安装环境
虚拟机系统:Ubuntu
⚫ Hadoop 安装模式:伪分布式(单节点)
⚫ 安装包: Pig(0.17.0)
安装步骤
(1) 解压
根据上面的下载网站,下载对应版本的pig,传递到虚拟机中,也可以直接在虚拟机中下载,然后解压。
tart -zxvf pig-0.17.0.tar.gz
转移到/usr/local/文件夹下
sudo mv pig-0.17.0 /usr/local/
(2) 配置pig环境变量
vim需要下载安装命令:sudo apt install vim
sudo vim /etc/profile
sudo vi /etc/profile
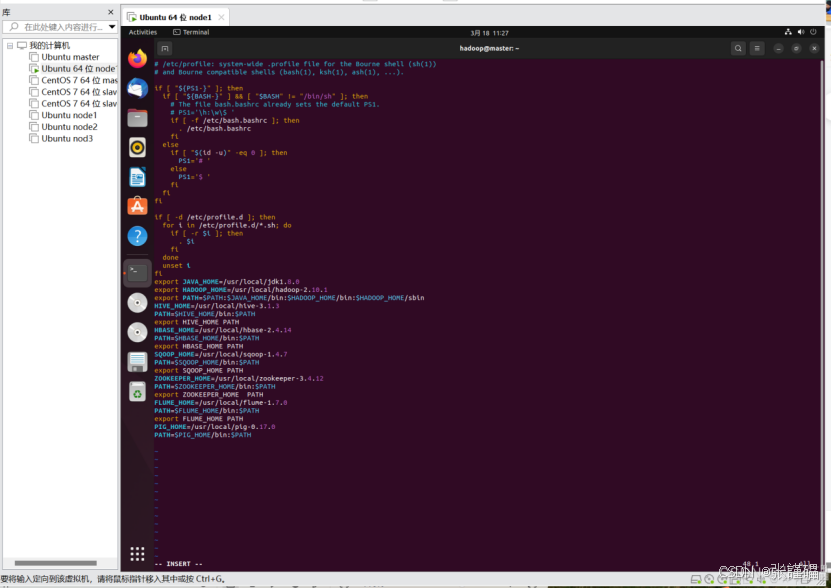
在最下面添加下面代码,如上图所示:
PIG_HOME=/usr/local/pig-0.17.0
PATH=PIG_HOME/bin:PATH
export PIG_HOME PATH
更新环境变量
source /etc/profile
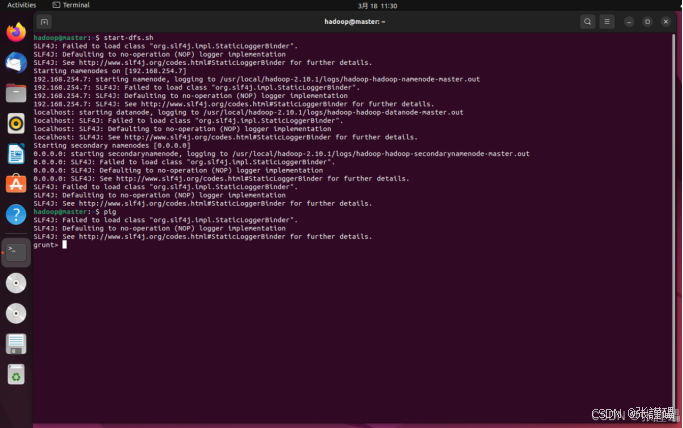
启动pig,先启动dfs,确保你的电脑上有hadoop分布式
pig
(3)pig配置文件
进入**/usr/local/hadoop-2.10.1/etc/hadoop** 路径下
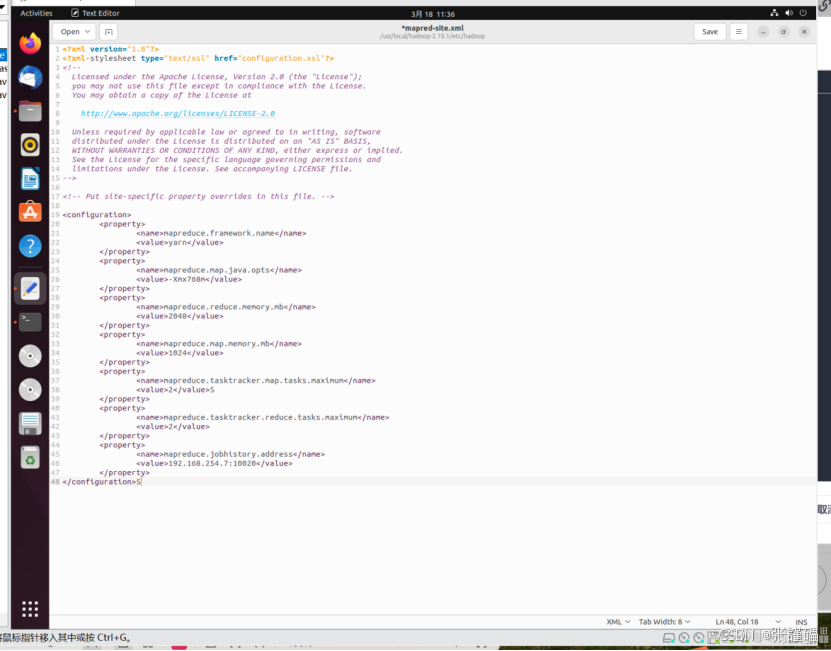
编辑 mapred-site.xml 进行配置
增加下面代,将里面的192.168.254.7改为自己的实际地址
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.254.7:10020</value>
</property>
(4)启动
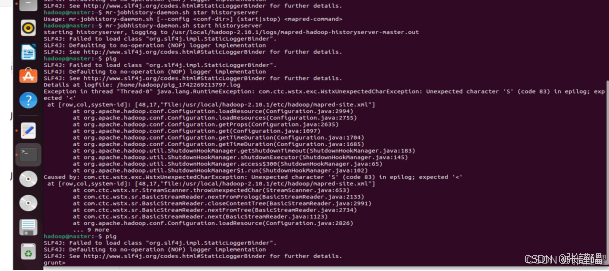
启动 Yarn 的 HistoryServer,记录所有执行过的任务
mr-jobhistory-daemon.sh start historyserver
启动pig
pig
测试
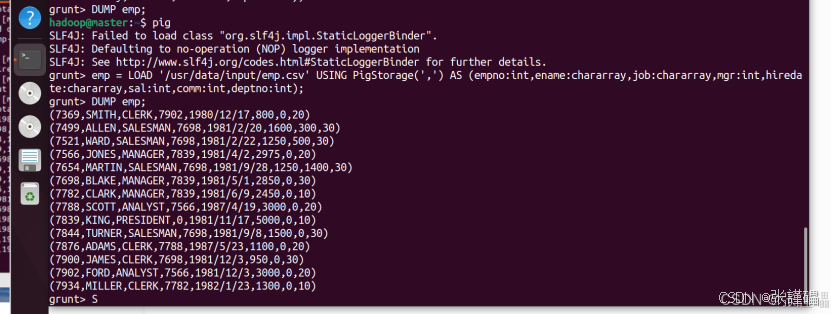
(1)从文件导入数据
emp = LOAD '/usr/data/input/emp.csv' USING PigStorage(',') AS (empno:int,ename:chararray,job:chararray,mgr:int,hiredate:chararray,sal:int,comm:int,deptno:int);
(2)查询
DUMP emp;