文章目录
- 1.项目的测试背景
- [2. 项目测试工具](#2. 项目测试工具)
- 3.手动对项目功能进行Web的基本功能测试
-
- [3.1 设计测试用例方法](#3.1 设计测试用例方法)
- [3.2 个人博客系统的设计测试用例脑图如下:](#3.2 个人博客系统的设计测试用例脑图如下:)
- [3.3 登录页面测试](#3.3 登录页面测试)
- [3.4 博客列表页面测试](#3.4 博客列表页面测试)
- [3.5 博客详情页面测试](#3.5 博客详情页面测试)
- [3.6 博客编辑页面测试](#3.6 博客编辑页面测试)
- [3.7 删除博客测试](#3.7 删除博客测试)
- [3.8 退出博客测试](#3.8 退出博客测试)
- 4.使用Selenium进行Web自动化测试(Python)
-
- [4.1 参照测试用例,编写自动化脚本](#4.1 参照测试用例,编写自动化脚本)
-
- [4.1.1 创建驱动对象](#4.1.1 创建驱动对象)
- [4.1.2 创建驱动对象步骤](#4.1.2 创建驱动对象步骤)
- [4.1.3 博客登录的自动化测试](#4.1.3 博客登录的自动化测试)
- [4.1.4 博客列表页的自动化测试](#4.1.4 博客列表页的自动化测试)
- [4.1.5 博客详情页的自动化测试](#4.1.5 博客详情页的自动化测试)
- [4.1.6 博客编辑页的自动化测试](#4.1.6 博客编辑页的自动化测试)
- [4.1.7 博客退出的自动化测试](#4.1.7 博客退出的自动化测试)
- 5.自动化测试的特点和优点
- 6.使用jmeter对博客系统进行性能测试
-
- [6.1 测试登录接口](#6.1 测试登录接口)
- [6.2 测试博客列表页接口](#6.2 测试博客列表页接口)
- [6.3 测试博客用户个人信息接口](#6.3 测试博客用户个人信息接口)
- [6.4 测试博客详情页接口](#6.4 测试博客详情页接口)
- [6.5 测试添加博客接口](#6.5 测试添加博客接口)
- [6.6 完善测试细节](#6.6 完善测试细节)
-
- [6.6.1 测试添加JSON断言](#6.6.1 测试添加JSON断言)
- [6.6.2 添加CSV数据文件设置](#6.6.2 添加CSV数据文件设置)
- [6.6.3 真正的性能测试](#6.6.3 真正的性能测试)
- [6.6.4 生成测试报告](#6.6.4 生成测试报告)
- [7. 自动化测试源码及性能测试链接](#7. 自动化测试源码及性能测试链接)
1.项目的测试背景
博客系统由五个页面构成:用户登录页面,博客列表页面,博客详情页面,博客编辑页面,博客发布页,为了验证个人博客系统的功能是否正常,现在对博客系统进行手动和自动化测试,以确保用户能够正常使用博客系统,项目的具体测试内容为:博客系统的登录,博客列表页、博客详情页、还有博客编辑页的页面呈现和功能,写博客,删除博客,退出博客登录的功能是否正常,个人博客系统可以实现发布个人博客,记录博客发布日期、时间、标题等信息。
2. 项目测试工具
- Xmind(编写测试用例)
- 谷歌浏览器版本142.0.7444.176
- PyCharm 2024.1.6 、python版本3.13.0
- selenium库版本4.0.0、webdriver-manager版本4.0.2
- jmeter工具
- postman工具
3.手动对项目功能进行Web的基本功能测试
3.1 设计测试用例方法
设计测试用例我们一般从功能测试、性能测试、界面测试、兼容性测试、易用性测试、安全测试这六个方面进行用例设计,个人实现的博客系统是一个web网址,我们主要对其核心功能和界面元素进行测试
3.2 个人博客系统的设计测试用例脑图如下:
针对博客系统的功能和界面元素得到的测试用例脑图总图:
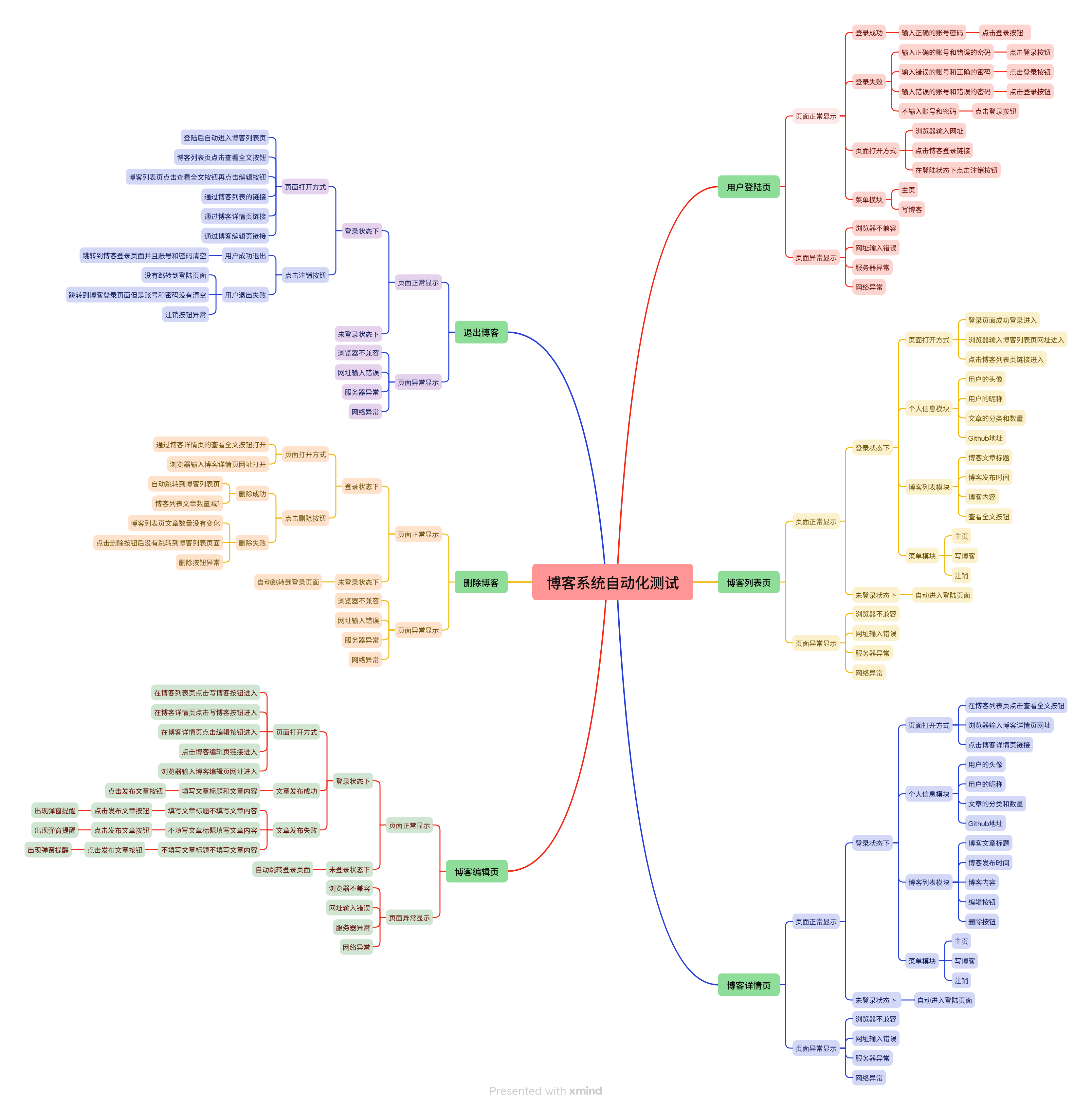
下面分别是用户登录页面,博客列表页面,博客详情页面,博客编辑页面,删除博客、退出博客等六个模块的测试用例脑图。
用户登录页面:
博客例表页面:
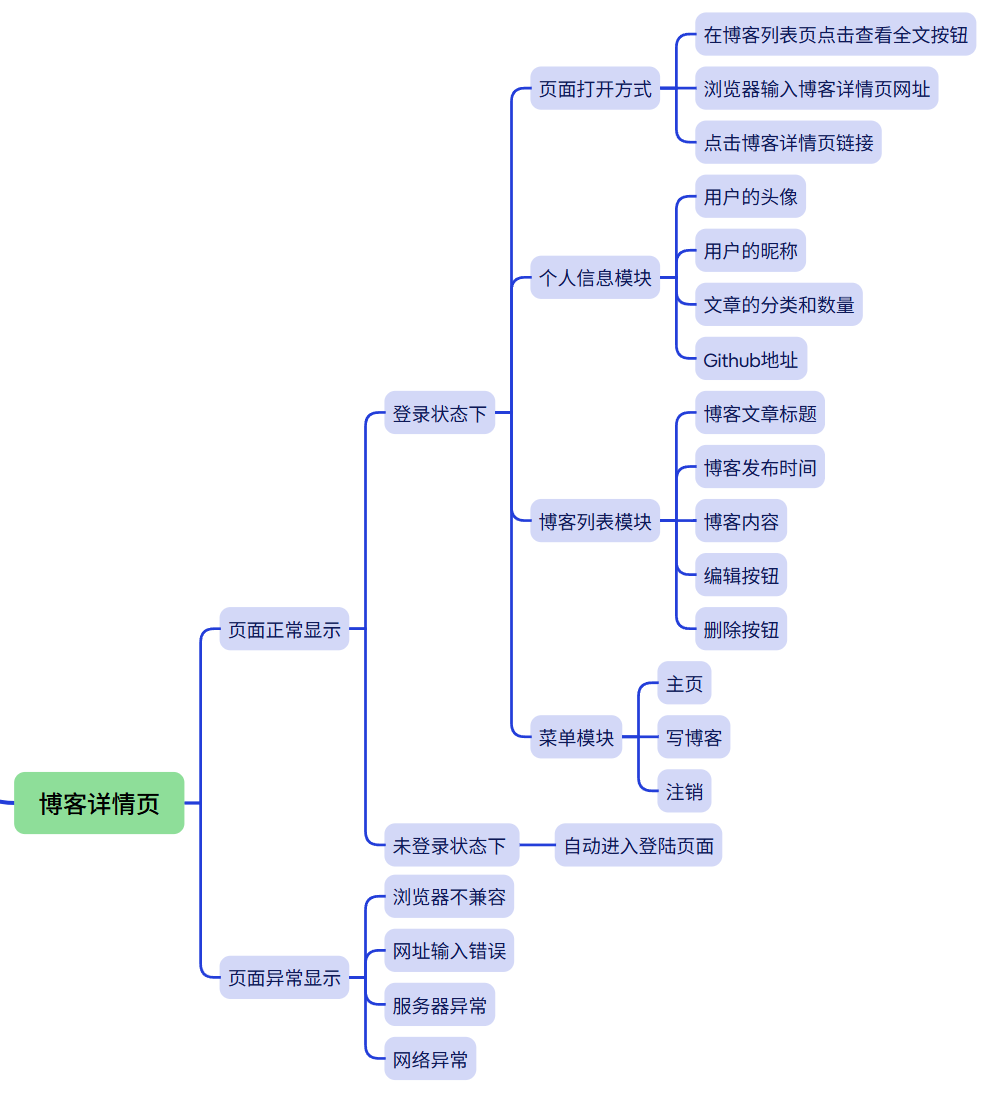
博客详情页面
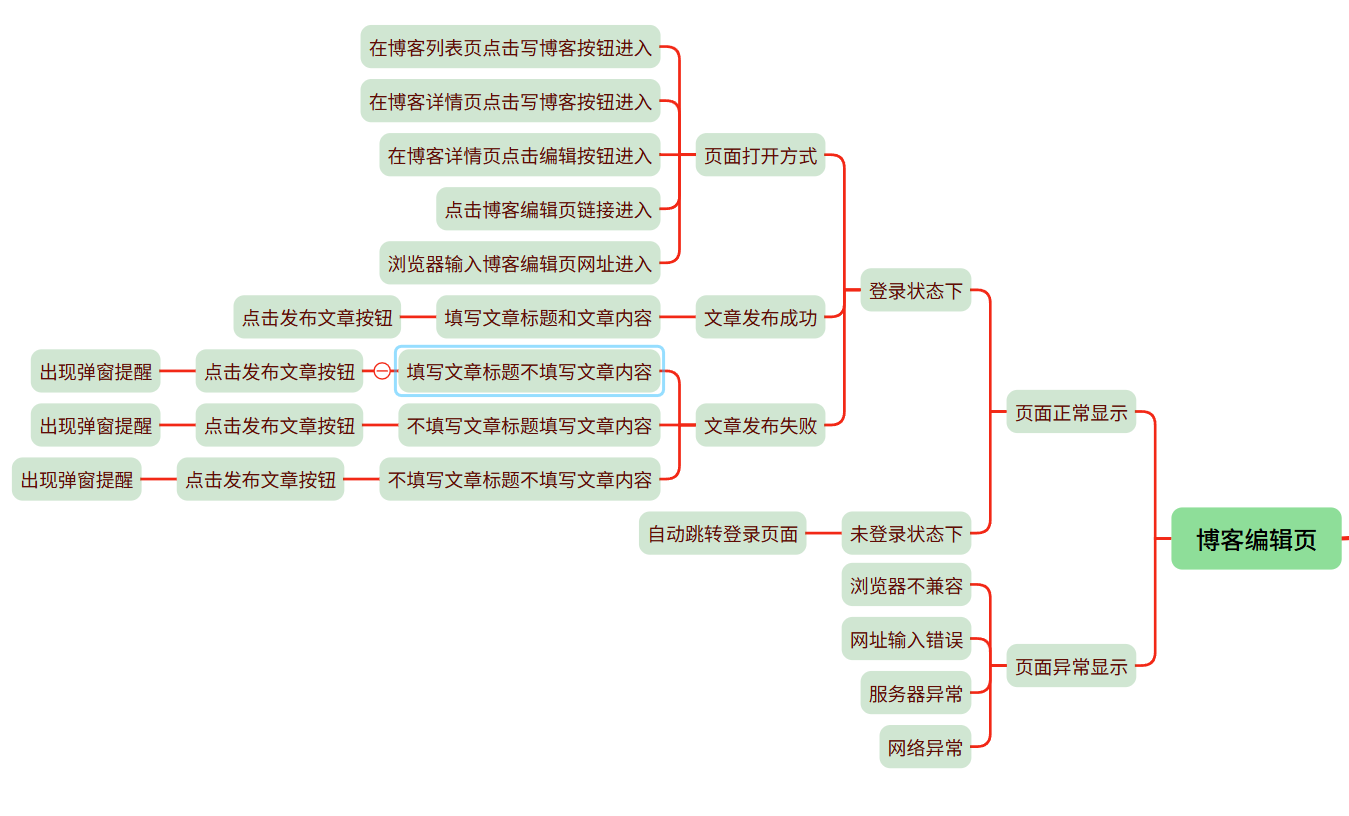
博客编辑页面
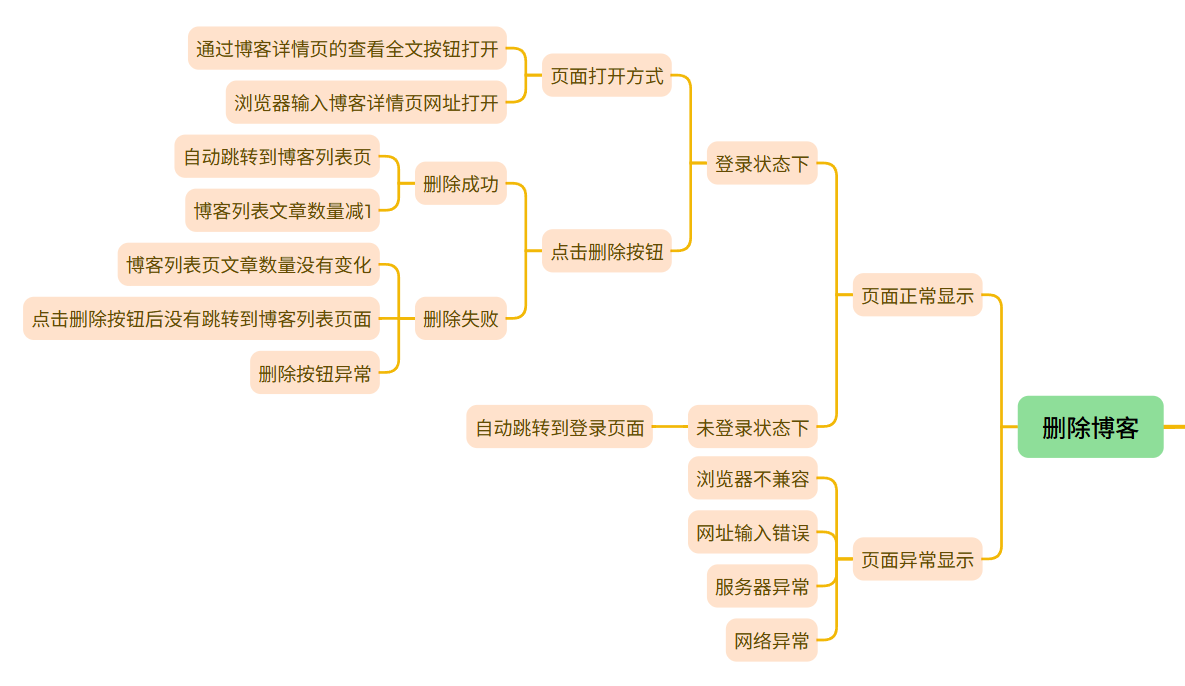
删除博客
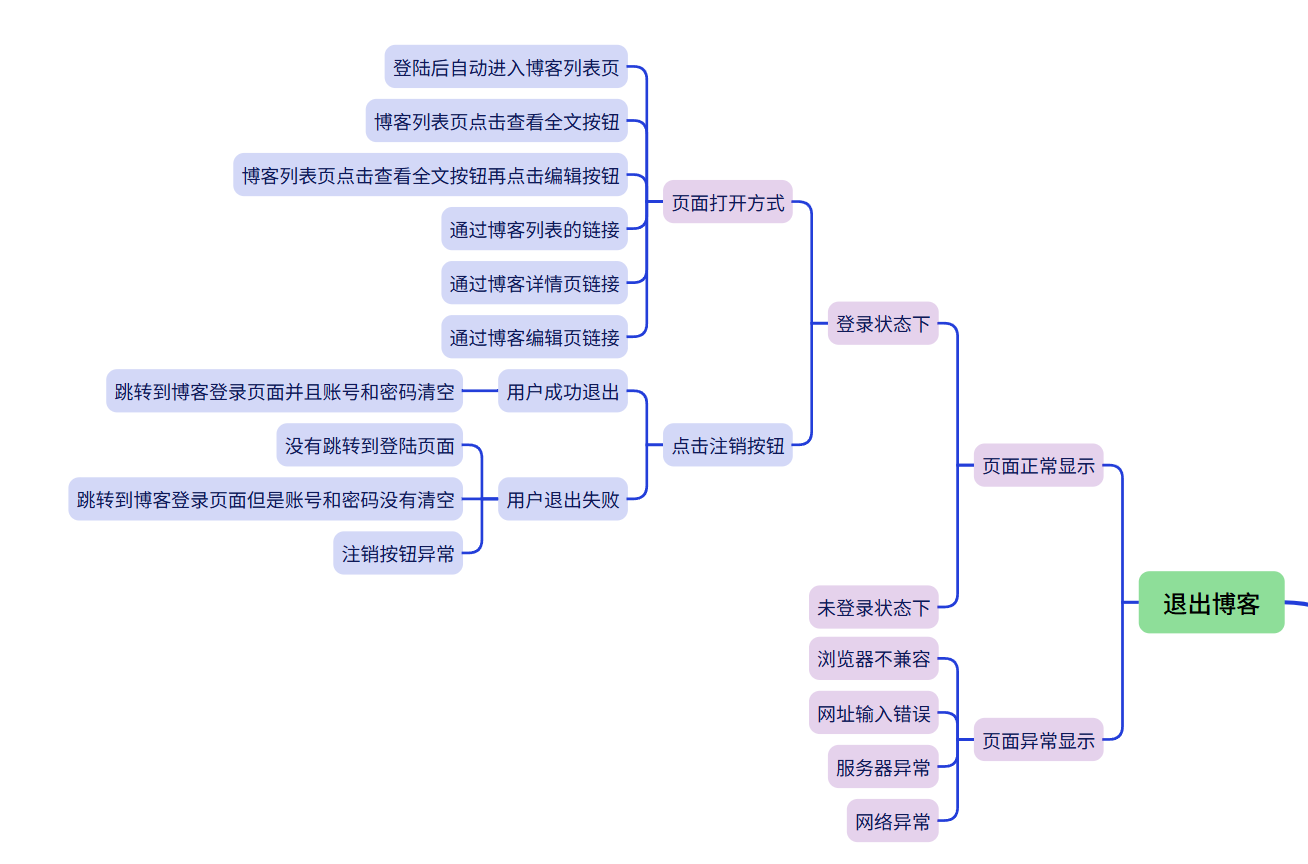
退出博客
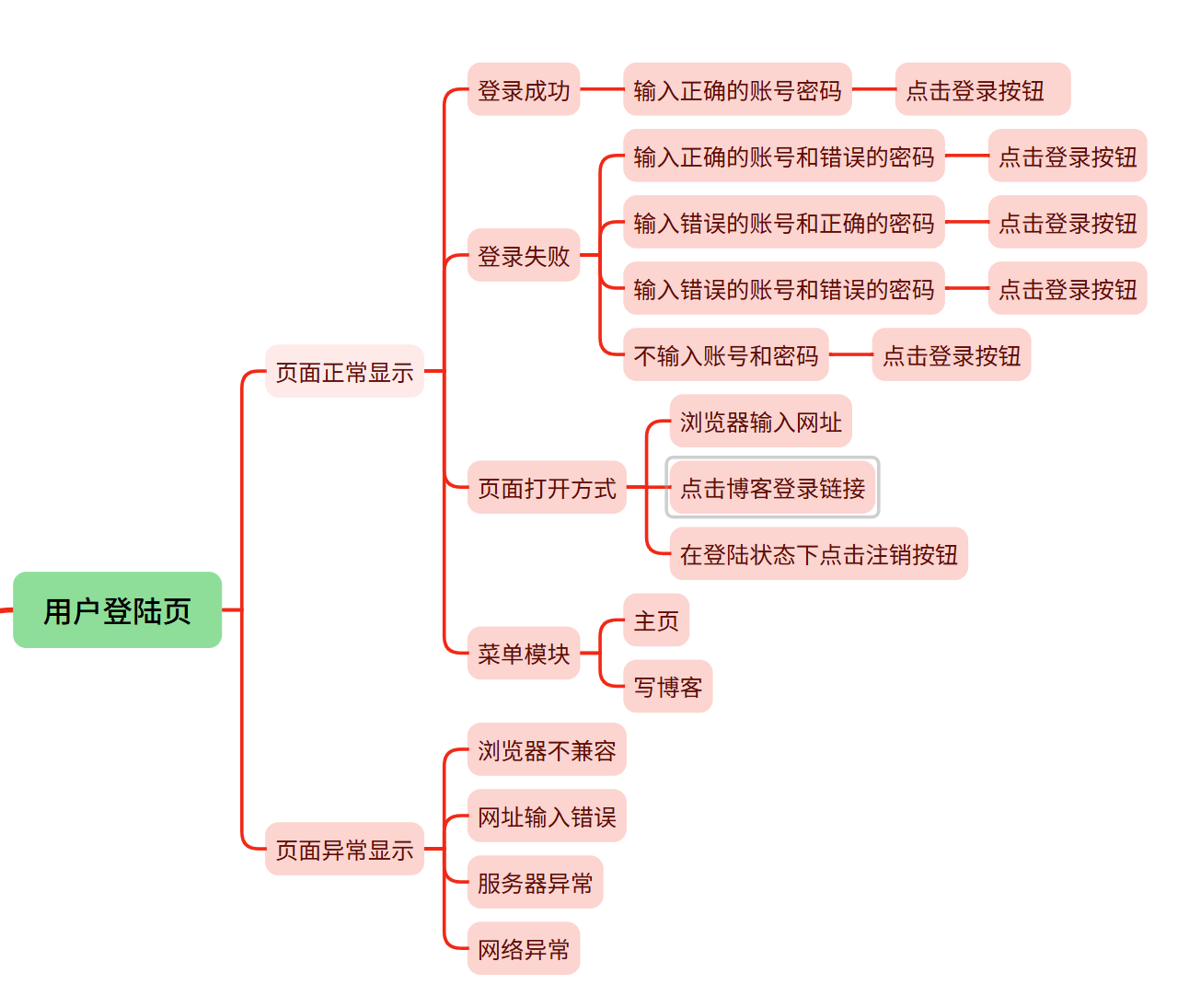
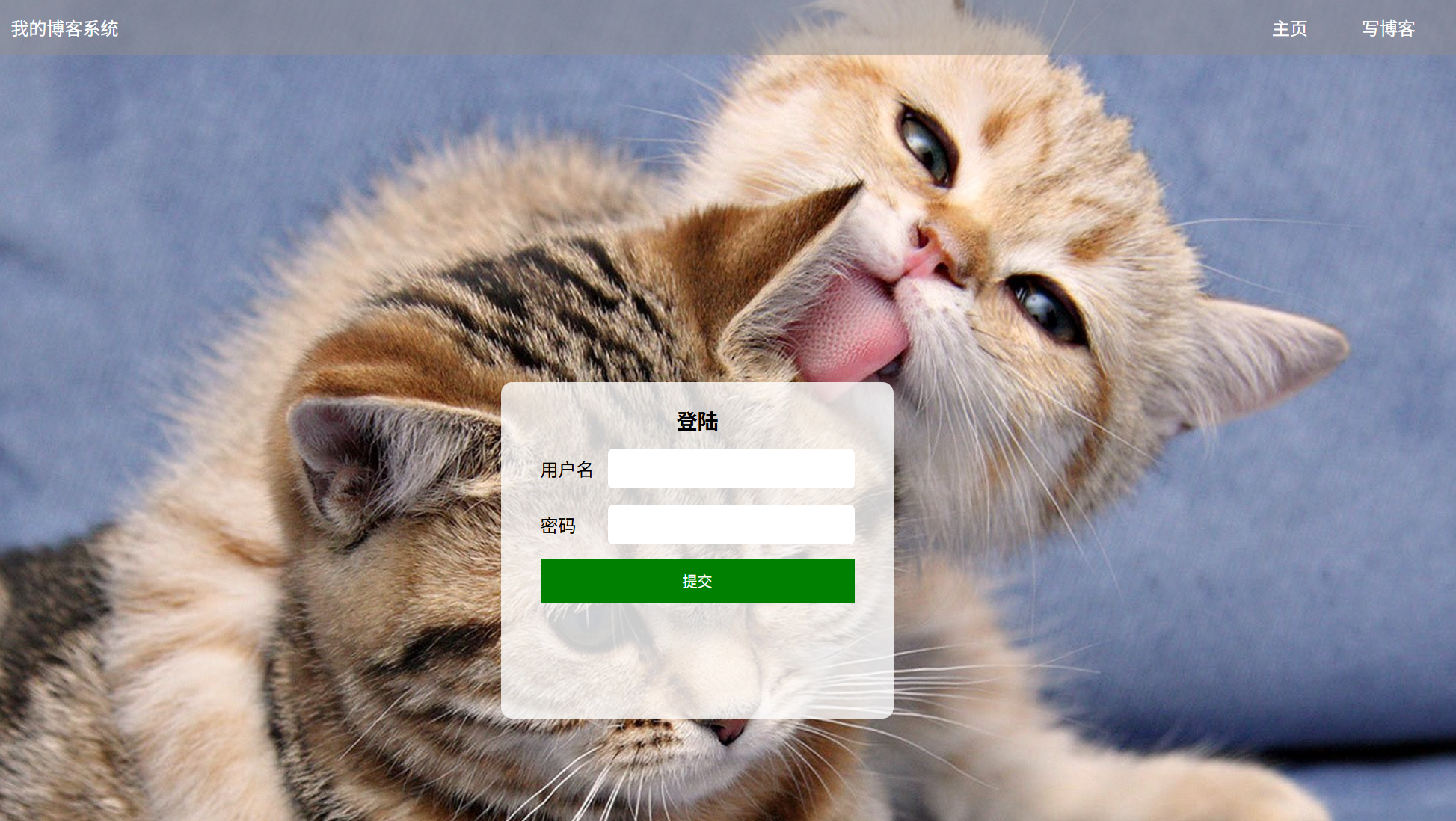
3.3 登录页面测试
(简介):因为账号和密码都已经储存在数据库里面,只要对应的输入框输入正常的账号和密码就可以,跳转到博客列表页了
(a)登录页面展示:
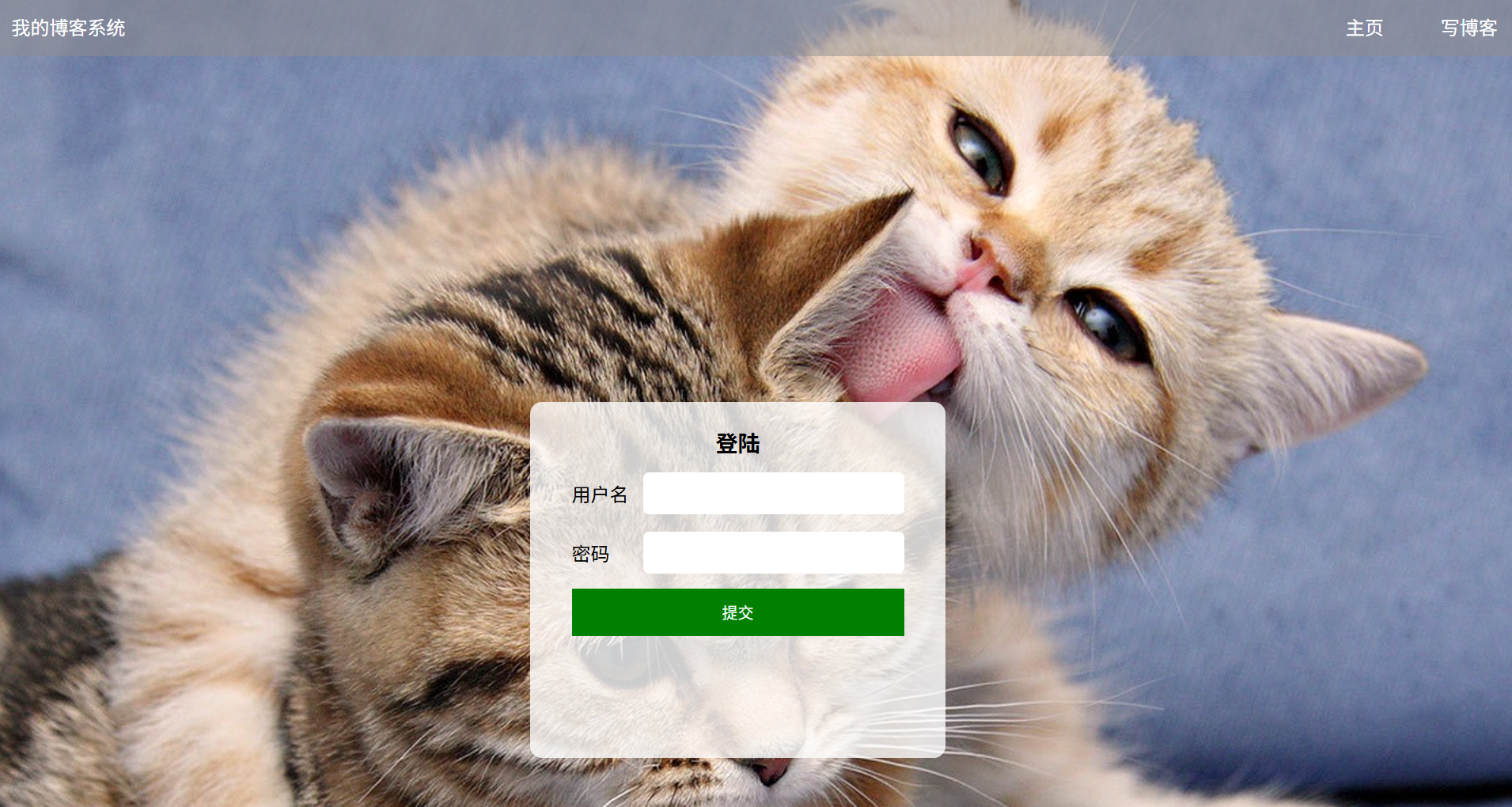
(b)输入框输入正确的账号和正确的密码:(账号:zhangsan 密码:123456)
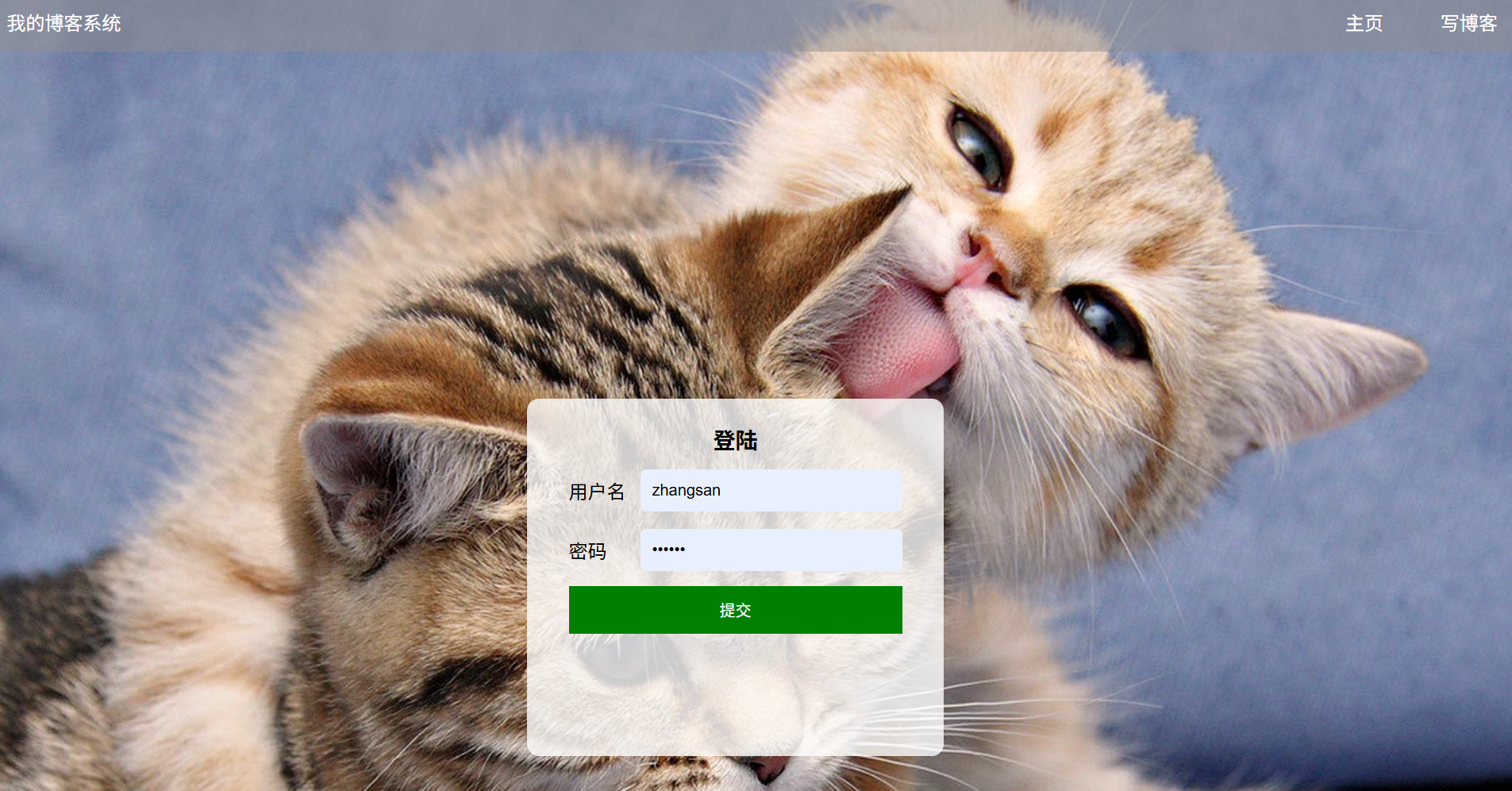
预期效果:登录成功并跳转到博客列表页
实际效果展示:
(c)c1:输入框输入正确的账号和错误的密码:(账号:zhangsan 密码:1)
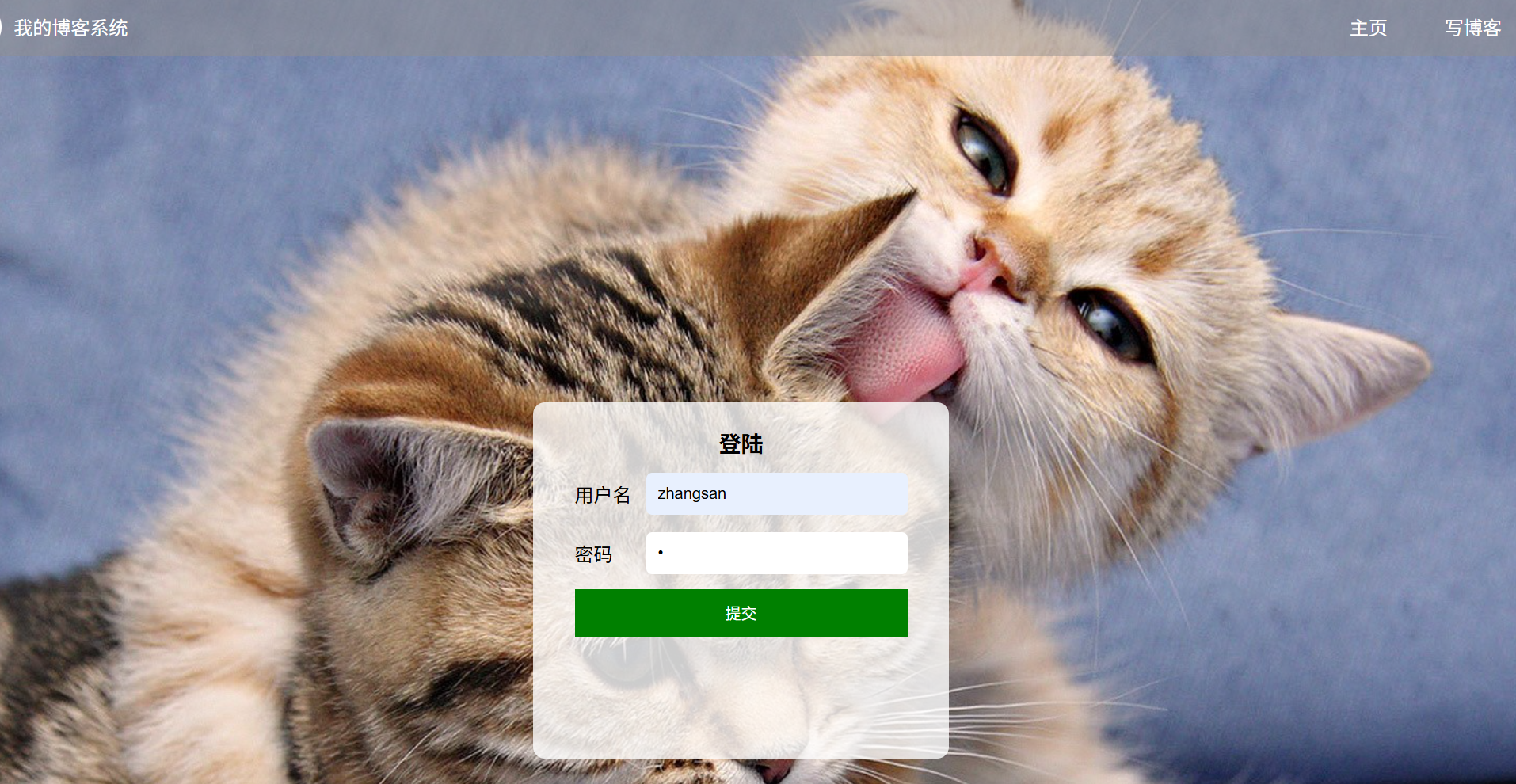
预期效果:登录失败并跳出警告弹窗提示密码错误
实际效果展示:
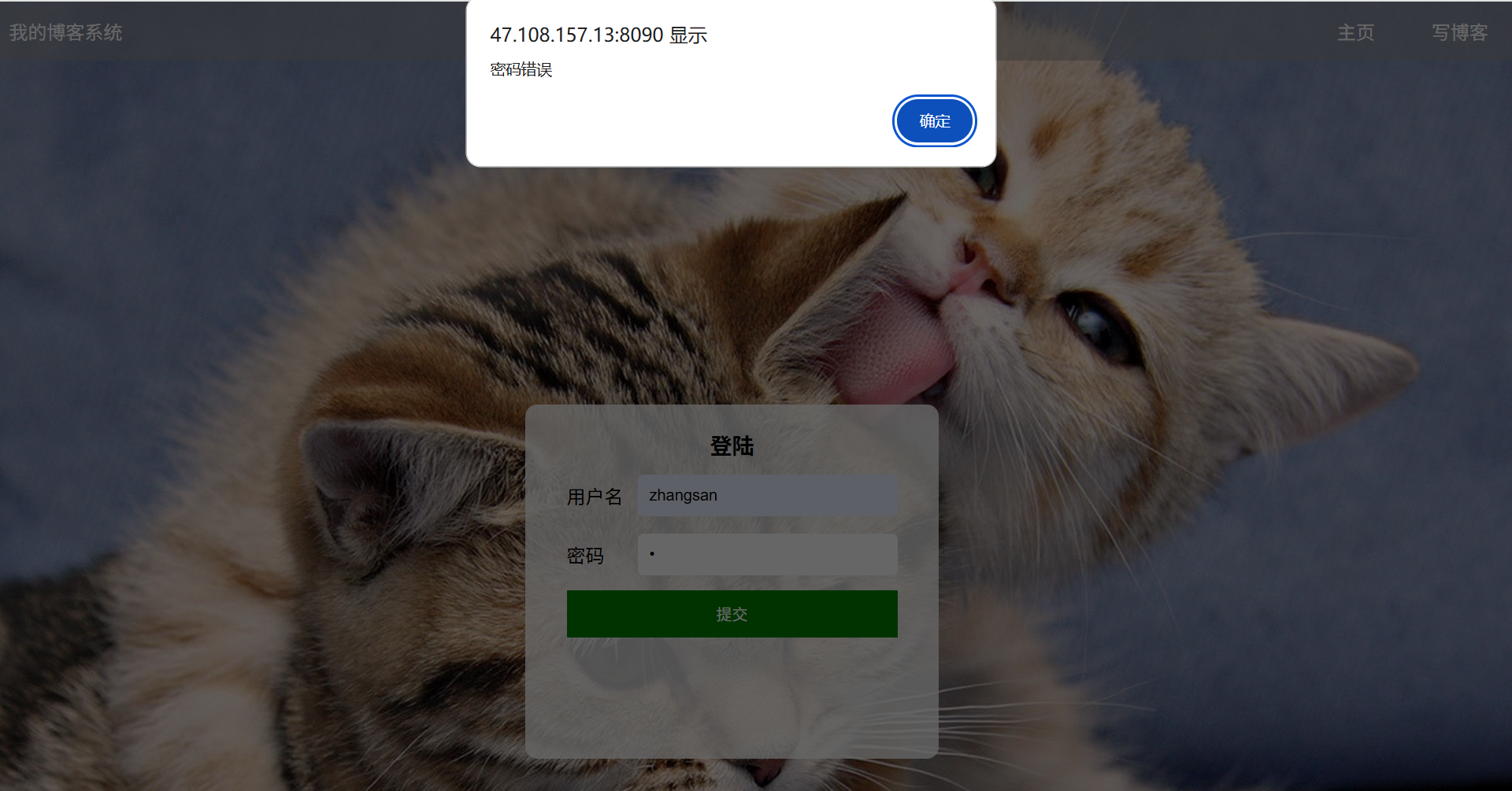
(c2):输入框输入错误的账号和正确的密码:(账号:zhang 密码:123456)
预期效果:登录失败并跳出警告弹窗提示用户不存在
实际效果展示:
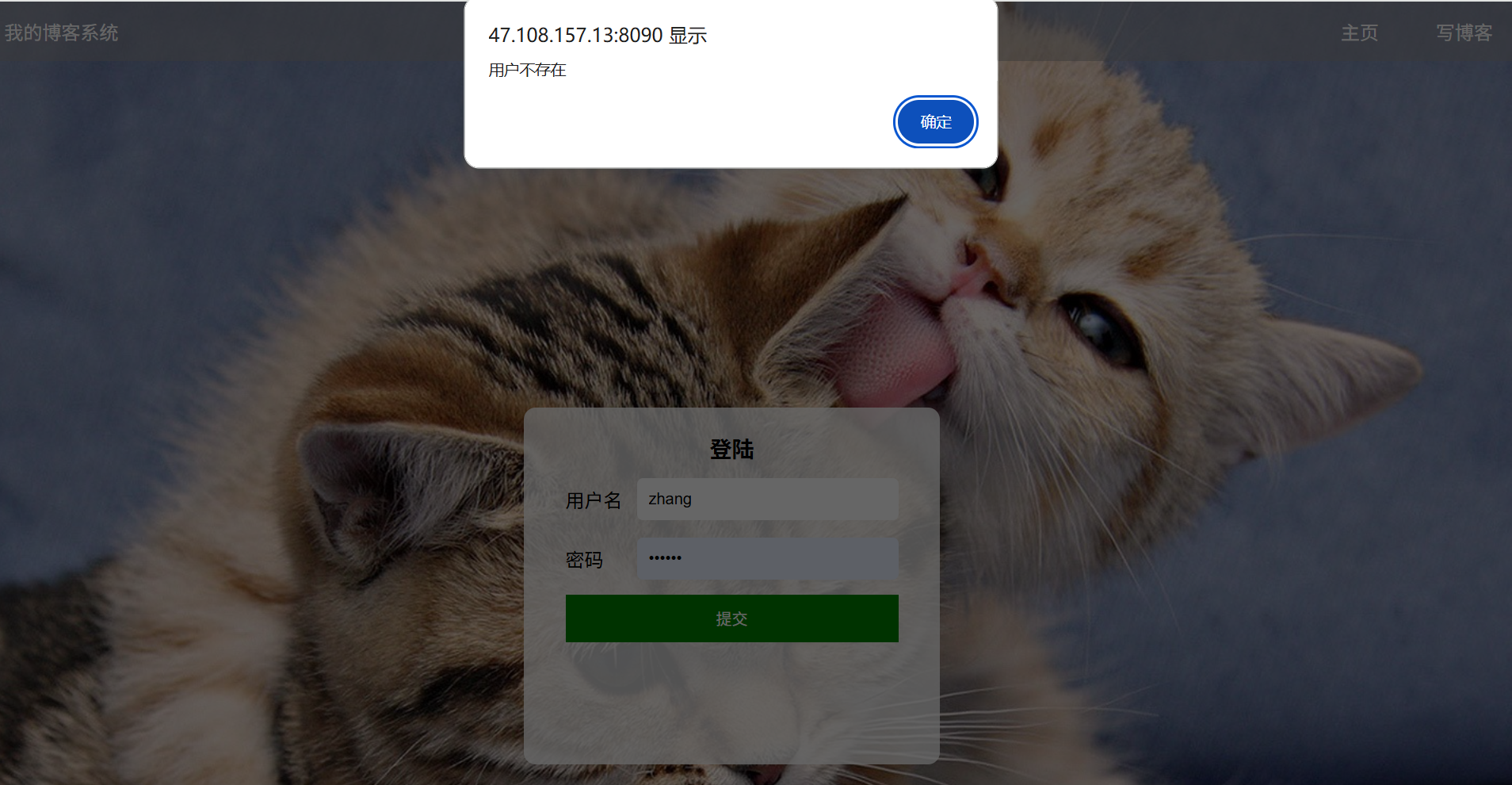
(c3):输入框输入错误的账号和错误的密码:(账号:zhang 密码:1)
预期效果:登录失败并跳出警告弹窗提示用户不存在
实际效果展示:
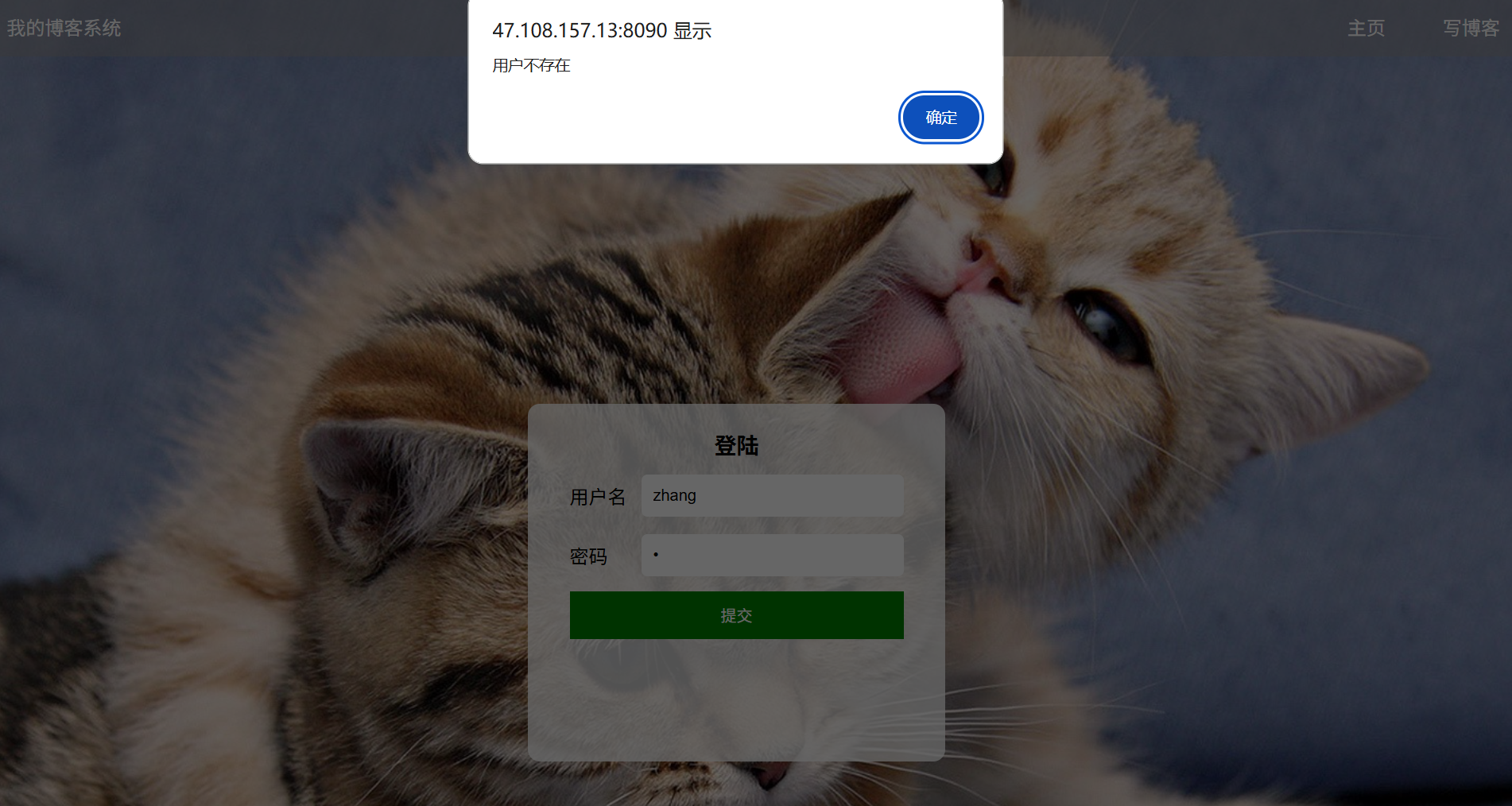
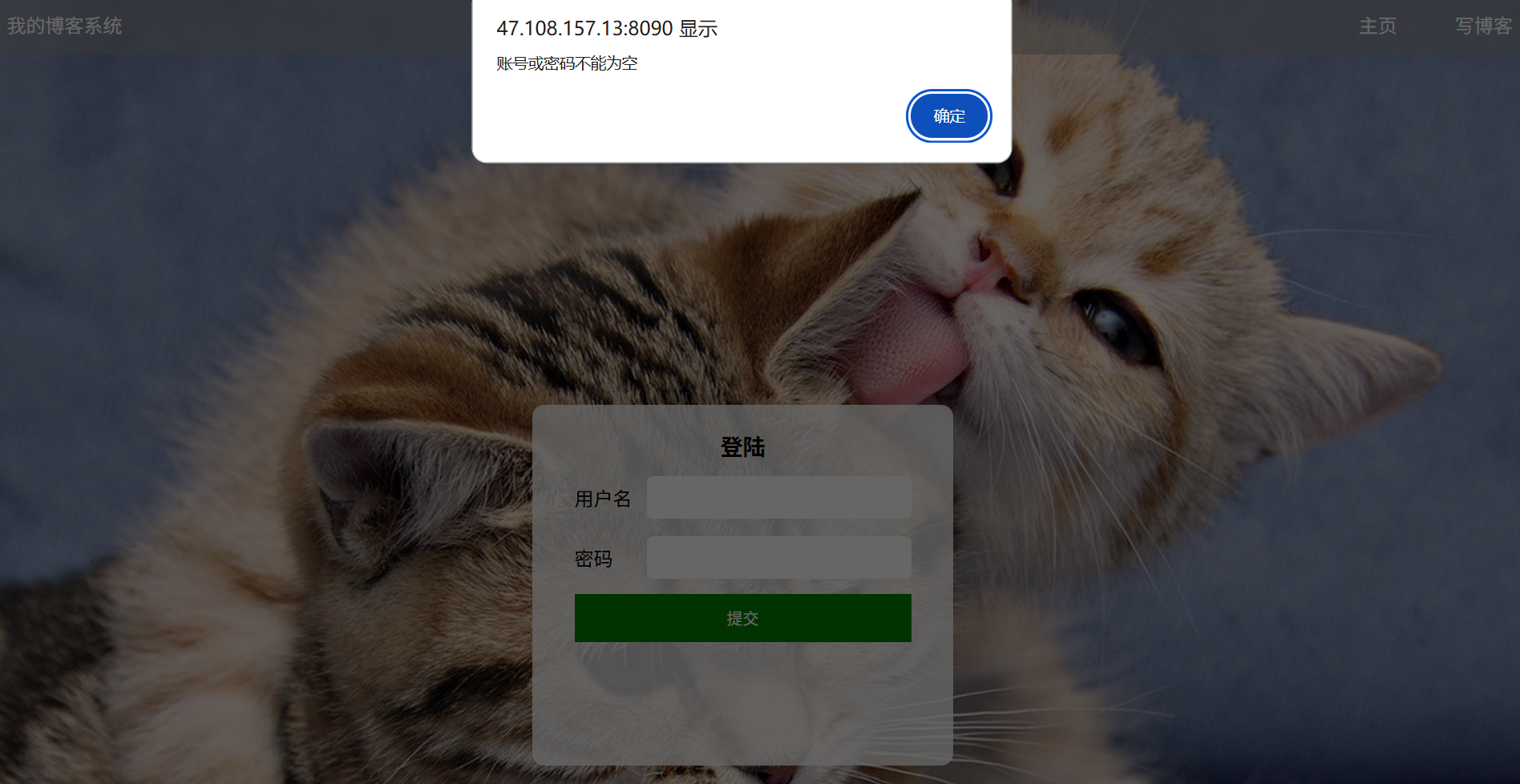
(c4):输入框不输入内容:(账号: 密码:)
预期效果:登录失败并跳出警告弹窗提示账号或密码不能为空
实际效果展示:
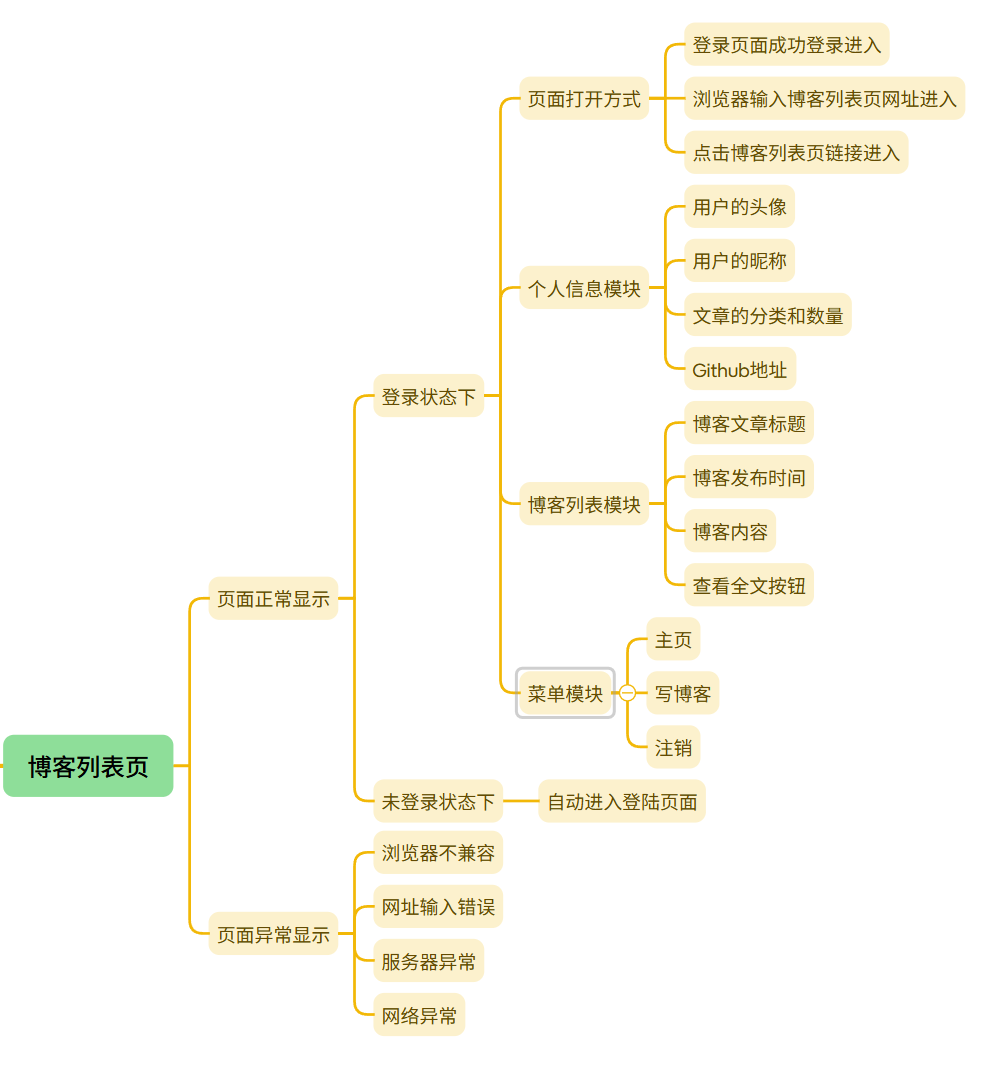
3.4 博客列表页面测试
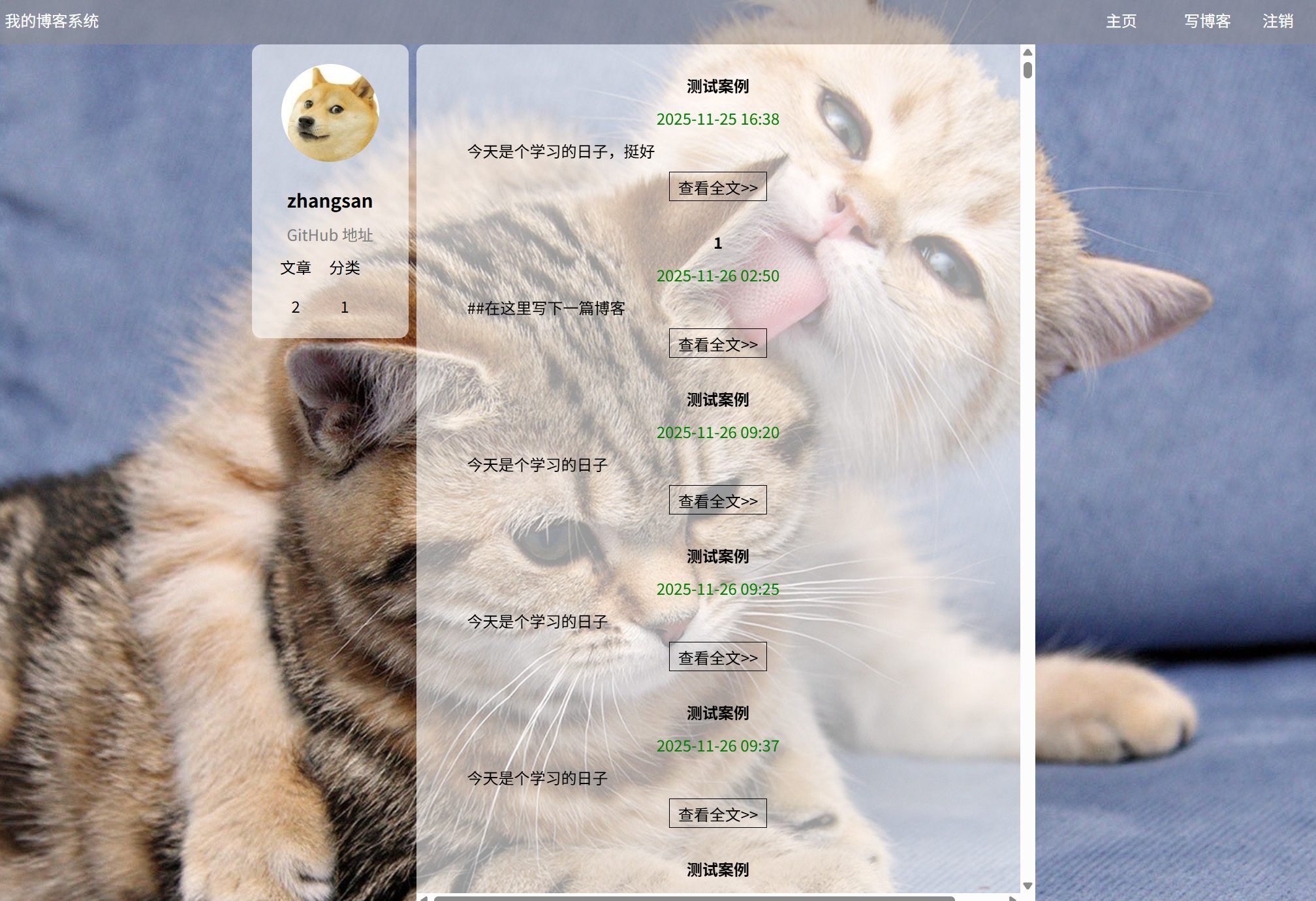
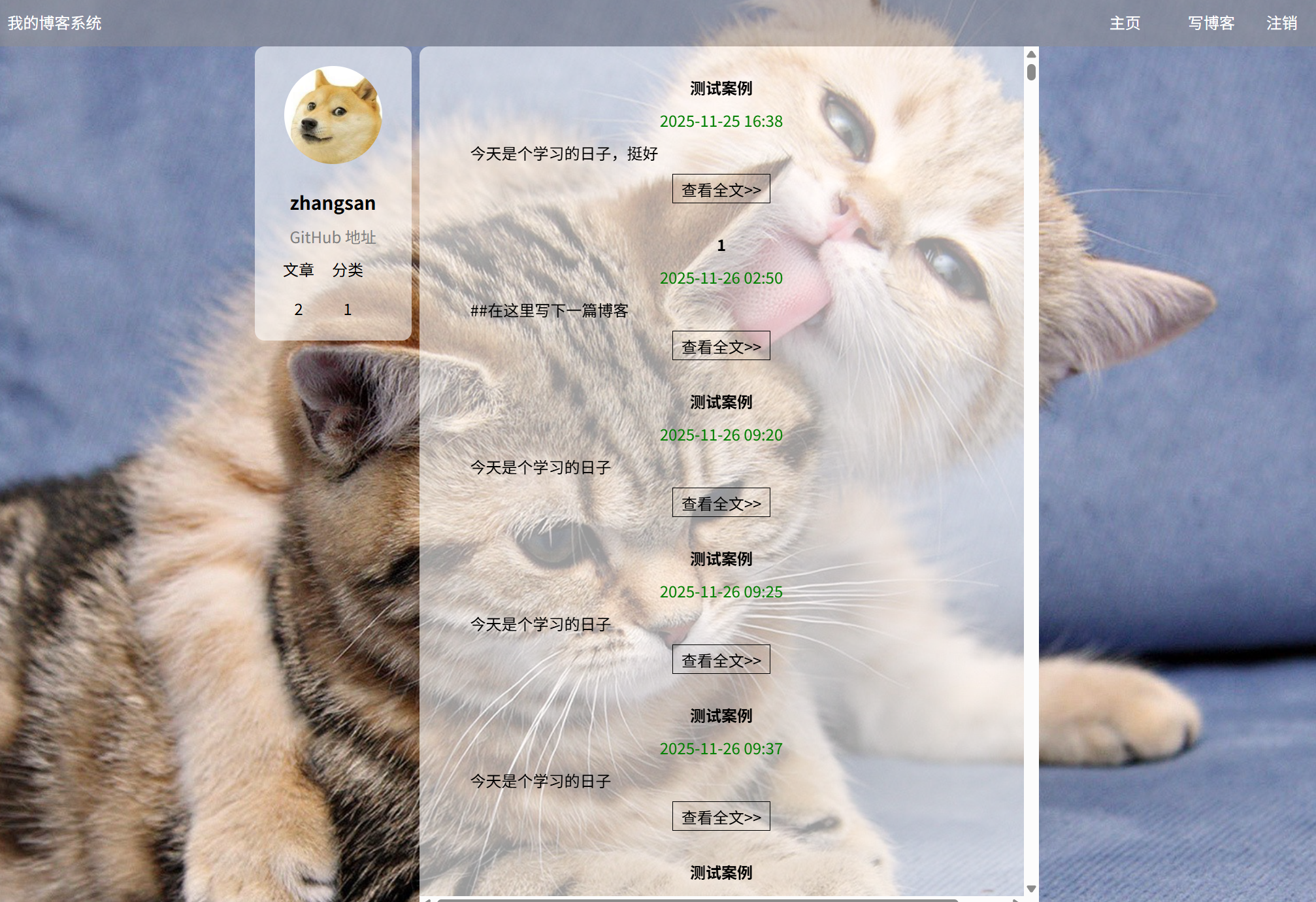
(简介):在登录页面在对应的输入框输入正确的账号和密码后,会跳转到博客列表页面,可以看到当前登录的用户昵称和发布文章数量还有分类,列表区可以看到已发布博客文章信息(包括标题、时间、博客内容)等信息
(a)博客列表页面展示:(如果已经发布文章,那么个人信息模块下的文章数量不为0)
3.5 博客详情页面测试
(简介):博客详情页面分用户信息模块和文章信息模块,在个人信息模块可以看到用户的昵称、GitHub地址、文章数量跟分类,在文章信息模块可以看到文章的标题、发布时间、文章内容、编辑按钮和删除按钮。(如果浏览的是别人的文章,那么只有可读权限,不能对文章进行编辑和删除)
(a)a1:博客详情页面展示:(用户自己文章)
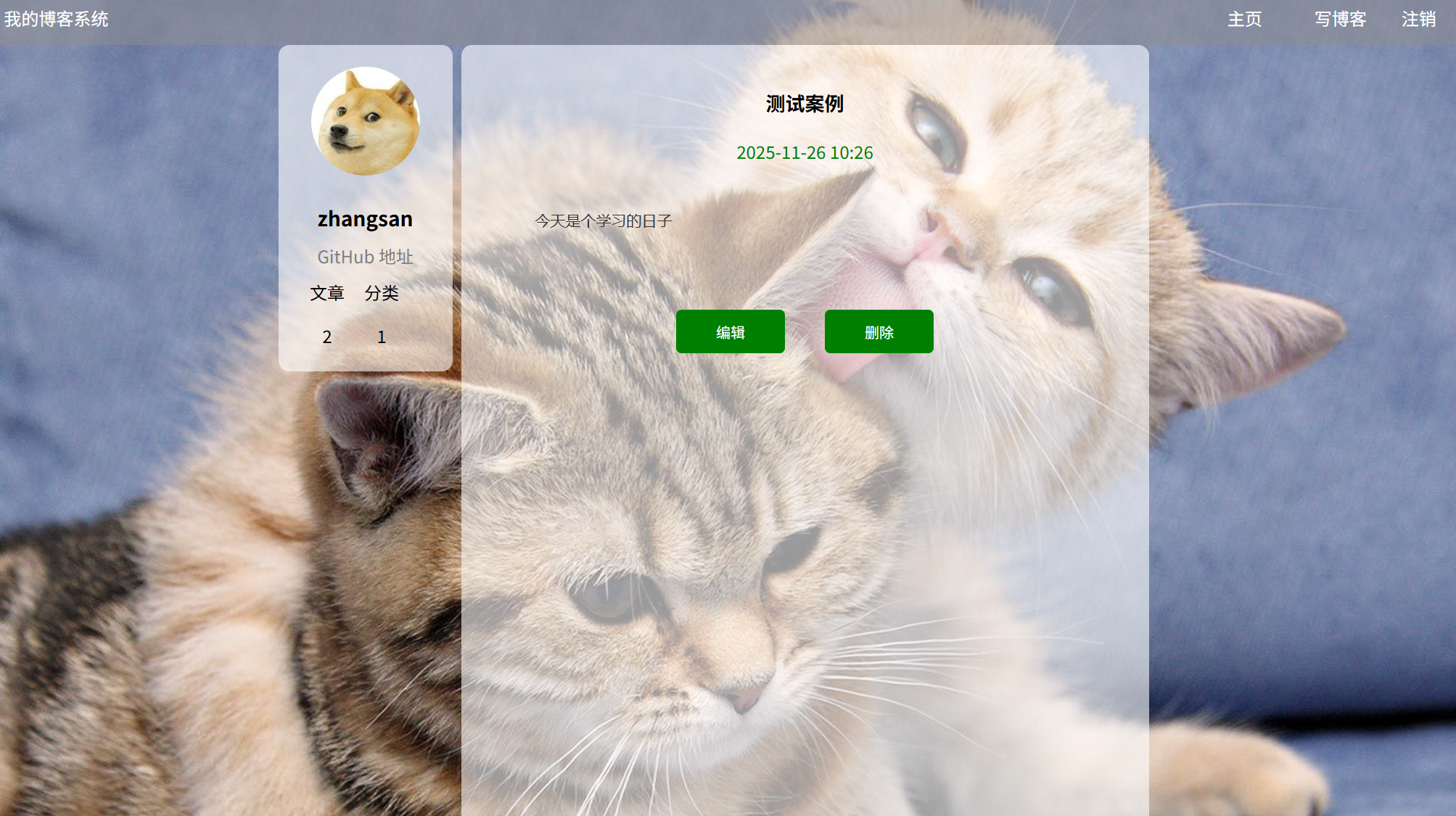
(a2):博客详情页面展示:(其他用户文章)
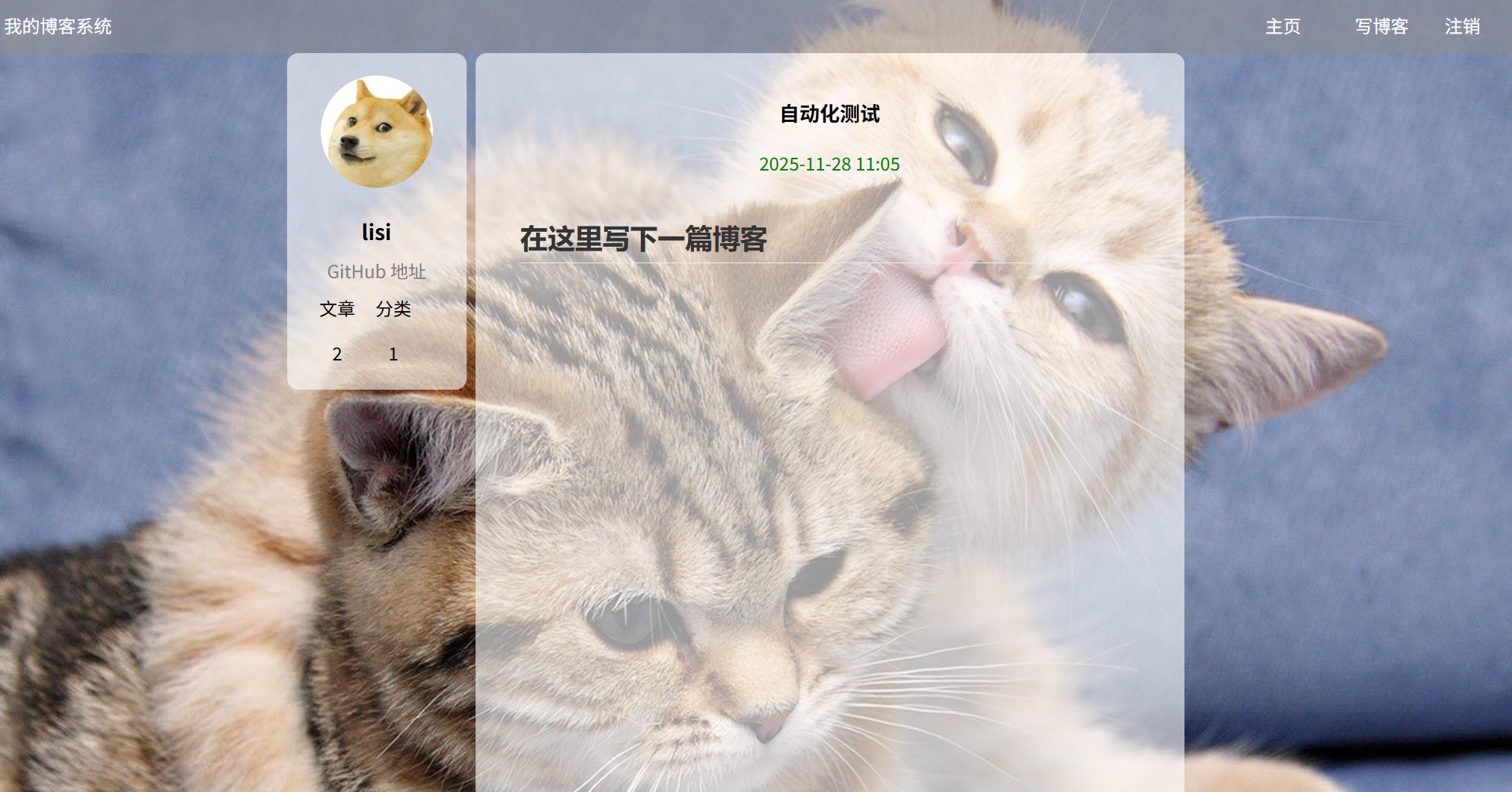
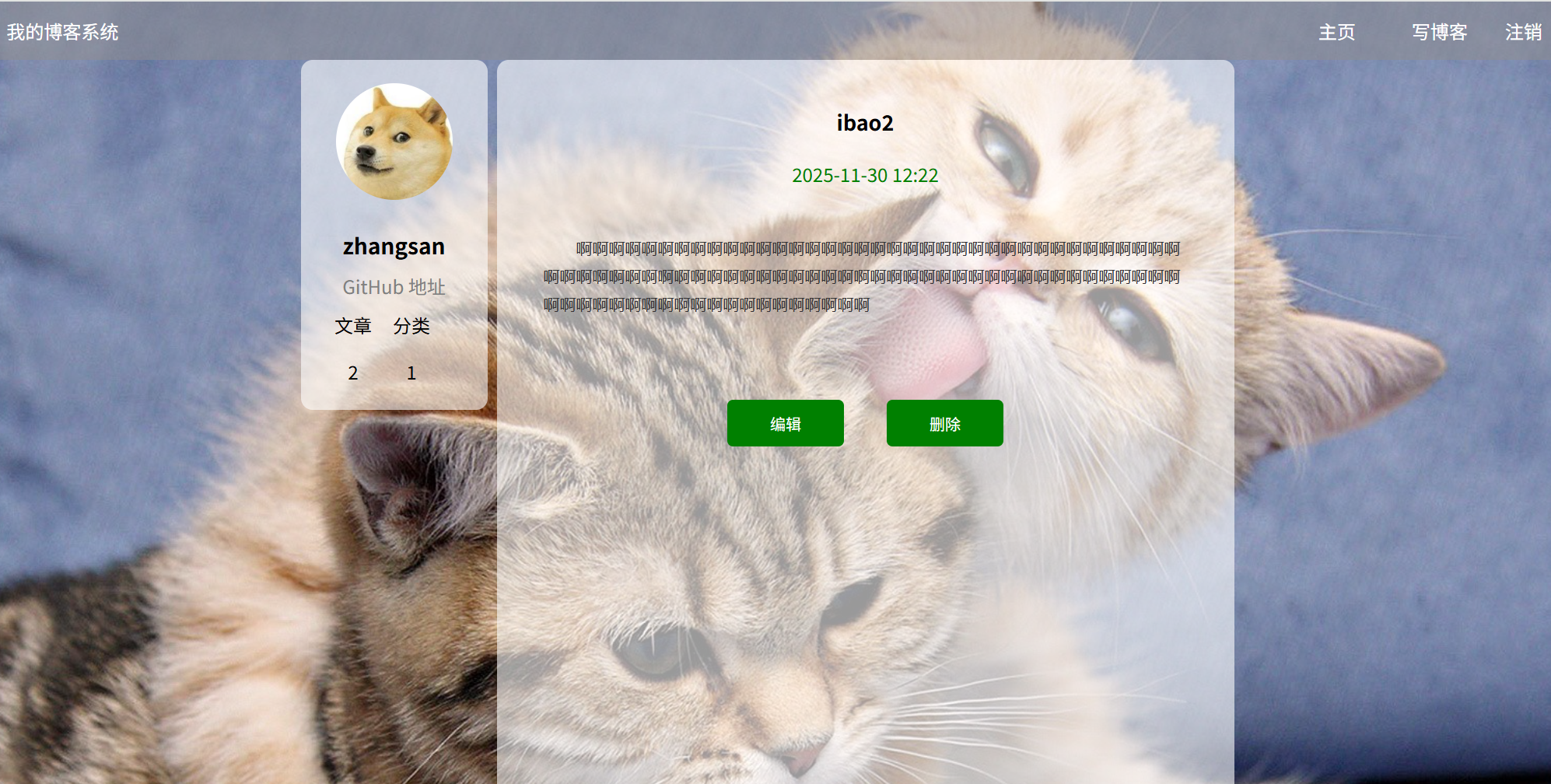
(b):点击查看全文按钮:

预期结果:跳转到博客详情页面并展示用户的基本信息和文章的基本信息
实际效果展示:
3.6 博客编辑页面测试
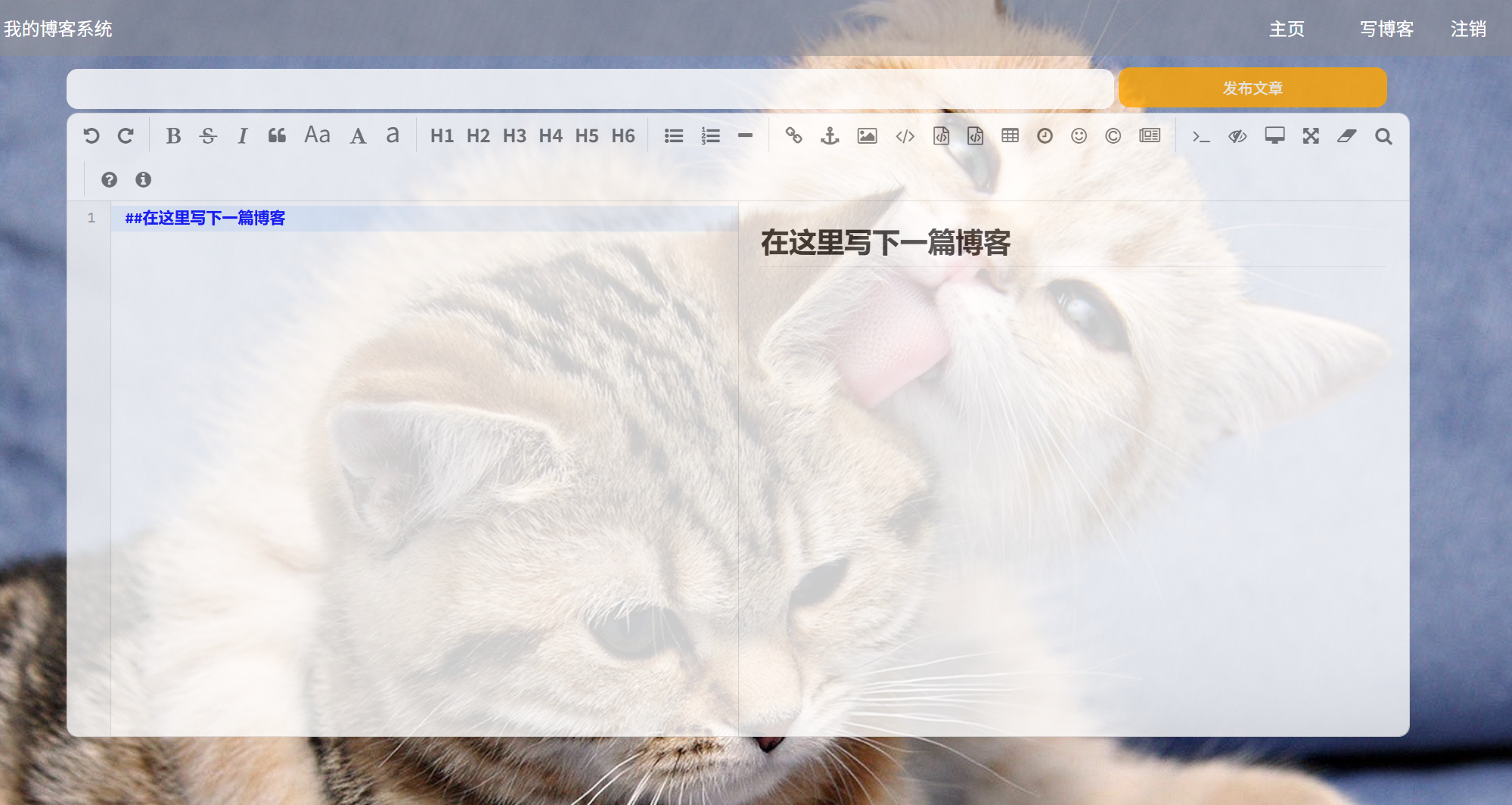
(简介):用户可以通过点击写博客按钮进入博客编辑页面,编辑页面分为标题框、内容框和发布按钮三部分,用户可以在填写文章标题和内容后点击发布按钮就能成功发布文章。如果已经写好文章则可在详情页点击编辑按钮对文章进行更新操作。
(a)a1:博客编辑页面展示:(发布新的文章)
(a2)博客编辑页面展示:(更新文章)
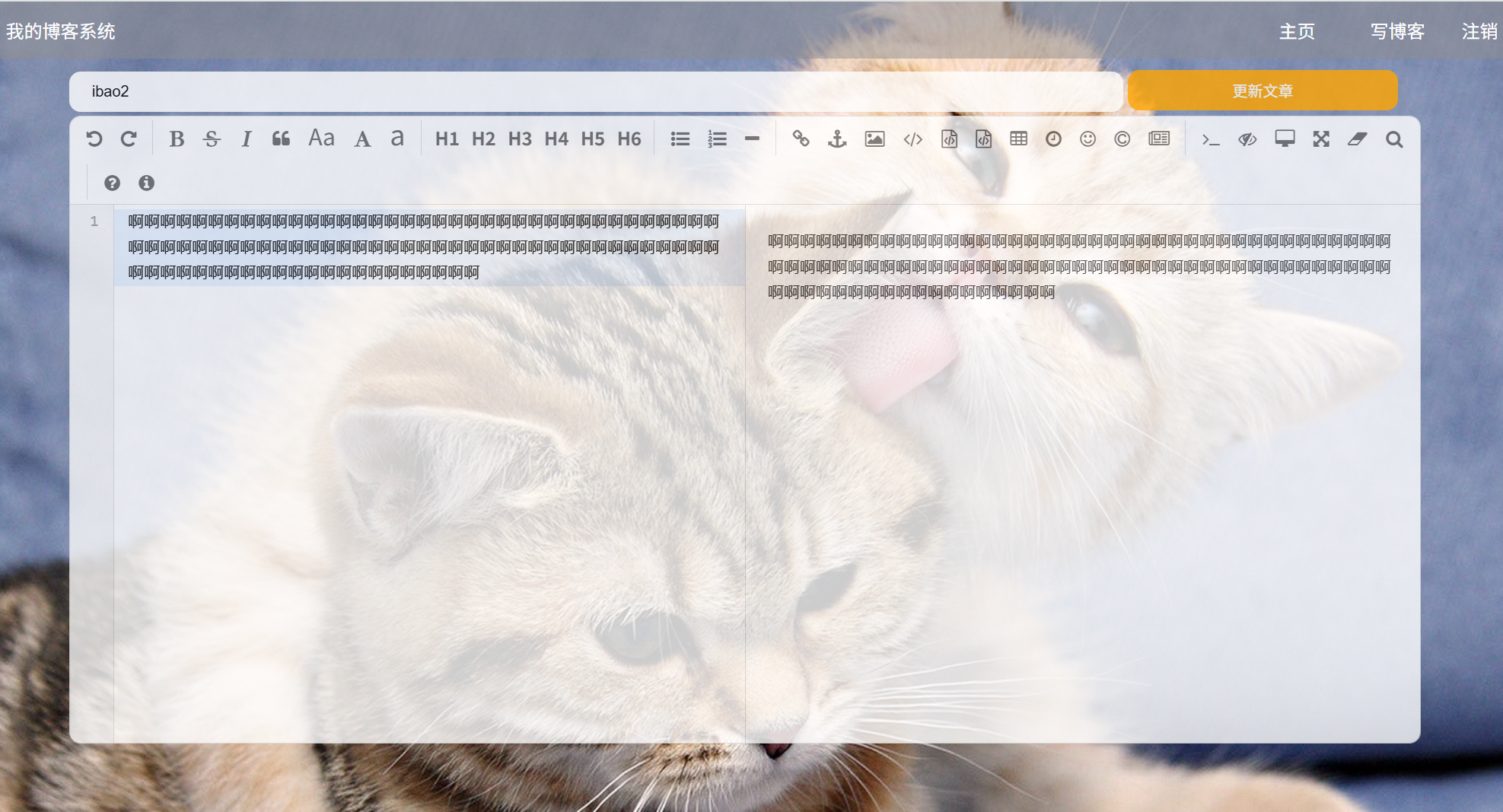
(b)b1:输入文章标题和内容:
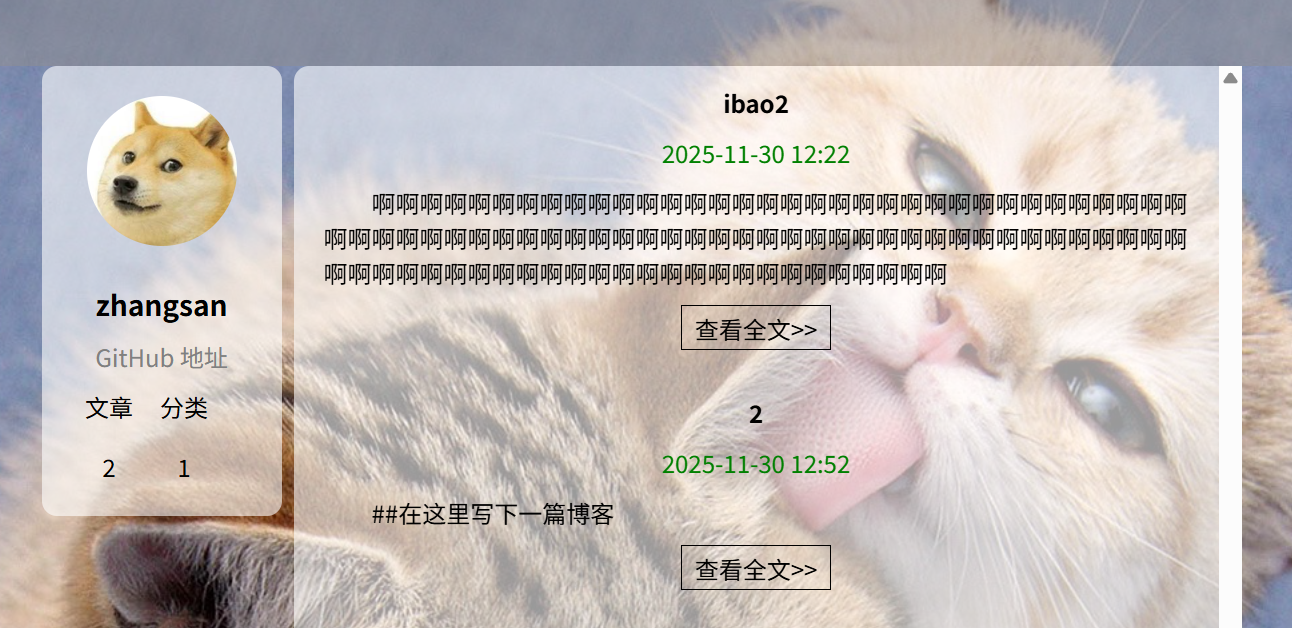
预期结果:成功发布文章并跳转到博客列表页,文章数量+1
实际结果展示:
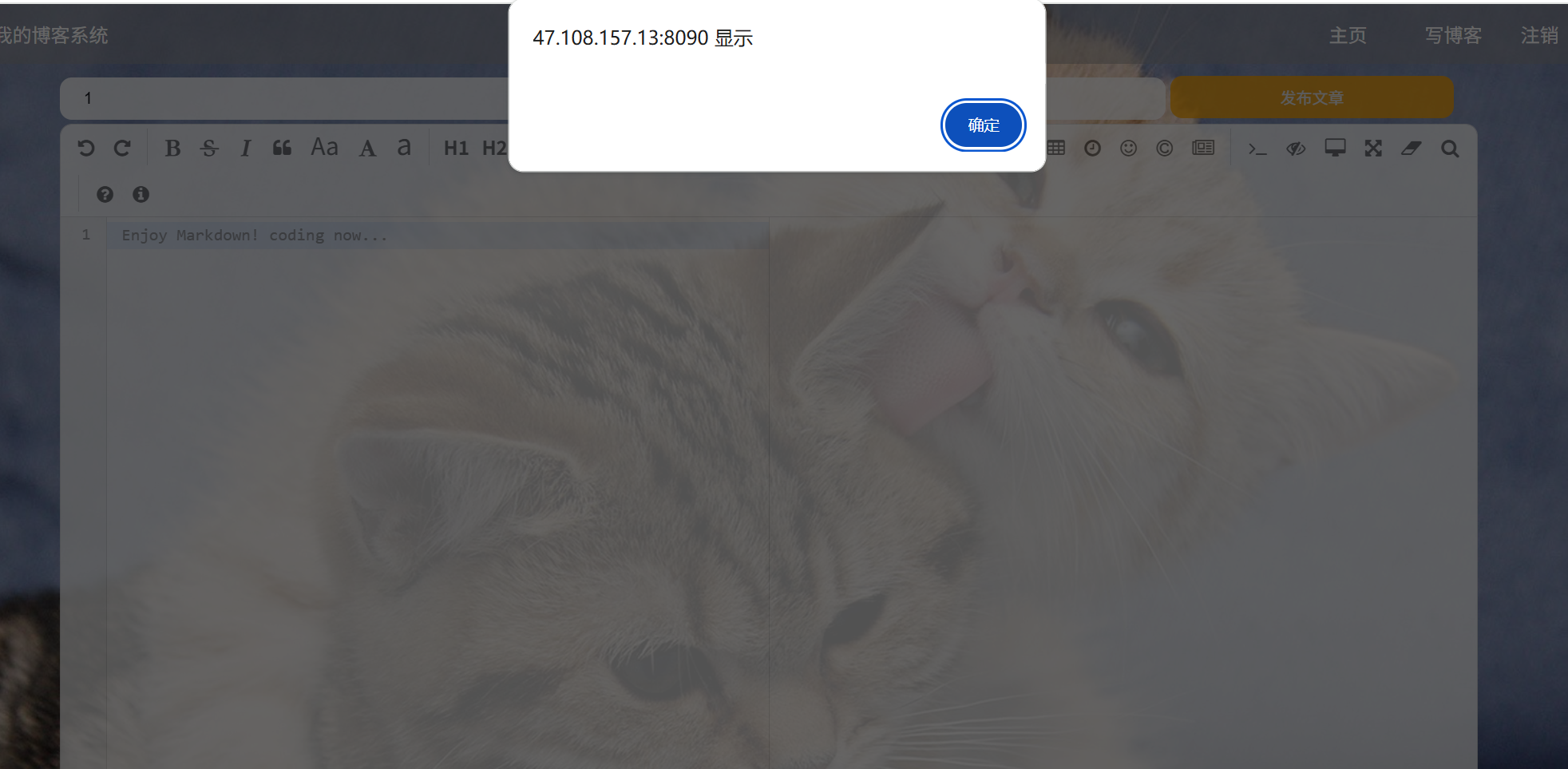
(b2)不输入文章标题或内容:
预期结果:文章发布失败并跳出警告弹窗
实际结果展示:
3.7 删除博客测试
(简介):在博客列表页点击任意一篇发布的文章查看全文按钮,就可以进去到该篇博客的详情页,然后点击博客详情页里面的删除按钮,页面就会跳转到博客列表页,并且该片博客会被删除,博客数量-1
(a)要删除文章展示:
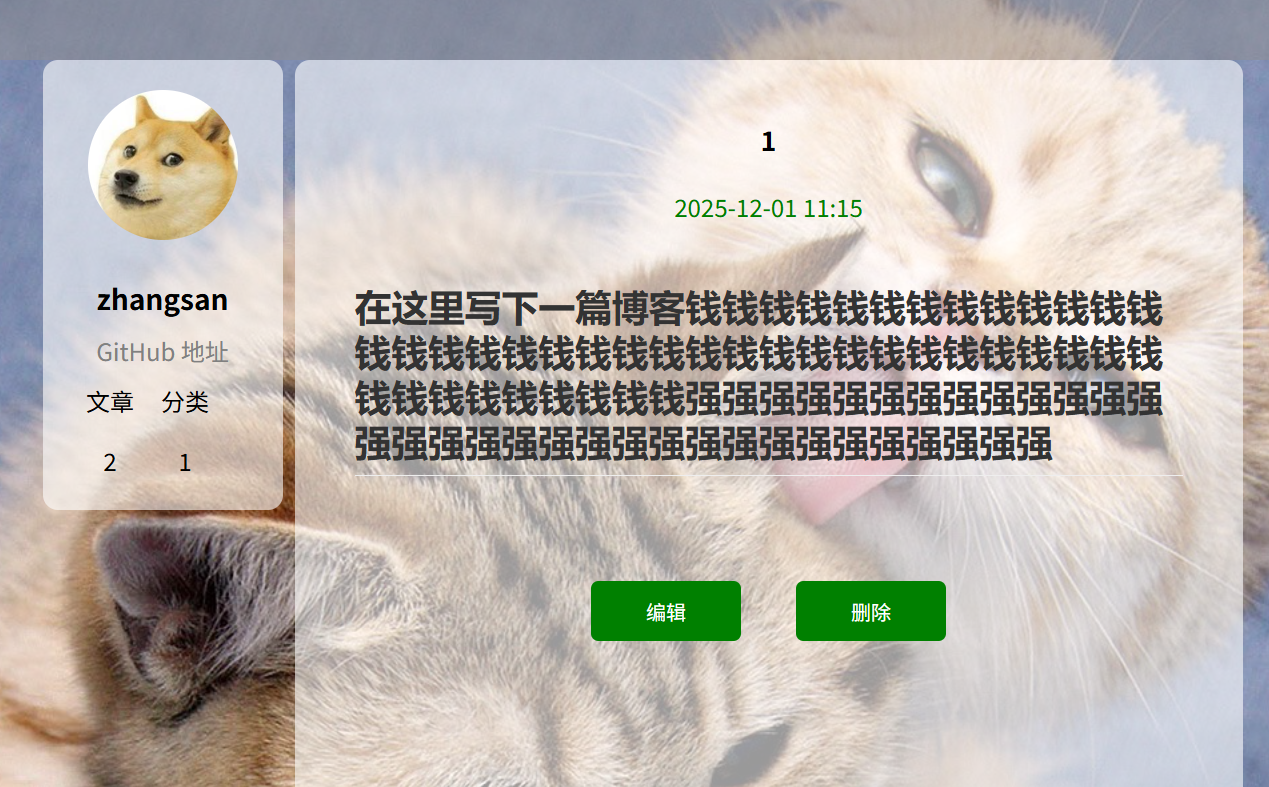

(b)点击删除按钮:

预期结果:删除文章成功并跳转到博客列表页,文章数量 -1
实际结果展示:文章被成功删除

3.8 退出博客测试
(简介):在博客列表页面点击注销按钮,系统跳转到博客登陆页面并且清空输入框的账号密码
(a)点击注销按钮:

预期结果:系统退出成功并跳转到博客登录页面,输入框为空
实际结果展示:
4.使用Selenium进行Web自动化测试(Python)
测前准备:(已经创建项目文件)
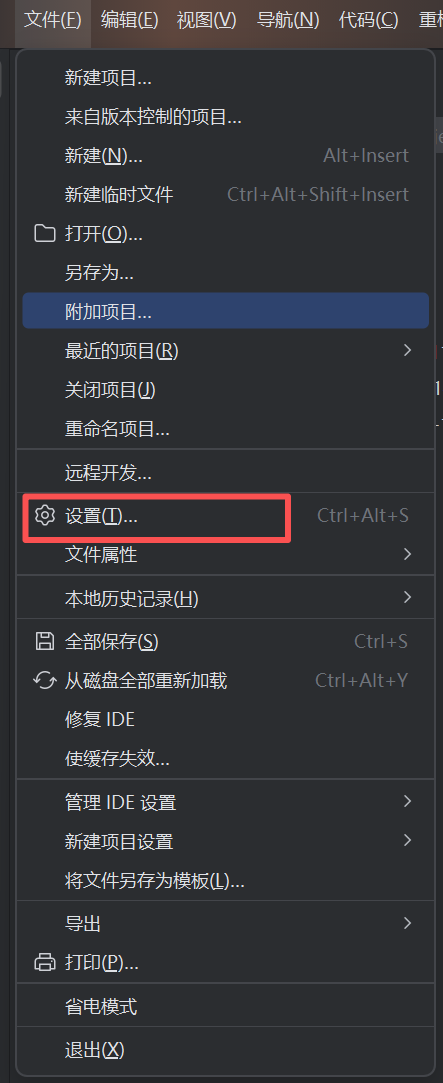
在进行自动化测试之前首先安装两个工具,分别是selenium库和webdriver-manager驱动。我们可以在终端分别输入 pip install selenium==4.0.0 和 pip install webdriver-manager 这两个命令来安装 selenium 库和 webdriver-manager驱动。(注意,安装selenium库一定要指定版本为4.0.0)
1.selenium库介绍 :selenium是⼀个web⾃动化测试⼯具,selenium中提供了丰富的⽅法供给使⽤者进⾏web⾃动化测试
2.webdriver-manager驱动:selenium中提供了驱动管理⼯具webdriver-manager,webdriver-manager⽆需⼿动安装浏览器驱动,它可以⾃动下载和安装适⽤于不同浏览器的 WebDriver。通过使⽤WebDriverManager,我们可以确保浏览器驱动版本始终与浏览器版本保持⼀ 致,从⽽避免因版本不匹配⽽导致的各种问题
安装完成后我们可以在设置-项目-python解释器中看到有没有成功安装这两个工具。
4.1 参照测试用例,编写自动化脚本
4.1.1 创建驱动对象
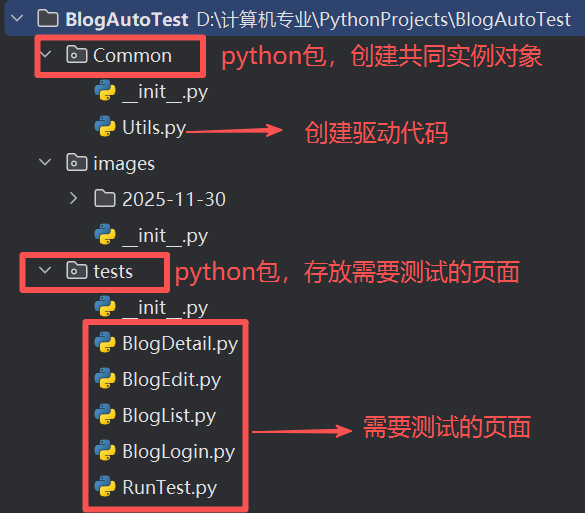
我们需要对博客登录页,博客列表页,博客详情页,博客编辑页这4个页面分别进行测试,在每个页面测试时都要去创建驱动对象,通过驱动对象去get页面的URL去访问,但是每次创建对象都要使用相同的代码,这会造成多次创建消耗性能的情况,于是我们可以把相同的部分提取出来放到一个python包里面,并使用单例模式创建一个浏览器驱动对象,每个页面测试都调用这一个对象。所以我们把创建驱动对象访问放到一个命名为Common的python包,把测试不同页面的文件放到一个命名为test的python包。
目录结构如图:
4.1.2 创建驱动对象步骤
首先在Common包里面的Utils.py文件里面创建
1.一个Driver类,在类里面定义一个驱动对象成员driver,和两个构造函数
- 两个构造函数,分别是对对象成员初始化的构造函数,和运行时截图的构造函数,添加截图函数是为了方便找出报错问题(在对对象成员初始化的时候可以设置加载方式为normal,这样可以避免页面渲染不出来截图空白问题)。
python
import datetime
import os.path
import sys
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# 创建一个浏览器对象
class Driver:
driver = ""
def __init__(self):
options = webdriver.ChromeOptions()
# 设置加载方式
options.page_load_strategy = 'normal'
self.driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
# 添加一个隐式等待,预防代码执行速度比页面渲染加载快,报错
self.driver.implicitly_wait(2) # 隐式等待两秒,隐式等待的生命周期是整个查找过程
# 添加屏幕截图方法
def GetScreeShot(self):
# 创建屏幕截图
# 为了更好区分,分别创建不同日期的文件夹
# 格式:../images/2025-1-3
dirname = datetime.datetime.now().strftime("%Y-%m-%d")
# 判断dirname文件夹是否存在,如果不存在就创建文件夹
if not os.path.exists("../images/" + dirname):
os.mkdir("../images/" + dirname)
# 创建图片路径:../images/调用方法/2025-1-3/2025-1-3-101153.png
filename = sys._getframe().f_back.f_code.co_name + datetime.datetime.now().strftime("%Y-%m-%d-%H%M%S")+".png"
self.driver.save_screenshot("../images/" + dirname + "/" + filename)
# 单例创建driver对象
BlogDriver = Driver()在创建一个运行文件RunTest.py,用来测试不同功能测试文件里面的测试函数(主函数的入口)
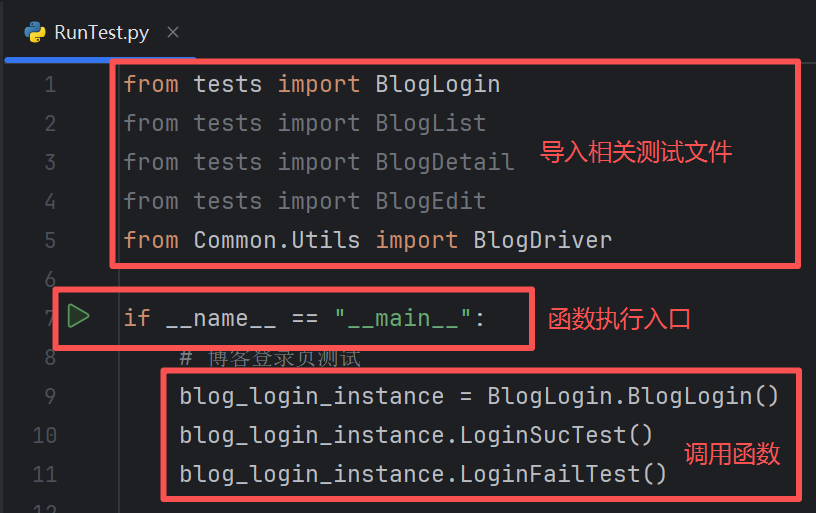
4.1.3 博客登录的自动化测试
①创建一个文件名为:BlogLogin.py,里面存在测试登录的函数(包括成功登录和异常登录)
②引入名为common的python包,包上Common里面的Utils.py文件
③创建一个名为BlogLogin的类,把driver和url成员变量还有函数的实现方法定义在里面(登录成功为LoginSucTest,登录失败为LoginFailTest)
④重点注意清空输入框的内容后才能再次输入用户名及密码进行登录
⑤(测试内容):在这个自动化测试中主要是对页面是否正常打开,并且针对是否可以登录成功/登录失败进行测试。
⑥在RunTest.py里面主要函数调用的顺序,想要看到其他页面的正常效果必须先登录成功
#博客登录页面的BlogLogin测试代码
python
# 测试登录登录页面
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from Common.Utils import BlogDriver
import time
class BlogLogin:
url = ""
driver = ""
def __init__(self):
self.url = "http://47.108.157.13:8090/blog_login.html"
self.driver = BlogDriver.driver
self.driver.get(self.url)
# 成功登录的测试用例
def LoginSucTest(self):
# 因调用方法顺序不同,输入框存在内容导致报错,每次输入之前都应清理输入框
self.driver.find_element(By.CSS_SELECTOR, "#username").clear()
self.driver.find_element(By.CSS_SELECTOR, "#password").clear()
# 输入框输入正确的账号和密码
self.driver.find_element(By.CSS_SELECTOR, "#username").send_keys("zhangsan")
self.driver.find_element(By.CSS_SELECTOR, "#password").send_keys("123456")
self.driver.find_element(By.CSS_SELECTOR, "#submit").click()
# 能够找到用户昵称、文章】分类说明登录成功
# 因为添加了加载模式为全部加载策略,代码执行过快会导致查找不打元素,需要添加等待
time.sleep(1)
# 登录成功的截图
BlogDriver.GetScreeShot()
# 检查一下用户的昵称是否存在
name = self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.left > div > h3").text
# 检查一下用户基本信息中的文章是否存在
article = self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.left > div > div:nth-child(4) "
"> span:nth-child(1)").text
# 检查一下用户基本信息中的分类是否存在
classification = self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.left > div > "
"div:nth-child(4) > span:nth-child(2)").text
print("BlogLogin:" + name)
print("BlogLogin:" + article)
print("BlogLogin:" + classification)
print("登陆成功!")
print("\n")
# 此页面两个方法同时使用在失败时退出
# self.driver.quit()
# 登录失败的测试用例
def LoginFailTest(self):
self.driver.back()
# 因调用方法顺序不同,输入框存在内容导致报错,每次输入之前都应清理输入框
self.driver.find_element(By.CSS_SELECTOR, "#username").clear()
self.driver.find_element(By.CSS_SELECTOR, "#password").clear()
time.sleep(1)
# 输入框输入错误的账号或密码
self.driver.find_element(By.CSS_SELECTOR, "#username").send_keys("zhan")
self.driver.find_element(By.CSS_SELECTOR, "#password").send_keys("123456")
# # 输入错误的账号,错误的密码
# self.driver.find_element(By.CSS_SELECTOR, "#username").send_keys("lisi")
# self.driver.find_element(By.CSS_SELECTOR, "#password").send_keys("123")
#
# # 输入错误的账号,正常的密码
# self.driver.find_element(By.CSS_SELECTOR, "#username").send_keys("lisi")
# self.driver.find_element(By.CSS_SELECTOR, "#password").send_keys("123456")
#
# # 输入正确的账号,错误的密码
# self.driver.find_element(By.CSS_SELECTOR, "#username").send_keys("zhangsan")
# self.driver.find_element(By.CSS_SELECTOR, "#password").send_keys("123")
#
# # 不输入账号,不输入密码
# self.driver.find_element(By.CSS_SELECTOR, "#username").send_keys("")
# self.driver.find_element(By.CSS_SELECTOR, "#password").send_keys("")
# 输入错误的截图
BlogDriver.GetScreeShot()
self.driver.find_element(By.CSS_SELECTOR, "#submit").click()
# 强制等待,避免代码执行过快,检测不到弹窗
time.sleep(1)
# 添加显示等待
# 创建显示等待对象
wait = WebDriverWait(self.driver, 3)
# 检查弹窗是否存在
wait.until(EC.alert_is_present())
# 切换弹窗
alert = self.driver.switch_to.alert
print(alert.text)
print("登陆失败!")
print("\n")
assert alert.text == "用户不存在"
alert.accept()
# 单独设置了启动文件,这里不需要单独关闭浏览器
# self.driver.quit()
# login = BlogLogin()
# login.LoginSucTest()
# login.LoginFailTest()#主函数调用代码
python
from tests import BlogLogin
from Common.Utils import BlogDriver
if __name__ == "__main__":
# 博客登录页测试
blog_login_instance = BlogLogin.BlogLogin()
# 成功登录
blog_login_instance.LoginSucTest()
# 失败登录
blog_login_instance.LoginFailTest()
# 退出浏览器
BlogDriver.driver.quit()运行代码后可以看到打印结果,没有报错
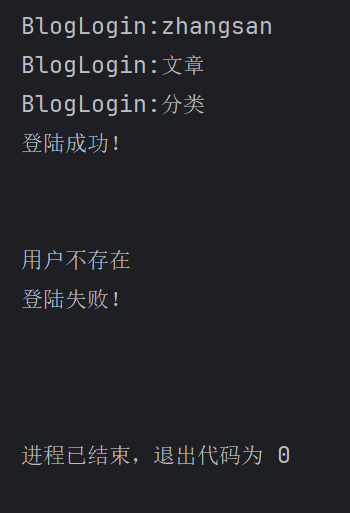
同时截图命名也是正确的
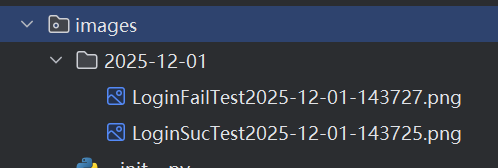
4.1.4 博客列表页的自动化测试
①创建一个文件名为:BlogList.py,里面存在测试列表页的函数(包括成功登录状态下的列表页测试和未登录状态下的列表页测试)
②引入名为Common的python包,包上Common里面的Utils.py文件
③创建一个名为BlogList的类,把driver和url成员变量还有函数的实现方法定义在里面(成功登录测试的列表BlogLoginList,登录状态下退出登录函数QuitBlogLoginList,,未登录测试的列表页为NotBlogLoginList)
④(测试内容):博客标题、博客发布的时间,博客内容、查看全文按钮,左边的用户基本信息等是否存在,以及"博客数量是否为0"
⑤在RunTest.py里面主要函数调用的顺序,想要看到其他页面的正常效果必须先登录成功
#博客列表页面的BlogListTest测试代码
python
# 博客列表页测试
import time
from selenium.webdriver.common.by import By
from Common.Utils import BlogDriver
class BlogList:
driver = ""
url = ""
def __init__(self):
self.driver = BlogDriver.driver
self.url = "http://47.108.157.13:8090/blog_list.html"
self.driver.get(self.url)
def BlogLoginList(self): # 登路状态下
# 检查一下博客的标题是否存在
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.right > div:nth-child(590) > div.title")
# 检查一下发布博客的时间是否存在
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.right > div:nth-child(590) > div.date")
# 检查一下博客的内容是否存在
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.right > div:nth-child(590) > div.desc")
# 检查一下博客列表页的查看全文按钮是否存在
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.right > div:nth-child(590) > a")
# 检查一下用户基本信息的昵称是否存在
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.left > div > h3")
# 检查一下用户基本信息的文章是否存在
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.left > div > div:nth-child(4) > "
"span:nth-child(1)")
# 检查一下用户基本信息的分类是否存在
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.left > div > div:nth-child(4) > "
"span:nth-child(2)")
# 检查一下博客数量是否为0,不为就就通过
Blognum = self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.left > div > div:nth-child(5) "
"> span:nth-child(1)").text
print(Blognum)
assert Blognum != 0
BlogDriver.GetScreeShot()
# self.driver.quit()
def NotBlogLoginList(self): # 未登录状态下
# 找到用户命名输入框和密码输入框把里面的内容清空
# self.driver.find_element(By.CSS_SELECTOR, "#username").clear()
# self.driver.find_element(By.CSS_SELECTOR, "#password").clear()
self.driver.get("http://47.108.157.13:8090/blog_list.html")
time.sleep(2)
BlogDriver.GetScreeShot()
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.right > div:nth-child(590) > div.title")
def QuitBlogLoginList(self): # 登录博客状态下测试退出
# 点击退出按钮
self.driver.find_element(By.CSS_SELECTOR, "body > div.nav > a:nth-child(6)").click()
BlogDriver.GetScreeShot()
# 判断一下退出后的页面url和页面的标题
Quittitle = self.driver.title
QuitUrl = self.driver.current_url
print(Quittitle)
print(QuitUrl)
assert Quittitle == "博客登陆页"
assert QuitUrl == "http://47.108.157.13:8090/blog_login.html"
# 判断一下账号输入框和密码输入框的内容是否为空
Quitusername = self.driver.find_element(By.CSS_SELECTOR, "#username").text
Quitpassword = self.driver.find_element(By.CSS_SELECTOR, "#password").text
print("Quitusername" + Quitusername)
print("Quitpassword" + Quitpassword)
assert Quitusername == ""
assert Quitpassword == ""#主函数调用代码
python
from tests import BlogLogin
from tests import BlogList
from Common.Utils import BlogDriver
if __name__ == "__main__":
# 2. 博客列表页面测试
blog_login_instance = BlogLogin.BlogLogin()
# 成功登录
blog_login_instance.LoginSucTest()
blog_list_instance = BlogList.BlogList()
# 登录状态下测试博客列表页
blog_list_instance.BlogLoginList()
# 退出博客登录
blog_list_instance.QuitBlogLoginList()
# 未登录状态下测试博客列表页
blog_list_instance.NotBlogLoginList()
BlogDriver.driver.quit()运行代码后打印信息
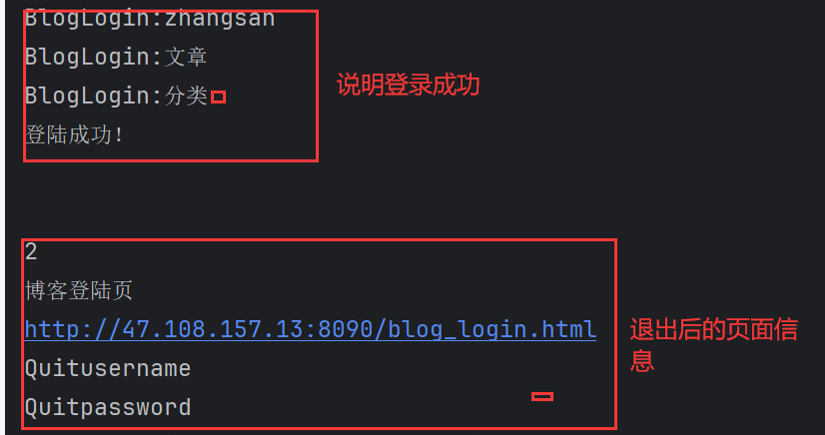
在退出系统之前没有报错,说明博客列表页的元素显示正常,下面报错信息显示说找不到元素,这时正常的,因为我们已经退出了系统,肯定找不到博客列表页的元素
python
NoSuchElementException: Message: no such element: Unable to locate element: {"method":"css selector","selector":"body > div.container > div.right > div:nth-child(590) > div.title"}
(Session info: chrome=142.0.7444.176)images文件里正常截到BlogListTest文件里面的测试函数运行时的图片
4.1.5 博客详情页的自动化测试
①创建一个文件名为:BlogDetail.py,里面存在测试详情页的函数(包括成功登录状态下的详情页测试和未登录状态下的详情页测试)
②引入名为Common的python包,包上Common里面的Utils.py文件
③创建一个名为BlogDtail的类,把driver和url成员变量还有函数的实现方法定义在里面(成功登录状态下测试的列表BlogLoginDetail,成功登录状态下删除博客DeteleBlogLoginDetail,未登录状态下测试的列表页为NotBlogLoginDetail)
④(测试内容):博客标题、博客发布的时间,博客内容、左边的用户基本信息,编辑和删除按钮等是否存在,能否正常删除文章
⑤在RunTest.py里面主要函数调用的顺序,想要看到其他页面的正常效果必须先登录成功
#博客详情页面的BlogDetail测试代码
python
# 博客详情页测试
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from Common.Utils import BlogDriver
class BlogDetail:
driver = ""
url = ""
def __init__(self):
self.driver = BlogDriver.driver
# 一篇博客的url
self.url = "http://47.108.157.13:8090/blog_detail.html?blogId=33254"
self.driver.get(self.url)
def BlogLoginDetail(self):
# 检查一下博客的标题是否存在
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.right > div > div.title")
# 检查一下发布博客的时间是否存在
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.right > div > div.date")
# 检查一下博客的内容是否存在
self.driver.find_element(By.CSS_SELECTOR, "#detail")
# 检查一下用户基本信息的昵称是否存在
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.left > div > h3")
# 检查一下用户基本信息的文章是否存在
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.left > div > div:nth-child(4) > "
"span:nth-child(1)")
# 检查一下用户基本信息的分类是否存在
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.left > div > div:nth-child(4) > "
"span:nth-child(2)")
# 检查一下编辑按钮是否存在
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.right > div > div.operating > "
"button:nth-child(1)")
# 检查一下删除按钮是否存在
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.right > div > div.operating > "
"button:nth-child(2)")
# 添加屏幕截图
BlogDriver.GetScreeShot()
time.sleep(2)
def DeleteBlogLoginDetail(self):
# 点击第一篇博客删除按钮
BlogDriver.GetScreeShot()
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.right > div > div.operating > "
"button:nth-child(2)").click()
# 点击删除按钮后会出现一个弹窗
wait = WebDriverWait(self.driver, 2)
# 检查弹窗是否出现
wait.until(EC.alert_is_present())
# 找到弹窗
alert = self.driver.switch_to.alert
# 判断一下弹窗里面的内容是否是确定删除?
actual = alert.text
print(actual)
assert actual == "确定删除?"
# 点击确定删除按钮
alert.accept()
time.sleep(1)
BlogDriver.GetScreeShot()
# 删除后判断一下是否返回到了博客列表页
time.sleep(1)
rettitle = self.driver.title
retUrl = self.driver.current_url
assert rettitle == "博客列表页"
assert retUrl == "http://47.108.157.13:8090/blog_list.html"
print("rettitle:" + rettitle)
print("retUrl:" + retUrl)
print("删除成功!\n")
def NotBlogLoginDetail(self):
# 检查一下博客的标题是否存在
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.right > div > div.title")
# 检查一下发布博客的时间是否存在
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.right > div > div.date")
# 检查一下博客的内容是否存在
self.driver.find_element(By.CSS_SELECTOR, "#detail")
# 检查一下用户基本信息的昵称是否存在
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.left > div > h3")
# 检查一下用户基本信息的文章是否存在
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.left > div > div:nth-child(4) > "
"span:nth-child(1)")
# 检查一下用户基本信息的分类是否存在
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.left > div > div:nth-child(4) > "
"span:nth-child(2)")
# 检查一下编辑按钮是否存在
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.right > div > div.operating > "
"button:nth-child(1)")
# 检查一下删除按钮是否存在
self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.right > div > div.operating > "
"button:nth-child(2)")
# 添加屏幕截图
BlogDriver.GetScreeShot()
time.sleep(2)#主函数调用代码
python
from tests import BlogLogin
from tests import BlogList
from tests import BlogDetail
from Common.Utils import BlogDriver
if __name__ == "__main__":
# 3. 博客详情页测试
# 登录
blog_login_instance = BlogLogin.BlogLogin()
# 成功登录
blog_login_instance.LoginSucTest()
blog_dateil_instance = BlogDetail.BlogDetail()
# 测试登录状态下的详情页
blog_dateil_instance.BlogLoginDetail()
# 测试登录状态下详情页删除第一篇文章
blog_dateil_instance.DeleteBlogLoginDetail()
# 退出登录
blog_list_instance = BlogList.BlogList()
# 退出博客登录
blog_list_instance.QuitBlogLoginList()
# 测试未登录状态下的详情页
blog_dateil_instance.NotBlogLoginDetail()
BlogDriver.driver.quit()运行代码后看打印结果可以知道登陆成功后博客详情页的元素都能找到,并且删除功能也没有问题,删除后系统能正常跳转到博客列表页
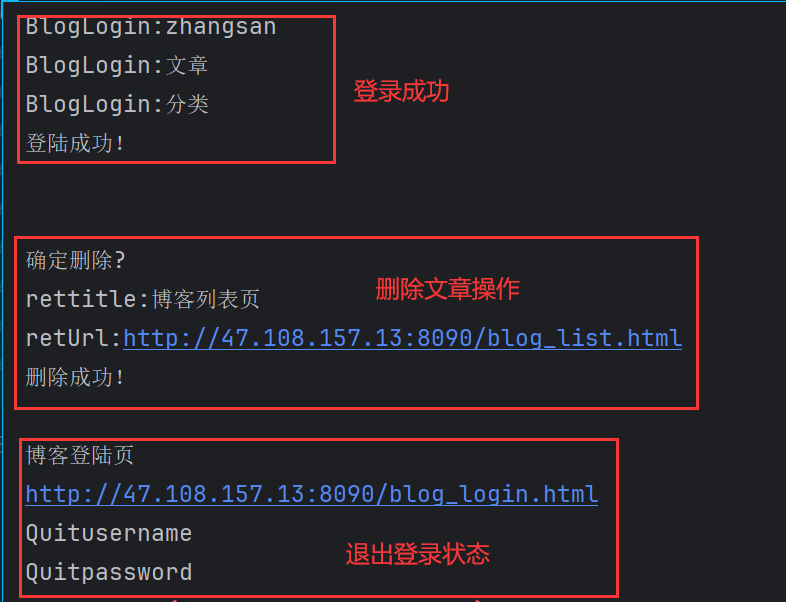
在退出系统后开始报错,显示元素找不到,这是符合预期的,因在退出系统后肯定找不到详情页的元素
python
NoSuchElementException: Message: no such element: Unable to locate element: {"method":"css selector","selector":"body > div.container > div.right > div > div.title"}
(Session info: chrome=142.0.7444.176)再看images文件夹,能够正常截到BlogDetailt文件里面的测试函数运行时的图片
4.1.6 博客编辑页的自动化测试
①创建一个文件名为:BlogEdit.py,里面存在测试编辑页的函数(包括登录状态下的编辑页测试和未登录状态下的编辑页测试)
②引入名为Common的python包,包上Common里面的Utils.py文件
③创建一个名为BlogEdit的类,把driver和url成员变量还有函数的实现方法定义在里面(登录状态下的测试函数BlogLoginEdit 和 未登录状态下的测试函数NotBlogLoginEdit)
⑤(测试内容):检查编辑页的能否正常编辑并且发布后能否在列表页找到该文章。
⑥在RunTest.py里面主要函数调用的顺序,想要看到其他页面的正常效果必须先登录成功
#博客编辑页面的BlogEdit测试代码
python
# 博客编辑页面测试
import time
from selenium.webdriver.common.by import By
from Common.Utils import BlogDriver
class BlogEdit:
driver = ""
url = ""
def __init__(self):
self.driver = BlogDriver.driver
# 编辑一篇新博克页面
self.url = "http://47.108.157.13:8090/blog_edit.html"
self.driver.get(self.url)
def BlogLoginEdit(self):
# 找到标题输入框输入标题
self.driver.find_element(By.CSS_SELECTOR, "#title").send_keys("博客系统测试编辑页面")
# 编辑区域的菜单栏是第三方插件,元素无法被选中,先不处理菜单栏
# 博客编辑区本来就不为空
time.sleep(5)
BlogDriver.GetScreeShot()
# 点击发布文章按钮
self.driver.find_element(By.CSS_SELECTOR, "#submit").click()
# 因为页面的跳转需要时间,代码执行的速度如果比页面渲染的速度快,就会导致找不到元素
time.sleep(1)
# 发布文章后,会自动跳转到博客列表页,可以判断一下跳转后的url是否等于博客列表页的url
jumpURL = self.driver.current_url
print(jumpURL)
assert jumpURL == "http://47.108.157.13:8090/blog_list.html"
# 判断一下博客列表页的文章标题是否是新发布的博客的给定的标题
# body > div.container > div.right > div: nth - child(590) > div.title,最近发布一篇文章是child(589)新发布的文章应该是child(590)
actual = self.driver.find_element(By.CSS_SELECTOR, "body > div.container > div.right > div:nth-child(590) > "
"div.title").text
print(actual)
assert actual == "博客系统测试编辑页面"
def NotBlogLoginEdit(self): # 未登录下
# 未登录下是找不到标题输入框输入标题
self.driver.find_element(By.CSS_SELECTOR, "#title").send_keys("博客系统测试编辑页面")#主函数调用代码
python
from tests import BlogLogin
from tests import BlogList
from tests import BlogDetail
from tests import BlogEdit
from Common.Utils import BlogDriver
if __name__ == "__main__":
# 4. 博客编辑页测试
# 博客编辑页面的测试
# 登录
blog_login_instance = BlogLogin.BlogLogin()
# 成功登录
blog_login_instance.LoginSucTest()
# 登录状态下的编辑页面测试
blog_edit_instance = BlogEdit.BlogEdit()
blog_edit_instance.BlogLoginEdit()
# 然后调用退出博客函数
blog_list_instance = BlogList.BlogList()
blog_list_instance.QuitBlogLoginList()
# 再调用未登录状态下,去测试博客编辑页
blog_edit_instance.NotBlogLoginEdit()
BlogDriver.driver.quit()代码运行后可以看到能够正常发布文章,说明编辑页功能正常
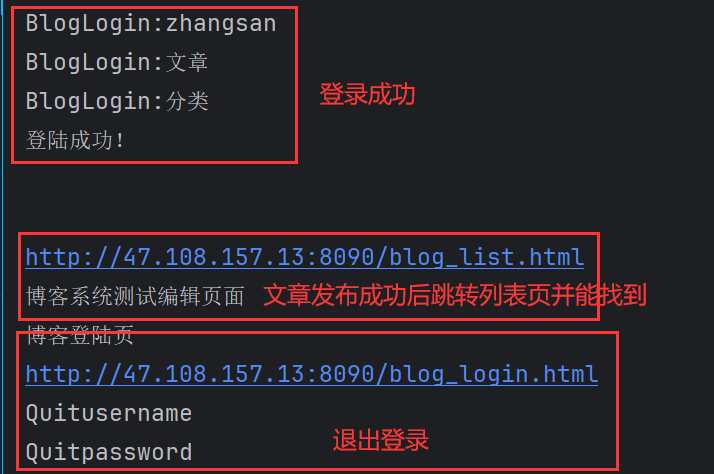
退出登陆后报错说找不到元素,符合预期
python
NoSuchElementException: Message: no such element: Unable to locate element: {"method":"css selector","selector":"#title"}
(Session info: chrome=142.0.7444.176)截图也能够正常截到BlogEdit文件里面的测试函数运行时的图片
4.1.7 博客退出的自动化测试
① 博客退出功能集成到了博客列表页里面,在BlogList文件的BlogList类中构造博客退出函数QuitBlogLoginList
②这个界面中,主要是针对页面是否显示正常,在列表页点击"注销"按钮是否正常跳转到登录页并清空输入框内容
博客列表测试文件里面的退出函数代码
python
def QuitBlogLoginList(self): # 登录博客状态下测试退出
# 点击退出按钮
self.driver.find_element(By.CSS_SELECTOR, "body > div.nav > a:nth-child(6)").click()
BlogDriver.GetScreeShot()
# 判断一下退出后的页面url和页面的标题
Quittitle = self.driver.title
QuitUrl = self.driver.current_url
print(Quittitle)
print(QuitUrl)
assert Quittitle == "博客登陆页"
assert QuitUrl == "http://47.108.157.13:8090/blog_login.html"
# 判断一下账号输入框和密码输入框的内容是否为空
Quitusername = self.driver.find_element(By.CSS_SELECTOR, "#username").text
Quitpassword = self.driver.find_element(By.CSS_SELECTOR, "#password").text
print("Quitusername" + Quitusername)
print("Quitpassword" + Quitpassword)
assert Quitusername == ""
assert Quitpassword == ""#主函数调用代码
python
from tests import BlogLogin
from tests import BlogList
from Common.Utils import BlogDriver
if __name__ == "__main__":
# 5. 博客退出功能测试
blog_login_instance = BlogLogin.BlogLogin()
# 成功登录
blog_login_instance.LoginSucTest()
blog_list_instance = BlogList.BlogList()
# # 退出博客登录
blog_list_instance.QuitBlogLoginList()
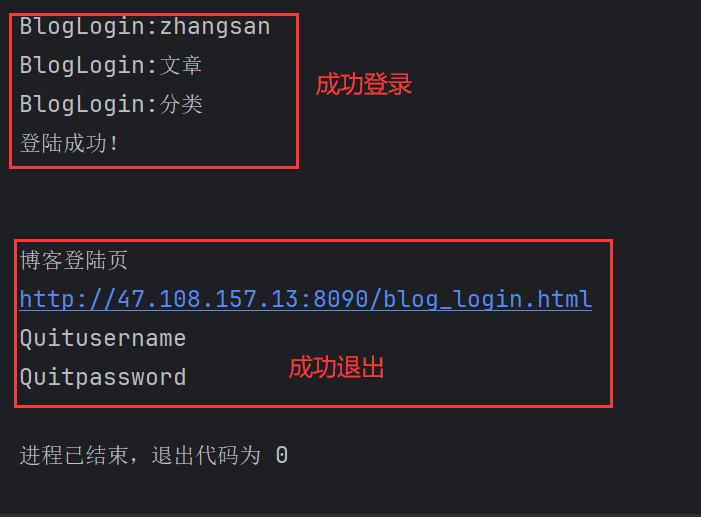
BlogDriver.driver.quit()程序运行后看打印结果说明博客能够成功退出
5.自动化测试的特点和优点
自动化测试的特点:
当我们设计好项目的测试用例后,然后在Pycharm里面利用selenium库里面很多自动化测试方法给我们编写自动化测试脚本,能够执行更加繁琐的测试用例和在一定程度上解放测试人员,避免了重复繁琐的测试过程,让测试人员有更多的精力去设计更详细的测试用例和编写性能更高的测试脚本,提高测试结果的可行度,但是重点注意的是,不是编写了自动化测试脚本后就完全不用管了,要检查和维护这个自动化测试化脚本。自动化测试的成本包括自动测试开发成本、自动测试运行成本、自动测试维护成本和其他相关任务带来的成本,以及软件的修改带来的测试脚本部分或全部修改所增加的测试维护的开销。
自动化测试的优点:
①把测试不同页面和不同功能分为不同的测试文件,提高的代码的可读性,检查的时间也方便查找出不同模块出现问题的位置
②把创建驱动放到一个python里面的python中,避免重复创建驱动的消耗,提高性能和节约空间和时间
③当代码的加载速度比页面的渲染速度快的时候,人力测试要盯着页面,而自动化测试可以使用显示等待和隐式等待可以在规定时间内等待页面加载出来,最好不要使用强制等待(消耗的时间太多)
④可以在每个测试函数调用的时候,调用在驱动对象类里面创建截图函数,来记录函数运行时的页面,当出现报错的时候可以在截图中查找问题
6.使用jmeter对博客系统进行性能测试
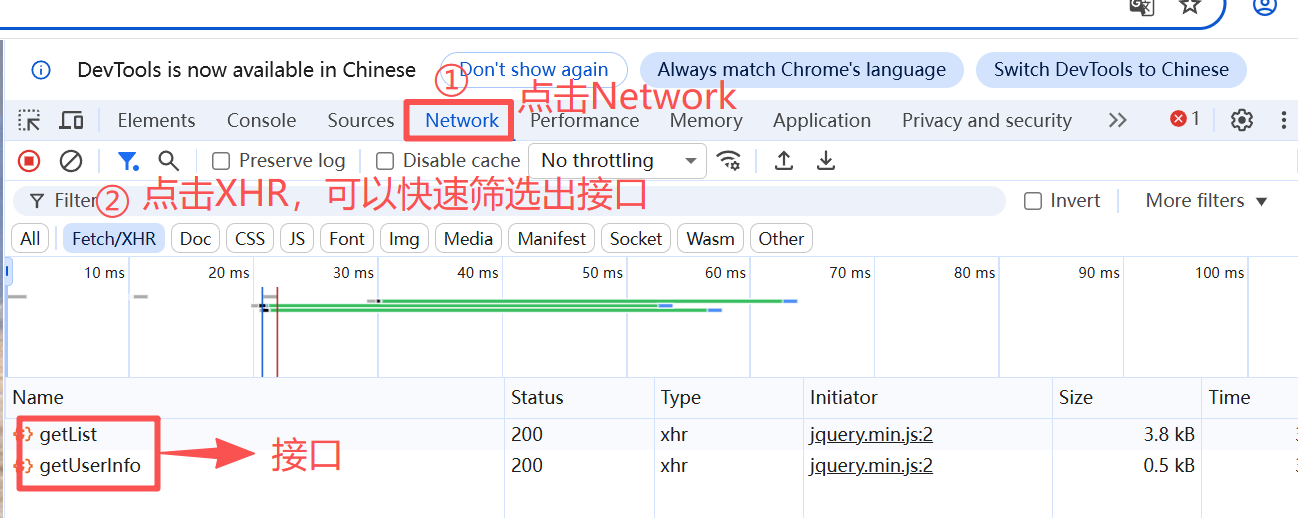
首先在浏览器的开发者工具中找到要测试的接口(ctrl+shift+i 快捷键打开开发者工具)
在使用 jmeter 工具对接口进行性能测试之前,通常会使用 postman 工具对接口进行简单的测试。
使用postman工具对登录接口进行简单的测试:
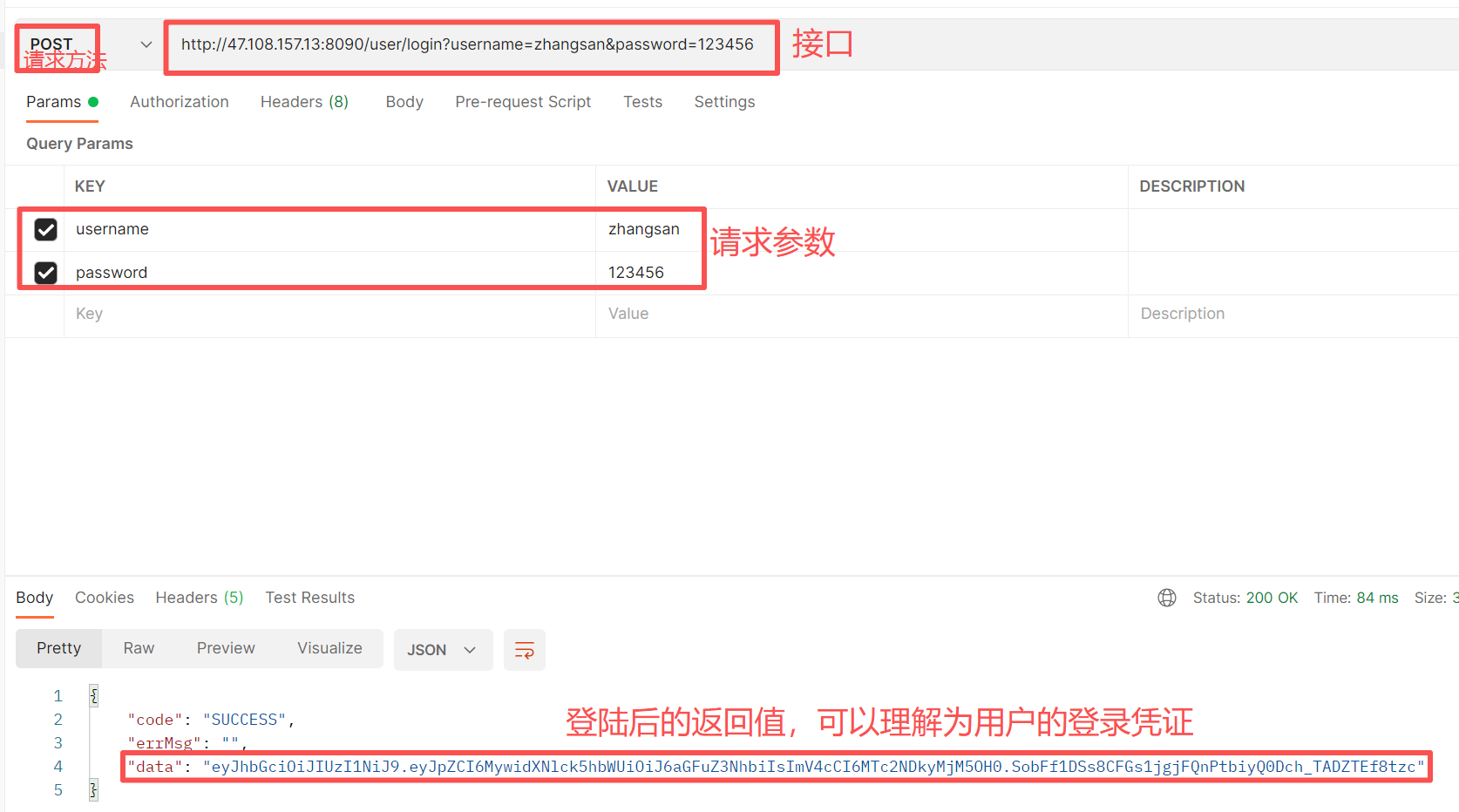
可以看到测试成功。
6.1 测试登录接口
首先创建一个线程组,在创建一个http请求,按照如下分别填写协议、IP地址、端口号、请求方法、路径和参数,然后执行测试(要想看到结果需添加查看结果树)
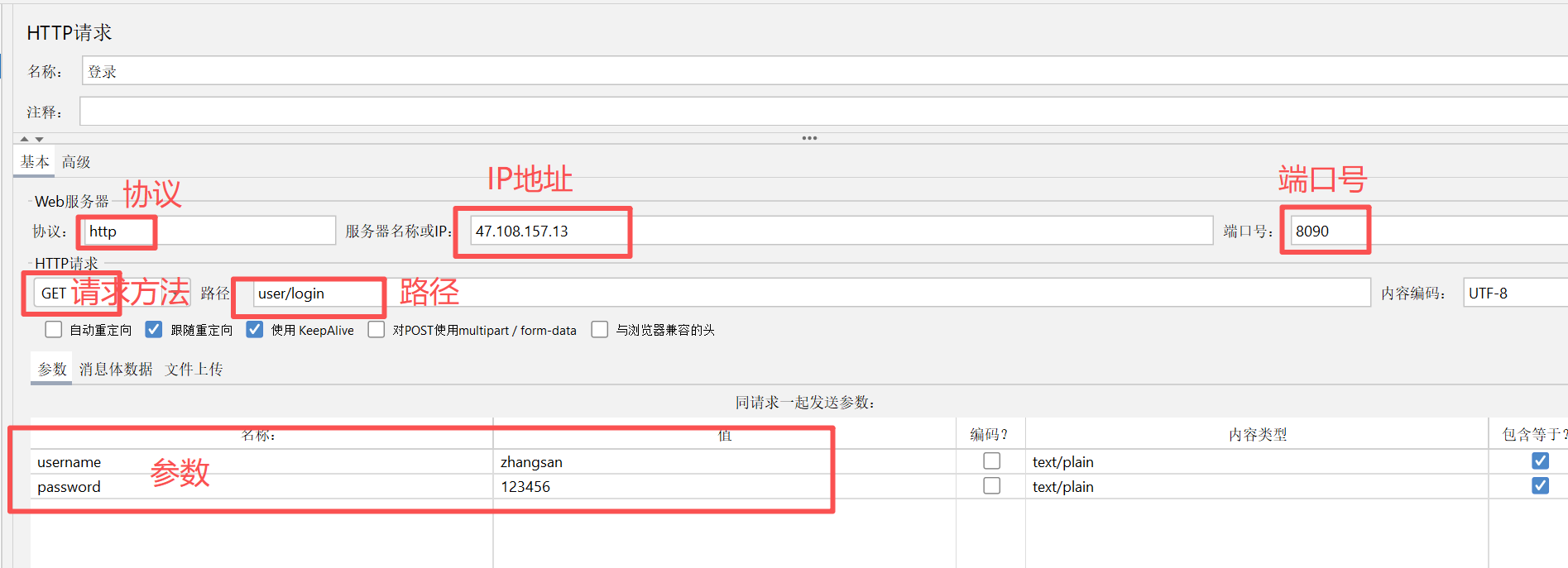
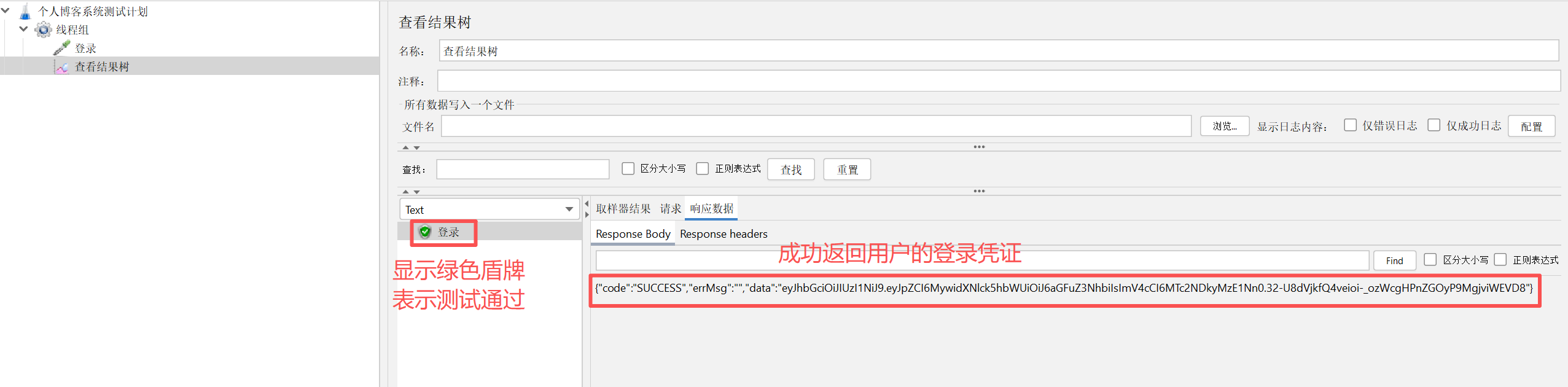
测试结果如下说明测试通过
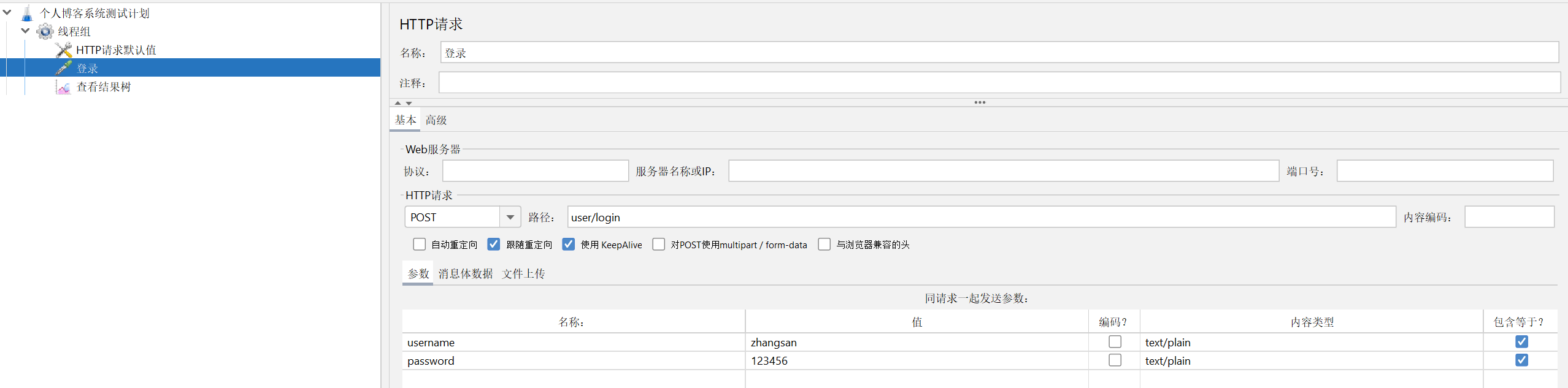
注意! 在同一个系统中协议,服务器名称或IP,端口号是不会发生变化的,所以我们可以添加一个HTTP请求默认值,这样其他页面只需要配置请求方法跟路径,其他设置在运行时会自动去HTTP请求默认值里面取

6.2 测试博客列表页接口
创建博客登录页http请求,并运行,结果却是报错的
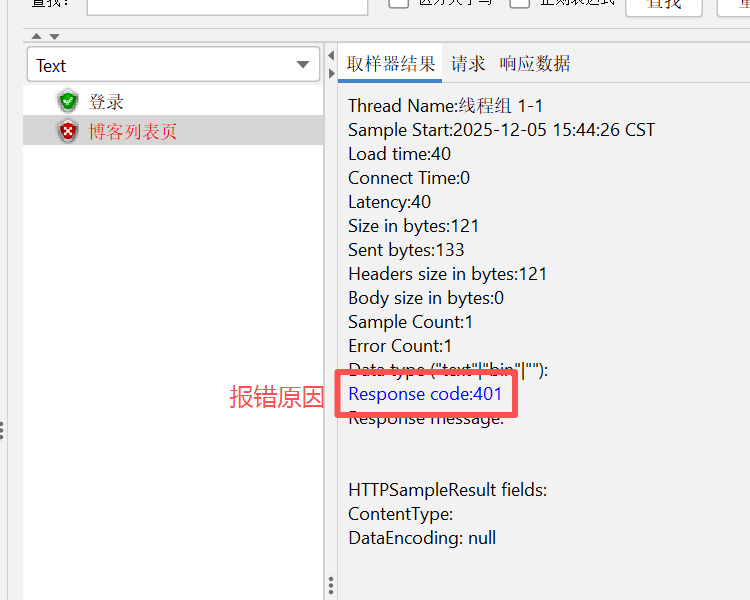
我们在postman中也进行测试,发现同样报错
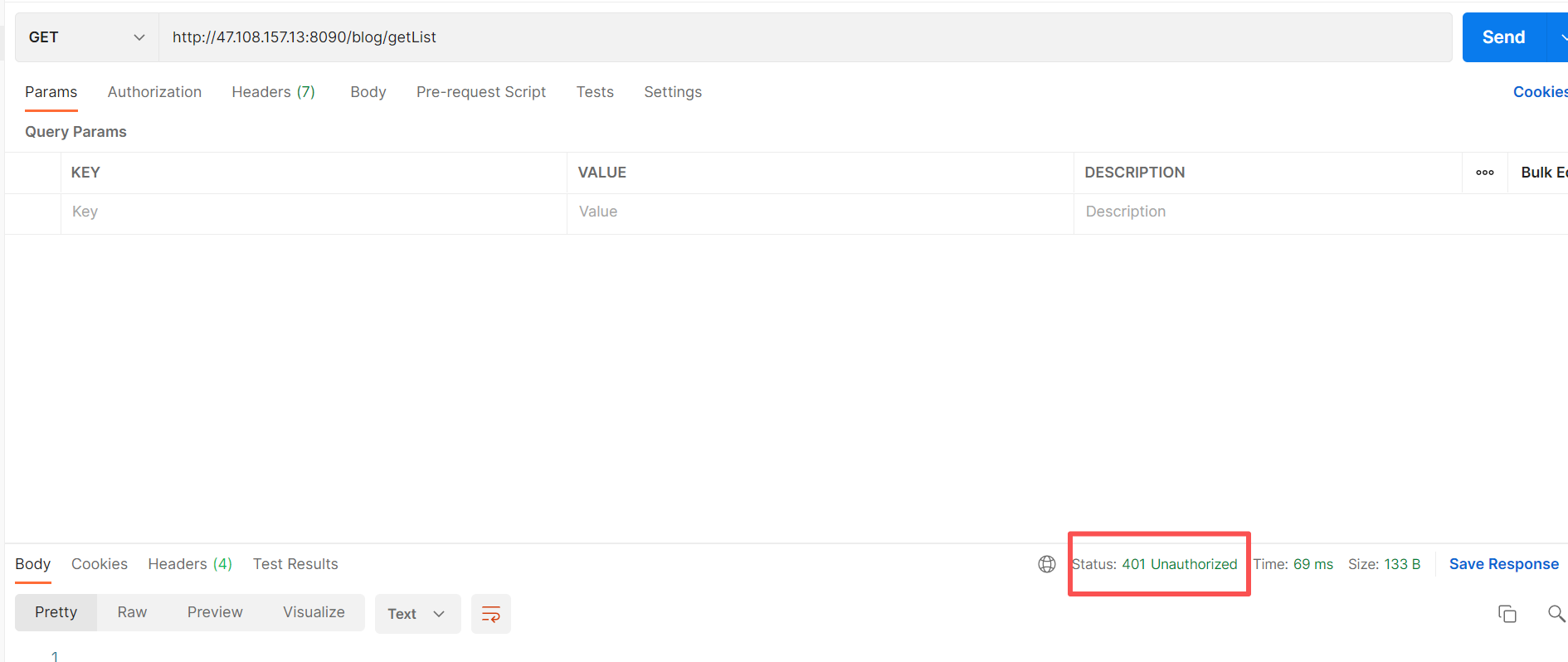
出现这样的问题是因为缺少用户的登录凭证,试想没有登录怎么能够进到登录页呢,我们可以看到在开发者工具中的请求头中有一个** user_token_header** 表示用户的登录状态,也就是用户的登录凭证,但是 postman 的请求头参数中中却没有,所以要加上这个参数
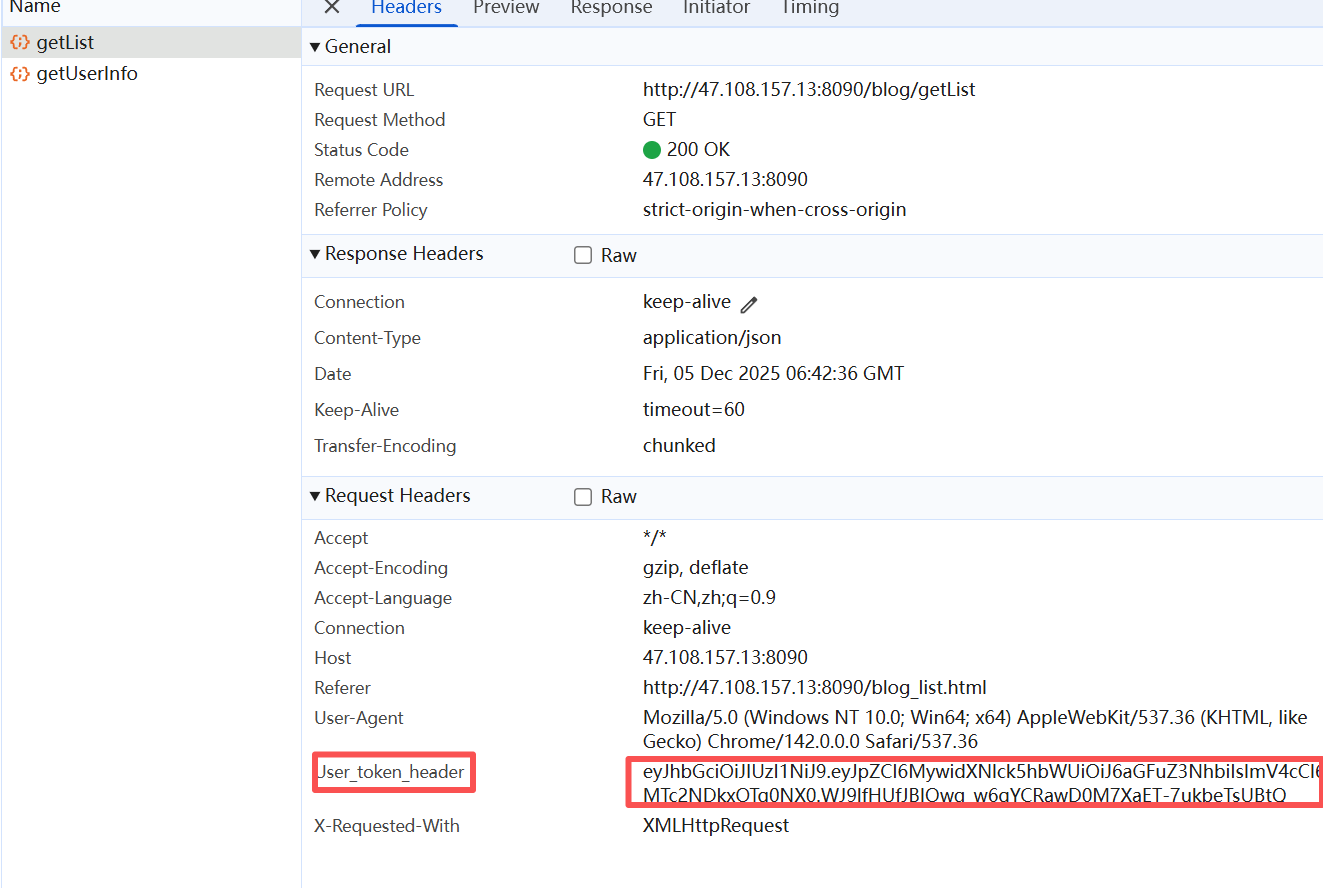
加上这个参数后可以看到运行成功
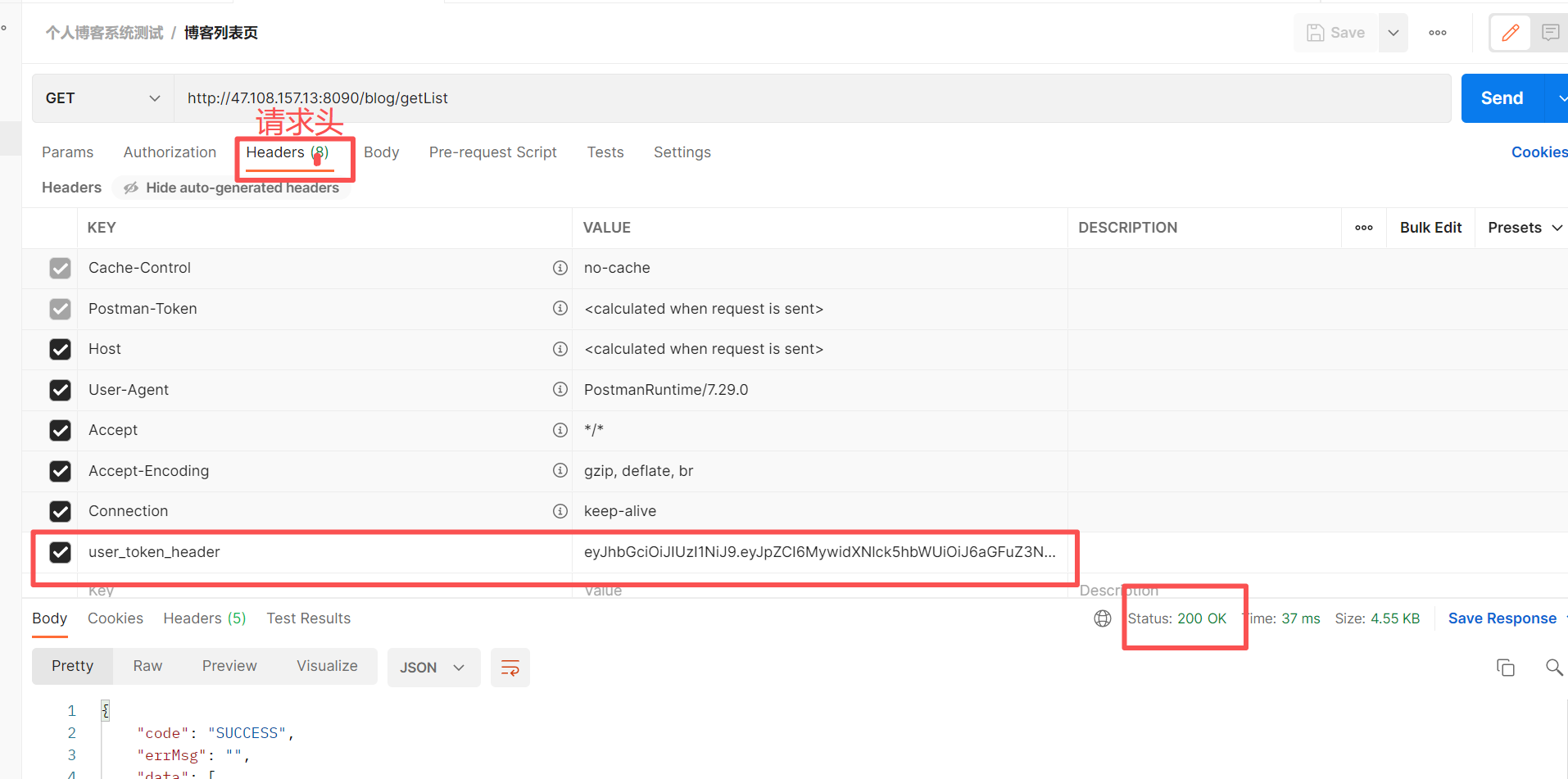
那么在 jmeter 中如何添加这个参数呢?这里我们可以使用json提取器 来提取登录页面的返回值,也就是登录凭证
json提取器 :放在登录的子路径下(json提取器会重复提取data),使该提取器只提取登录接口的用户凭证
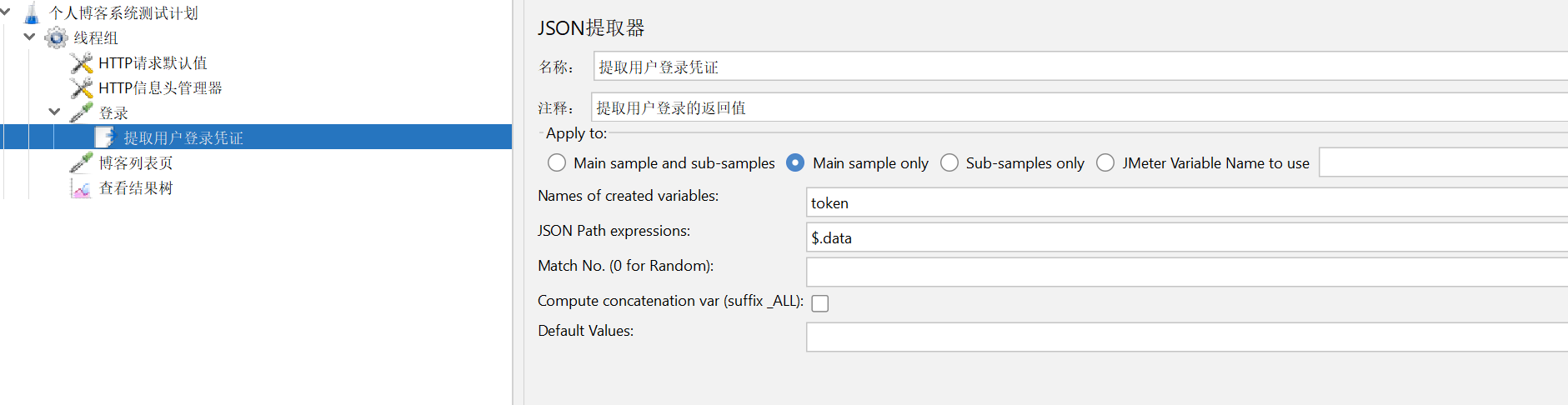
HTTP信息头管理器 :将提取到的用户凭证放到信息头管理器中,运行时http请求的请求头会自动拼接该登录凭证

所有准备做好后在运行会发现能够成功运行
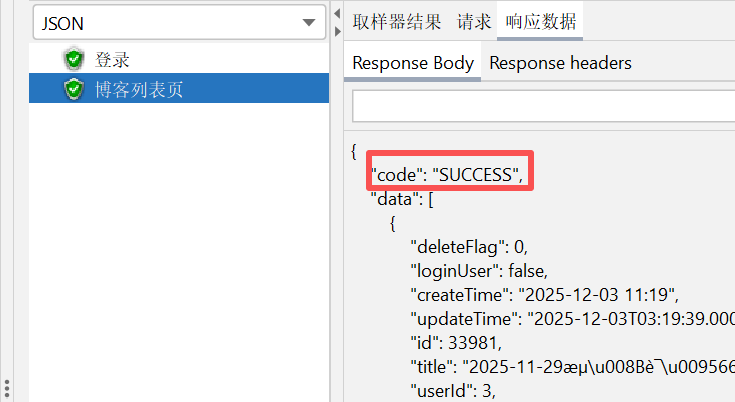
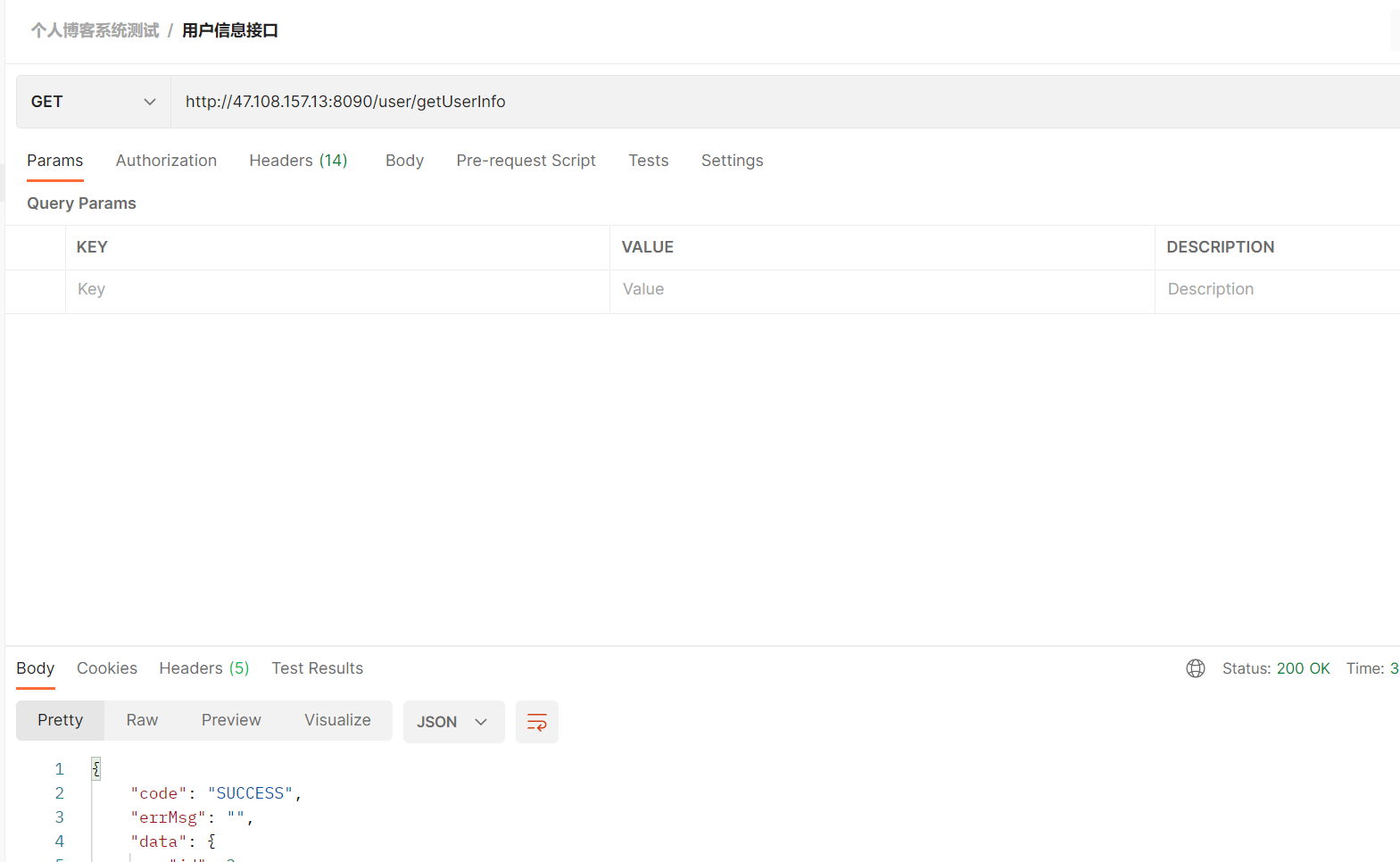
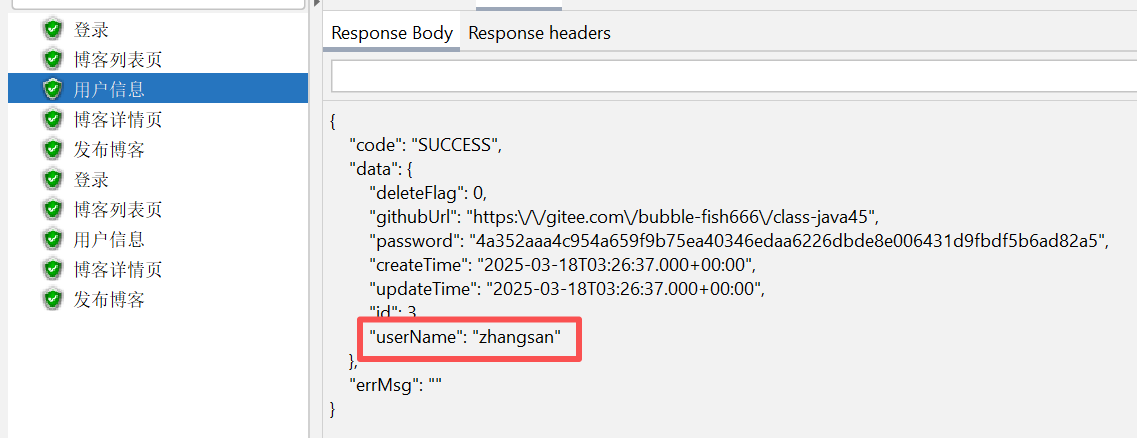
6.3 测试博客用户个人信息接口
可以看到有了登录凭证在 postman 中运行是成功的:
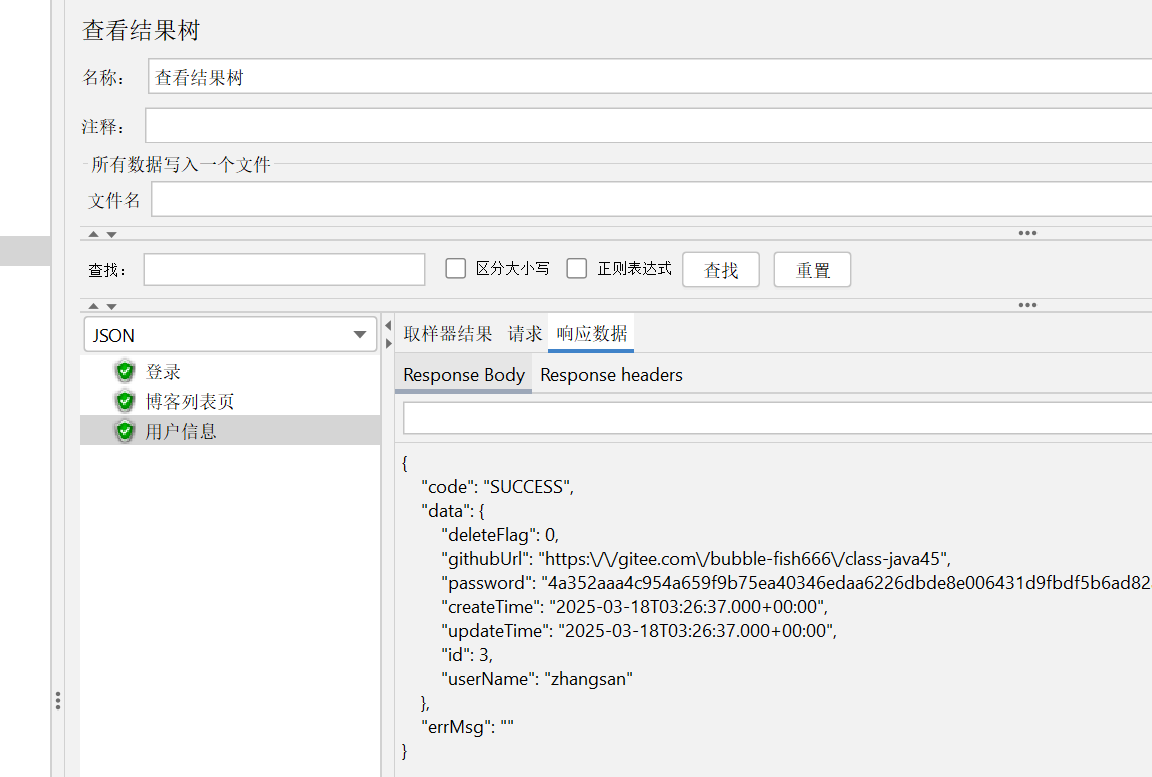
在 jmeter 上运行也是成功的:
6.4 测试博客详情页接口
在 postman 上可以跑通
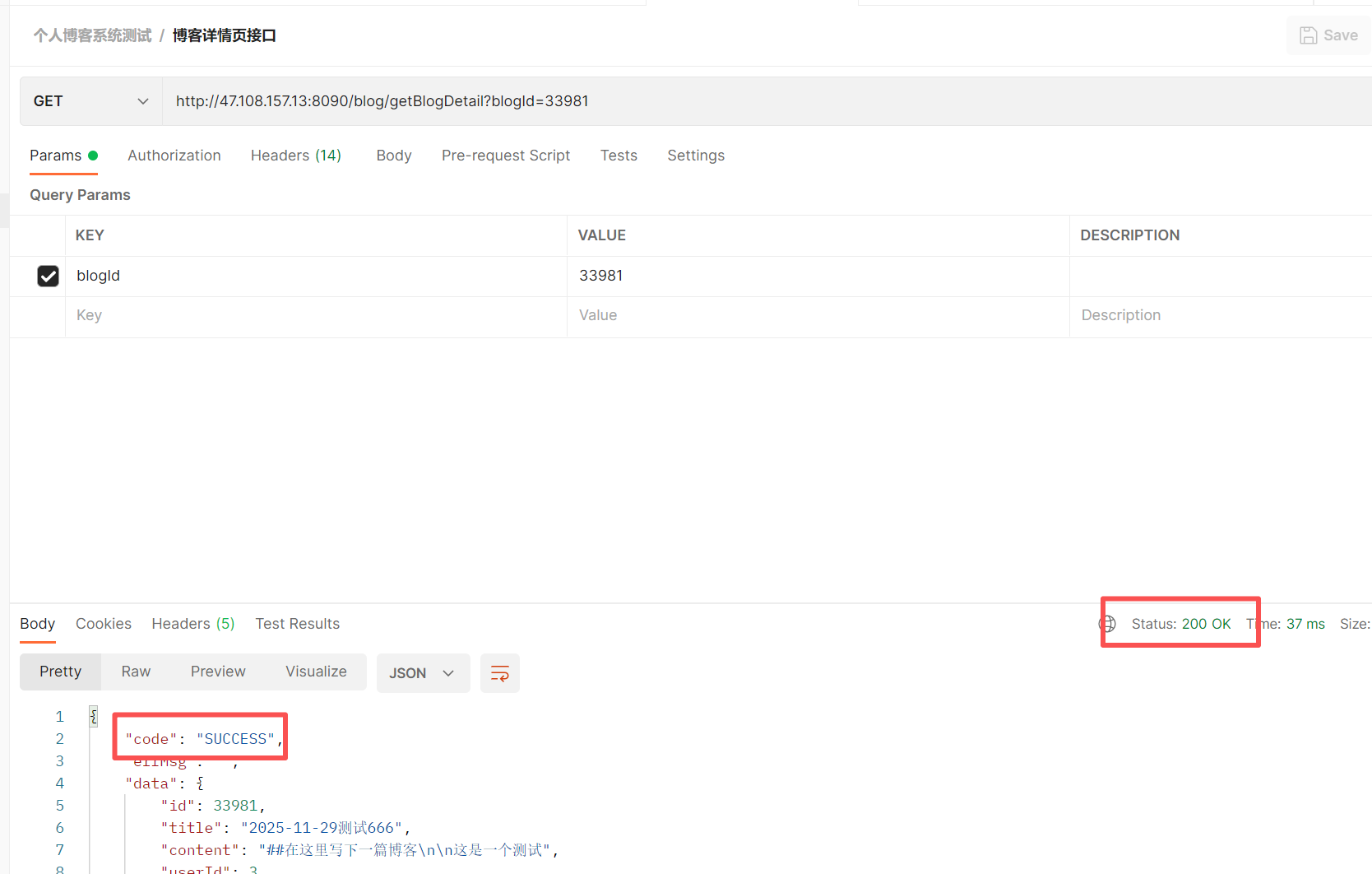
在 jmeter 上跑也可以跑通
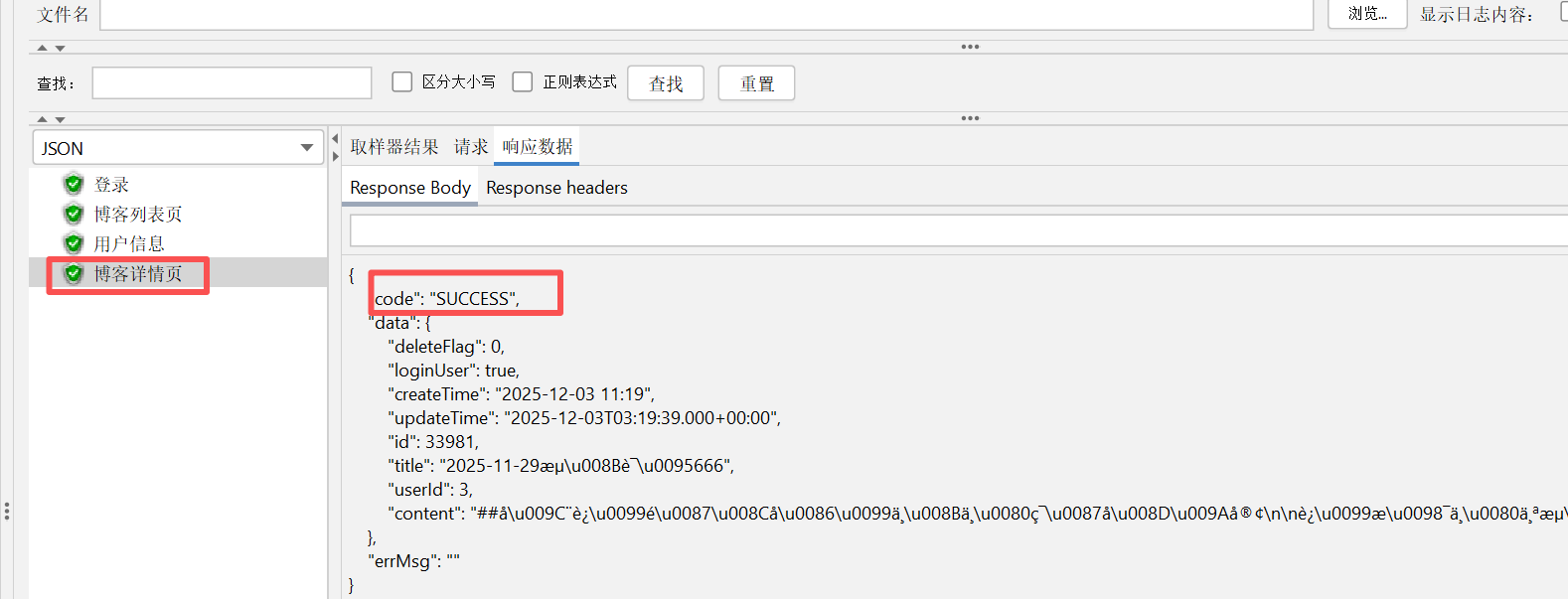
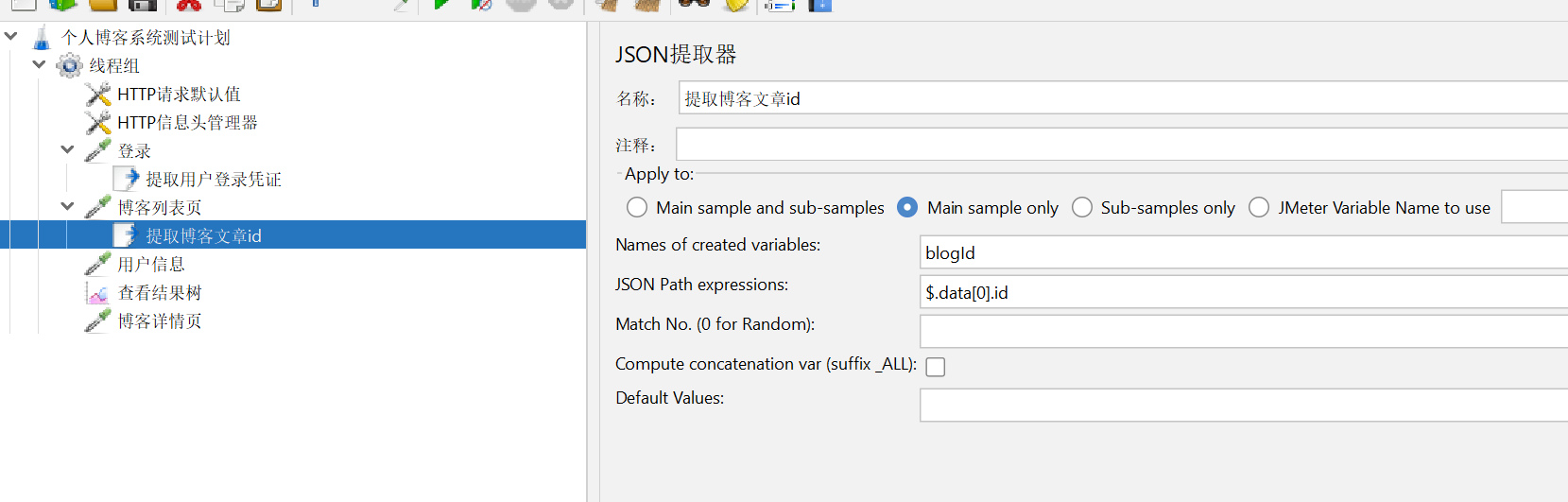
但是我们对接口进行大量测试的时候肯定不止测试一次,这上面的博客文章id 是写死的,如果我们在大量测试的时候想换一篇博客进行测试,我们只能手动一个一个的修改博客文章id ,那么如何避免这样的情况发生呢?这里可以继续使用我们的json提取器 来提取博客文章的id ,新建一个json提取器并放在博客列表页的子路径下,并提取博客列表页的博客文章id
提取博客文章id
修改博客详情页路径
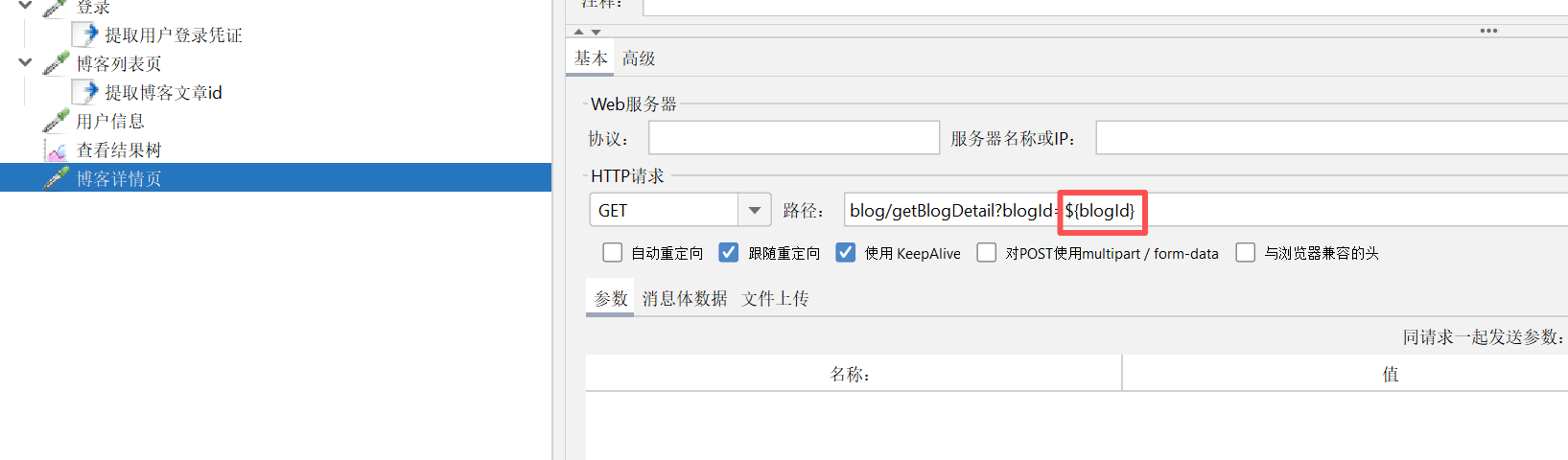
这样我们只需要修改提取博客文章id 的参数就可以自动修改博客详情页接口的博客文章id
6.5 测试添加博客接口
在 postman 可以添加博客
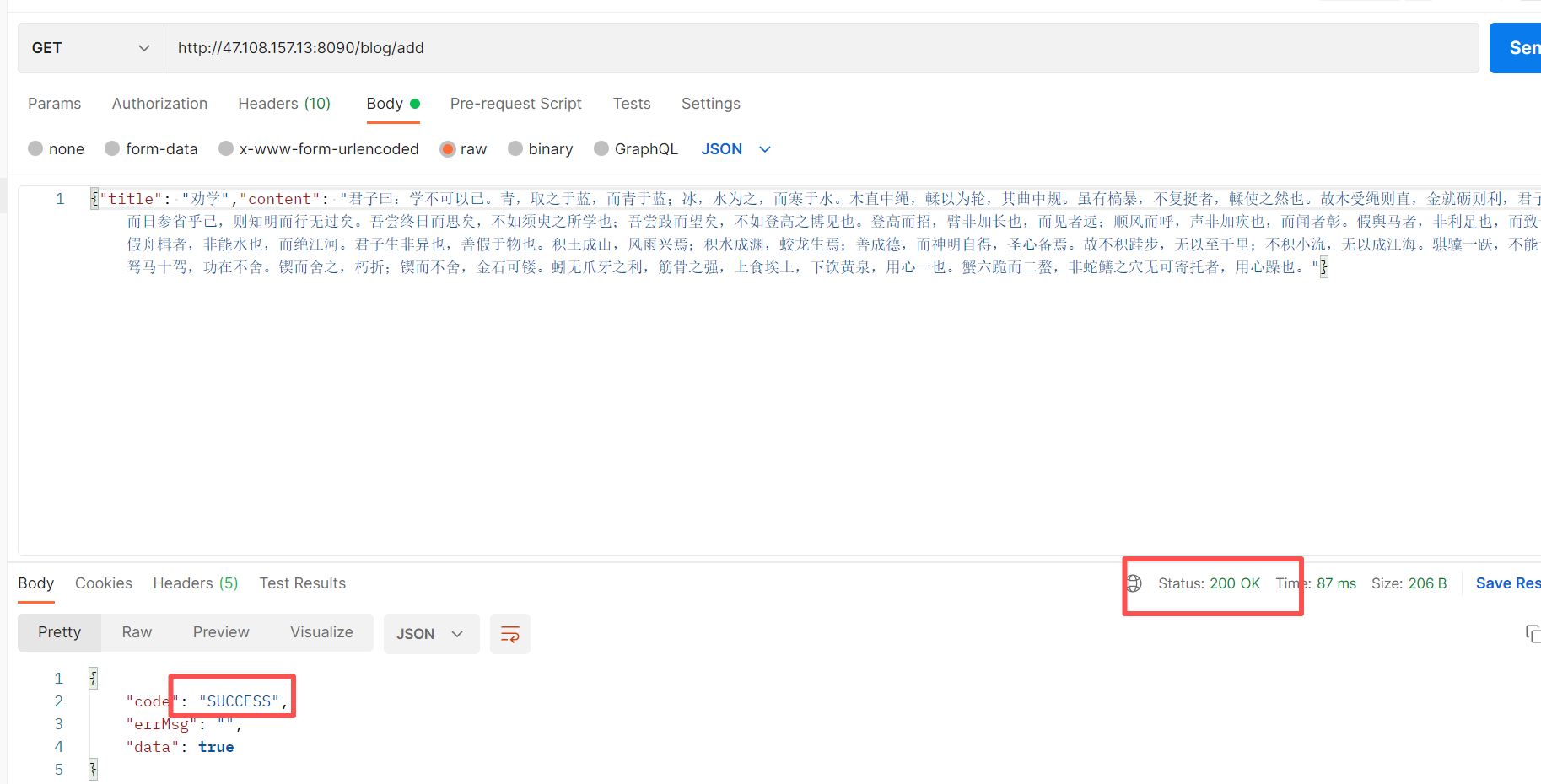
博客列表页也成功创建该博客

接下来在 jmeter 中添加博客
运行过后发现报错(虽然这里盾为绿色,但是这不是判断成功的唯一标准,可以看到请求体的状态为fail)
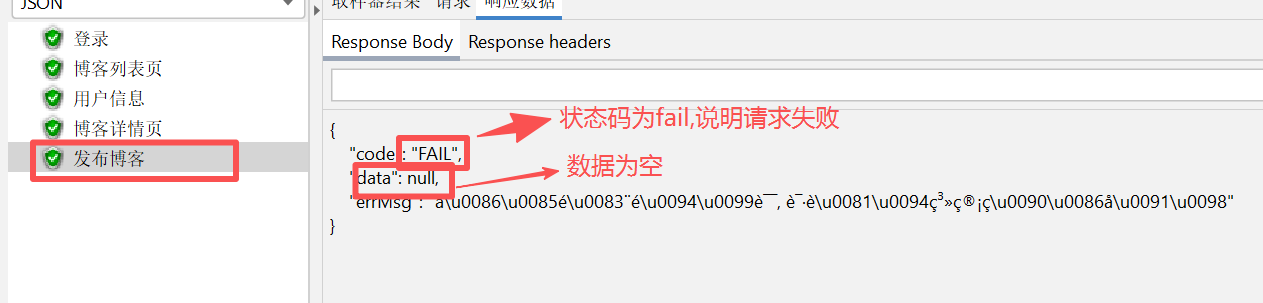
这是为什么呢,我们已经添加了登录凭证,其他接口也能成功运。,现在只能看看请求头是不是还有别的问题,上面可以看到在 postman 上可以跑起来,那么就对比 postman 的请求头、开发者工具界面的请求头和 jmeter 的请求头参数
经对比,我们可以看到开发者工具上面和postman的content-Type:是application/json,而jmeter的content-Type:是text/plain
postman请求头参数
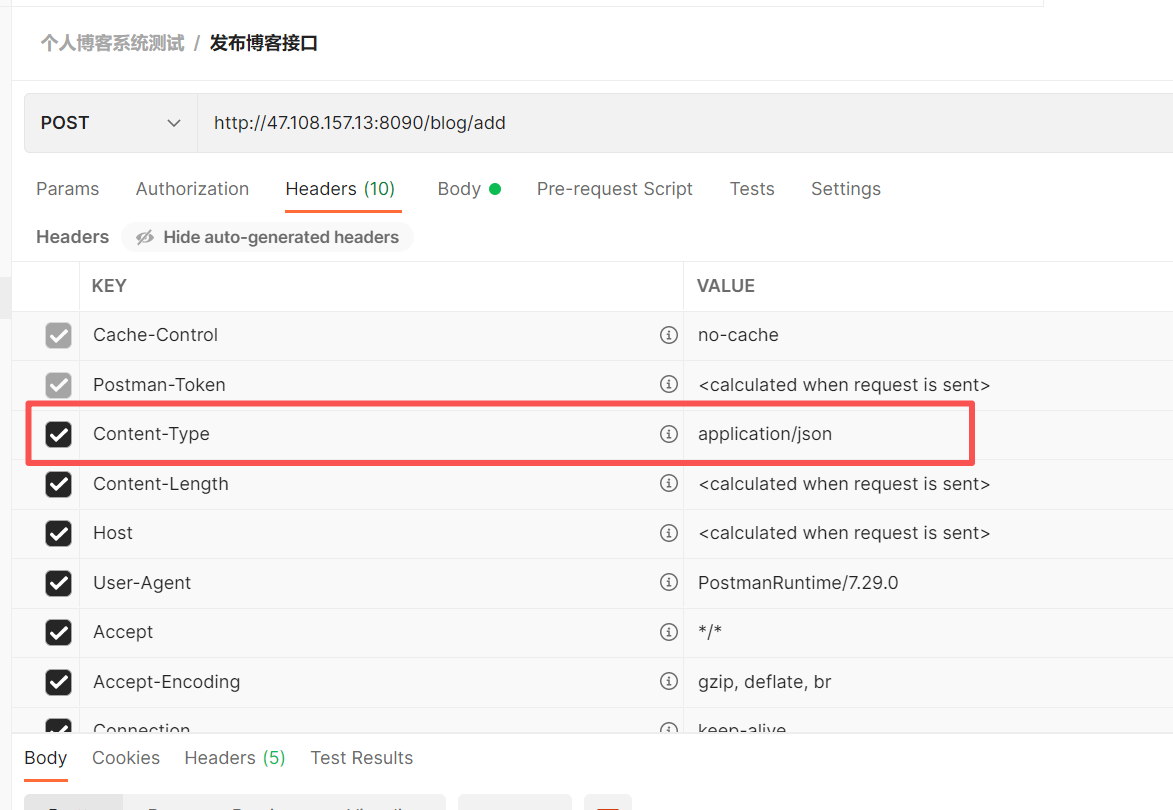
开发者工具请求头参数
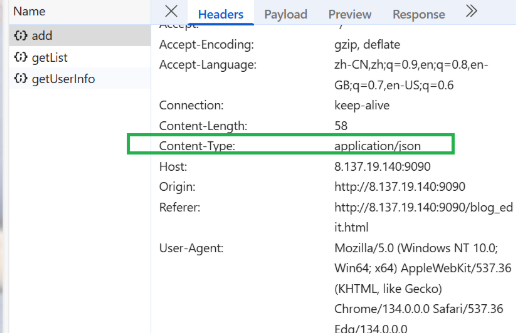
jmeter请求头参数
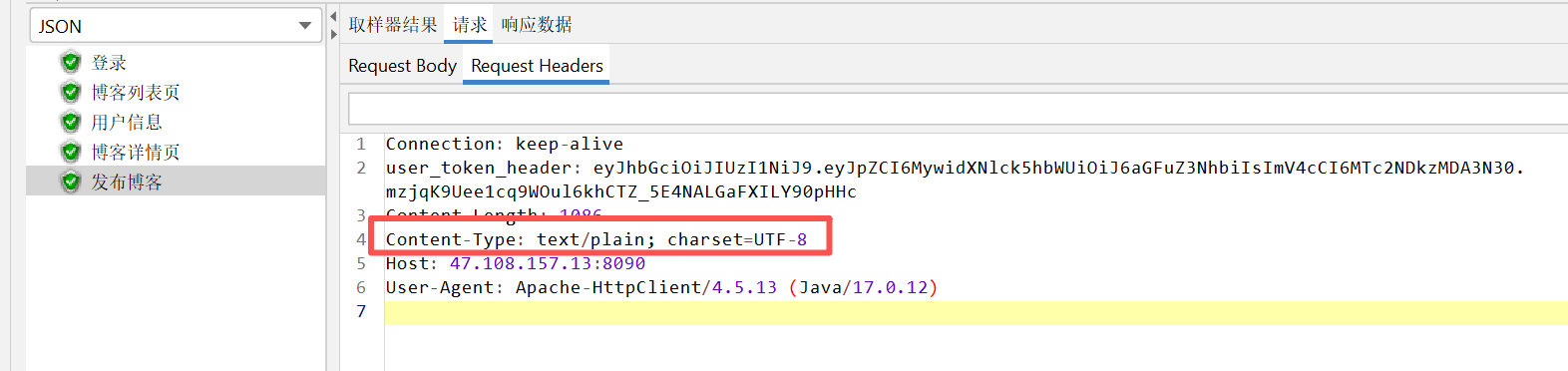
那么如何解决这个问题呢?这很简单,既然jmeter的请求头跟要用的不一样,那我们创建一个信息头管理器来更改一下jmeter的content-Type的内容,这个信息头管理器只能作用于发布博客接口(登录接口的请求头参数content-Type跟别的也不一样,如果更改登录接口就会失败,返回不了用户登录凭证)
可以看到更改信息头后状态码为 SUCCESS 返回数据为 true
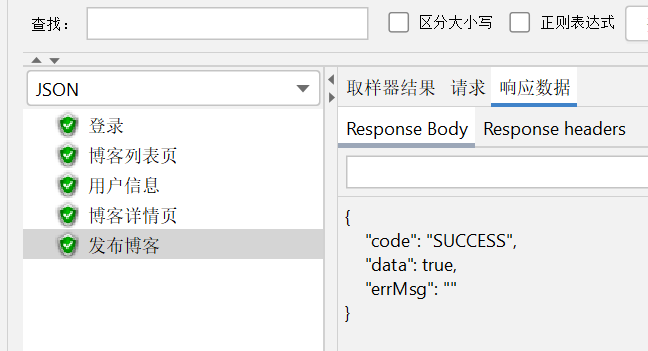
博客列表页也成功发布第二篇文章

6.6 完善测试细节
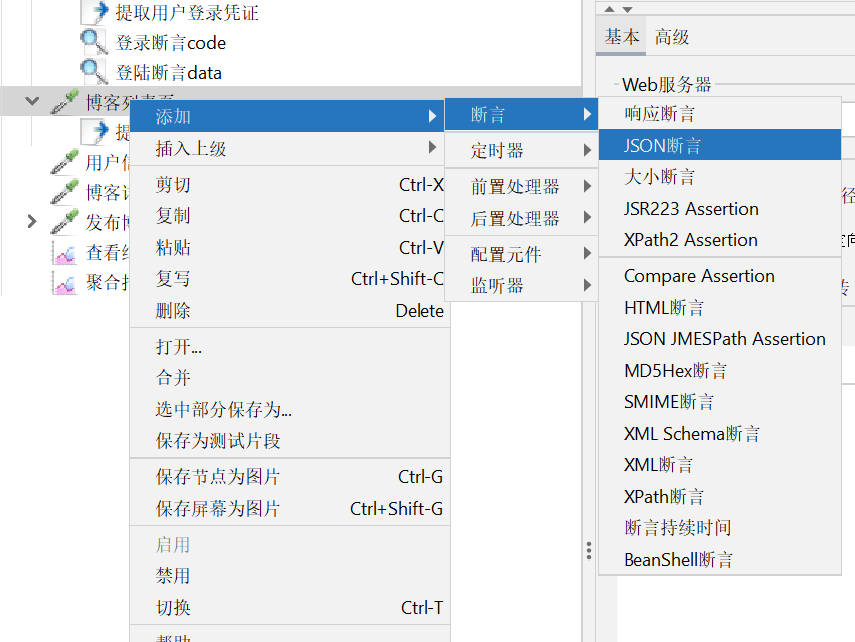
6.6.1 测试添加JSON断言
为什么要添加JSON断言呢?我们上面做的都是单线程测试,当我们进行负载测试或者压力测试时,需要多个线程并发执行,这样会有多个http请求,我们不可能每个请求结果都去细看,添加JSON断言可以帮助我们判断测试结果是否正确
如何添加JSON断言:
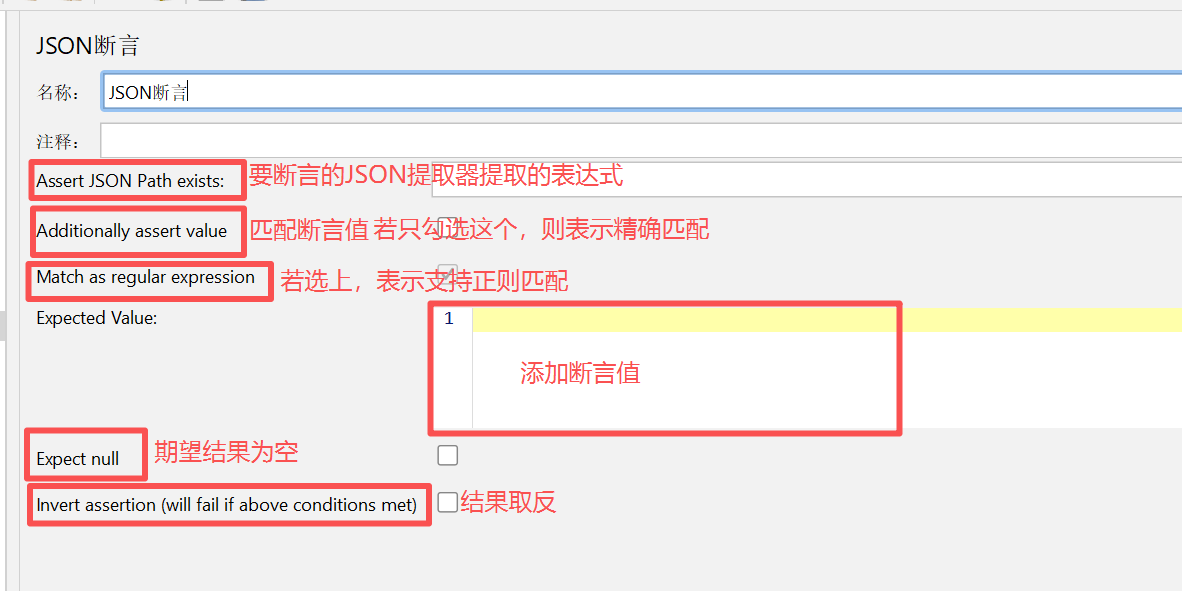
附带正则匹配语法的链接,感兴趣的可以了解 https://www.runoob.com/regexp/regexp-syntax.html
可以看到,在添加了JSON断言后测试依旧成功
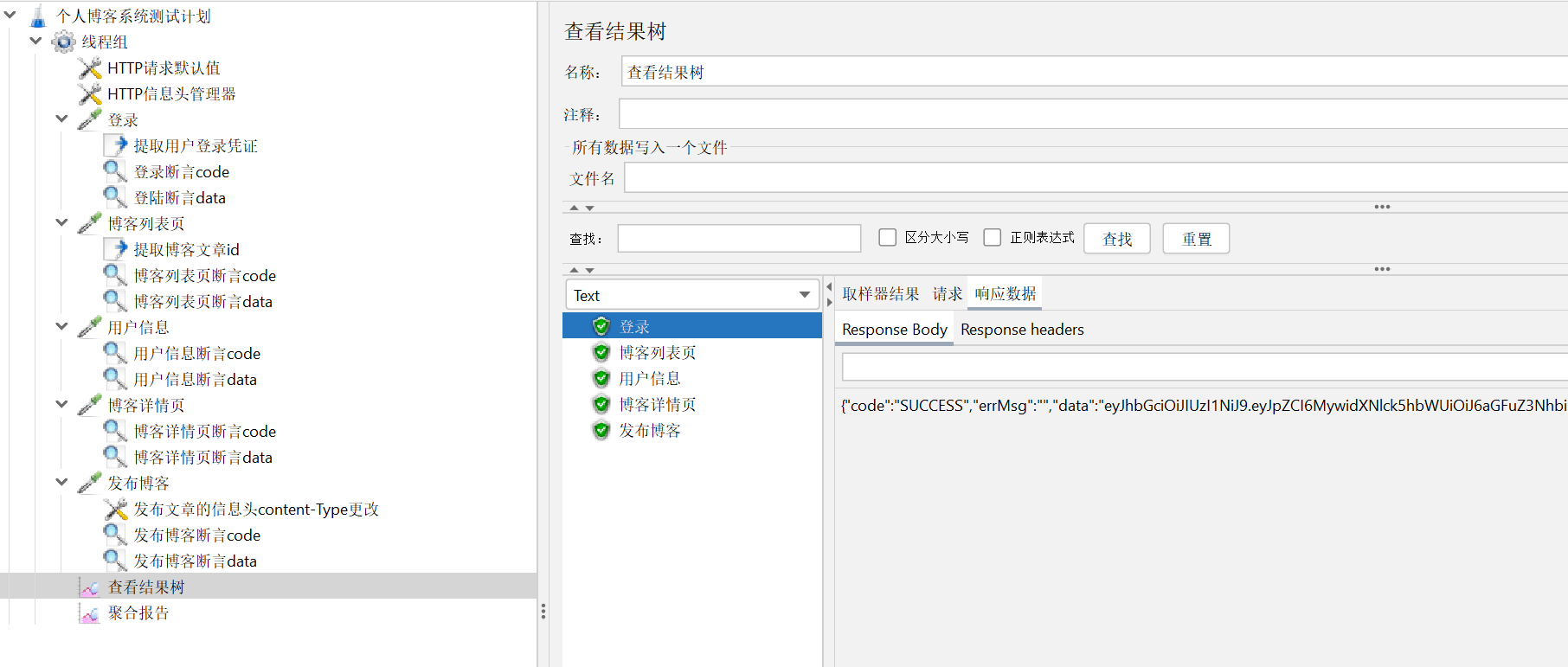
6.6.2 添加CSV数据文件设置
以登陆接口为例,当我们执行登陆接口的性能测试时,⼿动配置了用户名和密码为固定的username和 password,这样会导致账号和密码被写死,执行测试的时候用户永远只有这一个,然而实际使⽤中不可能只有⼀个用户登陆,为了模拟更真实的登录环境,我们需要添加CSV数据文件设置来提供更多的用户username和password来实现登录操作
添加CSV数据文件设置:
① 首先用excel工具创建表格并按如下填写账号和密码
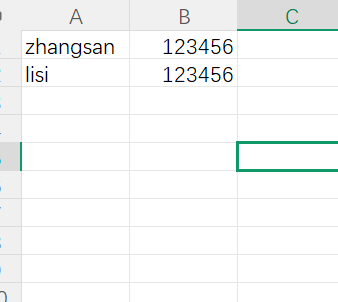
② 然后保存为 .csv 文件并放在 性能测试文件同级目录下(保存的时候要选择为 .csv格式,不能先选用其他格式在修改后缀为.csv,这样文件会出错)
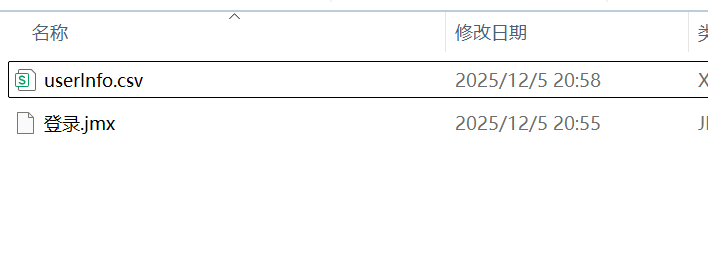
③ 添加CSV数据文件设置并导入该 .csv文件
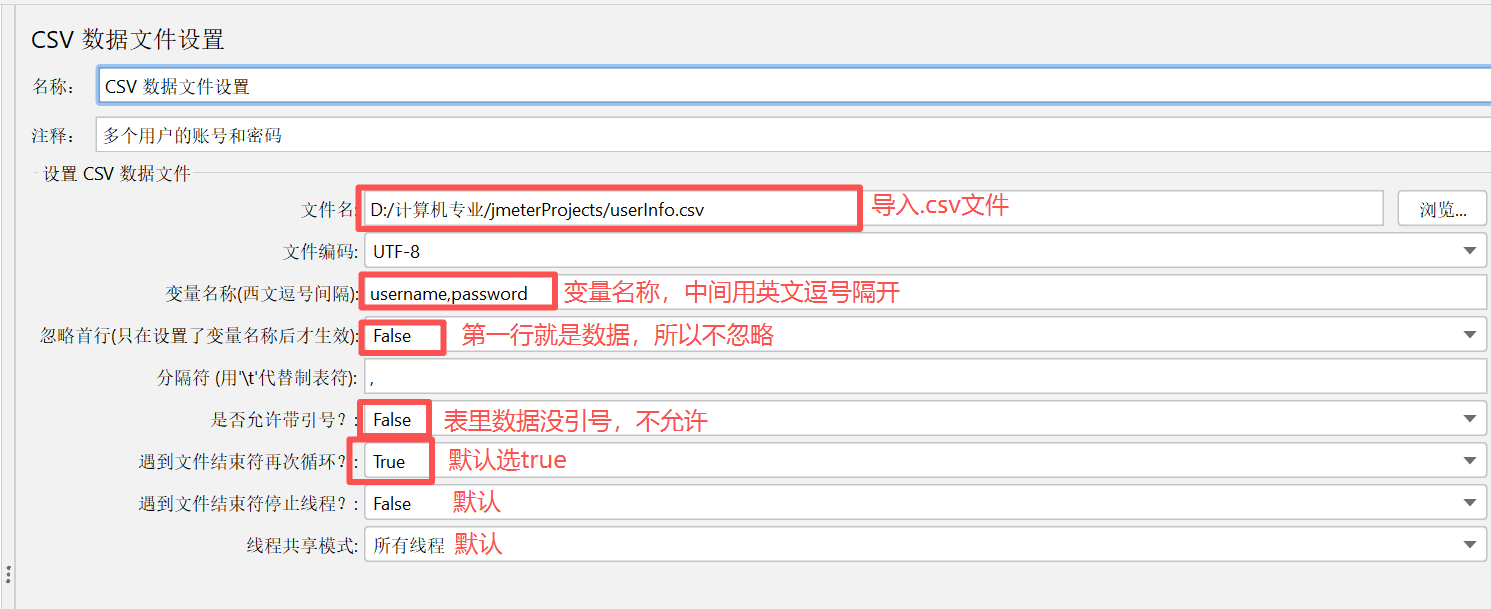
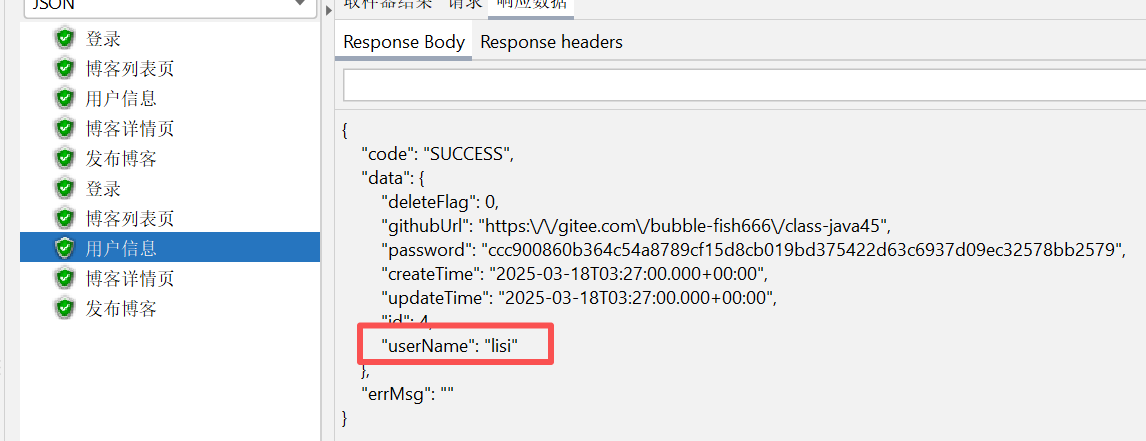
④ 修改登录参数的数据
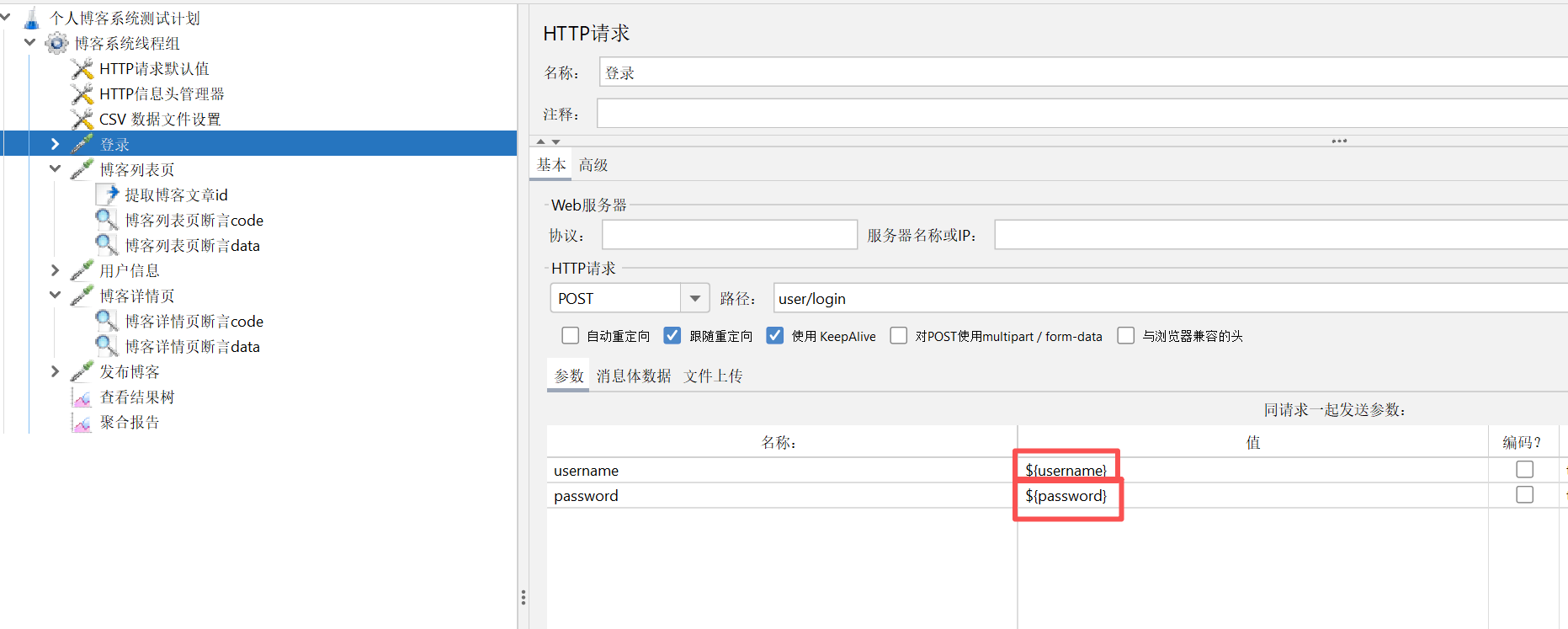
在结果树中可以看到登陆了两个不同的用户
6.6.3 真正的性能测试
假如我们要模拟实现最大4000个用户来并发执行,可以在线程组中直接配置4000个线程数,这样可以使这4000个线程在规定时限内发送请求。但是在实际测试过程中是一点一点的增加并发(一上来就给很大,可能直接给服务器干奔溃了),因此需要在 jmeter 中添加两个插件。
第一个插件:

第二个插件:

安装完这两个插件后线程组和监视器会多出这些东西:
Stepping Thread Group(梯度压测线程组):
添加完成后,我们就需要把线程组替换为梯度压测线程组(模拟多用户逐步增加线程)
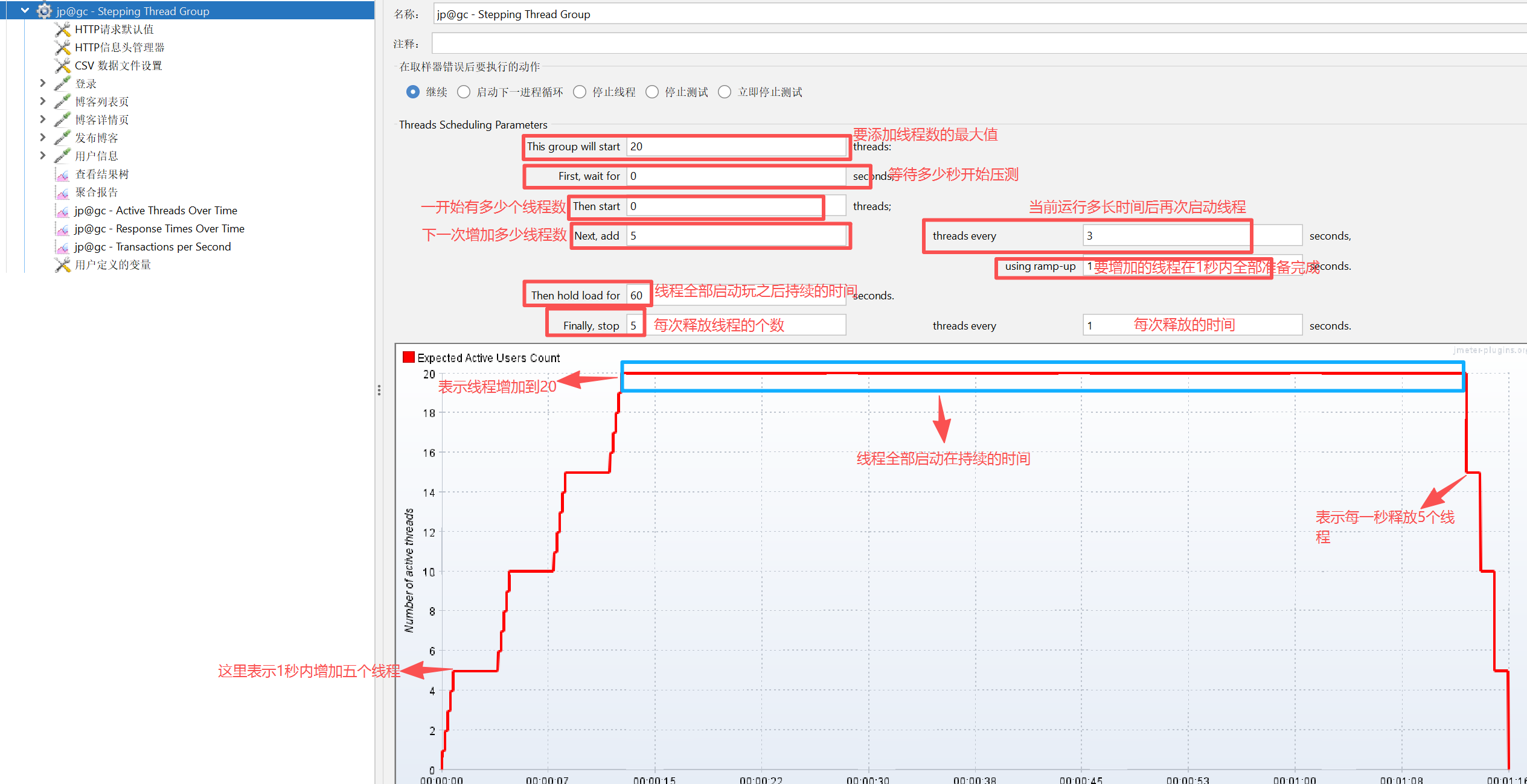
This group will start:启动多少个线程,同线程组中的线程数
First, wait for:等待多少秒才开始压测,⼀般默认为0
Then start:⼀开始有多少个线程数,⼀般默认为0
Next,add:下⼀次增加多少个线程数
threads every:当前运⾏多⻓时间后再次启动线程,即每⼀次线程启动完成之后的的持续时间;
using ramp-up:启动线程的时间;若设置为5秒,表⽰每次启动线程都持续5秒
thenhold loadfor:线程全部启动完之后持续运⾏多⻓时间
finally,stop/threadsevery:多⻓时间释放多少个线程;若设置为5个和1秒,表⽰持续负载结束之后每1秒钟释放5个线程
再在该线程组中添加一下三个监听器:

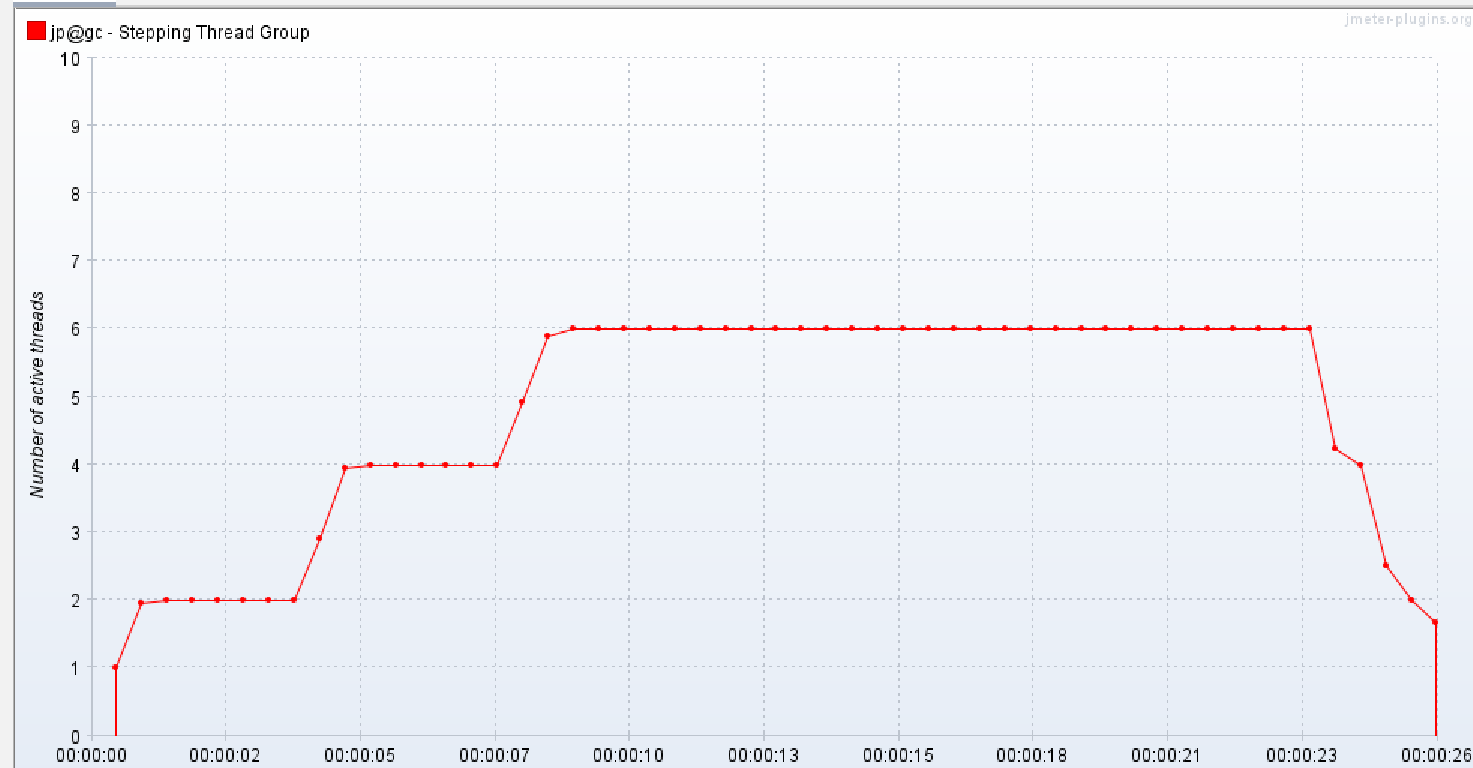
运行:
看一下活跃的线程数量:
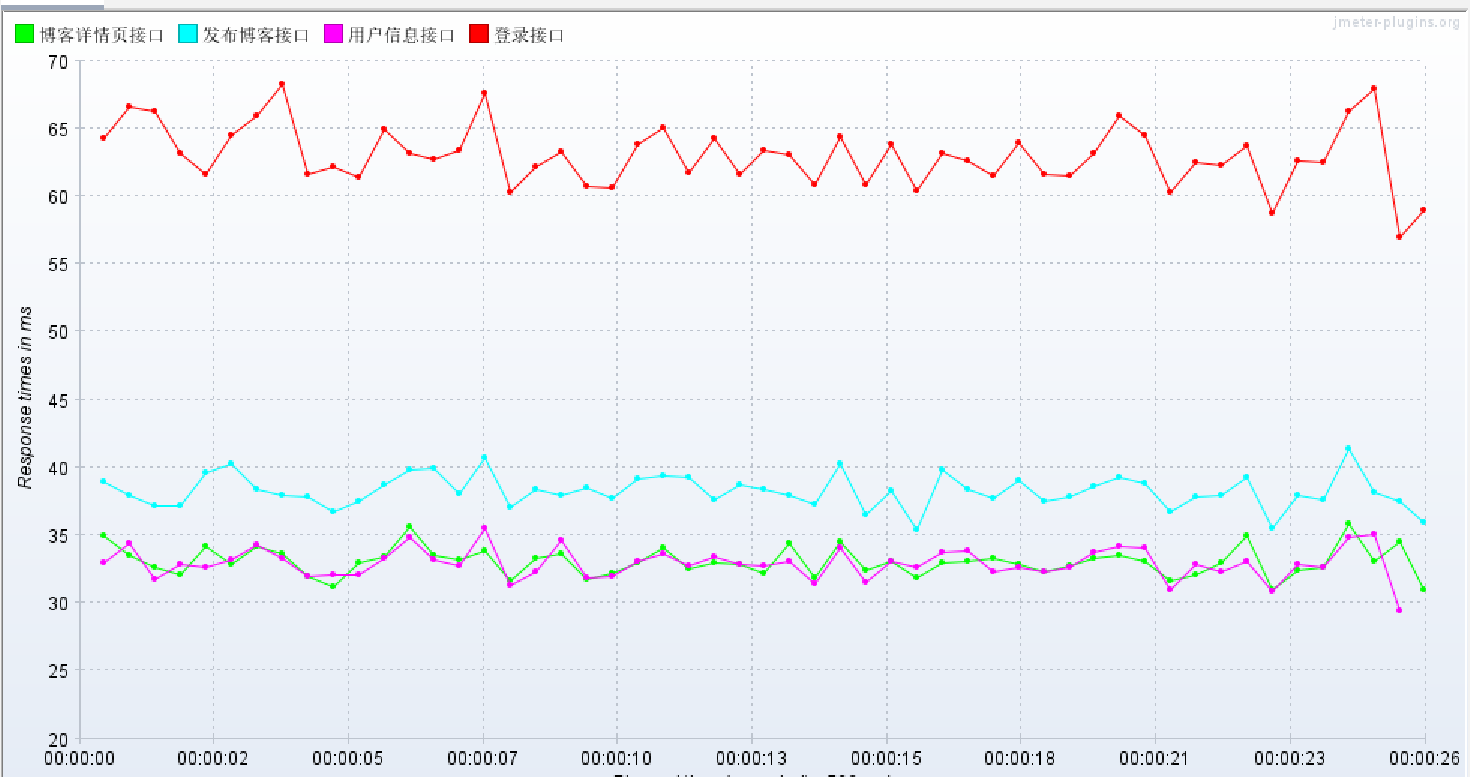
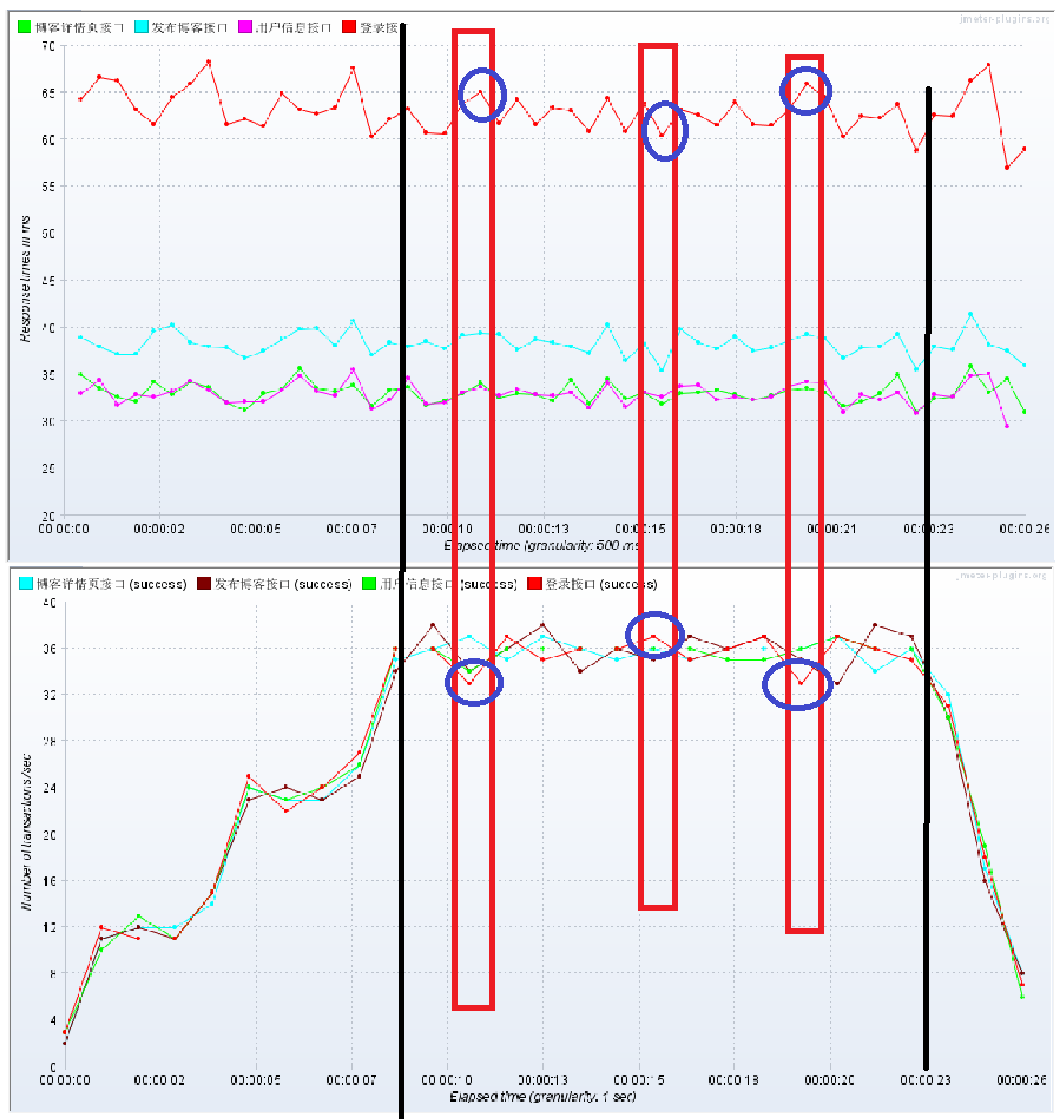
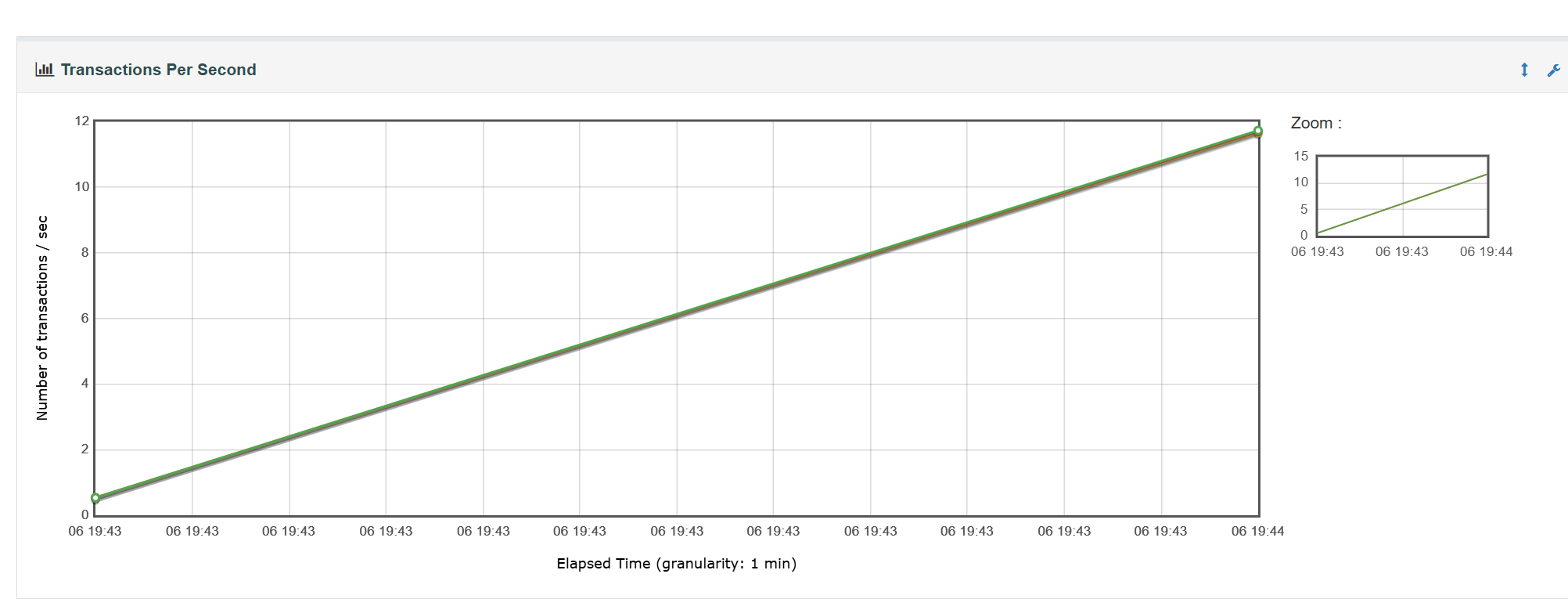
看一下响应时间:看图可以看到折线很平稳,没有太大的波动
看一下吞吐量:可以看到吞吐量先增加,在平缓,在23秒快结束的时候吞吐量才下降,结合上面的响应时间可以知道本次性能测试在系统的承受范围之内。
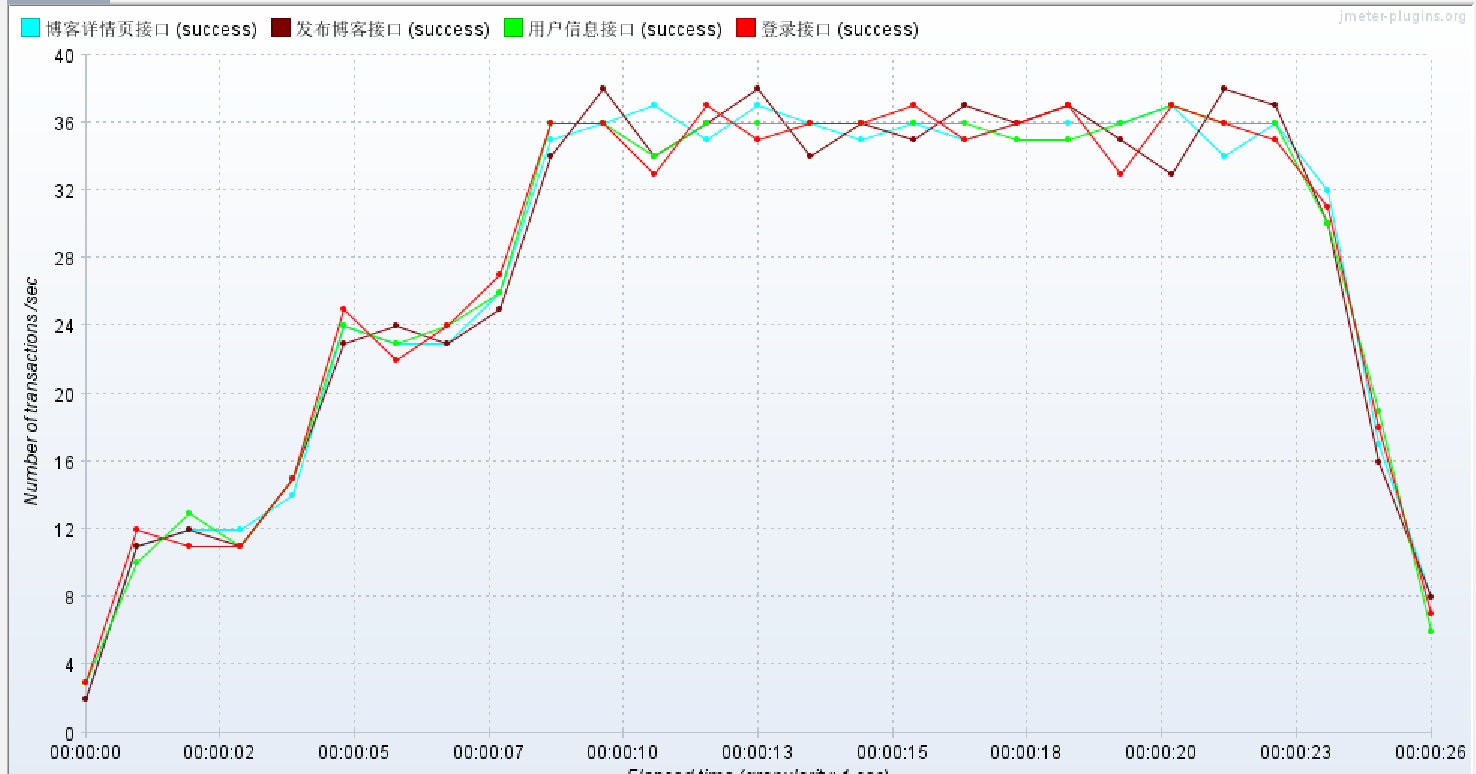
响应时间和吞吐量的关系:(响应时间高,吞吐量就低)
两图对比可以看出响应时间增加了,服务器就有了压力,这个时间服务器处理的并发数量是有限的,所以吞吐量就降低了
6.6.4 生成测试报告
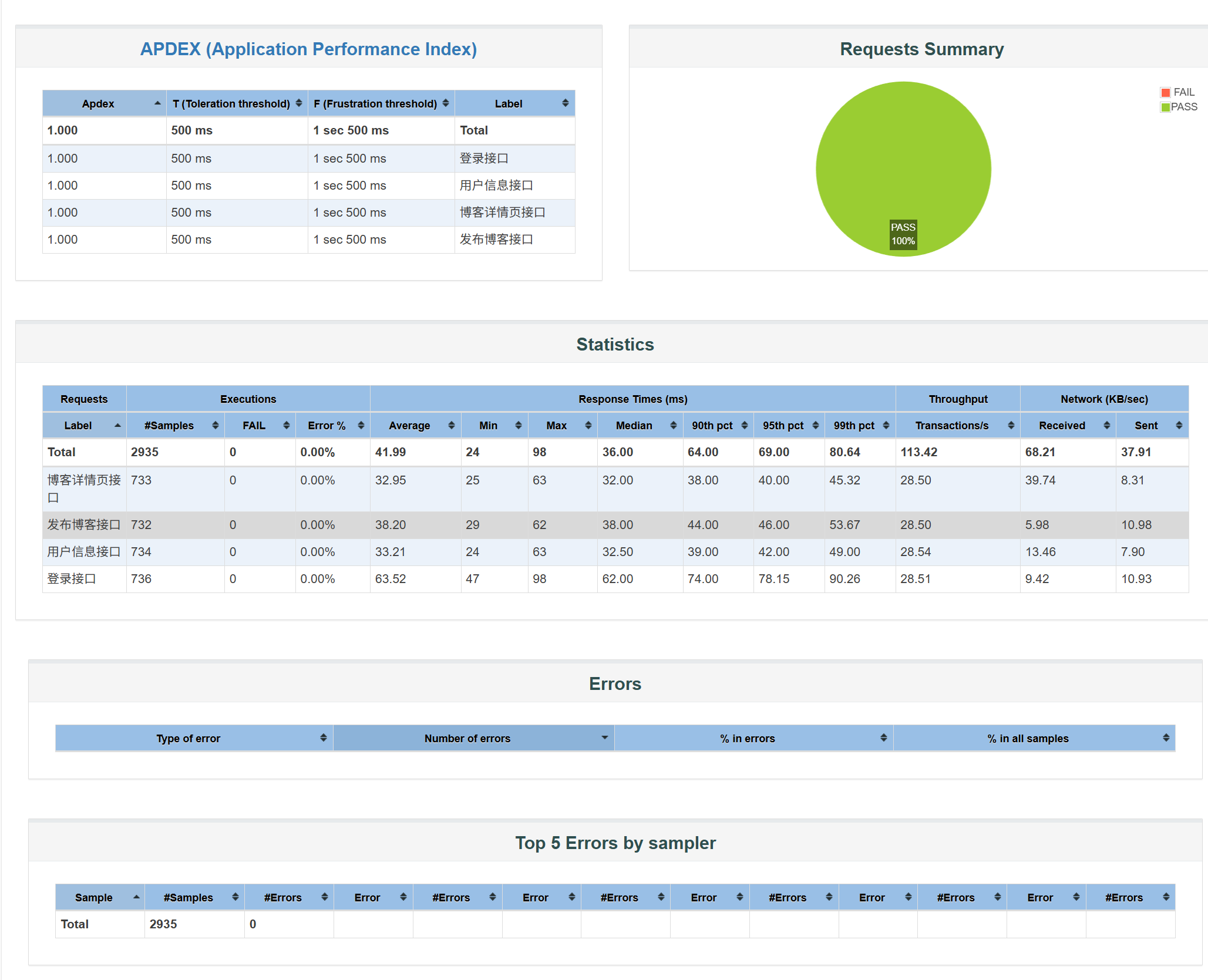
JMeter测试报告是⼀个全⾯⽽详细的⽂档,它提供了关于测试执⾏结果的详细信息,帮助⽤⼾全⾯评 估系统的性能并进⾏性能优化。
生成性能测试报告的命令:在终端执行命令(win+R)
生成测试报告的命令格式如下:
Jmeter -n -t 脚本⽂件 -l ⽇志⽂件 -e -o ⽬录
-n : 无图形化运行
-t : 被运行的脚本
-l : 将运⾏信息写入日志文件,后缀为 jtl 的日志文件
-e : 生成测试报告
-o : 指定报告输出⽬录

测试报告详情:
响应时间:
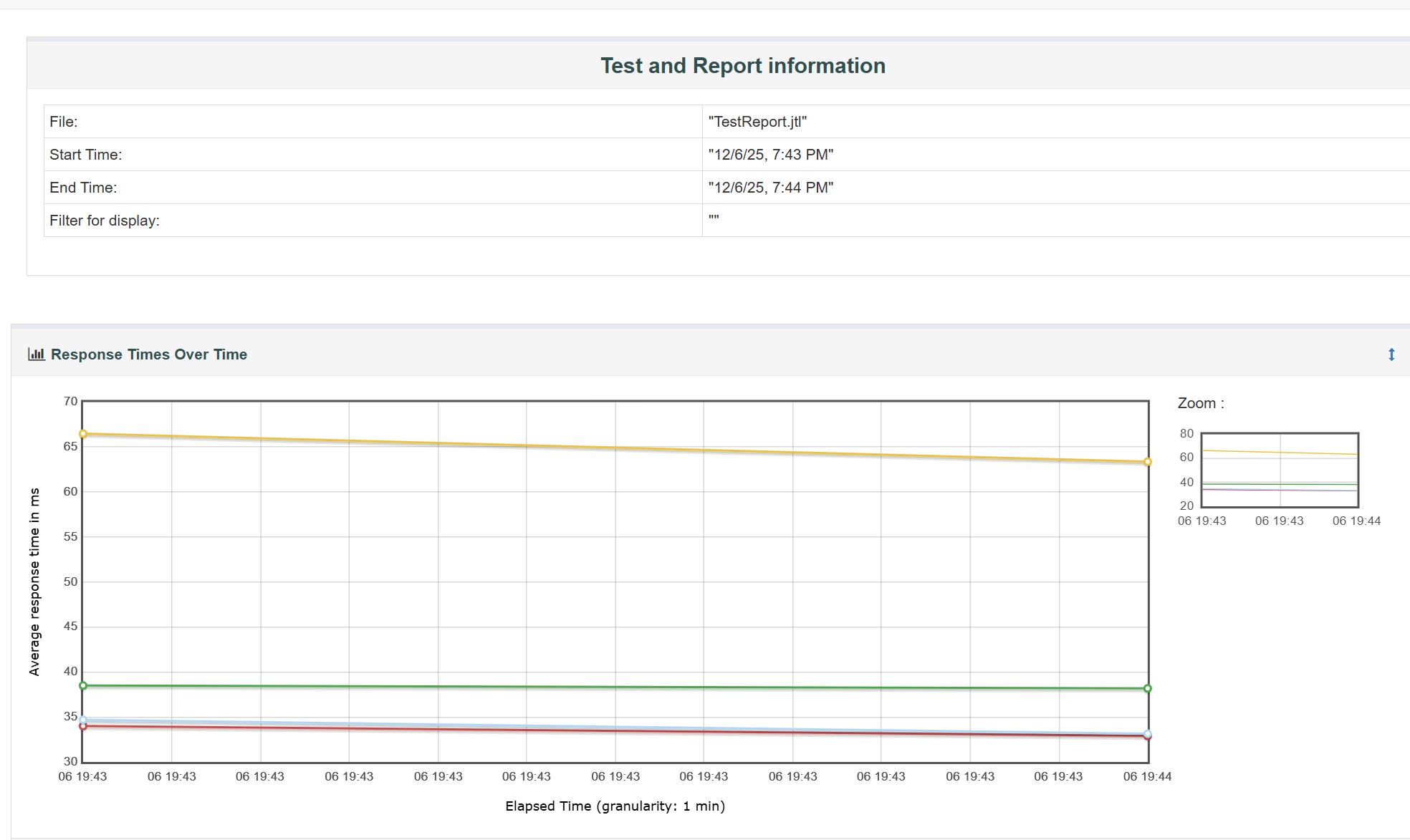
吞吐量:
7. 自动化测试源码及性能测试链接
链接:https://gitee.com/xijiang-64976/python_-selenium_-test