本节使用Z-Image 模型完成文生图,图生图,以及它背后的逻辑。

1.文生图背后逻辑
上一篇中,介绍了 Stable Diffusion的逻辑:
现在以 ComfyUI的视角,再强化一下一个逻辑:
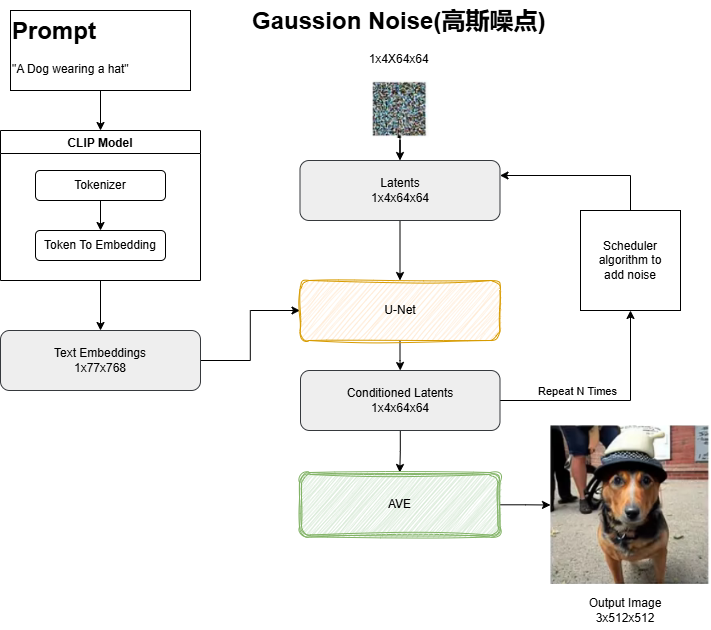
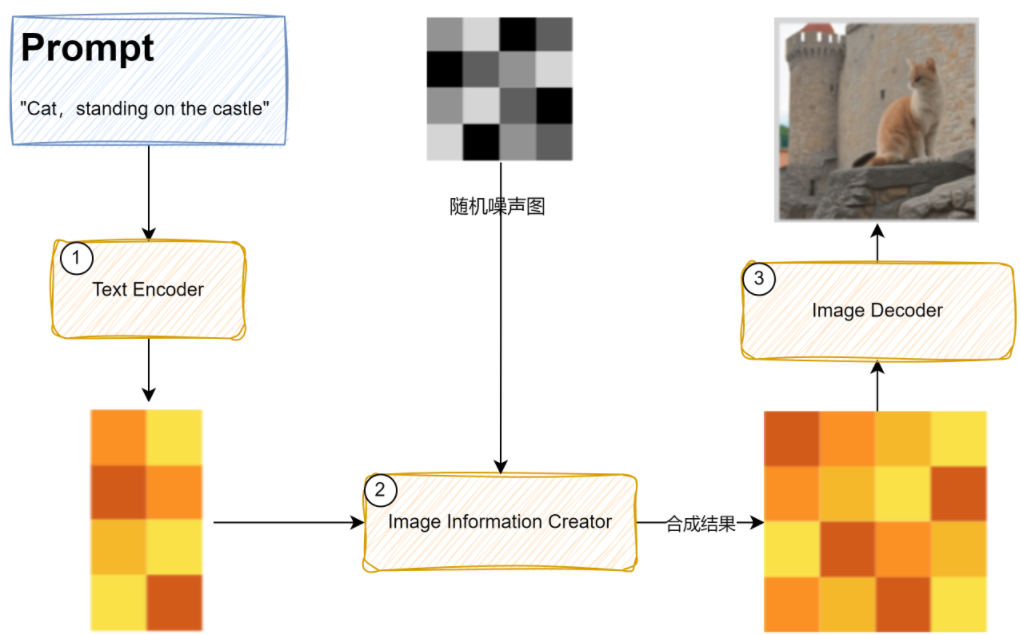
在 Stable Diffusion 这类扩散模型中,整个模型通常由三个主要组件构成:
- VAE(变分自编码器):负责将图像压缩到潜在空间(编码)或将潜在表示解码回像素图像。
- CLIP 文本编码器:将文本提示(prompt)转换为文本嵌入(text embeddings),供 UNet 使用。
- UNet:这是扩散过程的核心,它接收:带噪声的 latent 图像,文本嵌入向量,然后预测噪声,通过逐步去噪声生成清晰的 ladtent 图像
在 ComfyUI 中,默认情况下,你使用的是 Checkpoint Loader 节点,它一次性加载整个 .ckpt 或 .safetensors 模型文件(包含 VAE、CLIP 和 UNet)。
但 ComfyUI 也支持模块化加载,即分别加载这三个组件。这时就会用到:
- UNET Loader (或类似名称,如
Diffusion Model Loader) - CLIP Loader
- VAE Loader
UNet 加载器 专门用于加载模型中的 UNet 权重部分,通常需要配合已加载的 CLIP 和 VAE 一起使用。
2.文生图实操
2.1 清空工作流所有节点
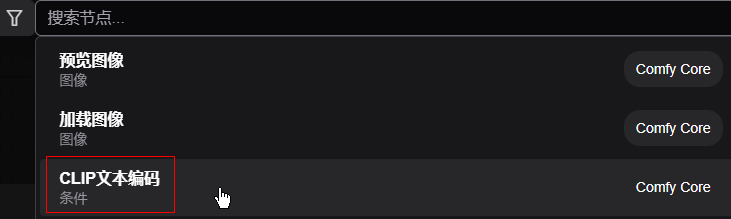
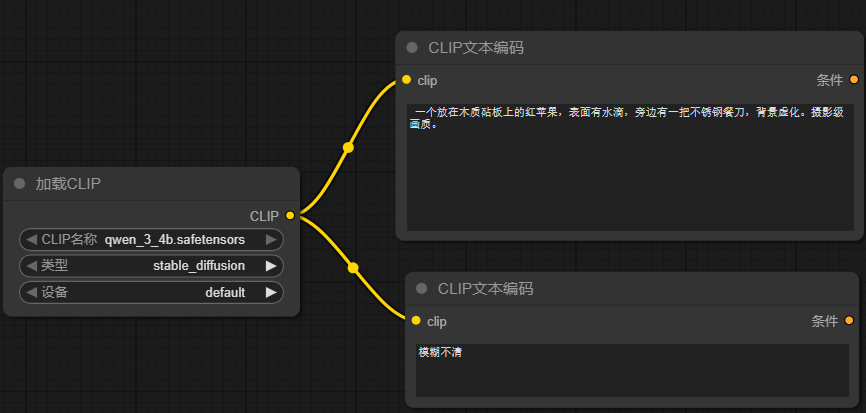
2.2 添加CLIP文本编码节点
在操作台上双击鼠标左键,可以搜索节点。现在我们需要的是对 CLIP 文本编码,所以选它。 要添加两个,一个正向(你要啥),一个反向(你不要啥)
正向提示词:
latex
高质量画质,极致的细节,一个红苹果放在木质桌面,苹果表面有水滴,旁边有一把不锈钢餐刀,背景虚化反向提示词:
latex
模糊不清写提示词的时候按照这个顺序去写: 质量词汇-> 主体词汇 -> 氛围词汇
越靠前的词汇,它的权重会越高,在最终呈现的图片上占比会更大。 所以要按照上面的顺序去写词汇,词汇之间使用逗号进行分割。
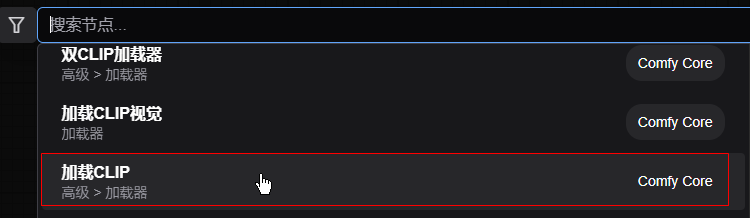
2.3 添加 CLIP加载器节点
文本编码需要模型驱动,我们输入的是中文,模型使用 qwwen_3_4b模型
2.4 连线
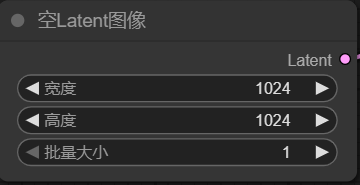
2.5 Latent节点
加入一个空的潜空间,宽高设置为1024x1024
注意它们都应该是 8的倍数
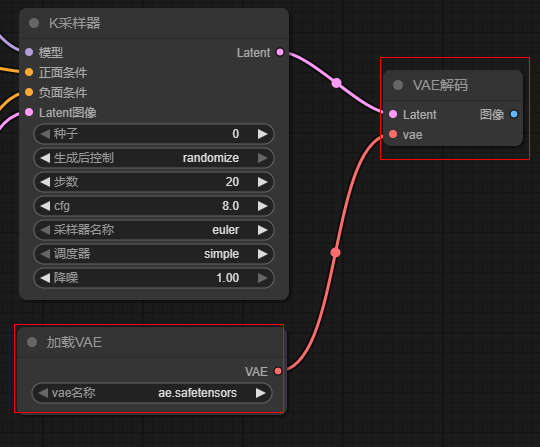
2.6 添加K采样器节点
采样器需要模型,鼠标点击模型前面的圆点,然后到空白处释放后,选择 UNet加载器。 UNet加载器中使用 z_image_turbo_bf16模型
- cfg 参数表示与提示词的匹配度,越大则越匹配。如果过低,则AI的发挥度就越大。一般它设置为 5~8
- 采样器:可以选择
dpmpp_2m或者dpmpp_2m_sde, 这是大家测试下来效果比较好的。
2.7 添加 VAE 解码节点和加载AVE模型节点
K采样器会输出 latent, 它需要一个AVE 解码节点进行解码,将其输出为图像。同样解码器还需要模型,所以再添加一个 VAE加载器
2.8 图像输出节点
最后再添加一个图像输出节点。 完整工作流为:
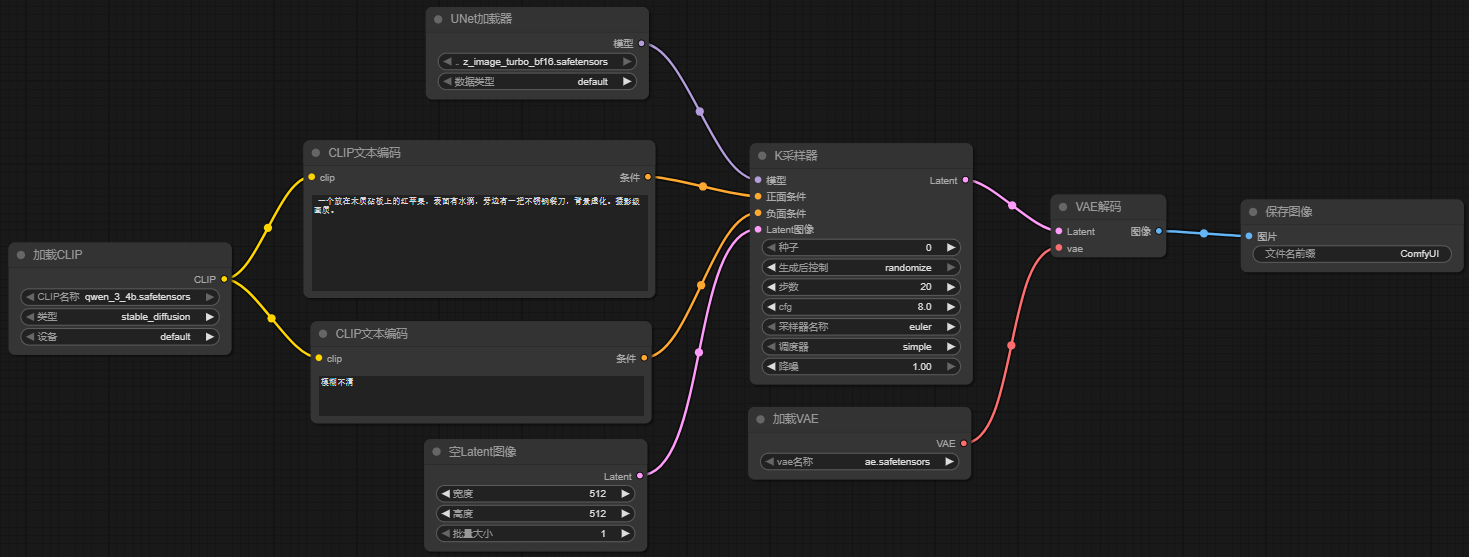
2.9 运行工作流
运行后生成的结果:
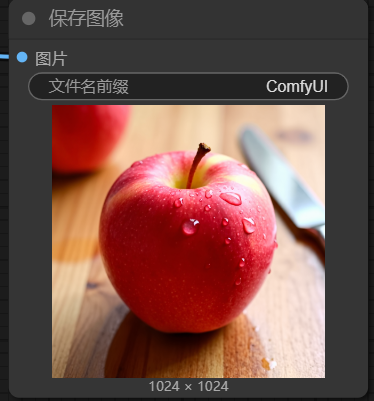
3.文生图小结
最终决定图片风格有以下的关键点:
- 提示词。提示词按照
质量词汇-> 主体词汇 -> 氛围词汇的顺序去写。至于提示词使用中文还是英文,要看将提示词向量化所使用的模型是否支持中文,如果支持就用中文,如果不支持,就将中文翻译成英文。前面我们使用的是 千问系列模型,它本身就支持中文。 - 模型。
U-NET中采用的模型。即K采样器中所使用的模型。如果这个模型在预训练的时候采用的数据集是动漫二次元风格,那么它最终生成的图就是动漫二次元风格。如果是写实的,那它生成的就是写实的。而本次所使用的模型是Z-Image在风格支持方面还是比较全面的。所以风格方面,你得靠提示词去做一些优化。 - Latent 限制了图片的大小. 它配置了大小后,就会添加噪点,然后交给 U-Net 来进行降噪。U-Net降噪的同时,会结合 CLIP文本特征向量,一遍一遍的降噪,最终生成图片。
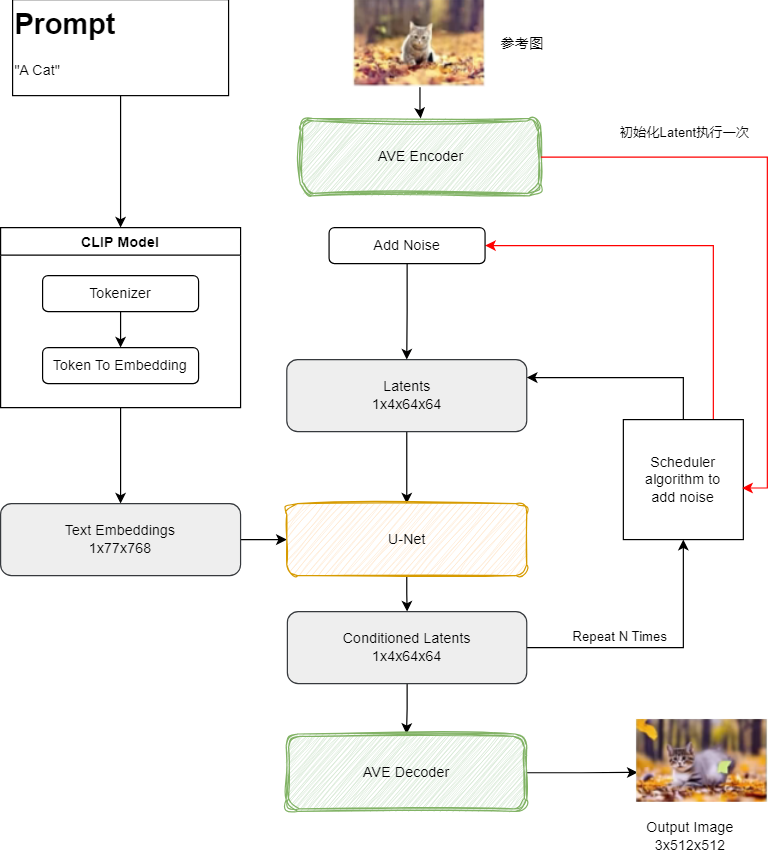
4.图生图背后的逻辑
这个原理基本与文生图是一样的,只不过是添加参考图的时候,多了使用 AVE Encoder 将参考图向量化,然后调度器加入了高斯噪点后放入了 Latents Space. 而文生图则使用的是Emptyt Latents Space.
剩下的流程就和文生图是一样的了。
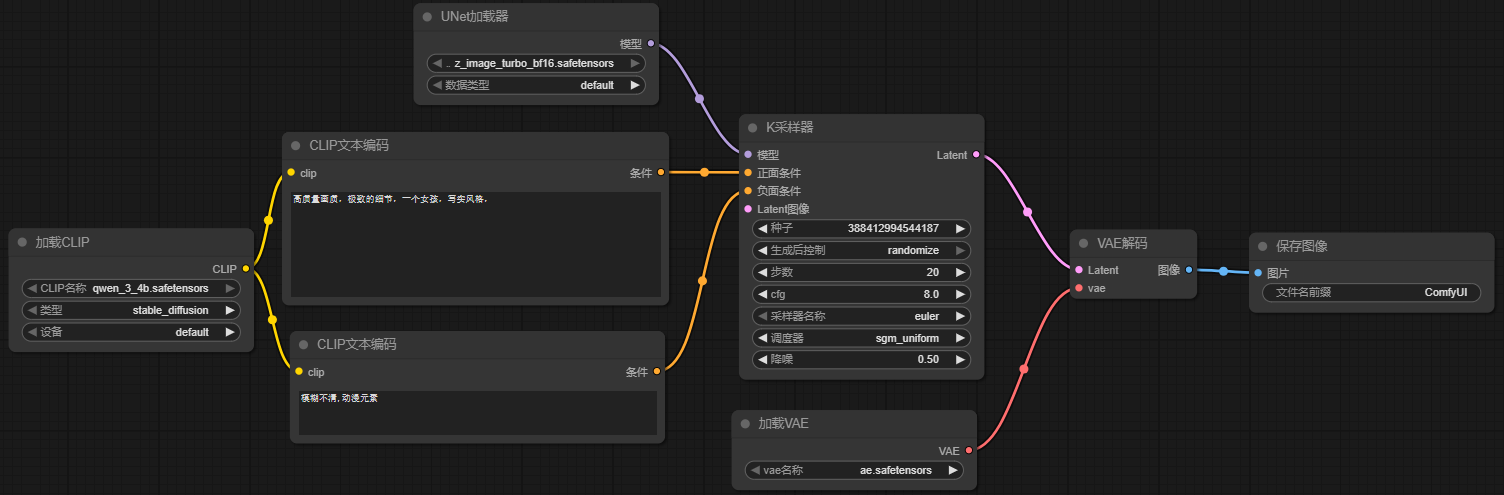
5.图生图实操
直接使用前面文生图的工作流,变更一下提示词,再加入参考图即可。所以将前面的文生图工作流另存为一个工作流,删除掉Empty Latents,效果是这样的。
5.1 添加参考图
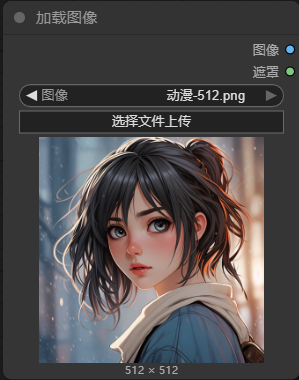
5.1.1添加"加载图像节点"
我上传了一个动漫图片,为了快速出图,我将图片裁剪到了 512x512
5.1.2 添加VAE编码节点
因为参考图要被向量化,所以要添加AVE编码节点。直接在"加载图像" 节点上的 "图像"(蓝色圆点)上用鼠标拖拽出连线然后释放鼠标,就弹出界面,然后选择 VAE编码即可
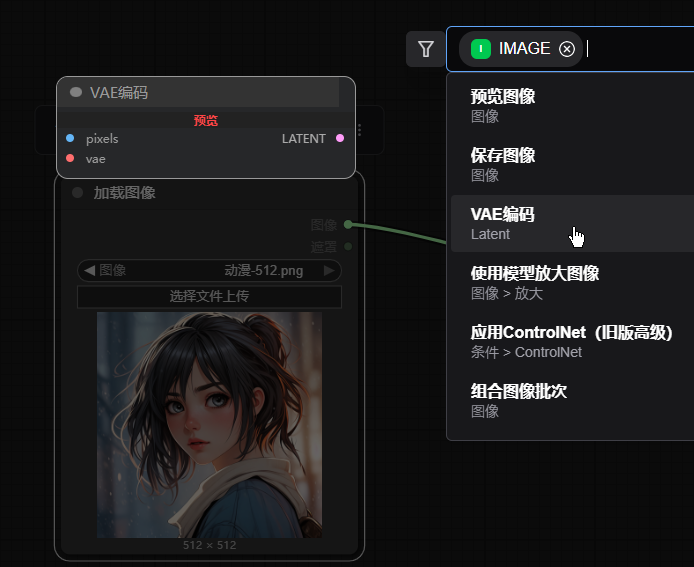
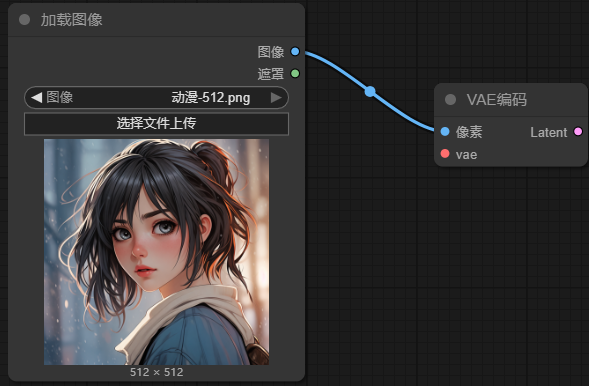
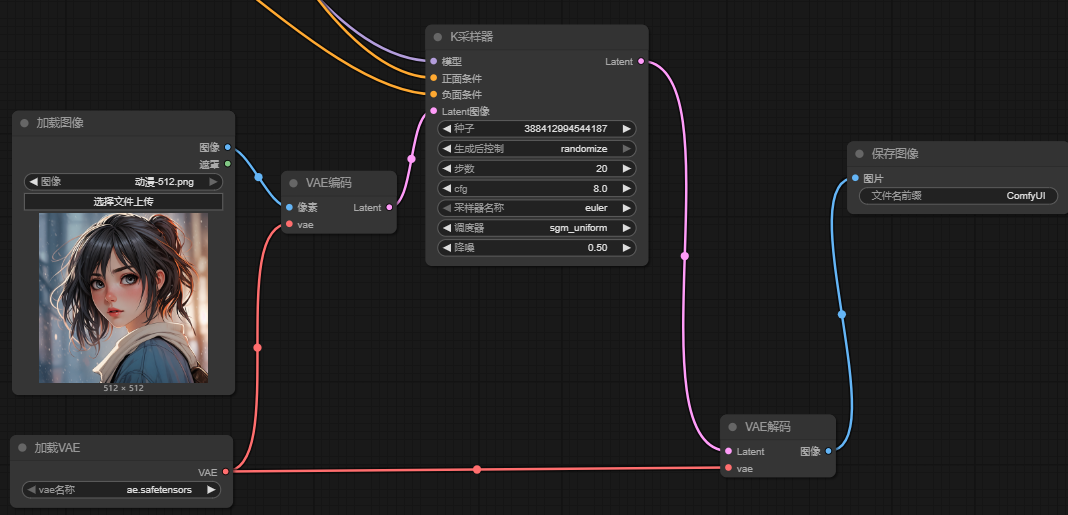
5.1.3 VAE编码节点连线
- VAE编码输出的
Latent连接到K采样器的Latent图像,它输出的Latent要交给K采样器来与 提示词合成新图。 - VAE编码节点要将参考图向量化,需要模型,所以要与
加载VAE节点进行连接
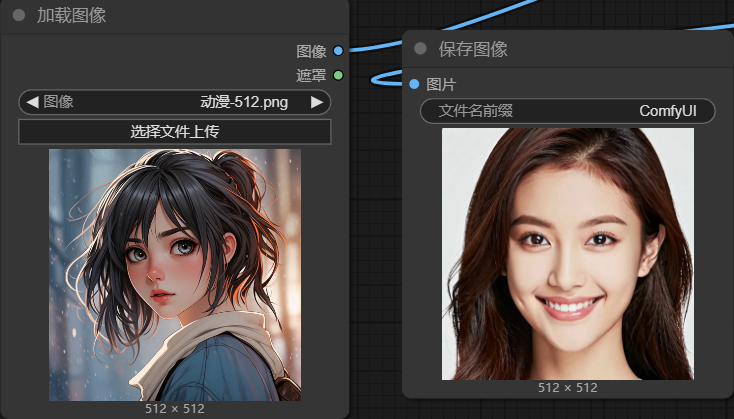
5.2 修改提示词
- 正向提示词:
latex
高质量画质,极致的细节,一个女孩,写实风格,- 反向提示词:
latex
模糊不清,动漫元素5.3 理解 K采样器:降噪参数
到目前为止,工作流已经构建好了,可以运行了。在运行之前,我们要理解K采样器中非常重要的参数: 降噪
5.3.1 降噪设置为:0
当设置为0,后运行会发现很快出结果。而且结果与原图几乎一模一样。这是为什么?这就是降噪参数的作用了。
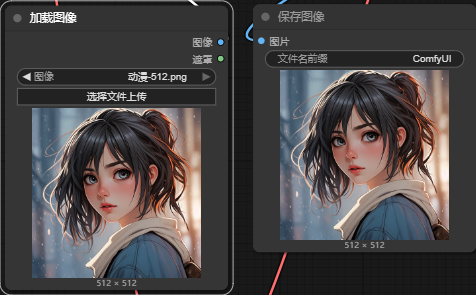
图生图的原理中,参考图是要加入"噪点"后放入
Latent space中的,如果降噪设置为0,这意味着不加入噪点,K采样器没什么可降噪的,输出的自然和参考图一样。
5.3.1 降噪设置为:1
如果设置为1,那就意味着参考图上全是噪点,那这个参考图就失去了意义了。那最终输出的图就有很大的不确定性,如果设置的步数太小,那最终的结果有可能还存在噪点,输出的图片就会很"诡异"
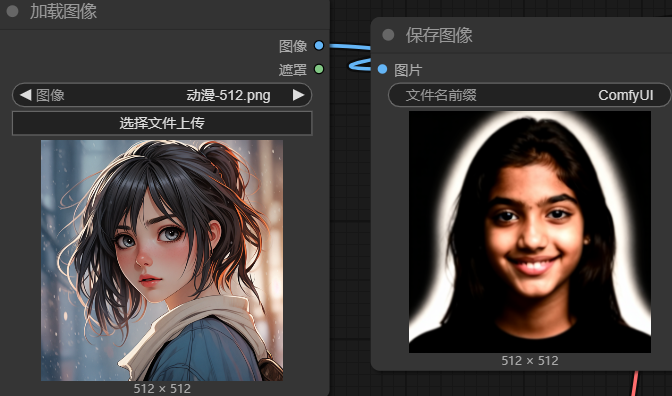
我把K采样器上的 步数调大到 40, 降噪依然是 1,也就是全是噪点,让AI 依靠提示词随意发挥,再看看效果。
5.3.2 小结
相对于参考图片:
- 降噪参数越小,则表示噪点越少,生成的结果越接近参考图。因为噪点少,那么步数自然也就小,此时调大部署没有意义。
- 降噪参数越大,表示噪点越多,AI发挥的空间就越大,生成的图与原图就相差较远。因为噪点多,此时可以适量增加步数充分降噪。
- 如果要调整风格:可以更换模型,这就要看模型是那种风格训练出来的。也可以更换提示词。但是需要注意:大模型的影响要比提示词影响大得多