cudnn还是不熟
改起来没那么顺手,不急,慢慢来,时间久了,就熟练了!
现在的cudnn,训练起来,总是差10分!说明自己写的cpu版本的程序还是很自信的!
cifar100不好训练,听说很难,试了试,确实!我在我那个71分的vgg上训练cifar100,得分train/test=30/25,改成cudnn最好15分的样子!
得分不重要,这里相互验证,说明cifar100程序cudnn改成功了!所以记录一下,得分低,说明以后还有余地!
先看两次训练结果:
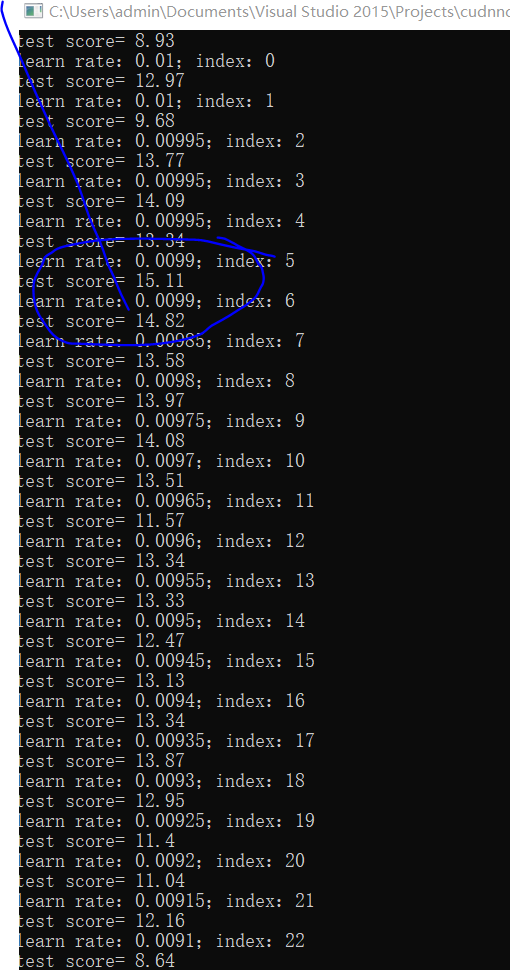
线性层多了一层,有效果:
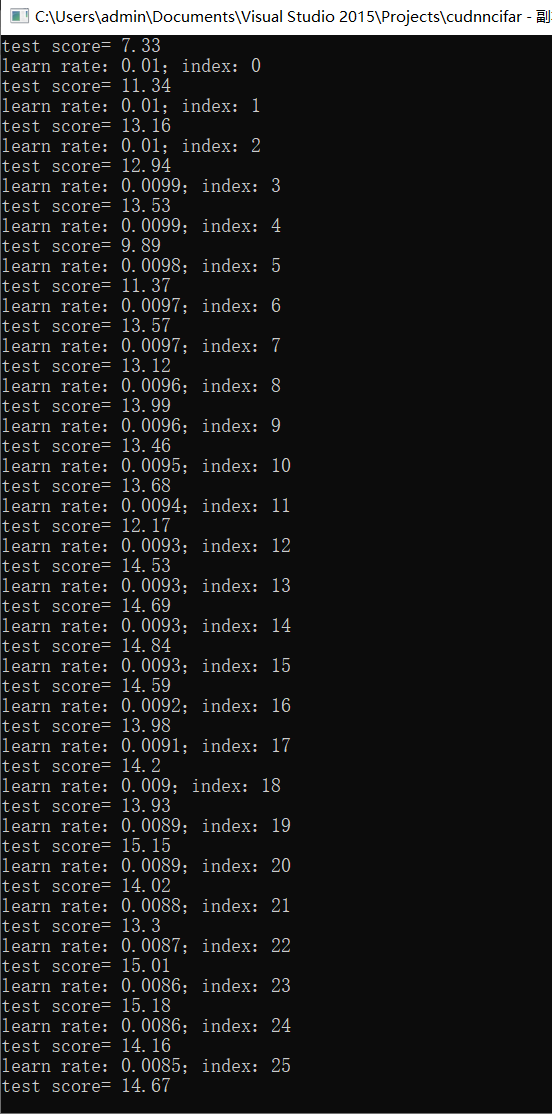
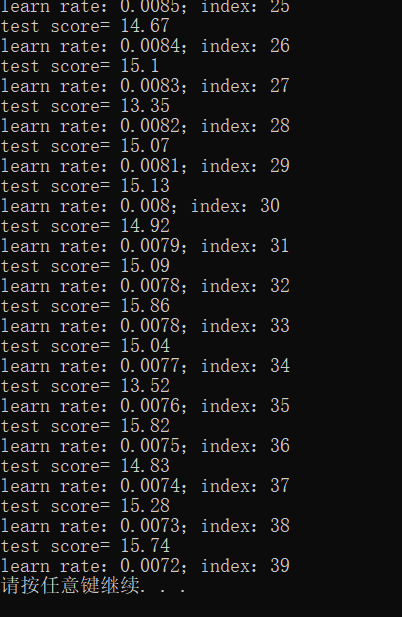
最好15.86分!可以训练,说明程序ok!
cifar10改cifar100,改动如下:(这个cifar10程序,上了62分,我们前面也记录了!)
1,改动,标签和图像的加载
2,改10类为100类,这个也有难度,就像当初把单一图像改成3通道rgb图像输入lenet网络,费了不少功夫和周折!
好,先看cifar100加载:还是整理了两个类,一个训练,一个测试:
struct cifar10Samlpe
{
cifar10Samlpe(const std::vector<float>& image_, const unsigned char &label_) :image(image_), label(label_) {}
std::vector<float> image;//32*32
unsigned char label;
};
class cifar100Dataset//checked 2.0
{
public:
cifar100Dataset(const std::string &image_file, const std::string &label_file) {
load_images(image_file);
//load_labels(label_file);
if (images.size() != labels.size()) {
throw std::runtime_error("Number of images and labels mismatch");
}
indices.resize(images.size());
for (size_t i = 0; i<indices.size(); i++)
indicesi = i;
}
std::vector<cifar10Samlpe> next_batch(size_t batch_size) {
std::vector<cifar10Samlpe> batch;
batch.reserve(batch_size);
for (size_t i = 0; i<batch_size; i++) {
if (current_idx >= indices.size()) current_idx = 0;
size_t idx = indicescurrent_idx++;
batch.emplace_back(cifar10Samlpe{ imagesidx, labelsidx });
}
return batch;
}
size_t size() const { return images.size(); }
private:
std::vector<std::vector<float>> images;
std::vector<unsigned char> labels;
std::vector<size_t> indices;
size_t current_idx = 0;
void load_images(const std::string &path) {
FILE* mnist_file = NULL;
int num = 50000; int rows = 32; int cols = 32;
images.resize(num, std::vector<float>(rows*cols * 3));
labels.resize(num);
unsigned char label; unsigned char label2;
unsigned char image_buffer32 \* 32; //保存图片信息
int err = fopen_s(&mnist_file, "c:\\traincifar100.bin", "rb");
if (mnist_file == NULL)
{
// cout << "load data from your file err..." << endl;
return;
}
else
{
//cout << "loading data...in func --\>\> load_mnist_data" << endl;
}
for (int i = 0; i < num; i++)//5万张
{
fread((char*)&label, sizeof(label), 1, mnist_file);//第一字节20个超类,不用
fread((char*)&label2, sizeof(label2), 1, mnist_file);//使用第二字节100个细类,
labelsi = label2;
fread(image_buffer, 1, 32 * 32, mnist_file);
for (int j = 0; j <32; j++)
{
for (int k = 0; k < 32; k++)
{
int shuffle_index = (j + 0) * 32 + k + 0;
imagesishuffle_index = image_buffershuffle_index / 255.0f;//b
}
}
//g
fread(image_buffer, 1, 32 * 32, mnist_file);
for (int j = 0; j <32; j++)
{
for (int k = 0; k < 32; k++)
{
int shuffle_index = (j + 0) * 32 + k + 0;
imagesishuffle_index + 32 \* 32 = image_buffershuffle_index / 255.0f;//
}
}
//r
fread(image_buffer, 1, 32 * 32, mnist_file);
for (int j = 0; j <32; j++)
{
for (int k = 0; k < 32; k++)
{
int shuffle_index = (j + 0) * 32 + k + 0;
imagesishuffle_index + 32 \* 32 \* 2 = image_buffershuffle_index / 255.0f;//
}
}
}
fclose(mnist_file);
mnist_file = NULL;
}
};
class cifar100DatasetTEST{
public:
cifar100DatasetTEST(const std::string &image_file, const std::string &label_file) {
load_images(image_file);
//load_labels(label_file);
if (images.size() != labels.size()) {
throw std::runtime_error("Number of images and labels mismatch");
}
indices.resize(images.size());
for (size_t i = 0; i<indices.size(); i++)
indicesi = i;
}
std::vector<cifar10Samlpe> next_batch(size_t batch_size) {
std::vector<cifar10Samlpe> batch;
batch.reserve(batch_size);
for (size_t i = 0; i<batch_size; i++) {
if (current_idx >= indices.size()) current_idx = 0;
size_t idx = indicescurrent_idx++;
batch.emplace_back(cifar10Samlpe{ imagesidx, labelsidx });
}
return batch;
}
size_t size() const { return images.size(); }
private:
std::vector<std::vector<float>> images;
std::vector<unsigned char> labels;
std::vector<size_t> indices;
size_t current_idx = 0;
void load_images(const std::string &path) {
FILE* mnist_file = NULL;
int num = 10000; int rows = 32; int cols = 32;
images.resize(num, std::vector<float>(rows*cols * 3));
labels.resize(num);
unsigned char label; unsigned char label2;
unsigned char image_buffer32 \* 32; //保存图片信息
int err = fopen_s(&mnist_file, "c:\\testcifar100.bin", "rb");
if (mnist_file == NULL)
{
// cout << "load data from your file err..." << endl;
return;
}
else
{
//cout << "loading data...in func --\>\> load_mnist_data" << endl;
}
for (int i = 0; i < 10000; i++)
{
fread((char*)&label, sizeof(label), 1, mnist_file);
fread((char*)&label2, sizeof(label2), 1, mnist_file);
labelsi = label2;
fread(image_buffer, 1, 32 * 32, mnist_file);
for (int j = 0; j <32; j++)
{
for (int k = 0; k < 32; k++)
{
int shuffle_index = (j + 0) * 32 + k + 0;
imagesishuffle_index = image_buffershuffle_index / 255.0f;//b
}
}
//g
fread(image_buffer, 1, 32 * 32, mnist_file);
for (int j = 0; j <32; j++)
{
for (int k = 0; k < 32; k++)
{
int shuffle_index = (j + 0) * 32 + k + 0;
imagesishuffle_index + 32 \* 32 = image_buffershuffle_index / 255.0f;//b
}
}
//r
fread(image_buffer, 1, 32 * 32, mnist_file);
for (int j = 0; j <32; j++)
{
for (int k = 0; k < 32; k++)
{
int shuffle_index = (j + 0) * 32 + k + 0;
imagesishuffle_index + 32 \* 32 \* 2 = image_buffershuffle_index / 255.0f;//b
}
}
}
fclose(mnist_file);
mnist_file = NULL;
}
};
要注意的,已经标红!其他和cifar10加载一样!
下来就是要在cifar10程序上10类改100:
先看架构中改100的地方:a:
LeNet(cublasHandle_t &cublas_, cudnnHandle_t &cudnn_, int batch_) :cublas(cublas_), cudnn(cudnn_), batch(batch_) {
layers.emplace_back(std::make_shared<Conv2D>(cudnn, batch, 3, 12, 32, 32, 5));//输入->>>c1,5*5,1*28*28-》6*24*24
layers.emplace_back(std::make_shared<ReLU>(cudnn, batch, 12, 28, 28)); //输入->>>c1,5*5,1*28*28-》6*24*24
//layers.emplace_back(std::make_shared<Conv2D>(cudnn, batch, 12, 12, 30, 30, 3));//输入->>>c1,5*5,1*28*28-》6*24*24
//layers.emplace_back(std::make_shared<ReLU>(cudnn, batch, 12, 28, 28)); //输入->>>c1,5*5,1*28*28-》6*24*24
layers.emplace_back(std::make_shared<MaxPool2D>(cudnn, batch, 12, 28, 28, 2, 2, 0, 2)); //s2,6*24*24->>6*12*12
layers.emplace_back(std::make_shared<Conv2D>(cudnn, batch, 12, 16, 14, 14, 5));//c3,6*12*12->>16*8*8
layers.emplace_back(std::make_shared<ReLU>(cudnn, batch, 16, 10, 10)); //c3,6*12*12->>16*8*8
layers.emplace_back(std::make_shared<MaxPool2D>(cudnn, batch, 16, 10, 10, 2, 2, 0, 2)); //s4,16*8*8->>16*4*4
layers.emplace_back(std::make_shared<Linear>(cublas, batch, 16 * 5 * 5, 120));//c5,16*4*4->>>120
layers.emplace_back(std::make_shared<ReLU>(cudnn, batch, 120, 1, 1)); //c5,16*4*4->>>120
layers.emplace_back(std::make_shared<Linear>(cublas, batch, 120, 100));//120->84
layers.emplace_back(std::make_shared<ReLU>(cudnn, batch, 100, 1, 1)); //120->84
layers.emplace_back(std::make_shared<Linear>(cublas, batch,100, 100));//84->10
cudaMalloc(&output, batch * 100 * sizeof(float));
cudaMalloc(&grad_input, batch * 3 * 32*32 * sizeof(float));
}
先看架构中改100的地方:b :
void forward(float *input_)override {
input = input_;
for (const auto &l : layers) {
l->forward(input);
input = l->get_output();
}
cudaMemcpy(output, input, sizeof(float)*batch * 100, cudaMemcpyDeviceToDevice);
}
再看训练函数以及测试函数中:
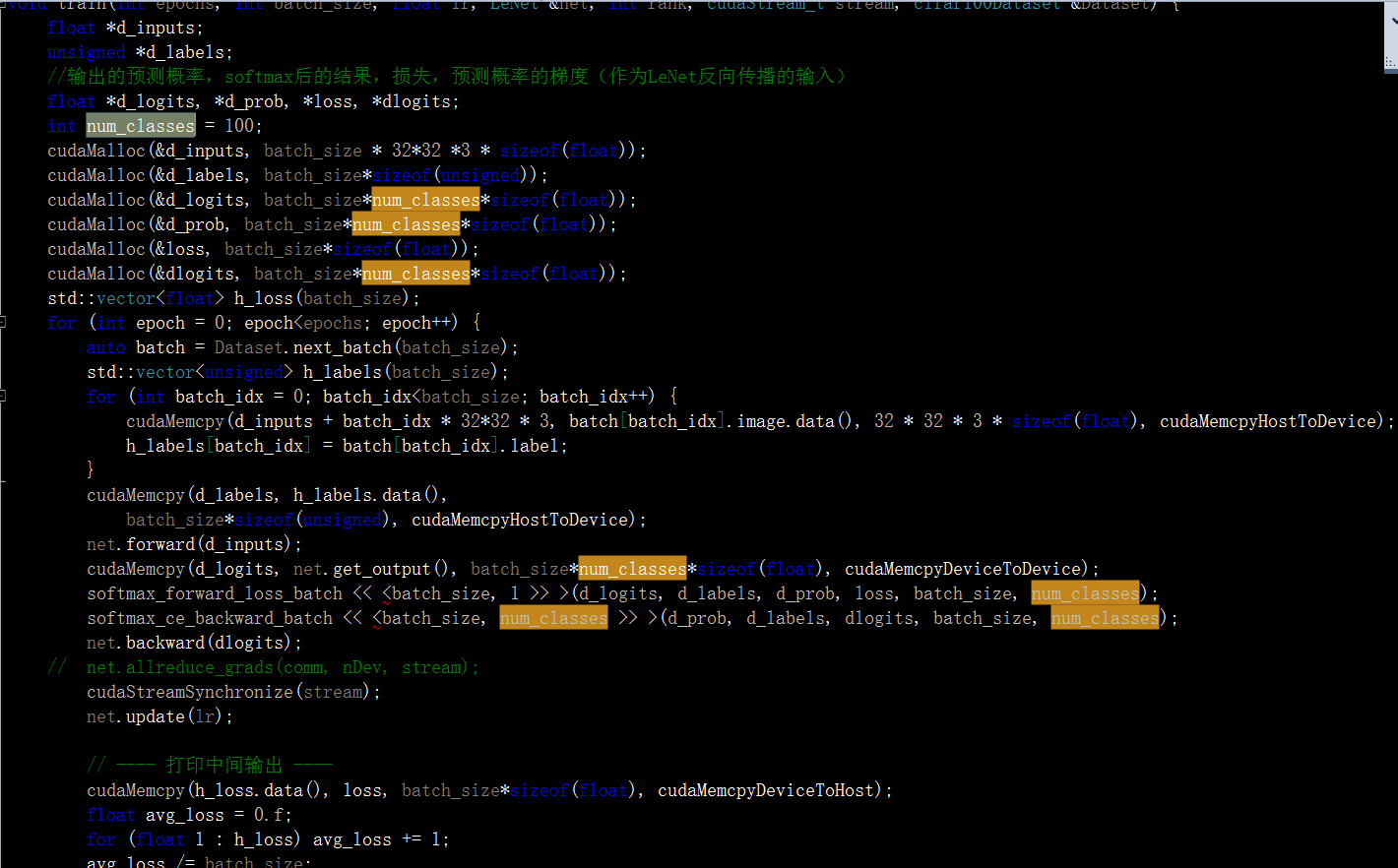
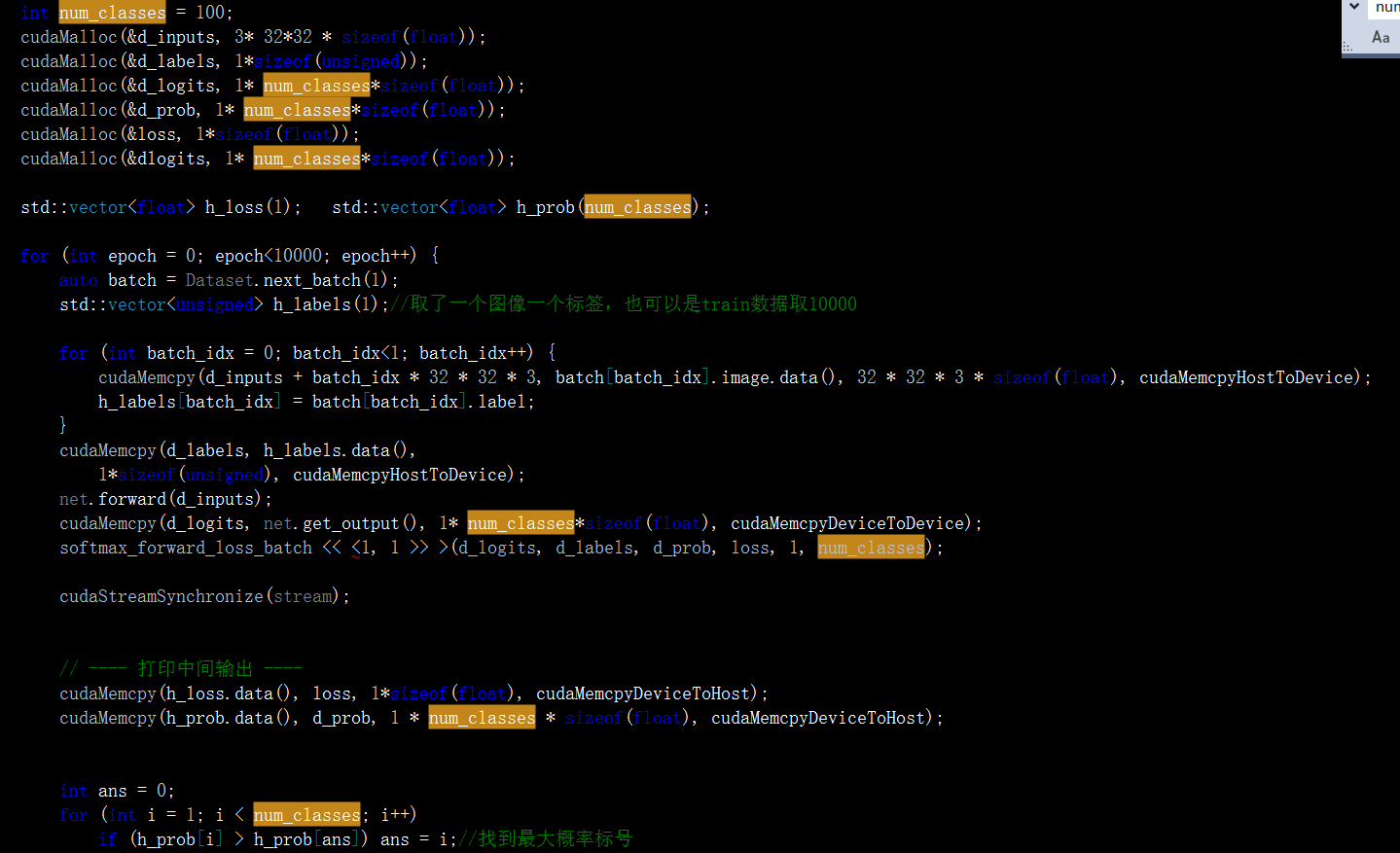
另外softmax计算中也要注意:
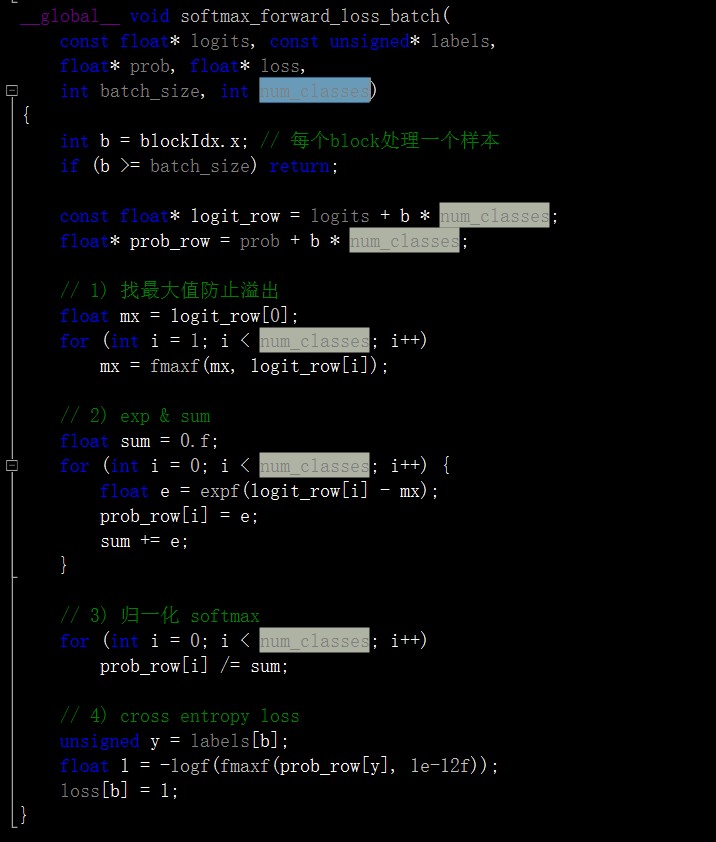
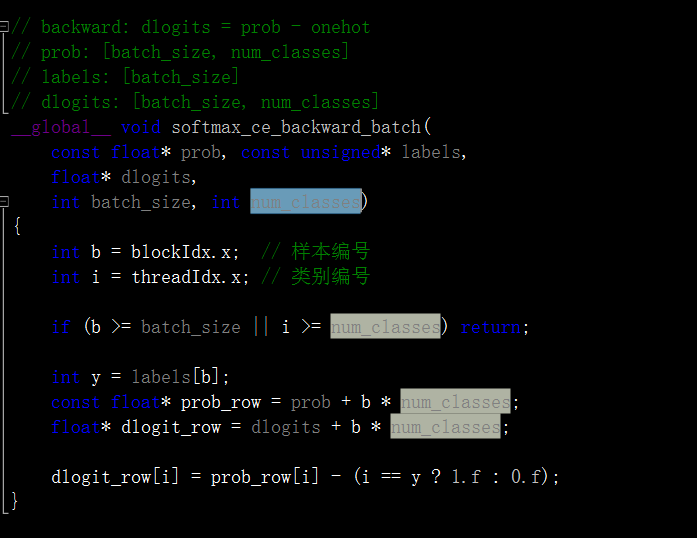
不少地方啊!很容易遗漏!我是对着cpu版本改动的,还好,通过编译,运行正常,虽然得分不高!但这已经是巨大进步了!
我们三个cudnn程序,循序渐进,只针对性的改动,很容易成功!