TRAE 是字节跳动于 2025 年 1 月发布的 AI 原生集成开发环境(AI IDE),其名字源于 "The Real AI Engineer",定位为 "智能协作 AI IDE"。最近又推出了SOLO模式,TRAE 的 SOLO 模式是一种以 AI 为主导的高度自动化开发模式,2025 年 7 月先推出 Beta 版,11 月迭代为正式版并同步上线国内版,国内版所有核心功能均免费开放。它定位为 "The Responsive Coding Agent",能自主完成从需求理解到部署的全流程开发任务。简单来说,就是可以让AI自动进行需求理解,环境配置,代码编写和测试的全流程,只要提出我们的需求,AI就会自己去编程实现,非常方便。最近我也安装了这款IDE,尝鲜试用了一下,还是不错的。我用TRAE和LangChain完成了一个比较简单的电影数据分析案例,目的是从豆瓣电影网站上获取近1年来的电影数据,通过大模型进行查询和分析,用到了postgresql MCP以及阿里推出的mcp-server-chart。
流程图如下:
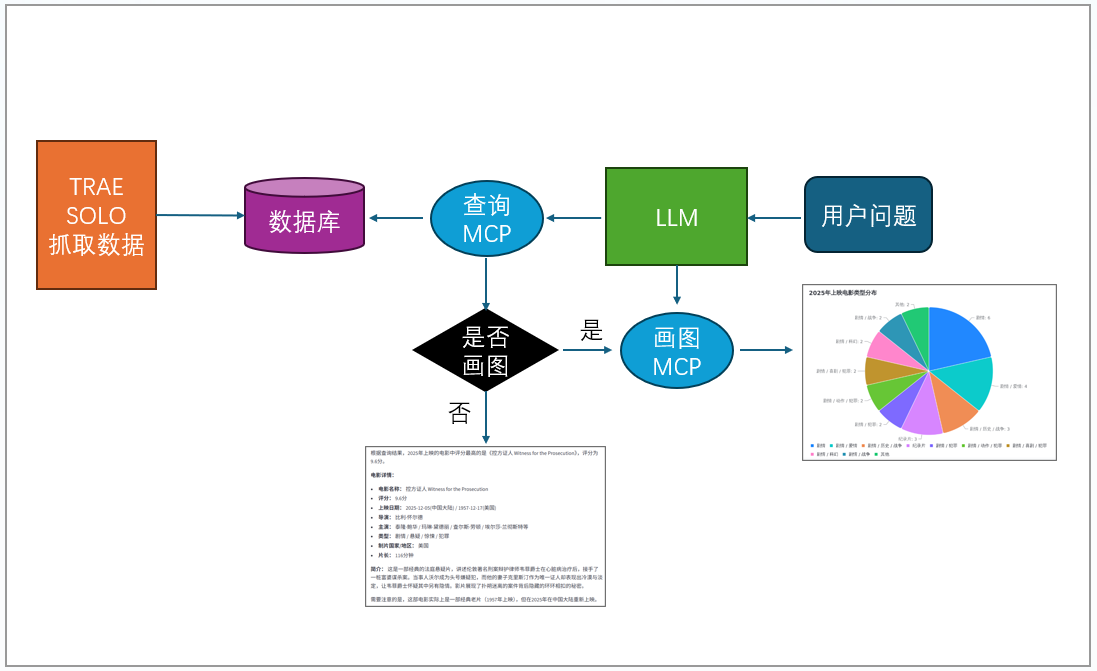
首先,我们需要设计数据库,因为我们获取的数据需要存储到数据库中,我选择了Postgresql数据库,因为工作中用的比较多。
根据豆瓣电影页面,我设计了11个字段,包括主键id,电影名称name,导演director,主演actor,类型category,制片国家/地区country,语言language,上映日期release_date,片长runtime,简介abstract,评分score。
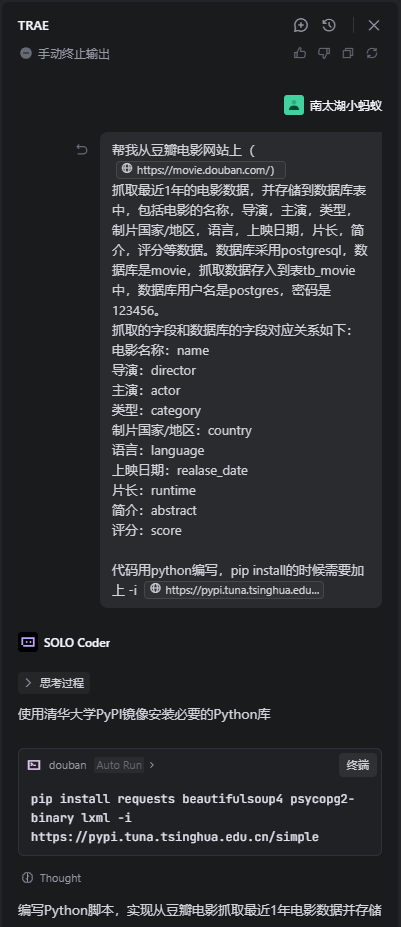
我输入了如下的请求给SOLO,让他帮我抓取最近1年的电影数据,并存储到数据库中,告诉了他数据库名称和表名,以及数据库用户名和密码,同时,我告诉他需要安装包的时候要从国内清华的镜像上去下载包。
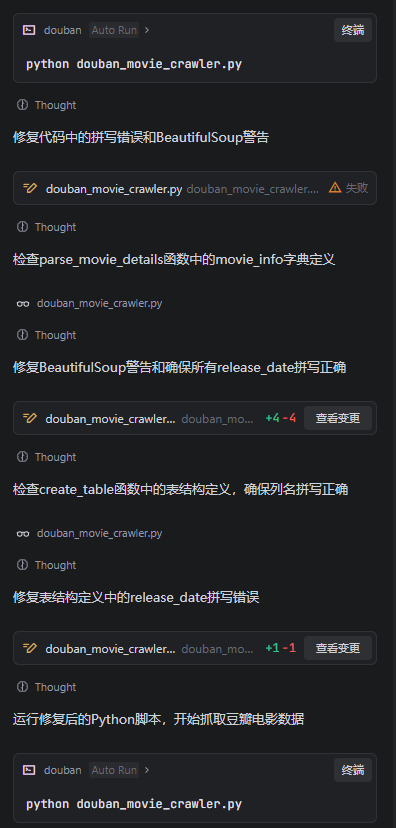
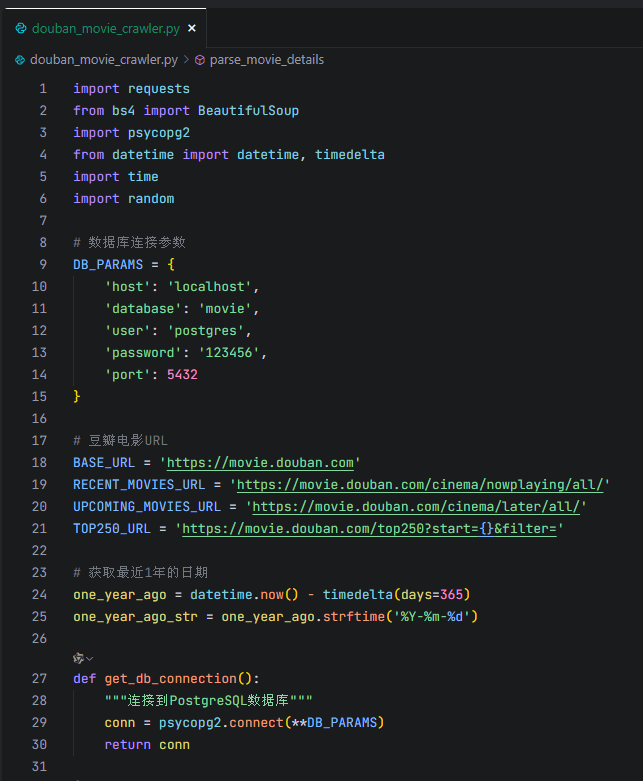
SOLO运行了大约15分钟左右,期间经过了多次尝试,发现了字段名的错误,并自己进行了修改,最终完成了如下的程序(这里只贴了前面的30行),并实现数据的抓取:
自动生成的代码:
数据库查询结果:
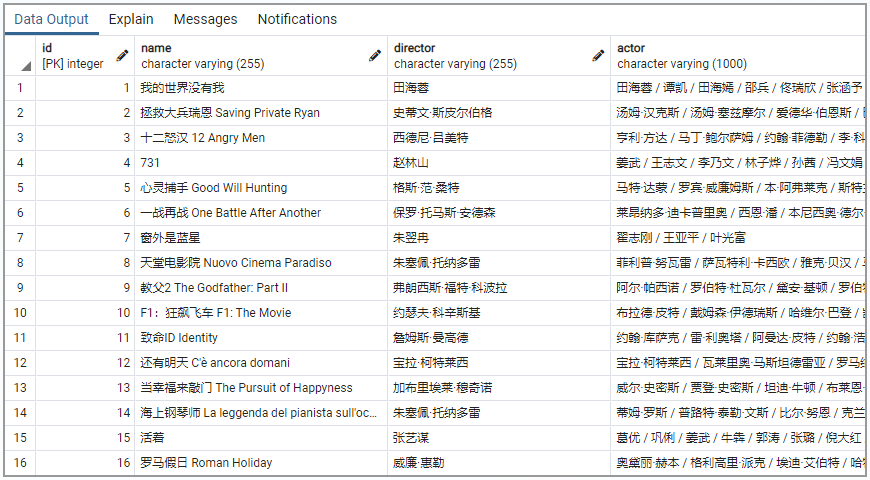
可以看到数据已经存储到了数据库中。下一步我们就可以构建一个查询数据库的问答系统。我这里采用了postgresql mcp来查询数据库,并采用阿里巴巴推出的mcp-server-chart。阿里巴巴(蚂蚁集团)AntV 团队开源的mcp-server-chart是一款基于 MCP(Model Context Protocol)协议的图表生成服务,支持大模型与 AI 工具一键调用,可快速生成 20 + 种专业图表,返回高质量图片链接。
核心代码如下,主要是使用了langgraph.prebuilt下的create_react_agent来构建一个智能代理,调用MCP工具进行查询:
python
async def stream_answer(query:str):
# 加载 MCP 配置
client = MultiServerMCPClient(
{
"postgres": {
"command": "cmd",
"args": [
"/c",
"npx",
"-y",
"@modelcontextprotocol/server-postgres",
"postgresql://postgres:123456@localhost:5432/movie"
],
"transport": "stdio",
},
"mcp-server-chart": {
"command": "cmd",
"args": [
"/c",
"npx",
"-y",
"@antv/mcp-server-chart"
],
"transport": "stdio",
}
}
)
system_prefix = """
请讲中文
当用户提问中涉及电影信息时,需要使用postgresql MCP进行数据查询和操作,仅返回前十条数据,表结构如下:
## 电影表(tb_movie)
"table_name": "tb_movie",
"description": "电影表",
"columns":[
{"column_name": "id","chinese_name": "标识码","data_type": "int"},
{"column_name": "name","chinese_name": "电影名称","data_type": "varchar"},
{"column_name": "actor","chinese_name": "主演","data_type": "varchar"},
{"column_name": "director","chinese_name": "导演","data_type": "varchar"},
{"column_name": "category","chinese_name": "类型","data_type": "varchar"},
{"column_name": "country","chinese_name": "制片国家/地区","data_type": "varchar"},
{"column_name": "language","chinese_name": "语言","data_type": "varchar"},
{"column_name": "release_date","chinese_name": "上映日期","data_type": "varchar"},
{"column_name": "runtime","chinese_name": "片长","data_type": "varchar"},
{"column_name": "abstract","chinese_name": "简介","data_type": "varchar"},
{"column_name": "score","chinese_name": "评分","data_type": "varchar"}
]
当用户提及画图时,返回数据按照如下格式输出,输出图片URL后直接结束,不要输出多余的内容:
1.查询结果:{}
2.图表展示:{图片URL}
否则,直接输出返回结果。
"""
tools = await client.get_tools()
agent = create_react_agent(
model, # LLM大模型
tools # MCP工具
)
result = await agent.ainvoke({
"messages": [
{"role":"system", "content":system_prefix},
{"role":"user", "content":query}
]
})
return result["messages"][-1].content下面,我们构建应用界面,界面的话使用Streamlit来构建。Streamlit 是一款 开源的 Python 库,专为数据科学家、机器学习工程师设计,核心定位是「快速构建数据应用的低代码工具」------ 无需前端开发经验(HTML/CSS/JS),仅用纯 Python 代码,就能在几分钟内将数据脚本、模型推理逻辑转化为可交互的 Web 应用,大幅降低数据可视化与 AI 应用落地的门槛。Streamlit非常好用,适合用来实现一些简单的应用以及搭建原型,当然如果要产品化的还是建议使用Vue等成熟的Web框架来构建UI。Streamlit构建的UI界面如下,当返回数据中包含图片URL时,自动展示图片,如果没有图片就直接返回文字:
python
import streamlit as st
from langchain_openai import ChatOpenAI
import asyncio
from langchain_db import stream_answer
import re
chat = ChatOpenAI(
streaming=True,
model='deepseek-chat',
openai_api_key=<你的API KEY>,
openai_api_base='https://api.deepseek.com',
max_tokens=1024
)
def find_urls_in_text(text):
"""
从给定的文本中找出所有的URL。
参数:
text (str): 要从中提取URL的文本。
返回:
list: 包含所有找到的URL的列表。
"""
# 正则表达式模式,用于匹配URL
url_pattern = r'(https?://\S+|www\.\S+)'
# 使用re.findall()查找所有匹配项
urls_found = re.findall(url_pattern, text)
# 确保匹配到的URL包含协议前缀,如果没有,则添加http://
for i, url in enumerate(urls_found):
if not re.match(r'^https?:', url):
urls_found[i] = 'http://' + url
return urls_found
async def main():
st.title("电影知识库")
question = st.text_input("请输入查询内容:")
if st.button("执行查询"):
if question:
result = await stream_answer(question)
urls = find_urls_in_text(result)
# 如果有图片,则获取URL展示图片
if(len(urls) > 0):
result = result.replace(urls[0], "")
result = result.replace("\n\n", "\n")
arr = result.split("图表展示:")
print(len(arr))
if(len(arr) > 1):
result1 = arr[0]
result2 = arr[1]
st.write(result1)
st.image(urls[0])
st.write(result2)
else:
result1 = arr[0]
st.write(result1)
st.image(urls[0])
else:
st.write(result)
else:
st.write("查询出错,请检查输入或数据库连接。")
if __name__ == "__main__":
asyncio.run(main())测试结果如下:
1.当所提问题不需要画图的时候,直接返回查询的结果,大模型会对返回的结果进行包装和总结。

2.当所提的问题需要画图统计图表时,系统会先返回查询结果,再把返回的图片URL直接展示在界面上。


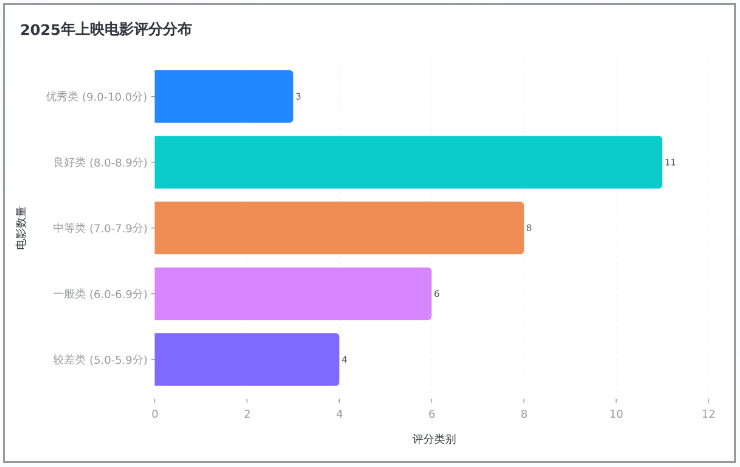
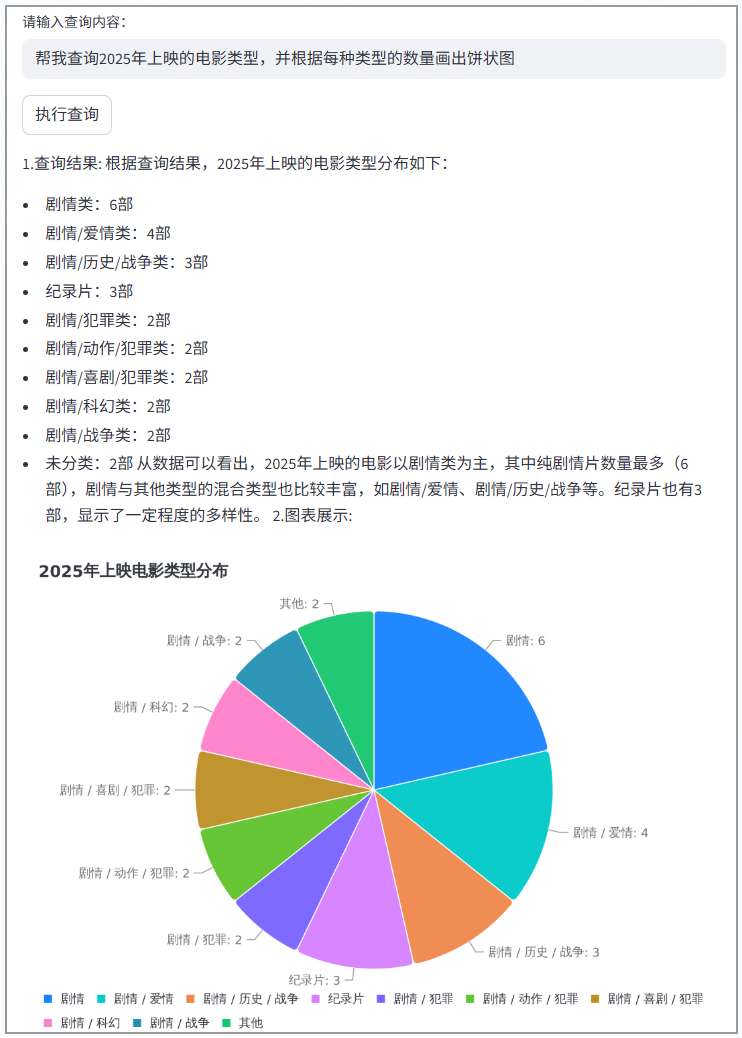
总的来说,TRAE的SOLO模式给我们提供了一种新的编程模式,可以让AI工具辅助我们设计出总体的框架并完成主题功能的编写,不过要注意的是,我们不能完全依赖于AI工具来完成工作,因为AI生成的代码还是有不少问题的,而且效率未必高,因此大多数情况下,我们仍然需要对代码进行微调,不过AI工具确实极大的提高了我们的生产效率。