文章目录
- 摘要
- Abstract
- 一、动手学大模型
-
- [1. 代码解读](#1. 代码解读)
-
- [1.1 数据加载与处理](#1.1 数据加载与处理)
- [1.2 模型加载](#1.2 模型加载)
- [1.3 主函数](#1.3 主函数)
-
- [1.3.1 参数初始化与日志打印](#1.3.1 参数初始化与日志打印)
- [1.3.2 加载预训练模型、配置和分词器](#1.3.2 加载预训练模型、配置和分词器)
- [1.3.3 加载数据并构建 Dataset](#1.3.3 加载数据并构建 Dataset)
- [1.3.4 定义评估指标函数compute_metrics](#1.3.4 定义评估指标函数compute_metrics)
- [1.3.5 配置训练参数TrainingArguments](#1.3.5 配置训练参数TrainingArguments)
- [1.3.6 初始化训练器Trainer](#1.3.6 初始化训练器Trainer)
- [1.3.7 训练流程](#1.3.7 训练流程)
- [1.3.8 验证流程](#1.3.8 验证流程)
- [1.3.9 测试流程](#1.3.9 测试流程)
- 二、传统OCR基础知识
-
- [1. 介绍](#1. 介绍)
-
- [1.1 图像预处理](#1.1 图像预处理)
- [2. 高斯滤波算法](#2. 高斯滤波算法)
- 总结
摘要
本周主要完成文本分类任务的代码解读,对解读过程中产生的疑问进行解答以及对遗忘的知识点进行复习。
同时,对OCR进行一些了解。知道OCR的定义,工作原理,并对图像预处理的去噪中的方法进行补充。
Abstract
This week, I mainly completed the code interpretation of the text classification task, addressed the questions arising during the interpretation process, and reviewed the forgotten knowledge points.
Meanwhile, I gained some understanding of OCR (Optical Character Recognition). I learned about its definition and working principle, and supplemented my knowledge of denoising methods in image preprocessing.
一、动手学大模型
1. 代码解读
1.1 数据加载与处理
load_data()加载数据
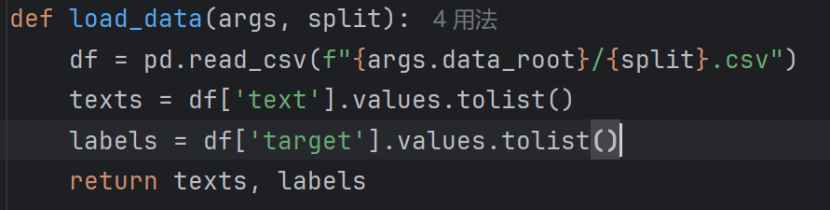
- 将数据按照相应分类存于不同的路径
文件路径是数据根目录 + 拆分类型.csv(比如args.data_root是./data、split是train的话,路径就是./data/train.csv)。 - 数据按照texts文本和labels标签进行存储
getitem ()加载单个样本
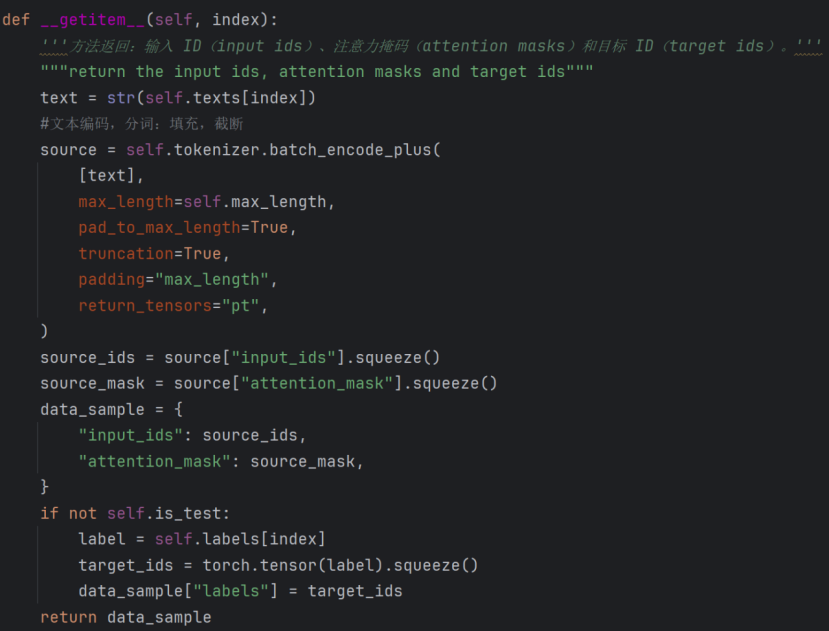
使用预训练的tokenizer(如 BERT 的 tokenizer)对文本进行编码,batch_encode_plus支持批量处理(这里传入text是单样本批量)。
- Source:设置最大长度,没有达到长度进行填充,超过长度进行截断。返回tensor格式数据。
- source"input_ids"是编码后的 token ID 张量,形状为1, max_length(因为传入了单样本批量text),squeeze()去除维度为 1 的维度,变为max_length。source"attention_mask"同理。
- 创建字典data_sample,存储模型输入的核心数据:input_ids(token ID 序列)和attention_mask(注意力掩码)。
- If语句:处理标签(非测试集时)
1.2 模型加载
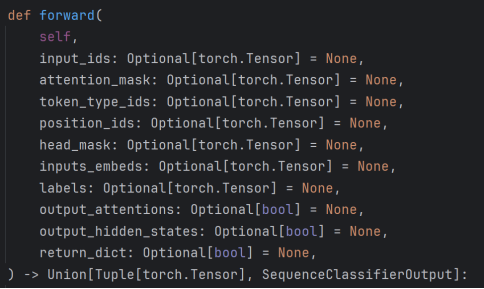
前向传播方法forward
前向方法是模型的核心,接收输入并返回输出(含损失和预测 logits)。

补充:
1,为什么要加位置编码
位置编码的核心作用是让模型感知序列中 token 的顺序信息,这是因为 Transformer(包括 BERT)的自注意力机制是 "无位置感知" 的。它本身是置换不变的(即打乱 token 顺序,自注意力的计算结果不会变),而文本的语义高度依赖 token 的顺序(比如 "我打你" 和 "你打我" 含义完全不同)。
2,为什么此时的位置编码不是用来进行残差链接?
位置编码的目的是让模型感知 token 的顺序,残差连接的目的是优化深度模型的训练(缓解深度神经网络的梯度消失问题;保留底层的原始信息,增强不同层之间的信息流动)。位置编码的接入会和残差连接的流程结合,但位置编码本身并不是为了残差连接而存在。
3,forward中optional和none什么意思
- OptionalX:是类型注解,说明参数允许的类型(X或None),属于 "代码提示",不影响运行逻辑。
- = None:是默认值设置,决定参数未传入时的取值,属于 "运行逻辑"。
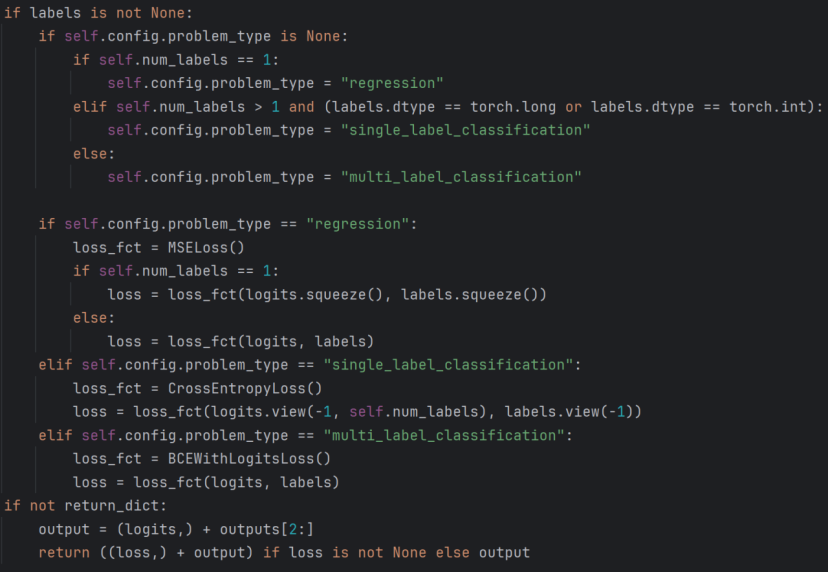
主要完成
1,任务类型判别。配置中未手动指定problem_type(任务类型),需要自动判别任务类型,根据标签数量判别任务属于回归还是分类(单标签?多标签?)。如果 类别数量 = 1判定为回归任务;当 类别数量 > 1,且标签类型是long或int 判定为单标签分类;剩余情况为多标签分类
补充:
单标签:一个样本对应一个类别,各个类别互斥,和为全集。标签形式:类别索引。
多标签:一个样本可能对应多个类别,各个类别相互独立。标签形式:二进制向量。
单标签输出softmax后概率最大的类别的索引号,而多标签可以视作多个二分类问题,根据每个问题softmax后概率大于判别值输出1,否则0,有几个类别输出几维0/1向量
2,根据不同的任务类别决定损失函数类型。
其中回归任务使用:用MSELoss(均方误差),适用于连续值预测。去除维度为1的维度(如batch_size,1→batch_size);
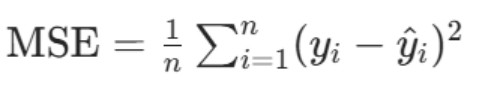
单标签任务使用:用CrossEntropyLoss(交叉熵),要求标签是类别索引,logits需展平为总数, 类别数,标签展平为总数。将logits和labels展平:logits→batch_size*seq_len, num_labels,labels→batch_size* seq_len;

多标签任务使用:用BCEWithLogitsLoss(二元交叉熵),标签是 0/1 向量(float 型),直接计算每个类别的二分类损失。

3,输出格式处理
不返回字典时(return_dict=False):
output = (logits,) + outputs2::将预测结果logits与 BERT 模型输出的额外信息(如隐藏层状态、注意力权重,即outputs2:)拼接成元组。
补充:
(1)当返回不为字典时,output为元组,此时Output组成:

此时,拼接后的output为:(logits, hidden_states, attentions)
(2)当返回字典是,output为类的一个对象,拥有以下属性:

1.3 主函数
1.3.1 参数初始化与日志打印
- Print ( json.dumps(vars(args), indent=2, sort_keys=False ) )
语句的作用:将命令行参数对象以格式化的 JSON 字符串形式打印输出
(1)vars()函数用于获取对象的属性字典,将args的参数(如data_root、epoch等)转为键值对字典
(2)json.dumps( ..., indent=2, sort_keys=False ):
参数说明:
①json.dumps()将 Python 字典转为 JSON 字符串;
②indent=2:设置缩进为 2 个空格,让输出格式更美观、易读;
③sort_keys=False:不按字母顺序排序字典的键,保持参数定义的原始顺序。
疑问:为什么设置随机种子数?
核心目的:保证实验的可复性。
(1)通过设置随机种子,可以让这些随机操作的结果固定,确保:
相同参数下,多次运行代码得到的结果一致;
不同实验(如调整超参数、修改模型结构)的对比是公平的。
补充:
为什么设置随机种子数可以确保实验结果一致?
随机种子会固定所有随机数生成器的 "初始状态",让原本 "随机" 的操作变成 "可预测的确定性操作"。
具体例子如下:
当种子数相同时,随机生成数据一致。因此并非真正的随机,而是通过确定性算法生成的 "伪随机数"。

如果不设置种子,随机数生成器会使用系统默认的动态种子(如当前时间戳、硬件状态等),每次运行的初始状态都不同,导致:
1,模型参数初始化不同;
2,数据顺序打乱方式不同;
3,Dropout 失活的神经元不同;
最终训练出的模型权重、验证精度等结果也会千差万别。
(2)随机种子数的使用时机
需在模型初始化、数据加载之前设置随机种子,确保后续所有随机操作都受种子控制。
(3)深度学习中随机性来源与种子的作用
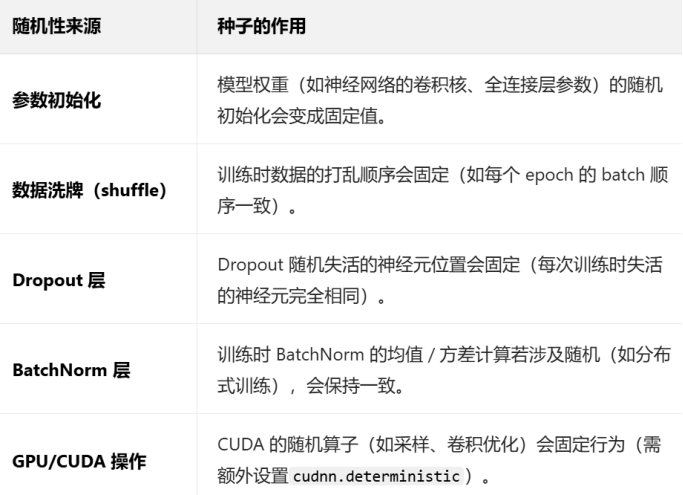
疑问:设置随机种子数会不会导致只有某一特定情况的训练效果最佳?
不会直接导致 "只有某一特定种子对应最佳效果",但会影响单次实验的结果波动,而 "最佳效果" 本质是模型在特定随机性下的表现,并非种子本身的特性。
实验中避免单一种子下结论;种子用于复现,非调优。
1.3.2 加载预训练模型、配置和分词器
AutoConfig:自动匹配预训练模型的配置(无需手动指定)。
AutoTokenizer:自动加载对应模型的分词器(处理文本编码)。
from_pretrained:加载预训练权重,初始化模型(若config中指定num_labels,则分类头适配任务类别数)。
1.3.3 加载数据并构建 Dataset
load_data :根据不同数据路径对数据进行加载(数据划分,分为训练集,验证机以及测试集)
构建自定义的Dataset:将数据按照任务需求进行编码作为模型输入
1.3.4 定义评估指标函数compute_metrics
EvalPrediction:包含predictions(模型输出 logits)和label_ids(真实标签)。是transformer
处理逻辑:
- 提取预测logits;
- 计算预测类别;
- 对比真实标签。
(1)preds = p.predictions0 if isinstance(p.predictions, tuple) else p.predictions
语句作用:条件赋值 + 类型判断,用于兼容不同模型的输出格式
语句分析:
- isinstance(a, b)是 Python 内置函数,用于判断a是否是b类型(或其子类)的实例。
- 三元运算符:语法为A if 条件 else B,若条件成立则赋值A,否则赋值B。
- Tuple为元组序列类型,有序且不可变。
(2)preds = np.argmax(preds, axis=1)
NumPy 的按轴取最大值的索引方法,专为单标签分类设计
(3).item()方法
作用:将包含单个元素的张量 / 数组转换为 Python 原生标量(如 int、float)。
补充:为什么需要.item()?
- 若直接用张量 / NumPy 标量参与运算,虽然结果可能正确,但会保留张量 / 数组类型,可能导致不必要的内存占用或类型错误;
- .item()确保得到的是 Python 原生数值类型,更轻量且兼容普通数值运算。
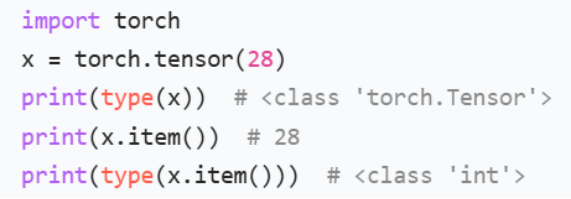
疑问一:参数什么意思 p : EvalPrediction ?
p: EvalPrediction是 Python 的类型注解,作用是:
(1)明确参数p的类型必须是EvalPrediction(或其子类),增强代码可读性和类型检查(如用mypy工具时可检测类型错误);
(2)告诉开发者p包含哪些属性(如predictions、label_ids),方便使用。
1.3.5 配置训练参数TrainingArguments
封装所有训练的超参数,无需手动写训练循环。
logging_strategy="steps",定义了日志记录的触发策略,日志(如训练损失、学习率等)会按指定的步数间隔记录。默认step=500,step是 Transformers 库的参数配置中用于表示 "按训练步数触发操作" 的策略标识。
save_strategy="epoch",定义了模型保存的触发策略,模型会在每个 epoch 结束后自动保存。
1.3.6 初始化训练器Trainer
Trainer:Transformers 库的核心训练器,封装了训练、验证、预测的完整逻辑(包括梯度下降、显存优化、分布式训练等)。
1.3.7 训练流程
开始训练:自动加载数据/前向传播/反向传播。trainer.train():启动训练循环,返回训练结果(包含损失、步数等)
获取训练指标:训练损失/耗时
保存模型和分词器,保存训练指标到文件并且还要保存训练状态。方便后续加载或分析。
1.3.8 验证流程
在验证集上评估。trainer.evaluate():在验证集上计算损失和自定义指标(如准确率)。
疑问:do_eval是什么?
do_eval并不是一个 "方法"(函数 / 方法),而是 Hugging Face Transformers 库中TrainingArguments类的布尔型配置参数,用于控制训练器(Trainer)是否执行验证 / 评估流程。
1.3.9 测试流程
在测试集上执行预测→将 logits 转换为类别→将预测结果按索引保存到文件
(1)do_predict是TrainingArguments中的布尔参数,用于控制是否执行测试集预测流程:do_predict=True,进入预测逻辑;do_predict=False,跳过预测步骤
(2)
(3)output_predict_file = os.path.join(args.output_dir, "predict_results.txt")
作用:拼接预测结果的保存路径。
os.path.join:跨平台拼接路径(避免 Windows/Linux 路径分隔符差异);
args.output_dir:训练参数中指定的输出目录(如experiments);
(4)trainer.is_world_process_zero():判断当前进程是否是 "主进程"(分布式训练中通常有多个进程,主进程编号为 0);
(5)with open(output_predict_file, "w") as writer:
以写入模式打开文件:
- with语句是 Python 的上下文管理器,自动处理文件的打开和关闭(即使发生错误也能安全关闭);
- "w"表示覆盖写入(若文件已存在则清空,否则新建)。
(6)writer.write("index\tprediction\n")
写入文件头:
index\tprediction:第一列是样本索引,第二列是预测类别,用制表符\t分隔,方便后续查看或解析。
(7)for index, item in enumerate(predictions):
遍历所有预测结果,逐行写入文件: - enumerate(predictions):同时获取样本的索引(index)和对应的预测类别(item);
- writer.write(f"{index}\t{item}\n"):按 "索引 + 制表符 + 预测类别 + 换行" 的格式写入
结果样式如下:

补充:训练轮数与批次
训练轮数epoch = n:表示所有数据全部训练n次,
批次batch=n:表示所有数据分为n份进行训练
二、传统OCR基础知识
1. 介绍
OCR定义:光学字符识别(Optical Character Recognition)是一种将图像中的文字转换为可编辑文本的技术。
OCR应用场景:文档数字化、车牌识别、票据处理等。
OCR的工作原理:图像预处理 → 文字检测 → 文字识别 → 后处理。
1.1 图像预处理
图像预处理:灰度化、二值化、去噪等操作。核心作用是 "突出文本特征、降低干扰信息"
-
灰度化(Grayscale):简化图像信息,减少计算量
通俗解释:把彩色图片(RGB 三个通道)变成黑白图片(仅一个通道),保留 "亮度" 信息,去掉 "色彩" 干扰。
-
去噪(Denoising):消除干扰点,让文字边缘更清晰
核心作用:避免 OCR 把 "噪声点" 误判为文字,或因噪声导致文字边缘模糊,识别准确率下降。
常用方法:
(1)高斯滤波(Gaussian Blur):适合消除高斯噪声(如轻微模糊);
(2)中值滤波(Median Blur):适合消除椒盐噪声(如黑白杂点);
(3)形态学处理(Morphology):比如 "开运算"(先腐蚀再膨胀),去掉小杂点同时保留文字轮廓。
-
二值化(Binarization):将图像变成 "纯黑纯白",突出文字
通俗解释:把灰度图(0-255 渐变)变成只有 "黑色" 和 "白色" 的二值图,让文字和背景完全分离。
核心作用:彻底剥离背景干扰(如阴影、渐变背景),让 OCR 模型只关注 "黑色文字",大幅提升识别精度。
常用方法:
(1)全局阈值二值化(Global Threshold):用一个固定阈值(如 127),灰度值低于阈值的设为黑色,高于的设为白色(适合背景均匀的图片);
(2)自适应阈值二值化(Adaptive Threshold):对图片不同区域用不同阈值(适合背景有阴影、亮度不均的图片,比如拍照倾斜的文档)。
2. 高斯滤波算法
高斯滤波是一种线性平滑滤波器,它使用高斯函数作为权重核来对图像(或信号)进行卷积,从而达到抑制噪声、平滑图像的目的。
核心思想是:距离中心像素越近的像素,对最终结果的贡献越大。
高斯函数:

高斯滤波的步骤
1,生成高斯核
核的大小:一般为奇数(例如:3×3)。尺寸越大,平滑效果越强,但细节丢失越多。
标准差σ:越小,图像关注区域越集中。如果非正,则从 ksize 计算σ = 0.3×((ksize-1)×0.5 - 1) + 0.8

核内每个位置的权重值计算:
-
首先,由于以图片中心为重点,因此对中心取为坐标(0,0),旁边其余坐标如下
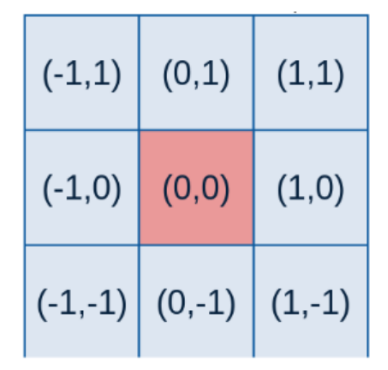
-
其次,根据标准差σ、二维高斯函数以及各个点的坐标计算得到高斯核内每一个位置的权重值
假设σ=1,得到如下矩阵A:
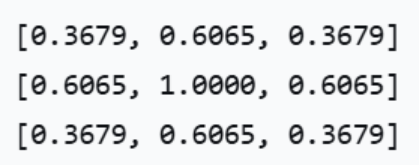
注意:由于最后要进行归一化处理,因此在计算模板中各个元素的值时,可以去掉高斯函数的系数1/(2·Π·σ2)
归一化:使核内所有权重之和为 1,以保证图像整体亮度不变。
在得到的权重矩阵前面乘上各个元素和的倒数,得到如下矩阵B:

计算表达式如下:B = A /(0.36794+0.6065 4+1)
以第一个具体值举例:0.075=0.3679/(0.36794+0.60654+1)
2,卷积
总结
本周主要完成代码解读,结合自身当前的学习情况,意识到后续的学习应加入更多的动手实践部分内容,因此打算后续的学习从实践入手,慢慢补充不会的知识细节,提高代码能力。同时要慢慢加入文献的阅读。