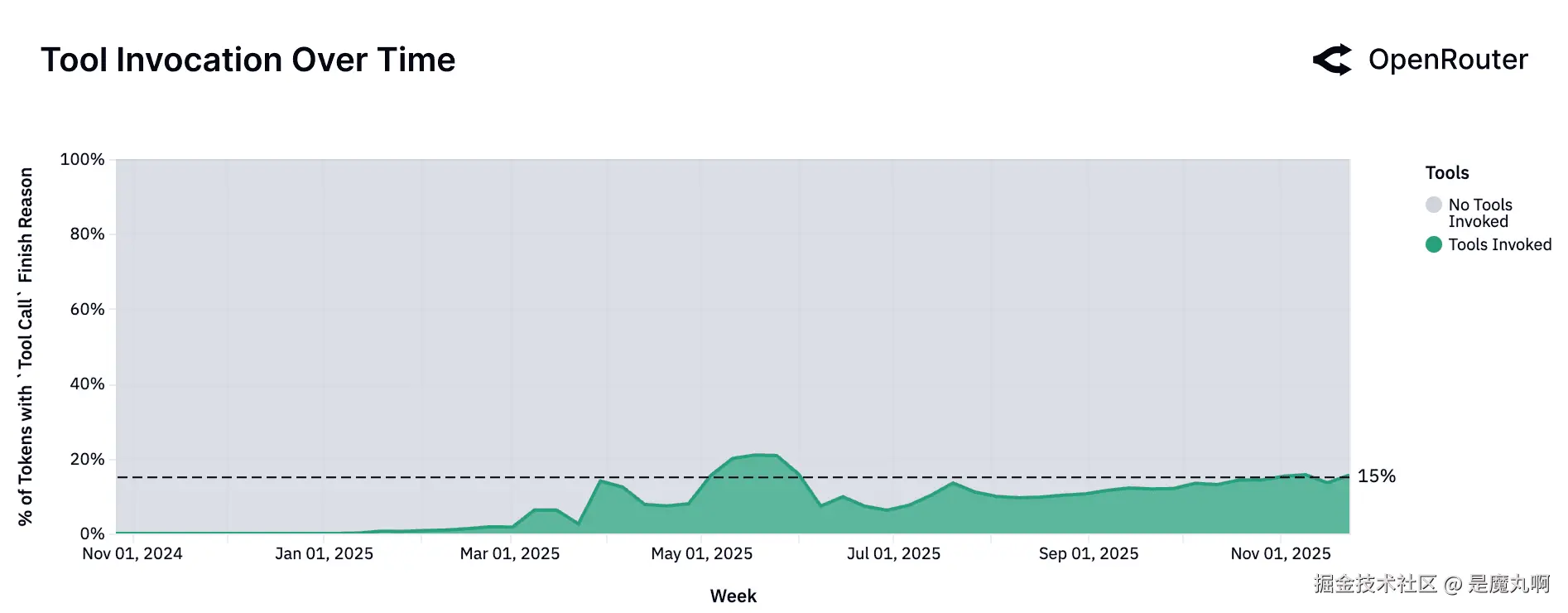
工具调用。 总token份额标准化为完成原因被分类为_工具调用_的请求,意味着在请求期间实际调用了工具。该指标反映成功的工具调用调用;包含工具定义的请求按比例更高。
上图中,我们报告完成原因是_工具调用_的请求产生的总token份额。该指标被标准化,仅捕获实际调用工具的那些交互。
这与_输入工具_信号形成对比,后者记录在请求期间是否向模型提供了工具(无论是否调用)。输入工具计数,根据定义,高于工具调用完成原因,因为提供是成功执行的超集。而完成原因指标测量实现工具使用,输入工具反映潜在可用性而非实际调用。因为这个指标仅在2025年9月引入,我们未在本报告中报告它。
上图中5月的明显峰值主要归因于一个大型账户的活动,该活动短暂提升了总体数量。除了这个异常,工具采用全年显示了持续上升趋势。
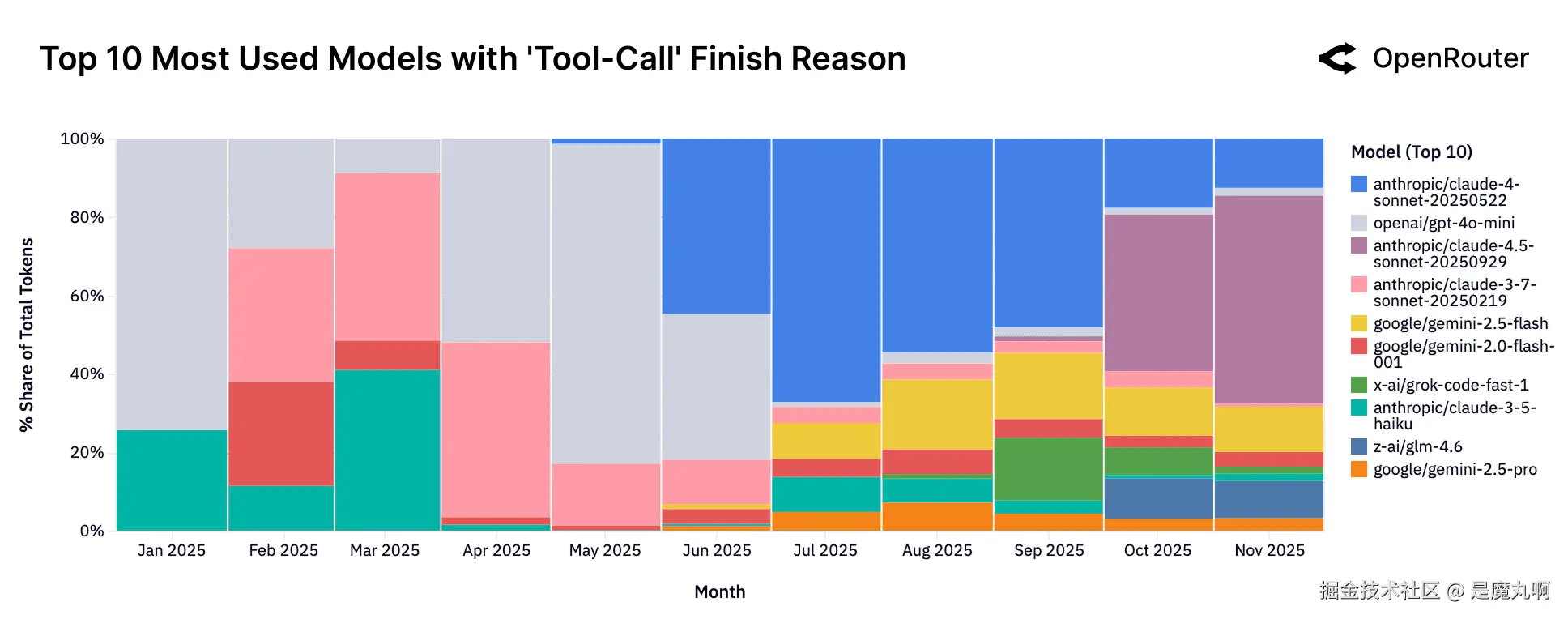
按提供工具数量排名的顶级模型。 工具提供集中在明确优化代理推理的模型中,如Claude Sonnet、Gemini Flash。
如上图所示,工具调用最初集中在少数模型群体中:OpenAI的gpt-4o-mini和Anthropic的Claude 3.5和3.7系列,它们在2025年早期占大多数启用工具的token。然而到年中,更广泛的模型群体开始支持工具提供,反映了更具竞争性和多元化的生态系统。从9月底开始,较新的Claude 4.5 Sonnet模型快速获得份额。同时,像Grok Code Fast和GLM 4.5这样的新进入者取得了可见进展,反映了工具能力部署的更广泛实验和多样化。
对于运营商来说,含义很明确:为高价值工作流程启用工具使用正在兴起。没有可靠工具格式的模型在企业采用和编排环境中面临落后风险。
提示-完成形状的分析
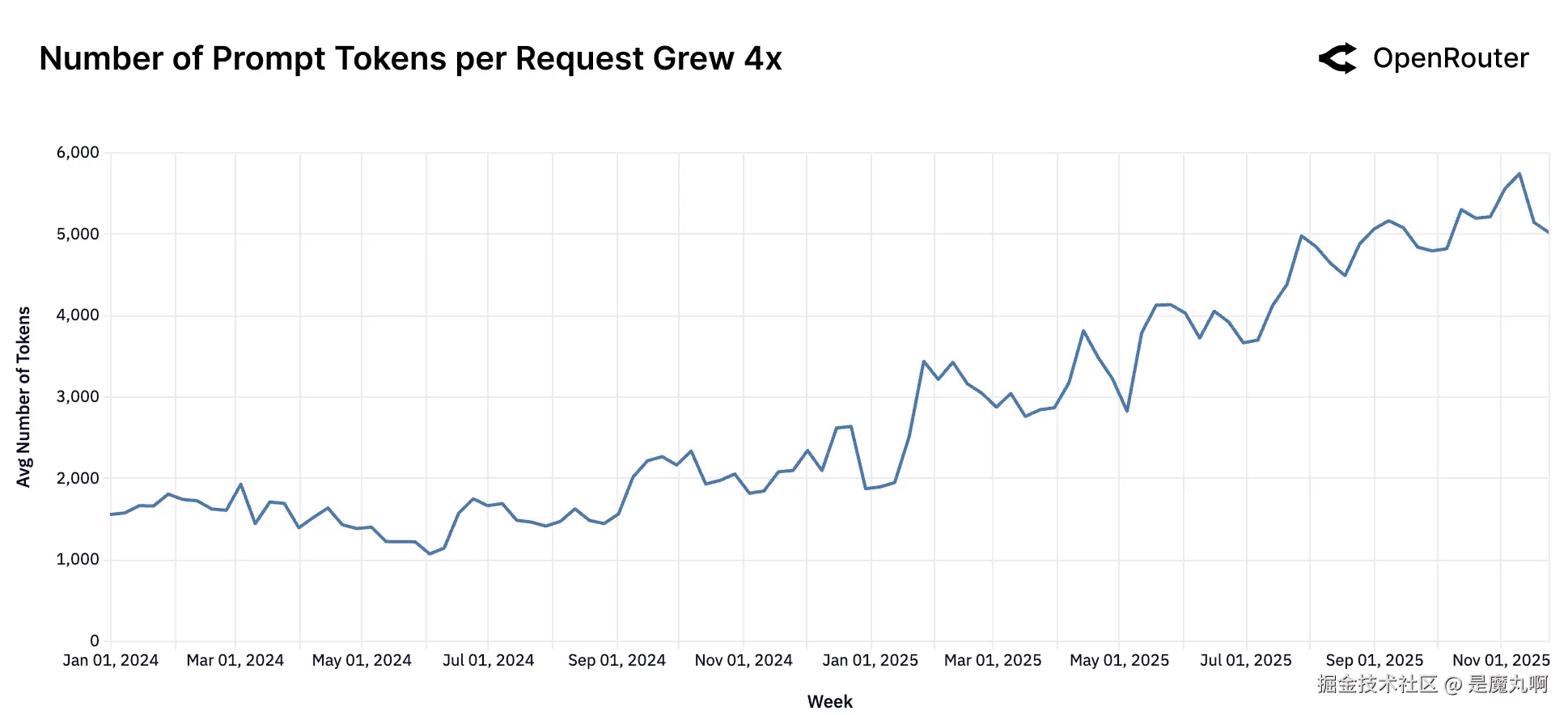
提示Token数量正在上升。 平均提示token长度自2024年初以来增长了近四倍,反映了日益上下文繁重的工作负载。
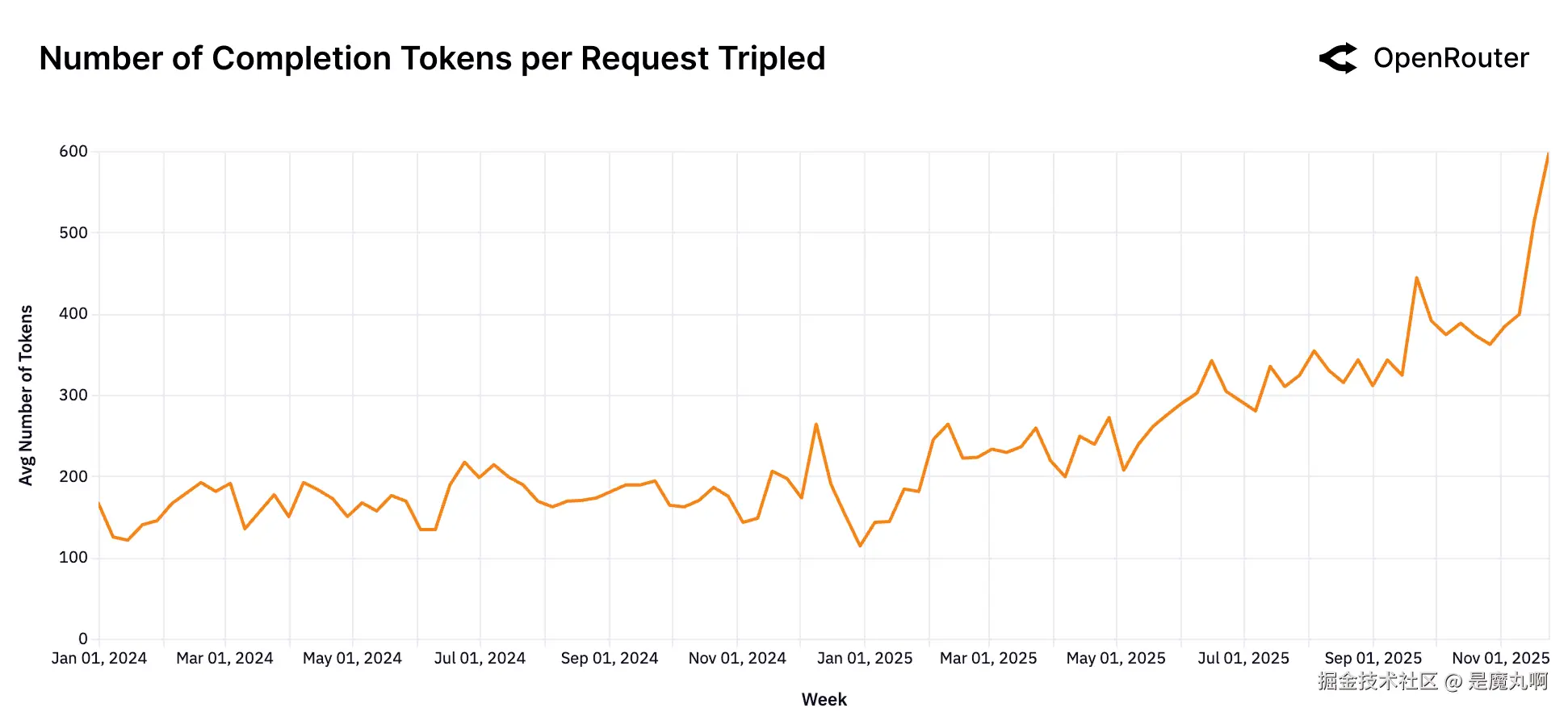
完成Token数量几乎翻倍。 输出长度也有所增加,虽然从较小的基数,表明更丰富、更详细的响应,主要由于推理token。
模型工作负载的形状在过去一年中发生了显著演变。提示(输入)和完成(输出)token数量都急剧增长,尽管规模和速率不同。每个请求的平均提示token大约增长了四倍,从约1.5K增长到超过6K,而完成token几乎翻了三倍,从约150增长到400。增长的相对数量级 highlight 了向更复杂、上下文丰富工作负载的决定性转变。
这种模式反映了模型使用的新平衡。今天的典型请求较少关于开放式生成("给我写一篇文章"),更多关于对大量用户提供材料(如代码库、文档、转录或长对话)进行推理,并产生简洁、高价值的洞察。模型越来越多地充当分析引擎而非创意生成器。
类别级数据(仅从2025年春季可用)提供了更细致的图景:编程工作负载是提示token增长的主要驱动力。涉及代码理解、调试和代码生成的请求通常超过20K输入token,而所有其他类别保持相对平坦和低容量。这种不对称贡献表明最近提示大小的扩展不是跨任务的统一趋势,而是与软件开发和技术推理使用案例相关的集中激增。
更长序列,更复杂交互
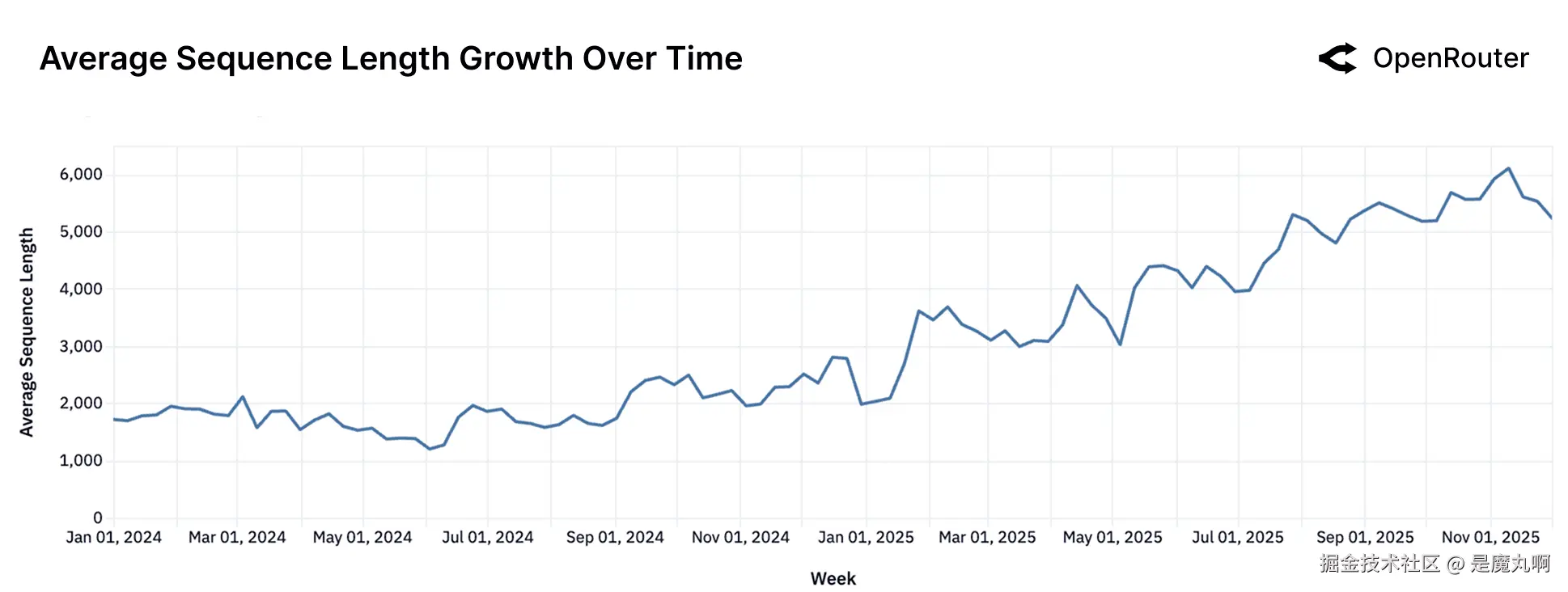
随时间变化的平均序列长度。 每次生成(提示+完成)的平均token数量。
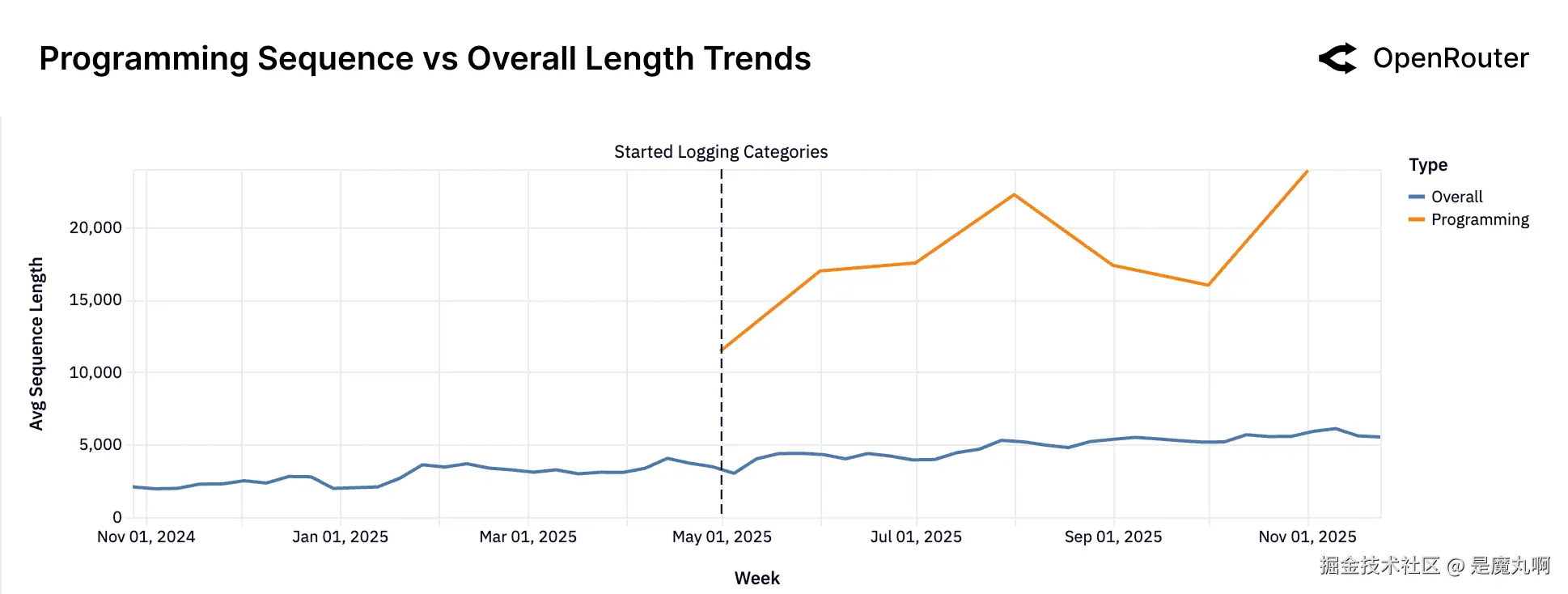
编程vs整体序列长度。 编程提示系统性地更长并且增长更快。
序列长度是任务复杂性和交互深度的代理。上图显示平均序列长度在过去20个月中增长了三倍多,从2023年底的不到2000个token增长到2025年底的超过5400个。这种增长反映了向更长上下文窗口、更深任务历史和更精细完成的结构性转变。
根据前一部分,第二个图表进一步阐明了:编程相关提示现在平均是通用提示长度的3-4倍。分歧表明软件开发工作流程是较长交互的主要驱动力。长序列不仅仅是用户的冗长:它们是嵌入式、更复杂的代理工作流程的签名。
含义:代理推理是新默认
总之,这些趋势(推理份额上升、工具使用扩展、序列更长以及编程的过大复杂性)表明LLM使用的重心已经转变。中位数LLM请求不再是简单问题或孤立指令。相反,它是结构化的、类似代理的循环的一部分,调用外部工具、对状态推理,并在更长上下文中持续。
对于模型提供商,这提高了默认能力的标准。延迟、工具处理、上下文支持和对畸形或对抗性工具链的鲁棒性变得越来越关键。对于基础设施运营商,推理平台现在必须管理不仅无状态请求,还有长期对话、执行跟踪和权限敏感的工具集成。很快,如果还没有,代理推理将接管大多数推理。
应用类别:人们如何使用LLM?
理解用户用LLM执行的任务分布对于评估真实世界需求和_模型-市场契合度_至关重要。如数据和方法论部分所述,我们将数十亿个模型交互分类为高级应用类别。在开源与闭源模型部分,我们专注于开源模型以观察社区驱动的使用。这里,我们将视角扩大到OpenRouter上_所有_LLM使用(闭源和开源模型),以获得人们对LLM在实践中用途的全面图景。
主导类别
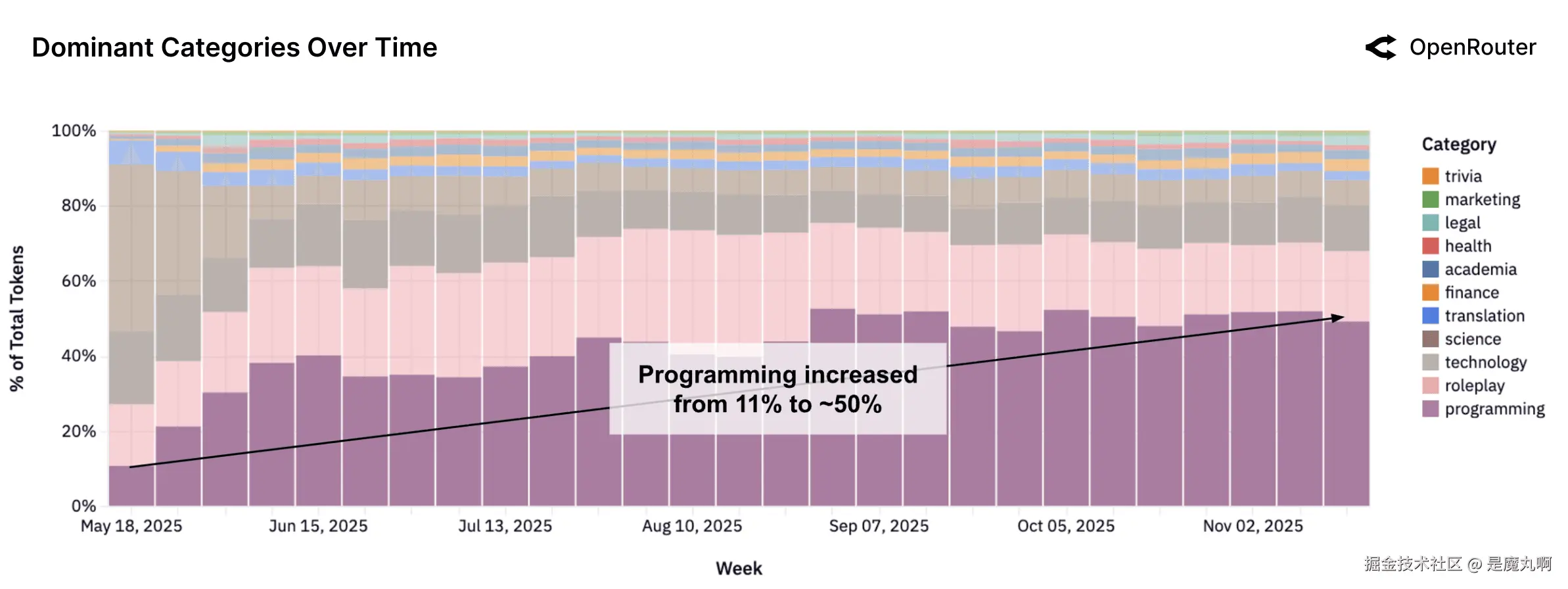
编程作为主导和增长类别。 被分类为编程的所有LLM查询份额稳步增长,反映了AI辅助开发工作流程的兴起。
编程已经成为所有模型中最持续扩展的类别。编程相关请求的份额在2025年稳步增长,与LLM辅助开发环境和工具集成的兴起平行。如上图所示,编程查询在2025年初约占总token数量的11%,在最近几周超过50%。这种趋势反映了从探索性或对话使用向应用任务如代码生成、调试和数据脚本编写的转变。随着LLM嵌入开发者工作流程,它们作为编程工具的角色正在正常化。这种演变对模型开发有影响,包括增加对代码中心训练数据的重视,改进多步骤编程任务的推理深度,以及模型与集成开发环境之间更紧密的反馈循环。
这种对编程支持需求的增长正在重塑模型提供商之间的竞争动态。如下图所示,Anthropic的Claude系列始终主导该类别,在观察期间的大多数时间占编程相关支出的60%以上。然而,景观已经发生了有意义的变化。在11月17日的一周,Anthropic的份额首次降至60%以下。自7月以来,OpenAI已将其份额从约2%扩大到最近几周的约8%,可能反映了对开发者中心工作负载的重新关注。同期,Google的份额保持稳定在约15%。中端细分市场也在变动。包括Z.AI、Qwen和Mistral AI在内的开源提供商正在稳步获得心智份额。特别是MiniMax,作为一个快速崛起的进入者出现,在最近几周显示出显著收益。
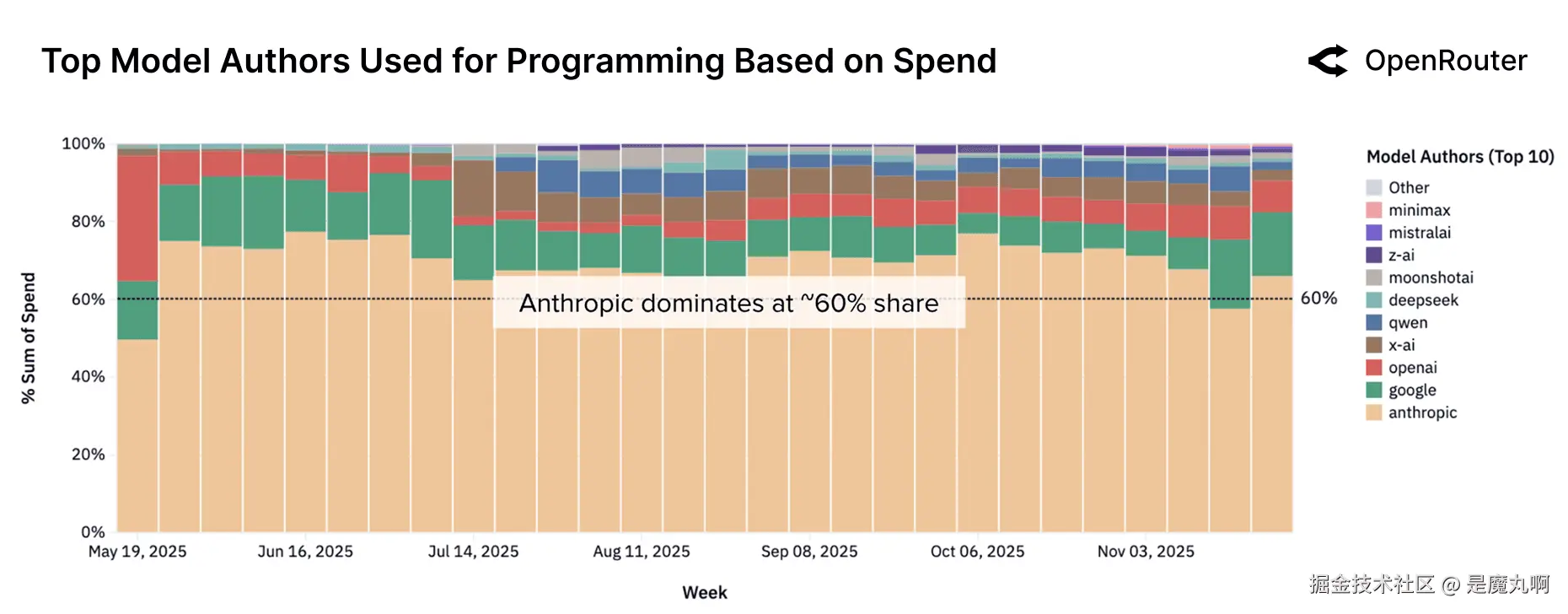
按模型提供商划分的编程请求份额。 编程工作负载高度集中:Anthropic的模型服务最大份额的编码查询,其次是OpenAI和Google,MiniMax占据不断增长的份额。其他提供商合计仅占很小部分。此图表省略了xAI,该模型有大量使用但在一段时间内免费提供。
总的来说,编程已经成为最具争议和战略重要性的模型类别之一。 它吸引了顶级实验室的持续关注,即使是模型质量或延迟的微小变化也可以每周改变份额。对于基础设施提供商和开发者来说,这突显了持续基准测试和评估的需要,特别是随着前沿不断演变。
类别内的标签组成
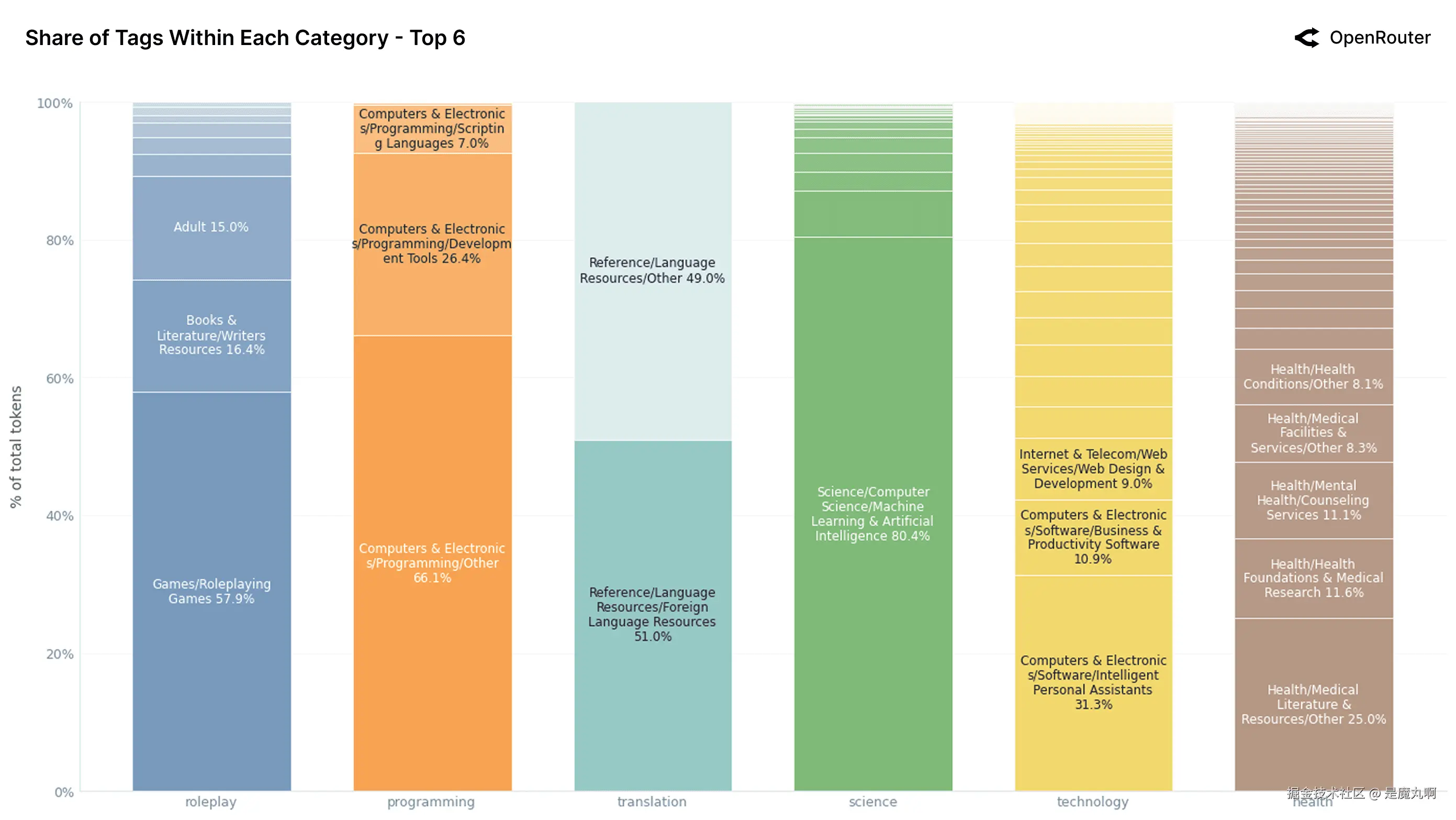
按总token份额排名的前6个类别。 每个条显示该类别内主导子标签的细分。标签指示为该类别贡献至少7% token的子标签。
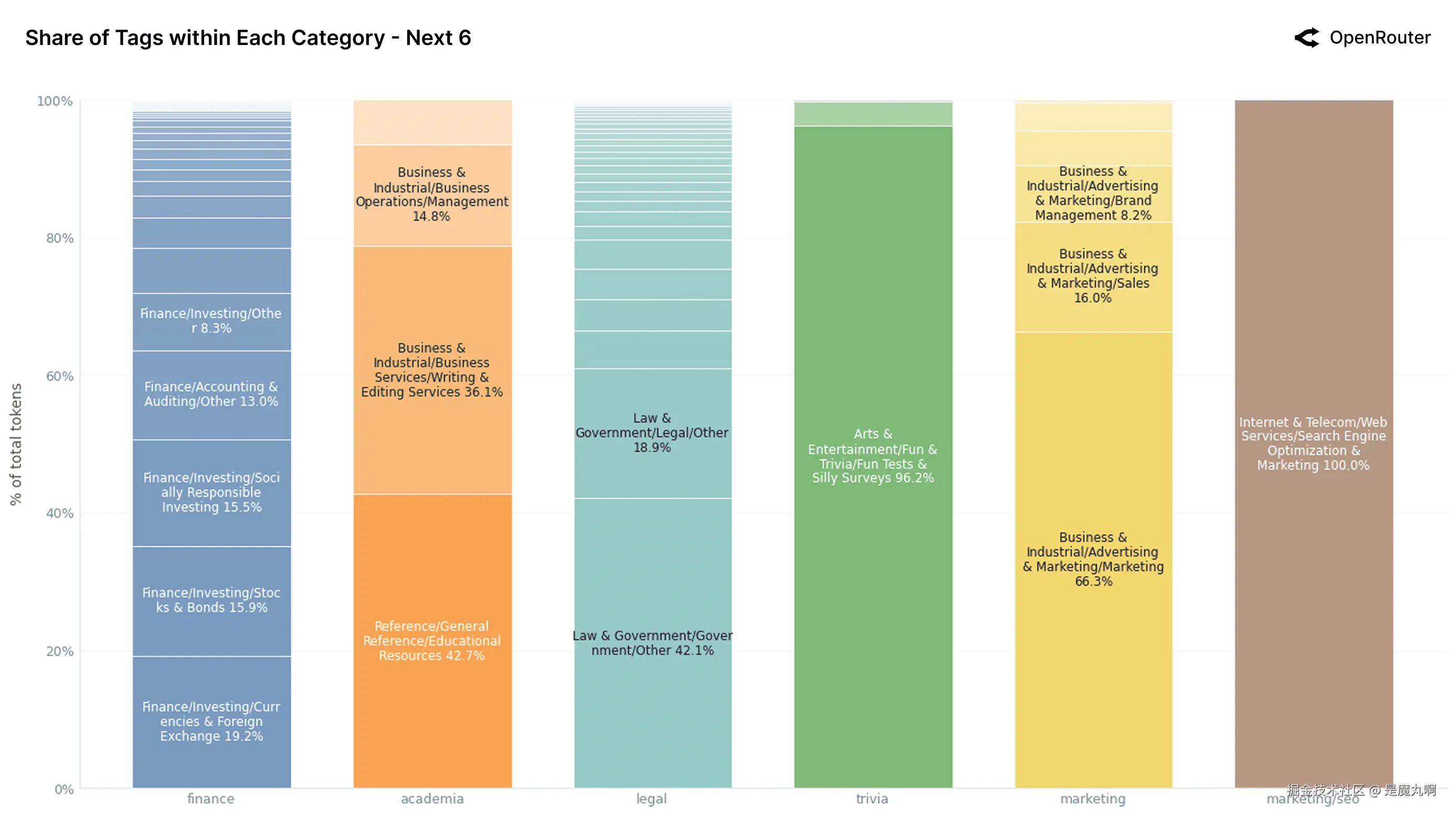
按token份额排名的接下来的6个类别。 次要类别的类似细分,说明了每个领域内的集中度(或缺乏)。
上图将LLM使用分解为十二个最常见的内容类别,揭示了每个类别的内部子主题结构。一个关键要点是大多数类别不是均匀分布的:它们由一个或两个重复的使用模式主导,往往反映集中用户意图或与LLM优势的一致性。
在最高容量的类别中,角色扮演__因其一致性和专门性而突出。近60%的角色扮演token属于_游戏/角色扮演游戏,表明用户较少将LLM视为休闲聊天机器人,更多视为结构化角色扮演或角色引擎。这进一步得到_作家资源(15.6%)和_成人内容_(15.4%)的存在强化,指向互动小说、场景生成和个人幻想的混合。与认为角色扮演主要是非正式对话的假设相反,数据显示一个定义明确和可重复的基于类型的使用案例。
_编程__同样偏向,超过三分之二的流量标记为_编程/其他 。这表明代码相关提示的广泛和通用性质:用户不专注于特定工具或语言,而是要求LLM从逻辑调试到脚本起草的一切。也就是说,开发工具(26.4%)和脚本语言的小份额表明新兴专门化。这种碎片化 highlight 了模型改进围绕结构化编程工作流程的标签或训练的机会。
除了角色扮演和编程的主导类别外,剩余域代表了LLM使用的多样化但较低容量的尾部。虽然个体较小,但它们揭示了用户如何与跨专业和新兴任务的模型交互的重要模式。例如,翻译 、_科学__和__健康__显示相对平坦的内部结构。在翻译中,使用几乎在_外语资源 (51.1%)和_其他_之间平均分配,表明分散需求:多语言查找、改写、轻量代码转换,而不是持续文档级翻译。科学由单一标签主导,机器学习与AI(80.4%),表明大多数科学查询是元AI问题而非一般的STEM主题如物理或生物。这反映了用户兴趣或模型优势偏向自我指代查询。
相比之下,健康是顶级类别中最碎片化的,没有子标签超过25%。token分布在医学研究、咨询服务、治疗指导和诊断查找中。这种多样性 highlight 了该领域的复杂性,但也显示了安全建模的挑战:LLM必须在单一使用案例中跨越高方差用户意图,通常在敏感上下文中。
将这些长尾类别联系在一起的是它们的广泛性:用户转向LLM进行探索性、轻度结构化或寻求帮助的交互,但没有在编程或个人助手中看到的专注工作流程。总而言之,这些次要类别可能不主导容量,但它们暗示了潜在需求。它们表明LLM正在许多领域的边缘使用,从翻译到医疗指导到AI内省,并且随着模型在领域鲁棒性和工具集成方面改进,我们可能看到这些分散意图收敛成更清晰、更高容量的应用。
相比之下,金融 、学术界__和__法律__更加分散。金融将其容量分布在外汇、社会责任投资和审计/会计:没有单一标签突破20%。法律显示类似的熵,使用在_政府/其他(43.0%)和_法律/其他(17.8%)之间分配。这种碎片化可能反映了这些领域的复杂性,或者仅仅缺乏针对它们的定向LLM工作流程,与编程和聊天等更成熟的类别相比。
数据表明真实世界的LLM使用不是统一探索性的:它紧密围绕一小组可重复、高容量的任务聚集。角色扮演、编程和个人协助每个都表现出清晰的结构和主导标签。科学、健康和法律领域相比之下更加分散,可能优化不足。这些内部分布可以指导模型设计、领域特定微调和应用程序级接口,特别是在将LLM定制到用户目标方面。
按类别的作者级洞察
不同模型作者被用于不同的使用模式。下图显示了主要模型家族(Anthropic的Claude、Google的模型、OpenAI的GPT系列、DeepSeek和Qwen)的内容类别分布。每个条代表该提供商token使用的100%,按顶级标签细分。
Anthropic。 主要用于编程和技术任务(超过80%),角色扮演使用最少。
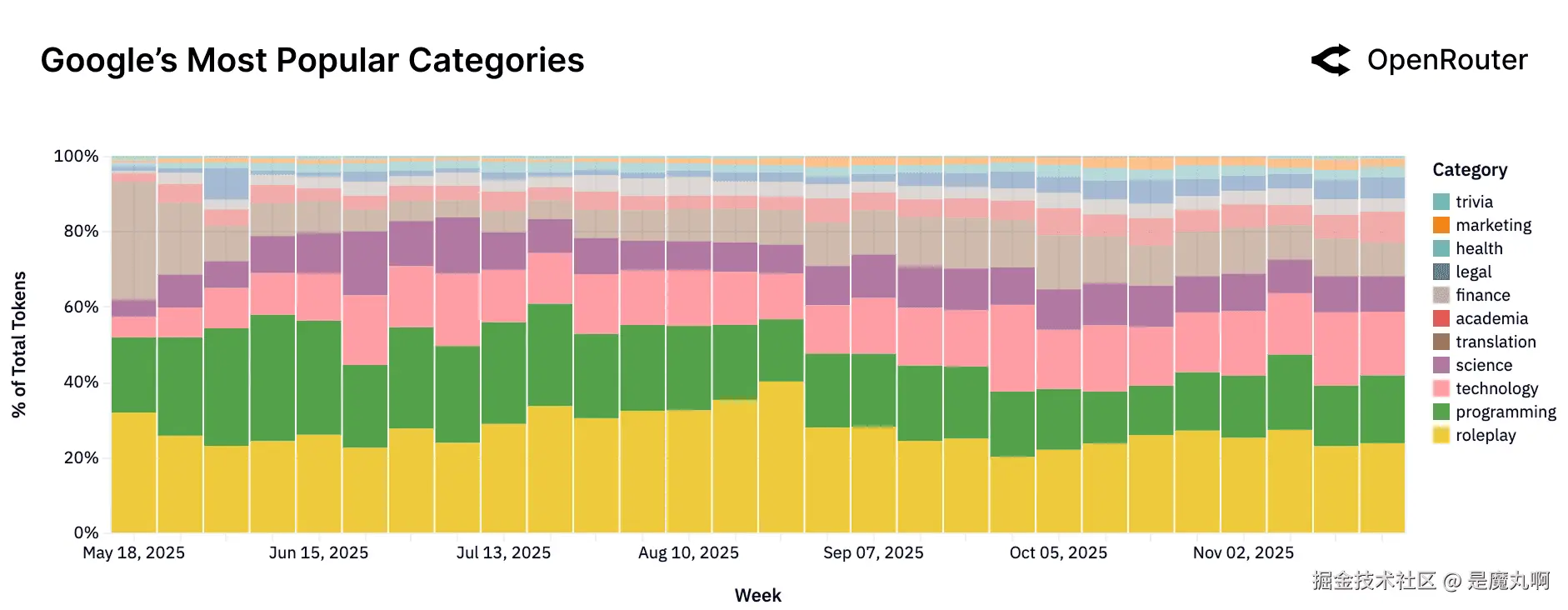
Google。 广泛使用组合,跨越法律、科学、技术和一些通用知识查询。
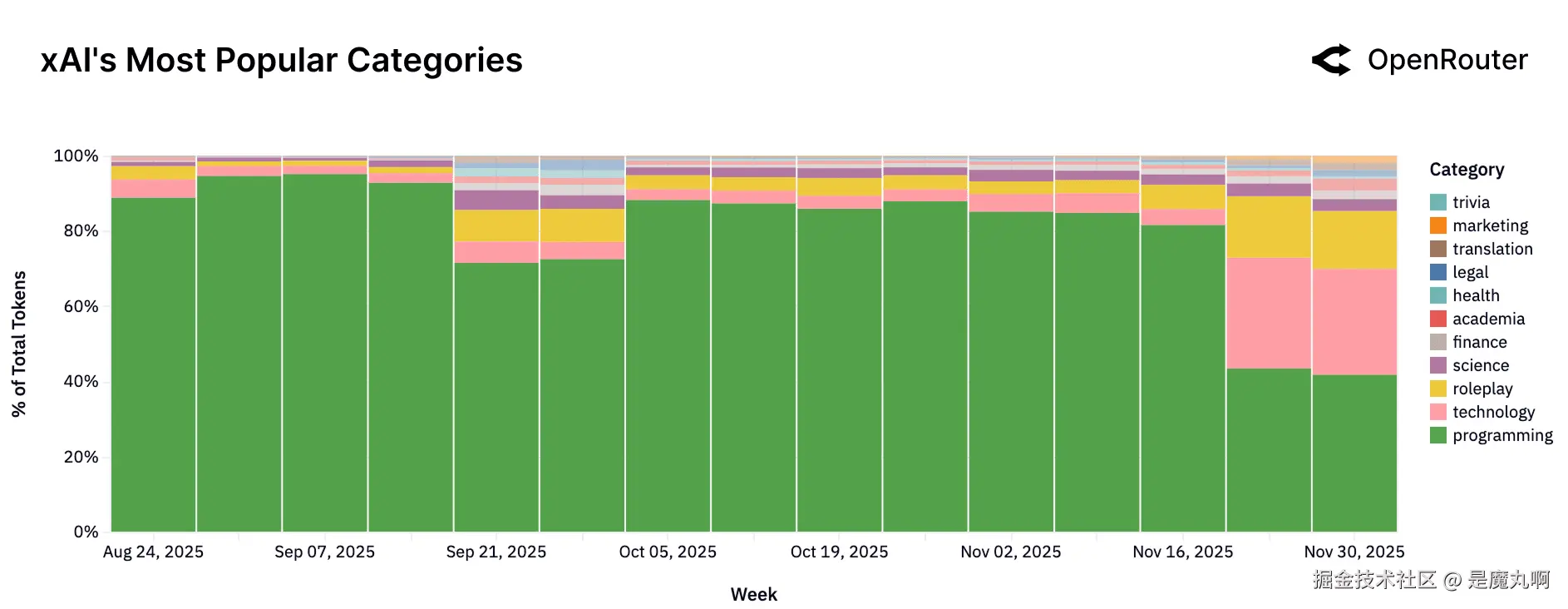
xAI。 Token使用高度集中在编程,技术、角色扮演和学术界在11月底更加突出。
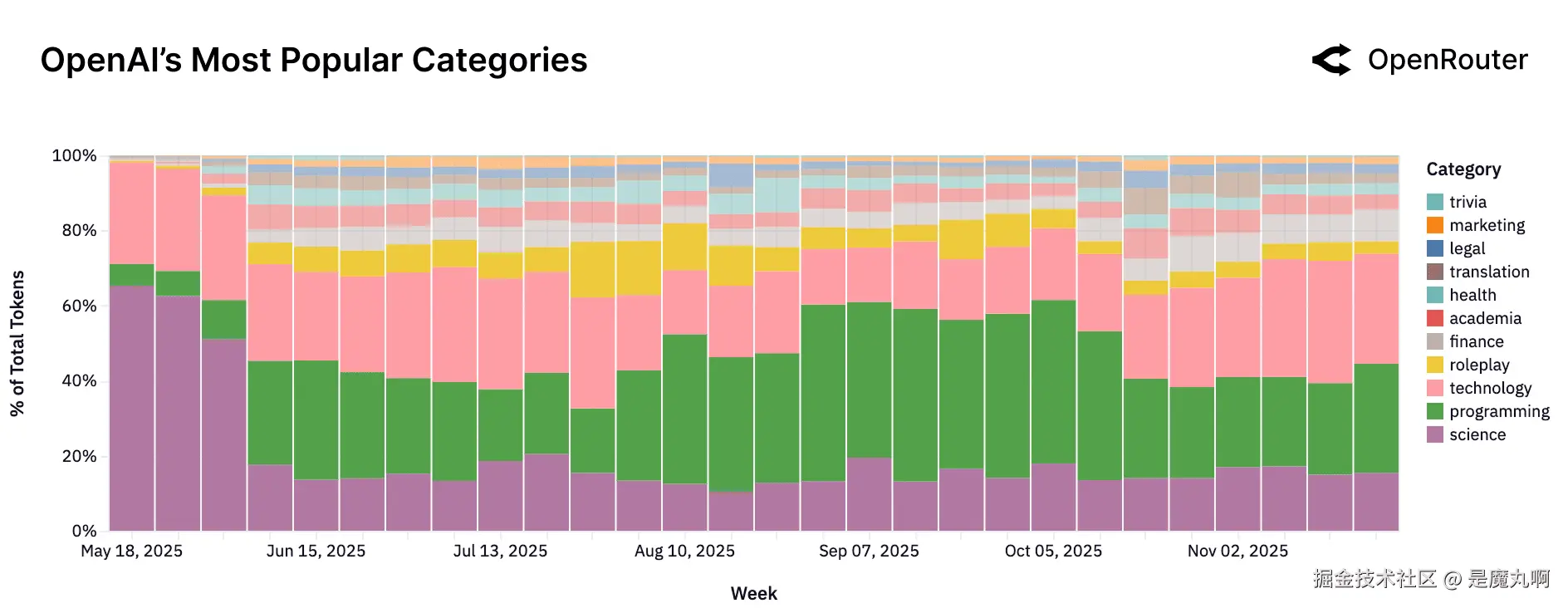
OpenAI。 随时间转向编程和技术任务,角色扮演和休闲聊天显著下降。
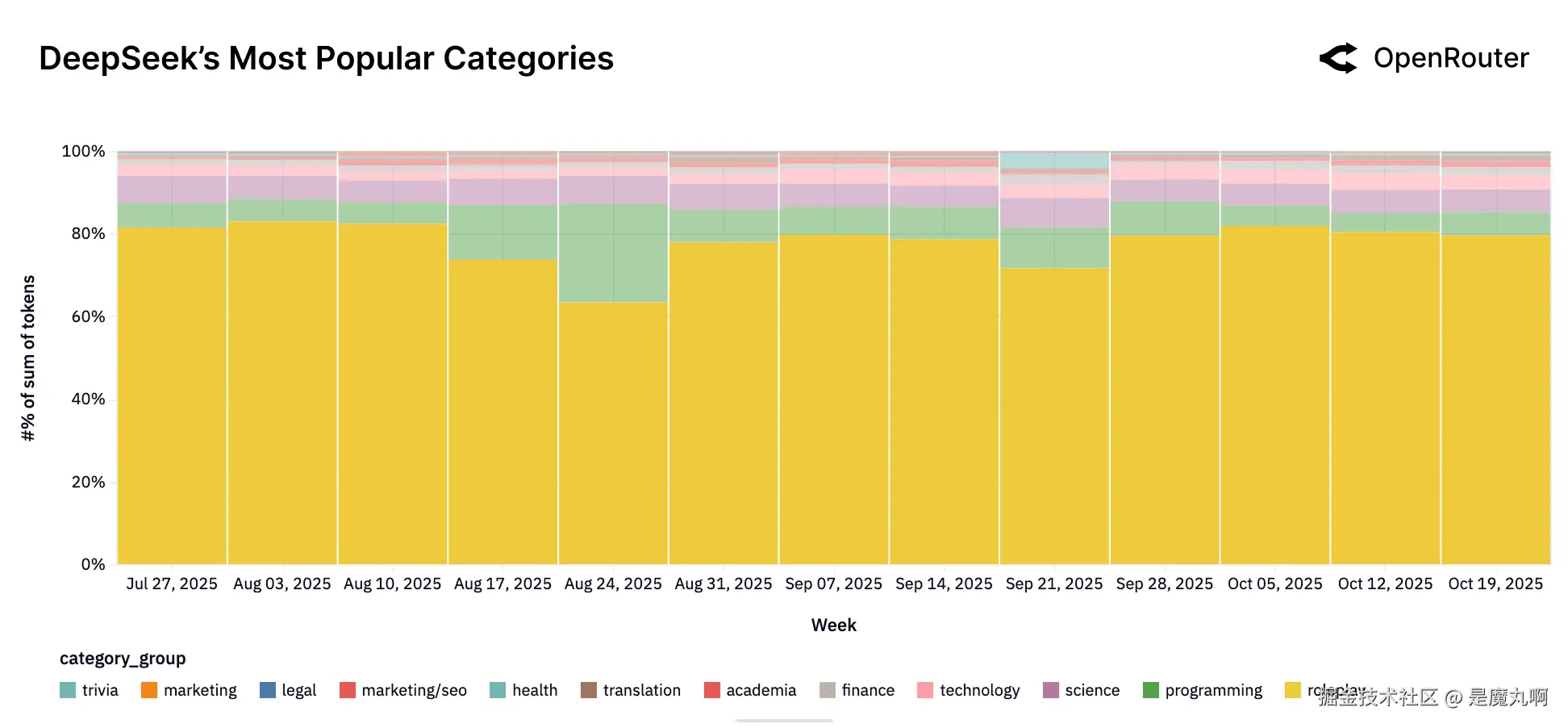
DeepSeek。 使用由角色扮演和休闲互动主导。
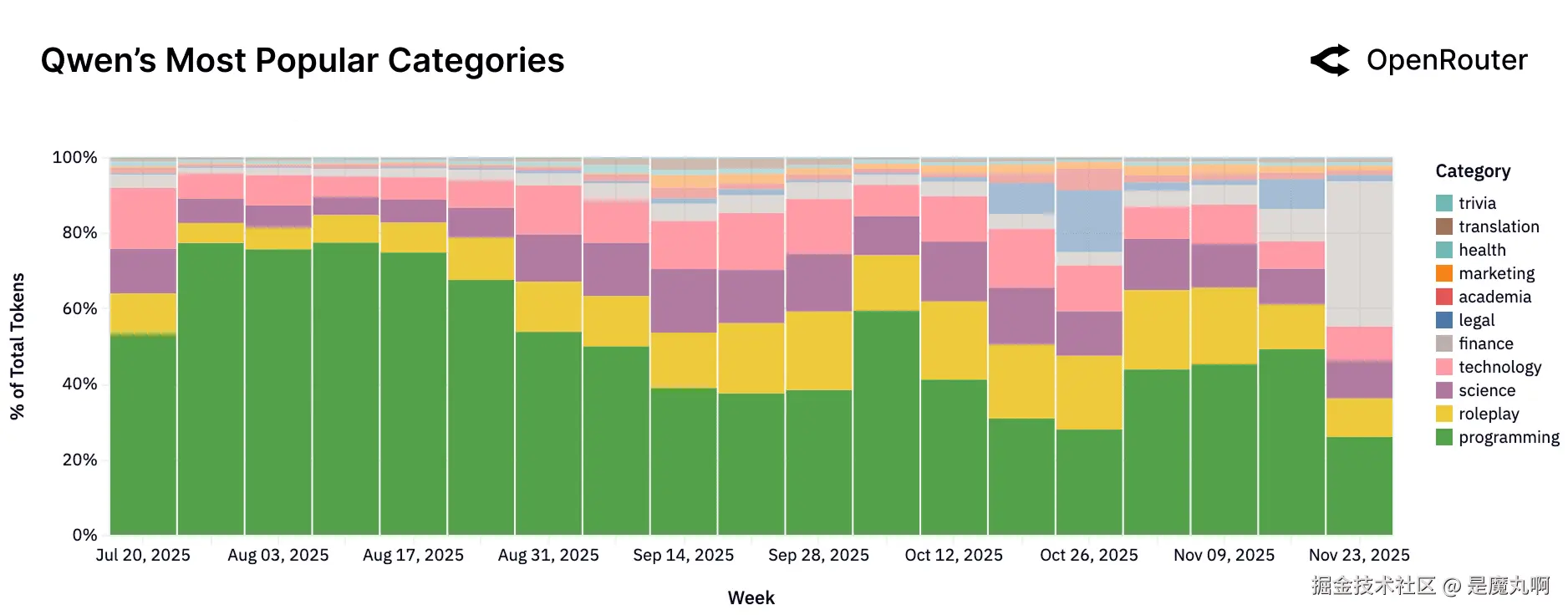
Qwen。 强度集中在编程任务,角色扮演和科学类别随时间波动。
Anthropic的Claude严重偏向__编程__+__技术__使用,合计超过其使用的80%。角色扮演和通用问答只是一小部分。这确认了Claude作为优化用于复杂推理、编码和结构化任务的模型的定位;开发者和企业似乎主要将Claude用作编码助理和问题解决者。
Google模型使用更加多样化。我们看到__翻译__、科学、__技术__和一些__通用知识__的显著分段。例如,约5%的Google使用是法律或政策内容,另约10%与科学相关。这可能暗示了Gemini的广泛培训焦点。与其他相比,Google在2025年底具有相对较少且事实上下降的编码份额(降至约18%),以及更广泛的类别尾部。这表明Google的模型更多地被用作通用信息引擎。
xAI的使用配置文件与其他提供商不同。在期间的大部分时间里,使用压倒性地集中在__编程__,通常超过所有token的80%。只在11月底分布变宽,技术、__角色扮演__和__学术界__获得显著收益。这种急剧转变与xAI模型通过选定消费者应用免费分发的时间一致,这可能引入了大量非开发者流量。结果是一个混合了早期开发者密集核心和突然的通用参与浪潮的使用配置文件,表明xAI的采用路径既受到技术用户也受到与促销可用性相关的间歇性激增的影响。
OpenAI的使用配置文件在2025年发生了显著变化。在年初,科学任务占所有OpenAI token的一半以上;到2025年底,该份额下降到15%以下。与此同时,编程和技术相关使用现在占总容量的一半以上(各占29%),反映了向开发者工作流程、生产力工具和专业应用的更深集成。OpenAI的使用配置文件现在位于Anthropic的紧密聚焦配置文件和Google的更分散分布之间,暗示了具有向高价值、结构化任务增长倾斜的广泛实用基础。
DeepSeek和Qwen表现出与早期讨论的模型家族大相径庭的使用模式。DeepSeek的token分布由角色扮演、休闲聊天和娱乐导向的交互主导,通常占其总使用量的三分之二以上。只有一小部分活动落入结构化任务如编程或科学。这种模式反映了DeepSeek的强大消费者导向和其作为高参与度对话模型的定位。值得注意的是,DeepSeek在夏末显示编程相关使用的适度稳定增长,暗示在轻量级开发工作流程中的增量采用。
相比之下,Qwen呈现出几乎相反的配置文件。在整个显示期间,编程一致代表40-60%的所有token,表明对技术和开发者任务的明确强调。与Anthropic更稳定的工程重度组成相比,Qwen在相邻类别如科学、技术和角色扮演中显示更高的波动性。这些周度变化暗示了异构用户基础和应用用例中的快速迭代。9月和10月角色扮演使用的显著上升,随后在11月收缩,暗示了演变用户行为或下游应用路由的调整。
总之,每个提供商显示出与其战略重点一致的不同配置文件。 差异 highlight 了为什么没有单一模型或提供商能最优地覆盖所有使用案例;它也强调了多模型生态系统的潜在好处。
地理分布:LLM使用在不同地区的差异
全球LLM使用表现出明显的区域变化。通过检查地理细分,我们可以推断本地使用和支出如何塑造LLM使用模式。虽然下图反映OpenRouter的用户基础,但它们提供了区域参与的一个快照。
使用的区域分布
如下面图表所示支出的分布 underscored 了AI推理市场日益增长的全球性质。北美虽然仍然是单一最大地区,但在观察期间的大多数时间现在占不到总支出的一半。欧洲显示稳定和持久的贡献。其相对周支出份额在整个时间线保持一致,通常占据中十几到低二十几之间的带。一个显著的发展是亚洲不仅作为前沿模型生产者的崛起,也作为快速扩展的消费者。在数据集的最早几周,亚洲约占全球支出的13%。随时间,这一份额翻倍多,在最近时期达到约31%。
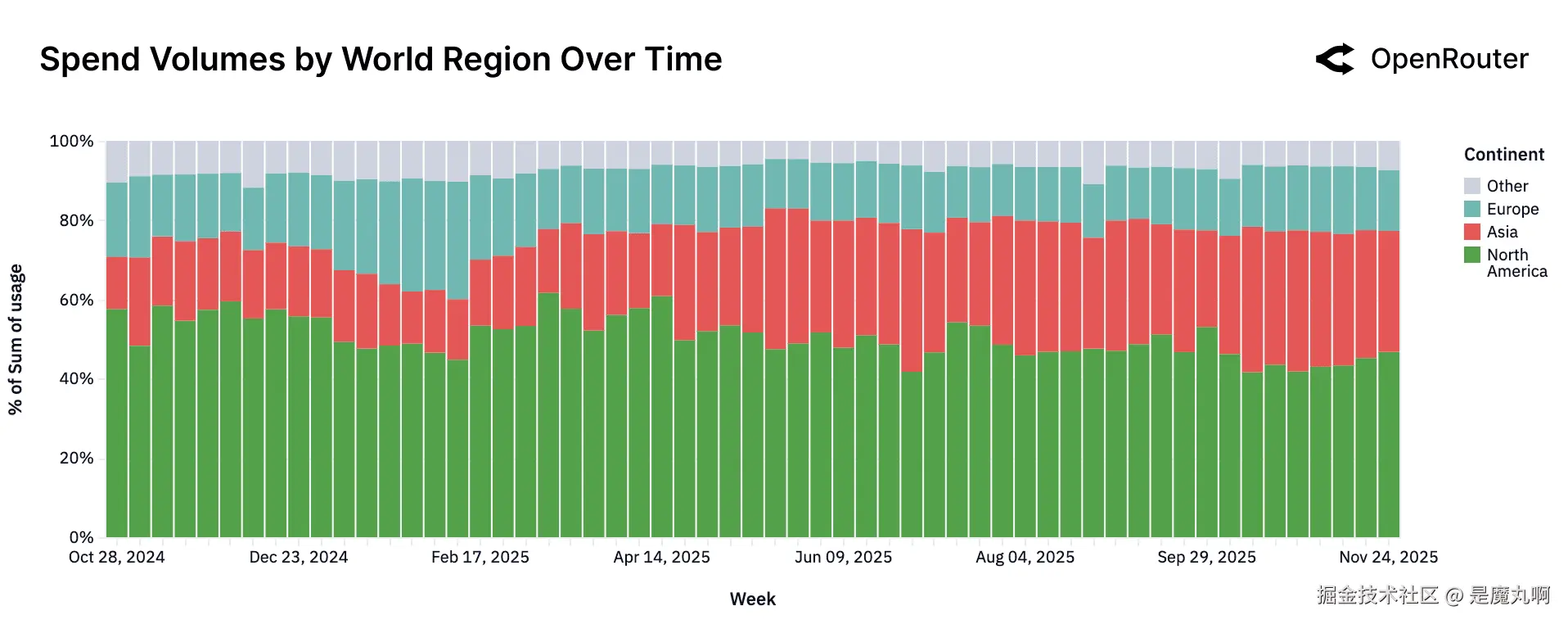
按世界地区划分的支出数量随时间变化。 归因于每个大洲的全球使用周份额。
LLM使用的洲际分布。 每个大洲产生的总token百分比(账单地区)。
| 大洲 | 份额 (%) |
|---|---|
| 北美 | 47.22 |
| 亚洲 | 28.61 |
| 欧洲 | 21.32 |
| 大洋洲 | 1.18 |
| 南美 | 1.21 |
| 非洲 | 0.46 |
按token数量排名的前10个国家。 按全球LLM token份额排名的国家。
| 国家 | 份额 (%) |
|---|---|
| 美国 | 47.17 |
| 新加坡 | 9.21 |
| 德国 | 7.51 |
| 中国 | 6.01 |
| 韩国 | 2.88 |
| 荷兰 | 2.65 |
| 英国 | 2.52 |
| 加拿大 | 1.90 |
| 日本 | 1.77 |
| 印度 | 1.62 |
| 其他(60多个国家) | 16.76 |
语言分布
按语言的token数量。 语言基于跨所有OpenRouter流量检测的提示语言。
| 语言 | Token份额 (%) |
|---|---|
| 英语 | 82.87 |
| 中文(简体) | 4.95 |
| 俄语 | 2.47 |
| 西班牙语 | 1.43 |
| 泰语 | 1.03 |
| 其他(合计) | 7.25 |
如上表所示,英语主导使用,占所有token的80%以上。这反映了英语语言模型的普遍性和OpenRouter用户基础的开发者中心偏向。然而,其他语言特别是中文、俄语和西班牙语构成了有意义的尾部。仅简体中文就占全球token的近5%,考虑到像DeepSeek和Qwen这样的中国OSS模型的增长,表明在双语或中文优先环境中的持续参与。
对于模型构建者和基础设施运营商来说,跨区域可用性,跨语言、合规制度和部署设置,在LLM采用同时全球和本地优化的世界中成为基本要求。
LLM用户留存分析
灰姑娘"水晶鞋"现象
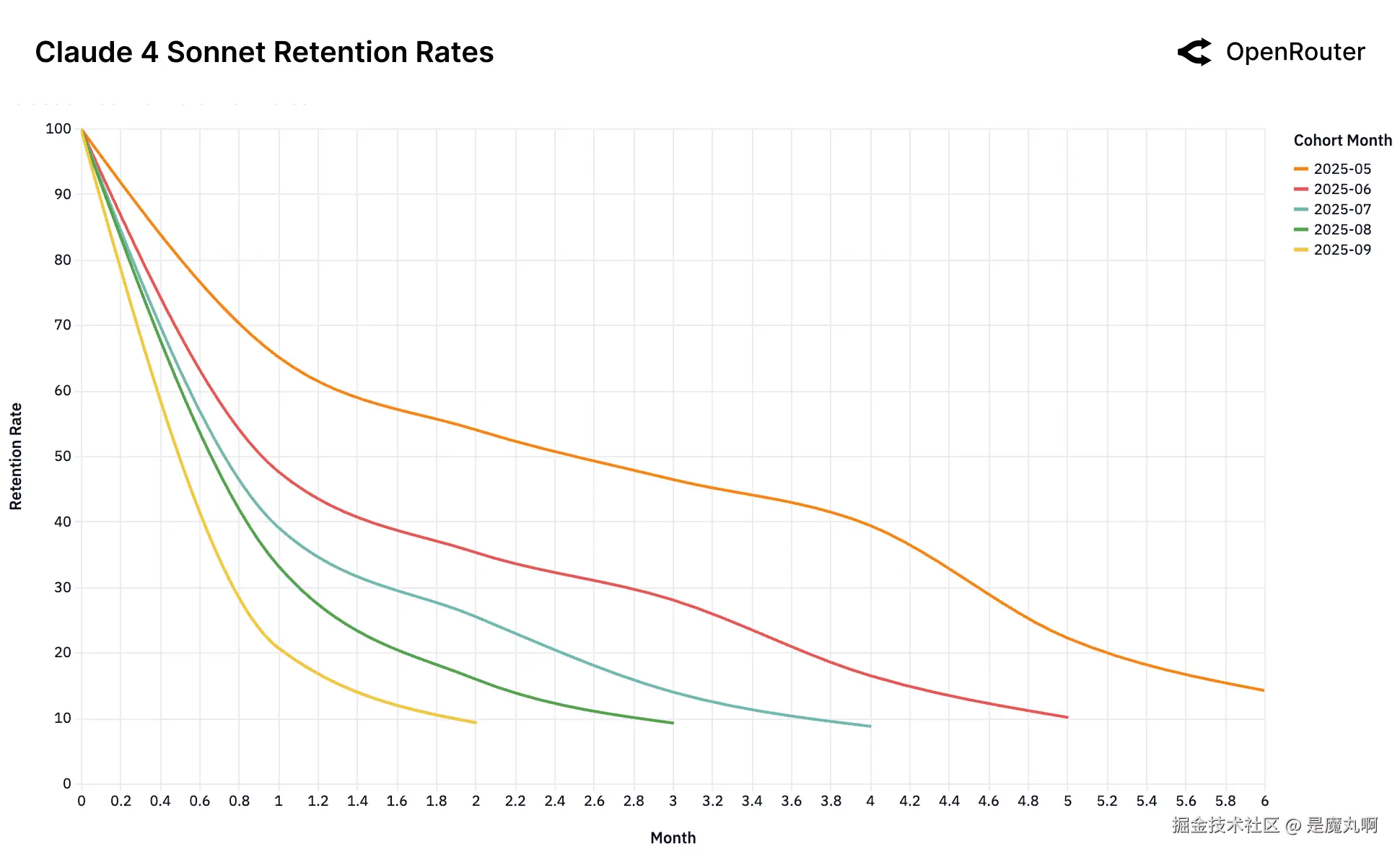
Claude 4 Sonnet
Gemini 2.5 Pro
Gemini 2.5 Flash
OpenAI GPT-4o Mini
Llama 4 Maverick
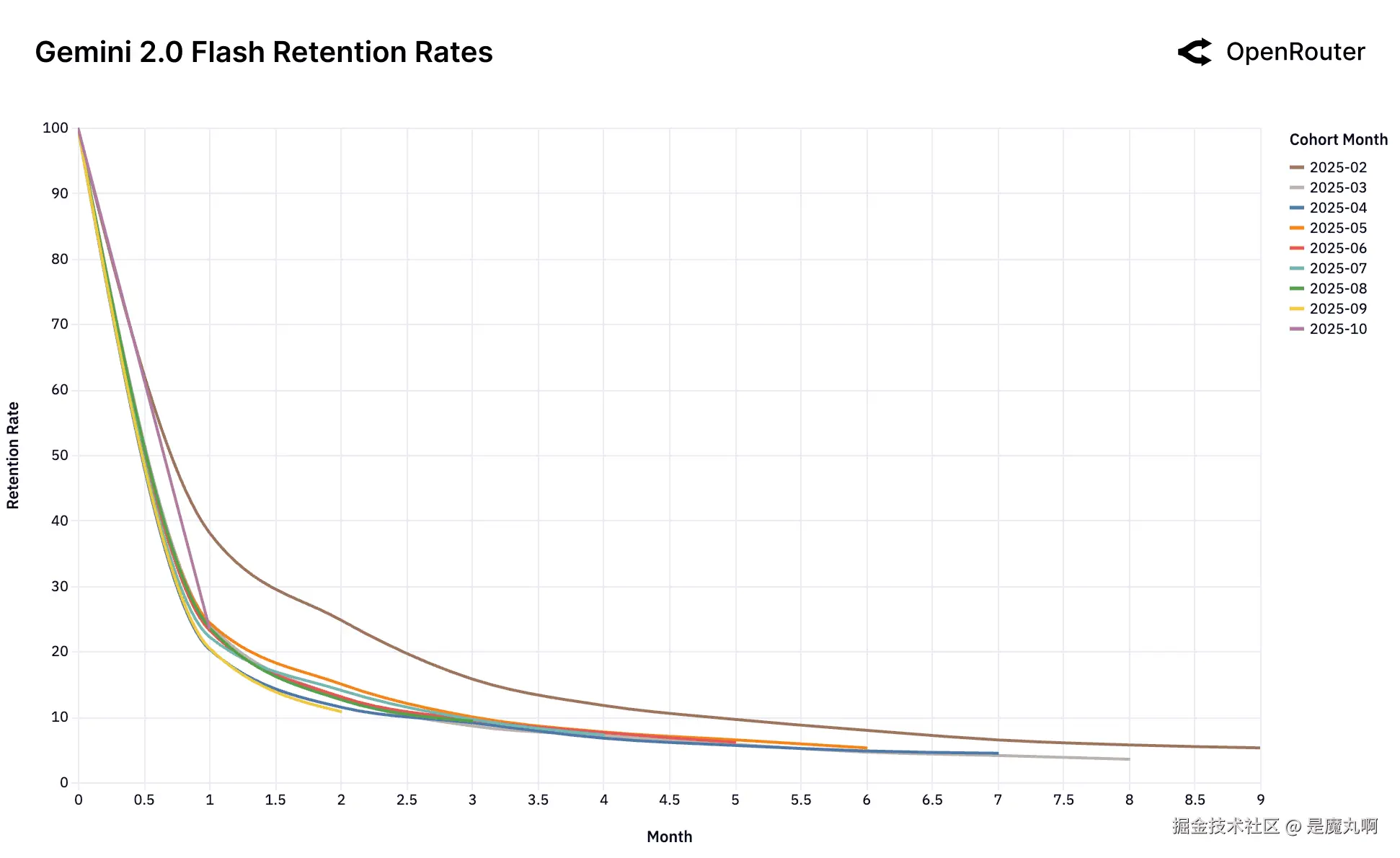
Gemini 2.0 Flash
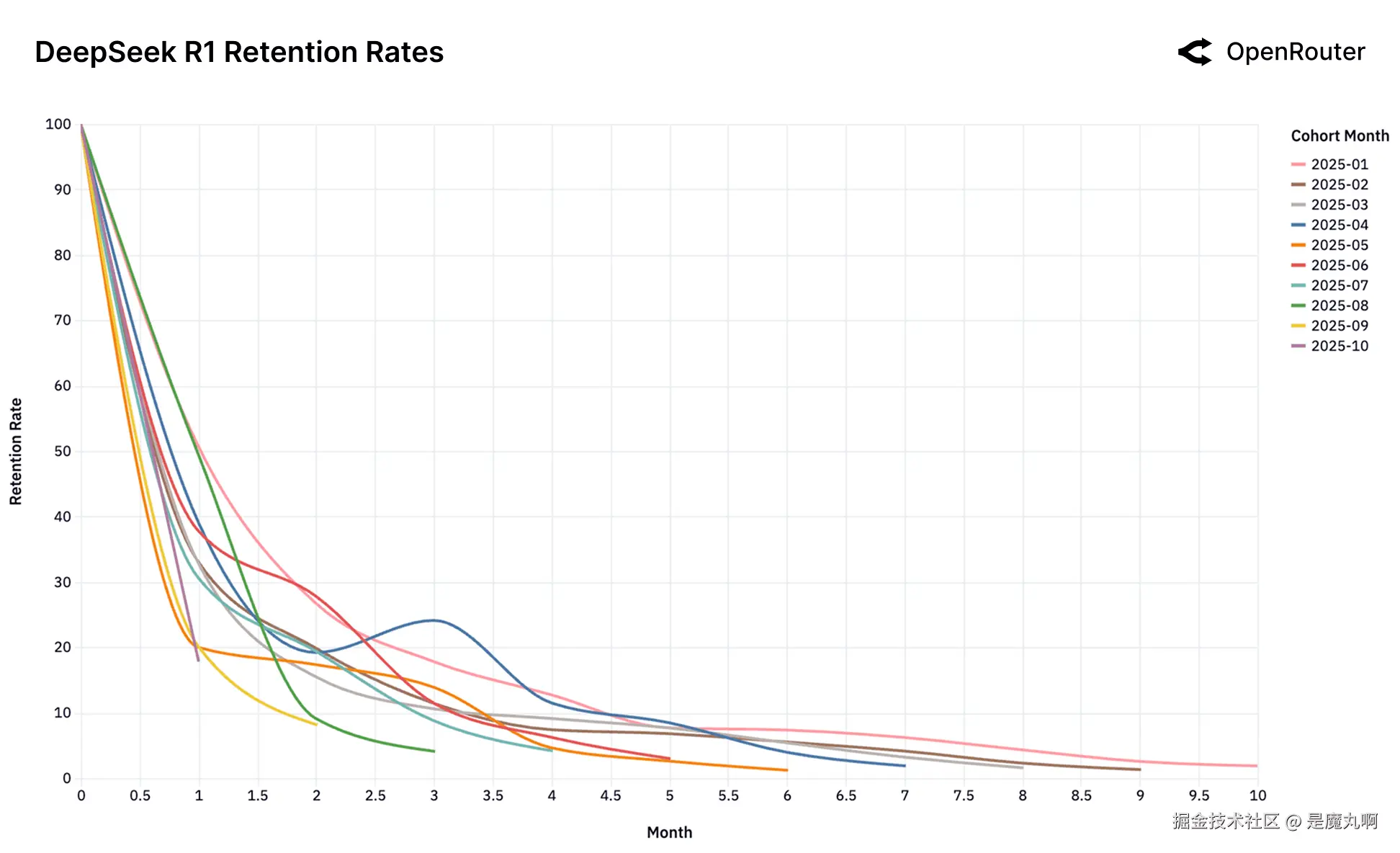
DeepSeek R1
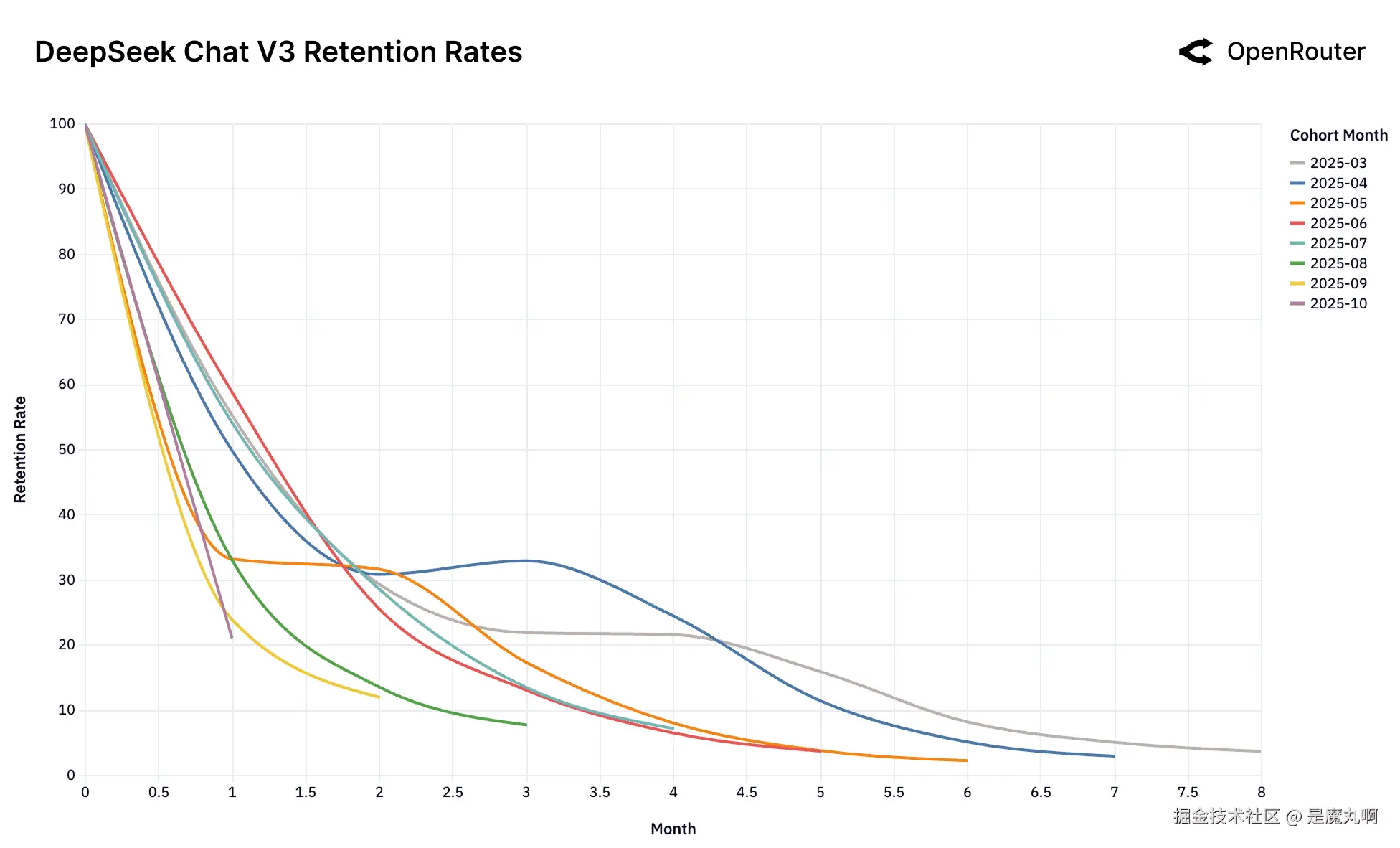
DeepSeek Chat V3-0324
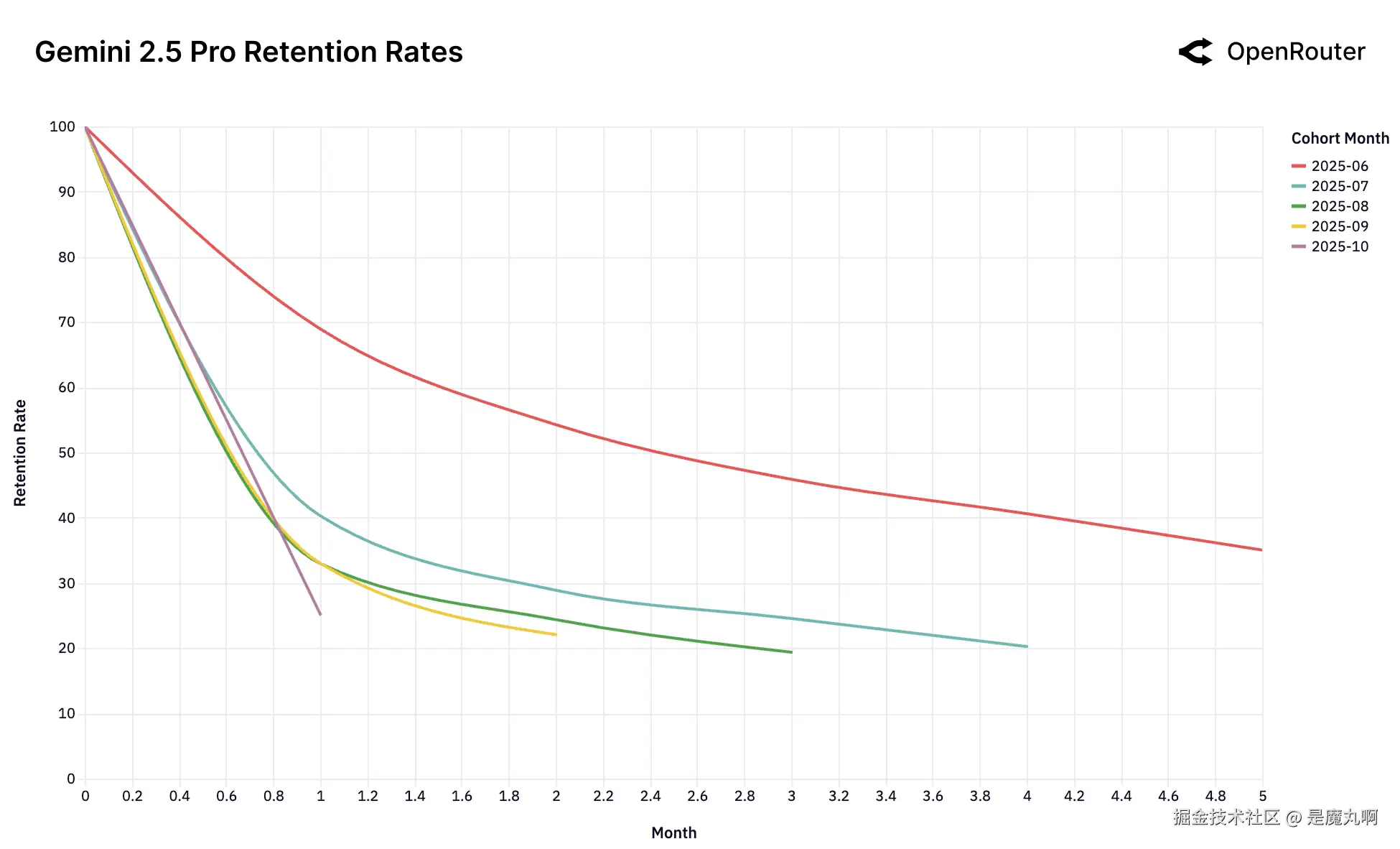
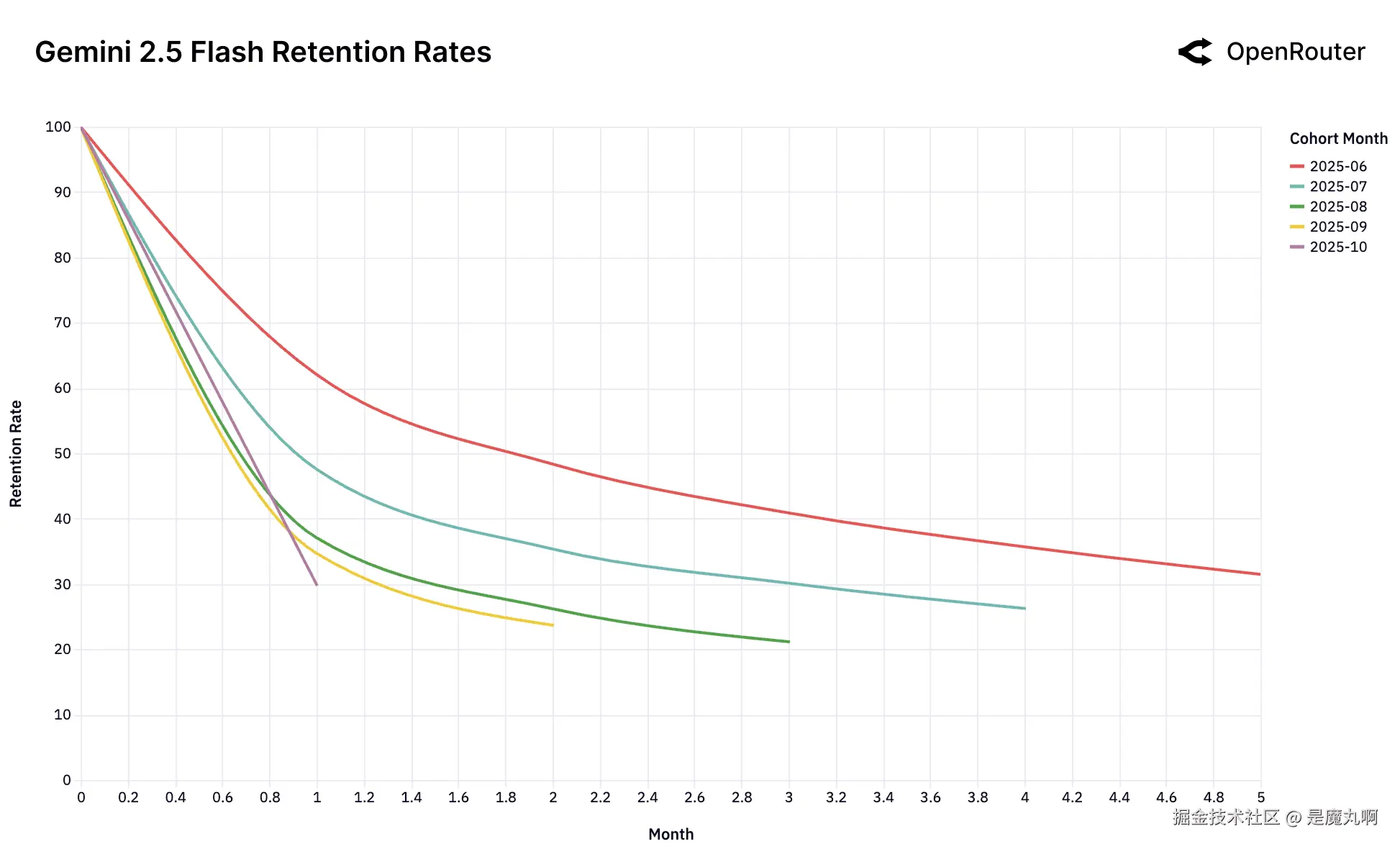
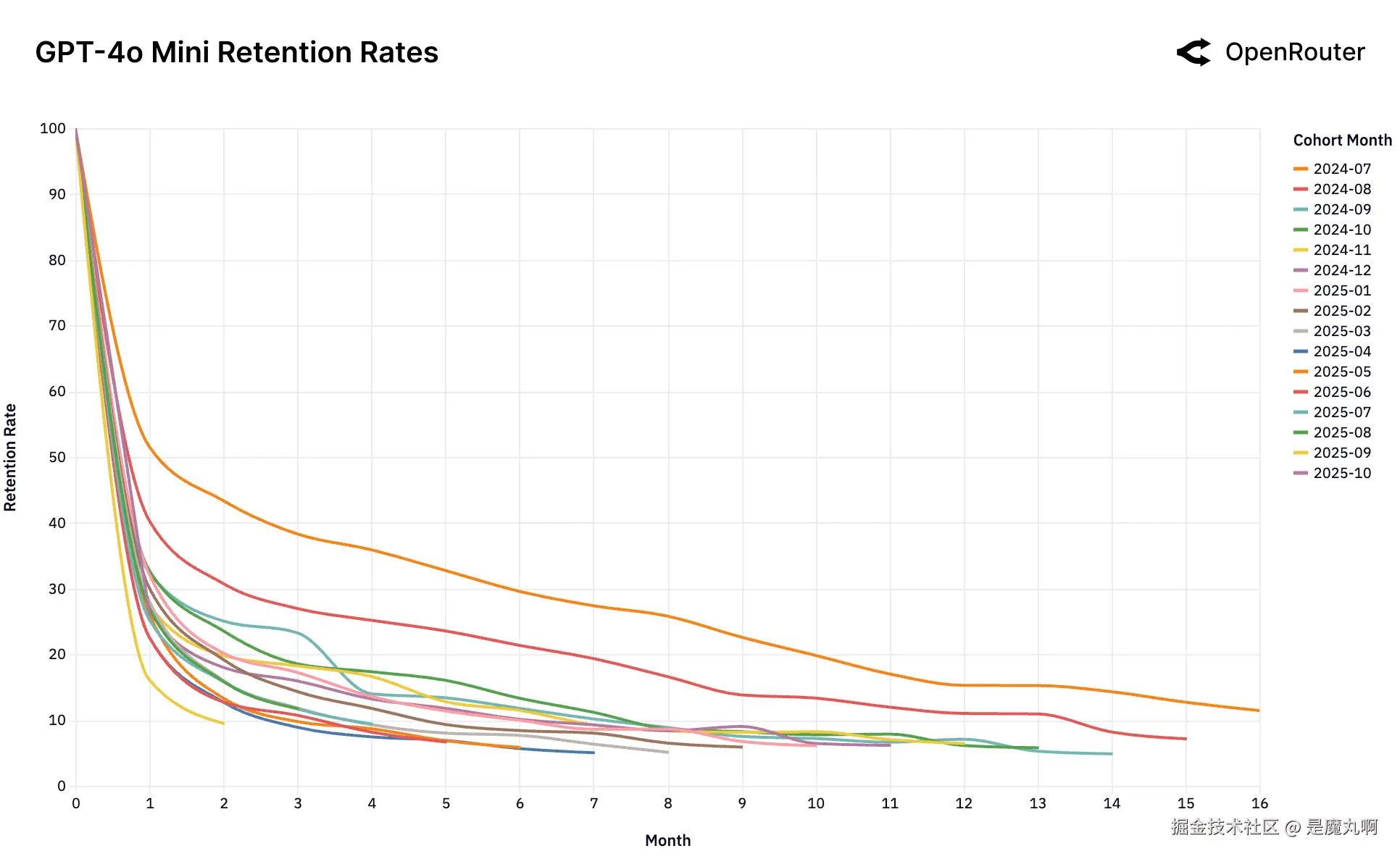
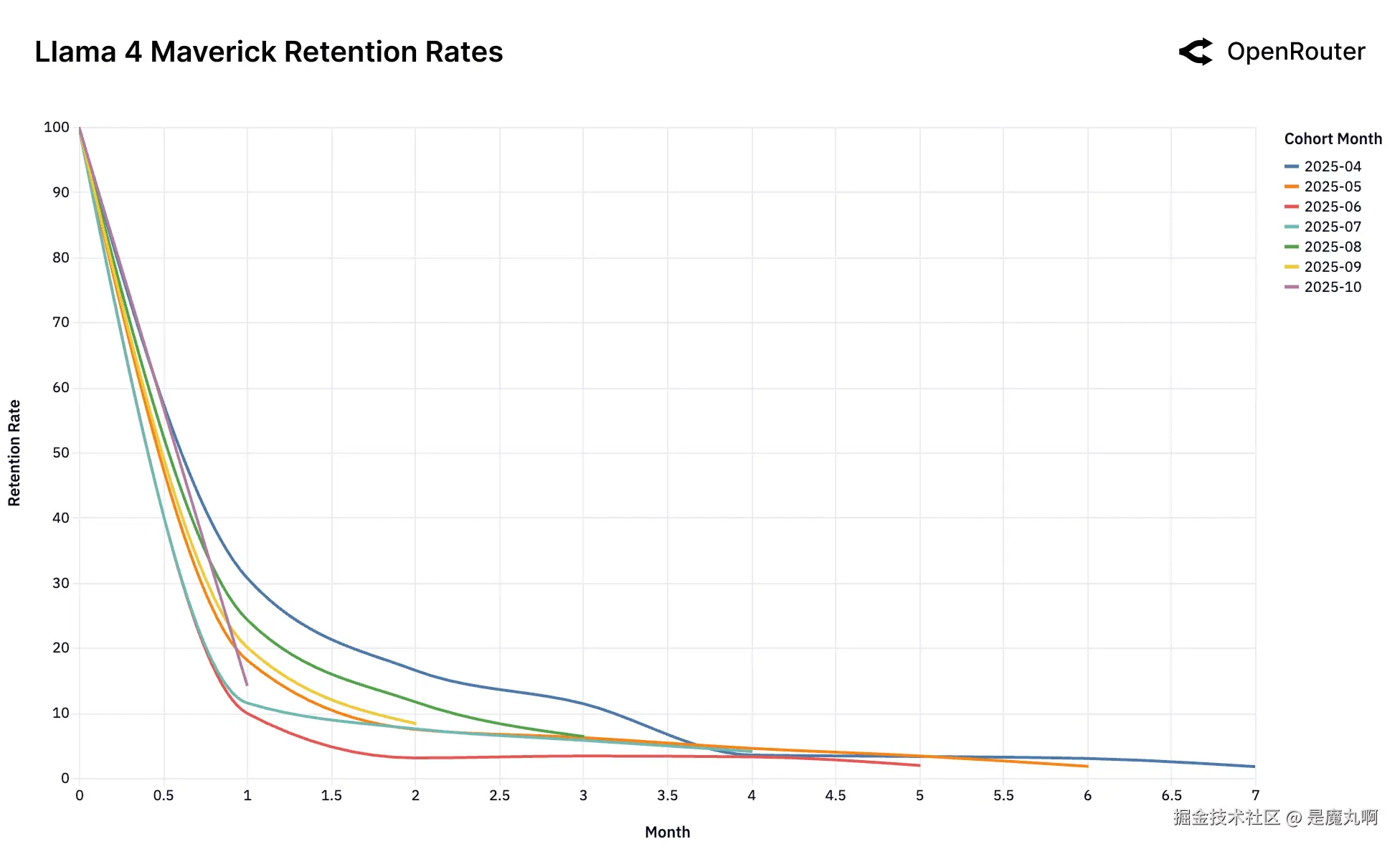
队列留存率。留存度量为_活动留存_,如果用户在后续月份返回,即使在非活跃期之后也被计入;因此,曲线可能表现出小的非单调性凸起。
这组留存图表捕捉了领先模型跨LLM用户市场的动态。乍一看,数据由高流失率和快速队列衰减主导。然而在这种波动性之下 lies 一个更微妙和更有后果的信号:一小部分早期用户队列表现出持久随时间的留存。我们称之为_基础队列_。
这些队列不仅仅是早期采用者;它们代表其工作负载已达到深度和持久_工作负载-模型契合度_的用户。一旦建立,这种契合在经济和认知惯性方面创造了抵抗替代的强有力因素,即使新模型出现也是如此。
我们引入灰姑娘__水晶鞋效应__作为描述这种现象的框架。该假设假设在快速演变的AI生态系统中,存在一个高价值工作负载的潜在分布,这些工作负载在连续模型世代中仍未解决。每个新的前沿模型实际上是针对这些开放问题"试穿"的。当新发布的模型恰好匹配以前未满足的技术和经济约束时,它实现了精确契合------隐喻的"水晶鞋"。
对于其工作负载最终"契合"的开发者或组织来说,这种一致创造了强大的锁定效应。他们的系统、数据管道和用户体验变得锚定到首先解决他们问题的模型上。随着成本下降和可靠性提高,重新平台的激励急剧减少。相反,没有找到这种契合的工作负载保持探索性,从一个模型迁移到另一个寻找自己的解决方案。
经验上,这种模式在2025年6月的Gemini 2.5 Pro队列和2025年5月的Claude 4 Sonnet队列中可观察到,它们在第5个月保留约40%的用户,显著高于后期队列。这些队列似乎对应于特定的技术突破(例如,推理保真度或工具使用稳定性),最终使以前不可能的工作负载成为可能。
- 首先解决作为持久优势。 当模型是第一个_解决_关键工作负载时,经典的先发优势获得意义。早期采用者将模型嵌入管道、基础设施和用户行为中,导致高切换摩擦。这创建了一个稳定平衡,模型即使在新替代方案出现时也保留其基础队列。
- 留存作为能力转折的指标。 队列级留存模式作为模型差异化的经验信号。一个或多个早期队列的持续留存表明有意义的能力转折------工作负载类别从不可能变为可能。缺乏这种模式表明能力平价和有限深度差异化。
- 前沿窗口的时间约束。 竞争景观施加了一个狭窄的时间窗口,模型可以捕获基础用户。随着连续模型缩小能力差距,形成新基础队列的概率急剧下降。"灰姑娘"时刻,模型和工作负载精确对齐的时间,因此是短暂但对长期采用动态决定性的。
总的来说,基础模型的快速能力转变 necessitates 用户留存的重定义。每个新模型世代引入一个简短的机会来解决以前未满足的工作负载。当这种一致发生时,受影响的用户形成_基础队列_:尽管随后引入模型,留存轨迹保持稳定的分段。
主导发布异常。 OpenAI GPT-4o Mini图表以极端形式显示这种现象。一个单一基础队列(2024年7月,橙线)在发布时建立了主导、粘性的工作负载-模型契合度。所有后续队列,在这个契合建立后和市场继续前进后到达,行为相同:它们流失并聚集在底部。这表明建立这种基础契合的窗口是单一的,只在模型被视为"前沿"的时刻发生。
无契合的后果。 Gemini 2.0 Flash和Llama 4 Maverick图表展示了当这种初始契合从未建立时会发生什么的警示故事。与其他模型不同,没有高性能的基础队列。每个单一队列表现同样差。这表明模型从未被视为高价值、粘性工作负载的"前沿"。它直接进入_足够好_市场,因此未能锁定任何用户基础。类似地,DeepSeek的混乱图表,尽管总体上压倒性成功,但难以建立稳定的基础队列。
回旋镖效应。 DeepSeek模型引入了更复杂的模式。它们的留存曲线显示高度异常:复活跳跃。不像典型的单调递减留存,几个DeepSeek队列在初始流失期后显示明显上升(例如,DeepSeek R1的2025年4月队列在第3个月左右,和DeepSeek Chat V3-0324的2025年7月队列在第2个月左右)。这表明一些流失用户正在返回模型。这种"回旋镖效应"暗示这些用户在尝试替代方案并通过竞争测试确认后返回DeepSeek,DeepSeek为他们的特定工作负载提供了最优的,并且常常更好的契合,由于专门技术性能、成本效率或其他独特功能的优越组合。
含义。 _水晶鞋_现象重新定义了留存不是结果而是理解能力突破的视角。基础队列是真实技术进步的指纹:它们标记AI模型何时从新奇转向必需。对于构建者和投资者来说,早期识别这些队列可能是持久模型-市场优势的最具预测性信号。
成本与使用动态
模型使用成本是影响用户行为的关键因素。在本节中,我们专注于不同AI工作负载类别如何分布在成本-使用景观中。通过检查类别如何在成本vs使用对数图上聚集,我们识别工作负载如何在低成本、高容量区域vs高成本、专门细分中集中的模式。我们还引用与杰文斯悖论效应的相似性,在低成本类别往往对应更高聚合使用的意义上,尽管我们不试图正式分析悖论或因果关系。
按类别的AI工作负载细分分析
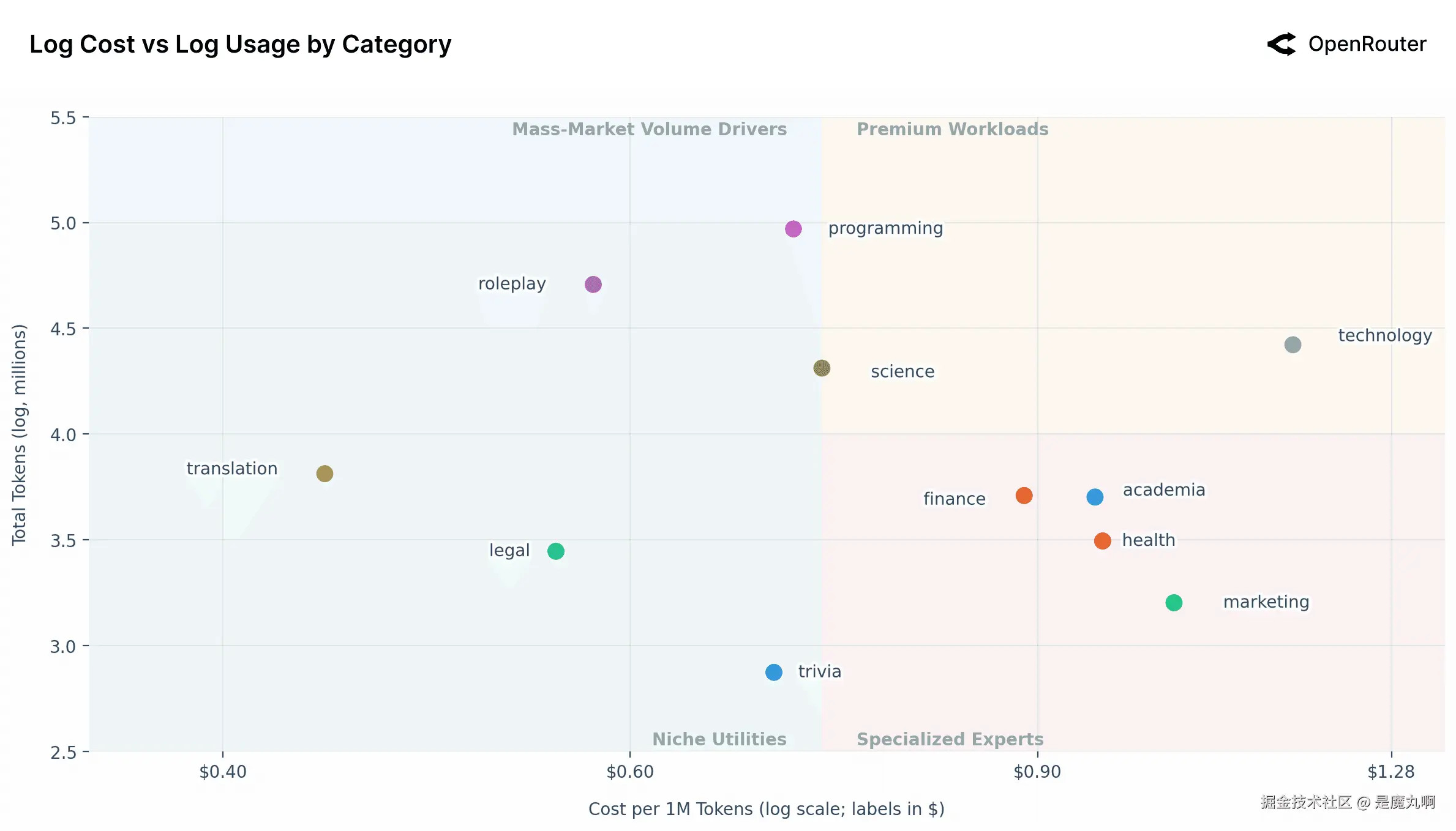
按类别划分的对数成本vs对数使用
上面的散点图揭示了AI使用案例的独特细分,基于它们的聚合使用量(总Token)与其单位成本(每百万Token成本)进行映射。一个关键的初步观察是两个轴都是对数的。这种对数缩放表示图表上的小视觉距离对应于现实世界容量和成本的实质性乘法差异。
图表被每百万Token__$0.73__的中位成本垂直线平分,有效地创建了一个四象限框架来简化跨类别的AI市场。
注意这些最终成本不同于公布的列表价格。高频工作负载受益于缓存,这降低了实现支出并产生比公开列出的 materially 更低的有效价格。显示的成本指标反映跨提示和完成token的混合速率,提供用户实际支付的聚合的更准确视图。数据集还排除BYOK活动以隔离标准化、平台中介使用并避免来自自定义基础设施设置的扭曲。
高级工作负载(右上): 这个象限包含高成本、高使用应用,现在包括技术和科学,正位于交汇处。这些代表有价值且重度使用的专业工作负载,用户愿意为性能或专门能力支付溢价。技术是一个显著异常值,比任何其他类别戏剧性地更昂贵。这表明技术作为使用案例(可能与复杂系统设计或架构相关)可能需要更强大和更昂贵的模型进行推理,然而它维持高使用容量,表明其本质重要性。
大众市场容量驱动因素(左上): 这个象限定义为高使用和低、平均或以下成本。这个区域由两个大量使用案例主导:角色扮演、编程以及科学。
编程作为"杀手级专业"类别突出,显示最高使用量同时具有高度优化的中位成本。角色扮演的使用容量巨大,几乎 rivaling编程。这是一个 striking 洞察:面向消费者的角色扮演应用驱动的参与容量与顶级专业相当。
这两个类别的绝对规模确认专业生产力和对话娱乐都是AI的主要、大规模驱动因素。这个象限中的成本敏感性是如前所述开源模型找到重要优势的地方。
专门专家(右下): 这个象限包含较低容量、高成本应用,包括金融、学术界、健康和营销。这些是高风险、细分专业领域。较低聚合容量是逻辑的,因为人们可能为"健康"或"金融"咨询AI的频率远低于"编程"。用户愿意为这些任务支付显著溢价,很可能因为对准确性、可靠性和领域特定知识的需求极高。
小众实用程序(左下): 这个象限以低成本、低容量任务为特色,包括翻译、法律和琐事。这些是功能性、成本优化的实用程序。翻译在这个组中有最高容量,而琐事有最低容量。它们的低成本和相对低容量表明这些任务可能高度优化、"已解决"或商品化,其中足够的替代品可廉价获得。
如前所述,这个图表上最显著的异常值是技术。它以相当大的幅度命令每token最高成本,同时维持高使用。这强烈暗示了一个具有高支付意愿的高价值、复杂答案(例如,系统架构、高级技术问题解决)的市场细分。一个关键问题是这种高价格是由高用户价值("需求侧"机会)还是由高服务成本("供给侧"挑战)驱动,因为这些查询可能需要最强大的前沿模型。技术中的"玩法"是服务这个高价值市场。能够服务这个细分的提供商,也许通过高度、优化的专家模型,可能潜在捕获更高利润的市场。
AI模型的有效成本vs使用
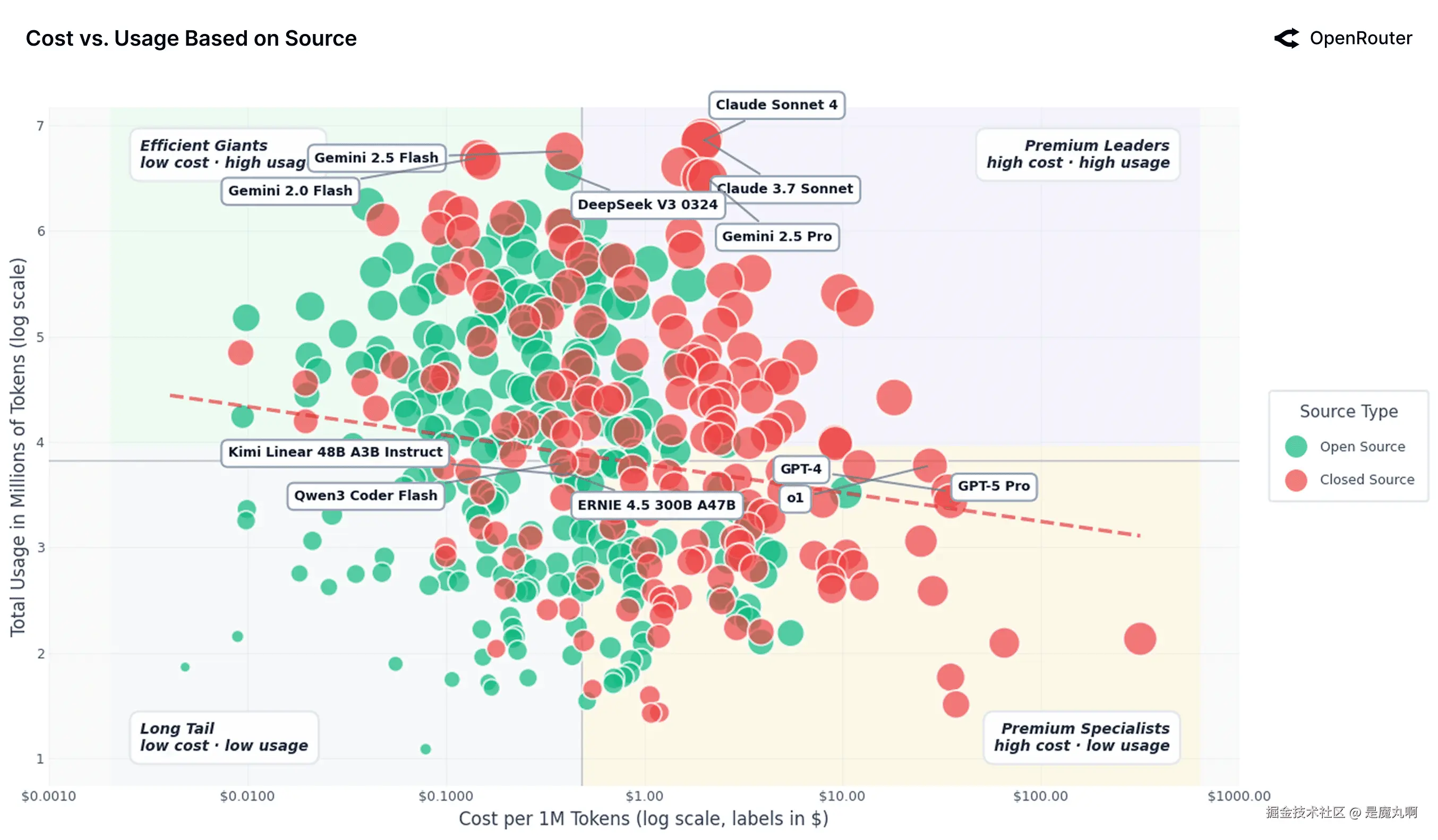
开源vs闭源模型景观:成本vs使用(对数-对数比例)。 每个点代表OpenRouter上提供的模型,按来源类型着色。闭源模型聚集在高成本、高使用象限,而开源模型主导低成本、高容量区域。虚线趋势线几乎平坦,显示成本与总使用之间的有限相关性。注意:指标反映跨提示和完成token的混合平均,由于缓存,有效价格通常低于列表费率。BYOK活动被排除。
上图将模型使用与每百万token成本(对数-对数比例)映射,揭示弱整体相关性。x轴为方便显示标称值。趋势线几乎平坦,表明需求相对价格无弹性;价格下降10%对应仅约0.5-0.7%的使用增长。然而图表内的分散是实质性的,反映强烈的市场细分。出现两个不同的制度:来自OpenAI和Anthropic的专有模型占据高成本、高使用区域,而像DeepSeek、Mistral和Qwen这样的开源模型占据低成本、高容量区域。这种模式支持一个简单启发式:闭源模型捕获高价值任务,而开源模型捕获高容量低价值任务。 弱价格弹性表明即使剧烈成本差异也不完全转变需求;专有提供商为关键任务应用保留定价能力,而开源生态系统吸收来自成本敏感用户的容量。
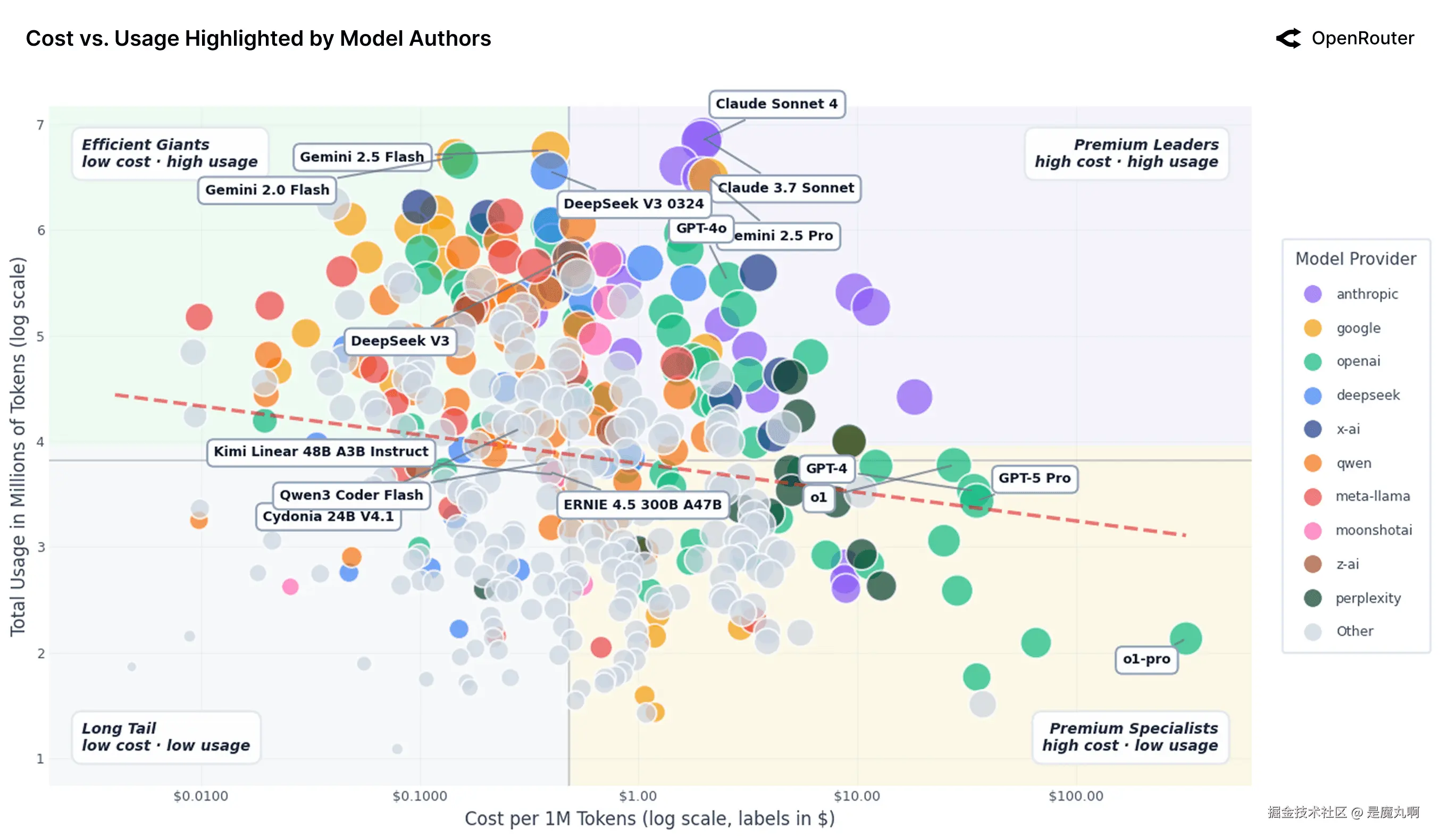
AI模型市场图:成本vs使用(对数-对数比例)。 类似于上图但每个点按模型提供商着色。
按细分的示例模型。 从更新数据集采样的值。市场级回归仍然几乎平坦,但细分级行为急剧不同。
| 细分 | 模型 | 每1M价格 | 使用(对数) | 要点 |
|---|---|---|---|---|
| 高效巨头 | google/gemini-2.0-flash | $0.147 | 6.68 | 低价格和强大分发使其成为默认高容量工作马 |
| 高效巨头 | deepseek/deepseek-v3-0324 | $0.394 | 6.55 | 有竞争质量的价格驱动大量采用 |
| 高级领导者 | anthropic/claude-3.7-sonnet | $1.963 | 6.87 | 尽管溢价价格仍有高使用,表明对质量和可靠性的偏好 |
| 高级领导者 | anthropic/claude-sonnet-4 | $1.937 | 6.84 | 企业工作负载似乎对可信前沿模型价格无弹性 |
| 长尾 | qwen/qwen-2-7b-instruct | $0.052 | 2.91 | 底价但有限覆盖,可能由于较弱模型-市场契合 |
| 长尾 | ibm/granite-4.0-micro | $0.036 | 2.95 | 便宜但细分,主要在有限设置中使用 |
| 高级专家 | openai/gpt-4 | $34.068 | 3.53 | 高成本和适中使用,保留给最苛刻任务 |
| 高级专家 | openai/gpt-5-pro | $34.965 | 3.42 | 超高级模型专注、高风险工作负载。考虑到最近发布,采用仍在早期。 |
上图类似于前图但显示模型作者。出现四个使用-成本原型。高级领导者 ,如Anthropic的Claude 3.7 Sonnet和Claude Sonnet 4,命令约每百万token 2的成本并仍然达到高使用,表明用户愿意为卓越推理和可靠性在规模上付费。高效巨头,如Google的Gemini2.0Flash和DeepSeekV30324,将强大性能与低于0.40每百万token的价格配对并实现相似使用水平,使其成为高容量或长上下文工作负载的有吸引力的默认选择。_长尾_模型,包括Qwen 2 7B Instruct和IBM Granite 4.0 Micro,定价仅为每百万token几分钱,但使用量在10^2.9左右,反映来自较弱性能、有限可见性或较少集成的约束。最后,高级专家,如OpenAI的GPT-4和GPT-5 Pro,占据高成本、低使用象限:在约每百万token $35和使用接近10^3.4,它们被谨慎用于细分、高风险工作负载,其中输出质量远比边际token成本重要。
总的来说,散点图 highlight LLM市场中的定价权不是统一的。虽然更便宜的模型可以通过效率和集成驱动规模,高级产品仍然在风险高的情况下保持强需求。这种碎片化表明市场尚未商品化,差异化,无论是通过延迟、上下文长度还是输出质量,仍然是战略优势的来源。
这些观察表明以下:
- 在宏观层面,需求无弹性,但这掩盖了不同的微观行为。具有关键任务的企业将支付高价格(所以这些模型看到高使用)。另一方面,爱好者和开发管道对成本非常敏感,涌向更便宜的模型(导致高效模型的大量使用)。
- 有一些__杰文斯悖论__的证据:使一些模型非常便宜(和快速)导致人们将它们用于更多任务,最终消费更多总token。我们在高效巨头组中看到这一点:随着每token成本下降,这些模型无处不在集成,总消费飙升(人们运行更长上下文、更多迭代等)。
- 质量和能力通常胜过成本: 昂贵模型(Claude、GPT-4)的重度使用表明,如果模型显著更好或有信任优势,用户将承担更高成本。通常这些模型集成到工作流程中,其中成本相对于它们产生价值可忽略(例如,节省开发者时间的代码远超过几次API调用的几美元)。
- 相反,仅仅便宜不够,模型也必须__可区分和足够胜任。__ 许多定价接近零的开源模型仍然因为它们只是足够好但没有找到_工作负载-模型契合_或不够可靠,所以开发者犹豫深入集成它们。
从运营商角度来看,出现几个战略模式。像Google这样的提供商严重倾向于分层产品(最显著的是Gemini Flash和Pro)明确交易速度、成本和能力。这种分层允许按价格敏感性和任务关键性进行市场细分:轻量级任务路由到更便宜、更快的模型;高级模型服务复杂或延迟容忍的工作负载。优化用例和可靠性通常和"削减"价格一样有影响。更快、专门构建的模型可能比更便宜但不可预测的模型更受欢迎,特别是在生产设置中。这将焦点从每token成本转移到每成功结果成本。相对平坦的需求弹性表明LLM还不是商品------许多用户愿意为质量、能力或稳定性支付溢价。 差异化仍然持有价值,特别是当任务结果比边际token节省更重要时。
讨论
这项实证研究提供了关于LLM实际如何使用的数据驱动视角, highlight 了几种 nuance 常规AI部署智慧的主题:
1. 多模型生态系统。 我们的分析显示没有单一模型主导所有使用。相反,我们观察到丰富的__多模型生态系统__,闭源和开源模型都捕获重要份额。例如,即使OpenAI和Anthropic模型在许多编程和知识任务中领先,像DeepSeek和Qwen这样的开源模型集体服务了总token的大部分(有时超过30%)。这表明LLM使用的未来可能模型无关和异构。对于开发者来说,这意味着保持灵活性,集成多个模型并为每个工作选择最佳,而不是将所有赌注押在一个模型的 supremacy 上。对于模型提供商来说, underscored 竞争可能来自意想不到的地方(例如,社区模型可能侵蚀你的市场部分,除非你持续改进和差异化)。
2. 生产力之外的多样性使用。 一个 surprising 发现是_角色扮演和娱乐导向使用_的绝对数量。超过一半的开源模型使用用于角色扮演和讲故事。即使在专有平台上,早期ChatGPT使用的非琐碎部分是休闲和创意,然后专业用例增长。这反驳了LLM主要用于编写代码、邮件或摘要的假设。实际上,许多用户与这些模型互动是为了陪伴或探索。这有重要含义。它 highlight 了消费者应用的实质机会,这些应用合并叙事设计、情感参与和互动性。它为个性化暗示了新前沿------发展个性、记住偏好或维持长形式互动的代理。它也重新定义了模型评估指标:成功可能较少依赖于事实准确性,更多于一致性、连贯性和维持吸引对话的能力。最后,它为AI和娱乐IP之间的交叉开辟了路径,在互动讲故事、游戏和创作者驱动的虚拟角色中具有潜力。
3. 代理 vs 人类:代理推理的兴起。 LLM使用正在从单轮交互转向_代理推理_,其中模型规划、推理和跨多个步骤执行。而不是产生一次性响应,它们现在协调工具调用,访问外部数据,并迭代优化输出以实现目标。早期证据显示上升的多步骤查询和链式工具使用,我们代理为代理使用。随着这种范式扩展,评估将从语言质量转向任务完成和效率。下一个竞争前沿是模型如何有效_执行持续推理_,这种转变可能最终重新定义大规模代理推理在实践中意味着什么。
4. 地理展望。 LLM使用变得日益_全球和分散__,在北美以外快速增长。亚洲的总token需求份额已从约13%上升到31%,反映了更强的企业采用和创新。同时,中国已崛起为主要力量 ,不仅通过国内消费也通过生产全球竞争模型。更广泛的要点:LLM必须全球有用,在语言、上下文和市场中表现良好。竞争的下一阶段将依赖文化适应性和多语言能力,不仅仅是模型规模。
5. 成本vs使用动态。 LLM市场似乎还不像商品行为:价格单独解释很少关于使用。用户平衡成本与推理质量、可靠性和能力广度。闭源模型继续捕获高价值、收入链接的工作负载,而开源模型主导低成本和高容量任务。这创建了一个动态平衡------较少由稳定性定义更多由来自下面的持续压力定义。开源模型持续推近_高效前沿_,特别是在推理和编码领域(例如,Kimi K2 Thinking),其中快速迭代和OSS创新缩小性能差距。开源模型的每次改进压缩专有系统的定价能力,迫使他们通过更优集成、一致性和企业支持来证明溢价。由此产生的竞争是快速移动、不对称和持续转变的。随时间,随着质量趋同加速,价格弹性可能增加,将曾经差异化的市场转变为更流动的市场。
6. 留存和灰姑娘水晶鞋现象。 随着基础模型飞跃而非步伐前进,留存已成为可防御性的真正衡量。每个突破创建一个短暂的发布窗口,模型可以完美"契合"高价值工作负载(灰姑娘水晶鞋时刻),一旦用户找到那种契合,他们会留下。在这个范式中,产品-市场契合等于工作负载-模型契合:作为第一个解决真正痛点的工作创造了深度、粘性采用,因为用户围绕该能力构建工作流程和习惯。然后切换变得昂贵,技术上和行为上。对于构建者和投资者,要观察的信号不是增长而是留存曲线,特别是基础队列的形成,它们通过模型更新持续存在。在日益快速移动的市场中,早期捕获这些重要未满足的需求决定了谁在下一个能力飞跃后持续。
总而言之,LLM正成为跨域推理类任务的基本计算基底,从编程到创意写作。随着模型继续进步和部署扩展,拥有真实世界使用动态的准确见解对于做出明智决策至关重要。人们使用LLM的方式不总是与期望一致,并且在国家、州、用例间显著不同。通过大规模观察使用,我们可以将我们对LLM影响的理解建立在现实基础上,确保后续发展,无论是技术改进、产品功能还是法规,与实际使用模式和需求一致。我们希望这项工作作为更多实证研究的基础,并鼓励AI社区在我们构建下一代前沿模型时持续从真实世界使用中测量和学习。
局限性
本研究反映了在单一平台(即OpenRouter)上观察到的模式,并在有限时间窗口内,仅提供更广泛生态系统的部分视图。某些维度,如企业使用、本地托管部署或封闭内部系统,仍然超出我们数据的范围。此外,我们的几个数据分析依赖于_代理度量_:例如,通过多步骤或工具调用调用识别代理推理,或从账单而非验证位置数据推断用户地理。因此,结果应解释为指示性行为模式,而非底层现象的明确测量。
结论
本研究提供了大型语言模型如何嵌入世界计算基础设施的实证视角。它们现在是工作流程、应用程序和代理系统的组成部分,转换信息如何生成、中介和消费。
过去一年催化了该领域如何概念化_推理_的步骤变化。_o1_类别模型的出现 normalizes 扩展审议和工具使用,将评估从单次基准转向基于过程的度量、延迟-成本权衡和编排下的任务成功。推理已成为模型如何有效规划和验证以提供更可靠结果的衡量。
数据显示LLM生态系统在结构上是多元的。没有单一模型或提供商主导;相反,用户沿多个轴选择系统,如能力、延迟、价格和信任,取决于上下文。这种异质性不是暂态阶段,而是市场的基本属性。它促进快速迭代并减少对任何单一模型或堆栈的系统性依赖。
推理本身也在变化。多步骤和工具链接交互的兴起标志着从静态完成向动态编排的转变。用户正在链合模型、API和工具以实现复合目标,产生可描述为_代理推理_的现象。有许多理由相信代理推理将超过,如果还没有,人类推理。
地理上,景观变得更加分散。亚洲使用份额继续扩展,中国特别 emerged 为模型开发者和出口商,由Moonshot AI、DeepSeek和Qwen等参与者的崛起证明。非西方开源权重模型的成功显示LLM是真正的全球计算资源。
实际上,_o1_没有结束竞争。远非如此。它扩展了设计空间。该领域正转向系统思维而非单体赌注,转向仪表化而非直觉,转向实证使用分析而非排行榜差异。如果过去一年证明代理推理在大规模上可行,下一个将专注于运营卓越:测量真实任务完成,减少分布转移下的方差,以及将模型行为与生产规模工作负载的实际需求对齐。
参考文献
-
R. Appel, J. Zhao, C. Noll, O. K. Cheche, and W. E. Brown Jr. Anthropic economic index report: Uneven geographic and enterprise AI adoption. arXiv preprint arXiv:2511.15080 , 2025. URL arxiv.org/abs/2511.15....
-
A. Chatterji, T. Cunningham, D. J. Deming, Z. Hitzig, C. Ong, C. Y. Shan, and K. Wadman. How people use chatgpt. NBER Working Paper 34255 , 2025. URL cdn.openai.com/pdf/a253471....
-
W. Zhao, X. Ren, J. Hessel, C. Cardie, Y. Choi, and Y. Deng. WildChat: 1M ChatGPT interaction logs in the wild. arXiv preprint arXiv:2405.01470 , 2024. URL arxiv.org/abs/2405.01....
-
OpenAI. OpenAI o1 system card. arXiv preprint arXiv:2412.16720 , 2024. URL arxiv.org/abs/2412.16....
-
W. L. Chiang, L. Zheng, Y. Sheng, A. N. Angelopoulos, T. Li, D. Li, H. Zhang, B. Zhu, M. Jordan, J. Gonzalez, and I. Stoica. Chatbot Arena: An open platform for evaluating LLMs by human preference. arXiv preprint arXiv:2403.04132 , 2024. URL arxiv.org/abs/2403.04....
-
J. Wei, X. Wang, D. Schuurmans, M. Bosma, E. H. Chi, F. Xia, Q. Le, and D. Zhou. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems , 35:24824--24837, 2022. URL proceedings.neurips.cc/paper_files....
-
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao. ReAct: Synergizing reasoning and acting in language models. International Conference on Learning Representations (ICLR) , 2023. URL arxiv.org/abs/2210.03....
-
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fan, et al. The Llama 3 Herd of Models. arXiv preprint arXiv:2407.21783 , 2024. URL arxiv.org/abs/2407.21....
-
DeepSeek-AI, A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, et al. DeepSeek-V3 technical report. arXiv preprint arXiv:2412.19437 , 2024. URL arxiv.org/abs/2412.19....
贡献者
这项工作可能归功于OpenRouter团队开发的基础平台、基础设施、数据集和技术愿景。特别是,Alex Atallah、Chris Clark、Louis Vichy提供了使本研究中的探索成为可能的工程基础和架构方向。Justin Summerville提供了实现、测试和实验优化的基础支持。额外贡献包括Natwar Maheshwari的发布支持和Julian Thayn的设计编辑。
Malika Aubakirova(a16z)担任首席作者,负责实验设计、实现、数据分析和论文的完整准备。Anjney Midha提供了战略指导并塑造了总体框架和方向。
早期探索性实验和系统设置得到Abhi Desai在a16z实习期间的支持。Rajko Radovanovic和Tyler Burkett在a16z全职任职期间提供了有针对性的技术见解和实际帮助,加强了工作的几个关键组件。
所有贡献者都参与了讨论、提供了反馈并审查了最终手稿。
附录
类别细分组成详情
下图分解了三个主要领域的内部子标签结构:角色扮演、编程和技术。每个领域表现出不同的内部模式,揭示用户如何在这些类别中与LLM互动。
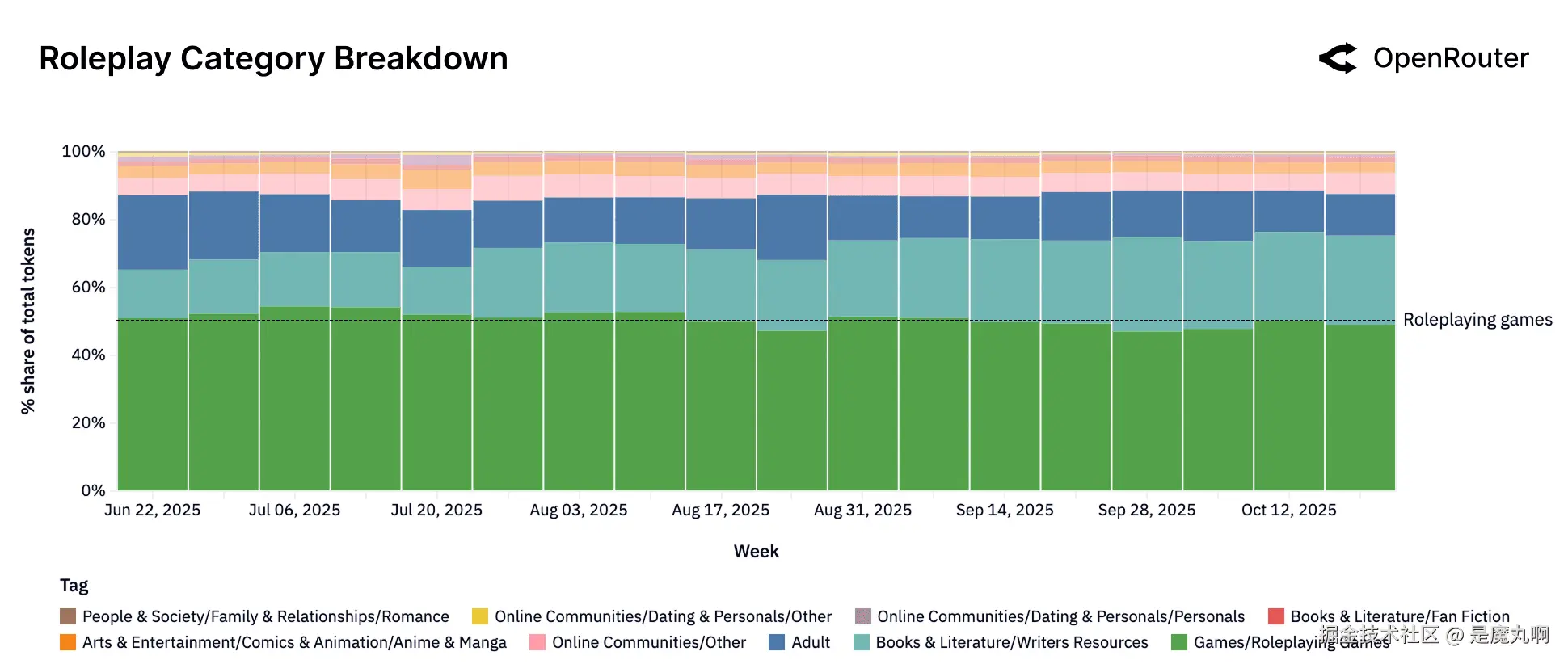
角色扮演(子标签)。 Token划分为_角色扮演游戏_场景(58%)和其他创意对话(人格聊天、叙事合著等)。
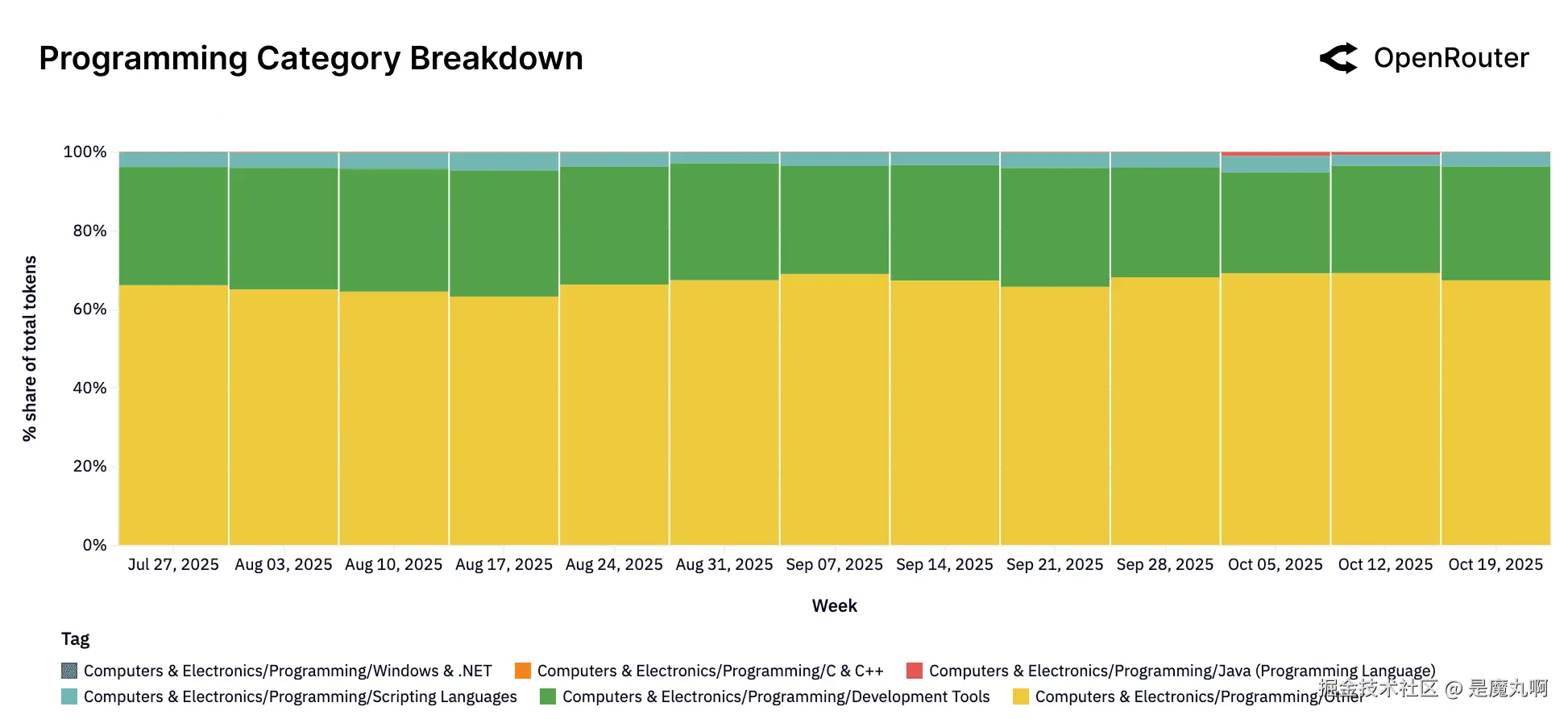
编程(子标签)。 通用编码任务构成大多数(没有单一特定领域主导),较小份额为web开发、数据科学等,表明跨编程主题的广泛使用。
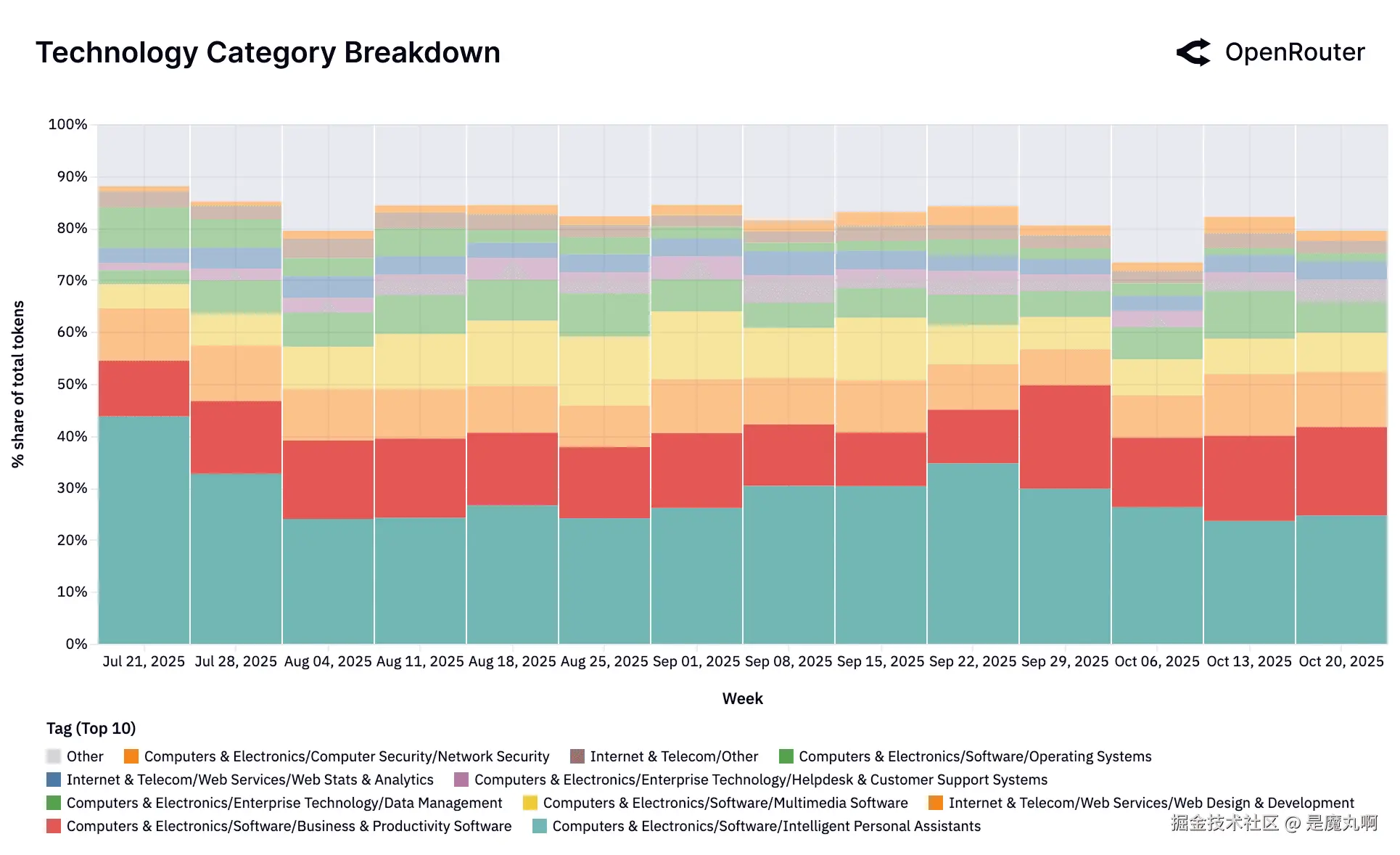
技术(子标签)。 由_智能助手_和_生产力软件_使用案例主导(合计约65%),其次是IT支持和消费电子产品查询。
所有三个领域(角色扮演、技术、编程)都表现出不同的内部模式,反映用户如何在每个主要领域内跨不同子类别与LLM互动。