一、中间代码的作用
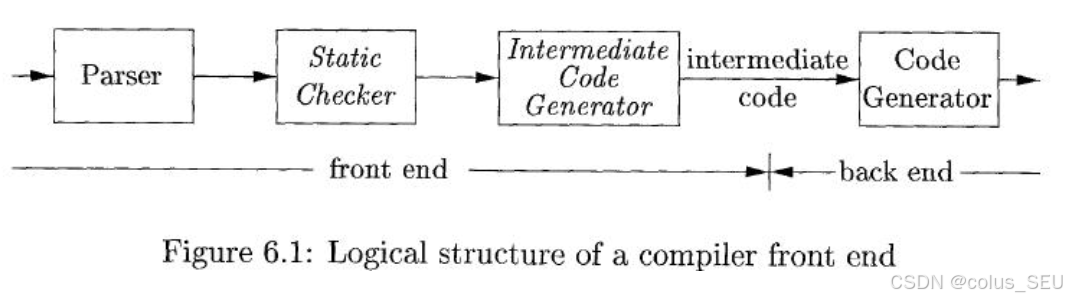
编译器的前端(和软件中的前端不同)处理的是与源语言相关的任务,而后端处理的是与目标语言相关的任务。代码生成器(Code Generator)将中间代码转换为目标机器的机器代码。中间代码作为前端和后端之间的桥梁,使得编译器可以更容易地支持多种源语言和目标平台。因此,中间代码的作用总结为:
-
促进可移植性 (Facilitate Portability):中间代码独立于目标机器,使得编译器可以在不同平台上运行。
-
促进优化 (Facilitate Optimization):在中间代码级别进行优化(如常量折叠、死代码消除)比在源代码或目标代码级别更高效、更通用。
二、中间代码的实现
Utilize semantics rule to evaluate the "code" attribute
中间代码的实现就是:利用语义规则来计算一个名为 "code" 的属性。例如:

三、中间代码的表示形式
Intermediate Representation:Three Address Code
-
三地址码 (Three Address Code) 是主要的中间表示形式。
-
具体数据结构包括:
-
四元组 (Quadruples)
-
三元组 (Triples)
-
间接三元组 (Indirect Triples)
-
3.1. 三地址码的形式
3.1.1. 三地址码的九种基本形式
以下规则定义了三地址码(Three Address Code)的基本指令形式,用于表示高级语言语句。
- 规则 1: 二元运算赋值
形如 的赋值指令,其中 op 是一个二元算术或逻辑运算符,x, y, z 均为内存地址。例如:
- 规则 2: 一元运算赋值
形如 的赋值指令,其中 op 是一个一元运算符。
常见的一元运算包括:一元负号(-),逻辑非(!),移位操作(<<, >>),类型转换(例如将整数转换为浮点数)
- 规则 3: 复制指令
形如 的复制指令,其中 x 被赋予 y 的值。例如:
- 规则 4: 无条件跳转
无条件跳转指令 。带有标签 L 的三地址指令是下一个要执行的指令。
- 规则 5: 条件跳转(基于布尔值)
条件跳转指令 if x goto L 和 ifFalse x goto L。
:如果 x 为真,则执行标签 L 处的指令。否则,顺序执行下一条三地址指令。
:如果 x 为假,则执行标签 L 处的指令。否则顺序执行下一条三地址指令。
- 规则 6: 条件跳转(基于关系运算)
条件跳转指令 ,其中
relop 是关系运算符(如 <, ==, >= 等)。
如果 x 与 y 满足关系 relop,则执行标签 L 处的指令。否则,顺序执行 if x relop y goto L 后面的下一条三地址指令。
- 规则 7: 过程调用与返回
过程调用和返回通过以下指令实现:
param x:传递参数 x。
call p, n:调用过程 p,参数个数为 n。
y = call p, n:调用函数 p,参数个数为 n,结果存入 y。
return y:返回值 y(可选)。
- 规则 8: 带索引的复制指令
形如 x = yi 和 xi = y 的带索引复制指令。
:将 y 地址后第 i 个内存单元的值赋给 x。
:将 y 的值赋给 x 地址后第 i 个内存单元。
- 规则 9: 地址与指针赋值
形如 、
和
的地址与指针赋值指令。
:将 x 的右值(r-value)设置为 y 的左值(l-value,即地址)。
:将 x 的右值设置为 y 所指向内存位置的内容。
:将 x 所指向的对象的右值设置为 y 的右值。
3.1.2. 为三地址码的代码块分配标签
需要注意的是,在生成三地址码时,为实现循环等控制流,还需要为代码块分配标签。
下图的例子中展示了两种主要方案:符号化标签(Symbolic labels) 和 位置编号(Position numbers) 。前者使用助记符(如 L)标记代码位置,便于人类阅读和调试;后者则直接使用指令的绝对序号(如 100)作为标签,更贴近机器执行的实际形式。两者功能等价,编译器通常先用符号化标签进行中间代码生成和优化,再将其转换为具体的位置编号以生成最终目标代码。

3.2. 三地址码的数据结构
3.2.1. 四元组(Quadruples)
一个四元组(或简称"quad")包含四个字段,我们称之为 op、arg₁、arg₂ 和 result。
-
op字段包含操作符的内部代码。 -
例如,三地址指令 x = y + z 通过将
+放入op、y放入arg₁、z放入arg₂、x放入result来表示。
以下是此规则的一些例外情况:
-
一元运算符指令:
-
如
或
arg₂。 -
注意,对于复制语句如 x = y,
op是=;而对于大多数其他操作,赋值操作符是隐含的。
-
-
参数传递操作符:
- 如
param这样的操作符既不使用arg₂也不使用result。
- 如
-
跳转指令:
- 条件跳转和无条件跳转指令会将目标标签放入
result字段。
- 条件跳转和无条件跳转指令会将目标标签放入
🚩 三地址码的四元组表示示例:

3.2.2. 三元组(Triples)
四元组中拿掉 result 字段就是三元组。
🚩 三地址码的三元组表示示例:a = b * (-c) + b * (-c) 的表示:

3.2.3. 间接三元组(Indirect Triples)
间接三元组的核心思想是将指令本身和对这些指令的引用分开存储,从而便于在优化阶段对指令进行重排。
-
三元组 (Triples) :直接以
(op, arg1, arg2)的形式存储每条指令。结果是隐式的,由其在列表中的位置决定。 -
间接三元组 :不直接在列表中存储指令,而是创建一个指针数组(或称为指令表),其中每个元素指向一个实际的三元组。这样做的好处是,在优化时可以重新排列这个指针数组,而无需移动实际的三元组数据。

四、常见语句的翻译
4.1. 表达式(Expression)
用于表达式的中间代码生成的SDD如下:

注:
new Temp() 表示在内存中新开一个地址,记作 t;
|| 表示 "followed by" 的意思,可以理解为换行符;
top.get(id.lexeme) 即从栈中获取栈顶的id的具体词。
例:使用该语法指导定义(syntax-directed definition)(SDD)将赋值语句 a = b + -c; 翻译为三地址码序列。
答:首先进行词法分析和语法分析得到:<id,1><=><id,2><+><-><id,3>
然后画出语法树,在计算属性 addr 和 code 的时候可以使用自底向上分析较为方便,因为是综合属性。
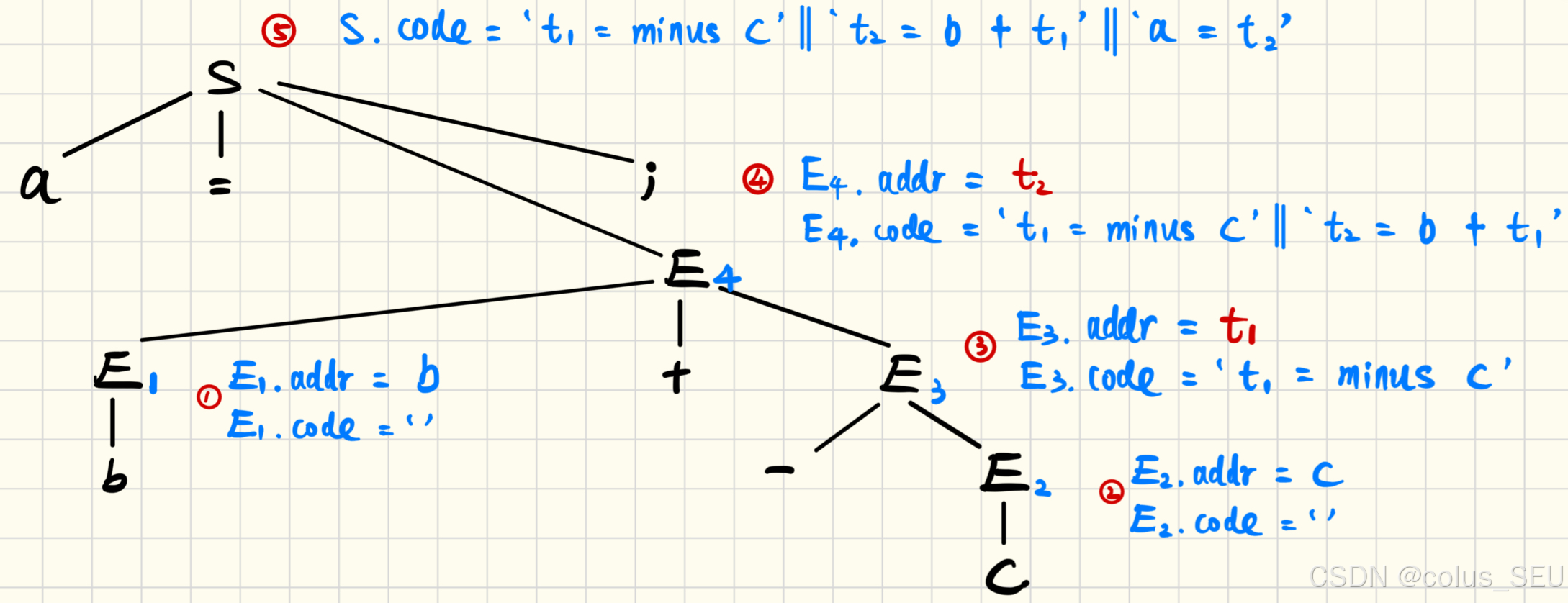
结果为S.code,即:
4.2. 数组(Array)
用于数组的中间代码生成的SDD如下:

注:
L.addr 表示一个临时变量,用于在计算数组引用的偏移量时,通过累加各项
L.array 是指向数组名符号表条目的指针。数组的基地址(例如,L.array.base)用于在分析完所有索引表达式后,确定数组引用的实际左值(l-value)。
L.type 是由 L 生成的子数组的类型。对于任意类型 t,我们假设其宽度由 t.width 给出。我们使用类型作为属性,而非宽度,因为无论如何都需要类型来进行类型检查。对于任何数组类型 t,假设 t.elem 给出了元素类型。
例:设 a 表示一个 2 * 3 的整数数组,c, i, 和 j 均表示整数。数组声明:a0...1, 0...2,即数组索引从0开始。请使用该语法指导定义(syntax-directed definition)(SDD)将数组 c + a[i][j] 翻译为三地址码序列。
答:首先分析该数组的类型与宽度:
-
数组
a的类型:array(2, array(3, integer)) -
数组
a的宽度 :假设一个整数的宽度为 4,则a的总宽度 w = 24。 -
子数组
a[i]的类型:array(3, integer),其宽度 w_1 = 12。 -
元素
a[i][j]的类型:integer
然后画出语法树,在计算属性时依旧使用自底向上分析。
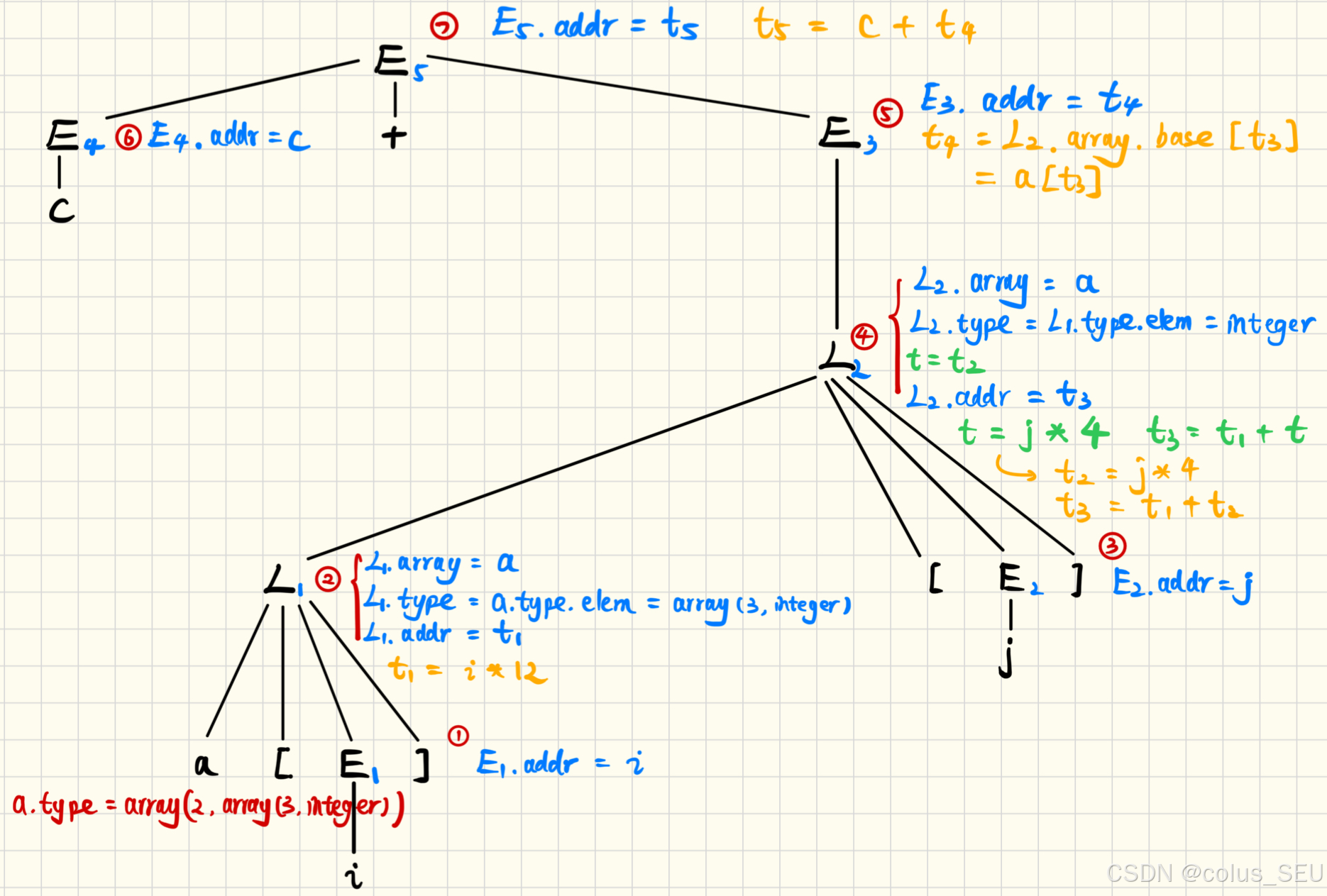
因此最终结果为:
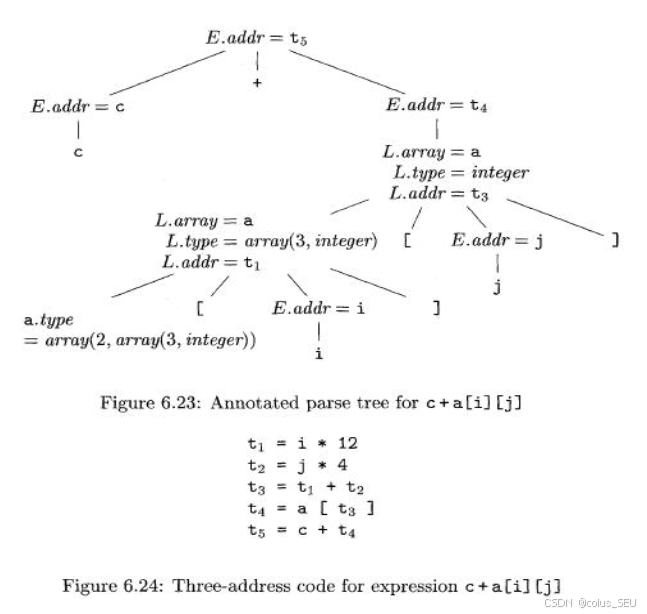
龙书中标答为:
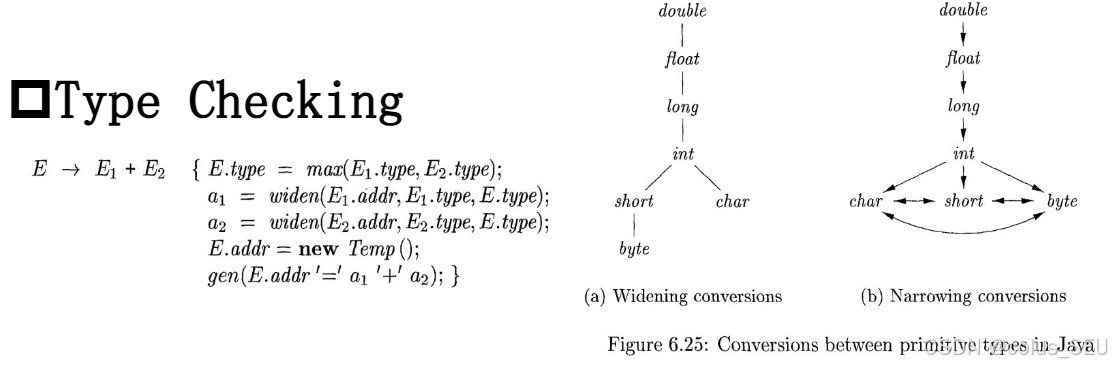
4.3. 类型检查(Type Checking)
类型检查函数
在中间代码生成中,为了处理不同类型之间的运算和赋值,需要定义以下两个核心函数:
-
-
该函数接收两个类型
t1和t2作为输入。 -
它返回这两个类型在"类型提升层次结构(widening hierarchy)"中的最大值(或最小上界)。
-
如果任一类型不在该层次结构中(例如,数组类型或指针类型),则会声明一个错误。
-
-
-
该函数用于在必要时,将一个地址
a(其类型为t)转换为一个类型为w的值。 -
如果
t和w是相同的类型,则直接返回a本身。 -
否则,它会生成一条指令来执行类型转换,并将结果存入一个临时变量
t中,然后返回这个临时变量作为结果。 -
该函数的实现如下:
Addr widen(Addr a, Type t, Type w) {
if (t == w) return a;
else if (t == integer && w == float) {
temp = new Temp();
gen(temp '= ' '(float)' a);
return temp;
}
else error;
}
-
我们以 a+b 的中间代码生成来举例说明以上两个类型检查函数:

4.4. 控制流语句(Flow-of-Control statements)
控制流语句的编码策略 (Coding Approaches for Flow-of-Control)
-
短路(跳转)编码 (Short Circuit (Jumping) Encoding):
-
使用继承属性
.code来管理跳转。 -
适用于布尔表达式和控制流语句。
-
-
回填编码 (Backpatching):
-
使用综合属性
.code来管理跳转。 -
在不知道跳转目标标签时,先生成跳转指令并记录待填充的列表,待目标确定后再回填(backpatching)。
-
包含
makelist(i),merge(p1,p2),backpatch(p,i)等操作。
-
4.4.1. Short Circuit (Jumping) codes
布尔表达式
For Boolean Expression,like:

该例子很好理解:
对于 ifFalse is allowed 的情况,先判断 if x<100,如果正确,说明整个语句成立,直接 goto L2,即执行 x=0,如果不正确,执行 ifFalse x>200 goto L1,即 x>200 不成立的话,goto L1,否则执行 ifFalse x!=y goto L1,即 x!=y 不成立的话,goto L1。
对于 ifFalse is not allowed 的情况,先判断 if x<100,如果正确,说明该语句直接成立,直接 goto L2,即执行 x=0,如果不正确,则该语句是否成立取决于接下来的表达式,因此 goto L3。在 L3 中,if x>200 goto L4,即 x>200 成立的话,整个语句是否成立就取决于 x!=y 是否成立,因此 goto L4,否则 goto L1,表示整个语句不成立。在 L4 中,if x!=y goto L2,即 x!=y 成立的话,goto L2,否则 goto L1。
控制流语句
For Flow Control,like:
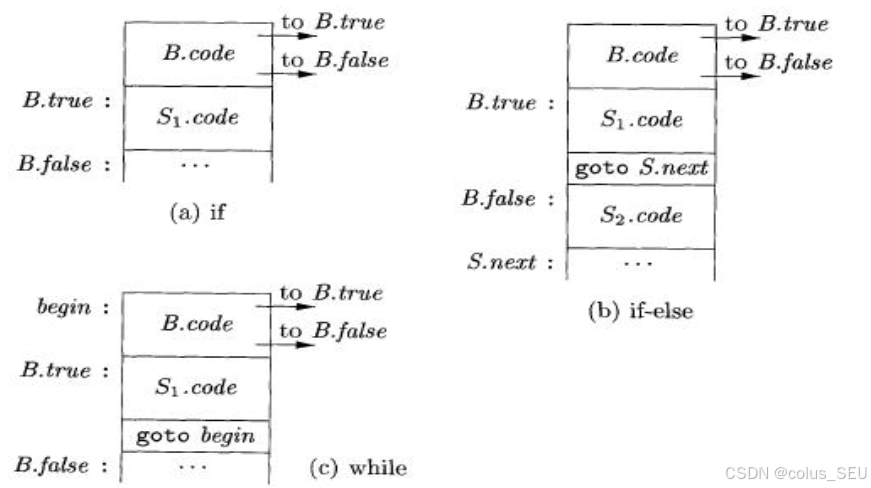
由 if, if-else, while 的具体含义可以很好理解上述表示的逻辑含义。
更加完整的SDD是:


例1:根据以上 SDD 给出语句的三地址码:if ( x<100 || x>200 && x!=y) x=0;
答:跳转编码对应继承属性,适用于自顶向下的分析:
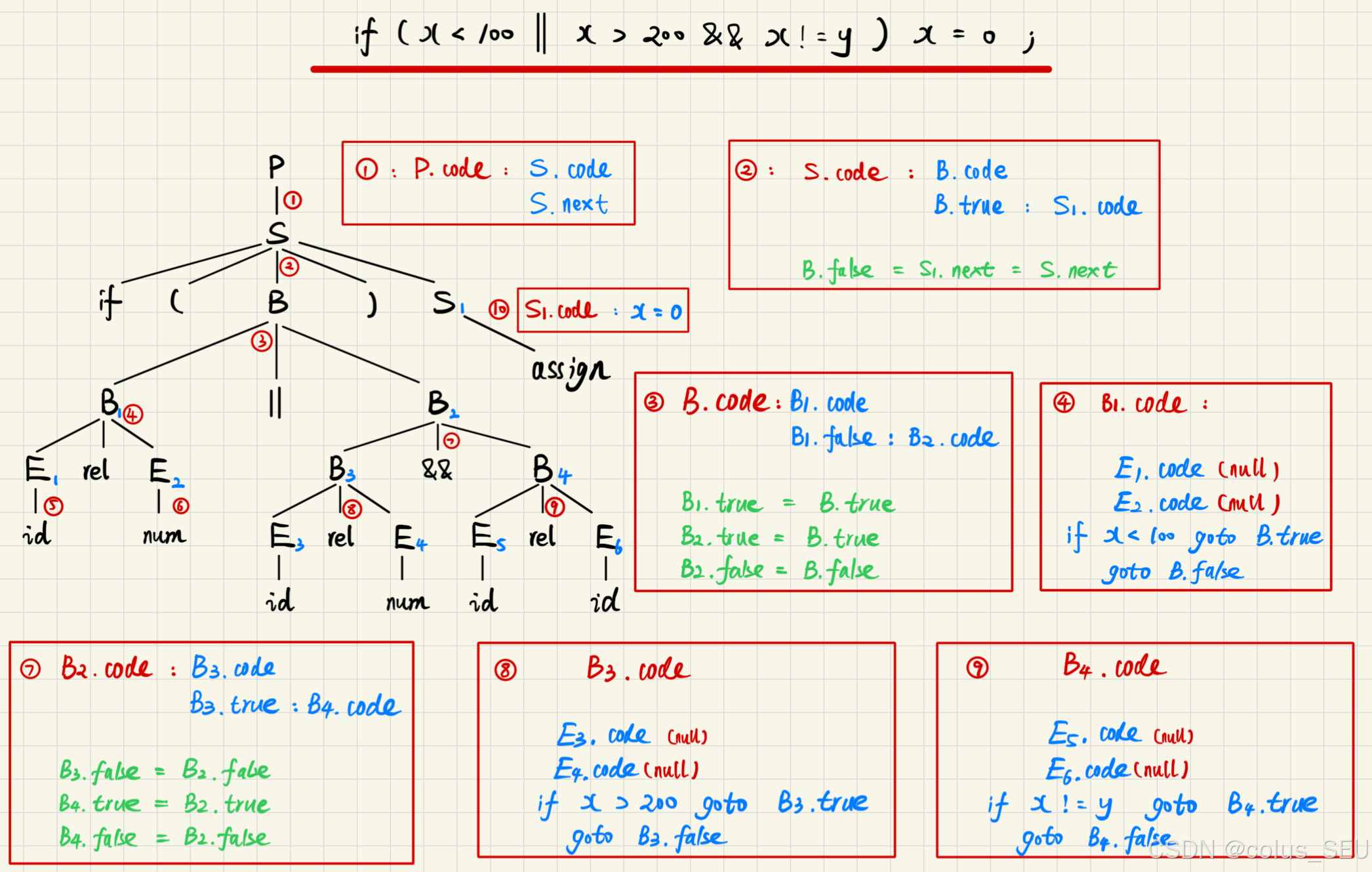
整合得到 P.code(即该语句的三地址码) 为:

例2:根据以上 SDD 给出以下源代码的三地址码。
cpp
i = 1;
tag = 0;
while (tag == 0 && i <= 10) do
{
j = 1;
while (tag == 0 && j <= 10) do
if (a[i, j] == x) tag = 1;
else j = j + 1;
if (tag == 0) i = i + 1;
}注意:规定数组 a 的索引从1开始。
答:自顶向下的分析如下:
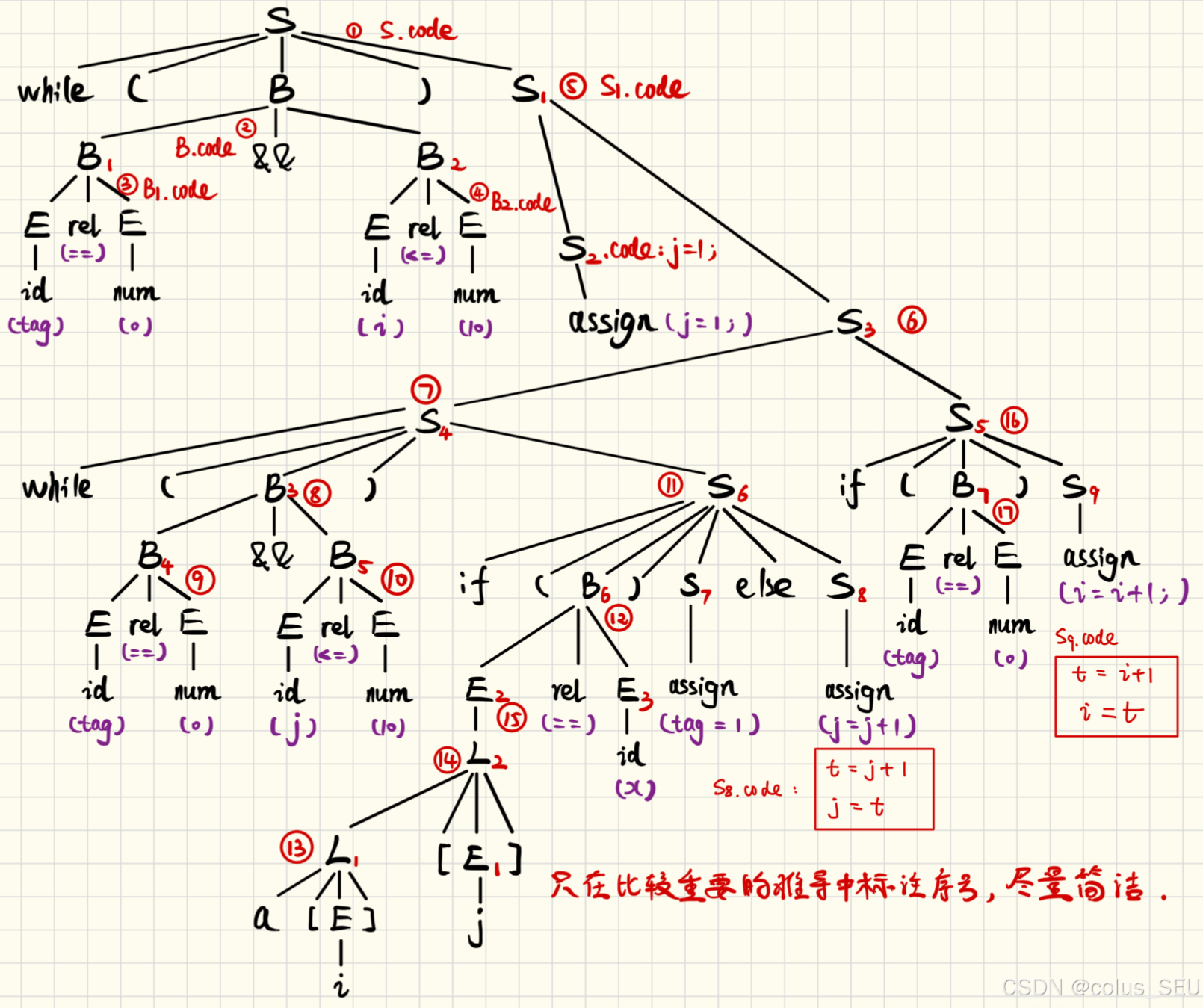
利用 SDT scheme 进行分析,注意数组和表达式的分析:

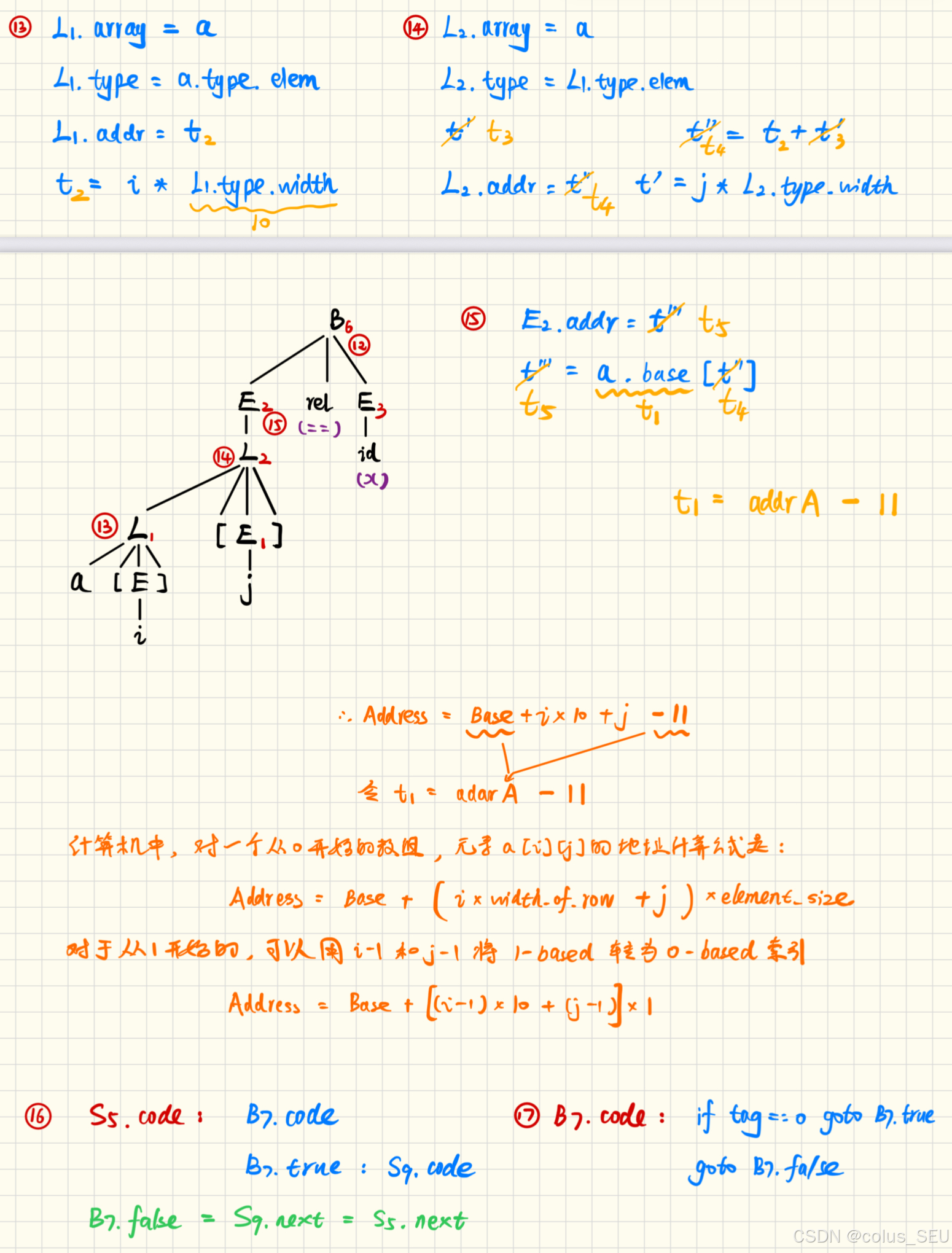
上面的分析中特别注意数组索引从 1 而不是 0 开始,因此需要定义 t1 = addrA - 11.
然后整合得到 S.code 为:
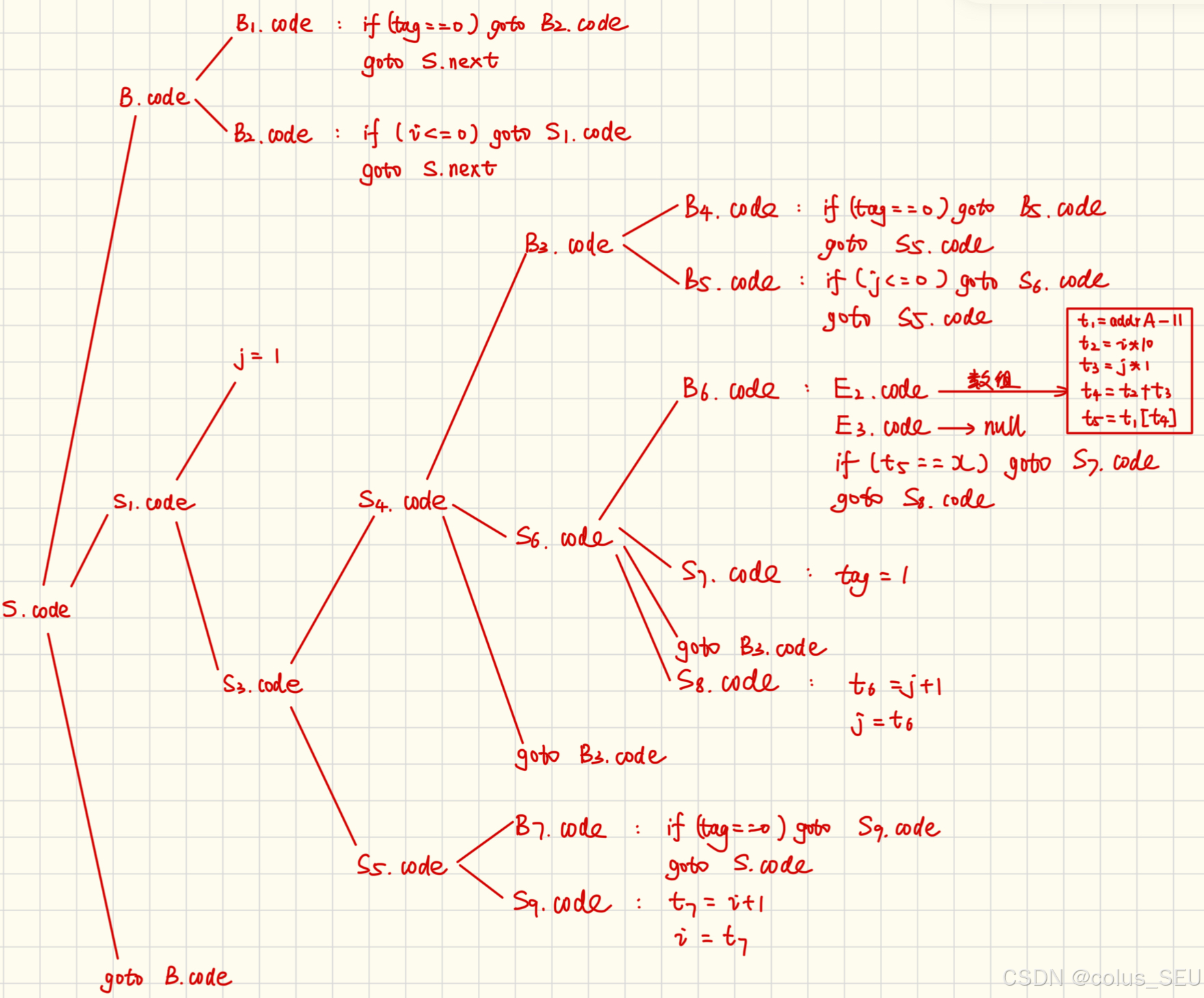
将 S.code 整合为跳转编码:
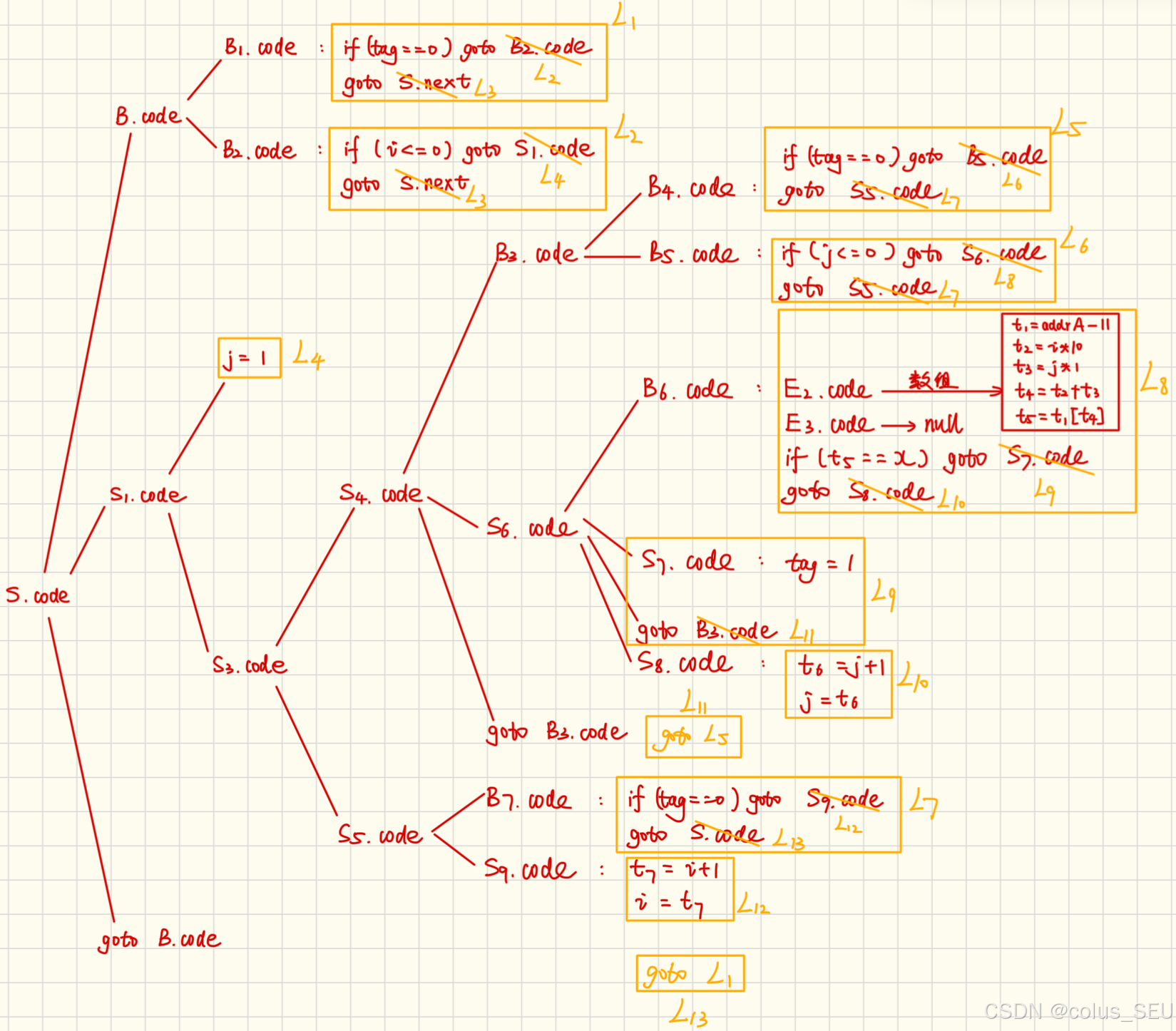
然后得到最终结果为:

4.4.2. Backpatching codes
1. 什么是回填?为什么需要它?
在为布尔表达式和控制流语句生成代码时,我们常常无法立即知道跳转指令的目标标签 。例如,在解析 if (x > y) then ... 时,当处理到 x > y 时,我们还不知道 then 分支结束后要跳转到哪里。
为了解决这个问题,我们可以:
-
先生成一系列分支指令,但将它们的跳转目标暂时留空。
-
将这些待填充目标的跳转指令加入一个列表中。
-
当程序后续执行到可以确定正确目标标签的位置时,再回头去填充这些空缺的标签。
这个后续填充标签的过程 就叫做回填(Backpatching)。
2. 用于操作回填标签列表的函数
为了高效地管理这些待填充的跳转指令列表,通常会定义三个核心函数:
-
-
创建一个只包含单个元素
i的新列表。 -
i是指向指令数组的一个索引。 -
该函数返回指向这个新创建列表的指针。
-
-
-
将由指针
p1和p2指向的两个列表进行拼接。 -
返回指向拼接后新列表的指针。
-
-
- 将目标标签
i填入由指针p所指向的列表中的每一条跳转指令中。
- 将目标标签
3. 回填法的SDT
控制流的回填法的 SDT:

布尔表达式的回填法的 SDT:

例:根据以上 SDT 用回填法给出语句的中间代码:x<100 || x>200 && x!=y
回填法对应综合属性,应该使用自底向上分析:
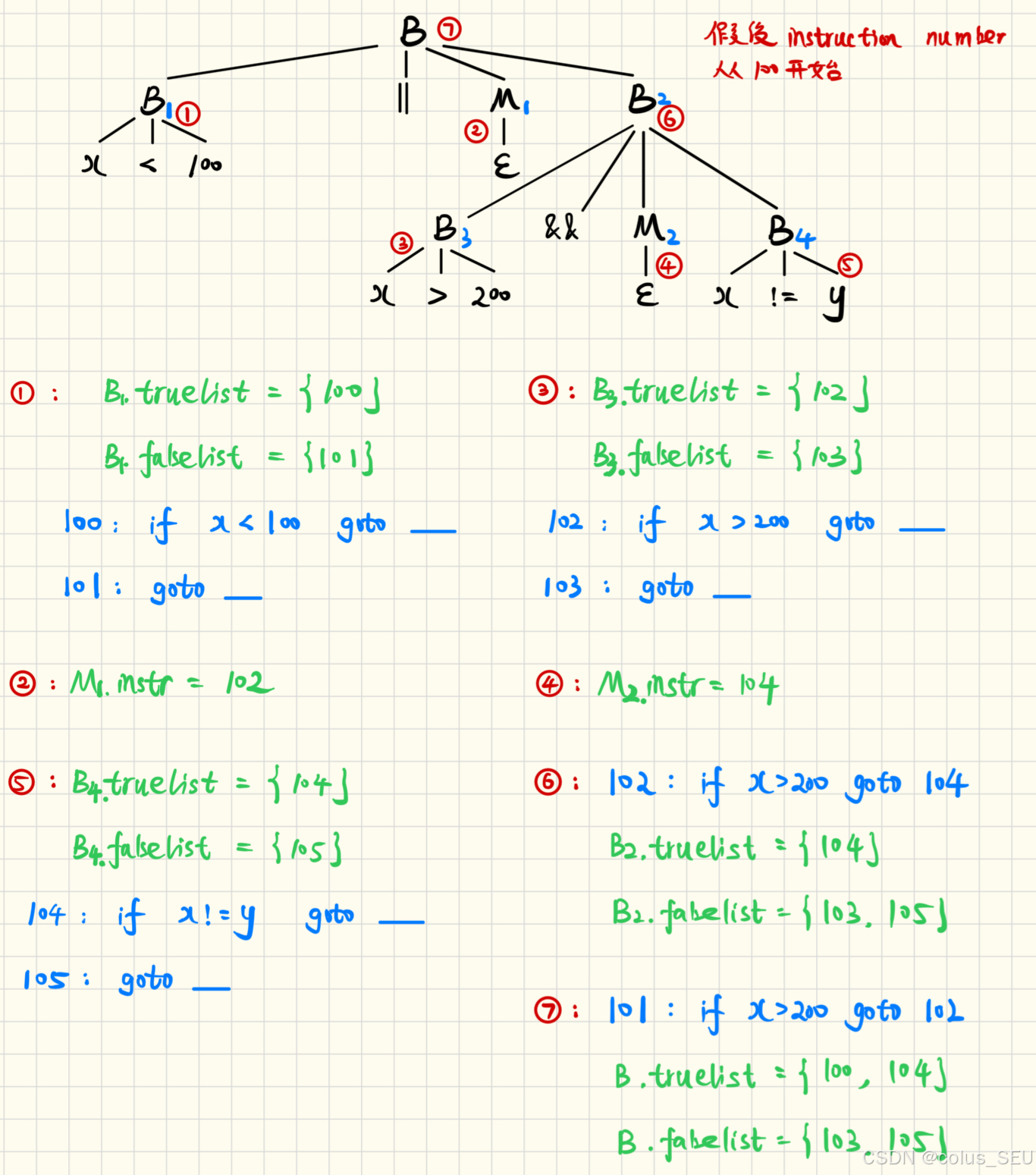
🎯 总结:
-
跳转代码 (Jumping codes):直接生成带标签的汇编式跳转指令。
-
回填代码 (Backpatching codes):使用四元组表示,通过回填机制生成最终的跳转代码