🤖 AI时代的数字生存战:爬虫与反爬虫的数据争夺全面解析
🚀 引言:AI时代的数据饥渴症
在ChatGPT引爆全球AI热潮的今天,大多数人的目光都聚焦在如何使用AI工具上。然而,一个更为根本的问题往往被忽视:AI的"粮食"从哪里来?
数据,这个看似普通的词汇,在AI时代正成为比石油更宝贵的战略资源。正如人类生存离不开食物,AI系统的成长离不开高质量的数据供给。当我们沉浸在AI带来的便利时,一场没有硝烟的战争正在数据领域激烈上演------爬虫与反爬虫的数字生存战。
核心洞察:AI技术的进步与数据资源的争夺正形成一种"水涨船高"的恶性循环,数据需求越大,数据争夺战越激烈。
📊 数据经济学:AI时代的"粮食危机"
数据的本质:从信息到战略资产
数据在AI时代的价值转变可以用一个简单的公式表示:
python
# 传统时代的数据价值
traditional_data_value = "信息记录" + "业务支撑"
# AI时代的数据价值
ai_era_data_value = traditional_data_value * 100 + "模型训练燃料" + "竞争优势壁垒"
print(f"数据价值增长倍数: {ai_era_data_value / traditional_data_value:.0f}倍")这种价值重估导致了数据地位的彻底改变。数据不再仅仅是企业运营的副产品,而成为了核心战略资产。
数据分类学:静态与动态的辩证关系
理解数据的时效性对于制定有效的爬虫策略至关重要。数据可以分为两大类别:
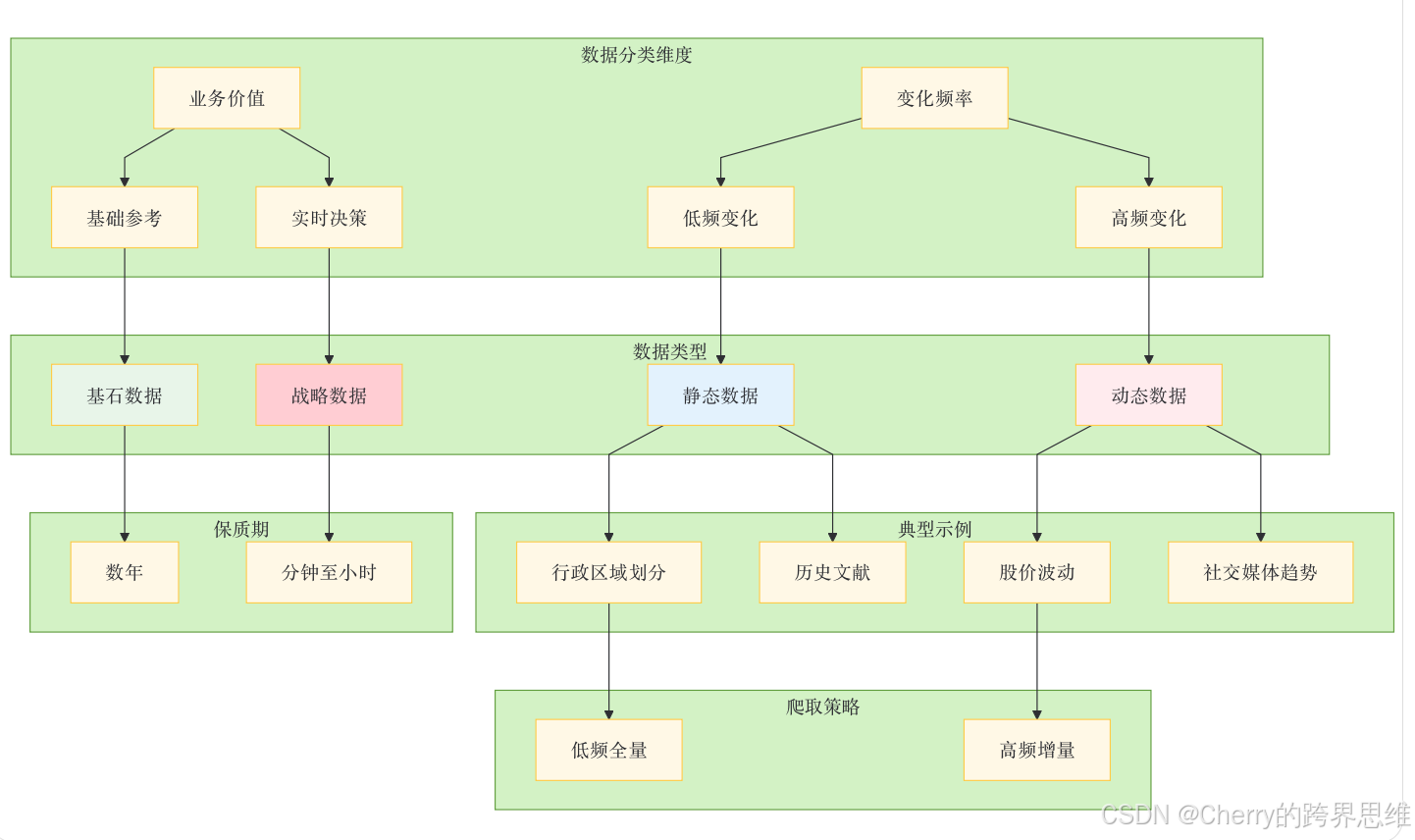
关键洞察:数据的"静态"与"动态"属性并非绝对,而是相对于业务需求的变化频率而言。一个在电商领域每分钟变化的价格数据是动态数据,但同样的变化频率在地质勘探领域可能被视为静态数据。
数据保质期:时效性与价值的非线性衰减
python
import math
import datetime
class DataFreshnessAnalyzer:
"""数据分析器:评估数据时效性与价值关系"""
def __init__(self, data_type):
self.data_type = data_type
self.base_value = 100 # 初始价值100分
def calculate_current_value(self, age_hours, half_life_hours=24):
"""
计算数据当前价值
age_hours: 数据年龄(小时)
half_life_hours: 半衰期,价值减半所需时间
"""
decay_factor = 0.5 ** (age_hours / half_life_hours)
# 不同类型数据衰减曲线不同
if self.data_type == "static":
# 静态数据衰减缓慢
effective_decay = decay_factor ** 0.3
elif self.data_type == "dynamic":
# 动态数据衰减迅速
effective_decay = decay_factor ** 2
else:
effective_decay = decay_factor
current_value = self.base_value * effective_decay
return max(0, current_value) # 价值不为负
def generate_freshness_report(self, data_points):
"""生成数据新鲜度报告"""
report = {
"data_type": self.data_type,
"analysis_time": datetime.datetime.now(),
"points": []
}
for point in data_points:
age = point["age_hours"]
value = self.calculate_current_value(age)
report["points"].append({
"data_id": point["id"],
"age_hours": age,
"current_value": round(value, 2),
"freshness_level": self.get_freshness_level(value)
})
return report
def get_freshness_level(self, value):
"""根据价值评估新鲜度等级"""
if value >= 80:
return "极新鲜"
elif value >= 60:
return "较新鲜"
elif value >= 40:
return "一般"
elif value >= 20:
return "即将过期"
else:
return "已过期"
# 使用示例
analyzer = DataFreshnessAnalyzer(data_type="dynamic")
sample_data = [
{"id": "price_001", "age_hours": 0.5}, # 30分钟前
{"id": "price_002", "age_hours": 2}, # 2小时前
{"id": "price_003", "age_hours": 24}, # 1天前
{"id": "price_004", "age_hours": 168}, # 1周前
]
report = analyzer.generate_freshness_report(sample_data)
print("数据新鲜度分析报告:")
for point in report["points"]:
print(f" 数据{point['data_id']}: 年龄{point['age_hours']}小时, "
f"价值{point['current_value']}分, 状态: {point['freshness_level']}")🔄 数据供应链:生产者、消费者与窃取者的三角关系
数据生产者:谁在创造数字世界的"石油"?
一个常见的误解是只有互联网公司才生产数据。实际上,数据生产的全民化正在发生:
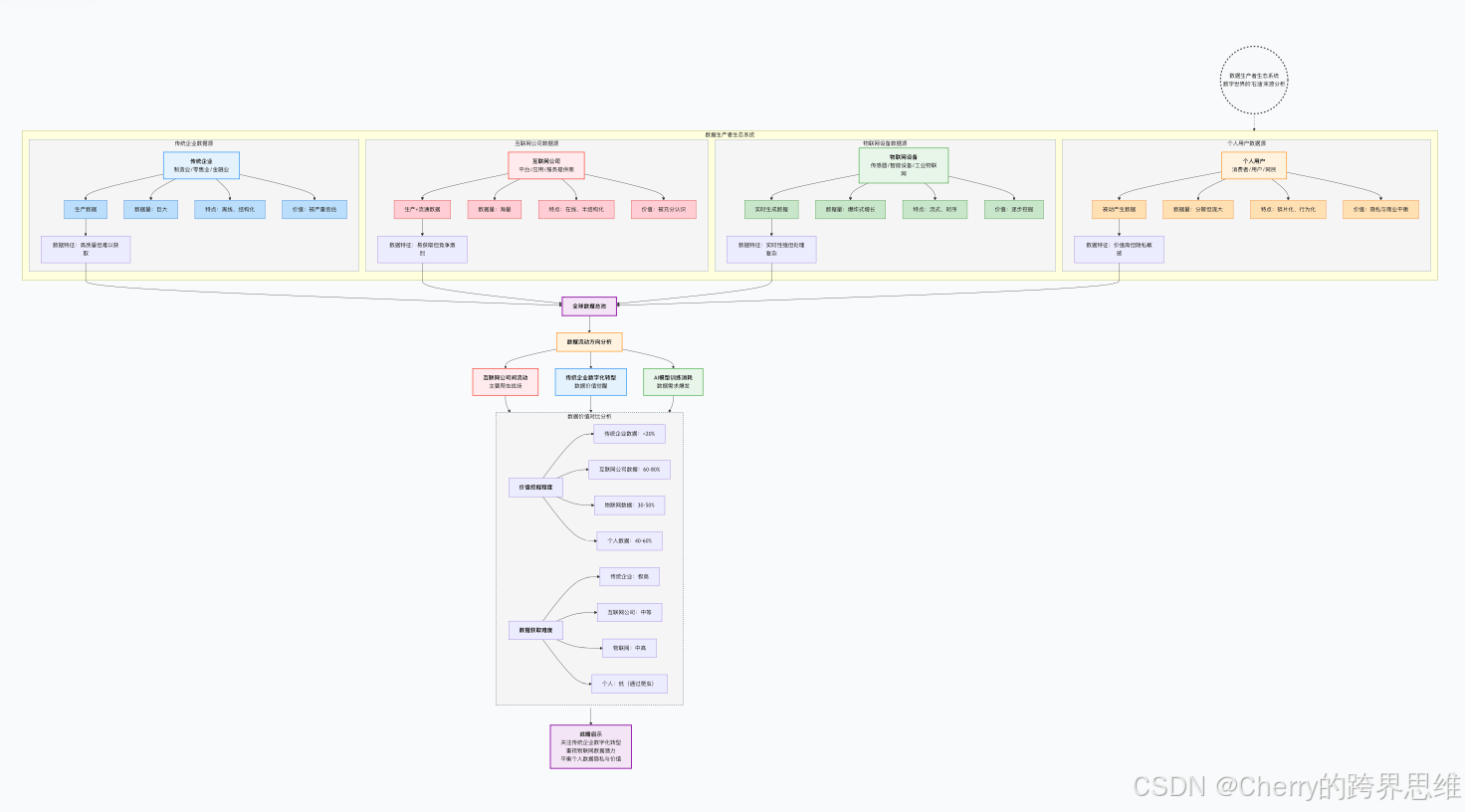
重要发现:传统企业实际上拥有比互联网公司更庞大、更高质量的数据资源,但这些数据大多处于"休眠"状态。数据爬取竞赛主要集中在互联网公司之间,形成了典型的"灯下黑"现象。
数据消费者:贪婪的胃口与挑剔的味觉
数据消费领域存在一个有趣的心理现象:"书非借不能读也"的数据版本。
python
class DataConsumerPsychology:
"""模拟数据消费者的心理模型"""
def __init__(self, company_type):
self.company_type = company_type
self.owned_data = [] # 自有数据
self.acquired_data = [] # 获取的外部数据
self.analysis_effort = 0 # 分析投入
def analyze_data(self, data_source, data_value):
"""分析数据的投入程度"""
if data_source == "owned":
# 对自有数据分析投入较低
effort = data_value * 0.3 # 只投入30%的努力
print(f"分析自有数据,投入努力值: {effort:.1f}")
else: # acquired
# 对外部数据分析投入较高
effort = data_value * 0.8 # 投入80%的努力
print(f"分析外部数据,投入努力值: {effort:.1f}")
self.analysis_effort += effort
return effort
def data_satisfaction(self, actual_data, desired_data):
"""数据满意度计算 - 永远不满足的怪圈"""
# 基本满意度
base_satisfaction = actual_data / desired_data if desired_data > 0 else 0
# 人类心理修正因子:总是觉得不够
human_factor = 0.7 # 70%的满足感阈值
# 时间衰减:随着时间推移,对现有数据越来越不满足
time_factor = 0.95 # 每月满意度衰减5%
effective_satisfaction = base_satisfaction * human_factor * time_factor
# 结果总是小于1,意味着永远不够用
return min(0.99, effective_satisfaction) # 最大99%,永不100%满足
def should_crawl_competitor(self, own_data_quality, competitor_data_quality):
"""决定是否爬取竞对数据的决策模型"""
# 计算相对优势
relative_advantage = competitor_data_quality - own_data_quality
# 决策因素
factors = {
"technical_feasibility": 0.8, # 技术可行性
"legal_risk": -0.6, # 法律风险
"perceived_value": 1.2, # 感知价值(外部数据总是看起来更香)
"management_pressure": 0.9, # 管理层压力
"resource_cost": -0.7, # 资源成本
}
# 加权决策分数
decision_score = relative_advantage
for factor, weight in factors.items():
decision_score += weight
return decision_score > 0 # 分数大于0则决定爬取
# 模拟企业数据消费心理
mature_company = DataConsumerPsychology(company_type="成熟企业")
startup = DataConsumerPsychology(company_type="创业公司")
print("=== 数据消费心理模拟 ===")
print(f"成熟公司分析外部数据努力值: "
f"{mature_company.analyze_data('acquired', 100):.1f}")
print(f"成熟公司分析自有数据努力值: "
f"{mature_company.analyze_data('owned', 100):.1f}")
print(f"\n满意度模拟(拥有80,期望100): "
f"{mature_company.data_satisfaction(80, 100):.2%}")
print(f"满意度模拟(拥有100,期望80): "
f"{mature_company.data_satisfaction(100, 80):.2%}") # 仍然不会100%满意
print(f"\n是否爬取竞对决策(自有质量70,竞对质量80): "
f"{mature_company.should_crawl_competitor(70, 80)}")⚔️ 爬虫与反爬虫的军备竞赛
创业公司vs成熟企业:不对称的数据战争
爬虫战场上的参与者呈现出鲜明的两极分化特征:
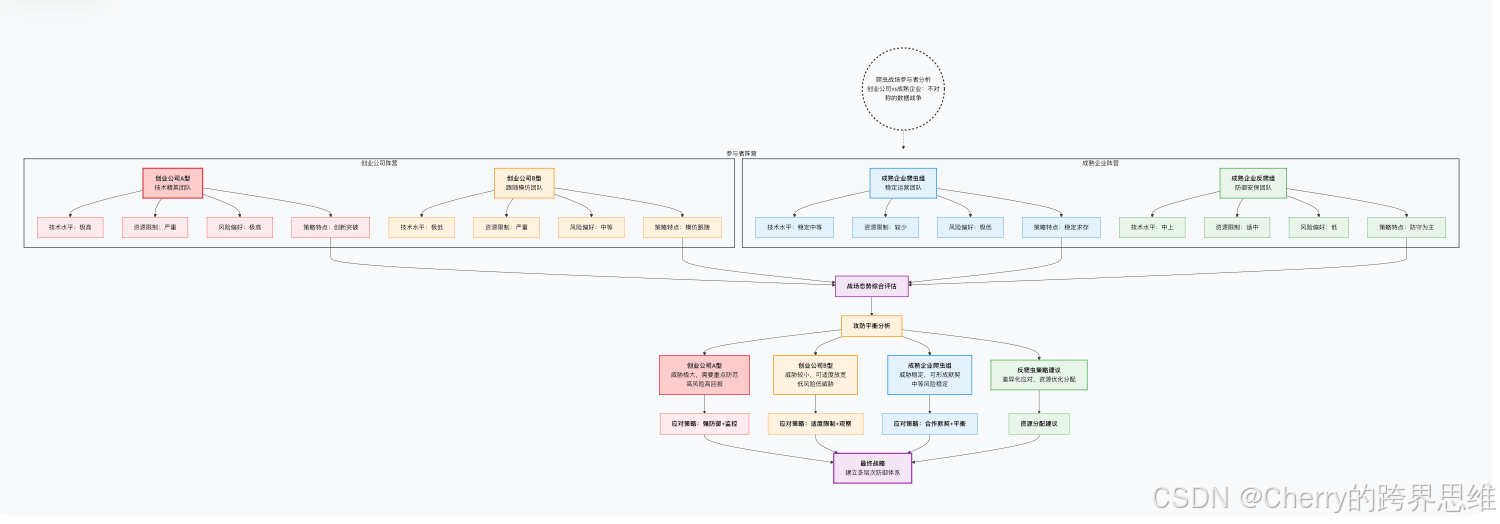
成本收益分析:为什么数据窃取难以根除?
python
class CrawlerEconomics:
"""爬虫行为的经济学分析模型"""
def __init__(self, company_type):
self.company_type = company_type
self.costs = {}
self.benefits = {}
def calculate_crawl_costs(self, scale, complexity):
"""计算爬虫成本"""
# 硬件成本
hardware_cost = scale * 100 # 每单位规模100元
# IP资源成本
ip_cost = scale * 50 # IP代理费用
# 研发人力成本
dev_cost = complexity * 2000 # 复杂度系数
# 法律风险成本(隐性但重要)
legal_risk_cost = scale * 30 # 法律风险准备金
total_cost = hardware_cost + ip_cost + dev_cost + legal_risk_cost
self.costs = {
"hardware": hardware_cost,
"ip_resources": ip_cost,
"development": dev_cost,
"legal_risk": legal_risk_cost,
"total": total_cost
}
return self.costs
def calculate_benefits(self, data_quality, data_freshness, business_impact):
"""计算爬虫收益"""
# 数据直接价值
direct_value = data_quality * 300
# 时间价值(新鲜度溢价)
freshness_premium = data_freshness * 100
# 业务影响价值
business_value = business_impact * 500
# 竞争情报价值
competitive_intel_value = 200 # 固定基础价值
total_benefit = (direct_value + freshness_premium +
business_value + competitive_intel_value)
self.benefits = {
"direct_data_value": direct_value,
"freshness_premium": freshness_premium,
"business_impact": business_value,
"competitive_intelligence": competitive_intel_value,
"total": total_benefit
}
return self.benefits
def roi_analysis(self, scale=10, complexity=5,
data_quality=8, freshness=7, business_impact=6):
"""投资回报率分析"""
costs = self.calculate_crawl_costs(scale, complexity)
benefits = self.calculate_benefits(data_quality, freshness, business_impact)
roi = (benefits["total"] - costs["total"]) / costs["total"] * 100
analysis_report = {
"company_type": self.company_type,
"total_costs": costs["total"],
"total_benefits": benefits["total"],
"roi_percentage": roi,
"breakdown": {
"costs": costs,
"benefits": benefits
},
"recommendation": "建议执行" if roi > 30 else "建议放弃"
}
return analysis_report
def comparative_analysis(self, scenarios):
"""多场景对比分析"""
results = {}
for scenario_name, params in scenarios.items():
analysis = self.roi_analysis(**params)
results[scenario_name] = analysis
return results
# 经济学分析示例
startup_econ = CrawlerEconomics(company_type="创业公司")
mature_econ = CrawlerEconomics(company_type="成熟企业")
# 不同场景配置
scenarios = {
"创业公司_激进爬取": {
"scale": 20, # 大规模
"complexity": 8, # 高复杂度
"data_quality": 9, # 高质量数据
"freshness": 9, # 高新鲜度
"business_impact": 8 # 高业务影响
},
"成熟企业_保守爬取": {
"scale": 5, # 小规模
"complexity": 3, # 低复杂度
"data_quality": 7, # 中等质量
"freshness": 6, # 中等新鲜度
"business_impact": 5 # 中等业务影响
}
}
print("=== 爬虫经济学分析 ===")
for scenario, params in scenarios.items():
econ = startup_econ if "创业公司" in scenario else mature_econ
result = econ.roi_analysis(**params)
print(f"\n{scenario}:")
print(f" 总成本: ¥{result['total_costs']:,.0f}")
print(f" 总收益: ¥{result['total_benefits']:,.0f}")
print(f" ROI: {result['roi_percentage']:.1f}%")
print(f" 建议: {result['recommendation']}")🤖 AI在数据战争中的双重角色
AI作为攻击者:为什么ChatGPT不是好的爬虫助手?
一个常见的误解是AI可以成为爬虫的利器。但现实恰恰相反:
python
class AICrawlerAssistant:
"""模拟AI爬虫助手的能力限制"""
def __init__(self, ai_model="ChatGPT"):
self.model = ai_model
self.ethical_constraints = True # 道德约束
self.technical_capabilities = {
"understand_encryption": 0.3, # 理解加密能力 30%
"bypass_authentication": 0.1, # 绕过认证能力 10%
"analyze_javascript": 0.4, # 分析JS能力 40%
"mimic_human_behavior": 0.6, # 模拟人类行为 60%
"legal_advice": 0.9 # 法律建议能力 90%
}
def assist_crawling(self, task_description):
"""AI协助爬虫任务"""
# AI的道德审查
if self.ethical_constraints:
unethical_keywords = ["破解", "绕过", "窃取", "非法", "攻击"]
for keyword in unethical_keywords:
if keyword in task_description:
return self.generate_ethical_refusal()
# 技术能力评估
task_complexity = self.assess_task_complexity(task_description)
ai_capability = self.estimate_capability(task_complexity)
if ai_capability < 0.5: # 能力不足50%
return self.generate_technical_limitation_response()
else:
return self.generate_assistance_response(task_complexity)
def assess_task_complexity(self, task):
"""评估任务复杂度"""
complexity_score = 0
indicators = {
"反爬虫机制": 0.8,
"动态加载": 0.7,
"验证码": 0.9,
"频率限制": 0.6,
"API调用": 0.4,
"静态页面": 0.2
}
for indicator, weight in indicators.items():
if indicator in task:
complexity_score += weight
return min(1.0, complexity_score)
def estimate_capability(self, complexity):
"""估计AI完成能力"""
# 能力与复杂度成反比
base_capability = 0.7
degradation = complexity * 0.5 # 复杂度每增加,能力下降
effective_capability = base_capability - degradation
return max(0, effective_capability)
def generate_ethical_refusal(self):
"""生成道德拒绝回复"""
responses = [
"抱歉,作为AI助手,我不能协助任何可能违法的活动。",
"这涉及到潜在的法律和道德问题,我无法提供帮助。",
"我建议您通过合法途径获取数据,尊重网站的条款和服务。"
]
return responses[0] # 总是选择最安全的回复
def generate_technical_limitation_response(self):
"""生成技术限制回复"""
return "这个任务超出了我当前的技术能力范围。"
def generate_assistance_response(self, complexity):
"""生成协助回复"""
if complexity < 0.3:
return "我可以帮助您分析网页结构,但具体实现需要您自己完成。"
else:
return "这个任务较为复杂,建议您咨询专业的技术团队。"
# 测试AI爬虫助手
assistant = AICrawlerAssistant()
test_tasks = [
"帮我写一个爬虫绕过这个网站的登录验证",
"如何破解这个网站的反爬虫机制",
"我需要爬取一些公开的天气数据",
"这个动态加载的网站怎么爬取"
]
print("=== AI爬虫助手测试 ===")
for task in test_tasks:
response = assistant.assist_crawling(task)
print(f"任务: {task[:30]}...")
print(f"回复: {response}\n")AI作为防御者:ChatGPT如何增强反爬能力
与攻击角色相反,AI在防御端表现出色:
AI增强型反爬虫工作流
AI协同分析
低风险
中风险
高风险
AI分析模块
流量监控系统
实时收集访问数据
异常检测引擎
ChatGPT辅助分析
模式识别
异常解释
策略建议
机器学习模型
行为聚类
风险评分
趋势预测
决策引擎
响应策略选择
观察模式
记录不干预
轻度限制
增加验证步骤
主动防御
阻断并收集证据
学习反馈环
模型优化
python
class AIEnhancedAntiCrawler:
"""AI增强的反爬虫系统"""
def __init__(self):
self.ml_model = self.load_ml_model()
self.llm_assistant = LLMAssistant() # 大语言模型助手
self.decision_history = []
def load_ml_model(self):
"""加载机器学习模型(简化示例)"""
# 实际中这里会加载训练好的模型
return {
"predict_risk": self.predict_risk_score,
"cluster_behaviors": self.cluster_similar_behaviors,
"detect_anomalies": self.detect_statistical_anomalies
}
def analyze_traffic_pattern(self, traffic_data):
"""分析流量模式 - 人机协同"""
# 机器学习分析
ml_results = {
"risk_score": self.ml_model["predict_risk"](traffic_data),
"behavior_clusters": self.ml_model["cluster_behaviors"](traffic_data),
"anomalies": self.ml_model["detect_anomalies"](traffic_data)
}
# AI语言模型分析
llm_prompt = f"""
分析以下网络流量模式,识别可能的爬虫行为:
数据特征:
- 请求频率: {traffic_data['request_rate']} 请求/秒
- 用户代理一致性: {traffic_data['ua_consistency']}
- 页面访问深度: {traffic_data['page_depth']}
- 会话持续时间: {traffic_data['session_duration']}
机器学习分析结果:
- 风险评分: {ml_results['risk_score']}/100
- 检测到的异常: {len(ml_results['anomalies'])} 个
请分析:
1. 这些特征是否表明爬虫行为?
2. 如果是,可能是哪种类型的爬虫?
3. 建议的应对策略是什么?
"""
llm_analysis = self.llm_assistant.analyze(llm_prompt)
# 综合决策
final_decision = self.make_decision(ml_results, llm_analysis)
# 记录学习
self.learn_from_decision(traffic_data, final_decision)
return {
"ml_analysis": ml_results,
"llm_analysis": llm_analysis,
"final_decision": final_decision
}
def make_decision(self, ml_results, llm_analysis):
"""基于AI分析做出决策"""
risk_score = ml_results["risk_score"]
if risk_score < 30:
return {
"action": "allow",
"confidence": 0.9,
"reason": "正常用户行为模式"
}
elif risk_score < 70:
return {
"action": "challenge",
"type": "adaptive_captcha", # 自适应验证码
"difficulty": risk_score / 100,
"reason": llm_analysis.get("suspected_crawler_type", "未知类型爬虫")
}
else: # risk_score >= 70
return {
"action": "block",
"duration": "24h", # 阻断24小时
"collect_evidence": True,
"reason": "确认的恶意爬虫行为"
}
def learn_from_decision(self, traffic_data, decision):
"""从决策中学习优化模型"""
self.decision_history.append({
"traffic_data": traffic_data,
"decision": decision,
"timestamp": datetime.now()
})
# 定期重新训练模型
if len(self.decision_history) % 1000 == 0:
self.retrain_models()
def predict_risk_score(self, traffic_data):
"""预测风险评分(简化实现)"""
score = 0
# 请求频率因子
if traffic_data['request_rate'] > 10: # 超过10请求/秒
score += 40
# 用户代理异常因子
if traffic_data['ua_consistency'] > 0.9: # UA高度一致
score += 30
# 行为模式因子
if traffic_data['page_depth'] < 3: # 页面访问深度浅
score += 20
# 时间模式因子
if traffic_data['session_duration'] < 5: # 会话时间短
score += 10
return min(100, score)
# 其他方法省略...
class LLMAssistant:
"""大语言模型助手(模拟)"""
def analyze(self, prompt):
"""分析提示并返回结果"""
# 这里模拟LLM的响应
responses = {
"low_risk": "流量模式显示正常用户行为,建议允许访问。",
"medium_risk": "检测到可能的初级爬虫,建议增加轻度验证。",
"high_risk": "确认高级分布式爬虫,建议立即阻断并收集证据。"
}
# 简单模拟:根据关键词返回响应
if "请求频率" in prompt and "10" in prompt:
return {
"verdict": "high_risk",
"suspected_crawler_type": "分布式爬虫",
"recommendation": "实施阻断并加强监控"
}
return responses.get("medium_risk", "需要进一步分析")⚖️ 新世界的道德与法律框架
技术伦理的演进:从代码到AI的三方关系
随着AI的加入,传统的"技术与人"的二元关系正在演变为"人、技术、AI"的三方互动:
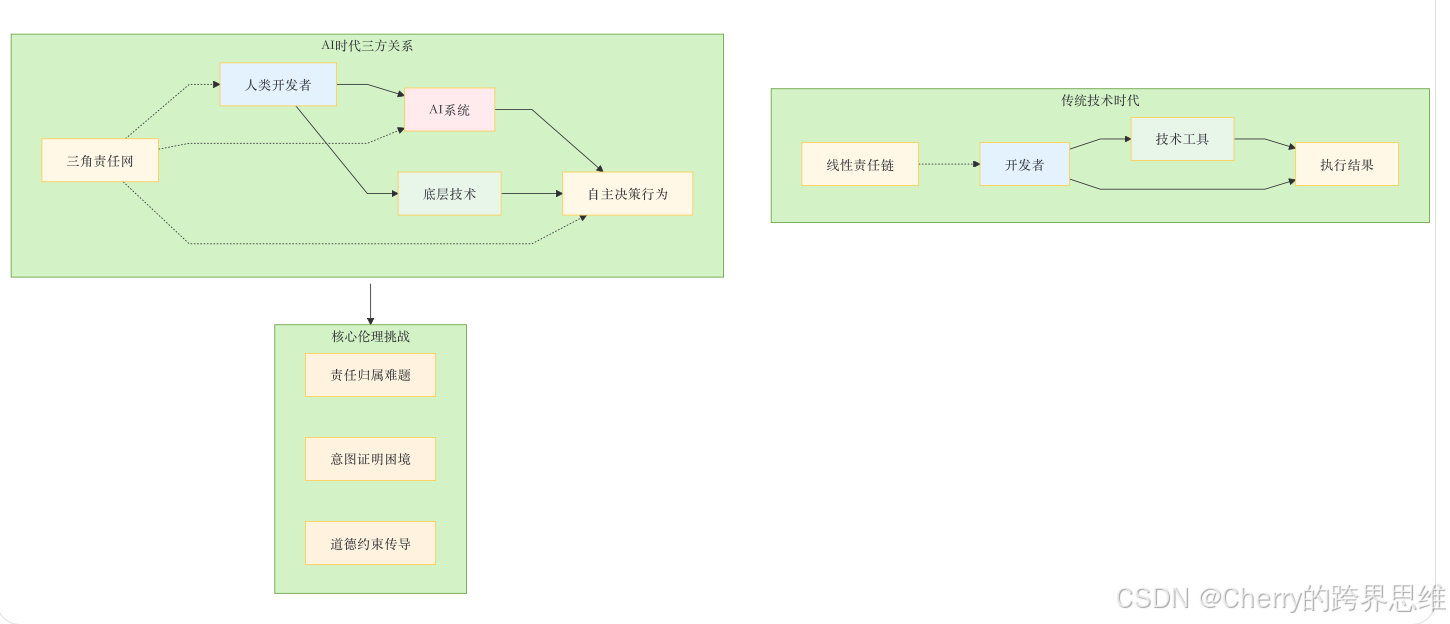
法律挑战:AI爬虫的罪与罚
当AI开始自主参与数据爬取时,法律面临前所未有的挑战:
python
class LegalFrameworkAnalyzer:
"""分析AI爬虫行为的法律框架"""
def __init__(self):
self.current_laws = self.load_current_legislation()
self.ai_specific_challenges = []
def load_current_legislation(self):
"""加载当前相关法律"""
return {
"刑法286条": {
"适用对象": "自然人、法人",
"主观要件": "故意",
"客观要件": "破坏计算机信息系统",
"对AI的适用性": "模糊"
},
"网络安全法": {
"数据获取规定": "合法、正当、必要",
"对爬虫的约束": "有原则性规定",
"对AI的适用性": "未明确"
},
"数据安全法": {
"数据分类分级": "明确",
"跨境数据流动": "严格限制",
"对AI爬虫的适用性": "间接相关"
}
}
def analyze_ai_crawler_case(self, scenario):
"""分析AI爬虫案例的法律问题"""
legal_issues = []
# 责任归属问题
if scenario["ai_autonomy_level"] > 0.7:
legal_issues.append({
"issue": "责任归属模糊",
"description": "AI高度自主决策,难以确定人类责任",
"severity": "高",
"current_law_gap": "刑法286条未涵盖AI主体"
})
# 意图证明问题
if scenario["human_awareness"] < 0.3 and scenario["ai_capability"] > 0.8:
legal_issues.append({
"issue": "间接意图证明困难",
"description": "人类可能通过训练AI实现间接违法目的",
"severity": "中高",
"current_law_gap": "难以证明'故意'要件"
})
# 证据收集问题
if scenario["ai_learning"] and scenario["behavior_evolution"]:
legal_issues.append({
"issue": "动态行为证据固定困难",
"description": "AI不断学习进化,违法证据难以固定",
"severity": "中",
"current_law_gap": "传统证据规则不适应AI特性"
})
return legal_issues
def propose_legal_solutions(self, issues):
"""提出法律解决方案建议"""
solutions = []
for issue in issues:
if issue["issue"] == "责任归属模糊":
solutions.append({
"proposal": "引入AI行为追溯责任制",
"details": "无论AI自主程度多高,最终追溯至人类开发者/使用者",
"implementation": "修改刑法,增加AI工具特别条款"
})
if issue["issue"] == "间接意图证明困难":
solutions.append({
"proposal": "建立AI行为预期评估体系",
"details": "开发者需对AI可能行为进行合理性评估并备案",
"implementation": "行政监管与刑事处罚结合"
})
return solutions
def generate_compliance_framework(self):
"""生成AI时代的合规框架"""
framework = {
"基本原则": [
"人类最终责任原则:AI行为责任最终归于人类",
"透明度要求:AI决策过程需可解释、可审计",
"预期管理:开发者需预见并约束AI可能行为",
"主动合规:建立AI行为监控与干预机制"
],
"技术实施要求": [
"行为日志完整记录AI决策全过程",
"设置人工干预接口和紧急停止机制",
"定期进行AI行为合规性审计",
"建立AI行为异常报警系统"
],
"组织管理要求": [
"设立AI伦理委员会审查高风险应用",
"制定AI开发与使用的内部合规流程",
"开展AI法律风险培训",
"建立AI事故应急预案"
]
}
return framework
# 法律分析示例
analyzer = LegalFrameworkAnalyzer()
test_scenario = {
"ai_autonomy_level": 0.8, # AI自主度80%
"human_awareness": 0.2, # 人类知晓度20%
"ai_capability": 0.9, # AI能力90%
"ai_learning": True, # AI会学习
"behavior_evolution": True # 行为会进化
}
print("=== AI爬虫法律分析 ===")
issues = analyzer.analyze_ai_crawler_case(test_scenario)
print("识别到的法律问题:")
for issue in issues:
print(f" - {issue['issue']}: {issue['description']}")
print(f" 严重程度: {issue['severity']}, 法律空白: {issue['current_law_gap']}")
solutions = analyzer.propose_legal_solutions(issues)
print("\n建议解决方案:")
for solution in solutions:
print(f" - {solution['proposal']}")
print(f" 详情: {solution['details']}")🎯 生存指南:在AI时代的数据战争中保持不败
企业级数据战略框架
基于以上分析,我们提出一个完整的AI时代数据战略框架:
python
class DataWarfareStrategy:
"""AI时代数据战争生存策略"""
def __init__(self, company_type, resource_level):
self.company_type = company_type
self.resource_level = resource_level # 资源水平:low, medium, high
self.strategy_matrix = self.build_strategy_matrix()
def build_strategy_matrix(self):
"""构建策略矩阵"""
strategies = {
"创业公司": {
"low": self.startup_low_resource_strategy,
"medium": self.startup_medium_resource_strategy,
"high": self.startup_high_resource_strategy
},
"成熟企业": {
"low": self.mature_low_resource_strategy,
"medium": self.mature_medium_resource_strategy,
"high": self.mature_high_resource_strategy
}
}
return strategies
def startup_low_resource_strategy(self):
"""创业公司低资源策略"""
return {
"爬虫策略": "高度聚焦,只爬取核心竞争数据",
"反爬策略": "依赖云服务基础防护,重点保护核心数据",
"AI应用": "使用公开AI工具进行基础数据分析",
"合规重点": "严格遵守法律红线,避免高风险操作",
"资源分配": "80%进攻(爬取),20%防守(反爬)"
}
def startup_high_resource_strategy(self):
"""创业公司高资源策略"""
return {
"爬虫策略": "创新突破,尝试新技术新方法",
"反爬策略": "建立基础防护体系,监控重点数据",
"AI应用": "探索AI在数据清洗和分析中的应用",
"合规重点": "在合规框架内最大化数据获取",
"资源分配": "70%进攻,30%防守"
}
def mature_low_resource_strategy(self):
"""成熟企业低资源策略"""
return {
"爬虫策略": "保守稳定,与主要竞对形成默契",
"反爬策略": "全面防守,重点在合规和风险控制",
"AI应用": "使用AI增强现有反爬系统",
"合规重点": "零容忍违规,建立完善合规体系",
"资源分配": "30%进攻,70%防守"
}
def mature_high_resource_strategy(self):
"""成熟企业高资源策略"""
return {
"爬虫策略": "技术领先,建立数据获取技术壁垒",
"反爬策略": "智能防御,AI驱动的自适应防护",
"AI应用": "全面集成AI到数据获取和防护全流程",
"合规重点": "参与行业标准制定,引领合规实践",
"资源分配": "40%进攻,60%防守"
}
def get_recommended_strategy(self):
"""获取推荐策略"""
strategy_func = self.strategy_matrix.get(self.company_type, {}).get(
self.resource_level, self.default_strategy
)
if callable(strategy_func):
return strategy_func()
else:
return strategy_func
def default_strategy(self):
"""默认策略"""
return {
"核心原则": "低调、合规、高效",
"行动指南": "在合法框架内最大化数据价值",
"风险控制": "始终将法律风险置于首位"
}
def generate_implementation_plan(self, timeline_months=12):
"""生成实施计划"""
strategy = self.get_recommended_strategy()
plan = {
"第一阶段(1-3个月)": [
"合规框架建立与团队培训",
"基础数据资产盘点与分类",
"现有爬虫/反爬系统评估"
],
"第二阶段(4-6个月)": [
"根据战略调整技术架构",
"部署AI增强的监控系统",
"建立数据质量评估体系"
],
"第三阶段(7-9个月)": [
"优化数据获取与防护策略",
"实施自动化合规检查",
"建立行业数据共享机制(如适用)"
],
"第四阶段(10-12个月)": [
"全面评估战略效果",
"调整优化长期策略",
"参与行业标准与最佳实践制定"
]
}
return {
"公司类型": self.company_type,
"资源水平": self.resource_level,
"核心战略": strategy,
"实施路线图": plan
}
# 策略生成示例
print("=== AI时代数据战争生存策略 ===")
scenarios = [
("创业公司", "high"),
("成熟企业", "medium"),
("创业公司", "low")
]
for company_type, resource_level in scenarios:
strategist = DataWarfareStrategy(company_type, resource_level)
plan = strategist.generate_implementation_plan()
print(f"\n{company_type} - {resource_level}资源水平:")
print("核心战略:")
for key, value in plan["核心战略"].items():
print(f" {key}: {value}")
print("\n首季度重点:")
for task in plan["实施路线图"]["第一阶段(1-3个月)"]:
print(f" - {task}")个人开发者的生存法则
对于个人开发者和小团队,在AI时代的数据战争中生存需要不同的策略:
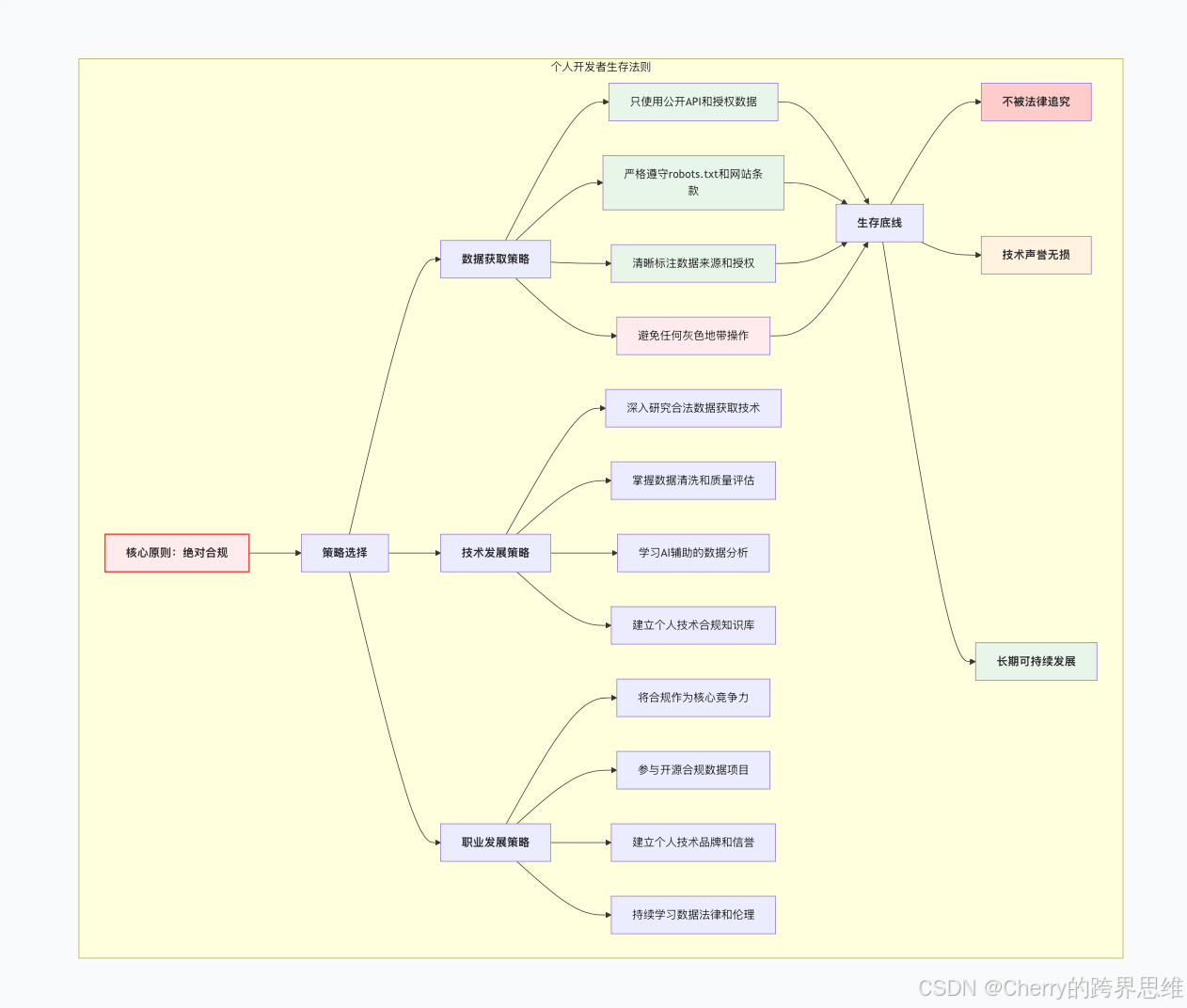
🌟 结语:三者的和谐共生
当技术、人类和AI在数据战场上相遇,我们面临的选择不是谁战胜谁,而是如何让这三者和谐共生。爬虫与反爬虫的战争本质上是数据资源分配的矛盾体现,而AI的加入既加剧了这场战争,也提供了新的解决方案。
最终生存法则:
- 技术是工具,不是目的 - 无论爬虫还是反爬虫,都应服务于业务价值创造
- 合规是底线,不是上限 - 在法律框架内创新,而不是挑战法律
- 数据是粮食,不是武器 - 用数据创造价值,而不是制造破坏
- AI是伙伴,不是替罪羊 - 人类应对AI的行为承担最终责任
在AI时代的数据战争中,最强大的武器不是最高深的技术,而是最清醒的认知:知道什么该做,什么不该做;知道何时进攻,何时防守;知道如何用技术创造价值,而不是制造麻烦。
记住,无论技术如何进化,人类的智慧、道德和责任永远是不可替代的核心。在这场数字生存战中,最终获胜的将不是技术最强大的那一方,而是最明智、最可持续的那一方。
技术可以复制,数据可以爬取,AI可以训练,但明智的判断和道德的坚守------这些才是AI时代最稀缺的资源,也是我们在这场数字生存战中最终的护城河。