第 39章 本地化(语言环境)( Locales)
(译注:以下交替使用"本地化"和"语言环境"这两种译名。)
目录
[39.1 处理文化差异(Handling Cultural Differences)](#39.1 处理文化差异(Handling Cultural Differences))
[39.2 类locale (Class locale)](#39.2 类locale (Class locale))
[39.2.1 命名locale (Named locales)](#39.2.1 命名locale (Named locales))
[39.2.1.1 构造新的locale (Constructing New locales)](#39.2.1.1 构造新的locale (Constructing New locales))
[39.2.2 比较字符串 (Comparing strings)](#39.2.2 比较字符串 (Comparing strings))
[39.3 类facet (Class facet)](#39.3 类facet (Class facet))
[39.3.1 在locale中访问facets (Accessing facets in a locale)](#39.3.1 在locale中访问facets (Accessing facets in a locale))
[39.3.2 一个简单的用户定义facet (A Simple User-Defined facet)](#39.3.2 一个简单的用户定义facet (A Simple User-Defined facet))
[39.3.3 使用locale和facet (Uses of locales and facets)](#39.3.3 使用locale和facet (Uses of locales and facets))
[39.4 标准 facet (Standard facets)](#39.4 标准 facet (Standard facets))
[39.4.1 string 比较 (string Comparison)](#39.4.1 string 比较 (string Comparison))
[39.4.1.1 命名collate(Named collate)](#39.4.1.1 命名collate(Named collate))
[39.4.2 数值格式化(Numeric Formatting)](#39.4.2 数值格式化(Numeric Formatting))
[39.4.2.1 数值标点(Numeric Punctuation)](#39.4.2.1 数值标点(Numeric Punctuation))
[39.4.2.2 数值输出(Numeric Output)](#39.4.2.2 数值输出(Numeric Output))
[39.4.2.3 数值输入(Numeric Input)](#39.4.2.3 数值输入(Numeric Input))
[39.4.3 货币格式化(Money Formatting)](#39.4.3 货币格式化(Money Formatting))
[39.4.3.1 货币标点(Money Punctuation)](#39.4.3.1 货币标点(Money Punctuation))
[39.4.3.2 货币输出(Money Output)](#39.4.3.2 货币输出(Money Output))
[39.4.3.3 货币输入(Money Input)](#39.4.3.3 货币输入(Money Input))
[39.4.4 日期和时间格式化(Date and Time Formatting)](#39.4.4 日期和时间格式化(Date and Time Formatting))
[39.4.4.1 time_put](#39.4.4.1 time_put)
[39.4.4.2 time_get](#39.4.4.2 time_get)
[39.4.5 字符分类(Character Classification)](#39.4.5 字符分类(Character Classification))
[39.4.6 字符编码转换(Character Code Conversion)](#39.4.6 字符编码转换(Character Code Conversion))
[39.4.7 消息(Messages)](#39.4.7 消息(Messages))
[39.4.7.1 使用来自其它 facet 的消息(Using Messages from Other facets)](#39.4.7.1 使用来自其它 facet 的消息(Using Messages from Other facets))
[39.5 便捷接口(Convenience Interfaces)](#39.5 便捷接口(Convenience Interfaces))
[39.5.1 字符分类(Character Classification)](#39.5.1 字符分类(Character Classification))
[39.5.2 字符转换(Character Conversions)](#39.5.2 字符转换(Character Conversions))
[39.5.3 字符串转换(String Conversions)](#39.5.3 字符串转换(String Conversions))
[39.5.4 缓冲区转换(Buffer Conversions)](#39.5.4 缓冲区转换(Buffer Conversions))
[39.6 建议(Advice)](#39.6 建议(Advice))
39.1 处理文化差异( Handling Cultural Differences**)**
locale 是一个表示一组文化偏好的对象,例如字符串的比较方式、数字作为人类可读输出的显示方式以及字符在外部存储中的表示方式。本地化(语言环境)的概念是可扩展的,因此程序员可以向语言环境添加新的facet ,这些facet 表示标准库不直接支持的特定于语言环境的实体,例如邮政编码和电话号码。标准库中语言环境的主要用途是控制写入 ostream 的信息的外观以及 istream 读取的数据的格式。
本章介绍如何使用locale ,如何使用facet 构建locale , 以及locale如何影响 I/O 流。
本地化的概念并非主要存在于 C++ 中。大多数操作系统和应用程序环境都具有本地化的概念。在原则上,该概念在系统上的所有程序之间共享,无论它们使用哪种编程语言编写。因此,C++ 标准库中的本地化概念可以视为一种标准且可移植的方式,供 C++ 程序访问在不同系统上具有截然不同表示方式的信息。 此外,C++ locale还是一个系统信息的接口,这些信息在不同系统上的表示方式可能不兼容。
假设你要编写一个需要在多个国家/地区使用的程序。以允许这种情况发生的风格编写程序通常被称为国际化 (internationalization)(强调程序可在多个国家/地区使用)或本地化(localization)(强调程序能够适应当地情况)。程序操作的许多实体通常会在这些国家/地区以不同的方式显示。我们可以通过编写 I/O 例程来解决这个问题,以将这种情况考虑在内。例如:
void print_date(const Date& d) // print in the appropriate for mat
{
switch(where_am_I) { // user-defined style indicator
case DK: // e.g., 7. marts 1999
cout << d.day() << ". " << dk_monthd.month() << " " << d.year();
break;
case ISO: // e.g., 1999-3-7
cout << d.year() << " − " << d.month() << " / " << d.day();
break;
case US: // e.g., 3/7/1999
cout << d.month() << "/" << d.day() << "/" << d.year();
break;
// ...
}
}
这种代码风格确实能满足需求。然而,这种代码很丑陋,而且难以维护。特别是,我们必须始终如一地使用这种风格,以确保所有输出都根据本地习惯进行了适当的调整。如果我们想添加一种新的日期书写方式,就必须修改应用程序代码。更糟糕的是,日期书写方式只是众多文化差异的例子之一。
因此,标准库提供了一种可扩展的方式来处理文化习俗。iostream库依赖此框架来处理内置类型和用户定义类型(§38.1)。例如,考虑一个简单的可能表示一系列测量值或一组事务的循环复制(Date,double) 对:
void cpy(istream& is, ostream& os)// copy (Date,double) stream
{
Date d;
double volume;
while (is >> d >> volume)
os << d << ' '<< volume << '\n';
}
当然,真正的程序会对记录做一些事情,理想情况下也会对错误处理更加小心。如何让这个程序读取一个符合法国格式的文件(法国格式中,逗号是用来表示浮点数小数点的字符;例如, 12,5 表示十二点五),并按照美国格式写入? 我们可以定义locale 和 I/O 操作,以便使用**cpy()**在两种格式之间进行转换:
void f(istream& fin, ostream& fout, istream& fin2, ostream& fout2)
{
fin.imbue(locale{"en_US.UTF −8"}); // American English
fout.imbue(locale{"fr_FR.UTF −8"}); // French
cpy(fin,fout); //read American English, write French
// ...
fin2.imbue(locale{"fr_FR.UTF −8"}); // French
fout2.imbue(locale{"en_US.UTF −8"}); // American English
cpy(fin2,fout2); //read French, write American English
// ...
}
已知这些流为:
Apr 12, 1999 1000.3
Apr 13, 1999 345.45
Apr 14, 1999 9688.321
...
3 juillet 1950 10,3
3 juillet 1951 134,45
3 juillet 1952 67,9
...
则这个程序会产生:
12 avril 1999 1000,3
13 avril 1999 345,45
14 avril 1999 9688,321
...
July 3, 1950 10.3
July 3, 1951 134.45
July 3, 1952 67.9
...
本章的其余部分将致力于描述实现这一目标的机制并解释如何使用它们。然而,大多数程序员几乎没有理由处理locale 的细节,并且永远不会明确地操作locale 。他们最多只会检索一个标准语言环境并将其注入(imbue)到流中(§38.4.5.1)。
本地化(国际化)的概念很简单。然而,实际的限制使得 locale 的设计和实现相当复杂:
1 locale封装了文化习俗,例如日期的显示方式。这些习俗在许多细微且不系统的方式上存在差异。这些习俗与编程语言无关,因此编程语言无法对其进行标准化。
2 locale的概念必须是可扩展的,因为不可能列举出所有对每一个 C++ 用户都重要的文化习俗。
3 locale用于人们要求运行时效率的操作(例如,I/O 和排序)。
4 对于大多数程序员来说,locale必须是不可见的,他们希望从"做正确的事情"的设施中获益,而不必确切知道"正确的事情"是什么或如何实现。
5 处理超出标准范围的文化敏感信息的设施设计人员必须能够使用locale。
这些用于组合这些locale并使其易于使用的机制构成了它们自己的一种小型编程语言。
locale 由控制各个方面的facet 组成,例如,浮点值输出中使用的标点符号(decimal_point() ;§39.4.2)以及读取货币值的格式(moneypunct ;§39.4.3)。facet 是从类 locale::facet (§39.3)派生的类的对象。我们可以将locale 视为facet(§39.2、§39.3.1)的容器。
39.2 类 locale ( Class locale )
locale 类及其相关设施呈现于**<locale>**。
|---------------------------------|------------------------------------------------------------------------------------------------------------------------------|
| locale 成员**(§iso.22.3.1)** ||
| locale loc {}; | loc是当前全局语言环境的副本;noexcept |
| locale loc {loc2}; | 复制构造函数:loc 存储 loc2 的副本;loc.name()==loc2.name();noexcept |
| locale loc {s}; | 将 loc 初始化为具有名称 s 的locale ;s 可以是string 或 C 风格字符串;loc.name()==s ;explicit |
| locale loc {loc2,s,cat}; | loc 是 loc2 的副本,除了类别为 cat 的方面,它是从 locale{s} 复制而来的;s 可以是string 或 C 风格字符串;如果loc2 有名称,则 loc 也有名称 |
| locale loc {loc2,pf}; | loc 是 loc2 的一个副本,除了对于facet ∗ pf 前提是 pf!=nullptr ;loc 没有名称 |
| locale loc {loc2,loc3,cat}; | loc 是 loc2 的副本,除了 cat 类别的facet,它是从 loc3 复制而来的;如果 loc2 和loc3 都有名称,那么loc也有一个名称 |
| loc. ˜locale() | 析构函数;非虚函数;noexcept |
| loc2=loc | 赋值:loc2 是 loc 的副本;noexcept |
| loc3=loc.combine<F>(loc2) | loc3 是 loc 的一个副本,除了facet F, 而 facet F 是从 loc2 复制而来的;loc3没有名称 |
| s=loc.name() | s 是 loc 的语言环境名称或**"** ∗ " |
| loc==loc2 | loc 和 loc2 是同一个**˜locale吗? |
| loc!=loc2 | !(loc==loc2) |
| loc()(s,s2) | 使用 loc 的 collat e<C> 方面比较 basic_string<C>s 和 s2 |
| loc2=global(loc) | 将全局语言环境设置为 loc ;loc2 是前一个全局locale** |
| loc=classic() | loc是经典的"C"语言环境 |
如果已知名称的locale 或所引用的facet 不存在,则命名它的locale 操作将引发runtime_error。
locale 的命名有点奇怪。当你基于另一个locale 加上一个facet 创建新的locale 时,并且生成的locale 有一个名称时,该名称是由实现定义的。通常,这种由实现定义的名称包含提供大部分facet 的locale 的名称。对于没有名称的locale ,name() 返回**"** ∗ "。
可以将locale 视为 map<id,facet ∗ > 的接口,也就是说,它允许我们使用 locale::id 来查找 locale::facet 派生类的对应对象。locale 的实际实现是这种思想的有效变体。布局如下所示:
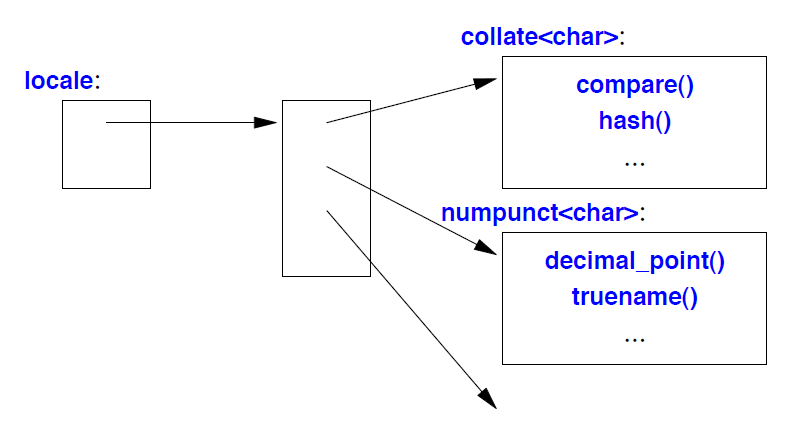
这里,collat e<char> 和numpunct<char> 是标准库 facet (§39.4)。所有 facet 均派生自locale::facet。
locale 旨在自由且低成本地复制 。因此,locale 几乎肯定会实现为构成其主要实现部分的特定 map<id,facet ∗ > 的句柄。在locale 中,各个方面必须能够快速访问。因此,特定map<id,facet ∗ > 将被优化以提供类似数组的快速访问。locale 的facet 可以通过 **use_facet<Facet>(loc)**表示法访问;参见 §39.3.1。
标准库提供了丰富的facet 。为了帮助程序员按逻辑分组操作facet ,标准facet 分为不同的类别,例如numeric 和collate (§39.4):
|--------------|-----------------------------------------------------------------|
| facet 分类 (§iso.22.3.1) ||
| collate | 例如, collate ; §39.4.1 |
| ctype | 例如,ctype ; §39.4.5 |
| numeric | 例如,num_put, num_g et, numpunct; §39.4.2 |
| monetary | money_put, money_g et, moneypunct; §39.4.3 |
| time | 例如,time_put, time_get; §39.4.4 |
| messages | messages ; §39.4.7 |
| all | collate | ctype | monetary | numeric | time | messages |
| none | |
程序员无法为新创建的locale 指定名称字符串。名称字符串要么在程序的执行环境中定义,要么由locale构造函数创建为这些名称的组合。
程序员可以替换现有类别中的facet(§39.4,§39.4.2.1)。但是,程序员无法定义新的类别。"类别"的概念仅适用于标准库facet,并且不可扩展。因此,facet不必属于任何类别,许多用户定义的facet也并非如此。
如果locale x 没有名称字符串,则locale::global(x) 是否影响 C 全局语言环境尚未定义。这意味着 C++ 程序无法可靠且可移植地将 C 语言环境设置为未从执行环境中检索的语言环境。C 程序没有设置 C++ 全局语言环境的标准方法(除非调用 C++ 函数)。在 C 和 C++ 混合程序中,使 C 全局语言环境与**global()**不同容易出错。
到目前为止,locale 的主要用途是隐式地应用于流 I/O 中。每个 istream 和 ostream 都有其自己的locale 。默认情况下,流的locale 是其创建时的全局locale (§39.2.1)。流的locale 可以通过 imbue() 操作设置,我们也可以使用 getloc() (§38.4.5.1) 提取流locale的副本。
设置全局locale 不会影响现有的 I/O 流;这些 I/O 流仍然使用重置全局locale之前所包含的语言环境。
39.2.1 命名 locale ( Named locale s**)**
一个locale 由另一个locale 和一些facet 构成。创建locale最简单的方法是复制一个现有的语言环境。例如:
locale loc1; // copy of the current global locale
locale loc2 {""}; // copy of ''the user's preferred locale''
locale loc3 {"C"}; // copy of the ''C'' locale
locale loc4 {locale::classic()}; // copy of the ''C'' locale
locale loc5 {"POSIX"}; // copy of the locale named "POSIX"
locale loc6 {"Danish_Denmark.1252"}; // copy of the locale named "Danish_Denmark.1252"
locale loc7 {"en_US.UTF −8"}; // copy of the locale named "en_US.UTF-8"
根据标准定义,locale{"C"} 指的是"经典"C 语言环境 ;本书通篇都使用此环境。其他locale名称则由具体实现定义。
locale{""} 被视为"用户的首选语言环境" 。此语言环境由程序执行环境中的非语言方式设置。因此,要查看你当前的**"首选语言环境"**,请键入:
locale loc("");
cout << loc.name() << '\n';
我的Windows笔记本电脑上显示:
English_United States.1252
在我的Linux系统上,我得到了:
en_US.UTF −8
C++ 中本地化设置的名称没有统一的标准。相反,诸如 POSIX 和 Microsoft **等各种组织针对不同的编程语言维护着各自不同的标准。**例如:
|---------------------|-----------------------|
| GNU本地化名称示例(基于POSIX) ||
| ja_JP | 日本的日语 |
| da_DK | 丹麦的丹麦语 |
| en_DK | 丹麦的英语 |
| de_CH | 瑞士的德语 |
| de_DE | 德国的德语 |
| en_GB | 英语的英语 |
| en_US | 美国的英语 |
| fr_CA | 加拿大的法语 |
| de_DE@euro | 德国的具有欧元符号€的德语 |
| de_DE.utf8 | 使用UTF-8的德国的德语 |
| de_DE.utf8@euro | 使用具有欧元符号€的UTF-8的德国的德语 |
POSIX 建议的格式为:小写语言名称,后跟可选的大写国家名称,再后跟可选的编码说明符,例如 sv_FI@euro(瑞典语,芬兰语,包含欧元符号)。
|---------------------------------|
| 微软本地化名称示例 |
| Arabic_Qatar.1256 |
| Basque.Spain.1252 |
| Chinese_Singapore.936 |
| English_United Kingdom.1252 |
| English_United States.1252 |
| French_Canada.1252 |
| Greek_Greece.1253 |
| Hebrew_Israel.1255 |
| Hindi_India.1252 |
| Russian_Russia.1251 |
微软使用语言名称,后跟国家/地区名称(可选),再后跟代码页编号。代码页(code page)是一种命名(或编号)的字符编码。
大多数操作系统都提供了为程序设置默认本地化的方法。通常,这是通过诸如 LC_ALL、LC_COLLATE 和 LANG 之类的环境变量来实现的。通常,当用户首次接触系统时,会选择一个适合自己的本地化。例如,我预计将 Linux 系统配置为使用阿根廷西班牙语作为默认设置的用户会发现 locale{""} 指的是 locale{"es_AR"} 。然而,这些名称在不同平台上并没有统一的标准。因此,要在特定系统上使用命名本地化,程序员必须查阅系统文档并进行实践。
通常来说,最好避免在程序文本中嵌入本地化名称字符串。 在程序文本中提及文件名或系统常量会限制程序的可移植性,并且常常迫使想要将程序适配到新环境的程序员去查找并修改这些值。提及区域设置名称字符串也会带来类似的负面影响。相反,可以从程序的执行环境中获取本地化设置 (例如,使用locale("") 或读取文件)。或者,程序可以请求用户通过输入字符串来指定备选本地化设置。例如:
void user_set_locale(const string& question)
{
cout << question; // e.g., "If you want to use a different locale, please enter its name"
string s;
cin >> s;
locale::global(locale{s}); // set global locale as specified by user
}
通常情况下,最好让非专业用户从一系列选项中进行选择。实现此功能的函数需要知道系统将本地化设置保存在哪里以及如何保存。例如,许多 Linux 系统将本地化设置保存在 /usr/share/locale 目录中。
如果字符串参数未指向已定义的本地化设置,则构造函数会抛出 runtime_error 异常(§30.4.1.1)。例如:
void set_loc(locale& loc, const char ∗ name)
try
{
loc = locale{name};
}
catch (runtime_error&) {
cerr << "locale
// ...
}
如果某个本地化设置有名称字符串 ,name() 函数将返回该名称字符串。否则,name() 函数将返回 string("*") 。**名称字符串主要用于引用存储在执行环境中的本地化设置。**其次,名称字符串还可以用作调试辅助工具。例如:
void print_locale_names(const locale& my_loc)
{
cout << "name of current global locale: " << locale().name() << "\n";
cout << "name of classic C locale: " << locale::classic().name() << "\n";
cout << "name of ''user's preferred locale'': " << locale("").name() << "\n";
cout << "name of my locale: " << my_loc.name() << "\n";
}
39.2.1.1 构造新的 locale ( Constructing New locale s**)**
创建新的locale 是通过在现有locale 的基础上添加或替换facet 来实现的。通常,新的 locale **只是基于现有本地化的一个细微变体。**例如:
void f(const locale& loc, const My_money_io ∗ mio) // My_money_io defined in § 39.4.3.1
{
locale loc1(locale{"POSIX"},loc,locale::monetary); // use monetary facets from loc
locale loc2 = locale(locale::classic(), mio); // classic plus mio
// ...
}
这里,loc1 是 POSIX locale 的副本,经过修改以使用 loc 的货币facet (§39.4.3)。类似地,loc2 是 C locale 的副本,经过修改以使用 My_money_io (§39.4.3.1)。最终的locale可以表示如下:
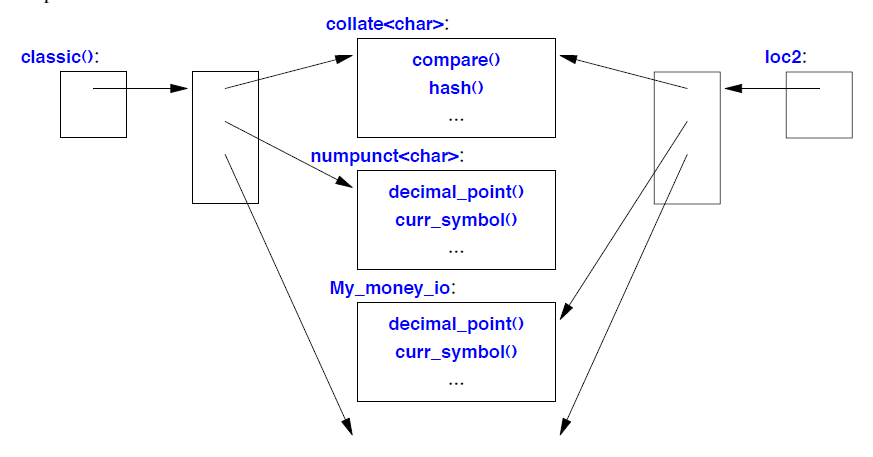
如果 Facet* 参数(此处为 My_money_io )为nullptr ,则生成的locale 只是locale参数的副本。
在构造函数 locale{loc,f } 中,参数 f 必须标识一个特定的facet 类型。普通的 facet ∗ 是不够的。例如:
void g(const locale::facet ∗ mio1, const money_put<char> ∗ mio2)
{
locale loc3 = locale(locale::classic(), mio1); // error : type of facet not known
locale loc4 = locale(locale::classic(), mio2); // OK: type of facet known (moneyput<char>)
// ...
}
locale 使用 Facet* 参数的类型在编译时确定 facet 的类型。具体来说,locale 的实现使用 facet 的标识类型 facet::id (§39.3)在locale 中查找该 facet(§39.3.1)。构造函数
template<class Facet> locale(const locale& x, Facet ∗ f);
是该语言中唯一允许程序员通过locale 提供facet 的机制。其他locale 由实现者以命名本地化设置的形式提供(§39.2.1)。命名本地化可以从程序的执行环境中获取。了解特定实现机制的程序员或许能够添加新的locale。
locale 构造函数集的设计使得每一个 facet 的类型都可以通过类型推导(根据 Facet 模板参数)或来自其他locale (已知其类型)来得知。指定 category 参数间接指定了 facet 的类型,因为locale 已知 category 中 facet 的类型。这意味着locale 类可以(并且确实)跟踪 facet 的类型,从而能够以最小的开销操作它们。
locale::id 成员类型由 locale 用于标识 facet 类型(§39.3)。
无法修改locale 。相反,locale 操作提供了从现有本地化创建新locale 的方法。locale 创建后不可更改,这对于运行时效率至关重要 。这使得使用locale 的用户能够调用 facet 的虚函数并缓存返回值。例如,istream 可以知道用什么字符来表示小数点,以及 如何在每一次读取一个数时都无需调用decimal_point() 、如何在每一次读一个bool 值时都无需调用truename() (§39.4.2)。只有对流调用imbue()(§38.4.5.1)才会导致此类调用返回不同的值。
39.2.2 比较字符串 ( Comparing string s**)**
根据locale 比较两个string 可能是locale 除了 I/O 操作之外最常见的用途。因此,locale 直接提供了此操作,用户无需根据collate 的facet (§39.4.1)构建自己的比较函数。此string 比较函数定义为locale 的 operator()()。例如:
void user(const string s1, const string s2, const locale& my_locale)
{
if (my_locale(s,s2)) { // is s<s2 according to my_locale?
// ...
}
}
将比较函数作为**()** 运算符,使其可以直接用作谓词(§4.5.4)。例如:
void f(vector<string>& v, const locale& my_locale)
{
sort(v.begin(),v.end()); //sor t using < to compare elements
// ...
sort(v.begin(),v.end(),my_locale); // sor t according to the rules of my_locale
// ...
}
默认情况下,标准库 sort() 使用 < 作为实现字符集的数值来确定排序顺序(§32.6,§31.2.2.1)。
39.3 类 facet ( Class facet )
locale 是一组facet 的集合。每一个 facet 代表一种具体的文化特征 ,例如数在输出中的表示方式 (num_put )、日期从输入中读取的方式 (time_get )以及字符在文件中的存储方式 (codecvt )。标准库中的facet列于第 39.4 节。
用户可以定义新的facet ,例如确定如何打印季节名称的facet(§39.3.2)。
在程序中,facet 表示为继承自 std::locale::facet 的类的对象。与其他所有locale 功能一样,facet 位于 **<locale>**中:
class locale::facet {
protected:
explicit facet(size_t refs = 0);
virtual ˜facet();
facet(const facet&) = delete;
void operator=(const facet&) = delete;
};
facet 类被设计为基类,并且没有公共函数。它的构造函数是受保护的,以防止创建"普通 facet"对象;它的析构函数是虚函数,以确保派生类对象被正确销毁。
facet 旨在通过存储在 locale 中的指针进行管理。facet 构造函数的参数为 0 表示 locale 应在最后一个引用消失时删除该facet 。相反,非零构造函数参数确保 locale 永远不会删除该facet 。非零参数用于极少数情况下 facet 的生命周期由程序员直接控制,而不是通过 locale 间接控制的情况。
每一种类型的facet 接口都必须有单独的 id:
class locale::id {
public:
id();
void operator=(const id&) = delete;
id(const id&) = delete;
};
id 的预期用途是供用户定义每一个提供新 facet 接口的类的id 类型静态成员(例如,参见 §39.4.1)。locale 机制使用 id 来标识 facet (§39.2,§39.3.1)。在locale 的直接实现中,id 用作 facet 指针向量的索引,从而实现高效的 map<id,facet*>。
用于定义(派生)facet 的数据在派生类中定义。这意味着定义 facet 的程序员对数据拥有完全控制权,并且可以使用任意数量的数据来实现facet 所表示的概念。
facet 的设计初衷是不可变的,因此用户定义的facet 的所有成员函数都应该定义为 const。
39.3.1 在 locale 中访问 facets ( Accessing facet s in a locale )
可以通过两个模板函数访问locale 的各个facet:
|---------------------------|-----------------------------------------------------------------------------------|
| 非成员 locale 函数 ||
| f=use_facet<F>(loc) | f 是指向loc 中 facet F 的引用;如果loc 中没有 facet F ,则抛出bad_cast 异常。 |
| has_facet<F>(loc) | loc 是否有facet F ? noexcept |
可以将这些函数视为在其locale 参数中查找模板参数F 。或者,可以将 use_facet 视为将locale 显式转换为特定 facet 的一种方式。这是可行的,因为一个facet 只能有一个已经类型的facet。例如:
void f(const locale& my_locale)
{
char c = use_facet<numpunct<char>>(my_locale).decimal_point() // use standard facet
// ...
if (has_facet<Encrypt>(my_locale)) { // does my_locale contain an Encrypt facet?
const Encrypt& f = use_facet<Encrypt>(my_locale); // retrieve Encr ypt facet
const Crypto c = f.g et_crypto(); // use Encrypt facet
// ...
}
// ...
}
标准facet 保证适用于所有locale (§39.4),因此我们不需要对标准facet 使用 has_facet。
理解 facet::id 机制的一种方式是将其视为一种编译时多态性的优化实现 。 可以使用 dynamic_cast 来获得与 use_facet 非常相似的结果。然而,特化的use_facet 实现方式比通用的dynamic_cast更高效。
id 用于标识接口和行为,而非类。也就是说,如果两个facet 类具有完全相同的接口并实现了相同的语义(就locale 而言),则它们应该使用相同的 id 进行标识。例如,collat e<char> 和 collat e_byname<char> 在同一locale 中可以互换,因此它们都使用 collat e<char>::id 进行标识(§39.4.1)。
如果我们定义一个具有新接口的facet ( 例如 f() 中的 Encrypt ),则必须定义一个相应的 id来标识它(参见 §39.3.2 和 §39.4.1)。
39.3.2 一个简单的用户定义 facet ( A Simple User-Defined facet )
标准库为最关键的文化差异领域(例如字符集和数的 I/O )提供了标准facet 。为了将facet 机制从广泛使用的类型的复杂性及其伴随的效率问题中剥离出来进行考察,我首先介绍一个简单的用户自定义类型的facet:
enum Season { spring, summer, fall, winter }; // very simple user-defined type
这里概述的 I/O 格式只需稍作修改即可用于大多数简单的用户自定义类型。
class Season_io : public locale::facet {
public:
Season_io(int i = 0) : locale::facet{i} { }
˜Season_io() { } // to make it possible to destroy Season_io objects (§39.3)
virtual const string& to_str(Season x) const = 0; // string representation of x
virtual bool from_str(const string& s, Season& x) const = 0; // place Season for s in x
static locale::id id; // facet identifier object (§39.2, §39.3, §39.3.1)
};
locale::id Season_io::id; // define the identifier object
为简单起见,此facet 仅限于char 型string。
Season_io 类为所有 Season_io 文化特征提供了一个通用的抽象接口。要定义特定locale 环境下的 Season 的 I/O 表示,我们需要从Season_io 类派生出一个类,并相应地定义to_str() 和**from_str()**函数。
输出Season 信息很简单。如果数据流包含 Season_io 的文化特征,我们可以使用它把值转换成字符串。否则,我们可以直接输出Season 的int值:
ostream& operator<<(ostream& os, Season x)
{
locale loc {os.getloc()}; // extract the stream ' s locale ( § 38.4.4)
if (has_facet<Season_io>(loc))
return os << use_facet<Season_io>(loc).to_str(x); // string representation
return os << static_cast<int>(x); // integer representation
}
为了最大限度地提高效率和灵活性,标准facet 通常直接操作流缓冲区(§39.4.2.2,§39.4.2.3)。但是,对于像Season 这样简单的用户自定义类型,则无需降低抽象的streambuf级别。
通常情况下,输入比输出要复杂一些:
istream& operator>>(istream& is, Season& x)
{
const locale& loc {is.getloc()}; // extract the stream ' s locale ( § 38.4.4)
if (has_facet<Season_io>(loc)) {
const Season_io& f {use_facet<Season_io>(loc)}; // get hold of the locale ' s Season_io facet
string buf;
if (!(is>>buf && f.from_str(buf,x))) // read alphabetic representation
is.setstate(ios_base::failbit);
return is;
}
int i;
is >> i; // read numer ic representation
x = static_cast<Season>(i);
return is;
}
错误处理很简单,遵循内置类型的错误处理风格。也就是说,如果输入字符串在所选本地化中不代表Season ,则流将进入失败状态。如果启用了异常处理,则意味着会抛出 **`ios_base::failure`**异常(参见第 38.3 节)。
这是一个简单的测试程序:
int main()
// a trivial test
{
Season x;
// use the default locale (no Season_io facet) implies integer I/O:
cin >> x;
cout << x << endl;
locale loc(locale(),new US_season_io{});
cout.imbue(loc); // use locale with Season_io facet
cin.imbue(loc); // use locale with Season_io facet
cin >> x;
cout << x << endl;
}
已知输入:
2
summer
程序响应:
2
summer
为此,我们必须从Season_io 派生出一个 US_season_io类,并定义一个合适的季节字符串表示形式:
class US_season_io : public Season_io {
static const string seasons\[\];
public:
const string& to_str(Season) const;
bool from_str(const string&, Season&) const;
// note: no US_season_io::id
};
const string US_season_io::seasons\[\] = {
"spring",
"summer",
"fall",
"winter"
};
然后,我们重写 Season_io函数,这些函数用于在字符串表示形式和枚举器之间进行转换:
const string& US_season_io::to_str(Season x) const
{
if (x<spring || winter<x) {
static const string ss = "no −such−season";
return ss;
}
return seasonsx;
}
bool US_season_io::from_str(const string& s, Season& x) const
{
const string ∗ p = find(begin(seasons),end(seasons),s);
if (p==end)
return false;
x = Season(p −begin(seasons));
return true;
}
请注意,由于 US_season_io 只是 Season_io 接口的一个实现,因此我没有为 US_season_io 定义 id 。实际上,如果我们希望US_season_io 用作Season_io ,则不能为其分配 id 。诸如 has_facet (§39.3.1)之类的本地化设置操作依赖于实现相同概念的facet 由相同的 id 标识(§39.3)。
唯一值得关注的实现问题是,如果被要求输出一个无效的Season 该怎么办。当然,这种情况不应该发生。然而,对于简单的用户自定义类型,遇到无效值的情况并不少见,因此考虑这种可能性是合理的。我本可以抛出异常,但对于供人阅读的简单输出,通常为超出范围的值生成一个"超出范围"的表示形式会很有帮助。请注意,对于输入,错误处理策略由 >> 运算符负责,而对于输出,facet 函数to_str() 实现了错误处理策略。这样做是为了说明不同的设计方案。在"生产环境设计"中,facet 函数要么同时实现输入和输出的错误处理,要么只报告错误信息,以便**>>** 和**<<**运算符进行处理。
此 Season_io 设计依赖于派生类来提供特定本地化的字符串。另一种设计方案是让 Season_io 本身从特定于本地化的存储库中检索这些字符串(参见 §39.4.7)。至于是否可以只使用一个Season_io类,并将季节字符串作为构造函数参数传递给它,则留待后续研究。
39.3.3 使用 locale 和 facet ( Uses of locale s and facet s**)**
标准库中本地化的主要用途是用于 I/O 流中 。然而,本地化机制是一种通用且可扩展的机制,用于表示文化敏感信息 。messages 文化特征(§39.4.7)就是一个与 I/O 流无关的 facet 示例。iostream 库的扩展,甚至非基于流的 I/O 功能,都可能利用本地化设置。此外,用户还可以使用本地化设置来方便地组织任意的文化敏感信息。
由于locale/facet 机制的通用性,用户自定义facet 的可能性是无限的。可以表示为facet的内容包括日期、时区、电话号码、社会保障号码(个人识别号码)、产品代码、温度、通用(单位,值)对、邮政编码、服装尺码和国际标准书号 (ISBN)。
与其他强大的机制一样,使用facet 也应谨慎。能够用facet来表示的事物并不意味着它就是最佳的表示方式。在选择文化依赖关系的表示方法时,需要考虑的关键问题------一如既往------是各种决策如何影响编码难度、最终代码的可读性、最终程序的可维护性,以及最终 I/O 操作在时间和空间上的效率。
39.4 标准 facet ( Standard facet s**)**
在 <locale> 中,标准库提供了以下facet:
|----------|----------|----------------------------------------------------------------------------------------------------|---------|
| 标准facet (§iso.22.3.1.1.1) ||||
| collate | 字符串比较 | collate<C> | §39.4.1 |
| numeric | 数值格式化 | numpunct<C> num_get<C,In> num_put<C,Out> | §39.4.2 |
| monetary | 货币格式化 | moneypunct<C> moneypunct<C,International> money_get<C,In> money_put<C,Out> | §39.4.3 |
| time | 日期和时间格式化 | time_put<C,Out> time_put_byname<C,Out> time_get<C,In> | §39.4.4 |
| ctype | 字符分类 | ctype<C> codecvt<In,Ex,SS> codecvt_byname<In,Ex,SS> | §39.4.5 |
| messages | 消息检索 | messages<C> | §39.4.7 |
详情请参见相关小节。
从该表中实例化 facet 时,C 必须是字符类型(§36.1)。这些facet 保证为 char 或 wchar_t 类型定义。此外,ctype<C> 保证支持char16_t 和 char32_t 类型。如果需要使用标准 I/O 处理其他字符类型X ,则必须依赖特定于实现的facet 特化,或为 X 提供合适的facet 版本。例如,可能需要 codecvt<X,char,mbstate_t> (§39.4.6)来控制 X 和 char之间的转换。
International 可以是true 或false ;true 表示使用货币符号的三字符(加上零终止符)"international"表示(§39.4.3.1),例如 USD 和 BRL。
移位状态参数SS 用于表示多字节字符表示的移位状态(§39.4.6)。在**<cwchar>** 中,mbstate_t 定义为,表示可以出现在一个由实现所定义的支持多字节字符编码规则集中的任何转换状态。对于任意字符类型X ,mbstate_t 的等效项是char_traits<X>::state_type(§36.2.2)。
In 和Out 分别是输入迭代器和输出迭代器(§33.1.2,§33.1.4)。通过这些模板参数为**_put** 和 _get 语言特征提供参数,程序员可以提供访问非标准缓冲区的 facet (§39.4.2.2)。与iostream 关联的缓冲区是流缓冲区,因此为它们提供的迭代器是 ostreambuf_iterators (§38.6.3,§39.4.2.2)。因此,可以使用函数 failed() 进行错误处理(§38.6.3)。
每个标准facet 都有一个**_byname** 版本。F_byname facet 派生自facet F 。F_byname 提供与F 相同的接口,但它添加了一个构造函数,该构造函数接受一个字符串参数来命名locale (例如,参见 §39.4.1)。F_byname(name) 为locale(name) 中定义的F提供相应的语义。例如:
sort(v.begin(),v.end(),collate_byname{"da_DK"}); // sort using character comparison from "da_DK"
其思路是从程序执行环境中指定的一个命名locale (§39.2.1)中选择一个标准 facet 的版本。这意味着,与无需查询环境的构造函数相比,_byname 构造函数速度非常慢。构造一个locale ,然后访问其 facet ,几乎总是比在程序中多处使用**_byname** facet 更快。因此,通常的做法是从环境中读取一次 facet,然后重复使用主内存中的副本。例如:
locale dk {"da_DK"}; // read the Danish locale (including all of its facets) once
// then use the dk locale and its facets as needed
void f(vector<string>& v, const locale& loc)
{
const collate<char>& col {use_facet<collate<char>>(dk)};
const ctype<char>& ctyp {use_facet<ctype<char>>(dk)};
locale dk1 {loc,&col}; // use Danish string comparison
locale dk2 {dk1,&ctyp}; // use Danish character classification and string comparison
sort(v.begin(),v.end(),dk2);
// ...
}
此dk2本地化将使用丹麦语风格的字符串,但会保留数的默认约定。
类别的概念为操作locale 中的标准facet 提供了一种更简单的方法。例如,给定 dk 本地化设置,我们可以构建一个locale,该本地化设置按照丹麦语(比英语多三个元音)的规则读取和比较字符串,但保留 C++ 中使用数的语法:
locale dk_us(locale::classic(),dk,collate|ctype); // 丹麦字母 , 美国数
对各个标准facet 的介绍包含了更多facet 使用的示例。特别是,对collate 的讨论(§39.4.1)揭示了facet的许多常见结构特征。
标准facet 通常相互依赖。例如,num_put 依赖于numpunct 。只有深入了解各个 facet ,才能成功地混合搭配不同的 facet ,或者添加标准 facet 的新版本。换句话说,除了简单的操作(例如对 iostream 的 imbue() 和对 sort() 的 collat e ),locale机制并不适合新手直接使用。有关本地化设置的详细讨论,请参阅 Langer,2000。
单个语言特征的设计通常比较复杂。部分原因是这些语言特征必须反映库设计者无法控制的复杂文化习俗,部分原因是 C++ 标准库的功能必须与 C 标准库和各种平台特定标准的功能保持高度兼容。
在另一方面, locale 和 facet 提供的框架具有通用性和灵活性。 facet 可以设计成承载任何数据,并且facet 的操作可以根据这些数据提供任何所需的操作。如果新facet的行为没有受到过多的约定限制,那么它的设计可以做到简洁明了(§39.3.2)。
39.4.1 string 比较**(** string Comparison**)**
标准collate语言特征提供了比较字符数组的方法:
template<class C>
class collate : public locale::facet {
public:
using char_type = C;
using string_type = basic_string<C>;
explicit collate(size_t = 0);
int compare(const C ∗ b, const C ∗ e, const C ∗ b2, const C ∗ e2) const
{ return do_compare(b,e,b2,e2); }
long hash(const C ∗ b, const C ∗ e) const
{ return do_hash(b,e); }
string_type transform(const C ∗ b, const C ∗ e) const
{ return do_transform(b,e); }
static locale::id id; // facet identifier object ( § 39.2, § 39.3, § 39.3.1)
protected:
˜collate(); // note: protected destructor
virtual int do_compare(const C ∗ b, const C ∗ e, const C ∗ b2, const C ∗ e2) const;
virtual string_type do_transform(const C ∗ b, const C ∗ e) const;
virtual long do_hash(const C ∗ b, const C ∗ e) const;
};
这定义了两个接口:
• 面向 facet 用户的public接口。
• 面向派生 facet 实现者的protected接口。
构造函数参数指定是由locale 还是用户负责删除 facet 。默认值**(0)** 表示"让locale负责管理"(§39.3)。
所有标准库 facet 都共享一个共同的结构 ,因此关于一个facet的主要事实可以通过关键函数来概括:
|--------------------------------------------------------------------------------------------------------------|
| collate<C> facet (§iso.22.4.4.1) |
| int compare(const C ∗ b, const C ∗ e, const C ∗ b2, const C ∗ e2) const; |
| long hash(const C ∗ b, const C ∗ e) const; |
| string_type transform(const C ∗ b, const C ∗ e) const; |
要定义一个facet ,请使用 collat e 作为模式。要从标准模式派生,只需定义提供该facet 功能的关键函数的do_ ∗ 版本即可。为了提供足够的信息来编写重载的 do_ ∗ 函数,我们列出了函数的完整声明(而不是使用模式)。例如,请参见 §39.4.1.1。
hash() 函数会计算其输入字符串的哈希值 。显然,这对于构建哈希表非常有用。
transform() 函数生成一个字符串,该字符串与另一个经过 **transform()**转换的字符串进行比较,结果与直接比较这两个字符串的结果相同。即:
cf.compare(cf.transform(s),cf.transform(s2)) == cf.compare(s,s2)
**transform()**函数的目的是优化将一个字符串与多个其他字符串进行比较的代码。这在实现字符串集合中的搜索时非常有用。
compare() 函数根据特定collate定义的规则执行基本的字符串比较。它返回:
1------ 如果第一个字符串的字典序大于第二个字符串。
0------ 如果两个字符串相同。
-1------ 如果第二个字符串大于第一个字符串。
例如:
void f(const string& s1, const string& s2, const collate<char>& cmp)
{
const char ∗ cs1 {s1.data()}; // because compare() operates on char\[\]s
const char ∗ cs2 {s2.data()};
switch (cmp.compare(cs1,cs1+s1.siz e(),cs2,cs2+s2.size()) {
case 0: // identical strings according to cmp
// ...
break;
case −1: // s1 < s2
// ...
break;
case 1: // s1 > s2
// ...
break;
}
}
collate 成员函数比较的是 [b:e) 范围内的 C 字符,而不是 basic_string 或以0结尾的 C 风格字符串。特别地,数值为 0 的 C 字符会被视为普通字符,而不是终止符。
标准库 string 不是 locale 敏感的。即,它根据实现所用字符集的规则比较字符串(§6.2.3) 。此外,标准 string 没有提供直接指定比较标准的方法(第36章) 。要进行区分locale 比较,我们可以使用collate 的 compare() 函数。例如:
void f(const string& s1, const string& s2, const string& name)
{
bool b {s1==s2}; // compare using implementation ' s character set values
const char ∗ s1b {s1.data()}; // get start of data
const char ∗ s1e {s1.data()+s1.size()} // get end of data
const char ∗ s2b {s2.data()};
const char ∗ s2e {s2.data()+s2.size()}
using Col = collate<char>;
const Col& global {use_facet<Col>(locale{})}; // from the current global locale
int i0 {global.compare(s1b,s1e,s2b,s2e)};
const Col& my_coll {use_facet<Col>(locale{""})}; // from my preferred locale
int i1 {my_coll.compare(s1b,s1e ,s2b,s2e)};
const Col& n_coll {use_facet<Col>(locale{name})}; // from a named locale
int i2 {n_coll.compare(s1b,s1e,s2b,s2e)};
}
从符号学角度来看,通过locale 的operator() 函数间接使用 collat e 的 compare() 函数可能更方便(§39.2.2)。例如:
void f(const string& s1, const string& s2, const string& name)
{
int i0 = locale{}(s1,s2); // 使用当前全局 locale 进行比较
int i1 = locale{""}(s1,s2); // 使用我喜欢的 locale 进行比较
int i2 = locale{name}(s1,s2); // 使用命名 locale 进行比较
// ...
}
不难想象 i0 、i1 和 i2不同的情况。请看以下这段来自德语词典的单词序列:
Dialekt, Di ¨ at, dich, dichten, Dichtung
按照惯例,名词(仅名词)首字母大写,但字母顺序不区分大小写。
区分大小写的德语排序会将所有以 D 开头的单词排在 d 之前:
Dialekt, Di ¨ at, Dichtung, dich, dichten
ä ( 元音变音a ) 被视为"一种 a ",因此它排在 c 之前。然而,在大多数常用字符集中,ä 的数值大于 c 的数值。因此,int('c')<int('a'),基于数值的简单默认排序结果为:
Dialekt, Dichtung, Di ¨ at, dich, dichten
编写一个能够根据字典正确排序此序列的比较函数是一个有趣的练习。
39.4.1.1 命名 collate ( Named collate )
collat e_byname 是针对由构造函数字符串参数命名的locale 的 collat e 的一个版本:
template<class C>
class collate_byname : public collate<C> { // note: no id and no new functions
public:
typedef basic_string<C> string_type;
explicit collate_byname(const char ∗ , siz e_t r = 0); // construct from named locale
explicit collate_byname(const string&, size_t r = 0);
protected:
˜collate_byname(); // note: protected destructor
int do_compare(const C ∗ b, const C ∗ e, const C ∗ b2, const C ∗ e2) const override;
string_type do_transform(const C ∗ b, const C ∗ e) const override;
long do_hash(const C ∗ b, const C ∗ e) const override;
};
因此,可以使用 collat e_byname 从程序执行环境中的一个命名locale 中选取一个collat e (§39.4)。在执行环境中存储 facet 的一种显而易见的方法是将其作为数据存储在文件中。另一种灵活性较低的方法是将 facet 表示为程序文本和一个 _byname 语言特征中的数据。
39.4.2 数值格式化( NumericFormatting**)**
数值输出由 num_put 语言特征写入流缓冲区完成(§38.6)。相反,数值输入由 num_get 语言特征从流缓冲区读取完成。num_put 和 num_get 使用的格式由名为 numpunct 的"数值标点" facet 定义。
39.4.2.1 数值标点( Numeric Punctuation**)**
numpunct 语言特征定义了内置类型(例如 bool ,int 和 double)的 I/O 格式:
|------------------------------------|---------------------|
| numpunct<C> facet (§iso.22.4.6.3.1) ||
| C decimal_point() const; | 例如,'.' |
| C thousands_sep() const; | 例如,',' |
| string grouping() const; | 例如,"", 指的是"不分组" |
| string_type truename() const; | 例如,"true" |
| string_type falsename() const; | 例如,"false" |
grouping() 函数返回的字符串字符被读取为一系列小的整数值。每个数指定一个分组的位数。字符0 指定最右边的分组(最低有效位),字符 1 指定其左侧的分组,依此类推。因此,"\004\002\003" 表示像123-45-6789 这样的数(前提是使用"- "作为分隔符)。如有必要,分组模式中的最后一个数可以重复使用,因此**"\003"** 等效于**"\003\003\003"** 。分组最常见的用途是使大数更易于阅读。grouping() 和 thousands_sep() 函数定义了整数和浮点数整数部分的输入和输出格式。
我们可以从numpunct 派生出一种新的标点符号样式。例如,我可以定义语言特征 My_punct 来写入整数值,用空格将数分组为三位一组,并写入浮点值,使用欧式逗号作为"小数点":
class My_punct : public numpunct<char> {
public:
explicit My_punct(size_t r = 0) :numpunct<char>(r) { }
protected:
char do_decimal_point() const override { return ','; } // comma
char do_thousands_sep() const override { return '_'; } // underscore
string do_grouping() const override { return "\003"; } // 3-digit groups
};
void f()
{
cout << "style A: " << 12345678
<< " ∗∗∗ " << 1234567.8
<< " ∗∗∗ " << fixed << 1234567.8 << '\n';
cout << defaultfloat; // reset floating for mat
locale loc(locale(),new My_punct);
cout.imbue(loc);
cout << "style B: " << 12345678
<< " ∗∗∗ " << 1234567.8
<< " ∗∗∗ " << fixed << 1234567.8 << '\n';
}
这产生:
style A: 12345678 ∗∗∗ 1.23457e+06 ∗∗∗ 1234567.800000
style B: 12_345_678 ∗∗∗ 1_234_567,800000 ∗∗∗ 1_234_567,800000
请注意,imbue() 函数会将参数的副本存储在其流中。因此,即使原locale 副本已被销毁,流仍然可以依赖于已注入的locale 。如果 iostream 的 boolalpha 标志已设置(参见 §38.4.5.1),则truename() 和 falsename() 返回的字符串分别用于表示true 和false ;否则,分别使用 1 和0。
标准库提供了 numpunct 的一个**_byname**版本(§39.4,§39.4.1):
template<class C>
class numpunct_byname : public numpunct<C> {
// ...
};
39.4.2.2 数值输出( Numeric Output**)**
当写入流缓冲区时(§38.6),ostream 依赖于 num_put语言特征:
|--------------------------------------------------------------------------------------------------------|
| num_put<C,Out=ostreambuf_iterator<C>> facet (§iso.22.4.2.2) 将值v 放入数据流s 中缓冲区位置b |
| Out put(Out b, ios_base& s, C fill, bool v) const; |
| Out put(Out b, ios_base& s, C fill, long v) const; |
| Out put(Out b, ios_base& s, C fill, long long v) const; |
| Out put(Out b, ios_base& s, C fill, unsigned long v) const; |
| Out put(Out b, ios_base& s, C fill, unsigned long long v) const; |
| Out put(Out b, ios_base& s, C fill, double v) const; |
| Out put(Out b, ios_base& s, C fill, long double v) const; |
| Out put(Out b, ios_base& s, C fill, const void ∗ v) const; |
**put()**的值是指向写入的最后一个字符位置之后一位的迭代器。
num_put 的默认特化(用于访问字符的迭代器类型为 ostreambuf_iterator<C> )是标准locale 的一部分(§39.4)。要在其他地方使用num_put 写入数据,我们必须定义一个合适的特化。例如,以下是一个非常简单的用于写入字符串的num_put示例:
template<class C>
class String_numput : public num_put<C,typename basic_string<C>::iterator> {
public:
String_numput() :num_put<C,typename basic_string<C>::iterator>{1} { }
};
我并不打算让 String_numput 进入locale,所以我使用了构造函数参数来保留其常规的生命周期规则。预期用法大致如下:
void f(int i, string& s, int pos) // format i into s starting at pos
{
String_numput<char> f;
f.put(s.begin()+pos,cout,' ',i); // format i into s; use cout ' s for matting rules
}
ios_base 参数(此处为 cout )提供有关格式化状态和locale的信息。例如:
void test(iostream& io)
{
locale loc = io.getloc();
wchar_t wc = use_facet<ctype<char>>(loc).widen(c); // char to C conversion
string s = use_facet<numpunct<char>>(loc).decimal_point(); // default: ' . '
string false_name = use_facet<numpunct<char>>(loc).falsename(); // default: "false"
}
像 num_put<char> 这样的标准 facet 通常通过标准的 I/O 流函数隐式使用。因此,大多数程序员无需了解它。然而,标准库函数对这些 facet 的使用方式很有意思,因为它们展示了 I/O 流的工作原理以及如何使用 facet。一如既往,标准库提供了许多有趣的编程技巧示例。
使用 num_put ,ostream的实现者可能会这样写:
template<class C, class Tr>
basic_ostream<C,Tr>& basic_ostream<C,Tr>::operator<<(double d)
{
sentry guard( ∗ this); // see § 38.4.1
if (!guard) return ∗ this;
try {
if (use_facet<num_put<C,Tr>>(g etloc()).put( ∗ this, ∗ this,this −>fill(),d).failed())
setstate(badbit);
}
catch (...) {
handle_ioexception( ∗ this);
}
return ∗ this;
}
这里涉及很多内容。哨兵机制确保所有前缀和后缀操作都已执行(§38.4.1)。我们通过调用其成员函数 getloc() 获取 ostream 的locale (§38.4.5.1)。我们使用 use_facet 从该locale 中提取 num_put 值(§39.3.1)。完成这些步骤后,我们调用相应的 put() 函数来执行实际操作。ostreambuf_iterator 可以从 ostream 构造(§38.6.3),并且 ostream 可以隐式转换为其基类ios_base (§38.4.4),因此 **put()**的前两个参数很容易提供。
调用 put() 函数会返回其输出迭代器参数。该输出迭代器取自 basic_ostream ,因此它是一个 ostreambuf_iterator 。因此,我们可以使用 **failed()**函数(参见 §38.6.3)来检测操作是否失败,并允许我们相应地设置流状态。
我没有使用 has_facet ,因为标准 facet (§39.4)保证存在于每个locale 中。如果违反此保证,则会抛出bad_cast异常(§39.3.1)。
put() 函数会调用虚函数 do_put() 。因此,可能会执行用户自定义代码,并且 operator<<() 必须准备好处理重载 do_put() 函数时抛出的异常。此外,某些字符类型可能不存在num_put 函数,因此 use_facet() 可能会抛出 bad_cast 异常(§39.3.1)。对于内置类型(例如 double ),<< 的行为由 C++ 标准定义。因此,问题不在于 handle_ioexception() 应该做什么,而在于它应该如何执行标准规定的操作。如果此ostream 的异常状态中设置了badbit (§38.3),则异常会被重新抛出。否则,异常的处理方式是设置流状态并继续执行。无论哪种情况,都必须在流状态中设置 badbit(§38.4.5.1):
template<class C, class Tr>
void handle_ioexception(basic_ostream<C,Tr>& s)// called from catch-clause
{
if (s.exceptions()&ios_base::badbit) {
try {
s.setstate(ios_base::badbit); // might throw basic_ios::failure
}
catch(...) {
// ... do nothing ...
}
throw; // re-throw
}
s.setstate(ios_base::badbit);
}
需要使用 try 代码块,因为 setstate() 可能会抛出 basic_ios::failure 异常(§38.3,§38.4.5.1)。但是,如果在异常状态下设置了badbit ,则 operator<<() 必须重新抛出导致调用 handle_ioexception() 的异常(而不是简单地抛出 basic_ios::failure异常)。
对于内置类型(例如 double ),<< 必须通过直接写入流缓冲区来实现。而对于用户自定义类型的 <<,我们通常可以通过将用户自定义类型的输出用现有类型的输出来表示(§39.3.2),从而避免由此产生的复杂性。
39.4.2.3 数值输入( Numeric Input**)**
从流缓冲区读取数据时(§38.6),istream 依赖于 num_get 语言特征:
|-----------------------------------------------------------------------------------------------------------------------------------|
| num_g et<In = istreambuf_iterator<C>> facet (§iso.22.4.2.1) 将**[b:e)** 读取到 v 中,使用来自s 的格式化规则,并通过设置 r报告错误。 |
| In get(In b, In e, ios_base& s, ios_base::iostate& r, bool& v) const; |
| In get(In b, In e, ios_base& s, ios_base::iostate& r, long& v) const; |
| In get(In b, In e, ios_base& s, ios_base::iostate& r, long long& v) const; |
| In get(In b, In e, ios_base& s, ios_base::iostate& r, unsigned short& v) const; |
| In get(In b, In e, ios_base& s, ios_base::iostate& r, unsigned int& v) const; |
| In get(In b, In e, ios_base& s, ios_base::iostate& r, unsigned long& v) const; |
| In get(In b, In e, ios_base& s, ios_base::iostate& r, unsigned long long& v) const; |
| In get(In b, In e, ios_base& s, ios_base::iostate& r, float& v) const; |
| In get(In b, In e, ios_base& s, ios_base::iostate& r, double& v) const; |
| In get(In b, In e, ios_base& s, ios_base::iostate& r, long double& v) const; |
| In get(In b, In e, ios_base& s, ios_base::iostate& r, void ∗ & v) const; |
基本上,num_get 的组织结构与 num_put 类似(参见 §39.4.2.2)。由于它执行的是读取操作而非写入操作,因此**get()**需要一对输入迭代器,并且指定读取目标的参数是一个引用。
iostate 变量r 用于反映流的状态。如果无法读取所需类型的值,则r 中的 failbit 会设置;如果触及输入结束符,则 r 中的 eofbit 会设置。输入运算符将使用 r 来确定如何设置其流的状态。如果没有遇到错误,则读取的值将赋给 v ;否则,v保持不变。
哨兵机制用于确保流的前缀和后缀操作得到执行(§38.4.1)。具体来说,哨兵机制用于确保我们仅在流处于良好状态时才尝试读取数据。例如,istream 的实现者可能会这样写:
template<class C, class Tr>
basic_istream<C,Tr>& basic_istream<C,Tr>::operator>>(double& d)
{
sentry guard( ∗ this); // see § 38.4.1
if (!guard) return ∗ this;
iostate state = 0; // good
istreambuf_iterator<C,Tr> eos;
try {
double dd;
use_facet<num_g et<C,Tr>>(g etloc()).get( ∗ this,eos, ∗ this,state,dd);
if (state==0 || state==eofbit) d = dd; // set value only if get() succeeded
setstate(state);
}
catch (...) {
handle_ioexception( ∗ this); // see § 39.4.2.2
}
return ∗ this;
}
我已注意,除非读取操作成功,否则不会修改 **>>**的目标。遗憾的是,这无法保证所有输入操作都能成功。
如果发生错误,则为istream 启用的异常将由 **setstate()**抛出(§38.3)。
通过定义一个numpunct (例如 §39.4.2.1 中的 My_punct),我们可以使用非标准标点符号进行阅读。例如:
void f()
{
cout << "style A: "
int i1;
double d1;
cin >> i1 >> d1; // read using standard ''12345678'' for mat
locale loc(locale::classic(),new My_punct);
cin.imbue(loc);
cout << "style B: "
int i2;
double d2;
cin >> i1 >> d2; // read using the ''12_345_678'' for mat
}
如果我们想要读取非常特殊的数字格式,就必须重写 do_get() 函数。例如,我们可以定义一个 num_get函数来读取罗马数字,例如 XXI 和 MM 。
39.4.3 货币格式化( Money Formatting**)**
币值的格式在技术上与"普通"数的格式类似(§39.4.2)。然而,币值的呈现方式对文化差异更为敏感。例如,负数(损失、借方),如 -1.25,在某些情况下应以括号括起来的(正)数表示:(1.25)。同样,在某些情况下,会使用颜色来帮助识别负数。
没有标准的"货币类型" 。**相反,货币属性旨在明确地用于程序员知道代表货币金额的数值。**例如:
struct Money { // simple type to hold a monetary amount
using Value = long long; // for currencies that have suffered inflation
Value amount;
};
// ...
void f(long int i)
{
cout << "value= " << i << " amount= " << Money{i} << '\n';
}
货币方面的任务是使编写 Money 的输出运算符变得相对容易,以便根据本地约定打印金额(参见 §39.4.3.2)。输出将根据 cout 的locale而变化。可能的输出包括:
value= 1234567 amount= $12345.67
value= 1234567 amount= 12345,67 DKK
value= 1234567 amount= CAD 12345,67
value= −1234567 amount= $−12345.67
value= −1234567 amount= −€12345.67
value= −1234567 amount= (CHF12345,67)
对于货币而言,精确到最小货币单位通常至关重要。因此,我采用了常见的约定,即用整数值表示分(便士、厄尔、菲尔、分等)的数量,而不是美元(英镑、克朗、第纳尔、欧元等)的数量。moneypunct 的 frac_digits() 函数(§39.4.3.1)支持此约定。同样,"小数点"的显示方式由**decimal_point()**函数定义。
money_get 和money_put 这两个facet 提供了根据 money_base语言特征定义的格式执行 I/O 的函数。
简单的Money 类型可用于控制 I/O 格式或存储货币值。在前一种情况下,我们会在写入之前将用于存储货币值的(其他)类型的值强制转换为Money 类型;在将值读取到 Money 变量之前,我们会先将其转换为其他类型。始终使用 Money 类型存储货币值可以降低出错的概率;这样,我们就不会忘记在写入之前将值强制转换为 Money 类型,也不会因为尝试以不区分locale 的方式读取货币值而导致输入错误。然而,在并非为此设计的系统中引入 Money 类型可能并不可行。在这种情况下,必须对读写操作应用 Money 类型转换(强制转换)。
39.4.3.1 货币标点( Money Punctuation**)**
控制货币金额呈现的facet 的moneypunct 自然类似于控制普通数的facet 的 numpunct(§39.4.2.1):
class money_base {
public:
enum part { // par ts of value layout
none, space , symbol, sign, value
};
struct pattern { // layout specification
char field4;
};
};
template<class C, bool International = false>
class moneypunct : public locale::facet, public money_base {
public:
using char_type = C;
using string_type = basic_string<C>;
// ...
};
moneypunct成员函数定义了货币输入和输出的布局:
|---------------------------------------------|------------------------------------------------------------|
| moneypunct<C,International>> facet (§iso.22.4.6.3) ||
| C decimal_point() const; | 例如,'.' |
| C thousands_sep() const; | 例如,',' |
| string grouping() const; | 例如,"" 指的是"不分组" |
| string_type curr_symbol() const; | 例如,"$" |
| string_type positive_sign() const; | 例如,"" |
| string_type negative_sign() const; | 例如," −" |
| int frac_digits() const; | "." 之后的数字数量,例如,2 |
| pattern pos_format() const; | symbol , space , sign , none , 或 value |
| pattern neg_format() const; | symbol , space , sign , none , 或 value |
| static const bool intl = International; | 使用三个字母的国际缩写 |
moneypunct 提供的设施主要供 money_put 和money_get 语言特征(§39.4.3.2,§39.4.3.3)的实施者使用。
moneypunct 的**_byname** 版本(§39.4,§39.4.1)如下:
template<class C, bool Intl = false>
class moneypunct_byname : public moneypunct<C, Intl> {
// ...
};
decimal_point() 、thousands_sep() 和 grouping() 成员的行为与numpunct 中的行为相同。
curr_symbol() 、positive_sign() 和 negative_sign() 成员分别返回用于表示货币符号(例如 $ 、¥ 、INR 、DKK )、加号和减号的字符串。如果 International 模板参数为true ,则intl 成员也为true ,并且将使用货币符号的"国际"表示形式。这种"国际"表示形式是一个四字符的 C 风格字符串。例如:
"USD"
"DKK"
"EUR"
最后一个(不可见)字符是终止符零。三字母货币标识符由 ISO-4217 标准定义。当International 设置为false 时,可以使用"本地"货币符号,例如**$** 、£ 和 ¥ 。
pos_format() 或 neg_format() 返回的模式由四部分组成,分别定义了数值、货币符号、正负号和空格出现的顺序。大多数常见格式都可以用这种简单的模式概念轻松表示。例如:
+$ 123.45 // { sign, symbol, space, value } where positive_sign() returns "+"
$+123.45 // { symbol, sign, value, none } where positive_sign() returns "+"
$123.45 // { symbol, sign, value, none } where positive_sign() returns ""
$123.45 − //{ symbol, value, sign, none }
−123.45 DKK // { sign, value, space, symbol }
($123.45) // { sign, symbol, value, none } where negative_sign() returns "()"
(123.45DKK) // { sign, value, symbol, none } where negative_sign() returns "()"
使用括号表示负数的方法是让 next_sign() 函数返回一个包含两个字符 () 的字符串。符号字符串的第一个字符位于模式中sign 出现的位置,符号字符串的其余部分则位于模式中所有其他部分之后。此功能最常见的用途是表示金融界使用括号表示负数的惯例,但它还有其他用途。例如:
−$123.45 //{ sign, symbol, value, none } where negative_sign() returns " − "
∗ $123.45 silly // { sign, symbol, value, none } where negative_sign() returns "* silly"
sign 、value 和 symbol 这三个值在模式中必须各出现一次。剩余的值可以是 space 或none 。在 space 出现的地方,则表示中至少可以出现一个也可能出现多个空格字符。在none 出现的地方,在表示中可以出现一个或多个空白字符(模式末尾除外)。
请注意,这些严格的规则禁止了一些看似合理的模式:
pattern pat = { sign, value , none , none }; // error : no symbol
frac_digits() 函数标识小数点的位置。通常,货币金额以最小货币单位表示(§39.4.3)。该单位通常是主要单位的百分之一(例如,¢ 是 $ 的百分之一),因此 frac_digits() 通常为 2 。
以下是一个定义为 facet 的简单格式:
class My_money_io : public moneypunct<char,true> {
public:
explicit My_money_io(siz e_t r = 0) :moneypunct<char,true>(r) { }
char_type do_decimal_point() const { return '.'; }
char_type do_thousands_sep() const { return ','; }
string do_grouping() const { return "\003\003\003"; }
string_type do_curr_symbol() const { return "USD "; }
string_type do_positive_sign() const { return ""; }
string_type do_negative_sign() const { return "()"; }
int do_frac_digits() const { return 2; } // two digits after decimal point
pattern do_pos_format() const { return pat; }
pattern do_neg_format() const { return pat; }
private:
static const pattern pat;
};
const pattern My_money_io::pat { sign, symbol, value , none };
39.4.3.2 货币输出( Money Output**)**
money_put 语言特征根据moneypunct 指定的格式写入货币金额。具体来说,money_put 提供 put() 函数,将格式合适的字符表示形式放入流的流缓冲区中:
|----------------------------------------------------------------------------------------------------|
| money_put<C,Out = ostreambuf_iterator<C>> facet (§iso.22.4.6.2) 将值 v 放入缓冲区位置 b |
| Out put(Out b, bool intl, ios_base& s, C fill, long double v) const; |
| Out put(Out b, bool intl, ios_base& s, C fill, const string_type& v) const; |
intl 参数表示是使用标准的四字符"国际"货币符号还是"本地"符号(§39.4.3.1)。
已知 money_put ,我们可以为Money 定义一个输出运算符(§39.4.3):
ostream& operator<<(ostream& s, Money m)
{
ostream::sentry guard(s); //see § 38.4.1
if (!guard) return s;
try {
const money_put<char>& f = use_facet<money_put<char>>(s.g etloc());
if (m==static_cast<long long>(m)) { // m can be represented as a long long
if (f.put(s,true ,s,s.fill(),m).failed())
s.setstate(ios_base::badbit);
}
else {
ostringstream v;
v << m; // convert to string representation
if (f.put(s,true ,s,s.fill(),v.str()).failed())
s.setstate(ios_base::badbit);
}
}
catch (...) {
handle_ioexception(s); // see § 39.4.2.2
}
return s;
}
如果long long 类型的值精度不足以精确表示货币值,我会将该值转换为字符串表示形式,并使用接受字符串的 put() 函数输出该字符串。
39.4.3.3 货币输入( Money Input**)**
money_get 语言特征根据moneypunct 指定的格式读取货币金额。具体来说,money_get 提供 get() 函数,用于从流的流缓冲区中提取格式合适的字符表示:
|--------------------------------------------------------------------------------------------------------------------------------------|
| money_g et<C,In = istreambuf_iterator<C>> facet (§iso.22.4.6.1) 将**[b:e)** 读取到v 中,使用来自s 的格式化规则,并通过设置r 报告错误。 |
| In get(In b, In e, bool intl, ios_base& s, ios_base::iostate& r, long double& v) const; |
| In get(In b, In e, bool intl, ios_base& s, ios_base::iostate& r, string_type& v) const; |
良定义的money_get 和 money_put 语言特征对将提供可无错误、无信息丢失地读取的输出格式。例如:
int main()
{
Money m;
while (cin>>m)
cout << m << "\n";
}
这个简单程序的输出应该可以作为其输入。此外,给定第一次运行的输出,第二次运行的输出应该与第一次运行的输出完全相同。
Money 类型的一个合理输入运算符是:
istream& operator>>(istream& s, Money& m)
{
istream::sentry guard(s); // see io.sentr y
if (guard) try {
ios_base::iostate state = 0; // good
istreambuf_iterator<char> eos;
string str;
use_facet<money_g et<char>>(s.g etloc()).get(s,eos,true,state,str);
if (state==0 || state==ios_base::eofbit) { // set value only if get() succeeded
long long i = stoll(str); // § 36.3.5
if (errno==ERANGE) {
state |= ios_base::failbit;
}
else {
m = i; // set value only if conversion to long long succeeded
}
s.setstate(state);
}
}
catch (...) {
handle_ioexception(s); // see § 39.4.2.2
}
return s;
}
我使用 get() 函数将数据读取到 string 中,因为先读取到 double 类型再转换为 long long 类型可能会导致精度损失。
long double 类型能够精确表示的最大值可能小于long long 类型能够表示的最大值。
39.4.4 日期和时间格式化( Date and Time Formatting**)**
日期和时间格式由 time_get<C,In> 和 time_put<C,Out> 控制。使用的日期和时间表示形式为 tm (§43.6)。
39.4.4.1 time_put
time_put 语言特征接受一个表示为 tm 的时间点,并使用 strftime() (§43.6) 或等效函数生成表示该时间点的字符序列。
|------------------------------------------------------------------------------------------------------------------|
| time_put<C,Out = ostreambuf_iterator<C>> facet (§iso.22.4.5.1) |
| Out put(Out s, ios_base& f, C fill, const tm ∗ pt, const C ∗ b, const C ∗ e) const; |
| Out put(Out s, ios_base& f, C fill, const tm ∗ pt, char format, char mod = 0) const; |
| Out do_put(Out s, ios_base& ib, const tm ∗ pt, char format, char mod) const; |
调用 s=put(s,ib,fill,pt,b,e) 将**b:e** 复制到输出流 s 。对于strftime() 中的每一个格式化字符 x (可选修饰符为 mod ),它会调用 do_put(s,ib,pt,x,mod) 。修饰符的可能值为 0 (默认值,表示"无")、E 或 O 。重写函数 p=do_put(s,ib,pt,x,mod) 会将 *pt 的相应部分格式化到 s 中,并返回一个指向 s 中最后一个写入字符之后位置的值。
标准库提供了 messages 的一个 _ byname 版本(§39.4,§39.4.1):
template<class C, class Out = ostreambuf_iterator<C>>
class time_put_byname : public time_put<C,Out>
{
// ...
};
39.4.4.2 time_get
基本思路是,get_time 可以使用相同的 strftime() 格式(§43.6)读取 put_time 生成的内容:
class time_base {
public:
enum dateorder {
no_order, // meaning mdy
dmy, //meaning "%d%m%y"
mdy, //meaning "%m%d%y"
ymd, // meaning "%y%m%d"
ydm // meaning "%y%d%m"
};
};
template<class C, class In = istreambuf_iterator<C>>
class time_get : public locale::facet, public time_base {
public:
using char_type = C;
using iter_type = In;
// ...
}
除了按格式读取,还有一些操作用于检查 dateorder 以及读取日期和时间表示的特定部分,例如 weekday 和 monthname :
|----------------------------------------------------------------------------------------------------------------------------|
| time_get<C,In> facet (§iso.22.4.5.1) 从 [b:e) 读取到 ∗ pt |
| dateorder do_date_order() const; |
| In get_time(In b, In e, ios_base& ib, ios_base::iostate& err, tm ∗ pt) const; |
| In get_date(In b, In e, ios_base& ib, ios_base::iostate& err, tm ∗ pt) const; |
| In get_weekday(In b, In e, ios_base& ib, ios_base::iostate& err, tm ∗ pt) const; |
| In get_monthname(In b, In e, ios_base& ib, ios_base::iostate& err, tm ∗ pt) const; |
| In get_year(In b, In e, ios_base& ib, ios_base::iostate& err, tm ∗ pt) const; |
| In get(In b, In e, ios_base& ib, ios_base::iostate& err, tm ∗ pt, char format, char mod) const; |
| In get(In b, In e, ios_base& ib, ios_base::iostate& err, tm ∗ pt, char format) const; |
| In get(In b, In e, ios_base& ib, ios_base::iostate& err, tm ∗ pt, C ∗ fmtb, C ∗ fmte) const; |
get_ ∗ () 函数从 [b:e) 读取内容到**∗pt** ,从 b 获取 locale ,并在出错时设置 err 。它返回一个指向 [b:e) 中第一个未读取字符的迭代器。
调用 p=get(b,e,ib,err,pt,format,mod) 会读取格式字符 format 和修饰符字符 mod 指定的值,具体由 strftime() 函数指定。如果未指定 mod ,则使用mod==0 。
调用 get(b,e ,ib,err,pt,fmtb,fmtb) 时,使用以字符串形式呈现的strftime() 格式(例如 [fmtb:fmte )。此重载以及带有默认修饰符的重载都没有 do_get() 接口。相反,它们是通过对第一个 get() 调用do_get() 来实现的。
时间和日期 facet 最显而易见的用途是为 Date 类提供 locale 相关的 I/O 。考虑一下 §16.3 中 Date 类的一个变体:
class Date {
public:
explicit Date(int d ={}, Month m ={}, int year ={});
// ...
string to_string(const locale& = locale()) const;
};
istream& operator>>(istream& is, Date& d);
ostream& operator<<(ostream& os, Date d);
Date::to_string() 使用 stringstream 生成特定locale() 的string (§38.2.2):
string Date::to_string(const locale& loc) const
{
ostringstream os;
os.imbue(loc);
return os << ∗ this;
}
已经 to_string() 函数,输出运算符非常简单:
ostream& operator<<(ostream& os, Date d)
{
return os<<to_string(d,os.getloc());
}
输入操作符需要注意状态:
istream& operator>>(istream& is, Date& d)
{
if (istream::sentry guard{is}) {
ios_base::iostate err = goodbit;
struct tm t;
use_facet<time_get<char>>(is.g etloc()).get_date(is,0,is,err,&t); // read into t
if (!err) {
Month m = static_cast<Month>(t.tm_mon+1);
d = Date(t.tm_day,m,t.tm_year+1900);
}
is.setstate(err);
}
return is;
}
需要 +1900 ,因为 1900 年是 tm 的元年(§43.6)。
标准库提供了messages 的一个**_byname** 版本(§39.4, §39.4.1):
template<class C, class In = istreambuf_iterator<C>>
class time_get_byname : public time_get<C, In> {
// ...
};
39.4.5 字符分类( Character Classification**)**
从输入中读取字符时,通常需要对其进行分类才能理解读取的内容。例如,要读取一个数,输入程序需要知道哪些字母代表数字。类似地,§10.2.2 展示了如何使用标准字符分类函数来解析输入。
字符分类自然取决于所使用的字母表。因此,我们提供了一个语言特征类型 ctype 来表示特定 locale 中的字符分类。
字符类由一个名为mask 的枚举描述:
class ctype_base {
public:
enum mask { // the actual values are implementation-defined
space = 1, // whitespace (in "C" locale: ' ' , ' \n ' , ' \t ' , ...)
print = 1<<1, // printing characters
cntrl = 1<<2, // control characters
upper = 1<<3, // uppercase characters
lower = 1<<4, // lowercase characters
alpha = 1<<5, // alphabetic characters
digit = 1<<6, // decimal digits
punct = 1<<7, // punctuation characters
xdigit = 1<<8, // hexadecimal digits
blank = 1 << 9; // space and horizontal tab
alnum=alpha|digit, // alphanumer ic characters
graph=alnum|punct
};
};
template<class C>
class ctype : public locale::facet, public ctype_base {
public:
using char_type = C;
// ...
};
此 mask 不依赖于特定的字符类型。因此,此枚举被放置在(非模板)基类中。
显然,mask 反映了传统的 C 和 C++ 分类(§36.2.1)。然而,对于不同的字符集,不同的字符值属于不同的类别。例如,在 ASCII 字符集中,整数值 125 代表字符"}",这是一个标点符号字符(punct )。但是,在丹麦语字符集中,125 代表元音字母**"** å " ,在丹麦语 locale 中,该字母必须归类为 alpha 。
这种分类称为"掩码",因为传统的、针对小型字符集的高效字符分类实现方法是使用一个表格,其中每一个条目包含表示分类的位。例如:
table'P' == upper|alpha
table'a' == lower|alpha|xdigit
table'1' == digit|xdigit
table' ' == space|blank
已知该实现,如果字符c 是m ,则 tablec&m 为非零值,否则为0 。
ctype 语言特征的定义如下:
|------------------------------------------------------------------------------------------------------------|
| ctype<C> facet (§iso.22.4.1.1) |
| bool is(mask m, C c) const; |
| const C ∗ is(const C ∗ b, const C ∗ e, mask ∗ v) const; |
| const C ∗ scan_is(mask m, const C ∗ b, const C ∗ e) const; |
| const C ∗ scan_not(mask m, const C ∗ b, const C ∗ e) const; |
| C toupper(C c) const; |
| const C ∗ toupper(C ∗ b, const C ∗ e) const; |
| C tolower(C c) const; |
| const C ∗ tolower(C ∗ b, const C ∗ e) const; |
| C widen(C c) const; |
| const char ∗ widen(const char ∗ b, const char ∗ e, C ∗ b2) const; |
| char narrow(C c, char def) const; |
| const C ∗ narrow(const C ∗ b, const C ∗ e, char def, char ∗ b2) const; |
调用is(m,c) 来测试字符 c 是否属于分类 m 。例如:
int count_spaces(const string& s, const locale& loc)
{
const ctype<char>& ct = use_facet<ctype<char>>(loc);
int i = 0;
for(auto p = s.begin(); p!=s.end(); ++p)
if (ct.is(ctype_base::space, ∗ p)) //whitespace as defined by ct
++i;
return i;
}
请注意,也可以使用 is() 函数来检查字符是否属于多个分类之一。例如:
ct.is(ctype_base::space|ctype_base::punct,c); // c 是 ct 中的空白字符或标点吗 ?
调用is(b,e,v) 确定 [b:e) 中每一个字符的分类,并将其放置在数组 v 中的相应位置。
调用 scan_is(m,b,e) 返回指向集合 [b:e) 中第一个为 m 的字符的指针。如果没有字符被判定为 m ,则返回 e 。与标准 facet 一样,公共成员函数是通过调用其虚函数 do_ 来实现的。一个简单的实现可能是:
template<class C>
const C ∗ ctype<C>::do_scan_is(mask m, const C ∗ b, const C ∗ e) const
{
while (b!=e && !is(m, ∗ b))
++b;
return b;
}
调用scan_not(m,b,e) 返回指向 [b:e) 中第一个非m 字符的指针。如果所有字符都判定为 m ,则返回e 。
调用 toupper(c) 返回 c 的大写版本(若这样一个版本存在于所使用的字符集中),否则返回 c 本身。
调用 toupper(b,e) 将范围 [b:e) 内的每一个字符转换为大写,并返回 e 。一个简单的实现方式如下:
template<class C>
const C ∗ ctype<C>::to_upper(C ∗ b, const C ∗ e)
{
for (; b!=e; ++b)
∗ b = toupper( ∗ b);
return e;
}
tolower() 函数与toupper() 函数类似,区别在于它会将字母转换为小写。
调用widen(c) 将字符c 转换为其对应的 C 值。如果 C 字符集中有多个与 c 对应的字符,则标准规定应使用"最简单的合理转换"。例如:
wcout << use_facet<ctype<wchar_t>>(wcout.g etloc()).widen('e');
将输出与wcout 的locale 中的字符 e 相当的合理值。
使用widen() 函数也可以在不相关的字符表示形式(例如 ASCII 和 EBCDIC )之间进行转换。例如,假设存在一个 ebcdic 本地化:
char EBCDIC_e = use_facet<ctype<char>>(ebcdic).widen('e');
调用 widen(b,e,v) 会获取范围 [b:e) 中的每一个字符,并将加宽后的版本放置在数组 v 中的相应位置。
调用 narrow(ch,def) 会生成一个与来自C 类型中的字符 ch 对应的 char 值。同样,这里要使用"最简单的合理转换"。如果不存在对应的 char ,则返回 def 。
调用 narrow(b,e ,def,v) 会获取范围 [b:e) 中的每一个字符,并将缩减后的版本放置在数组 v 中的相应位置。
其基本思路是,narrow() 函数将较大的字符集转换为较小的字符集,而 widen() 函数执行相反的操作。对于较小字符集中的字符c ,我们期望:
c == narrow(widen(c),0) // 不保证
如果字符 c 表示的字符在"较小的字符集"中只有一种表示形式,那么上述说法成立。然而,这并不能保证。如果字符char 表示的字符不是较大字符集 (C) 所表示字符的子集,那么我们应该预料到,在以通用方式处理字符时,代码会出现异常和潜在问题。
类似地,对于来自较大字符集的字符 ch ,我们可能会期望:
widen(narrow(ch,def)) == ch || widen(narrow(ch,def)) == widen(def) // 不保证
然而,尽管这种情况很常见,但对于在大字符集中有多个值而在小字符集中只有一个值的字符,则无法保证这一点。例如,数字 7 在大字符集中通常有多种不同的表示形式。这通常是因为大字符集包含多个常规字符集作为子集,而较小字符集中的字符为了便于转换会被复制。
对于基本源字符集(§6.1.2)中的每一个字符,都保证
widen(narrow(ch_lit,0)) == ch_lit
例如:
widen(narrow('x',0)) == 'x'
narrow() 和 widen() 函数尽可能遵循字符分类。例如,如果 is(alpha,c) 为真,则只要alpha 是所用 locale 的一个有效掩码,则 is(alpha,narrow(c,'a')) 和 is(alpha,widen(c)) 也成立。
使用 ctype 语言特征的一个主要原因(特别是使用 narrow() 和 widen() 函数)是为了能够编写对任何字符集进行 I/O 和字符串操作的代码,也就是说,使代码能够通用化,不受字符集的限制。 这意味着 iostream 的实现严重依赖于这些功能。通过依赖 <iostream> 和 <string> ,用户可以避免大多数直接使用 ctype 语言特征的情况。
标准库提供了 ctype 的一个 _byname 版本:
template<class C>
class ctype_byname : public ctype<C> {
// ...
};
39.4.6 字符编码转换( Character Code Conversion**)**
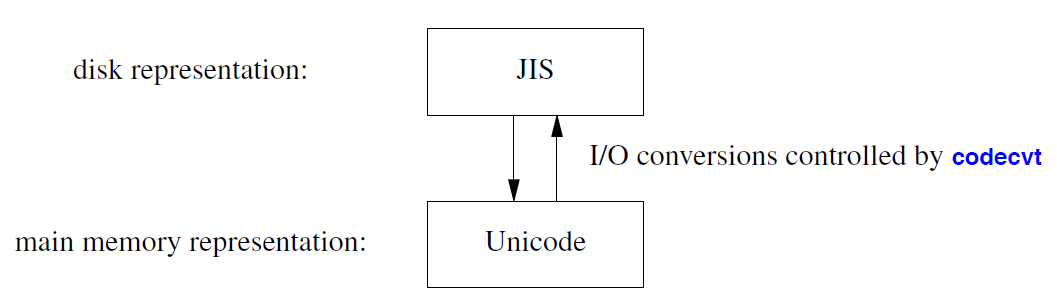
有时,存储在文件中的字符表示形式与这些字符在主内存中的预期表示形式不同 。例如,日文字符通常存储在其中的标识符("移位")标识已知字符序列属于四种常用字符集(汉字、片假名、平假名和罗马字)中的哪一种的文件中。这种方式略显繁琐,因为每一个字节的含义都取决于其"移位状态",但它可以节省内存,因为只有汉字需要超过 1 个字节的表示。在主内存中,如果使用多字节字符集表示这些字符,且每一个字符的大小相同,则更容易操作。此类字符(例如,Unicode 字符)通常放置在宽字符 (wchar_t ; §6.2.3) 中。因此, codecvt 语言特征提供了一种机制,用于在读取或写入字符时将其从一种表示形式转换为另一种表示形式。 例如:
这种代码转换机制足够通用,可以实现任意字符表示形式的转换。它允许我们使用合适的内部字符表示形式(存储在 char 、wchar_t 或其他类型中)编写一个程序,然后通过调整 iostream 使用的 locale 来接受各种输入字符流表示形式。另一种方法是修改程序本身,或者将输入输出文件转换为各种格式。
codecvt 语言特征提供在流缓冲区和外部存储之间移动字符时,不同字符集之间的转换:
class codecvt_base {
public:
enum result { // result indicators
ok, partial, error, noconv
};
};
template<class In, class Ex, class SS>
class codecvt : public locale::facet, public codecvt_base {
public:
using intern_type = In;
using extern_type = Ex;
using state_type = SS;
// ...
};
|-----------------------------------------------------------------------------------------------------------------------------------------------|
| codecvt<In,Ex,SS> facet (§iso.22.5) using CI = const In; using CE = const Ex; |
| result in(SS& st, CE ∗ b, CE ∗ e, CE ∗ & next, In ∗ b2, In ∗ e2, In ∗ & next2) const; |
| result out(SS& st, CI ∗ b, CI ∗ e, CI ∗ & next, Ex ∗ b2, Ex ∗ e2, Ex ∗ & next2) const; |
| result unshift(SS& st, Ex ∗ b, Ex ∗ e, Ex ∗ & next) const; |
| int encoding() const noexcept; |
| bool always_noconv() const noexcept; |
| int length(SS& st, CE ∗ b, CE ∗ e, siz e_t max) const; |
| int max_length() const noexcept; |
一个codecvt 语言特征由basic_filebuf (§38.2.1)用于读取或写入字符。一个basic_filebuf 从流的 locale (§38.1)中获取此 facet 。
State 模板参数是用于保存正在转换的流的移位状态的类型。State 还可以通过指定特化来标识不同的转换。后者非常有用,因为各种字符编码(字符集)的字符可以存储在相同类型的对象中。例如:
class JISstate { /* .. */ };
p = new codecvt<wchar_t,char,mbstate_t>; // standard char to wide char
q = new codecvt<wchar_t,char,JISstate>; // JIS to wide char
如果没有不同的状态参数,facet 就无法知道应该对字符流采用哪种编码。来自 <cwchar> 或**<wchar.h>** 的 mbstate_t 类型标识了系统在 char 和 wchar_t 之间的标准转换。
也可以将新的 codecvt 创建为派生类,并用名称进行标识。例如:
class JIScvt : public codecvt<wchar_t,char,mbstate_t> {
// ...
};
调用 in(st,b,e,next,b2,e2,next2) 会读取范围 [b:e) 中的每一个字符并尝试将其转换。如果一个字符被转换,in() 会将其转换后的形式写入范围 [b2:e2) 中的对应位置;否则,in() 会在该位置停止。返回时,in() 会将读取到的最后一个字符之后的位置(下一个要读取的字符)存储在next 中,并将写入到的最后一个字符之后的位置(下一个要写入的字符)存储在 next2 中。in() 返回的结果值标识了已完成的工作量。
|-------------|----------------------------|
| codecvt_base result (§iso.22.4.1.4) ||
| ok | 所有位于 [b:e) 范围内的字符均已转换 |
| partial | 并非 [b:e) 中的所有字符都被转换了。 |
| error | 无法转换某个字符 |
| noconv | 无需转换 |
请注意,部分转换并不一定意味着错误。可能是需要读取更多字符才能完成多字节字符的转换并写入,或者需要清空输出缓冲区以腾出空间容纳更多字符。
state_type 参数st 标识在调用 in() 函数开始时输入字符序列的状态。当外部字符表示使用移位状态时,这一点尤为重要。请注意,st 是一个(非常量)引用参数:在调用结束时,st 保存的是输入序列的移位状态。这使得程序员能够处理部分转换,并使用多次调用 in() 函数来转换一个较长的序列。
字符流必须以"中性"(未移位)状态开始和结束。通常,该状态为 state_type{} 。
调用 unshift(ss,b,e,next) 会检查字符串 st ,并根据需要将字符放入**[b:e)** 中,以使字符序列恢复到未移位状态。unshift() 的结果以及 next 的使用方式与 out() 相同。
调用 length(st,b,e,max) 返回 in() 可以从 b:e 转换的字符数。encoding() 的返回值含义如下:
-1 ------ 外部字符集的编码使用状态(例如,使用移位和取消移位字符序列)。
0 ------ 编码使用不同数量的字节来表示单个字符(例如,字符表示可能使用字节中的一个位来标识使用 1 个字节还是 2 个字节来表示该字符)。
n ------ 外部字符表示中的每一个字符都占用 n 个字节。
如果内部字符集和外部字符集之间不需要转换,则调用 always_noconv() 返回 true ,否则返回 false 。显然,always_noconv() == true 使得实现能够提供最高效的方案,即完全不调用转换函数。
调用 cvt.max_length() 返回 cvt.length(ss,p,q,n) 对于一组有效的参数可以返回的最大值。
我能想到的最简单的代码转换就是将输入转换为大写。因此,这已经是 codecvt 能提供服务的最简单的程度了:
class Cvt_to_upper : public codecvt<char,char,mbstate_t> { // 转换为大写
public:
explicit Cvt_to_upper(size_t r = 0) : codecvt(r) { }
protected:
// 读入外部表示 , 写入内部表示 :
result do_in(State& s,
const char ∗ from, const char ∗ from_end, const char ∗ & from_next,
char ∗ to, char ∗ to_end, char ∗ & to_next
) const override;
// read internal representation, write exter nal representation:
result do_out(State& s,
const char ∗ from, const char ∗ from_end, const char ∗ & from_next,
char ∗ to, char ∗ to_end, char ∗ & to_next
) const override;
result do_unshift(State&, E ∗ to, E ∗ to_end, E ∗ & to_next) const override { return ok; }
int do_encoding() const noexcept override { return 1; }
bool do_always_noconv() const noexcept override { return false; }
int do_length(const State&, const E ∗ from, const E ∗ from_end, size_t max) const override;
int do_max_length() const noexcept override; // maximum possible length()
};
codecvt<char,char,mbstate_t>::result
Cvt_to_upper::do_out(State& s,
const char ∗ from, const char ∗ from_end, const char ∗ & from_next,
char ∗ to, char ∗ to_end, char ∗ & to_next) const
{
return codecvt<char,char,mbstate_t>::do_out(s,from,from_end,from_next,to,to_end,to_next);
}
codecvt<char,char,mbstate_t>::result
Cvt_to_upper::do_in(State& s,
const char ∗ from, const char ∗ from_end, const char ∗ & from_next,
char ∗ to, char ∗ to_end, char ∗ & to_next) const
{
// ...
}
int main() // trivial test
{
locale ulocale(locale(), new Cvt_to_upper);
cin.imbue(ulocale);
for (char ch; cin>>ch; )
cout << ch;
}
标准库提供了 codecvt 的一个 _byname 版本(§39.4,§39.4.1):
template<class I, class E, class State>
class codecvt_byname : public codecvt<I,E,State> {
// ...
};
39.4.7 消息( Messages**)**
大多数最终用户很显然更喜欢使用他们的母语与程序交互。 然而,我们无法提供用于表达特定于 locale 的通用交互标准机制。因此,该库提供了一种简单的机制,用于维护一组特定于 locale 的字符串,程序员可以从中编写简单的消息。在本质上, messages 实现了一个简单的只读数据库:
class messages_base {
public:
using catalog = /* implementation-defined integer type */; // catalog identifier type
};
template<class C>
class messages : public locale::facet, public messages_base {
public:
using char_type = C;
using string_type = basic_string<C>;
// ...
};
消息接口相对简单:
|-----------------------------------------------------------------------------------------|
| messages<C> facet ( § iso.22.4.7.1) |
| catalog open(const string& s, const locale& loc) const; |
| string_type get(catalog cat, int set, int id, const basic_string<C>& def) const; |
| void close(catalog cat) const; |
调用 open(s,loc) 会为本地化loc 打开一个称为 s 的消息"目录"。一个目录是一组以特定于实现的方式组织的字符串,可通过 messages::get() 函数访问。如果无法打开名为 s 的目录,则返回负值。必须先打开目录,然后才能首次使用get() 函数。
调用close(cat) 关闭由cat 标识的目录,并释放与该目录关联的所有资源。
调用 get(cat,set,id,"foo") 会在目录 cat 中查找由 (set,id) 标识的消息。如果找到字符串,get() 返回该字符串;否则,get() 返回默认字符串( 此处为 string("foo") )。
以下是一个消息语言特征实现的示例,其中消息目录是一个"消息"集合的有序数组,"消息"是一个字符串:
struct Set {
vector<string> msgs;
};
struct Cat {
vector<Set> sets;
};
class My_messages : public messages<char> {
vector<Cat>& catalogs;
public:
explicit My_messages(siz e_t = 0) :catalogs{ ∗ new vector<Cat>} { }
catalog do_open(const string& s, const locale& loc) const; // open catalog s
string do_get(catalog cat, int s, int m, const string&) const; // get message (s,m) in cat
void do_close(catalog cat) const
{
if (catalogs.size()<=cat)
catalogs.erase(catalogs.begin()+cat);
}
˜My_messages() { delete &catalogs; }
};
所有 messages 的成员函数都是 const ,因此目录数据结构(vector<Set> )存储在 facet 之外。
选择消息时,需指定一个目录、该目录中的一个集合以及该集合中的一条消息字符串。提供一个字符串作为参数,用于在目录中未找到消息时作为默认结果。
string My_messages::do_get(catalog cat, int set, int id, const string& def) const
{
if (catalogs.size()<=cat)
return def;
Cat& c = catalogscat;
if (c.sets.size()<=set)
return def;
Set& s = c.setsset;
if (s.msgs.size()<=msg)
return def;
return s.msgsid;
}
打开目录涉及将磁盘上的文本表示读入Cat 结构。这里,我选择了一种易于读取的表示形式。集合由 <<< 和 >>> 分隔,每条消息都是一行文本:
messages<char>::catalog My_messages::do_open(const string& n, const locale& loc) const
{
string nn = n + locale().name();
ifstream f(nn.c_str());
if (!f) return −1;
catalogs.push_back(Cat{}); // make in-core catalog
Cat& c = catalogs.back();
for(string s; f>>s && s=="<<<"; ) { // read Set
c.sets.push_back(Set{});
Set& ss = c.sets.back();
while (getline(f,s) && s != ">>>") // read message
ss.msgs.push_back(s);
}
return catalogs.size() −1;
}
以下是一个简单用法:
int main()
// a trivial test
{
if (!has_facet<My_messages>(locale())) {
cerr << "no messages facet found in" << locale().name() << '\n';
exit(1);
}
const messages<char>& m = use_facet<My_messages>(locale());
extern string message_director y; // where I keep my messages
auto cat = m.open(message_director y,locale());
if (cat<0) {
cerr << "no catalog found\n";
exit(1);
}
cout << m.get(cat,0,0,"Missed again!") << endl;
cout << m.get(cat,1,2,"Missed again!") << endl;
cout << m.get(cat,1,3,"Missed again!") << endl;
cout << m.get(cat,3,0,"Missed again!") << endl;
}
若这个目录是:
<<<
hello
goodbye
>>>
<<<
yes
no
maybe
>>>
程序打印:
hello
maybe
Missed again!
Missed again!
39.4.7.1 使用来自其它 facet 的消息( Using Messages from Other facet s**)**
除了作为与用户通信时使用的与 locale 相关的字符串的存储库,message 还可以用于保存其他 facet 所需的字符串。例如,Season_io 语言特征(§39.3.2)可以这样编写:
class Season_io : public locale::facet {
const messages<char>& m; // message directory
messages_base::catalog cat; // message catalog
public:
class Missing_messages { };
Season_io(size_t i = 0)
: locale::facet(i),
m(use_facet<Season_messages>(locale())),
cat(m.open(message_director y,locale()))
{
if (cat<0)
throw Missing_messages();
}
˜Season_io() { } // to make it possible to destroy Season_io objects ( § 39.3)
const string& to_str(Season x) const; // string representation of x
bool from_str(const string& s, Season& x) const; // place Season corresponding to s in x
static locale::id id; // facet identifier object ( § 39.2, § 39.3, § 39.3.1)
};
locale::id Season_io::id; // define the identifier object
string Season_io::to_str(Season x) const
{
return m −>get(cat,0,x,"no−such−season");
}
bool Season_io::from_str(const string& s, Season& x) const
{
for (int i = Season::spring; i<=Season::winter; i++)
if (m −>get(cat,0,i,"no−such−season") == s) {
x = Season(i);
return true;
}
return false;
}
这种基于 messages 的解决方案与原始解决方案(§39.3.2)的不同之处在于,为新 locale 的 Season 字符串集的实现者需要能够将其添加到消息目录中。对于向执行环境添加新 locale 的人员来说,这很容易。但是,由于 messages 仅提供只读接口,因此添加新的季节名称集可能超出了应用程序员的能力范围。
标准库提供了 messages 的一个 _byname 版本(§39.4,§39.4.1):
template<class C>
class messages_byname : public messages<C> {
// ...
};
39.5 便捷接口( Convenience Interfaces**)**
除了简单地注入 I/O iostream 之外,locale 功能可能使用起来很复杂。因此,我们提供了便捷的接口来简化表示法并最大限度地减少错误。
39.5.1 字符分类( Character Classification**)**
ctype 语言特征最常见的用途是查询字符是否属于给定的分类。因此,我们提供了一组函数来实现这一目的:
|---------------------|----------------------------------------------------------|
| locale 敏感字符分类(§iso.22.3.3.1) ||
| isspace(c,loc) | c 是 loc 中的空格吗? |
| isblank(c,loc) | c 是loc 中的空格吗? |
| isprint(c,loc) | c 可打印吗? |
| iscntrl(c,loc) | c 是一个控制字符吗? |
| isupper(c,loc) | c 是一个大写字母吗? |
| islower(c,loc) | c 是一个小写字母吗? |
| isalpha(c,loc) | c 是一个字母吗? |
| isdigit(c,loc) | c 是一个十进制数吗? |
| ispunct(c,loc) | c 不是一个字母、数字、空白、或不可见控制字符吗? |
| isxdigit(c,loc) | c 是一个十六进制数字吗? |
| isalnum(c,loc) | isalpha(c) 或isdigit(c) |
| isgraph(c,loc) | isalpha(c) 或isdigit(c) 或ispunct(c) (注意:不是空格) |
这些功能使用 use_facet 可以轻松实现。例如:
template<class C>
inline bool isspace(C c, const locale& loc)
{
return use_facet<ctype<C>>(loc).is(space,c);
}
这些函数的单参数版本(§36.2.1)使用当前的 C 全局区域本地化。除了极少数 C 全局本地化与 C++ 全局本地化不同的情况(§39.2.1),我们可以将单参数版本视为应用于 locale() 函数的双参数版本。例如:
inline int isspace(int i)
{
return isspace(i,locale()); // almost
}
39.5.2 字符转换( Character Conversions**)**
大小写转换可能与 locale 有关:
|------------------------|---------------------------------------------|
| 字符转换**(§iso.22.3.3.2.1)** ||
| c2= toupper(c,loc) | use_facet<ctype<C>>(loc).toupper(c) |
| c2= tolower(c,loc) | use_facet<ctype<C>>(loc).tolower(c) |
39.5.3 字符串转换( String Conversions**)**
字符编码转换可能与 locale 有关。类模板 wstring_convert 执行宽字符串和字节字符串之间的转换。 它允许你指定一个编码转换 facet (例如 codecvt ) 来执行转换,而不会影响任何流或 locale 。例如,你可以直接使用名为 codecvt_utf8 的编码转换 facet ,将 UTF-8 多字节序列输出到 cout ,而不会更改 cout 的locale :
wstring_conver t<codecvt_utf8<wchar_t>> myconv;
string s = myconv.to_bytes(L"Hello\n");
cout << s;
wstring_convert 的定义相当传统:
template<class Codecvt,
class Wc = wchar_t,
class Wa = std::allocator<Wc>, // wide-character allocator
class Ba = std::allocator<char> // byte allocator
>
class wstring_conver t {
public:
using byte_string = basic_string<char, char_traits<char>, Ba>;
using wide_string = basic_string<Wc, char_traits<Wc>, Wa>;
using state_type = typename Codecvt::state_type;
using int_type = typename wide_string::traits_type::int_type;
// ...
};
wstring_convert 构造函数允许我们指定一个字符转换 facet ,初始转换状态以及发生错误时要使用的值:
|----------------------------------------|--------------------------------------------------------------------------------------|
| wstring_conver t<Codecvt,Wc,Wa,Ba> (§iso.22.3.3.2.2) ||
| wstring_convert cvt {}; | wstring_conver t cvt {new Codecvt}; |
| wstring_convert cvt {pcvt,state} | cvt 使用了转换语言特征**∗** pcvt 和转换状态 state |
| wstring_convert cvt {pcvt}; | wstring_conver t cvt {pcvt,state_type{}}; |
| wstring_convert cvt {b_err,w_err}; | wstring_conver t cvt{}; 使用b_error 和w_err |
| wstring_convert cvt {b_err}; | wstring_conver t cvt{}; 使用b_error |
| cvt. ˜wstring_conver t(); | 析构函数 |
| ws=cvt.from_bytes(c) | ws 包含转换为 Wc 的char c 。 |
| ws=cvt.from_bytes(s) | ws 包含转换为 Wc 格式的 s 的 char ; s 是一个 C 风格字符串或一个string 。 |
| ws=cvt.from_bytes(b,e) | ws 包含转换为 Wc 的**[b:e)** 的char 。 |
| s=cvt.to_bytes(wc) | s 包含转换为char 的 wc |
| s=cvt.to_bytes(ws) | s 包含转换为char 的 ws 的 Wc ; ws 是一个 C 风格的字符串或一个basic_string<Wc> |
| s=cvt.to_bytes(b,e) | s 包含转换为 char 的 [b:e) 的 Wc |
| n=cvt.conver ted() | n 是由 cvt 转换的输入元素的数量 |
| st=cvt.state() | st 是 cvt 的状态 |
如果转换为wide_string 失败,则使用非默认 w_err 字符串构造的cvt 上的函数将返回该字符串(作为错误消息);否则,它们将抛出range_error 。
如果转换为byte_string 失败,则使用非默认 b_err 字符串构造的 cvt 上的函数将返回该字符串(作为错误消息);否则,它们将抛出 range_error 。
例如:
void test()
{
wstring_conver t<codecvt_utf8_utf16<wchar_t>> conver ter;
string s8 = u8"This is a UTF −8 string";
wstring s16 = conver ter.from_bytes(s8);
string s88 = conver ter.to_bytes(s16);
if (s8!=s88)
cerr <"Insane!\n";
}
39.5.4 缓冲区转换( Buffer Conversions**)**
我们可以使用代码转换 facet (§39.4.6)直接写入流缓冲区或直接从流缓冲区读取数据(§38.6):
template<class Codecvt,
class C = wchar_t,
class Tr = std::char_traits<C>
>
class wbuffer_convert
: public std::basic_streambuf<C,Tr> {
public:
using state_type = typename Codecvt::state_type;
// ...
};
|------------------------------------------|----------------------------------------------------------------------------------|
| wbuffer_conver t<Codecvt,C,Tr> (§iso.22.3.3.2.3) ||
| wbuffer_convert wb {psb,pcvt,state}; | wb 使用转换器 ∗ pcvt 和初始转换状态state ,从 streambuf ∗ psb 进行转换 |
| wbuffer_convert wb {psb,pcvt}; | wbuffer_conver t wb {psb,pcvt,state_type{}}; |
| wbuffer_convert wb {psb}; wbuffer_ | wbuffer_conver t wb {psb,new Codecvt{}}; |
| wbuffer_convert wb {}; | wbuffer_conver t wb {nullptr}; |
| psb=wb.rdbuf() | psb 是 wb 的流缓冲区 |
| psb2=wb.rdbuf(psb) | 将 wb 的流缓冲区设置为 *psb ; ∗ psb2 是 wb 的前一个流缓冲区 |
| t=wb.state() | t 的 wb 转换状态 |
39.6 建议( Advice**)**
1 预期所有与用户直接交互的非平凡程序或系统都将在多个不同国家/地区使用;§39.1。
2 不要假设每个人都使用与你相同的字符集;§39.1,§39.4.1。
3 优先使用 locale 来编写文化相关的 I/O 专用代码;§39.1。
4 使用 locale 来满足外部(非 C++)标准;§39.1。
5 将 locale 视为包含多个 facet 的容器;§39.2。
6 避免在程序文本中嵌入 locale 名称字符串;§39.2.1。
7 尽量只在程序中的少数几个地方更改 locale ;§39.2.1。
8 尽量减少全局格式信息的使用;§39.2.1。
9 优先使用 locale 敏感的字符串比较和排序;参见 §39.2.2、§39.4.1。
10 使 facet 不可变;参见 §39.3。
11 让 locale 控制 facet 的生命周期;参见 §39.3。
12 你可以创建自己的 facet ;参见 §39.3.2。
13 编写 locale 敏感的 I/O 函数时,请记住处理用户提供的(重写)函数的异常;参见 §39.4.2.2。
14 如果需要在数中使用分隔符,请使用 numput ;参见 §39.4.2.1。
15 使用简单的 Money 类型来存储货币值;参见 §39.4.3。
16 使用简单的用户定义类型来存储要求 locale 敏感的 I/O 的值(而不是在内置类型的值之间进行强制转换)。 §39.4.3 。
17 time_put 语言特征可用于**<chrono>** 和 <ctime> 两种类型的时间。§39.4.4 。
18 优先使用显式指定 locale 的字符分类函数;§39.4.5,§39.5 。
内容来源:
<<The C++ Programming Language >> 第4版,作者 Bjarne Stroustrup